
- 1self attention 摘自李宏毅老师公开课_李宏毅 qkv
- 2chatgpt赋能python:如何创建空矩阵_python创建空矩阵
- 3图像处理的未来:揭秘扫描全能王的AI驱动创新_ai-scan
- 4Pytorch for training1——read data/image
- 5制造业数据挖掘的一些思考(2023年)
- 6Android emulator无法启动的解决方法_没都会弹 android emulator closed unexpectedly
- 7鸿蒙Harmony跨模块交互_鸿蒙打开另外一个module的页面
- 8构建高效外卖配送系统:技术要点与实际代码示例
- 9计算机考研复试题目大全_计算机专业考研题库
- 10医学图像分割:UNet++
深度学习应用篇-计算机视觉-图像分类[3]:ResNeXt、Res2Net、Swin Transformer、Vision Transformer等模型结构、实现、模型特点详细介绍_res2net预训练模型
赞
踩

【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等

专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等
本专栏主要方便入门同学快速掌握相关知识。后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。
声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
专栏订阅:
深度学习应用篇-计算机视觉-图像分类[3]:ResNeXt、Res2Net、Swin Transformer、Vision Transformer等模型结构、实现、模型特点详细介绍
1.ResNet
相较于VGG的19层和GoogLeNet的22层,ResNet可以提供18、34、50、101、152甚至更多层的网络,同时获得更好的精度。但是为什么要使用更深层次的网络呢?同时,如果只是网络层数的堆叠,那么为什么前人没有获得ResNet一样的成功呢?
1.1. 更深层次的网络?
从理论上来讲,加深深度学习网络可以提升性能。深度网络以端到端的多层方式集成了低/中/高层特征和分类器,且特征的层次可通过加深网络层次的方式来丰富。举一个例子,当深度学习网络只有一层时,要学习的特征会非常复杂,但如果有多层,就可以分层进行学习,如 图1 所示,网络的第一层学习到了边缘和颜色,第二层学习到了纹理,第三层学习到了局部的形状,而第五层已逐渐学习到全局特征。网络的加深,理论上可以提供更好的表达能力,使每一层可以学习到更细化的特征。

1.2. 为什么深度网络不仅仅是层数的堆叠?
1.2.1 梯度消失 or 爆炸
但网络加深真的只有堆叠层数这么简单么?当然不是!首先,最显著的问题就是梯度消失/梯度爆炸。我们都知道神经网络的参数更新依靠梯度反向传播(Back Propagation),那么为什么会出现梯度的消失和爆炸呢?举一个例子解释。如 图2 所示,假设每层只有一个神经元,且激活函数使用Sigmoid函数,则有:
z i + 1 = w i a i + b i a i + 1 = σ ( z i + 1 ) z_{i+1} = w_ia_i+b_i\\ a_{i+1} = \sigma(z_{i+1}) zi+1=wiai+biai+1=σ(zi+1)
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 为sigmoid函数。

根据链式求导和反向传播,我们可以得到:
∂
y
∂
a
1
=
∂
y
∂
a
4
∂
a
4
∂
z
4
∂
z
4
∂
a
3
∂
a
3
∂
z
3
∂
z
3
∂
a
2
∂
a
2
∂
z
2
∂
z
2
∂
a
1
=
∂
y
∂
a
4
σ
′
(
z
4
)
w
3
σ
′
(
z
3
)
w
2
σ
′
(
z
2
)
w
1
\frac{\partial y}{\partial a_1} = \frac{\partial y}{\partial a_4}\frac{\partial a_4}{\partial z_4}\frac{\partial z_4}{\partial a_3}\frac{\partial a_3}{\partial z_3}\frac{\partial z_3}{\partial a_2}\frac{\partial a_2}{\partial z_2}\frac{\partial z_2}{\partial a_1} \\ = \frac{\partial y}{\partial a_4}\sigma^{'}(z_4)w_3\sigma^{'}(z_3)w_2\sigma^{'}(z_2)w_1
∂a1∂y=∂a4∂y∂z4∂a4∂a3∂z4∂z3∂a3∂a2∂z3∂z2∂a2∂a1∂z2=∂a4∂yσ′(z4)w3σ′(z3)w2σ′(z2)w1
Sigmoid 函数的导数
σ
′
(
x
)
\sigma^{'}(x)
σ′(x) 如 图3 所示:
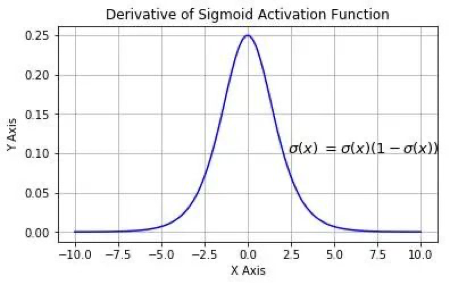
我们可以看到sigmoid的导数最大值为0.25,那么随着网络层数的增加,小于1的小数不断相乘导致 ∂ y ∂ a 1 \frac{\partial y}{\partial a_1} ∂a1∂y 逐渐趋近于零,从而产生梯度消失。
那么梯度爆炸又是怎么引起的呢?同样的道理,当权重初始化为一个较大值时,虽然和激活函数的导数相乘会减小这个值,但是随着神经网络的加深,梯度呈指数级增长,就会引发梯度爆炸。但是从AlexNet开始,神经网络中就使用ReLU函数替换了Sigmoid,同时BN(Batch Normalization)层的加入,也基本解决了梯度消失/爆炸问题。
1.2.2 网络退化
现在,梯度消失/爆炸的问题解决了是不是就可以通过堆叠层数来加深网络了呢?Still no!
我们来看看ResNet论文中提到的例子(见 图4),很明显,56层的深层网络,在训练集和测试集上的表现都远不如20层的浅层网络,这种随着网络层数加深,accuracy逐渐饱和,然后出现急剧下降,具体表现为深层网络的训练效果反而不如浅层网络好的现象,被称为网络退化(degradation)。
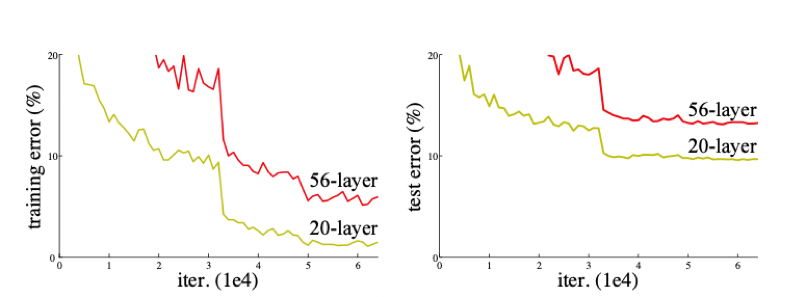
为什么会引起网络退化呢?按照理论上的想法,当浅层网络效果不错的时候,网络层数的增加即使不会引起精度上的提升也不该使模型效果变差。但事实上非线性的激活函数的存在,会造成很多不可逆的信息损失,网络加深到一定程度,过多的信息损失就会造成网络的退化。
而ResNet就是提出一种方法让网络拥有恒等映射能力,即随着网络层数的增加,深层网络至少不会差于浅层网络。
1…3. 残差块
现在我们明白了,为了加深网络结构,使每一次能够学到更细化的特征从而提高网络精度,需要实现的一点是恒等映射。那么残差网络如何能够做到这一点呢?
恒等映射即为 H ( x ) = x H(x) = x H(x)=x,已有的神经网络结构很难做到这一点,但是如果我们将网络设计成 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x,即 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x,那么只需要使残差函数 F ( x ) = 0 F(x) = 0 F(x)=0,就构成了恒等映射 H ( x ) = F ( x ) H(x) = F(x) H(x)=F(x)。
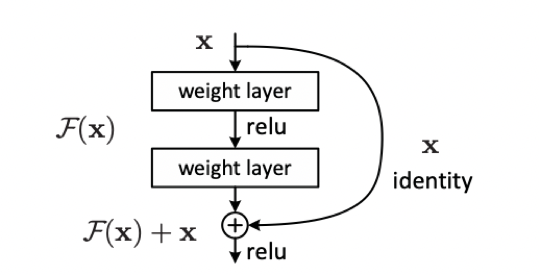
残差结构的目的是,随着网络的加深,使 F ( x ) F(x) F(x) 逼近于0,使得深度网络的精度在最优浅层网络的基础上不会下降。看到这里你或许会有疑问,既然如此为什么不直接选取最优的浅层网络呢?这是因为最优的浅层网络结构并不易找寻,而ResNet可以通过增加深度,找到最优的浅层网络并保证深层网络不会因为层数的叠加而发生网络退化。
- 参考文献
[1] Visualizing and Understanding Convolutional Networks
[2] Deep Residual Learning for Image Recognition
2. ResNeXt(2017)
ResNeXt是由何凯明团队在2017年CVPR会议上提出来的新型图像分类网络。ResNeXt是ResNet的升级版,在ResNet的基础上,引入了cardinality的概念,类似于ResNet,ResNeXt也有ResNeXt-50,ResNeXt-101的版本。那么相较于ResNet,ResNeXt的创新点在哪里?既然是分类网络,那么在ImageNet数据集上的指标相较于ResNet有何变化?之后的ResNeXt_WSL又是什么东西?下面我和大家一起分享一下这些知识。
2.1 ResNeXt模型结构
在ResNeXt的论文中,作者提出了当时普遍存在的一个问题,如果要提高模型的准确率,往往采取加深网络或者加宽网络的方法。虽然这种方法是有效的,但是随之而来的,是网络设计的难度和计算开销的增加。为了一点精度的提升往往需要付出更大的代价。因此,需要一个更好的策略,在不额外增加计算代价的情况下,提升网络的精度。由此,何等人提出了cardinality的概念。
