
mysql 聚簇索引和非聚簇索引_图文并茂,说说MySQL索引
赞
踩
点击上方 小伟后端笔记 ,选择 星标 公众号
重磅资讯、干货,第一时间送达
作者:小小木的博客来源:cnblogs.com/wyc1994666/p/10831039.html序
开门见山,直接上图,下面的思维导图即是现在要讲的内容,可以先有个印象~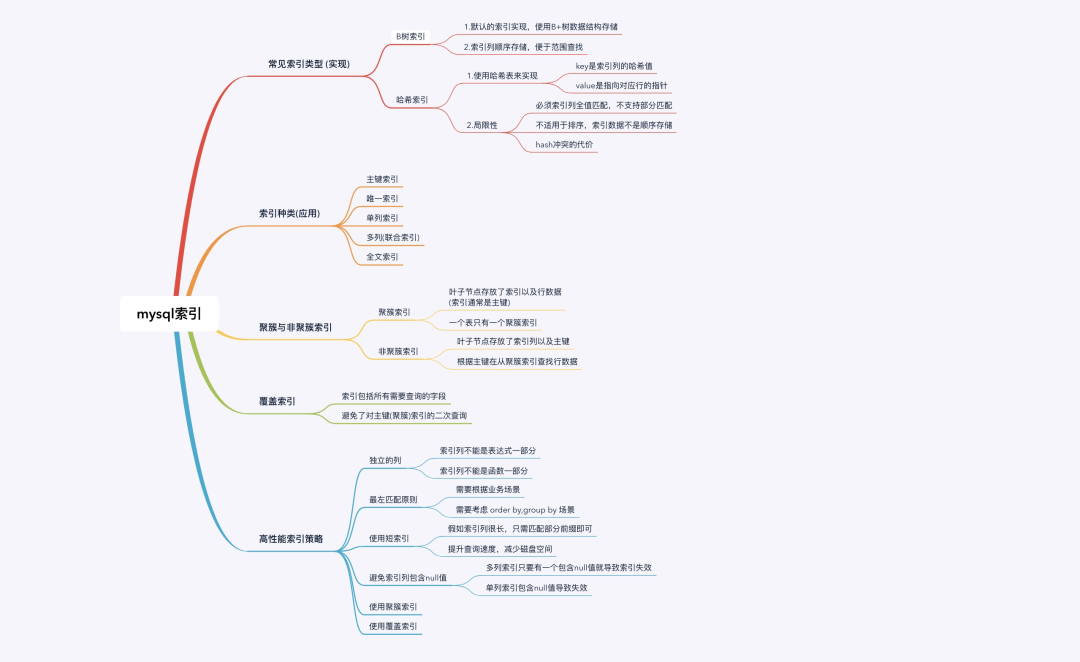
- 常见索引类型(实现层面)
- 索引种类(应用层面)
- 聚簇索引与非聚簇索引
- 覆盖索引
- 最佳索引使用策略
1.常见索引类型(实现层面)
首先不谈Mysql怎么实现索引的,先马后炮一下,如果让我们来设计数据库的索引,该怎么设计?
