
- 1最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能_openai gpt4源代码
- 2修改conda环境安装路径,解决环境默认安装在C盘问题_conda可执行文件路径怎么选
- 3【Python】Linux、Windows更换镜像源(pip、conda、pycharm)_linux 修改python镜像源
- 401背包问题_01背包问题 csdn
- 5han模型,fastext,textCNN_han特征筛选
- 6Docker:将docker的node-red容器连同安装的节点保存为docker镜像(打成tar包)
- 7centos7 网卡聚合bond0模式配置_centos7 配置bond
- 8Unity误删解决方案_unity误删场景文件
- 9【c++20】CPP-20-STL-Cookbook 学习笔记
- 10大模型: 提示词工程(prompt engineering)_大模型的提示词作用是什么
从0到1 | 手把手教你如何使用哈工大NLP工具——PyLTP!
赞
踩

作者 | 杨秀璋
来源 | CSDN 博客(CSDN id:Eastmount)
(本文经作者授权,此系列文章整理后微信平台首发于AI科技大本营)
【导语】此文是作者基于 Python 构建知识图谱的系列实践教程,具有一定创新性和实用性。文章前半部分内容先介绍哈工大 pytltp 工具,包括安装过程、中文分词、词性标注和实体识别的一些基本用法;后半部分内容讲解词性标注、实体识别、依存句法分析和语义角色标注及代码实现。
【上篇】
一、哈工大LTP
LTP(Language Technology Platform)中文为语言技术平台,是哈工大社会计算与信息检索研究中心开发的一整套中文语言处理系统。LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块(包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library,DLL)的应用程序接口,可视化工具,并且能够以网络服务的形式进行使用。
LTP开发文档:
https://ltp.readthedocs.io/zh_CN/latest/index.html
语言云LTP-Cloud:
http://www.ltp-cloud.com/
模型下载地址:
http://ltp.ai/download.html
在线演示案例如下图所示:
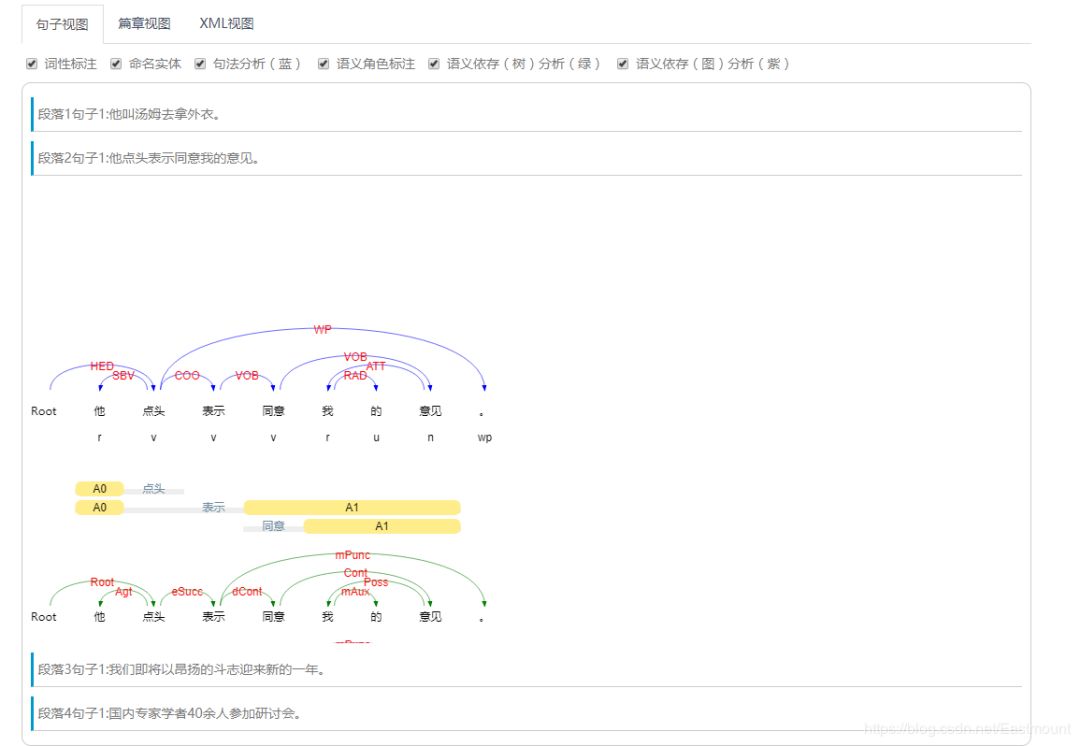
相信从事NLP、数据挖掘、知识图谱等领域的博友都知道哈工大LTP、同义词词林这些工具,该系列文章也会介绍相关的知识,希望对您有所帮助。
