
- 1mysql 填充零无效_MySQL数据库之windows下navicate for mysql 零填充不显示
- 2程序员之死,没一个产品是无辜的!
- 3【MySQL】查询的数据,字符串前后补0_mysql补齐0
- 4spring@RequestMapping_spring requestmapping
- 5网络基础学习(第七章):VRRP协议介绍及配置
- 6激光雷达点云数据处理_pointpillars ransac
- 7sed命令使用_sed -i -r
- 8单片机学习笔记---AD/DA工作原理(含运算放大器的工作原理)_简述da和ad转换的原理
- 9bert实践:关系抽取解读_bert关系抽取
- 10生成式深度学习(第二版)-译文-第一章-生成式建模_生成式深度学习第二版
ElasticSearch数据库导出数据——(以6.8.2为例)_kibana导出es数据
赞
踩
使用elasticdump导出数据
需求描述
我现在是有两套ES环境,一套在内网(有数据),一套在外网(没数据)。
由于开发测试需要,要将内网的数据导出到外边来进行测试。
导出数据
一、预先准备
1.安装node和npm
# 使用公网服务器下载安装包并上传至离线服务器
wget https://nodejs.org/dist/v10.13.0/node-v10.13.0-linux-x64.tar.xz
# 在公网服务器和离线服务器将安装包移动到/root/下并解压
xz -d node-v10.13.0-linux-x64.tar.xz
tar xvf node-v10.13.0-linux-x64.tar
# 两台机器建立文件软连接到系统命令
ln -s /root/node-v10.13.0-linux-x64/bin/node /usr/bin/node
ln -s /root/node-v10.13.0-linux-x64/bin/npm /usr/bin/npm
# 检查是否安装成功
node -v
npm -v
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.安装elasticdump
外网机器在线安装
# 安装
npm install elasticdump -g
# 建立文件软连接到系统命令
ln -s /root/node-v10.13.0-linux-x64/lib/node_modules/elasticdump/bin/elasticdump /usr/bin/elasticdump
# 验证
elasticdump --help