我们首先思考一下索引到底想达到什么效果?其实就是想能够实现「快速查找」数据的策略,所以索引的实现本质上就是一个「查找算法」。
但是跟普通的查找有所不同,因为我们的数据有以下特征:
「1.存储的数据是非常非常多的」「2.并且还不断的动态变化」
所以实现索引时需要考虑到这两个特点。我们需要找一个最合适的数据结构算法来实现查找功能。
下面一起看下常见的查找策略,如下图:
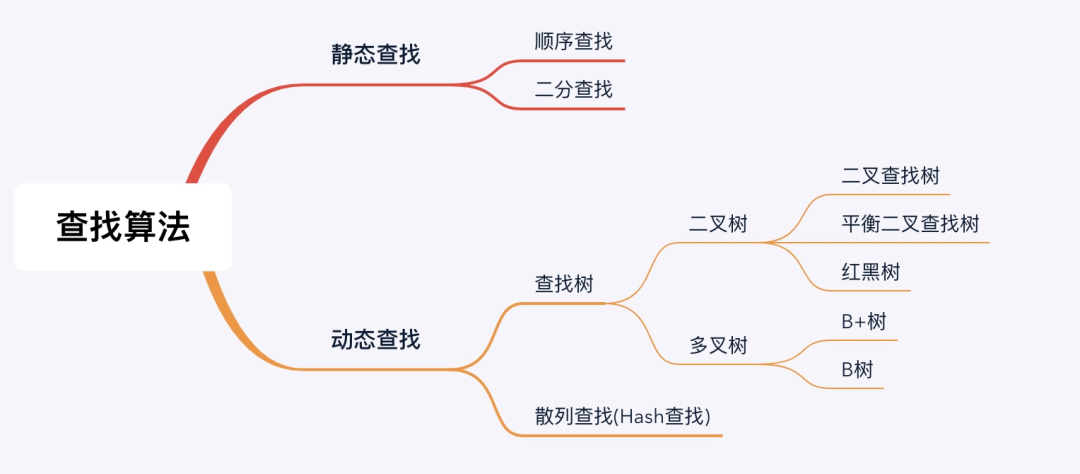
由于前面说的两个特点我们首先排除静态查找的算法。
至于查找树,我们有二叉树和多叉树两种选择:
「二叉树」:如果先查二叉树的话,由于我们的数据量庞大,二叉树的深度会变得非常大,我们的索引树会变成参天大树,每次查询会导致很多磁盘IO。
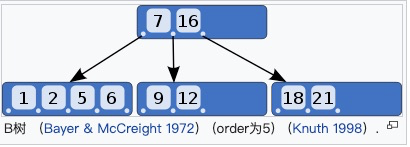
「多叉树」:多叉树解决了了树的深度大的问题,那么我们到底选择B树还是B+树呢?
❝B树 摘自维基百科 https://zh.wikipedia.org/wiki/B%2B树
❞
❝B+树 摘自维基百科 https://zh.wikipedia.org/wiki/B%2B树
❞
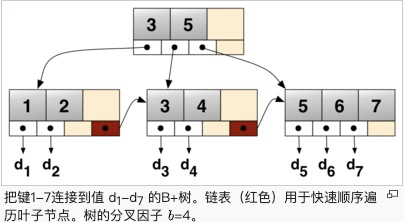
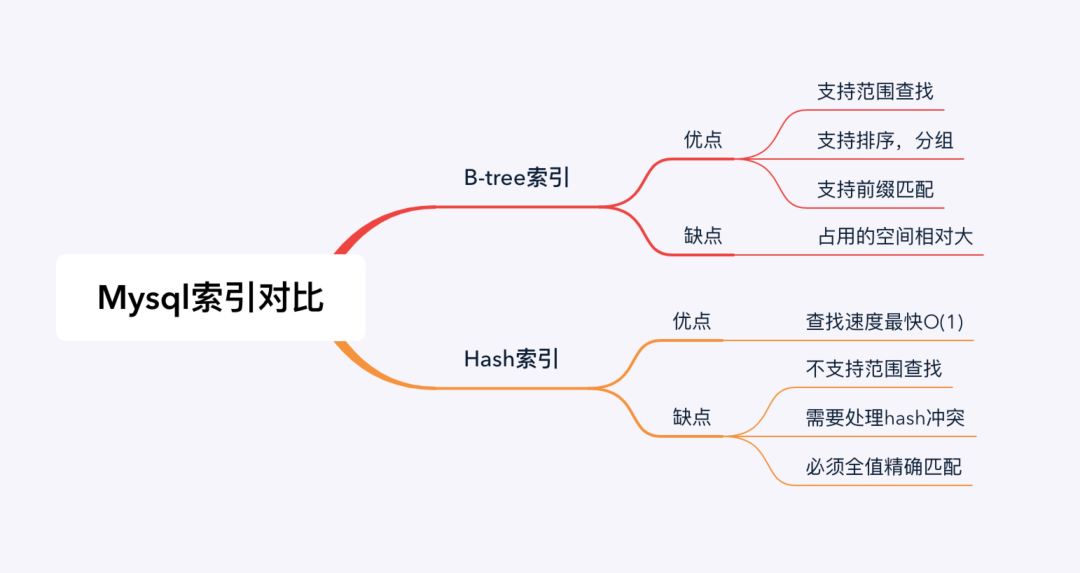