此外,再补充另一个在线NLP分析系统,感兴趣的朋友们也可以试一下~
http://ictclas.nlpir.org/nlpir/
二.pyltp 终极安装
下面介绍 Windows10 Python 环境下 LTP 的扩展包 pyltp 安装过程。
1.常见错误
大家通常会调用 “pip install pyltp” 安装该扩展包,但会遇到各种错误,下面介绍一种可行的方法。
2.安装pyltp包
首先,安装Python3.6环境,如下图所示“python-3.6.7-amd64.exe”。

接着,下载pyltp扩展包的whl文件至本地,调用CMD环境进行安装,注意需要将所在文件的路径写清楚。
- pyltp-0.2.1-cp35-cp35m-win_amd64.whl (对应Python3.5版本)
- pyltp-0.2.1-cp36-cp36m-win_amd64.whl (对应Python3.6版本)
- pip install C:\Python36\Scripts\pyltp-0.2.1-cp36-cp36m-win_amd64.whl
whl下载地址:
https://download.csdn.net/download/qq_22521211/10460778
安装过程下图所示,此时表示pyltp安装成功。
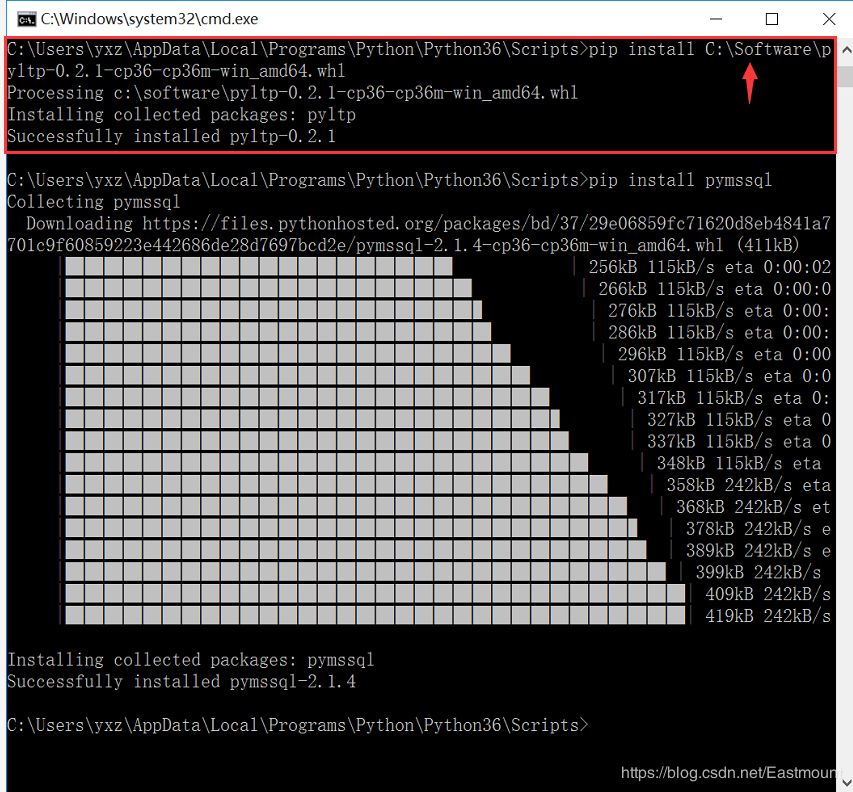
注意,如果报错“error:Microsoft Visual C++ 9.0 is required”,则安装下面exe文件。

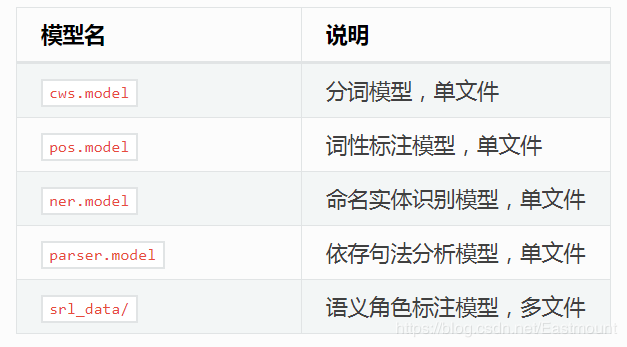
3.下载模型文件
最后需要下载模型文件,其下载地址为:
百度云
https://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569#list/path=%2F
七牛云
http://ltp.ai/download.html
本文下载3.4版本的模型,下载解压如下图所示:

模型对应的说明如下图所示:
在编写代码时,需要导入指定文件夹中的模型,再进行中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注等分析。例如:
- #词性标注
- pdir='AgriKG\\ltp\\pos.model'
- pos = Postagger()
- pos.load(pdir)
- postags = pos.postag(word) #基于分词得到的list将下词性标注
- postags = list(postags)
- print(u"词性:", postags)