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
内网机器离线安装
外网准备
验证成功之后,由于内网不能在线安装,需要将外网安装的elasticdump导入内网中,在内网离线安装。
# 查看缓存目录位置
npm config get cache
/root/.npm
cd /root/
# 打包缓存
tar -cf npm-cache.tar .npm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
操作完成后,会在当前目录下生成一个tar文件,如下图所示
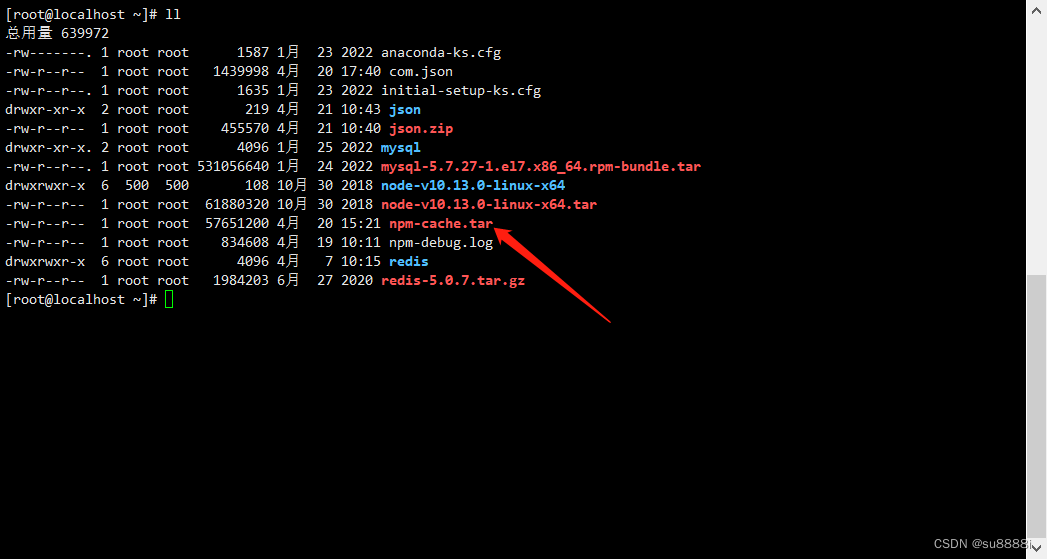
使用sz命令或者xftp将jar包下载到本地,并拿到内网机器上。
内网安装
将npm-cache.tar安装包上传到服务器/root/目录
解压安装包
tar -xvf npm-cache.tar
- 1
进入到node-v10.13.0-linux-x64/bin目录执行安装命令
(有的说是在lib目录下执行安装命令,但我是在bin下执行的,也成功了,总之安装到哪儿软连接的时候就写哪儿)