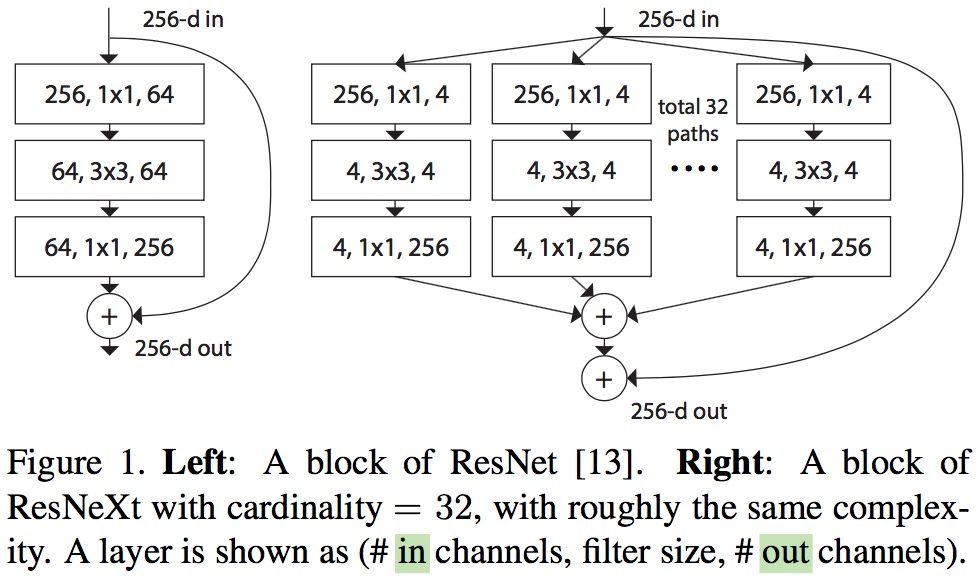
下图是ResNet(左)与ResNeXt(右)block的差异。在ResNet中,输入的具有256个通道的特征经过1×1卷积压缩4倍到64个通道,之后3×3的卷积核用于处理特征,经1×1卷积扩大通道数与原特征残差连接后输出。ResNeXt也是相同的处理策略,但在ResNeXt中,输入的具有256个通道的特征被分为32个组,每组被压缩64倍到4个通道后进行处理。32个组相加后与原特征残差连接后输出。这里cardinatity指的是一个block中所具有的相同分支的数目。
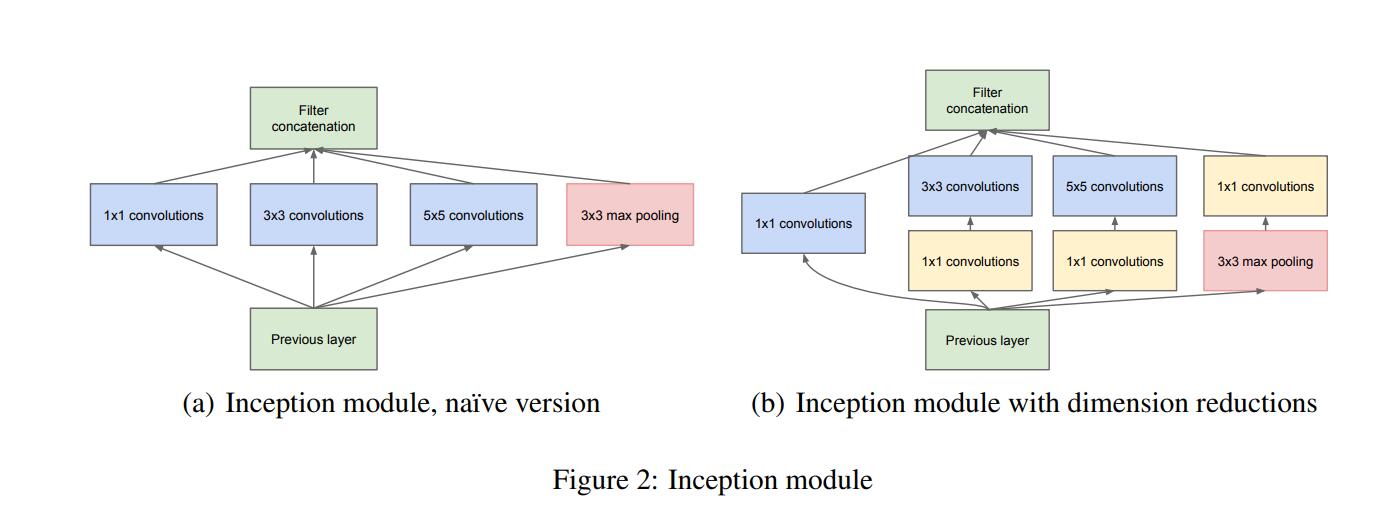
下图是InceptionNet的两种inception module结构,左边是inception module的naive版本,右边是使用了降维方法的inception module。相较于右边,左边很明显的缺点就是参数大,计算量巨大。使用不同大小的卷积核目的是为了提取不同尺度的特征信息,对于图像而言,多尺度的信息有助于网络更好地对图像信息进行选择,并且使得网络对于不同尺寸的图像输入有更好的适应能力,但多尺度带来的问题就是计算量的增加。因此在右边的模型中,InceptionNet很好地解决了这个问题,首先是1×1的卷积用于特征降维,减小特征的通道数后再采取多尺度的结构提取特征信息,在降低参数量的同时捕获到多尺度的特征信息。
ResNeXt正是借鉴了这种“分割-变换-聚合”的策略,但用相同的拓扑结构组建ResNeXt模块。每个结构都是相同的卷积核,保持了结构的简洁,使得模型在编程上更方便更容易,而InceptionNet则需要更为复杂的设计。
2.2 ResNeXt模型实现
ResNeXt与ResNet的模型结构一致,主要差别在于block的搭建,因此这里用paddle框架来实现block的代码
class ConvBNLayer(nn.Layer): def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act=None, name=None, data_format="NCHW" ): super(ConvBNLayer, self).__init__() self._conv = Conv2D( in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, weight_attr=ParamAttr(name=name + "_weights"), bias_attr=False, data_format=data_format ) if name == "conv1": bn_name = "bn_" + name else: bn_name = "bn" + name[3:] self._batch_norm = BatchNorm( num_filters, act=act, param_attr=ParamAttr(name=bn_name + '_scale'), bias_attr=ParamAttr(bn_name + '_offset'), moving_mean_name=bn_name + '_mean', moving_variance_name=bn_name + '_variance', data_layout=data_format ) def forward(self, inputs): y = self._conv(inputs) y = self._batch_norm(y) return y class BottleneckBlock(nn.Layer): def __init__(self, num_channels, num_filters, stride, cardinality, shortcut=True, name=None, data_format="NCHW" ): super(BottleneckBlock, self).__init__() self.conv0 = ConvBNLayer(num_channels=num_channels, num_filters=num_filters, filter_size=1, act='relu', name=name + "_branch2a", data_format=data_format ) self.conv1 = ConvBNLayer( num_channels=num_filters, num_filters=num_filters, filter_size=3, groups=cardinality, stride=stride, act='relu', name=name + "_branch2b", data_format=data_format ) self.conv2 = ConvBNLayer( num_channels=num_filters, num_filters=num_filters * 2 if cardinality == 32 else num_filters, filter_size=1, act=None, name=name + "_branch2c", data_format=data_format ) if not shortcut: self.short = ConvBNLayer( num_channels=num_channels, num_filters=num_filters * 2 if cardinality == 32 else num_filters, filter_size=1, stride=stride, name=name + "_branch1", data_format=data_format ) self.shortcut = shortcut def forward(self, inputs): y = self.conv0(inputs) conv1 = self.conv1(y) conv2 = self.conv2(conv1) if self.shortcut: short = inputs else: short = self.short(inputs) y = paddle.add(x=short, y=conv2) y = F.relu(y) return y

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
2.3 ResNeXt模型特点
- ResNeXt通过控制cardinality的数量,使得ResNeXt的参数量和GFLOPs与ResNet几乎相同。
- 通过cardinality的分支结构,为网络提供更多的非线性,从而获得更精确的分类效果。
2.4 ResNeXt模型指标
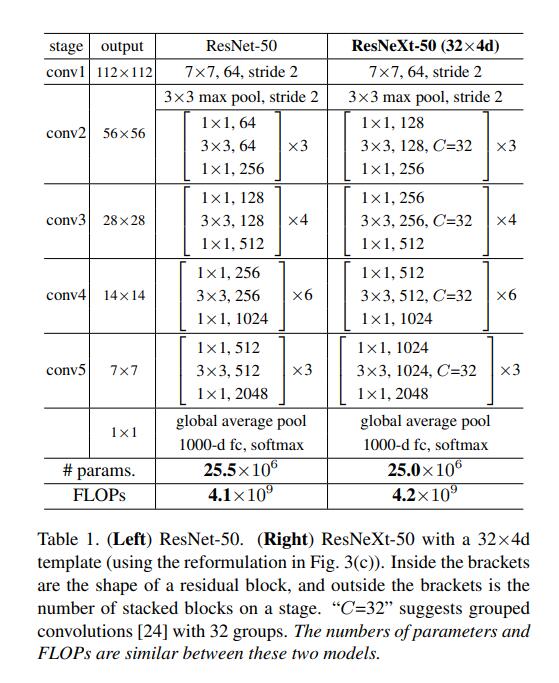
上图是ResNet与ResNeXt的参数对比,可以看出,ResNeXt与ResNet几乎是一模一样的参数量和计算量,然而两者在ImageNet上的表现却不一样。
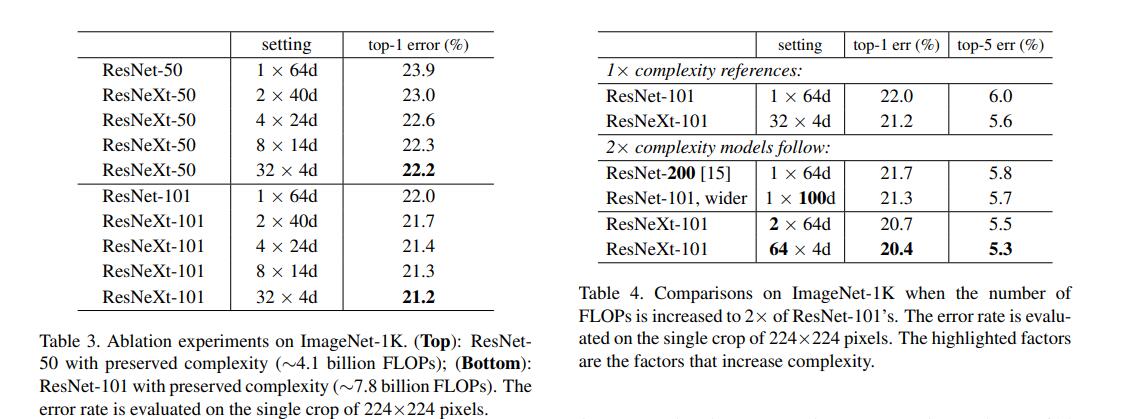
从图中可以看出,ResNeXt除了可以增加block中3×3卷积核的通道数,还可以增加cardinality的分支数来提升模型的精度。ResNeXt-50和ResNeXt-101都大大降低了对应ResNet的错误率。图中,ResNeXt-101从32×4d变为64×4d,虽然增加了两倍的计算量,但也能有效地降低分类错误率。
在2019年何凯明团队开源了ResNeXt_WSL,ResNeXt_WSL是何凯明团队使用弱监督学习训练的ResNeXt,ResNeXt_WSL中的WSL就表示Weakly Supervised Learning(弱监督学习)。
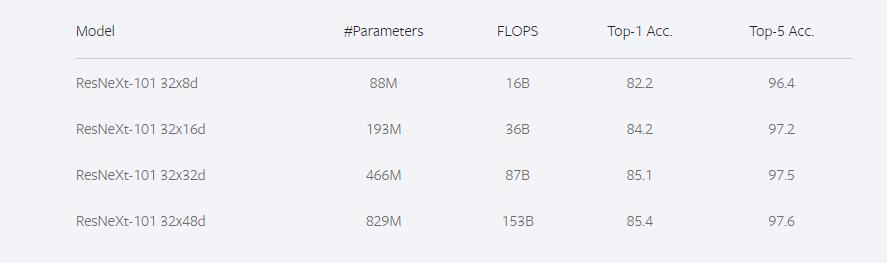
ResNeXt101_32×48d_WSL有8亿+的参数,是通过弱监督学习预训练的方法在Instagram数据集上训练,然后用ImageNet数据集做微调,Instagram有9.4亿张图片,没有经过特别的标注,只带着用户自己加的话题标签。
ResNeXt_WSL与ResNeXt是一样的结构,只是训练方式有所改变。下图是ResNeXt_WSL的训练效果。
-
- 参考文献
ResNet
- 参考文献
3.Res2Net(2020)
2020年,南开大学程明明组提出了一种面向目标检测任务的新模块Res2Net。并且其论文已被TPAMI2020录用。Res2Net和ResNeXt一样,是ResNet的变体形式,只不过Res2Net不止提高了分类任务的准确率,还提高了检测任务的精度。Res2Net的新模块可以和现有其他优秀模块轻松整合,在不增加计算负载量的情况下,在ImageNet、CIFAR-100等数据集上的测试性能超过了ResNet。因为模型的残差块里又有残差连接,所以取名为Res2Net。
3.1 Res2Net模型结构
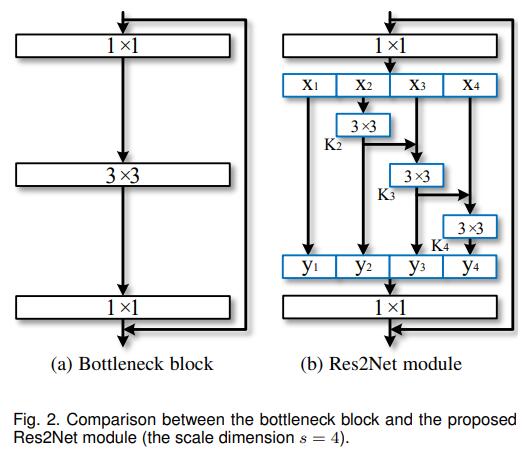
模型结构看起来很简单,将输入的特征x,split为k个特征,第i+1(i = 0, 1, 2,…,k-1) 个特征经过3×3卷积后以残差连接的方式融合到第 i+2 个特征中。这就是Res2Net的主要结构。那么这样做的目的是为什么呢?能够有什么好处呢?