分词、词性标注、句法分析一系列任务之间存在依赖关系。举例来讲,对于词性标注,必须在分词结果之上进行才有意义。LTP中提供的5种分析之间的依赖关系如下所示:
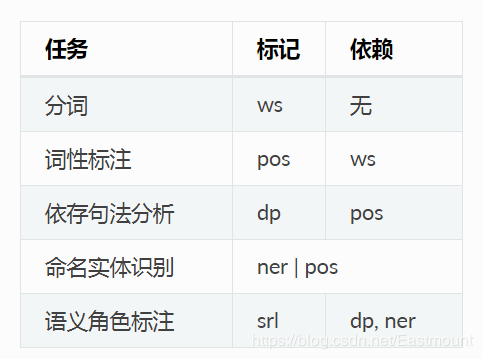
讲到这里,哈工大pyltp基本安装成功,接下来将介绍它的基本用法。
基础性文章,希望对入门者有所帮助。
三.中文分句和分词
官方文档:
https://pyltp.readthedocs.io/zh_CN/latest/api.html#id13
实现原理:
https://ltp.readthedocs.io/zh_CN/latest/theory.html#customized-cws-reference-label
1.中文分句
- # -*- coding: utf-8 -*-
- from pyltp import SentenceSplitter
- from pyltp import Segmentor
- from pyltp import Postagger
- from pyltp import NamedEntityRecognizer
- #分句
- text = "贵州财经大学要举办大数据比赛吗?那让欧几里得去问问看吧!其实是在贵阳花溪区吧。"
- sents = SentenceSplitter.split(text)
- print('\n'.join(sents))
中文分句的输出结果如下所示:
- 贵州财经大学要举办大数据比赛吗?
- 那让欧几里得去问问看吧!
- 其实是在贵阳花溪区吧。
2.中文分词
- # -*- coding: utf-8 -*-
- from pyltp import SentenceSplitter
- from pyltp import Segmentor
- from pyltp import Postagger
- from pyltp import NamedEntityRecognizer
-
- text = "贵州财经大学要举办大数据比赛吗?那让欧几里得去问问看吧!其实是在贵阳花溪区吧。"
-
- #中文分词
- segmentor = Segmentor() #初始化实例
- segmentor.load("AgriKG\\ltp\\cws.model") #加载模型
- words = segmentor.segment(text) #分词
- print(type(words))
- print(' '.join(words))
- segmentor.release() #释放模型
输出结果如下所示(人工换行):
- <class 'pyltp.VectorOfString'>
- 贵州 财经 大学 要 举办 大 数据 比赛 吗 ?
- 那 让 欧 几 里 得 去 问问 看 吧 !