npm install --cache /root/.npm --optional --cache-min 99999999999 -shrinkwarp false elasticdump
#创建软连接
ln -s /opt/node-v10.13.0-linux-x64/lib/node_modules/elasticdump/bin/elasticdump /usr/bin/elasticdump
#验证
elasticdump --help
- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、使用命令导出数据
1.导出mapping
elasticdump --input=http://{es服务器用户名}:{es服务器密码}@{es服务器ip}:{es服务端口}/{索引名称} ---output={文件路径} --type=mapping
#例如:
elasticdump --input=http://admin:admin@localhost:9200/dataworks --output=/root/dataworks_mapping.json --type=mapping
- 1
- 2
- 3
- 4
2.导出data
elasticdump --input=http://{es服务器用户名}:{es服务器密码}@{es服务器ip}:{es服务端口}/{索引名称} ---output={文件路径} --type=data
#例如:
elasticdump --input=http://admin:admin@localhost:9200/dataworks --output=/root/dataworks_data.json --type=data
- 1
- 2
- 3
- 4
- 5
导入数据
三、使用命令导入数据
1.导入mapping
elasticdump --input={文件路径} --output=http://{es服务器用户名}:{es服务器密码}@{es服务器ip}:{es服务端口}/{索引名称} --type=mapping
#例如:
elasticdump --input=/root/dataworks_mapping.json --output=http://admin:admin@localhost:9200/dataworks --type=mapping
- 1
- 2
- 3
- 4
2.导入data
elasticdump --input={文件路径} --output=http://{es服务器用户名}:{es服务器密码}@{es服务器ip}:{es服务端口}/{索引名称} --type=data
