
- 1鸿蒙Harmony跨模块交互_鸿蒙 一个模块调用另一个模块的文件
- 2C#DataTable一些基本操作_c# datatable where
- 3深度学习 - 38.Gensim Word2Vec 实践
- 4python跨文件夹调用别的文件夹下的py文件或参数方式_python不同文件夹下的py文件调用
- 5解决 jenkins 插件下载失败问题 - 配置 jenkins 插件中心为国内镜像地址_jenkins update site mirror
- 6RabbitMQ如何保证消息幂等性_rabbitmq如何保证消息的幂等性
- 7汽车牌照-C++
- 8【sex.com最贵的域名】
- 9scratch编程 蓝桥杯编程题 红绿灯_scratch模拟信号灯
- 10R语言实验报告【全集】
云计算与大数据笔记之Spark【重点:流水线机制】
赞
踩
图片和部分笔记来自于厦门大学-林子雨-大数据技术原理与应用(第3版) 配套PPT
三大分布式计算系统开源项目Hadoop、Spark、Storm
Storm、Hadoop和Spark都是处理大数据的框架,但它们各自在设计上有着不同的侧重点,这导致了它们在实际应用中的不同定位。
Hadoop
- 主要组件:Hadoop Distributed File System (HDFS) 和 MapReduce。
- 设计理念:主要针对的是大规模数据集的批处理。
- 使用场景:适用于那些不需要实时处理的场景,比如大数据的存储、离线分析等。
- 优点:稳定、成熟,生态系统丰富。
Spark
- 主要组件:Spark Core, Spark SQL, Spark Streaming, MLlib(机器学习)和GraphX(图计算)。
- 设计理念:相较于Hadoop的MapReduce,Spark更加灵活,可以进行批处理、交互式查询、实时分析、机器学习和图处理。
- 使用场景:适用于需要快速迭代数据处理任务的场景,包括实时处理和批处理。
- 优点:速度快(在内存计算),API丰富,可以用于多种数据处理需求。
Storm
- 主要组件:主要是其流式计算模型。
- 设计理念:Storm专注于实时数据流的处理。
- 使用场景:适用于需要对数据流进行实时处理和分析的场景,比如实时广告投放、复杂事件处理等。
- 优点:实时性强,可以实现低延迟的数据处理。
为什么Storm的教学资源不如Hadoop和Spark?
- 市场占有率和流行度:Hadoop和Spark由于其通用性和广泛的应用场景,拥有更大的用户基础和社区支持。这导致更多的教育资源和开发者关注。
- 使用场景限制:Storm专注于实时数据流处理,这是一个相对更专业和细分的领域。相较之下,Hadoop和Spark的使用场景更广泛,涵盖了批处理和实时处理等多种需求。
- 技术发展:随着时间的推移,一些新的实时处理框架和技术(如Apache Flink)的兴起,可能在某些方面超越了Storm,导致社区和开发者的关注点转移。
- 学习曲线:实时数据流处理涉及的概念和模型可能对于新手来说比较复杂,这可能导致相对较少的入门级或初学者友好的教学资源。
尽管Storm在某些特定的实时处理场景中非常有用,但它的使用场景相比Hadoop和Spark来说更加专一,这可能是它教学资源相对较少的一个原因。然而,对于需要处理实时数据流的应用场合,Storm仍然是一个非常强大和有价值的工具。
Spark笔记简介


Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统:
- 既能够提供内存计算框架,也可以支持SQL即时查询、实时流式计算、机器学习和图计算等。
- Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。
因此,Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理。

Spark线程并行与MR进程并行
进程并行(MapReduce)
MapReduce 是 Hadoop 的计算框架,设计用于大规模数据处理。它的核心是将计算任务分解为两个阶段:Map(映射)和 Reduce(归约)。每个阶段可以在不同的数据块上独立并行运行,通常是在不同的机器上。
- 进程:在操作系统中,一个进程是运行中程序的一个实例,拥有独立的内存空间。MapReduce 更侧重于进程并行,意味着它依赖于启动多个独立的进程,每个进程处理数据的一个子集。这些进程可以分布在一个分布式系统的不同机器上。
线程并行(Spark)
Spark 是一种内存计算框架,用于大规模数据处理,能够进行批处理、流处理、机器学习等。Spark 的设计允许它在内存中处理数据,从而比基于磁盘的MapReduce更快。
- 线程:线程是进程中的一个实际执行单元,共享进程的内存空间。线程并行,或在Spark中的任务并行,是指在单个或多个进程内并行运行多个线程,这些线程可以共享相同的数据和内存空间。
- 资源共享:由于线程之间可以共享内存,Spark 可以更有效地利用系统资源,减少数据在不同任务或作业间的移动和复制。
深度对比
- 资源隔离性:进程间内存是隔离的,这提供了较好的容错性,但增加了数据处理的开销。线程共享内存,虽然提高了效率,但在处理隔离性和错误恢复方面可能更复杂。
- 并发模型:MapReduce 的并发模型基于进程,每个任务运行在独立的JVM(Java虚拟机)进程中,这简化了编程模型,但可能增加了开销。Spark 通过在同一JVM进程中并行运行多个任务(线程并行)来减少这种开销,使得数据处理更快,特别是在需要频繁读写数据的应用中。
- 性能:Spark通常比MapReduce更快,原因是它的内存计算能力和更高效的任务调度。MapReduce适用于大规模的数据批处理,而Spark则支持快速的迭代计算,更适合于需要复杂数据处理的任务。
Spark执行模型
在Spark中,执行计算的基本单位是Task,而Task在运行时实际上是作为线程在Executor进程中执行的。这是Spark执行模型的一个核心组成部分,与MapReduce的执行模型形成鲜明对比,后者在Hadoop中通常是以进程为单位进行任务的分配和执行。下面是Spark中关于Executor和Task的一些关键点:
Executor
- Executor定义:在Spark中,Executor是一个运行在集群节点上的进程,负责执行Spark作业中的任务。每个Executor进程可以同时运行多个任务。
- 内存和资源共享:由于Executor是以进程形式存在的,它为运行在其上的任务提供了共享内存和资源。这使得任务之间能够高效地共享数据,降低了数据交换和通信的开销,特别是在执行需要频繁数据交换的操作(如Shuffle)时。
Task
- Task定义:Task是Spark中执行的最小工作单元,每个Task对应于数据集(如RDD)的一个分区,由Executor中的一个线程执行。