- 其实 是 在 贵阳 花溪区 吧 。
此时的分词效果并不理想,如 “大数据” 分为了“大”、“数据”,“欧几里得”分为了“欧”、“几”、“里”、“得”,“贵阳花溪区”分为了“贵阳”、“花溪区”等,故需要引入词典进行更为准确的分词。同时,返回值类型是native的VectorOfString类型,可以使用list转换成Python的列表类型。
3.导入词典中文分词
pyltp 分词支持用户使用自定义词典。分词外部词典本身是一个文本文件(plain text),每行指定一个词,编码同样须为 UTF-8,比如“word”文件,如下图所示:
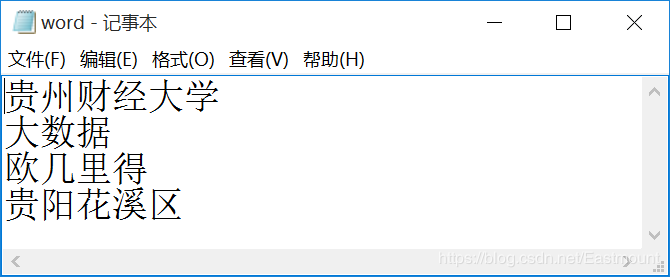
完整代码如下所示:
- # -*- coding: utf-8 -*-
- from pyltp import SentenceSplitter
- from pyltp import Segmentor
- from pyltp import Postagger
- from pyltp import NamedEntityRecognizer
-
- ldir='AgriKG\\ltp\\cws.model' #分词模型
- dicdir='word' #外部字典
- text = "贵州财经大学要举办大数据比赛吗?那让欧几里得去问问看吧!其实是在贵阳花溪区吧。"
-
- #中文分词
- segmentor = Segmentor() #初始化实例
- segmentor.load_with_lexicon(ldir, 'word') #加载模型
- words = segmentor.segment(text) #分词
- print(' '.join(words)) #分词拼接
- words = list(words) #转换list
- print(u"分词:", words)
- segmentor.release() #释放模型

输出结果如下所示,它将“大数据”、“欧几里得”、“贵阳花溪区”进行了词典匹配,再进行相关分词,但是“贵州财经大学”仍然划分为“贵州”、“财经”、“大学”。Why?
- 贵州 财经 大学 要 举办 大数据 比赛 吗 ?
- 那 让 欧几里得 去 问问 看 吧 !
- 其实 是 在 贵阳花溪区 吧 。
- 分词: ['贵州', '财经', '大学', '要', '举办', '大数据', '比赛', '吗', '?',
- '那', '让', '欧几里得', '去', '问问', '看', '吧', '!',
- '其实', '是', '在', '贵阳花溪区', '吧', '。']
4.个性化分词
个性化分词是 LTP 的特色功能。个性化分词为了解决测试数据切换到如小说、财经等不同于新闻领域的领域。在切换到新领域时,用户只需要标注少量数据。个性化分词会在原有新闻数据基础之上进行增量训练。从而达到即利用新闻领域的丰富数据,又兼顾目标领域特殊性的目的。
pyltp 支持使用用户训练好的个性化模型。关于个性化模型的训练需使用 LTP,详细介绍和训练方法请参考 个性化分词 。在 pyltp 中使用个性化分词模型的示例如下:
- # -*- coding: utf-8 -*-
- from pyltp import CustomizedSegmentor
- customized_segmentor = CustomizedSegmentor() #初始化实例
- customized_segmentor.load('基本模型', '个性模型') #加载模型
- words = customized_segmentor.segment('亚硝酸盐是一种化学物质')
- print '\t'.join(words)
- customized_segmentor.release()
【下篇】
词性标注、实体识别、依存句法分析和语义角色标注及代码实现
一.词性标注
词性标注(Part-Of-Speech tagging, POS tagging)也被称为语法标注(grammatical tagging)或词类消疑(word-category disambiguation),是语料库语言学(corpus linguistics)中将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术。
pyltp词性标注与分词模块相同,将词性标注任务建模为基于词的序列标注问题。对于输入句子的词序列,模型给句子中的每个词标注一个标识词边界的标记。在LTP中,采用的北大标注集。
完整代码:
- # -*- coding: utf-8 -*-
- from pyltp import SentenceSplitter
- from pyltp import Segmentor
- from pyltp import Postagger
- from pyltp import NamedEntityRecognizer
-
- ldir='AgriKG\\ltp\\cws.model' #分词模型
- dicdir='word' #外部字典
- text = "贵州财经大学要举办大数据比赛吗?"
-
- #中文分词
- segmentor = Segmentor() #初始化实例
- segmentor.load_with_lexicon(ldir, 'word') #加载模型
- words = segmentor.segment(text) #分词
- print(text)
- print(' '.join(words)) #分词拼接
- words = list(words) #转换list
- print(u"分词:", words)
- segmentor.release() #释放模型
-
- #词性标注
- pdir='AgriKG\\ltp\\pos.model'
- pos = Postagger() #初始化实例
- pos.load(pdir) #加载模型
-
- postags = pos.postag(words) #词性标注
- postags = list(postags)
- print(u"词性:", postags)
- pos.release() #释放模型
-
- data = {"words": words, "tags": postags}
- print(data)
输出结果如下图所示,“贵州”词性为“ns”(地理名词 ),“财经”词性为“n”(一般名词),“举办”词性为“v”(动词),“吗”词性为“u”(助词),“?”词性为“wp”(标点)。
- 贵州财经大学要举办大数据比赛吗?