#例如:
elasticdump --input=/root/dataworks_data.json --output=http://admin:admin@localhost:9200/dataworks --type=data
- 1
- 2
- 3
- 4
使用kibana导出数据
导出数据
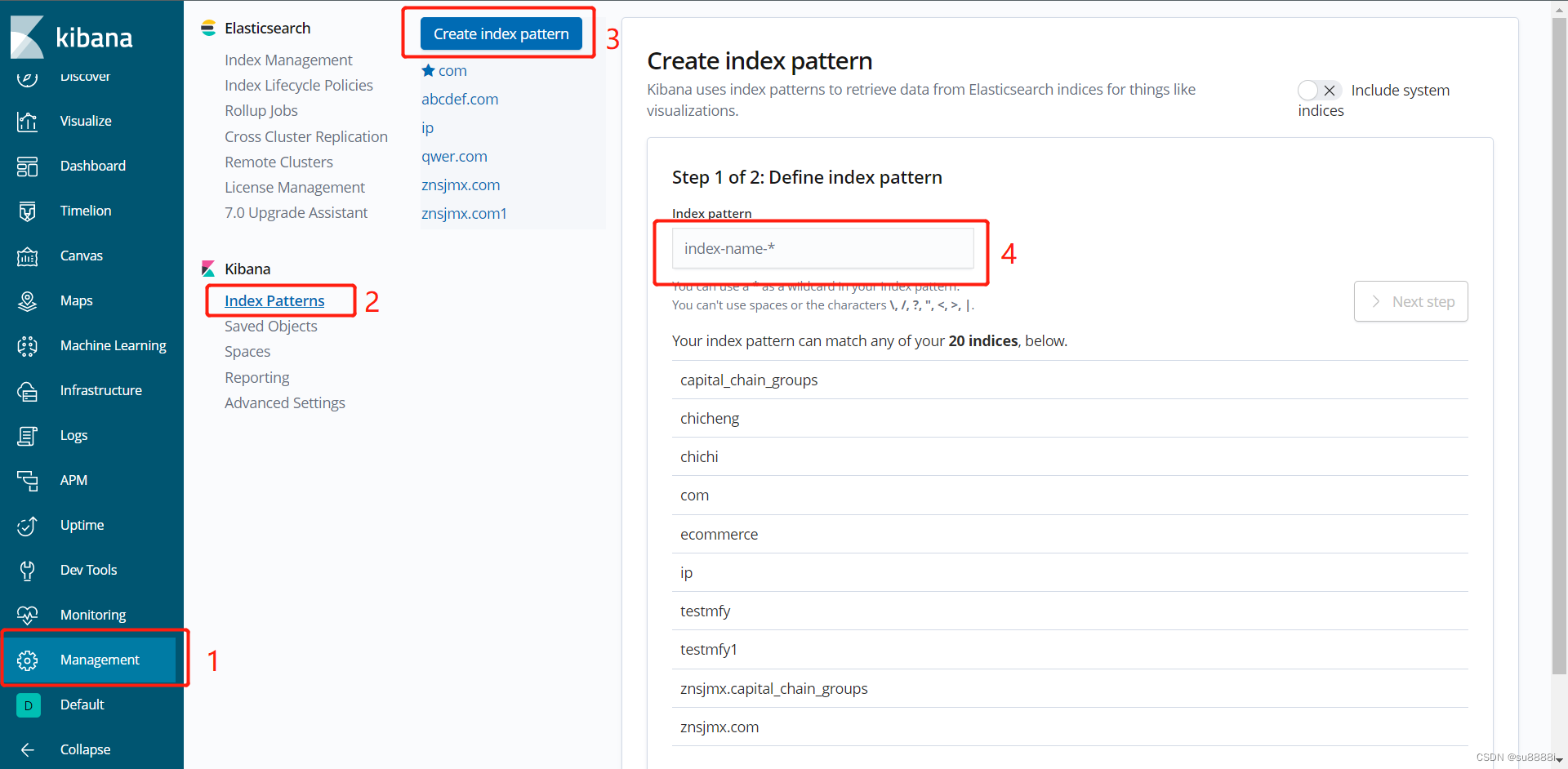
一、创建索引
按顺序点击框选的按钮,在4号位置搜索已存在的索引名称(可以添加星号*进行模糊匹配)
随后点击右侧的Next step,无脑下一步即可。
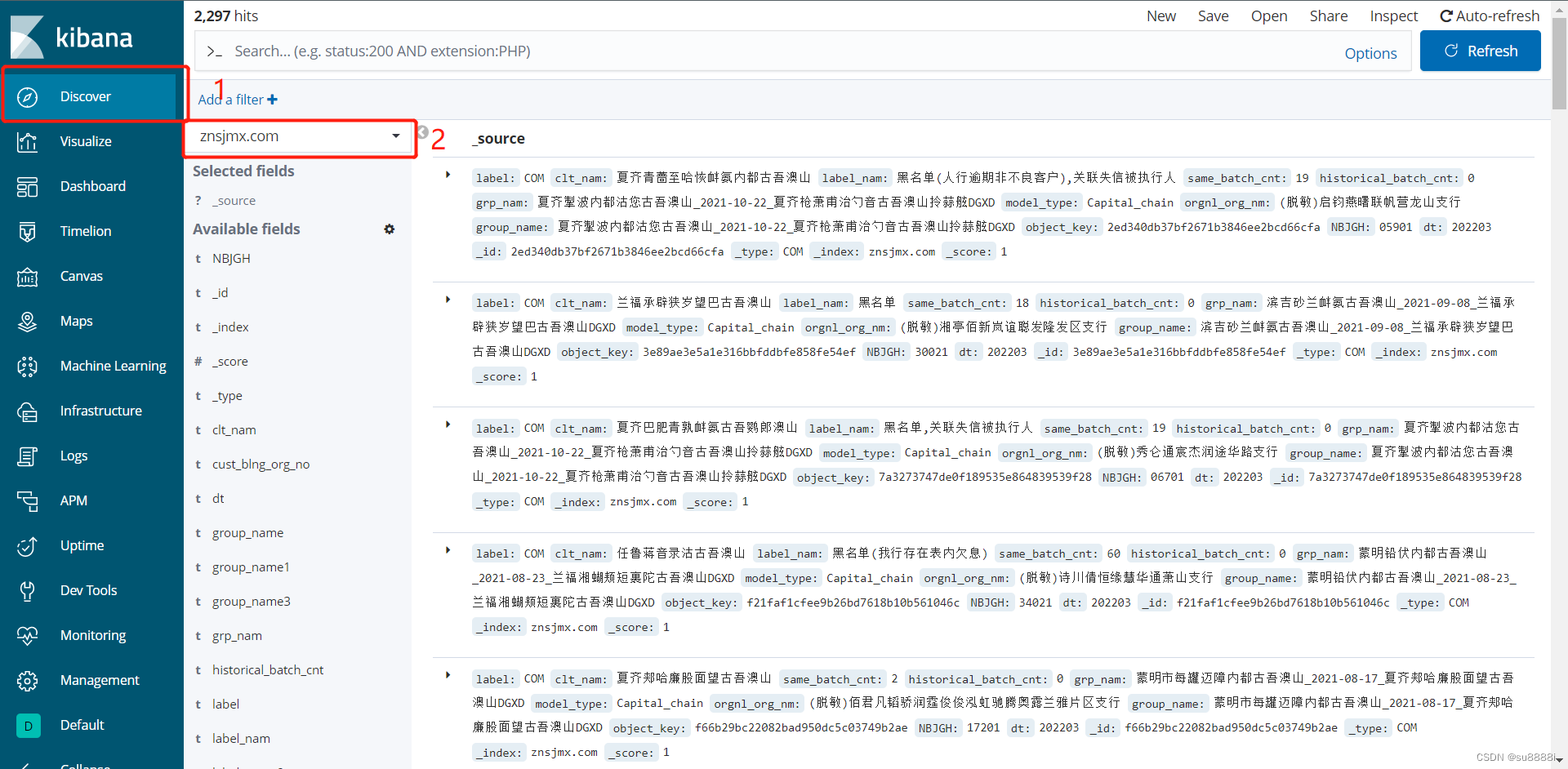
二、筛选导出
点击左侧的Discover,并在2号位置选择刚刚创建好的索引,可以在下方Available fields选择筛选的字段,点击右侧的add按钮添加,则只会展示所选中的字段。也可以将添加的字段在Selected fields下方点击remove删除,默认为全量数据。
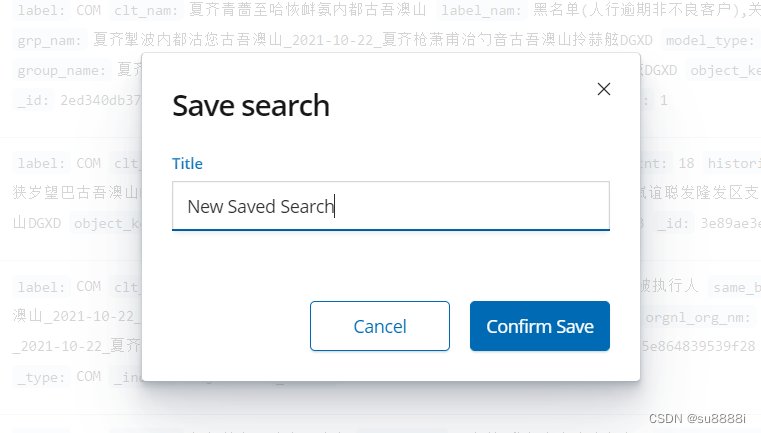
点击右上角的save按钮,将搜索到的结果保存并命名。
之后点击右上角的Share—>CSV Reports—>Generate CSV,生成文件。