答案就是多尺度卷积。多尺度特征在检测任务中一直是很重要的,自从空洞卷积提出以来,基于空洞卷积搭建的多尺度金字塔模型在检测任务上取得里程碑式的效果。不同感受野下获取的物体的信息是不同的,小的感受野可能会看到更多的物体细节,对于检测小目标也有很大的好处,而大的感受野可以感受物体的整体结构,方便网络定位物体的位置,细节与位置的结合可以更好地得到具有清晰边界的物体信息,因此,结合了多尺度金字塔的模型往往能获得很好地效果。在Res2Net中,特征k2经过3×3卷积后被送入x3所在的处理流中,k2再次被3×3的卷积优化信息,两个3×3的卷积相当于一个5×5的卷积。那么,k3就想当然与融合了3×3的感受野和5×5的感受野处理后的特征。以此类推,7×7的感受野被应用在k4中。就这样,Res2Net提取多尺度特征用于检测任务,以提高模型的准确率。在这篇论文中,s是比例尺寸的控制参数,也就是可以将输入通道数平均等分为多个特征通道。s越大表明多尺度能力越强,此外一些额外的计算开销也可以忽略。
3.2 Res2Net模型实现
Res2Net与ResNet的模型结构一致,主要差别在于block的搭建,因此这里用paddle框架来实现block的代码
class ConvBNLayer(nn.Layer): def __init__( self, num_channels, num_filters, filter_size, stride=1, groups=1, is_vd_mode=False, act=None, name=None, ): super(ConvBNLayer, self).__init__() self.is_vd_mode = is_vd_mode self._pool2d_avg = AvgPool2D( kernel_size=2, stride=2, padding=0, ceil_mode=True) self._conv = Conv2D( in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, weight_attr=ParamAttr(name=name + "_weights"), bias_attr=False) if name == "conv1": bn_name = "bn_" + name else: bn_name = "bn" + name[3:] self._batch_norm = BatchNorm( num_filters, act=act, param_attr=ParamAttr(name=bn_name + '_scale'), bias_attr=ParamAttr(bn_name + '_offset'), moving_mean_name=bn_name + '_mean', moving_variance_name=bn_name + '_variance') def forward(self, inputs): if self.is_vd_mode: inputs = self._pool2d_avg(inputs) y = self._conv(inputs) y = self._batch_norm(y) return y class BottleneckBlock(nn.Layer): def __init__(self, num_channels1, num_channels2, num_filters, stride, scales, shortcut=True, if_first=False, name=None): super(BottleneckBlock, self).__init__() self.stride = stride self.scales = scales self.conv0 = ConvBNLayer( num_channels=num_channels1, num_filters=num_filters, filter_size=1, act='relu', name=name + "_branch2a") self.conv1_list = [] for s in range(scales - 1): conv1 = self.add_sublayer( name + '_branch2b_' + str(s + 1), ConvBNLayer( num_channels=num_filters // scales, num_filters=num_filters // scales, filter_size=3, stride=stride, act='relu', name=name + '_branch2b_' + str(s + 1))) self.conv1_list.append(conv1) self.pool2d_avg = AvgPool2D(kernel_size=3, stride=stride, padding=1) self.conv2 = ConvBNLayer( num_channels=num_filters, num_filters=num_channels2, filter_size=1, act=None, name=name + "_branch2c") if not shortcut: self.short = ConvBNLayer( num_channels=num_channels1, num_filters=num_channels2, filter_size=1, stride=1, is_vd_mode=False if if_first else True, name=name + "_branch1") self.shortcut = shortcut def forward(self, inputs): y = self.conv0(inputs) xs = paddle.split(y, self.scales, 1) ys = [] for s, conv1 in enumerate(self.conv1_list): if s == 0 or self.stride == 2: ys.append(conv1(xs[s])) else: ys.append(conv1(xs[s] + ys[-1])) if self.stride == 1: ys.append(xs[-1]) else: ys.append(self.pool2d_avg(xs[-1])) conv1 = paddle.concat(ys, axis=1) conv2 = self.conv2(conv1) if self.shortcut: short = inputs else: short = self.short(inputs) y = paddle.add(x=short, y=conv2) y = F.relu(y) return y
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
3.3 模型特点
- 可与其他结构整合,如SENEt, ResNeXt, DLA等,从而增加准确率。
- 计算负载不增加,特征提取能力更强大。
3.4 模型指标
ImageNet分类效果如下图
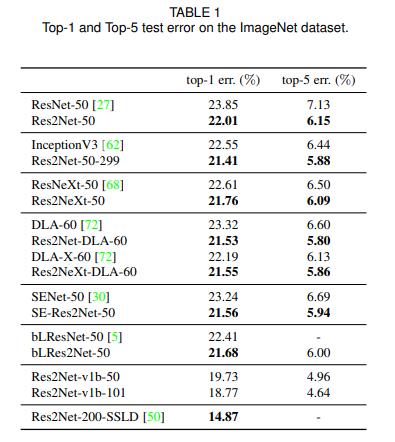
Res2Net-50就是对标ResNet50的版本。
Res2Net-50-299指的是将输入图片裁剪到299×299进行预测的Res2Net-50,因为一般都是裁剪或者resize到224×224。
Res2NeXt-50为融合了ResNeXt的Res2Net-50。
Res2Net-DLA-60指的是融合了DLA-60的Res2Net-50。
Res2NeXt-DLA-60为融合了ResNeXt和DLA-60的Res2Net-50。
SE-Res2Net-50 为融合了SENet的Res2Net-50。
blRes2Net-50为融合了Big-Little Net的Res2Net-50。
Res2Net-v1b-50为采取和ResNet-vd-50一样的处理方法的Res2Net-50。
Res2Net-200-SSLD为Paddle使用简单的半监督标签知识蒸馏(SSLD,Simple Semi-supervised Label Distillation)的方法来提升模型效果得到的。
可见,Res2Net都取得了十分不错的成绩。
COCO数据集效果如下图
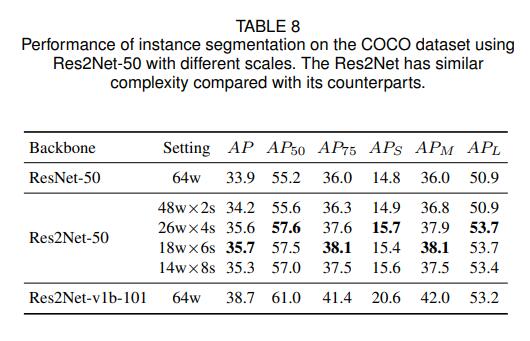
Res2Net-50的各种配置都比ResNet-50高。
显著目标检测数据集指标效果如下图
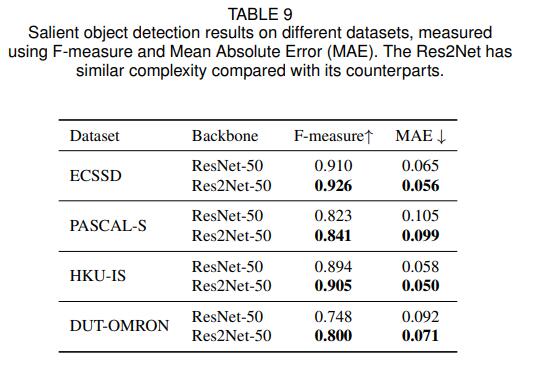
ECSSD、PASCAL-S、DUT-OMRON、HKU-IS都是显著目标检测任务中现在最为常用的测试集,显著目标检测任务的目的就是分割出图片中的显著物体,并用白色像素点表示,其他背景用黑色像素点表示。从图中可以看出来,使用Res2Net作为骨干网络,效果比ResNet有了很大的提升。
- 参考文献
Res2Net
4.Swin Trasnformer(2021)
