
- 1‘error:03000086:digital envelope routines::initialization“处理方法
- 2程序员辞职常用借口_java离职原因怎么写最合适
- 3Ultra96之DPU-1_zcu102-dpu-trd-2019-1-190809.zip
- 4【DataWhale】灵境Agent开发——低代码创建AI智能体_分支链中强制意图的意思
- 5Mogdb 5.0新特性:SQL PATCH绑定执行计划
- 6极客公园对话 Zilliz 星爵:大模型时代,需要新的「存储基建」
- 7用栈实现队列(力扣第232题)
- 8mysql limit实现数据查询分页显示_navicat 查询分页
- 9boss:整个卡尔曼滤波器的简单案例——估计机器人位置
- 10JAVAWEB--封装通用的crud操作(jdbc)
编码在网络安全中的应用和原理_网络中数据编码的原理是什么
赞
踩

目录
常见的一些编码的介绍(已经了解也可以看看,有一些我的个人总结)
前言:现在的网站架构复杂,大多都有多个应用互相配合,不同应用之间往往需要数据交互,应用之间的编码不统一,编码自身的特性等都很有可能会被利用来绕过或配合一些策略,造成一些重大的漏洞。
什么是编码,为什么要有编码?
众所周知,计算机只能够理解0和1,也就是二进制。可是我们的世界0和1以外,还有太多太多的符号和语言了,这时候,我们通过人为的规定一种0和1的排列组合顺序为某一种符号或者语言,这就是编码。是一种人为的规定的一种映射集合。
常见的一些编码的介绍(已经了解也可以看看,有一些我的个人总结)
ASCII:
因为一开始计算机只在美国用,要表达的也仅仅是大小写英文单词和一些特殊符号等。于是用八位的字节的01不同顺序来表示一些想表示的符号,所以一共可以组合出256种不同的状态。他们把其中的编号从0开始的32种状态分别规定了特殊的用途,33号以后到127表示一些英文单词,运算符号,阿拉伯数字等。可是之后计算机的普及,导致各个国家都能够使用上计算机,而每个国家又有自己的一些特定符号语言,这之后ASCII哪怕后128位都用上(比如latin1就是把ASCII的扩充),都不够用了,于是就出现了很多国家就自己创建了一些编码,把自己国家的一些符号语言加入进去,比如下面的GBK编码。
GBK
GBK是我们国家为了应付ASCII放不下汉字等(还有一些其他想表达的)而制定的一套编码,其中废弃了ASCII127之后所有的字符,规定一个小于127的字符的意义与原来相同,但大于128的字符表示和其后一字节字符连在一起,表示一个汉字。前身还有GB2312等,GBK是汉字加的最多的。而所谓的半角全角字符其实就是ASCII中原先定义的和GBK2个大于127定义字符的区别。还有说一个中文等于两个英文,也是这个编码的原因
UNCODE
如果每个国家都有自己的编码规则,而计算机又是一个大的网络,那信息交互不是就存在很大的问题了,你讲英语而我的规则的中文,那肯定就不能交流了,所有就有了UNCODE,其中规定两个ASCII为一个UNCODE 原来的ASCII就在前面填充0,然后把各国需要的一些字符加入到规则映射集合里,所以,这套规则就不存在一个中文等于两个英文了。所以就有了严重的浪费,一个英文都有八位的字节浪费。在网络传输中,这是不能忍受的。并且,当从中间开始匹配时,也不知道这个字节是第一个还是第二个。所以都没有推广开。
UTF-8:
这套编码就是解决UNCODE的空间浪费,他把UNCODE的进行分割,第一类就是原来的最高的ASCII的127个,127在二进制需要7位,所有用0XXXXXXX来表达,而之后的UNCODE采用6位分一组的方式写道UTF-8,可能直接说会有点晕晕的,我拿一个例子。比如二进制码为0110 1100 0101 0111的UNCODE的码表达的是中文汗,转换成UTF-8就是先6位从后到前分组0110 110001 010111,不难看出这里一共分了3组,所有UTF-8在第一字节先写上3个1,表示自己是3个字节的,再在3个1后面加0,这是规定,别问为什么。所以第一个字节还剩下4个可用字节,然后在往后的字节开头都为10,还剩下6个可用字节,6+6+4=16,刚好把之前的2字节的UNCODE码给抄上去,所以UTF-8表达“汗”就是11100110 10110001 10010111
URL编码:
URL编码主要是在WEB传输中方便WEB容器识别而制定的一套规则,比如URL为 http://www.0d9y.cn/index.php?a==&3&&b=&3,那么到底参数是什么,就很难说,所有URL编码就是为了让这些分隔符更好的被识别出来,所有任何参数里包含分隔符的都必须把符号用URL编码的方式来表达。URL编码的对应规则就是根据传输协议的编码的16进制形式给每个十六进制加上百分号%。例如“汗”,传输协议是UTF-8,则UTF编码就是%e6%b1%97,和上面刚好对应。
编码引起的安全
GBK编码绕过GPC
这个相信大家都听说过,但是不知道大家有没有仔细思考过为什么呢?拿这个例子带大家深入理解编码和安全的关系。
首先一次SQL注入需要考虑的编码有网页前端编码,因为这个编码会在URL编码中用到,然后就是后台PHP和数据库连接时用到的编码,最后就是数据库本身的编码。
虽然由于编码不一致导致的漏洞很多,但在我看来,这次绕过主要就是GBK编码一个缺陷而并非任何编码不一致。
GPC是PHP的一种防注入手段,会给所有的对所有的 GET、POST 和 COOKIE 数据自动运行 addslashes()函数,如果数据中有",',\,NULL会在前面加上\达到转义的效果。现在版本的PHP一般默认不开启,不过利用addslashes()函数来过滤数据依旧很普遍。首先什么是GBK编码绕过GPC呢?就是可以用如%DF来配合GPC或者 addslashes(),在编码转换存在问题的时候,就会生成一个乱码加上单引号',造成SQL注入安全。原理如下:
单引号'和反斜杠\都在ASCII表里,ASCII码分别是0x5C、0x27,当网页前端返回编码是GBK时,则单引号'的内码就是01011100,如果网页前端返回编码是UTF-8时,内码同样也是01011100。PHP的addslashes()会给单引号进行转义,在其前面加上反斜杠\,(假设后端PHP编码是GBK)在GBK编码下,内码是00100111,(假设后端PHP编码是UTF-8) 在UTF-8编码下,内码同样也是00100111,所以网络上很多人说只有前端是GBK才会有这个漏洞是错误的,因为不论前端后端是什么编码,单引号'或者反斜杠\内码都是一样的。
而这个漏洞的名称为什么叫GBK编码绕过GPC呢,很简单,当你哪里会用到你注入的这段污点参数,而那里用的编码是GBK,这个漏洞就会存在。这是GBK编码的特性决定的。因为GBK编码的定义是,当遇到一个字节其表示二进制数值转换成十进制后大于128就会默认这个字节和之后一个字节合并表示一个汉字,就把后面反斜杠\的内码吃掉了组成一个汉字(可能有点绕,多读两遍就好了,不理解可以来我的博客或者下方留言)。
为什么要注入%DF呢?因为%DF是经过URL编码的,不管这个URL编码是通过哪一种编码DECODE来的,可以确定的是,这个URL编码其最终的内码就是11011111,转换成10进制是223,是大于127的,所以其实不一定是%DF,%81以上,其实都是可以的。不过值得一体,我测试最新版本的mysql时,发现mysql把二进制转换成GBK编码的时候似乎能避免这个漏洞。这里还比较疑惑,以后等我弄明白了再给大家解释。
UTF-8编码引起的编码绕过
上面已经解释过UTF8编码的定义了,所以不妨设想一下,一个ASCII编码是不是除了0加ASCII外,可以自定义字节呢?比如说单引号',UTF-8解码就是01011100,那么11000001 10011100 代表不也是单引号'么 甚至11100000 10000001 10011100 是不是也可以代表单引号'呢?经过测试,发现有一些系统可以识别这种加长后的二进制码,而有一些又不可以,具体原因不解,等以后理解深入继续解答。不过这不尝是一种绕过的技巧,如果WAF不能识别加长版的UTF-8嘛而其他调用的组件又可以识别,那就可以成功利用,之前的Apache Tomcat目录遍历漏洞,就是利用这个方法,把/../进行加长编码。再比如%00截断,也可以用%C080,一旦WAF没有解析而PHP解析了,就会照成漏洞。
不同程序对畸形编码的处理方式不同
拿一道CTF的题目来给大家介绍,首先是一个名叫ctf的数据库,其中表名为name,字段id有且仅有字符型数据"ctf",PHP源代码如下图怎么样进行绕过拿到flag呢?
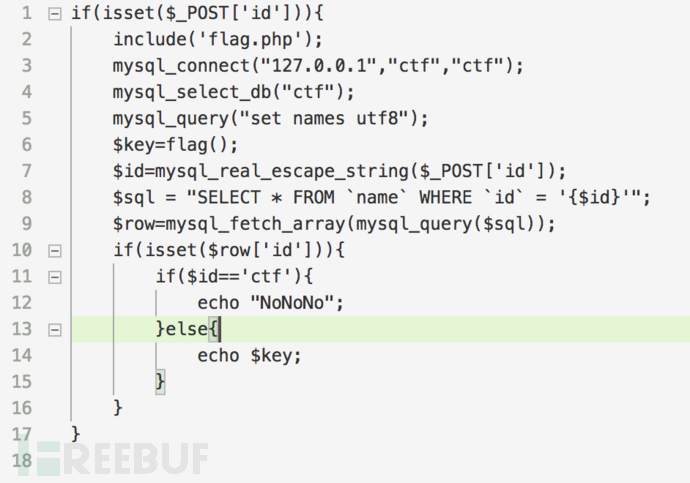
不难看出,其中就是$id和数据库取回来$row['id']的要不一样,然后数据库连接编码是utf8,所以我们可以构造参数id=ctf%c2的方式进行绕过,因为PHP对畸形的编码%FF会输出ASCII扩展码里的内容,而数据库mysql则会对其进行过滤,直接忽略,这也就可以绕过CTF中的$id=='ctf'的限制了。再比如前面的ApacheTomcat容器,对畸形的非最短UTF-8编码就会进行解析,而Nginx则会不识别等,熟知不同程序的处理方式,也会对渗透提供帮助。
总结
编码安全应当引起我们大家足够多的重视,在我们平时开发尽量统一编码字符集,很多时候绕过WAF出现困难也可以尝试利用编码特性来进行绕过。
原文作者:alerttest,来自FreeBuf.COM
学习更多渗透技能!欢迎领取hack视频网络安全资料