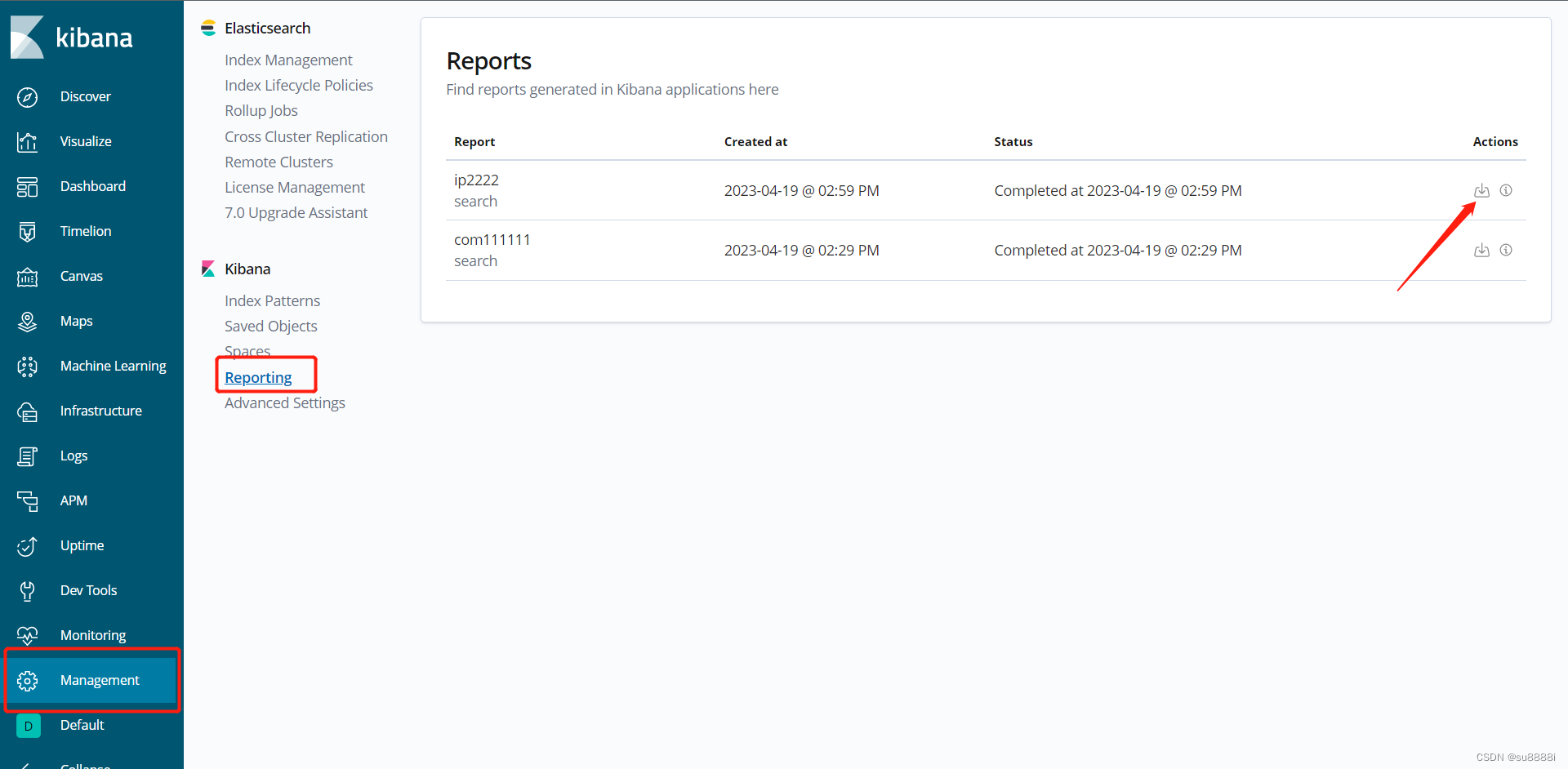
最后在Mangement当中的reporting中查找刚刚所生成的csv文件,并下载。
导入数据
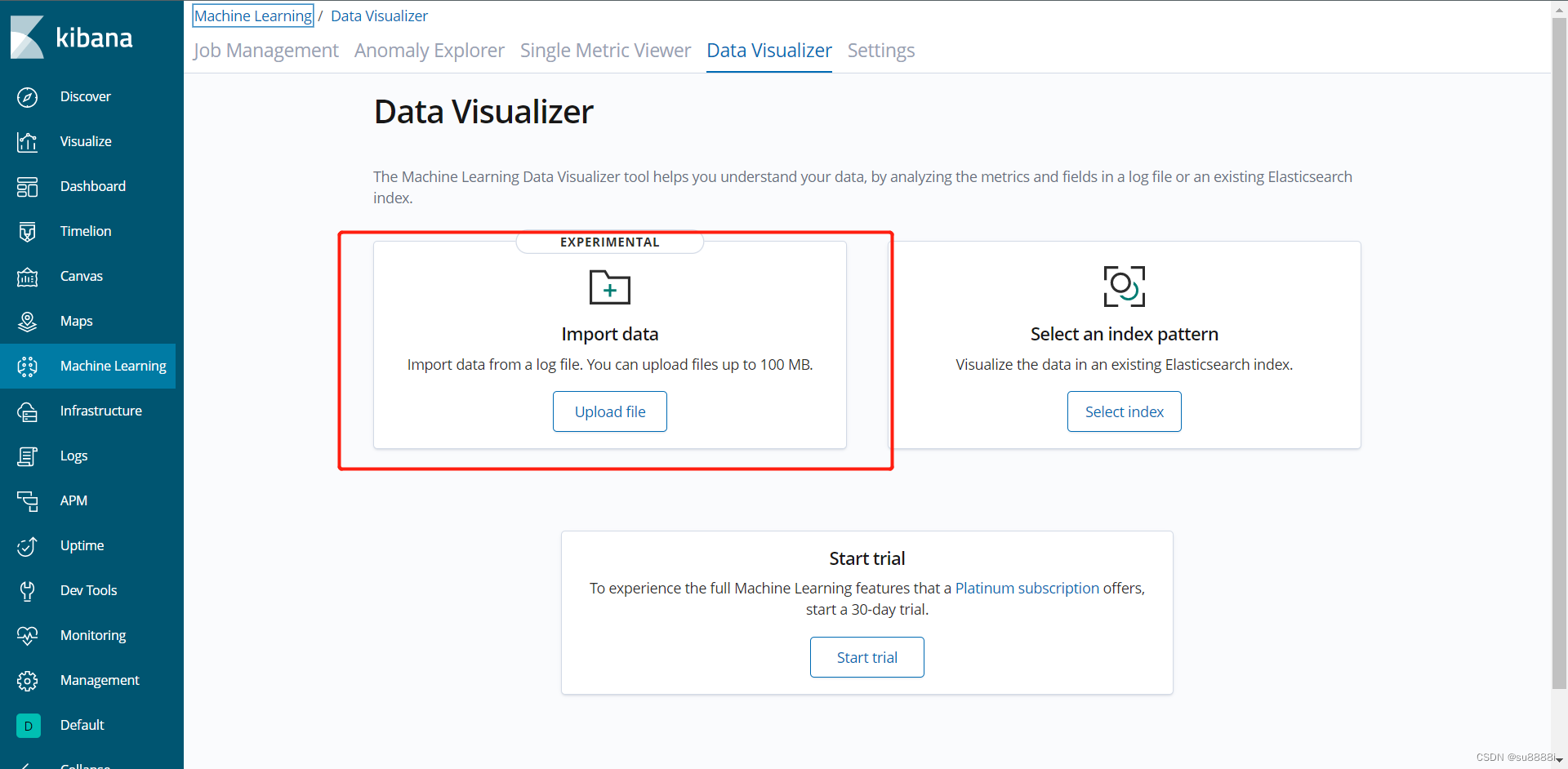
点击左侧的Machine Learning,import data,选择下载好的.csv文件。
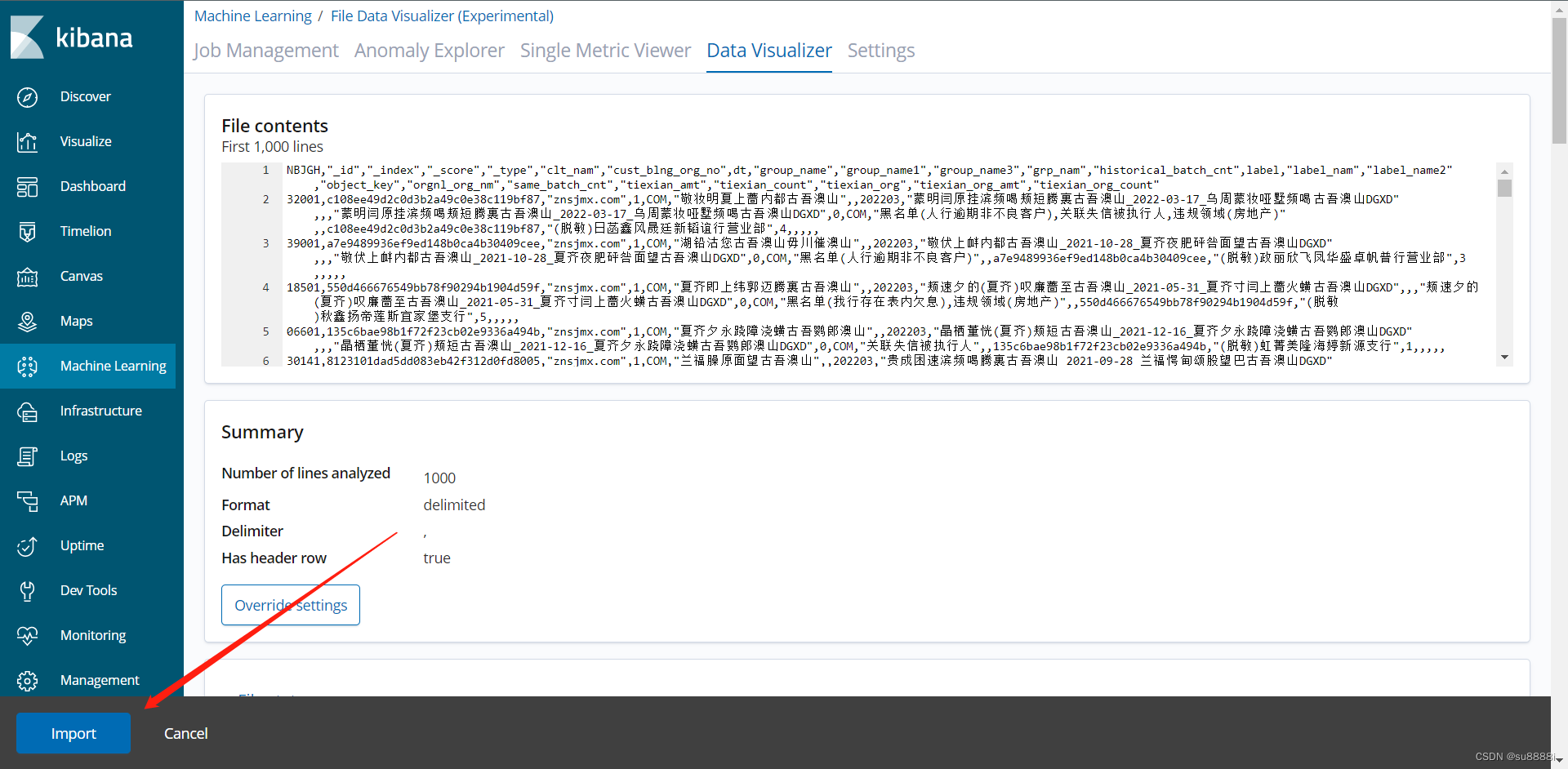
(此处少截了一个选择文件的图)
点击左下角的import
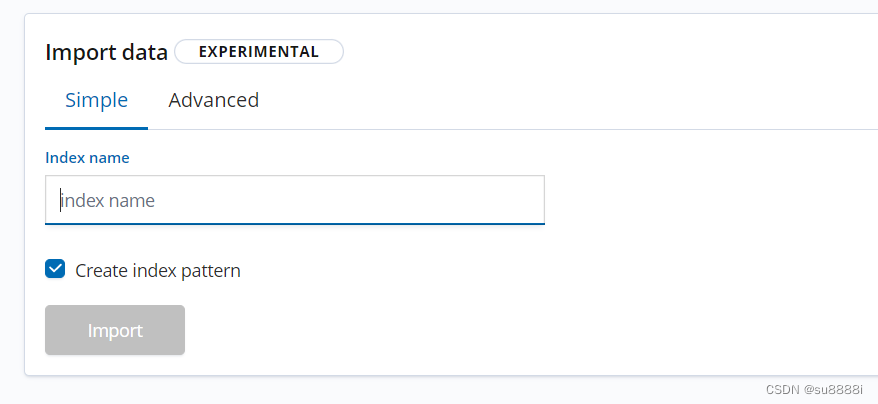
在这里填写要生成的索引的名称,填写Import即可导出完成
ps:但是我报错了,没弄成,不然也不会再去用上面的方法导入数据 -,-
文章参考:
https://blog.csdn.net/youmatterhsp/article/details/130122049
https://blog.csdn.net/weixin_41546364/article/details/127791395
https://blog.csdn.net/swrd456/article/details/126030887