Swin Transformer是由微软亚洲研究院在今年公布的一篇利用transformer架构处理计算机视觉任务的论文。Swin Transformer 在图像分类,图像分割,目标检测等各个领域已经屠榜,在论文中,作者分析表明,Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:1. 两个领域涉及的scale不同,NLP的token是标准固定的大小,而CV的特征尺度变化范围非常大。2. CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。另外,Swin Transformer可以作为图像分类、目标检测和语义分割等任务的通用骨干网络,可以说,Swin Transformer可能是CNN的完美替代方案。
4.1 Swin Trasnformer模型结构
下图为Swin Transformer与ViT在处理图片方式上的对比,可以看出,Swin Transformer有着ResNet一样的残差结构和CNN具有的多尺度图片结构。

整体概括:
下图为Swin Transformer的网络结构,输入的图像先经过一层卷积进行patch映射,将图像先分割成4 × 4的小块,图片是224×224输入,那么就是56个path块,如果是384×384的尺寸,则是96个path块。这里以224 × 224的输入为例,输入图像经过这一步操作,每个patch的特征维度为4x4x3=48的特征图。因此,输入的图像变成了H/4×W/4×48的特征图。然后,特征图开始输入到stage1,stage1中linear embedding将path特征维度变成C,因此变成了H/4×W/4×C。然后送入Swin Transformer Block,在进入stage2前,接下来先通过Patch Merging操作,Patch Merging和CNN中stride=2的1×1卷积十分相似,Patch Merging在每个Stage开始前做降采样,用于缩小分辨率,调整通道数,当H/4×W/4×C的特征图输送到Patch Merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,之后经过一个MLP,将特征维度降为2C。因此变为H/8×W/8×2C。接下来的stage就是重复上面的过程。
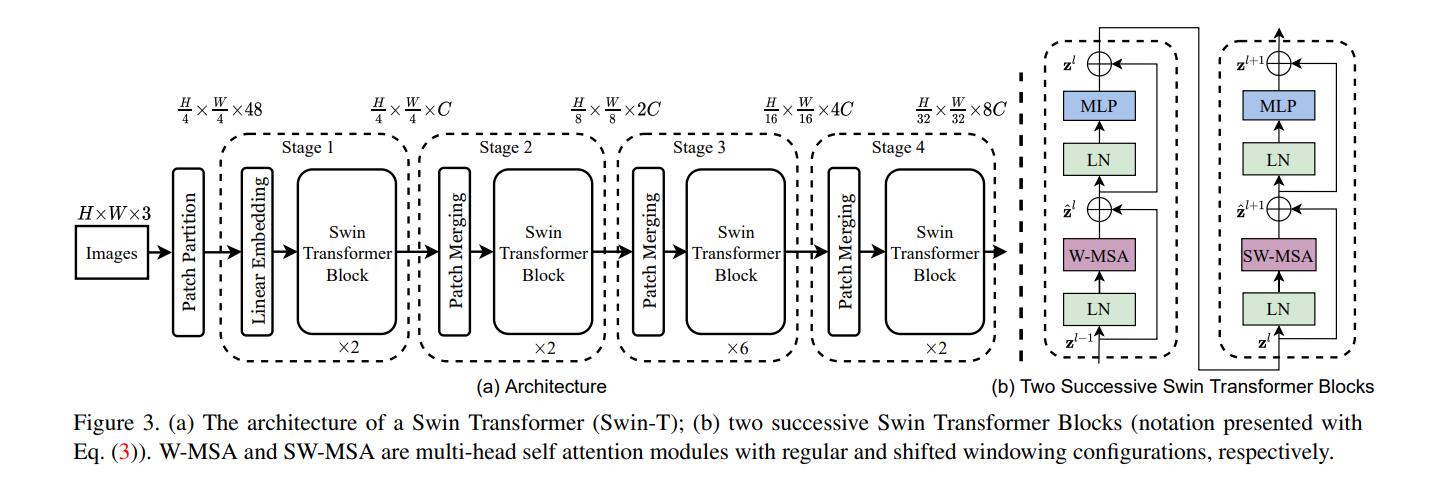
每步细说:
Linear embedding
下面用Paddle代码逐步讲解Swin Transformer的架构。 以下代码为Linear embedding的操作,整个操作可以看作一个patch大小的卷积核和patch大小的步长的卷积对输入的B,C,H,W的图片进行卷积,得到的自然就是大小为 B,C,H/patch,W/patch的特征图,如果放在第一个Linear embedding中,得到的特征图就为 B,96,56,56的大小。Paddle核心代码如下。
class PatchEmbed(nn.Layer): """ Image to Patch Embedding Args: img_size (int): Image size. Default: 224. patch_size (int): Patch token size. Default: 4. in_chans (int): Number of input image channels. Default: 3. embed_dim (int): Number of linear projection output channels. Default: 96. norm_layer (nn.Layer, optional): Normalization layer. Default: None """ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None): super().__init__() img_size = to_2tuple(img_size) patch_size = to_2tuple(patch_size) patches_resolution = [ img_size[0] // patch_size[0], img_size[1] // patch_size[1] ] self.img_size = img_size self.patch_size = patch_size self.patches_resolution = patches_resolution self.num_patches = patches_resolution[0] * patches_resolution[1] #patch个数 self.in_chans = in_chans self.embed_dim = embed_dim self.proj = nn.Conv2D( in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) #将stride和kernel_size设置为patch_size大小 if norm_layer is not None: self.norm = norm_layer(embed_dim) else: self.norm = None def forward(self, x): B, C, H, W = x.shape x = self.proj(x) # B, 96, H/4, W4 x = x.flatten(2).transpose([0, 2, 1]) # B Ph*Pw 96 if self.norm is not None: x = self.norm(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
Patch Merging
以下为PatchMerging的操作。该操作以2为步长,对输入的图片进行采样,总共得到4张下采样的特征图,H和W降低2倍,因此,通道级拼接后得到的是B,4C,H/2,W/2的特征图。然而这样的拼接不能够提取有用的特征信息,于是,一个线性层将4C的通道筛选为2C, 特征图变为了B,2C, H/2, W/2。细细体会可以发现,该操作像极了
卷积常用的Pooling操作和步长为2的卷积操作。Poling用于下采样,步长为2的卷积同样可以下采样,另外还起到了特征筛选的效果。总结一下,经过这个操作原本B,C,H,W的特征图就变为了B,2C,H/2,W/2的特征图,完成了下采样操作。
class PatchMerging(nn.Layer): r""" Patch Merging Layer. Args: input_resolution (tuple[int]): Resolution of input feature. dim (int): Number of input channels. norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm """ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm): super().__init__() self.input_resolution = input_resolution self.dim = dim self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False) self.norm = norm_layer(4 * dim) def forward(self, x): """ x: B, H*W, C """ H, W = self.input_resolution B, L, C = x.shape assert L == H * W, "input feature has wrong size" assert H % 2 == 0 and W % 2 == 0, "x size ({}*{}) are not even.".format( H, W) x = x.reshape([B, H, W, C]) # 每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。 x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C # 拼接在一起作为一整个张量,展开。通道维度会变成原先的4倍(因为H,W各缩小2倍) x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C x = x.reshape([B, H * W // 4, 4 * C]) # B H/2*W/2 4*C x = self.norm(x) # 通过一个全连接层再调整通道维度为原来的两倍 x = self.reduction(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Swin Transformer Block:
下面的操作是根据window_size划分特征图的操作和还原的操作,原理很简单就是并排划分即可。