- 线程并行:在单个Executor进程内部,多个Task可以并行执行,因为它们是作为线程运行的。这种并行性的级别由Executor分配给它的核心数决定。【下文将详解】
执行模型的含义
- 效率和性能:通过允许在单个Executor进程中并行执行多个Task,Spark能够更有效地利用计算资源,减少任务启动的延迟,提高了数据处理的速度。
- 任务调度和资源管理:Spark的这种执行模型也意味着其任务调度和资源管理机制比基于进程的模型更为复杂。Spark需要在保证执行效率的同时,也要管理好资源分配、任务之间的依赖关系以及错误恢复机制。
宽依赖、窄依赖与流水线
在Spark中,“流水线”优化,也被称为管道化执行,是一种优化技术,它允许在可能的情况下,将多个操作合并到单个阶段中顺序执行,从而减少计算过程中的开销。这种优化主要适用于窄依赖的情况。为了理解这一点,首先需要区分Spark中的两种依赖类型:窄依赖和宽依赖。
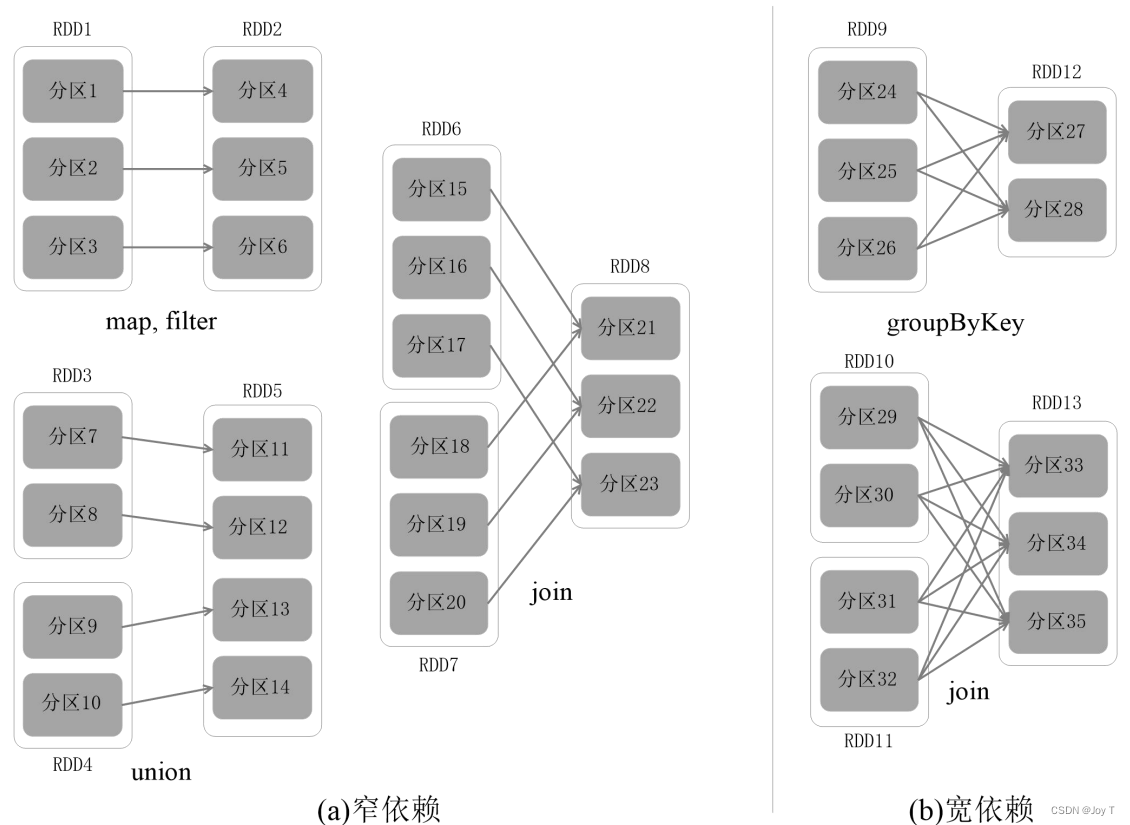
窄依赖
在窄依赖中,每个父分区被一个或少数子分区所依赖,这意味着父RDD的每个分区只需要为一个子RDD的少数分区(通常是一个)提供数据。这种依赖关系允许Spark在不同的转换操作之间实现流水线优化,因为这些操作可以在不进行额外shuffle的情况下连续执行。
流水线优化:在窄依赖的情况下,Spark可以将多个转换操作(如map、filter等)合并成一个任务连续执行,而不需要在每个操作之间写入磁盘或进行网络传输。这类似于在生产线上,一个产品可以从一个加工步骤直接进入下一个步骤,而不需要回到仓库中等待。这种优化减少了I/O开销,提高了执行效率。
宽依赖
在宽依赖中,父RDD的每个分区可能会被多个子分区所依赖,通常在这种依赖关系中,需要对数据进行重新组织(例如,通过shuffle操作),以确保每个子分区可以获取到它需要处理的全部数据。宽依赖通常出现在groupBy、reduceByKey等操作中,这些操作需要将不同分区的数据集中到一起处理。
无法实现流水线优化:宽依赖涉及到的shuffle操作需要将数据从一个阶段的任务输出到另一个阶段的任务输入,这个过程需要写磁盘和网络传输,导致无法像窄依赖那样直接在内存中流水线执行多个操作。每次shuffle操作都可能成为数据处理的瓶颈,因为它涉及到磁盘I/O和网络I/O,显著增加了计算的开销。
理解流水线
理解Spark中的“流水线”优化,可以想象一个装配线,其中产品(数据)在装配线上移动时,可以不间断地经过多个工作站(操作)进行加工。在窄依赖的场景下,数据可以顺畅地流过多个操作,每个操作像装配线上的一个工作站,接连不断地对数据进行加工。但在宽依赖的场景下,数据需要经过一个重组的过程(类似于中断了装配线,将产品重新分配到不同的线上),这个过程会打断流水线的连续性,造成额外的开销。
通过这种方式,Spark尽可能地在内存中处理数据,减少了对磁盘的依赖,提高了整个数据处理流程的效率。
Executor流水线与CPU流水线
前置知识:在Spark中,任务(Task)的资源使用情况既不完全是集中式的,也不是每个Task都有完全独立的资源槽。实际上,它采用的是一种中间态——资源在Executor级别被分配,而在这些Executor内部,多个Task共享这些资源。
在Spark中,流水线执行主要指的是将多个数据处理操作(如map、filter等)在同一个任务(Task)中无缝地串联起来,以减少数据移动和中间存储的开销。这种优化在窄依赖的操作中特别有效,因为这些操作不需要重组(shuffle)数据就能在上下游RDD之间顺畅地传递。
单核Executor中的Task执行
在单核Executor的情况下,由于只有一个CPU核心可用,Executor一次只能执行一个Task。这意味着在任何给定时刻,Executor都在处理单个Task上的操作。这里的“流水线”实际上是指在这个单个Task中,多个数据处理操作可以连续执行,而不是多个Task同时执行。
每个Task将会按顺序执行,完成一个Task的所有操作后,才会开始执行下一个Task。
流水线的实现机制
在Spark的流水线机制中,数据在内存中从一个操作传递到下一个操作,这些操作都是在单个Task的上下文中顺序执行的。例如,一个map操作后面紧跟一个filter操作,Spark会尽量将这两个操作合并在同一个Task中顺序执行,而无需将map操作的结果写入磁盘或进行网络传输等待filter操作处理。
与CPU流水线的对比
CPU流水线依赖于CPU内部的多个物理单元同时工作,即使是单核CPU也拥有多个这样的单元,每个单元负责不同的处理阶段。因此,在某一时刻,第一个指令可能在执行阶段,而第二个指令已经在取指或译码阶段了。这样的并行处理大大提高了CPU的执行效率。
而单核Executor无法同时开始执行另一个Task。这意味着,不同Task之间的操作无法像CPU流水线中的指令那样重叠执行。
- 物理并行性:单核CPU的流水线通过利用CPU内部的多个物理单元(用于不同指令执行阶段)来实现并行性,即使在单核心情况下也能同时处理多个指令的不同部分。这种并行性是建立在硬件层面上的。
- 软件并行性限制:相比之下,Spark中的单核Executor受限于单个CPU核心,无法同时执行多个Task。其并行性主要是通过多个Executor(可能在不同的物理或虚拟机上)来实现的,而不是在单个Executor内部。
想想就行啦,现在很少有单核Executor啦!
Spark的设计和广泛应用确实受益于现代硬件发展的几个关键趋势,特别是内存容量的增加和多核处理器的普及。这些硬件进步为Spark提供了理想的运行环境,使其能够有效地处理大规模数据集,并充分利用内存计算来提高性能。
多核Executor的优势
- 并行处理能力:多核Executor可以同时执行多个任务(Task),这显著提高了数据处理的并行度和整体作业的执行效率。
- 内存利用率:Spark利用了内存计算的优势,能够在处理大数据集时减少对磁盘I/O的依赖。多核Executor能够更高效地使用其分配的内存资源,加速数据处理和分析任务。
- 资源配置的灵活性:在集群管理器(如Apache YARN、Mesos或Spark自身的Standalone模式)的帮助下,Spark允许灵活地配置Executor的数量、每个Executor的内核数以及内存大小,以适应不同的数据处理需求和优化性能。
企业环境中的应用
在实际的企业环境中,使用多核Executor已经成为常态,主要原因包括:
- 硬件资源的可用性:随着多核处理器成为标准配置,企业拥有的计算资源普遍支持并行处理。
- 性能要求:大数据应用和实时数据处理需求的增加,驱动企业优化资源配置以实现更快的数据处理速度。
- 成本效率:合理配置的多核Executor可以提高资源的利用率,从而降低运行成本。
多核CPU是怎么执行指令的呢?每个核还是用流水线吗?