- 贵州 财经 大学 要 举办 大数据 比赛 吗 ?
- 分词: ['贵州', '财经', '大学', '要', '举办', '大数据', '比赛', '吗', '?']
- 词性: ['ns', 'n', 'n', 'v', 'v', 'n', 'v', 'u', 'wp']
- {'words': ['贵州', '财经', '大学', '要', '举办', '大数据', '比赛', '吗', '?'],
- 'tags': ['ns', 'n', 'n', 'v', 'v', 'n', 'v', 'u', 'wp']}
具体词性为:
- Tag Description Example
- a adjective:形容词 美丽
- b other noun-modifier:其他的修饰名词 大型, 西式
- c conjunction:连词 和, 虽然
- d adverb:副词 很
- e exclamation:感叹词 哎
- g morpheme 茨, 甥
- h prefix:前缀 阿, 伪
- i idiom:成语 百花齐放
- j abbreviation:缩写 公检法
- k suffix:后缀 界, 率
- m number:数字 一, 第一
- n general noun:一般名词 苹果
- nd direction noun:方向名词 右侧
- nh person name:人名 杜甫, 汤姆
- ni organization name:公司名 保险公司,中国银行
- nl location noun:地点名词 城郊
- ns geographical name:地理名词 北京
- nt temporal noun:时间名词 近日, 明代
- nz other proper noun:其他名词 诺贝尔奖
- o onomatopoeia:拟声词 哗啦
- p preposition:介词 在, 把,与
- q quantity:量词 个
- r pronoun:代词 我们
- u auxiliary:助词 的, 地
- v verb:动词 跑, 学习
- wp punctuation:标点 ,。!
- ws foreign words:国外词 CPU
- x non-lexeme:不构成词 萄, 翱
- z descriptive words 描写,叙述的词 瑟瑟,匆匆
二.命名实体识别
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。
在哈工大Pyltp中,NE识别模块的标注结果采用O-S-B-I-E标注形式,其含义如下(参考):
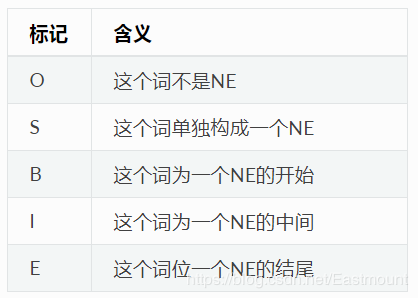
LTP中的NE 模块识别三种NE,分别为人名(Nh)、机构名(Ni)、地名(Ns)。
完整代码:
- # -*- coding: utf-8 -*-
- from pyltp import SentenceSplitter
- from pyltp import Segmentor
- from pyltp import Postagger
- from pyltp import NamedEntityRecognizer
-
- ldir='AgriKG\\ltp\\cws.model' #分词模型
- dicdir='word' #外部字典
- text = "贵州财经大学要举办大数据比赛吗?"