def window_partition(x, window_size): """ Args: x: (B, H, W, C) window_size (int): window size Returns: windows: (num_windows*B, window_size, window_size, C) """ B, H, W, C = x.shape x = x.reshape([B, H // window_size, window_size, W // window_size, window_size, C]) windows = x.transpose([0, 1, 3, 2, 4, 5]).reshape([-1, window_size, window_size, C]) return windows def window_reverse(windows, window_size, H, W): """ Args: windows: (num_windows*B, window_size, window_size, C) window_size (int): Window size H (int): Height of image W (int): Width of image Returns: x: (B, H, W, C) """ B = int(windows.shape[0] / (H * W / window_size / window_size)) x = windows.reshape([B, H // window_size, W // window_size, window_size, window_size, -1]) x = x.transpose([0, 1, 3, 2, 4, 5]).reshape([B, H, W, -1]) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Swin Transformer中重要的当然是Swin Transformer Block了,下面解释一下Swin Transformer Block的原理。
先看一下MLP和LN,MLP和LN为多层感知机和相对于BatchNorm的LayerNorm。原理较为简单,因此直接看paddle代码即可。
class Mlp(nn.Layer): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
下图就是Shifted Window based MSA是Swin Transformer的核心部分。Shifted Window based MSA包括了两部分,一个是W-MSA(窗口多头注意力),另一个就是SW-MSA(移位窗口多头自注意力)。这两个是一同出现的。
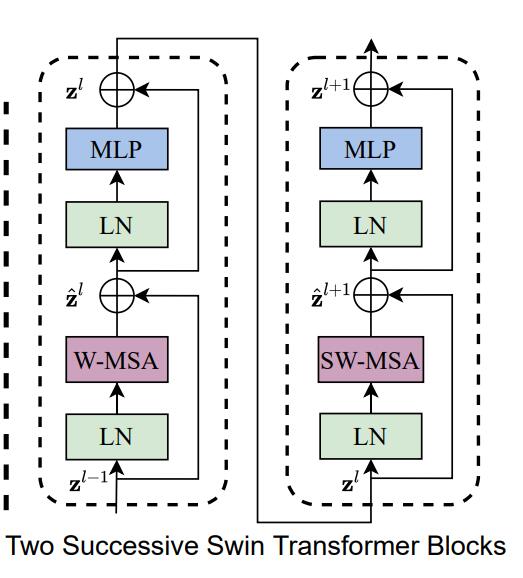
一开始,Swin Transformer 将一张图片分割为4份,也叫4个Window,然后独立地计算每一部分的MSA。由于每一个Window都是独立的,缺少了信息之间的交流,因此作者又提出了SW-MSA的算法,即采用规则的移动窗口的方法。通过不同窗口的交互,来达到特征的信息交流。注意,这一部分是本论文的精华,想要了解的同学必须要看懂源代码
class WindowAttention(nn.Layer): """ Window based multi-head self attention (W-MSA) module with relative position bias. It supports both of shifted and non-shifted window. Args: dim (int): Number of input channels. window_size (tuple[int]): The height and width of the window. num_heads (int): Number of attention heads. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0 proj_drop (float, optional): Dropout ratio of output. Default: 0.0 """ def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.dim = dim self.window_size = window_size # Wh, Ww self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 # define a parameter table of relative position bias relative_position_bias_table = self.create_parameter( shape=((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads), default_initializer=nn.initializer.Constant(value=0)) # 2*Wh-1 * 2*Ww-1, nH self.add_parameter("relative_position_bias_table", relative_position_bias_table) # get pair-wise relative position index for each token inside the window coords_h = paddle.arange(self.window_size[0]) coords_w = paddle.arange(self.window_size[1]) coords = paddle.stack(paddle.meshgrid([coords_h, coords_w])) # 2, Wh, Ww coords_flatten = paddle.flatten(coords, 1) # 2, Wh*Ww relative_coords = coords_flatten.unsqueeze(-1) - coords_flatten.unsqueeze(1) # 2, Wh*Ww, Wh*Ww relative_coords = relative_coords.transpose([1, 2, 0]) # Wh*Ww, Wh*Ww, 2 relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0 relative_coords[:, :, 1] += self.window_size[1] - 1 relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1 self.relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww self.register_buffer("relative_position_index", self.relative_position_index) self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) self.softmax = nn.Softmax(axis=-1) def forward(self, x, mask=None): """ Args: x: input features with shape of (num_windows*B, N, C) mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None """ B_, N, C = x.shape qkv = self.qkv(x).reshape([B_, N, 3, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4]) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) q = q * self.scale attn = q @ swapdim(k ,-2, -1) relative_position_bias = paddle.index_select(self.relative_position_bias_table, self.relative_position_index.reshape((-1,)),axis=0).reshape((self.window_size[0] * self.window_size[1],self.window_size[0] * self.window_size[1], -1)) relative_position_bias = relative_position_bias.transpose([2, 0, 1]) # nH, Wh*Ww, Wh*Ww attn = attn + relative_position_bias.unsqueeze(0) if mask is not None: nW = mask.shape[0] attn = attn.reshape([B_ // nW, nW, self.num_heads, N, N]) + mask.unsqueeze(1).unsqueeze(0) attn = attn.reshape([-1, self.num_heads, N, N]) attn = self.softmax(attn) else: attn = self.softmax(attn) attn = self.attn_drop(attn) x = swapdim((attn @ v),1, 2).reshape([B_, N, C]) x = self.proj(x) x = self.proj_drop(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81

4.2 Swin Trasnformer模型实现