从上面图可知「B+树的叶子节点存放了所有的索引值」,并且叶子结点之间以链表的形式相互关联,所以我们只需从最左的链表遍历的话即可查找所有的值,最常见的用途就是范围查找,而B树则不满足这范围查找,又或者说实现特别复杂,所以Mysql最终选择了使用B+树实现这一功能。
1.1 B-Tree 索引(B+树)
先说明一下,虽然叫在Mysql官方叫做B-Tree索引,但采用的是B+树数据结构。
B-tree索引能够加快访问数据的速度,不需要进行全表扫描,而是从索引树的根节点层层往下搜索,在根节点存放了索引值和指向下一个节点的指针。
下面看下单列索引的数据怎么组织的。
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, key(`uid`));上面User 表给uid列创建了一个索引,那么往表里插入uid(96~102)的时候存储引擎是怎么管理索引的呢?看下面的索引树
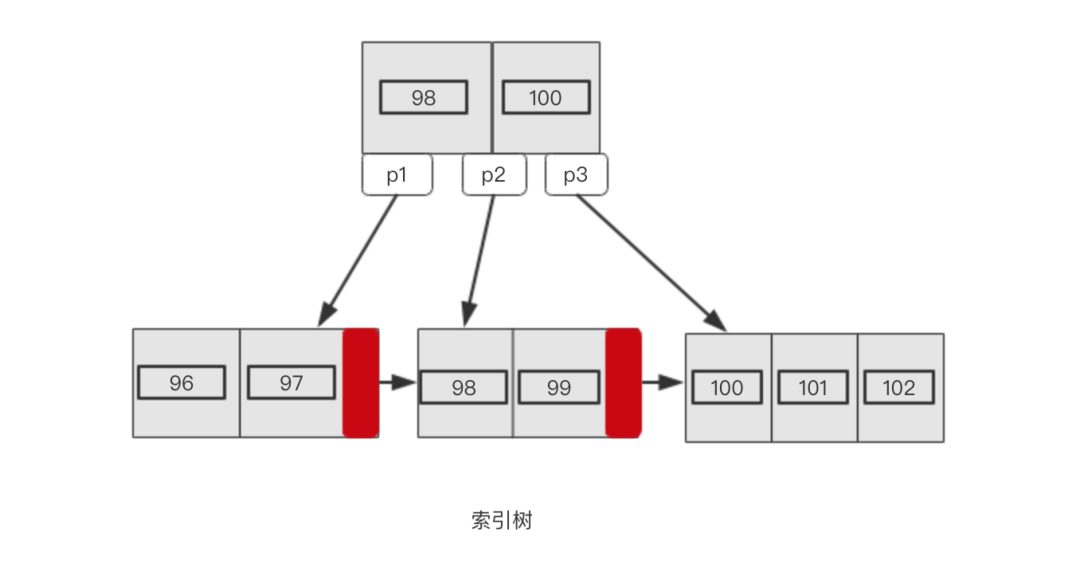
「1.在叶子节点存放所有的索引值,非叶子节点值是为了更快定位包含目标值的叶子节点」
「2.叶子节点的值是有序的」
「3.叶子节点之间以链表形式关联」
下面在看一下多列(联合)索引的数据怎么组织的。
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, key(`uid`,`name`));给User 表创建了联合索引 key(uid,name) 这种情况下他的索引树是如下图所示。