-
- #中文分词
- segmentor = Segmentor() #初始化实例
- segmentor.load_with_lexicon(ldir, 'word') #加载模型
- words = segmentor.segment(text) #分词
- print(text)
- print(' '.join(words)) #分词拼接
- words = list(words) #转换list
- print(u"分词:", words)
- segmentor.release() #释放模型
-
- #词性标注
- pdir='AgriKG\\ltp\\pos.model'
- pos = Postagger() #初始化实例
- pos.load(pdir) #加载模型
-
- postags = pos.postag(words) #词性标注
- postags = list(postags)
- print(u"词性:", postags)
- pos.release() #释放模型
-
- data = {"words": words, "tags": postags}
- print(data)
- print(" ")
-
- #命名实体识别
- nermodel='AgriKG\\ltp\\ner.model'
- reg = NamedEntityRecognizer() #初始化命名实体实例
- reg.load(nermodel) #加载模型
- netags = reg.recognize(words, postags) #对分词、词性标注得到的数据进行实体标识
- netags = list(netags)
- print(u"命名实体识别:", netags)
-
- #实体识别结果
- data={"reg": netags,"words":words,"tags":postags}
- print(data)
- reg.release()
输出结果如下图所示,识别出的三个命名实体分别是:“贵州”(B-Ni)表示一个NE开始-机构名,“财经”(I-Ni)表示一个NE中间-机构名,“大学”(E-Ni)表示一个NE结束-机构名。
PS:虽然导入指定词典,但“贵州财经大学”分词仍然被分割,后续研究中。

三.依存句法分析
依存句法是由法国语言学家L.Tesniere最先提出。它将句子分析成一棵依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。如下图所示:
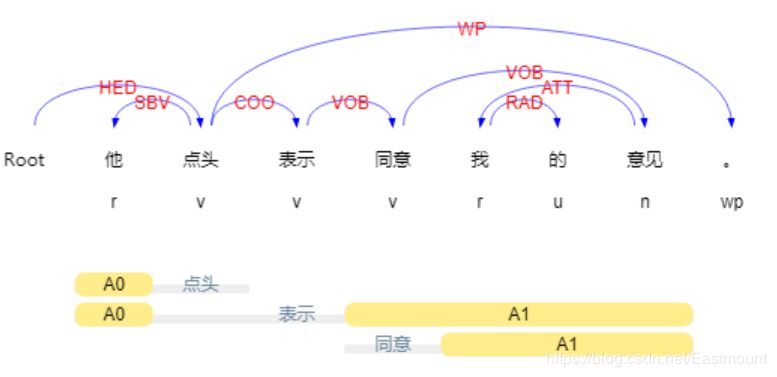
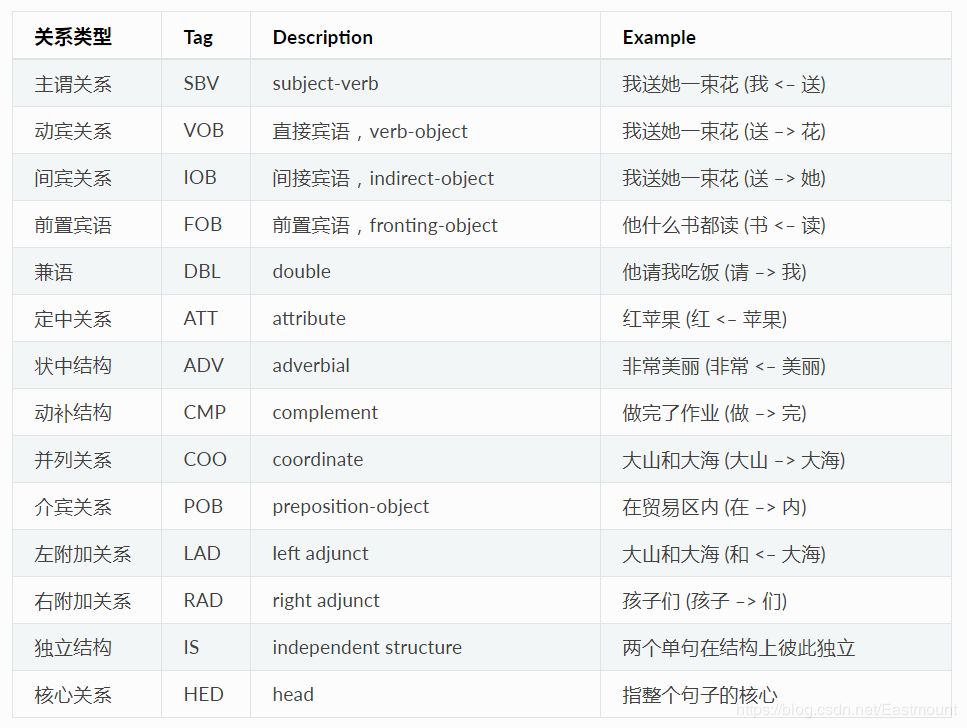
哈工大Pyltp的依存句法关系如下图所示。
参考:
https://ltp.readthedocs.io/zh_CN/latest/appendix.html
完整代码:
- # -*- coding: utf-8 -*-
- from pyltp import SentenceSplitter
- from pyltp import Segmentor
- from pyltp import Postagger
- from pyltp import Parser
- from pyltp import NamedEntityRecognizer
-
- ldir = 'AgriKG\\ltp\\cws.model' #分词模型
- dicdir = 'word' #外部字典
- text = "贵州财经大学要举办大数据比赛吗?"
