
热门标签
热门文章
- 1Python sklearn模型选择_x = maxabs_scale(x, axis=1)
- 2spring 和spring boot的区别
- 3名帖212 赵孟頫 行书《秋兴赋》_赵孟頫秋兴赋
- 4Code Interpreter - AI助力代码理解
- 5图像编辑之对比度调整(亮度对比度的算法公式)_对比度算法原理
- 6爬虫 - requests + xpath 爬取猫眼电影排行榜 TOP100_爬取猫眼电影top100排行榜,电影名及评分(xpath或bs
- 7vue3简易对话窗口_vue实现一个聊天对话框
- 8聊聊CVE漏洞编号和正式公开那些事_cve reserved后
- 9Jetson Nano之ROS入门 -- YOLO目标检测与定位_jetson nano yolo
- 10科大学长对数学系学弟学妹的忠告_狄多涅现代分析基础
当前位置: article > 正文
数据分享|纯净音自然多轮对话数据集——语音大模型_自发风格语音
作者:凡人多烦事01 | 2024-04-06 05:57:17
赞
踩
自发风格语音
在过去的一年里,大语言模型一路高歌猛进,让人惊艳的产品不断被推出。语音大模型也迎来突破,其中就包括还原度越来越高的声音复刻技术。
优秀的语音复刻性能离不开高质量的训练数据支撑。语音大模型构建需要大量的自然数据,尽可能保证自然度,内容多样性,以及口音多样性。晴数智慧设计的纯净音自然多轮对话数据集,为语音大模型训练使用,录制环境安静纯净,录音人地区分布广泛,人数众多,领域设计广泛,版权清晰,是市面上不可多得的语音复刻/对话大模型的高品质选择。
数据概览

数据亮点
1、纯净录制环境
数据采集环节对环境进行了配置,确保采集环境相对安静,环境噪音少。
2、多风格自发对话
此数据集含有说话人在多种状态下的自发对话,包括商务工作、购物咨询、争议协商、闲聊等状态,帮助机器学习及掌握人类在多种对话状态下的发音特征和风格从而实现更好地拟合。
3、风格、领域多样性
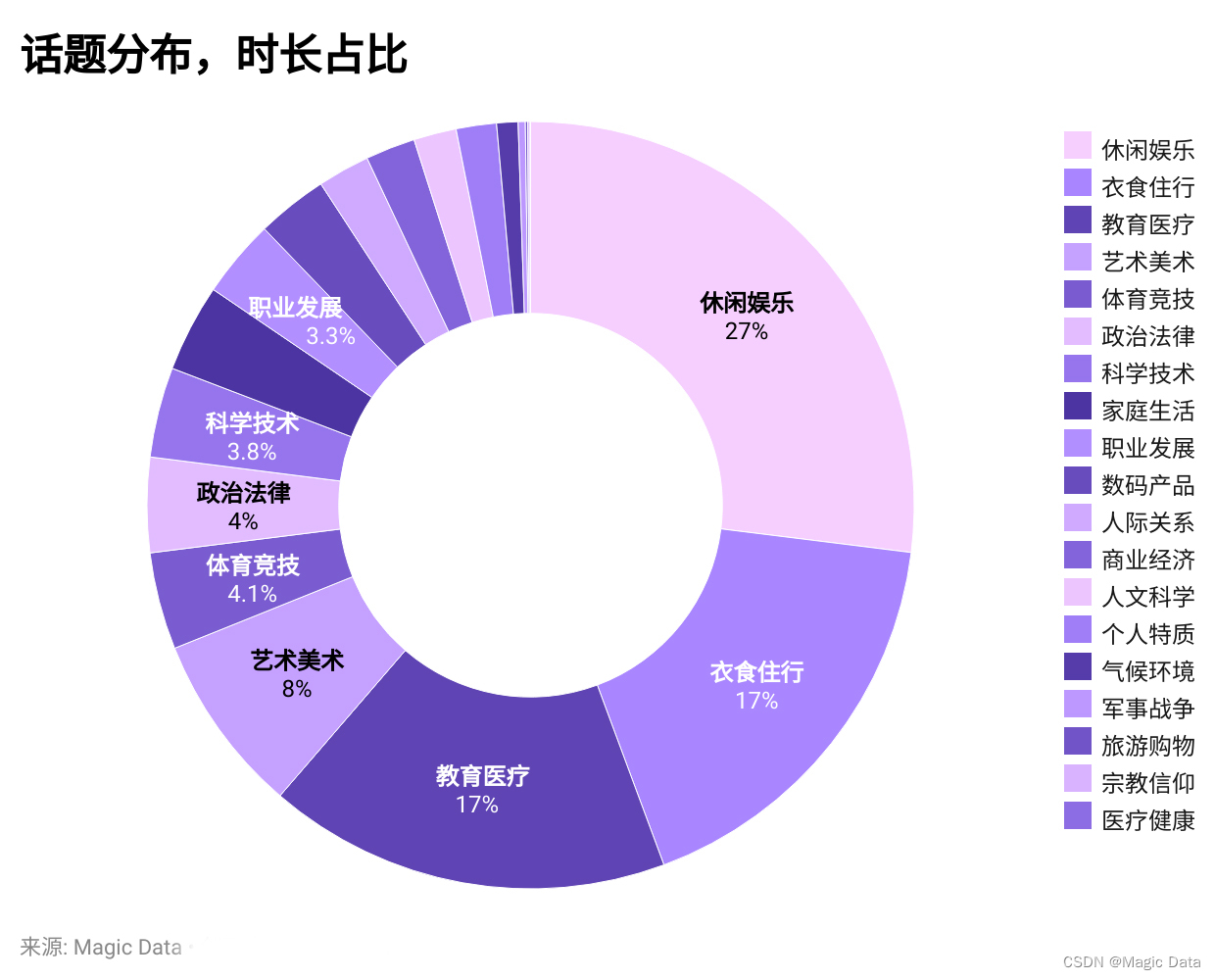
此数据集采集自来自中国30个省份的说话人,地域分布均衡,涵盖18-60岁的说话人,囊括了普遍的说话风格与特点;同时内容覆盖商业经济、数码产品等20类话题,具有极高的话题丰富度。


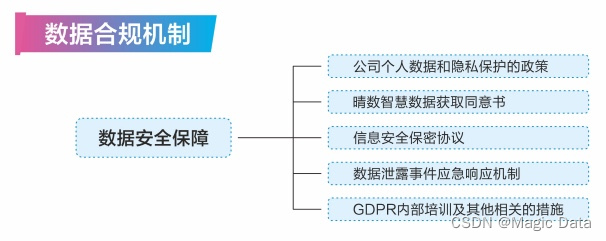
数据合规
晴数智慧高纯净音自然多轮对话数据集处理过程遵循完整的晴数智慧数据合规保障机制,在整个数据生命周期中,保证数据的流转可溯性,确保数据版权完整。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/370180
推荐阅读
相关标签