Swin Transformer涉及模型代码较多,所以建议完整的看Swin Transformer的代码,因此推荐一下桨的Swin Transformer实现。
4.3 Swin Trasnformer模型特点
-
首次在cv领域的transformer模型中采用了分层结构。分层结构因为其不同大小的尺度,使不同层特征有了更加不同的意义,较浅层的特征具有大尺度和细节信息,较深层的特征具有小尺度和物体的整体轮廓信息,在图像分类领域,深层特征具有更加有用的作用,只需要根据这个信息判定物体的类别即可,但是在像素级的分割和检测任务中,则需要更为精细的细节信息,因此,分层结构的模型往往更适用于分割和检测这样的像素级要求的任务中。Swin Transformer 模仿ResNet采取了分层的结构,使其成为了cv领域的通用框架。
-
引入locality思想,对无重合的window区域内进行self-attention计算。不仅减少了计算量,而且多了不同窗口之间的交互。
4.4 Swin Trasnformer模型效果
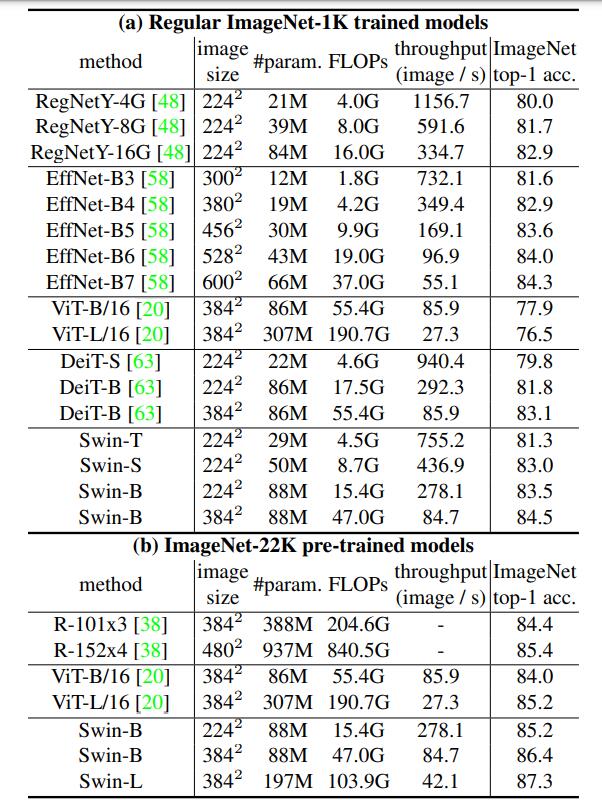
第一列为对比的方法,第二列为图片尺寸的大小(尺寸越大浮点运算量越大),第三列为参数量,第四列为浮点运算量,第五列为模型吞吐量。可以看出,Swin-T 在top1准确率上超过了大部分模型EffNet-B3确实是个优秀的网络,在参数量和FLOPs都比Swin-T少的情况下,略优于Swin-T,然而,基于ImageNet1K数据集,Swin-B在这些模型上取得了最优的效果。另外,Swin-L在ImageNet-22K上的top1准确率达到了87.3%的高度,这是以往的模型都没有达到的。并且Swin Transformer的其他配置也取得了优秀的成绩。图中不同配置的Swin Transformer解释如下。

C就是上面提到的类似于通道数的值,layer numbers就是Swin Transformer Block的数量了。这两个都是值越大,效果越好。和ResNet十分相似。
下图为COCO数据集上目标检测与实例分割的表现。都是相同网络在不同骨干网络下的对比。可以看出在不同AP下,Swin Transformer都有大约5%的提升,这已经是很优秀的水平了。怪不得能成为ICCV2021最佳paer。
下图为语义分割数据集ADE20K上的表现。相较于同为transformer的DeiT-S, Swin Transformer-S有了5%的性能提升。相较于ResNeSt-200,Swin Transformer-L也有5%的提升。另外可以看到,在UNet的框架下,Swin Transformer的各个版本都有十分优秀的成绩,这充分说明了Swin Transformer是CV领域的通用骨干网络。

- 参考文献
Swin Transformer
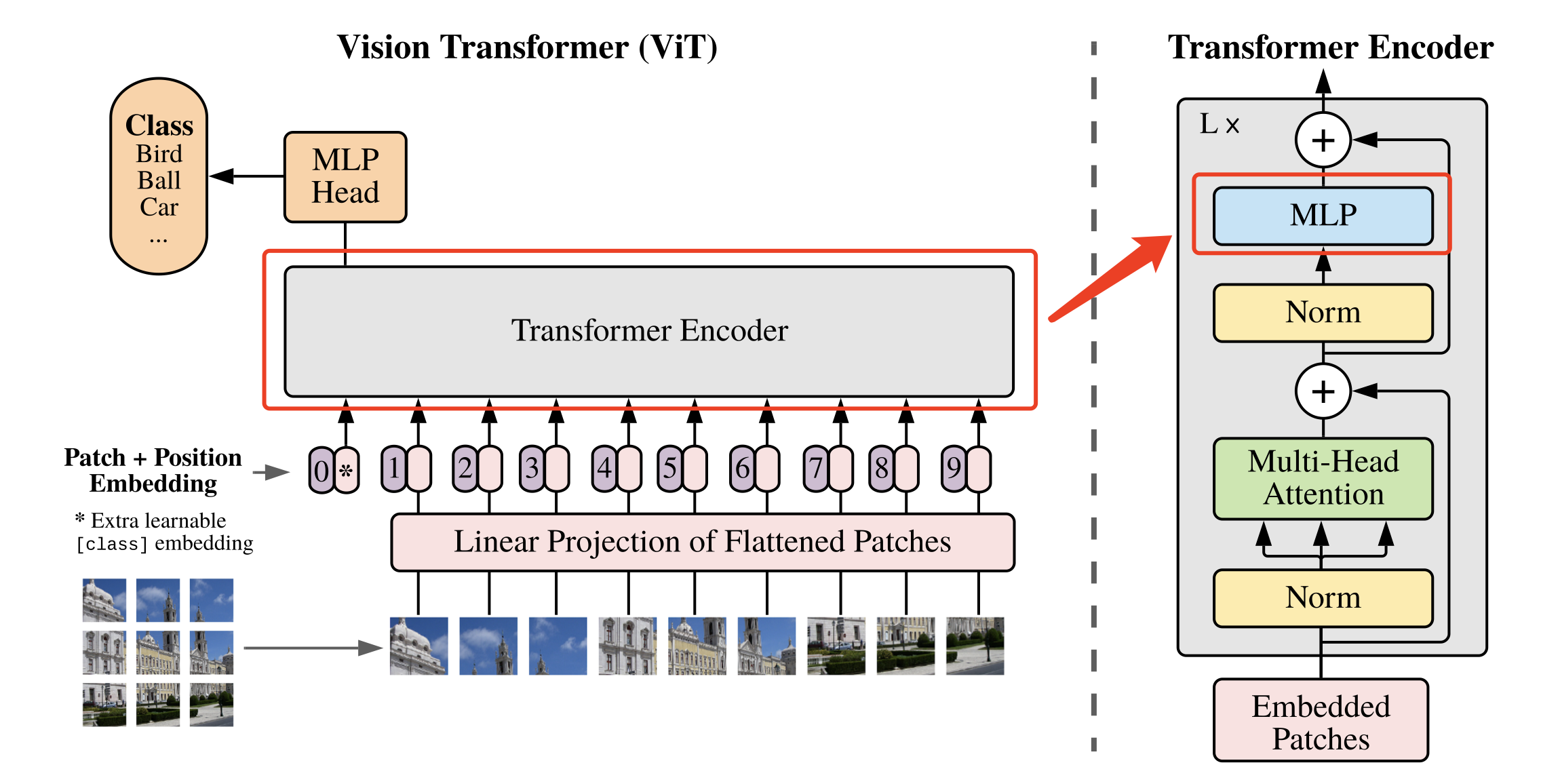
5.ViT( Vision Transformer-2020)
在计算机视觉领域中,多数算法都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。有研究者提出,没有必要总是依赖于CNN。因此,作者提出ViT[1]算法,仅仅使用Transformer结构也能够在图像分类任务中表现很好。
受到NLP领域中Transformer成功应用的启发,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
该算法在中等规模(例如ImageNet)以及大规模(例如ImageNet-21K、JFT-300M)数据集上进行了实验验证,发现:
- Transformer相较于CNN结构,缺少一定的平移不变性和局部感知性,因此在数据量不充分时,很难达到同等的效果。具体表现为使用中等规模的ImageNet训练的Transformer会比ResNet在精度上低几个百分点。
- 当有大量的训练样本时,结果则会发生改变。使用大规模数据集进行预训练后,再使用迁移学习的方式应用到其他数据集上,可以达到或超越当前的SOTA水平。
5.1 ViT模型结构与实现
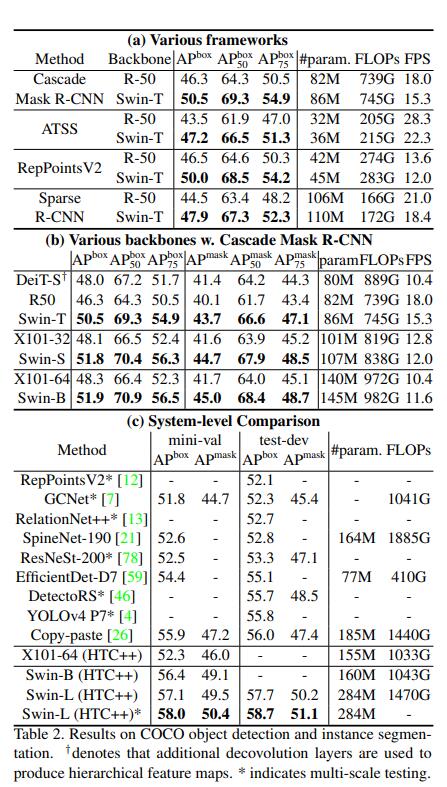
ViT算法的整体结构如 图1 所示。
5.1.1. ViT图像分块嵌入
考虑到在Transformer结构中,输入是一个二维的矩阵,矩阵的形状可以表示为 ( N , D ) (N,D) (N,D),其中 N N N 是sequence的长度,而 D D D 是sequence中每个向量的维度。因此,在ViT算法中,首先需要设法将 H × W × C H \times W \times C H×W×C 的三维图像转化为 ( N , D ) (N,D) (N,D) 的二维输入。
ViT中的具体实现方式为:将 H × W × C H \times W \times C H×W×C 的图像,变为一个 N × ( P 2 ∗ C ) N \times (P^2 * C) N×(P2∗C) 的序列。这个序列可以看作是一系列展平的图像块,也就是将图像切分成小块后,再将其展平。该序列中一共包含了 N = H W / P 2 N=HW/P^2 N=HW/P2 个图像块,每个图像块的维度则是 ( P 2 ∗ C ) (P^2*C) (P2∗C)。其中 P P P 是图像块的大小, C C C 是通道数量。经过如上变换,就可以将 N N N 视为sequence的长度了。
但是,此时每个图像块的维度是 ( P 2 ∗ C ) (P^2*C) (P2∗C),而我们实际需要的向量维度是 D D D,因此我们还需要对图像块进行 Embedding。这里 Embedding 的方式非常简单,只需要对每个 ( P 2 ∗ C ) (P^2*C) (P2∗C) 的图像块做一个线性变换,将维度压缩为 D D D 即可。
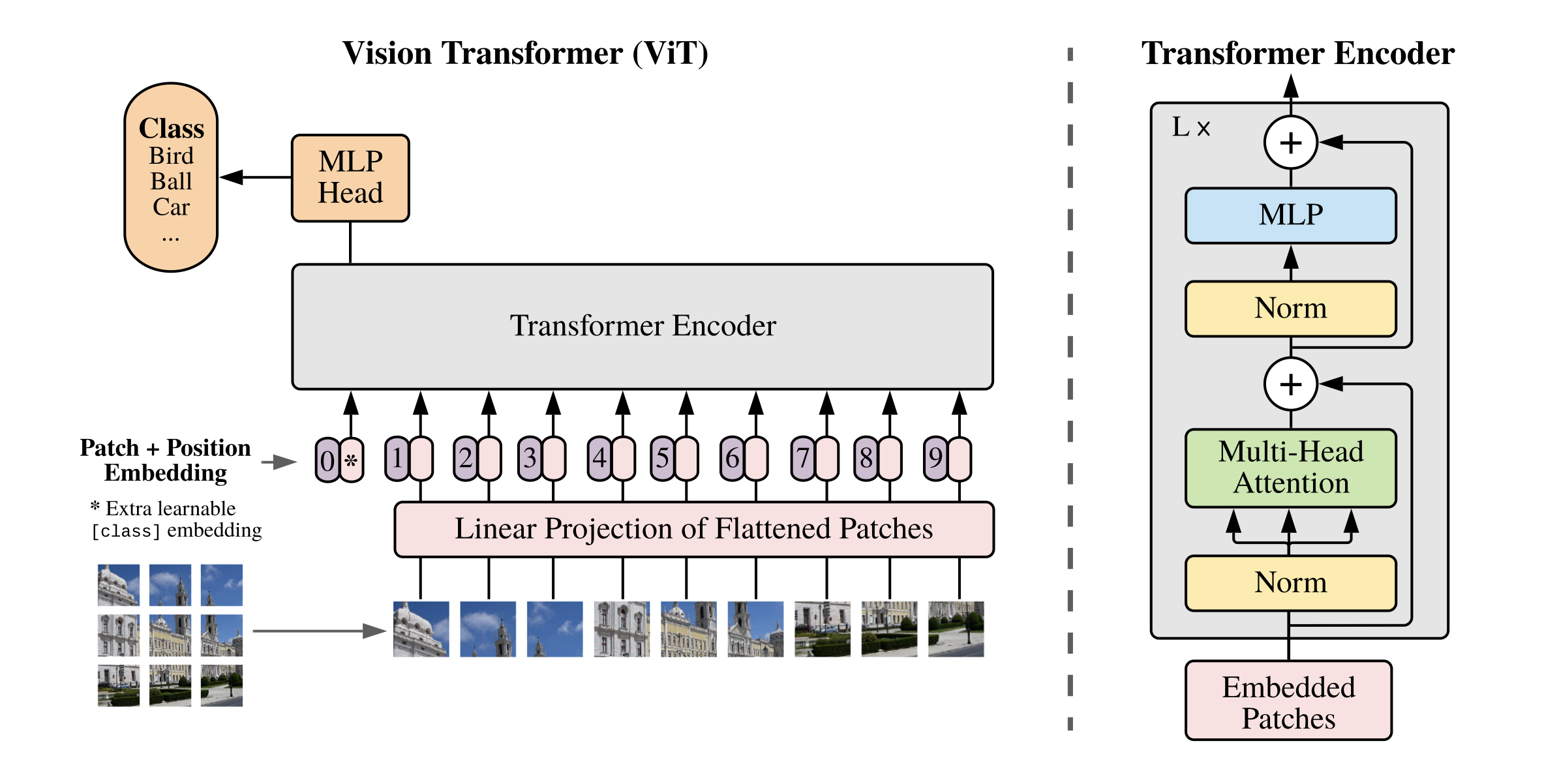
上述对图像进行分块以及 Embedding 的具体方式如 图2 所示。
具体代码实现如下所示。本文中将每个大小为 P P P 的图像块经过大小为 P P P 的卷积核来代替原文中将大小为 P P P 的图像块展平后接全连接运算的操作。
#图像分块、Embedding class PatchEmbed(nn.Layer): def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768): super().__init__() # 原始大小为int,转为tuple,即:img_size原始输入224,变换后为[224,224] img_size = to_2tuple(img_size) patch_size = to_2tuple(patch_size) # 图像块的个数 num_patches = (img_size[1] // patch_size[1]) * \ (img_size[0] // patch_size[0]) self.img_size = img_size self.patch_size = patch_size self.num_patches = num_patches # kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理 # 输入维度为3,输出维度为块向量长度 # 与原文中:分块、展平、全连接降维保持一致 # 输出为[B, C, H, W] self.proj = nn.Conv2D( in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x): B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ "Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." # [B, C, H, W] -> [B, C, H*W] ->[B, H*W, C] x = self.proj(x).flatten(2).transpose((0, 2, 1)) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
5.1.2. ViT多头注意力
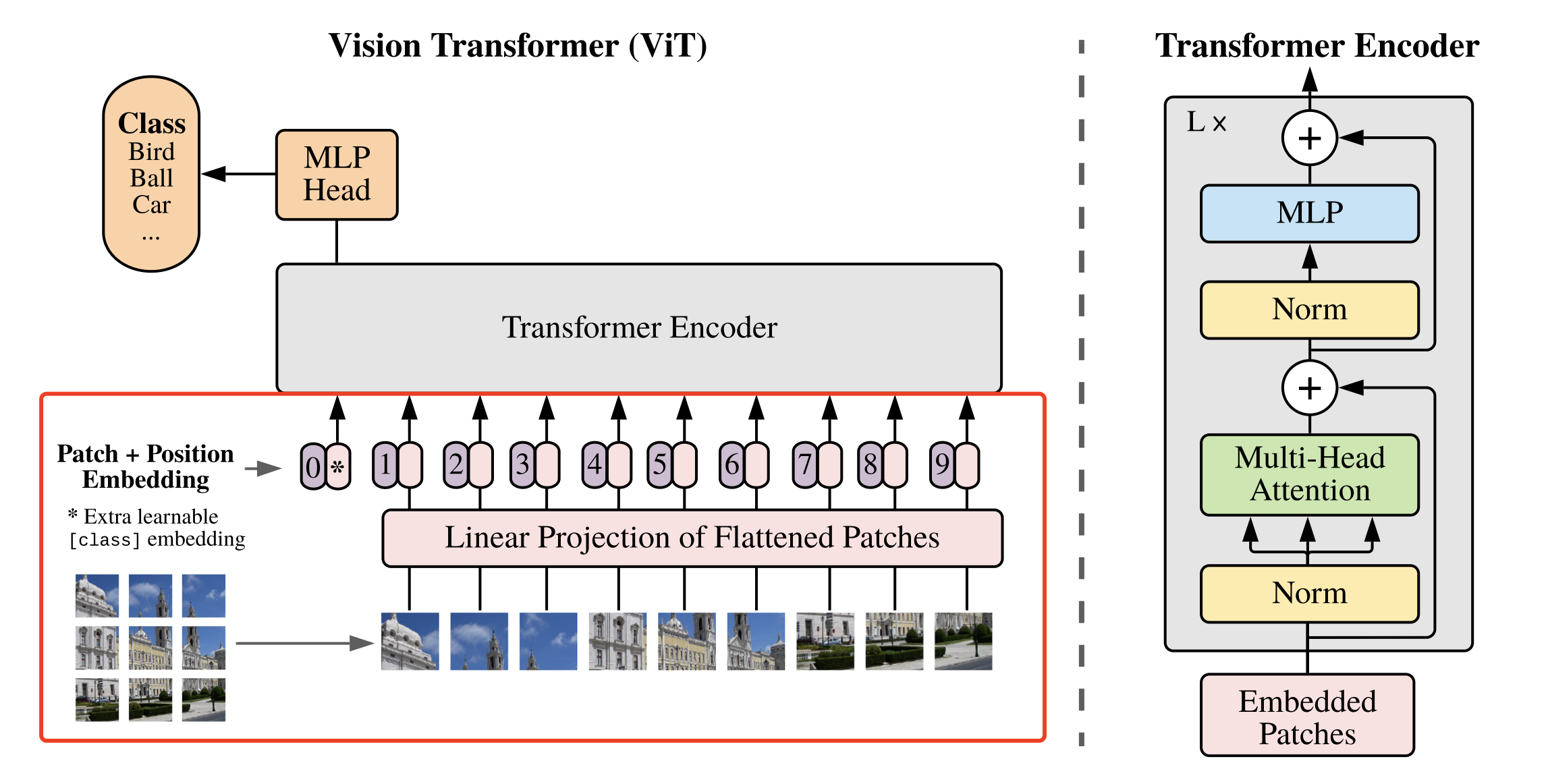
将图像转化为 N × ( P 2 ∗ C ) N \times (P^2 * C) N×(P2∗C) 的序列后,就可以将其输入到 Transformer 结构中进行特征提取了,如 图3 所示。
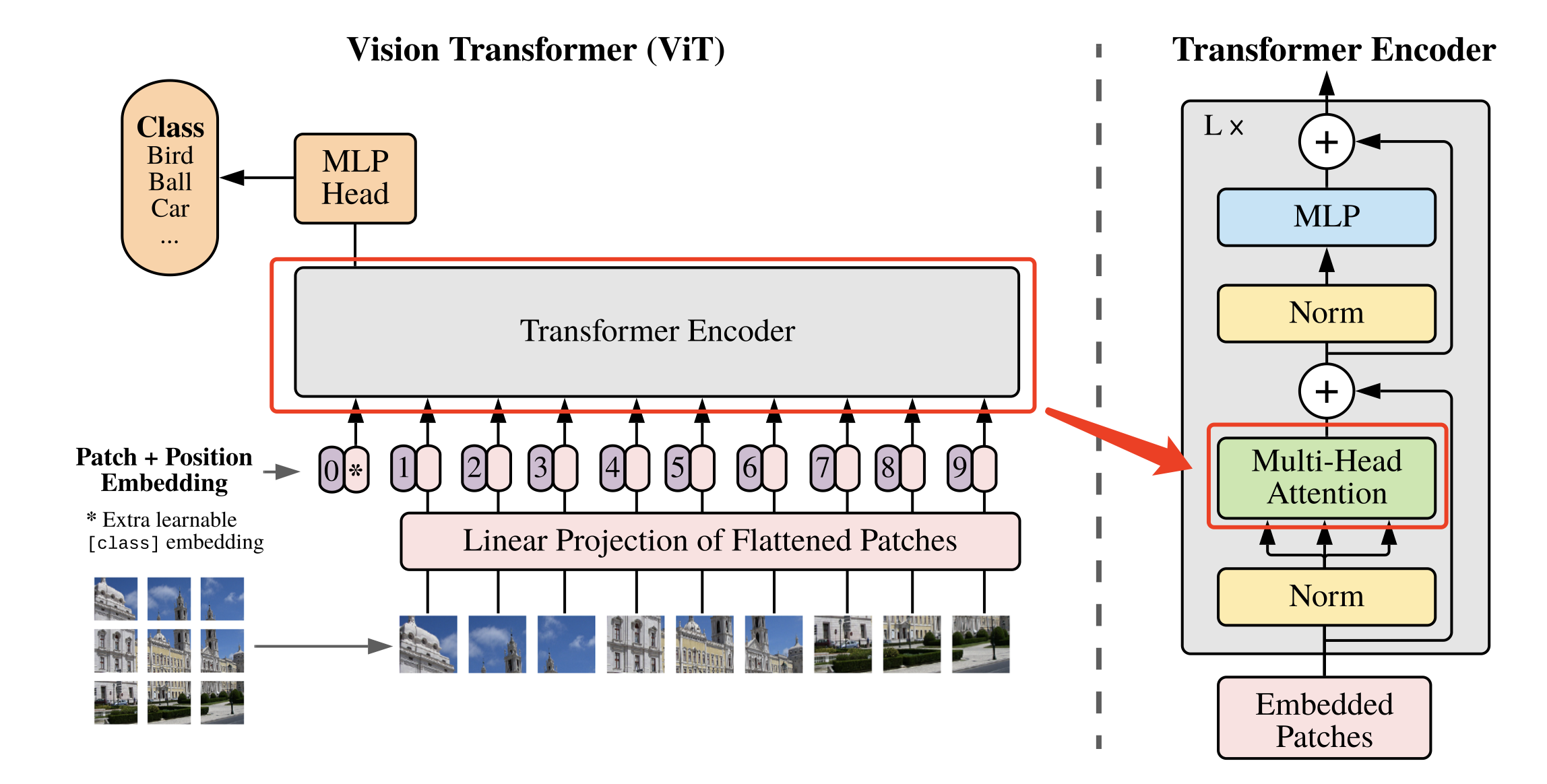
Transformer 结构中最重要的结构就是 Multi-head Attention,即多头注意力结构。具有2个head的 Multi-head Attention 结构如 图4 所示。输入 a i a^i ai 经过转移矩阵,并切分生成 q ( i , 1 ) q^{(i,1)} q(i,1)、 q ( i , 2 ) q^{(i,2)} q(i,2)、 k ( i , 1 ) k^{(i,1)} k(i,1)、 k ( i , 2 ) k^{(i,2)} k(i,2)、 v ( i , 1 ) v^{(i,1)} v(i,1)、 v ( i , 2 ) v^{(i,2)} v(i,2),然后 q ( i , 1 ) q^{(i,1)} q(i,1) 与 k ( i , 1 ) k^{(i,1)} k(i,1) 做 attention,得到权重向量 α \alpha α,将 α \alpha α 与 v ( i , 1 ) v^{(i,1)} v(i,1) 进行加权求和,得到最终的 b ( i , 1 ) ( i = 1 , 2 , … , N ) b^{(i,1)}(i=1,2,…,N) b(i,1)(i=1,2,…,N),同理可以得到 b ( i , 2 ) ( i = 1 , 2 , … , N ) b^{(i,2)}(i=1,2,…,N) b(i,2)(i=1,2,…,N)。接着将它们拼接起来,通过一个线性层进行处理,得到最终的结果。