-
- #中文分词
- segmentor = Segmentor() #初始化实例
- segmentor.load_with_lexicon(ldir, 'word') #加载模型
- words = segmentor.segment(text) #分词
- print(text)
- print(' '.join(words)) #分词拼接
- words = list(words) #转换list
- print(u"分词:", words)
- segmentor.release() #释放模型
-
- #词性标注
- pdir = 'AgriKG\\ltp\\pos.model'
- pos = Postagger() #初始化实例
- pos.load(pdir) #加载模型
-
- postags = pos.postag(words) #词性标注
- postags = list(postags)
- print(u"词性:", postags)
- pos.release() #释放模型
-
- data = {"words": words, "tags": postags}
- print(data)
- print(" ")
-
- #命名实体识别
- nermodel = 'AgriKG\\ltp\\ner.model'
- reg = NamedEntityRecognizer() #初始化命名实体实例
- reg.load(nermodel) #加载模型
- netags = reg.recognize(words, postags) #对分词、词性标注得到的数据进行实体标识
- netags = list(netags)
- print(u"命名实体识别:", netags)
-
- #实体识别结果
- data={"reg": netags,"words":words,"tags":postags}
- print(data)
- reg.release() #释放模型
- print(" ")
-
- #依存句法分析
- parmodel = 'AgriKG\\ltp\\parser.model'
- parser = Parser() #初始化命名实体实例
- parser.load(parmodel) #加载模型
- arcs = parser.parse(words, postags) #句法分析
-
- #输出结果
- print(words)
- print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
-
- rely_id = [arc.head for arc in arcs] # 提取依存父节点id
- relation = [arc.relation for arc in arcs] # 提取依存关系
- heads = ['Root' if id == 0 else words[id-1] for id in rely_id] # 匹配依存父节点词语
- for i in range(len(words)):
- print(relation[i] + '(' + words[i] + ', ' + heads[i] + ')')
-
- parser.release()
输出结果如下所示,其中ATT表示定中关系,如“贵州-大学”、“财经-大学”;SBV表示主谓关系,如“大学-举办”;ADV表示状中结果“要-举办”;HED表示核心关系“举办-Root”,即“举办大数据”。
补充:arc.head表示依存弧的父节点词的索引,arc.relation表示依存弧的关系。arc.head中的ROOT节点的索引是0,第一个词开始的索引依次为1、2、3。

四.语义角色标注
该部分代码仅供博友们参考,作者还在深入研究中。
- #语义角色标注
- from pyltp import SementicRoleLabeller
-
- srlmodel = 'AgriKG\\ltp\\pisrl.model'
- labeller = SementicRoleLabeller() #初始化实例
- labeller.load(srlmodel) #加载模型
-
- words = ['元芳', '你', '怎么', '看']
- postags = ['nh', 'r', 'r', 'v']
- arcs = parser.parse(words, postags) #依存句法分析
-
- #arcs使用依存句法分析的结果
- roles = labeller.label(words, postags, arcs) #语义角色标注
-
- # 打印结果
- for role in roles:
- print(role.index, "".join(
- ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
-
- labeller.release() #释放模型
输出结果如下:
3 A0:(1,1)ADV:(2,2)上面的例子,由于结果输出一行,所以“元芳你怎么看”有一组语义角色。其谓词索引为3,即“看”。这个谓词有三个语义角色,范围分别是(0,0)即“元芳”,(1,1)即“你”,(2,2)即“怎么”,类型分别是A0、A0、ADV。
希望这篇基础性文章对你有所帮助,如果有错误或不足之处,还请海涵。
原文链接:
https://blog.csdn.net/Eastmount/article/details/90771843
https://blog.csdn.net/Eastmount/article/details/92440722
最近,大家都在谈论高考志愿报考话题,Python大本营也发起投票,欢迎大家与我们交流~
(*本文经作者授权微信平台首发于AI科技大本营,转载请微信联系1092722531)
◆
精彩推荐
◆
比写代码更重要的是抓住下一个技术风口,6月技术福利,BTA大牛带你一起探索未来的技术方向。机器学习、数据分析、自然语言处理、知识图谱等热门领域的大牛们都在关注什么?企业落地实践经验有哪些?扫码参与活动,限时免费获取。

推荐阅读:
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢

