
热门标签
热门文章
- 1程序员又背锅?美团外卖声明“杀熟会员”是技术原因,软件定位缓存导致配送费不准!网友:程序员太惨!...
- 2PyTorch入门-词向量_pytorch 词向量
- 3Efficient Large Language Models: A Survey
- 4微博评论情感分析-百度自然语言处理API使用教程_contentalldf = self.get_comment_ori(self.textpath)
- 52024最全的Sora学习资料合集
- 6达观数据CEO陈运文:“AI+RPA”如何赋能企业数字化转型
- 7车道线检测之-sobel算子边缘检测原理介绍_sobel算子是canny边缘检测里的吗
- 8基于最大相关最小冗余的特征选择方法MRMR_最大相关最小冗余特征选择
- 9超炫酷的网红游戏主播/带货达人/歌手/人物介绍视频素材PR模板
- 10简单对已有云服务器进行linux环境搭建以及共享服务器
当前位置: article > 正文
Transformer硬件实现第一篇:算法结构拆解_nv transformer硬件实现
作者:凡人多烦事01 | 2024-04-06 17:06:35
赞
踩
nv transformer硬件实现
本文借鉴引用1的知乎文章,进行了细节的补充,根据后期硬件实现需要做了重新介绍与排版,感谢知乎博主。阅读本文建议先阅读引用1的知乎文章。
Transformer硬件实现第一篇算法结构分析,作为数字电路领域的学生,后期会不断更新,最终利用Verilog语言设计一个Transformer加速器。
前言
Transformer是全连接层+Attention的结合体。任意单词之间的距离是1,解决了NLP的长期依赖问题。并行性好,应用不局限在nlp。
彻底摒弃了rnn和cnn,丧失了局步特征捕捉能力,三者结合带来更好结果。模型无法捕捉位置信息,Position Embedding只是权宜之计。
实现Transformer硬件加速器,首先需要理解算法的各个计算单元。
零、顶层结构
Transformer本质是一个Encoder和Decoder模型。Encoder和Decoder各包含6个block。对1个block,结构如下:
1.数据送入self-attention模块,得到加权的特征向量Z,即
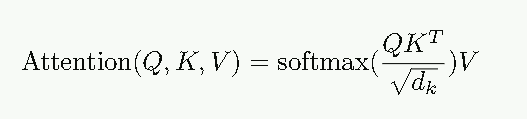
2.得到的结果Z送入二层前馈网络层,第一层为ReLU,第二层为全连接层。
一与二步骤完成Encoder的计算,现在将得到的结果送入Decoder。Decoder由Self-attention + Encoder-decoder attention + 前馈网络组成。
3.Self-attention:上下文的关系,即当前句子与之
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/373218
推荐阅读
相关标签