是的,多核CPU中的每个核心仍然使用流水线技术来执行指令,以提高效率和处理速度。多核CPU的设计允许同时并行处理多个计算任务,而每个核心内部的流水线则进一步提高了单个核心处理指令的能力。这样,多核CPU结合了两个层面的并行处理能力:核心间的并行性和核心内的流水线并行性。
多核CPU的工作原理
- 核心间并行:多核CPU有多个处理核心,每个核心可以独立执行不同的任务或线程。这意味着,如果一个程序能够被分解为多个可以并行执行的部分,那么多核CPU可以显著提高这个程序的执行速度。
- 核心内流水线:尽管每个核心可以独立执行任务,每个核心内部还是采用了流水线技术来执行单个任务中的指令。流水线技术将指令执行过程分解为多个阶段,如取指、译码、执行、访存和写回等。通过在不同阶段并行处理多个指令,每个核心的处理速度得到了提升。
流水线的效益
流水线技术能够显著提高处理速度的原因在于其能够减少处理器空闲的时间。在没有流水线的情况下,CPU在执行一个指令的不同阶段时,其他部分可能处于空闲状态。而流水线允许后续指令在前一个指令完成其第一阶段后立即进入处理器开始其第一阶段的处理,这样就几乎可以同时在不同阶段处理多个指令。
多核与流水线的结合
多核处理器与流水线技术的结合,为现代计算任务提供了极高的处理能力。多核提供了在不同核心上并行执行多个任务的能力,而每个核心内的流水线则确保了每个核心在执行单个任务时能够高效利用其内部资源。这种设计使得多核处理器非常适合执行多线程程序和并行计算密集型应用。
在实际应用中,如何充分利用多核处理器的能力取决于软件的并行化设计,包括操作系统的调度策略、程序的多线程设计以及应用的并行算法等。正确的并行化设计和优化可以显著提高程序在多核处理器上的执行效率。
作者总结(一)
所以Executor和CPU的流水线还是不一样,前者是串行流水线,后者是并行流水线。而在多核情况下,Executor是并行流水线并且线程之间相互独立,CPU是并行中的并行流水线,第一个并行是多核之间相互独立,第二个并行是CPU流水线带来的不是完全意义上的逻辑并行。
Executor的流水线(在Spark中)
- 串行流水线:在单核Executor的情况下,虽然任务(Task)内部可以实现操作的流水线执行(例如,将多个map或filter操作顺序执行而不需要中间存储),但由于只有一个核心,这些任务必须串行执行。因此,这种情况下的流水线是串行的,一个任务完成所有操作后,另一个任务才能开始。
- 并行流水线:在多核Executor的情况下,可以同时执行多个任务,每个任务在各自的线程上运行,线程之间相互独立。这提供了一种并行流水线,每个核心(或线程)可以独立地执行自己的任务流水线。
CPU的流水线
- 并行中的并行:CPU的流水线技术允许在单个核心内部并行处理多个指令的不同阶段。当结合多核处理器时,这种并行性被扩展到了更高的层面,每个核心可以独立处理不同的任务或线程,而每个核心内部的流水线则进一步提高了其处理指令的效率。因此,多核CPU实现了两层面的并行:多核之间的并行处理不同的任务,以及核心内部通过流水线技术并行处理指令的不同阶段。
作者总结(二)
其实说到底还是一个Stage中的Task比指令复杂的多,导致其不能让Executor中的集中式共享资源按照每一个SubTask去分配物理资源,这应该是最根本的原因。
复杂性的来源
-
任务的粒度:Spark中的一个Task通常包含对数据集的一系列操作,这些操作可能涉及复杂的数据处理逻辑,如数据转换、聚合或连接等。相比之下,CPU的一个指令通常执行非常具体和原子化的操作,如加法、乘法或者数据移动等。Task的高级抽象和操作的复杂性导致其无法像指令那样被精细地拆分和流水线处理。
-
资源共享与调度:在Spark中,尽管多个Task可以在多核Executor上并行执行,但这些Task共享Executor的资源(如内存和CPU)。资源的共享和调度需要在软件层面上进行管理,以确保每个Task的执行效率和整体作业的性能。而CPU内部的资源(如寄存器、算术逻辑单元等)在设计时就考虑了流水线并行,每个指令的不同阶段可以利用这些硬件资源进行高效执行。
根本原因
-
执行单位的不同:Spark的执行单位是Task,它在逻辑上代表了对数据集一部分的一系列复杂操作。而CPU的执行单位是指令,它是硬件层面的原子操作。这种在执行单位粒度上的根本差异导致了并行处理和资源分配策略的不同。
-
并行处理机制:Spark的并行处理侧重于在软件层面上通过多线程和多核心处理器实现数据处理任务的并行。而CPU的并行处理机制是通过硬件设计,特别是流水线和多核技术,来在指令级别实现并行。
-
资源分配与管理:在Spark中,对物理资源的分配和管理是由任务调度器和执行器在软件层面上完成的,考虑到任务的复杂性和资源共享的需求。CPU则通过硬件级别的设计来优化资源的利用,实现高效的流水线并行处理。

