
- 1【数据集研究】PASCAL VOC 2007_voc2007数据集
- 23天精通Postman---基础应用&接口测试流程&接口架构和协议_postman支持的接口协议包括
- 3单链表接口函数的实现(增删查改)
- 4计算机网络 | 应用层 :HTTP协议详解_抓取应用层的http数据分组并解读每个字段的含义。
- 5一键部署、开箱即用的Stable Diffusion云平台-仙宫云_仙宫云部署端口
- 6执行ssh-copy-id报错REMOTE HOST IDENTIFICATION HAS CHANGED_/usr/bin/ssh-copy-id: info: source of key(s) to be
- 7文心一言与GPT-4比对测试!
- 8Python制作抽奖系统_怎么用python做抽奖系统
- 9FastAdmin使用——基本使用篇_fastadmin教程
- 10计算机毕业设计Node.js+uniapp安卓人防管理系统APP(源码+程序+lw+远程调试)_uniapp 安卓 管理员登陆
实时语音识别(Python+HTML实战)_funasr python实时语音识别
赞
踩
1 安装库文件
项目提示所需要下载的库文件:pip install -U funasr 和 pip install modelscope
运行过程中,我发现还需要下载以下库文件才能正常运行:
下载:pip install websockets,pip install ffmpeg
2 运行 .py 文件
运行 FunASR-main/runtime/python/websocket/funasr_wss_server.py 文件,加载模型
注:如果提示缺少什么模型,就 pip 下载什么模型

部署本地的情况下需要修改默认 host 值 "0.0.0.0" 为 "127.0.0.1":
- --host:是 FunASR runtime-SDK 服务部署机器的 ip,默认为本机 ip(127.0.0.1),如果 client 与服务不在同一台服务器,需要改为部署机器 ip
- --port:10095 是部署的端口号
成功运行结果如下:
.cache\modelscope\hub\iic\speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch\model.pt
.cache\modelscope\hub\iic\speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online\model.pt
.cache\modelscope\hub\iic\speech_fsmn_vad_zh-cn-16k-common-pytorch\model.pt

.cache\modelscope\hub\iic\punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727\model.pt

提示如下内容,说明模型已经加载完毕:
![]()
3 运行 .html 文件
运行 FunASR-main/runtime/html5/static/index.html 文件,加载项目主页面
第一个 asr 服务器的地址填入:
wss://127.0.0.1:10095
点击左下角的连接按钮,回到 Pycharm 运行界面提示连接成功!
![]()
4 结果展示
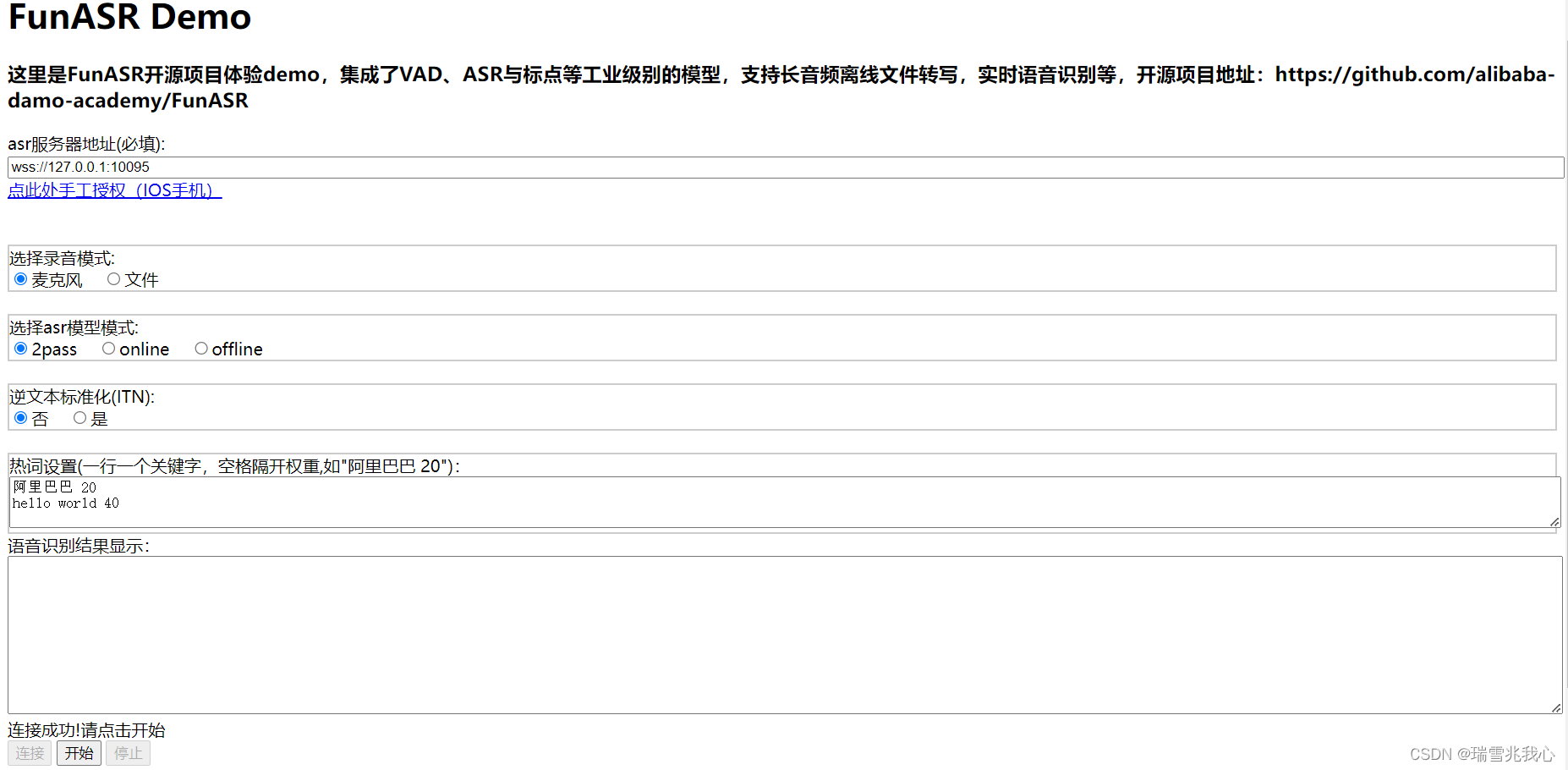
该项目支持麦克风实时录音功能,同时可以传入多种音频格式的文件(如 .wav, .pcm, .mp3 等),也支持视频输入(如 .mp4 等),以及多文件列表 wav.scp 输入。