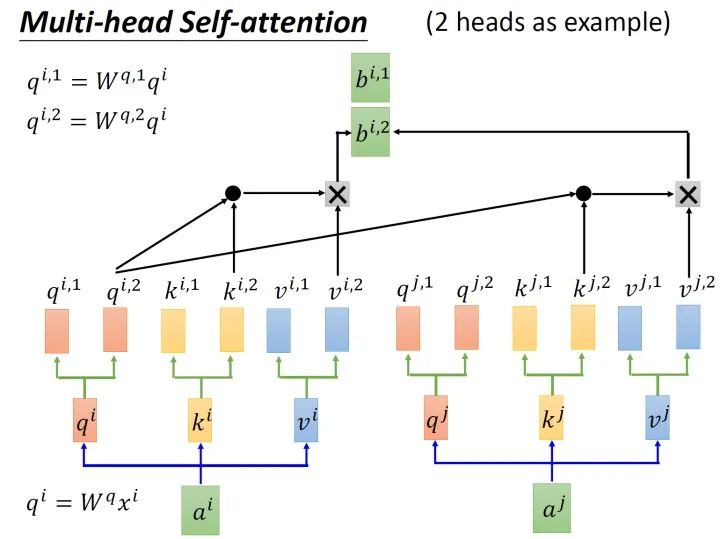
其中,使用 q ( i , j ) q^{(i,j)} q(i,j)、 k ( i , j ) k^{(i,j)} k(i,j) 与 v ( i , j ) v^{(i,j)} v(i,j) 计算 b ( i , j ) ( i = 1 , 2 , … , N ) b^{(i,j)}(i=1,2,…,N) b(i,j)(i=1,2,…,N) 的方法是缩放点积注意力 (Scaled Dot-Product Attention)。 结构如 图5 所示。首先使用每个 q ( i , j ) q^{(i,j)} q(i,j) 去与 k ( i , j ) k^{(i,j)} k(i,j) 做 attention,这里说的 attention 就是匹配这两个向量有多接近,具体的方式就是计算向量的加权内积,得到 α ( i , j ) \alpha_{(i,j)} α(i,j)。这里的加权内积计算方式如下所示:
α ( 1 , i ) = q 1 ∗ k i / d \alpha_{(1,i)} = q^1 * k^i / \sqrt{d} α(1,i)=q1∗ki/d
其中, d d d 是 q q q 和 k k k 的维度,因为 q ∗ k q*k q∗k 的数值会随着维度的增大而增大,因此除以 d \sqrt{d} d 的值也就相当于归一化的效果。
接下来,把计算得到的 α ( i , j ) \alpha_{(i,j)} α(i,j) 取 softmax 操作,再将其与 v ( i , j ) v^{(i,j)} v(i,j) 相乘。
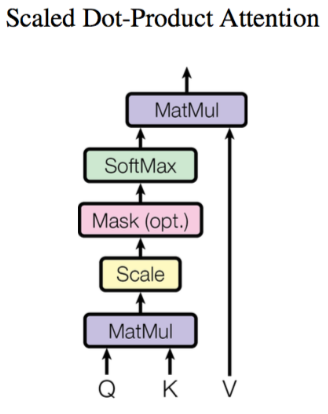
具体代码实现如下所示。
#Multi-head Attention class Attention(nn.Layer): def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim**-0.5 # 计算 q,k,v 的转移矩阵 self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) # 最终的线性层 self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) def forward(self, x): N, C = x.shape[1:] # 线性变换 qkv = self.qkv(x).reshape((-1, N, 3, self.num_heads, C // self.num_heads)).transpose((2, 0, 3, 1, 4)) # 分割 query key value q, k, v = qkv[0], qkv[1], qkv[2] # Scaled Dot-Product Attention # Matmul + Scale attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale # SoftMax attn = nn.functional.softmax(attn, axis=-1) attn = self.attn_drop(attn) # Matmul x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((-1, N, C)) # 线性变换 x = self.proj(x) x = self.proj_drop(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
5.1.3. 多层感知机(MLP)
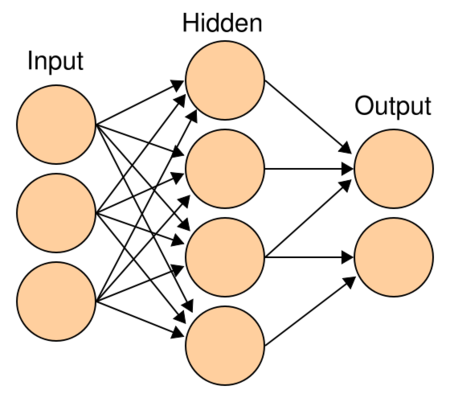
Transformer 结构中还有一个重要的结构就是 MLP,即多层感知机,如 图6 所示。
多层感知机由输入层、输出层和至少一层的隐藏层构成。网络中各个隐藏层中神经元可接收相邻前序隐藏层中所有神经元传递而来的信息,经过加工处理后将信息输出给相邻后续隐藏层中所有神经元。在多层感知机中,相邻层所包含的神经元之间通常使用“全连接”方式进行连接。多层感知机可以模拟复杂非线性函数功能,所模拟函数的复杂性取决于网络隐藏层数目和各层中神经元数目。多层感知机的结构如 图7 所示。
具体代码实现如下所示。
class Mlp(nn.Layer): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): # 输入层:线性变换 x = self.fc1(x) # 应用激活函数 x = self.act(x) # Dropout x = self.drop(x) # 输出层:线性变换 x = self.fc2(x) # Dropout x = self.drop(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
5.1.4. DropPath
除了以上重要模块意外,代码实现过程中还使用了DropPath(Stochastic Depth)来代替传统的Dropout结构,DropPath可以理解为一种特殊的 Dropout。其作用是在训练过程中随机丢弃子图层(randomly drop a subset of layers),而在预测时正常使用完整的 Graph。
具体实现如下:
def drop_path(x, drop_prob=0., training=False): if drop_prob == 0. or not training: return x keep_prob = paddle.to_tensor(1 - drop_prob) shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1) random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype) random_tensor = paddle.floor(random_tensor) output = x.divide(keep_prob) * random_tensor return output class DropPath(nn.Layer): def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
5.1.5 基础模块
基于上面实现的 Attention、MLP、DropPath模块就可以组合出 Vision Transformer 模型的一个基础模块,如 图8 所示。
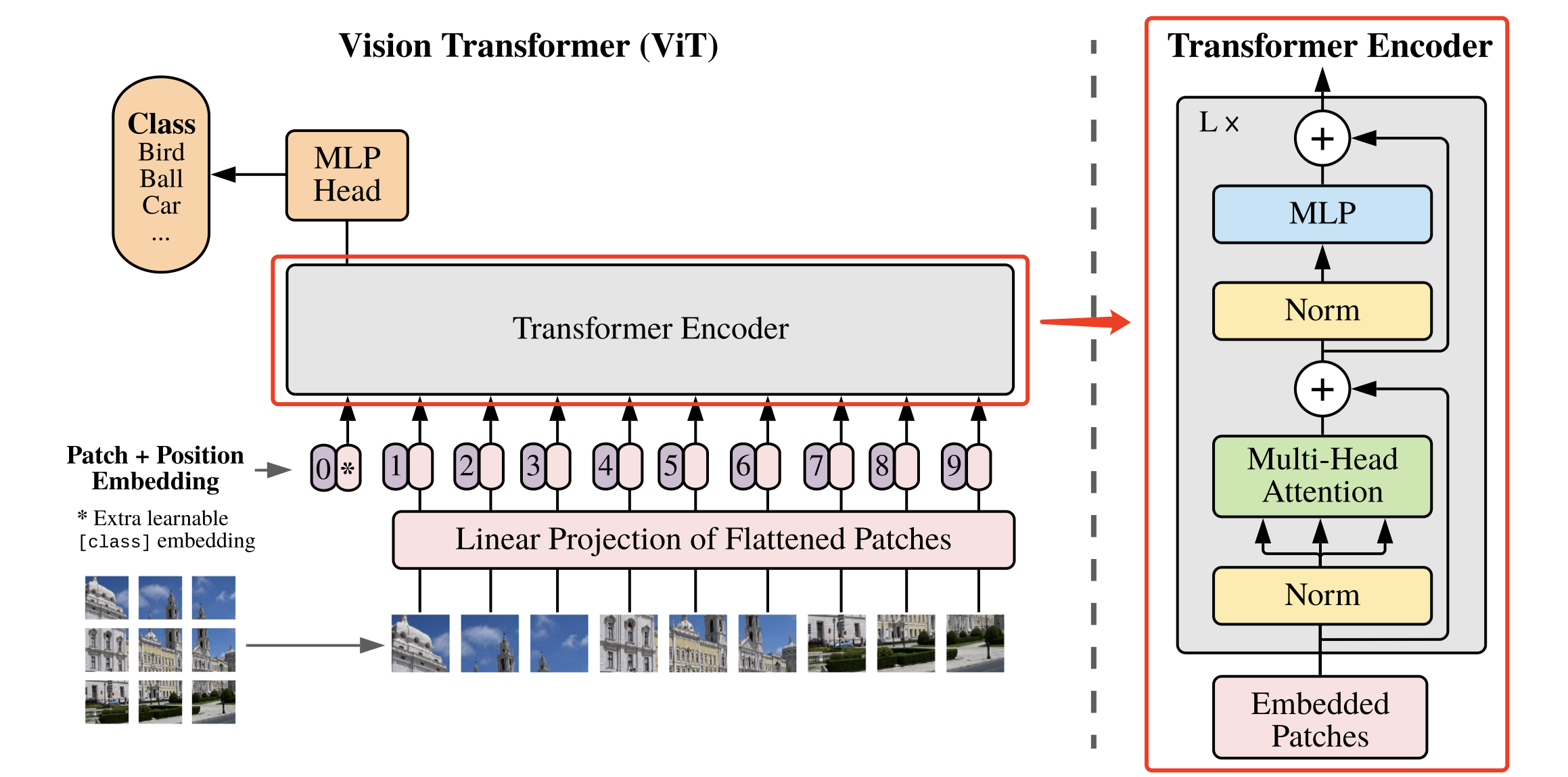
基础模块的具体实现如下:
class Block(nn.Layer): def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer='nn.LayerNorm', epsilon=1e-5): super().__init__() self.norm1 = eval(norm_layer)(dim, epsilon=epsilon) # Multi-head Self-attention self.attn = Attention( dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop) # DropPath self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity() self.norm2 = eval(norm_layer)(dim, epsilon=epsilon) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def forward(self, x): # Multi-head Self-attention, Add, LayerNorm x = x + self.drop_path(self.attn(self.norm1(x))) # Feed Forward, Add, LayerNorm x = x + self.drop_path(self.mlp(self.norm2(x))) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
5.1.6. 定义ViT网络
基础模块构建好后,就可以构建完整的ViT网络了。在构建完整网络结构之前,还需要给大家介绍几个模块:
- Class Token
假设我们将原始图像切分成 3 × 3 3 \times 3 3×3 共9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。那么这个 Class Token 有什么作用呢?