特点跟单列索引一样,不同之处在于他的排序,「如果第一个字段相同时会按第二个索引字段排序」
「如何通过B-tree快速查找数据?」
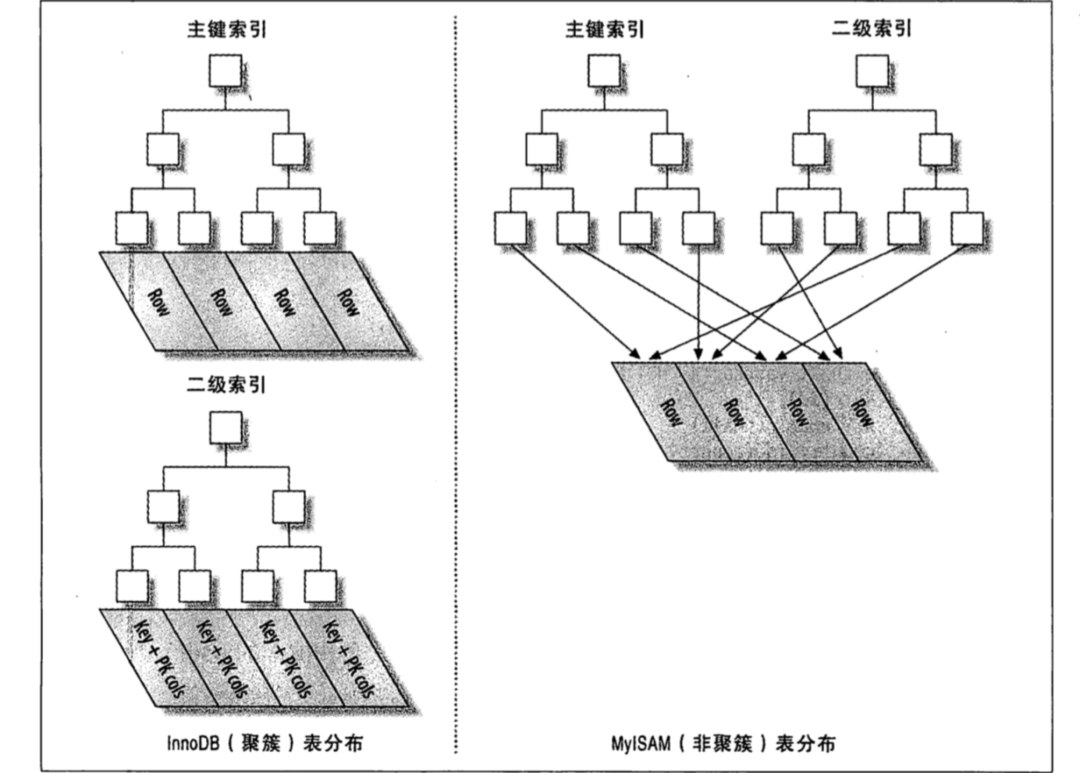
对于InnoDb 存储引擎的B-tree索引,会按以下步骤通过索引找到行数据
- 如果使用了聚簇索引(主键),则叶子节点上就包含行数据,可直接返回
- 如果使用了非聚簇索引(普通索引),则在叶子节点存了主键,再根据主键查询一次上面 的聚簇索引,最后返回数据
对于MyISAM 存储引擎的B-tree索引,会按以下步骤通过索引找到行数据
- 在MyISAM 的索引树的叶子节点上除了索引值之外即没存储主键,也没存储行数据,而是存了指向行数据的指针,根据这个指针在从表文件查询数据。
1.2 Hash 索引(哈希表)
哈希索引是基于哈希表来实现的,只有精确匹配所有的所有列才能生效。
也就是说假设有个hash索引 key (col1,col2) 那么每次只有 col1和col2两个字段都用才能够生效。因为生成hash索引的时候是根据一个hash函数对所有的索引列取hash值来实现的。
如下方图,有个hash索引key(name)
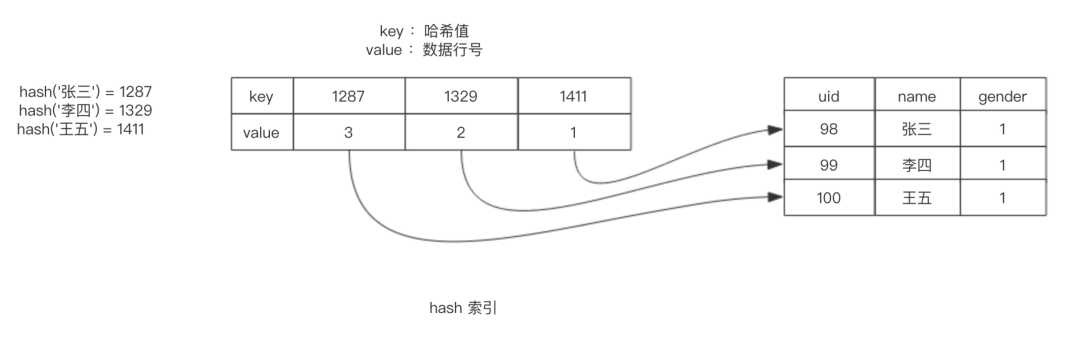
当我们执行 mysql> select * from User where name='张三'; 时怎么利用hash索引快速查找的?
- 第一步,计算出hash值,hash(张三) = 1287
- 第二步,定位行号,比如key=1287 对应的行号为3
- 第三步,找到指定行并且比较name列值是否为张三做个校验
2.常见索引种类(应用层面)
「主键索引」
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, primary key(`uid`));主键索引是唯一的,通常以表的ID设置为主键索引,一个表只能有一个主键索引,这是他跟唯一索引的区别。
「唯一索引」
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, unique key(`name`));唯一索引主要用于业务上的唯一约束,他跟主键索引的区别是,一个表可以有多个唯一索引
「单列索引」
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, key(`name`));以某一个字段为索引
「联合索引」
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, key(`name`,`uid`));两个或两个以上字段联合组成一个索引。使用时需要注意满足最左匹配原则!
还有其他不常用的就不介绍了~
3.聚簇索引与非聚簇索引
什么是聚簇索引?聚簇索引指的是他的 「索引和行数据」 在一起存储。也就是在一颗B+树的叶子结点上存储的不仅是他的索引值,还有对应的某一行的数据。待会儿看图便知。
「聚簇索引不是一种索引,而是一种数据存储组织方式 !!!」
crreate table test( col1 int not null, col2 int not null, PRIMARY KEY(col1), KEY(col2));如上所示,表test 由两个索引,分别是主键 col1 和 普通索引 col2。那么这俩索引跟聚簇非聚簇有啥关系呢?
会生成一个聚簇索引和一个非聚簇索引(二级索引),也就是说会组织两个索引树。主键索引会生成聚簇索引的树 以及以col2为索引的非聚簇索引的树。
「InnoDb 将通过主键来实现聚簇索引」 ,如果没有主键则会选选一个唯一非空索引来实现。如果没有唯一非空索引则会隐式生成一个主键。
下面看下聚簇索引和非聚簇索引在索引树上数据是怎么分布的,图片摘自《高性能Nysql》
「下图是聚簇索引的数据组织方式。col1为主键索引的聚簇索引树」
「索引列是主键 col1」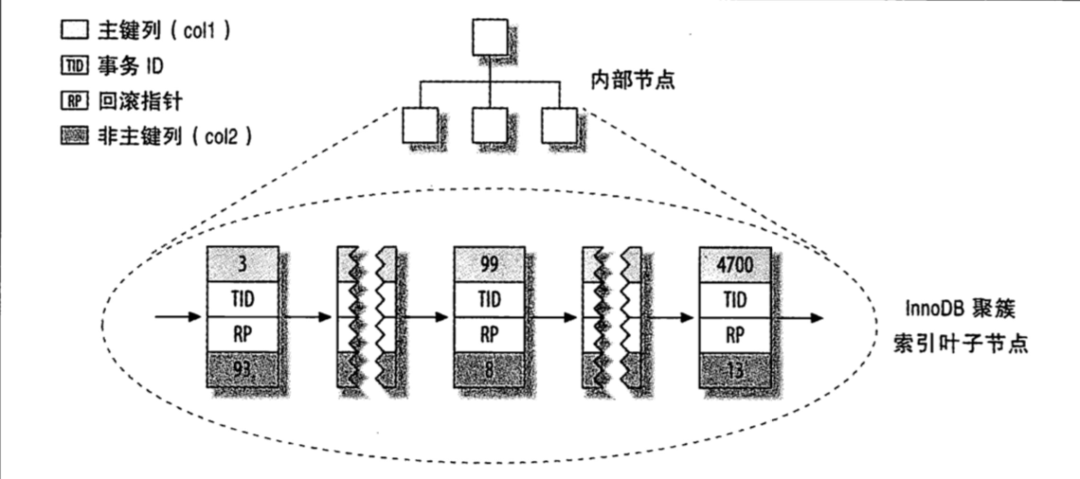 可以看出叶子结点除了存储索引值 列col1 (3994700)值 之外还存储了其他列的值,如列col2 (92813),如果还有别的列的话也会存储,或者换句话说聚簇索引树 在叶子节点上存储某个索引值对应的一行数据。
可以看出叶子结点除了存储索引值 列col1 (3994700)值 之外还存储了其他列的值,如列col2 (92813),如果还有别的列的话也会存储,或者换句话说聚簇索引树 在叶子节点上存储某个索引值对应的一行数据。
「下图是非聚簇索引(二级索引)的数据组织方式。」
「索引列是 col2」

与聚簇索引不同的是非聚簇索引在索引树叶子节点上除了索引值之外只存了主键值。而聚簇索引则存了一行数据。
假如有一条sql 语句 select * from test where col2=93;上面这条语句会经历两次从索引树查找过程
1.第一步从非聚簇索引的索引树上找到包含col2=93的叶子节点,并定位到行的主键 3 2.第二步 根据主键 3 在从聚簇索引定位包含 主键=3的叶子节点并返回全部行数据。
以上说的都是基于InnoDb存储引擎的,「MyISAM」是不支持聚簇索引的,因为他的数据文件和索引文件是相互独立存储的 「MyISAM」存储引擎的索引树的叶子节点不会存主键值,而存一个指向对应行的地址或者说是指针,然后再从表数据文件里去找,如下面图所示。

结论:
- 聚簇索引: 通常由主键或者非空唯一索引实现的,叶子节点存储了一整行数据
- 非聚簇索引:又称二级索引,就是我们常用的普通索引,叶子节点存了索引值和主键值,在根据主键从聚簇索引查
4.覆盖索引
「覆盖索引就是指索引包含了所有需要查询的字段。」
create table User(`name` varchar(50) not null,`uid` int(4) not null,`gender` int(2) not null, key(`uid`,`name`));假如表 User有三个字段 User (name,uid,gender),且有个联合索引 key(name,uid)那么 执行如下面这条sql查询时就用到了 覆盖索引。
select name,uid from User where name in ('a','b') and uid >= 98 and uid <=100 ;
上面这条sql语句使用了联合索引 key(name,uid),并且只需查找 name,uid两个字段,所以使用了覆盖索引。覆盖索引有什么好处呢?先看一下下面这个图上面这个图就是 联合索引key(name,uid) 所对应的索引树,从图中可以看出,如果我们只需查询(name,uid)两个字段的话,从索引树就能得到我们需要查的数据。不需要找到索引值之后再从表数据文件定位对应的行数据了。
覆盖索引好处 1.避免了对主键索引(聚簇)的二次查询 2.由于不需要回表查询(从表数据文件)所以大大提升了Mysql缓存的负载
总之大大提升了读取数据的性能
5.最佳索引使用策略
最后在讲讲使用索引过程中的避坑指南
「独立的列」
独立的列不是指单列索引,而是指索引列不能是表达式的一部分或者是函数的一部分。
select * FROM test where col1 + 1 =100; // 不能是表达式一部分
select * FROM test where ABS(col1) =100; // 不能是函数一部分
「最左匹配原则」
假如有个联合索引 key (col1,col2)。那么以下查询是索引无效的
select * from test where col2 = 3;
select * from test where col1 like '%3';
对于最左匹配原则,大家想一下B+树的叶子节点的关联就差不多知道为啥需要最左匹配原则了,因为B+的叶子结点,从左到右以链表的形式关联的,索引我们查询的时候要么范围查询,要么有明确的左边一个开始的索引值,不能跳过或者不明确如 like '%XYZ'这种查询。
「索引值不能是null值」
单列索引有null值会导致索引无效 多列索引只要有个列有null值会导致索引无效
「使用聚簇索引和覆盖索引大大提升读取性能」
因为聚簇索引和覆盖索引的索引树上就有了需要的字段,所以不需要回表文件查询,所以提升了查询速度
「使用短索引」如果很长的字符串进行查询,只需匹配一个前缀长度,这样能够节省大量索引空间
 推荐阅读:
推荐阅读:
从传统Web框架切换到SpringBoot后的总结
阿里云盘正式上架,附下载链接+邀请码
换工作,关于面试的总结
学会这个!微信支付能提现免费!
为什么SimpleDateFormat不是线程安全的?
不开心就点点 在看 开心也要点点 在看 ↘↘↘