我们可以想象,如果没有这个向量,也就是将 N = 9 N=9 N=9 个向量输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?因此,ViT算法提出了一个可学习的嵌入向量 Class Token,将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
其实这里也可以理解为:ViT 其实只用到了 Transformer 中的 Encoder,而并没有用到 Decoder,而 Class Token 的作用就是寻找其他9个输入向量对应的类别。
- Positional Encoding
按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 s i n c o s sincos sincos 编码,而是直接设置为可学习的 Positional Encoding。对训练好的 Positional Encoding 进行可视化,如 图9 所示。我们可以看到,位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行/列中的 patch 具有相似的位置编码。
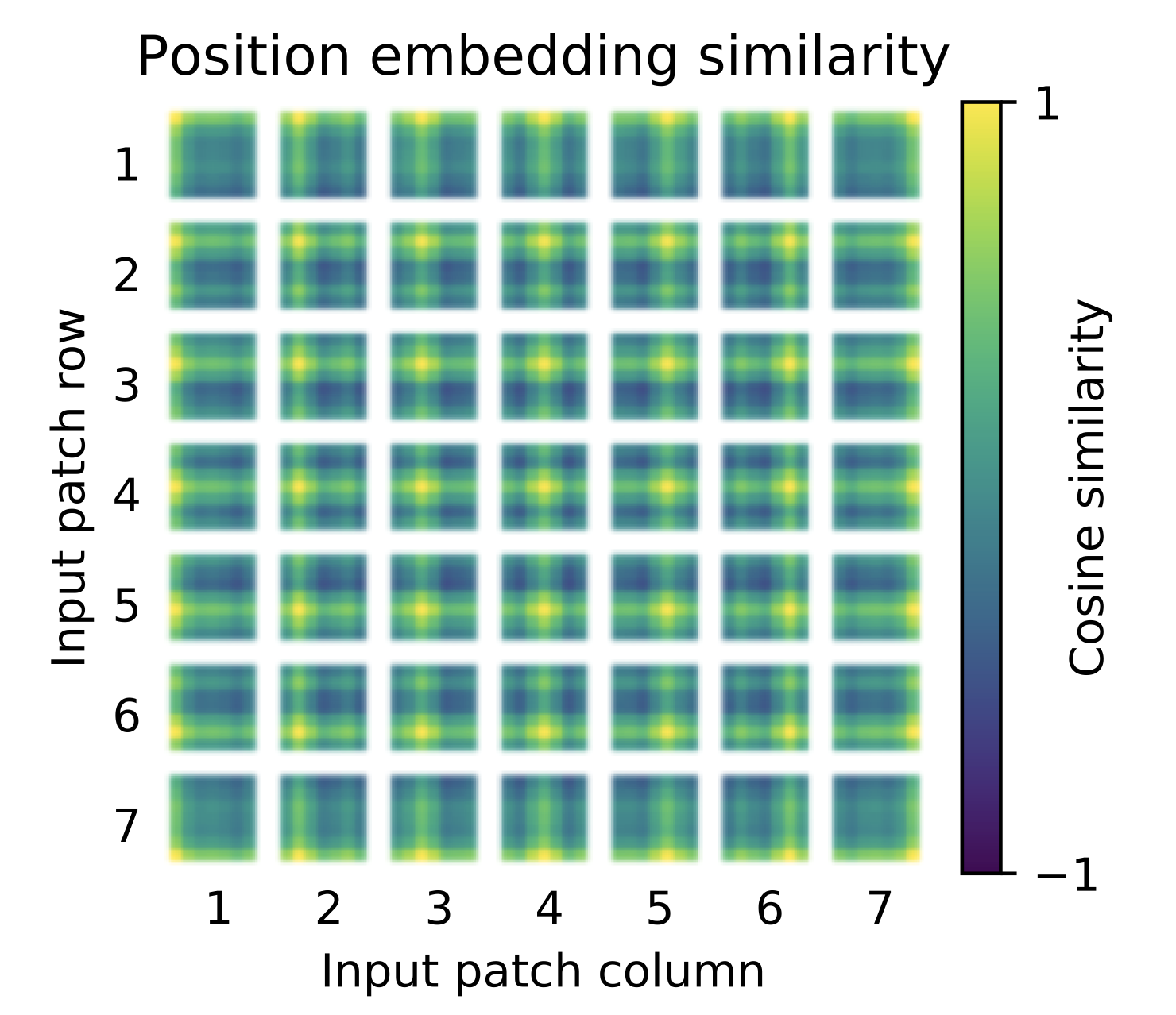
- MLP Head
得到输出后,ViT中使用了 MLP Head对输出进行分类处理,这里的 MLP Head 由 LayerNorm 和两层全连接层组成,并且采用了 GELU 激活函数。
具体代码如下所示。
首先构建基础模块部分,包括:参数初始化配置、独立的不进行任何操作的网络层。
#参数初始化配置 trunc_normal_ = nn.initializer.TruncatedNormal(std=.02) zeros_ = nn.initializer.Constant(value=0.) ones_ = nn.initializer.Constant(value=1.) #将输入 x 由 int 类型转为 tuple 类型 def to_2tuple(x): return tuple([x] * 2) #定义一个什么操作都不进行的网络层 class Identity(nn.Layer): def __init__(self): super(Identity, self).__init__() def forward(self, input): return input
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
完整代码如下所示。
class VisionTransformer(nn.Layer): def __init__(self, img_size=224, patch_size=16, in_chans=3, class_dim=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer='nn.LayerNorm', epsilon=1e-5, **args): super().__init__() self.class_dim = class_dim self.num_features = self.embed_dim = embed_dim # 图片分块和降维,块大小为patch_size,最终块向量维度为768 self.patch_embed = PatchEmbed( img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) # 分块数量 num_patches = self.patch_embed.num_patches # 可学习的位置编码 self.pos_embed = self.create_parameter( shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_) self.add_parameter("pos_embed", self.pos_embed) # 人为追加class token,并使用该向量进行分类预测 self.cls_token = self.create_parameter( shape=(1, 1, embed_dim), default_initializer=zeros_) self.add_parameter("cls_token", self.cls_token) self.pos_drop = nn.Dropout(p=drop_rate) dpr = np.linspace(0, drop_path_rate, depth) # transformer self.blocks = nn.LayerList([ Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, epsilon=epsilon) for i in range(depth) ]) self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon) # Classifier head self.head = nn.Linear(embed_dim, class_dim) if class_dim > 0 else Identity() trunc_normal_(self.pos_embed) trunc_normal_(self.cls_token) self.apply(self._init_weights) # 参数初始化 def _init_weights(self, m): if isinstance(m, nn.Linear): trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None: zeros_(m.bias) elif isinstance(m, nn.LayerNorm): zeros_(m.bias) ones_(m.weight) def forward_features(self, x): B = paddle.shape(x)[0] # 将图片分块,并调整每个块向量的维度 x = self.patch_embed(x) # 将class token与前面的分块进行拼接 cls_tokens = self.cls_token.expand((B, -1, -1)) x = paddle.concat((cls_tokens, x), axis=1) # 将编码向量中加入位置编码 x = x + self.pos_embed x = self.pos_drop(x) # 堆叠 transformer 结构 for blk in self.blocks: x = blk(x) # LayerNorm x = self.norm(x) # 提取分类 tokens 的输出 return x[:, 0] def forward(self, x): # 获取图像特征 x = self.forward_features(x) # 图像分类 x = self.head(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
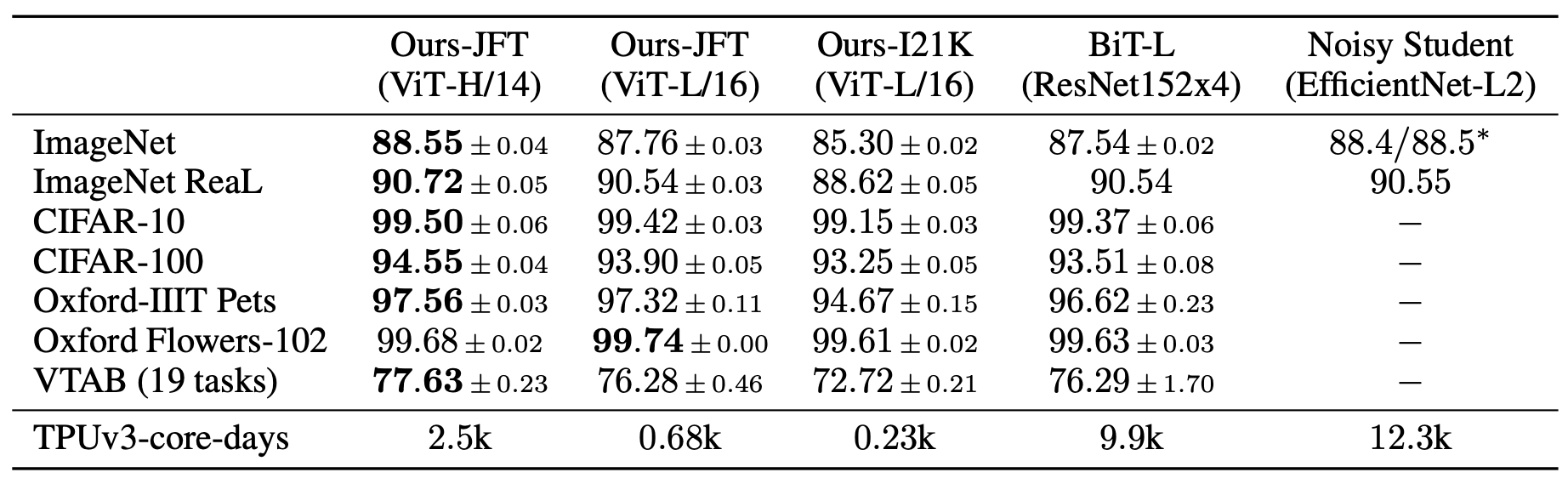
5.2 ViT模型指标
ViT模型在常用数据集上进行迁移学习,最终指标如 图10 所示。可以看到,在ImageNet上,ViT达到的最高指标为88.55%;在ImageNet ReaL上,ViT达到的最高指标为90.72%;在CIFAR100上,ViT达到的最高指标为94.55%;在VTAB(19 tasks)上,ViT达到的最高指标为88.55%。
5.3 ViT模型特点
- 作为CV领域最经典的 Transformer 算法之一,不同于传统的CNN算法,ViT尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。
- 为了满足 Transformer 输入结构的要求,将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列输入到网络。同时,使用了Class Token的方式进行分类预测。
- 参考文献
[1] An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale

