
- 1朴素贝叶斯(Naive Bayes)
- 2《近匠》专访启明星辰安全研究中心副总监侯浩俊——物联网安全攻防的“线上幽灵”...
- 3关于微信小程序自定义导航栏时,如何获取手机状态栏和导航栏高度_微信小程序获取状态栏高度
- 4vue3前端实现全屏显示,元素垂直填满页面_vue3 全屏
- 5Docker 部署_glpi docker
- 6Postman 传递当前时间戳最佳实践_postman timestamp
- 7SpringCloud商城day02 分布式文件存储解决方案-2021-09-29_spring cloud 分布式文件储存
- 8(6)成本计算题:挣值分析--信息系统项目管理师考试系列_软件项目管理挣值法例题
- 9Docker 部署 stirling-pdf 组件_stirling-tools/stirling-pdf[1]
- 10Android 第二十二章 CalendarView_android calendarview
Redis内存满的最佳解决方案_redis磁盘空间不足
赞
踩

前言
Redis是一款高性能的内存数据库,被广泛应用于缓存、消息队列、计数器等场景。然而,由于Redis是基于内存的数据库,当数据量过大或者配置不合理时,就有可能导致Redis的内存满。内存满的情况会严重影响Redis的性能和可用性,甚至导致系统崩溃。因此,了解Redis内存满的原因以及如何应对是非常重要的。本文将介绍Redis内存满的几种原因,并提供相应的解决方案,帮助读者有效应对Redis内存满的问题。
造成内存满原因
Redis造成内存满的几种原因包括:
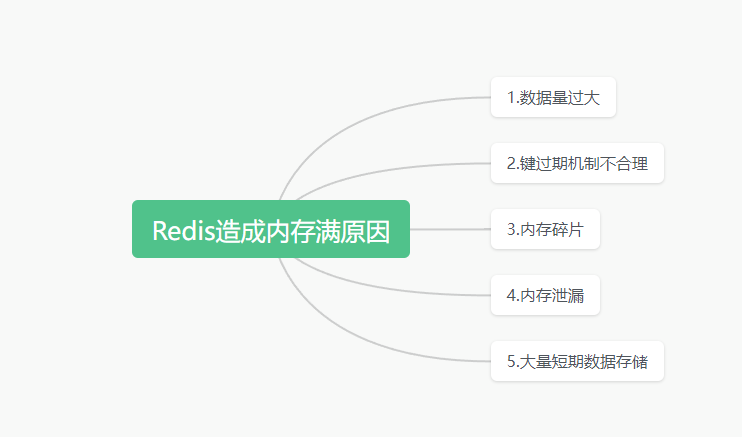
数据量过大
如果Redis中存储的数据量超过了可用内存的限制,就会导致内存满。这可能是因为数据量的增长超过了内存的增长速度,或者是由于Redis实例的内存配置不足。
键过期机制不合理
如果Redis中的键没有设置过期时间,或者过期时间设置不合理,就会导致过期的键一直占用内存。这会导致内存不断增长,最终导致内存满。
内存碎片
Redis使用内存分配器来管理内存,当频繁进行键的删除和修改操作时,可能会产生内存碎片。内存碎片会导致内存无法被充分利用,最终导致内存满。
内存泄漏
如果Redis中存在内存泄漏的情况,即某些键值对占用的内存没有被正确释放,就会导致内存不断增长,最终导致内存满。
大量短期数据存储
如果Redis中存储了大量的短期数据,而这些数据没有被及时清理,就会导致内存不断增长,最终导致内存满。
为了避免Redis内存满的问题,需要合理配置Redis的内存大小,设置合理的键过期时间,定期清理过期的键值对,避免内存碎片和内存泄漏问题,并根据实际需求进行监控和调优。
解决方案
当Redis的内存满了时,可以采取以下几种方式来处理:
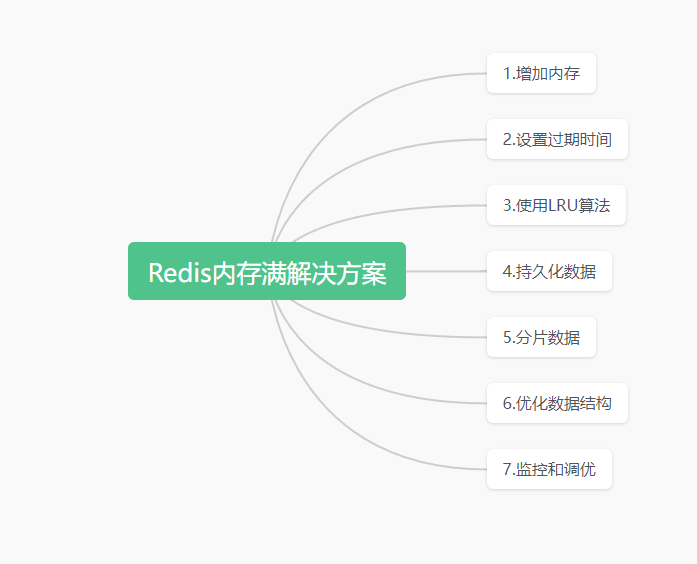
1.增加内存
可以通过增加Redis实例的内存大小来解决内存满的问题。可以通过修改Redis配置文件中的maxmemory参数来设置Redis实例的最大内存限制。如果Redis实例运行在集群模式下,可以增加集群中的节点数量来增加总体的内存容量。
配置Redis能使用的最大的内存大小方式
1.1.通过在Redis配置文件redis.conf中设置maxmemory参数来限制Redis能使用的最大内存。例如,限制Redis最大使用100MB内存:
# Redis最大内存限制
>CONFIG SET maxmemory 100mb
# 达到限制时淘汰策略
>CONFIG SET maxmemory-policy allkeys-lru
- 1
- 2
- 3
- 4
- 5
1.2.通过Redis命令动态设置:
config set maxmemory 100mb
- 1
2.设置过期时间
可以通过设置键的过期时间来释放一些不再使用的键值对。可以使用EXPIRE命令或者在插入键值对时设置过期时间。
2.1.在set命令中指定过期时间(秒):
set key value EX 10
- 1
这个key将在10秒后自动删除。
2.2.在set命令中指定过期时间(毫秒):
set key value PX 100000
- 1
这个key将在100000毫秒(100秒)后自动删除。
2.3.使用expire命令为已有key设置过期时间(秒):
expire key 20
- 1
为已存在的key设置20秒过期时间。
2.4.使用pexpire命令为已有key设置过期时间(毫秒):
pexpire key 120000
- 1
为已存在的key设置120000毫秒(120秒)过期时间。
2.5.使用expireat命令直接设置key的过期时间:
expireat key 1655097600
- 1
将key的过期时间设置为Unix时间戳1655097600。
3.使用LRU算法
可以通过设置Redis的maxmemory-policy参数为allkeys-lru来启用LRU(最近最少使用)算法。当内存满时,Redis会自动删除最近最少使用的键值对来腾出空间。
# 达到限制时淘汰策略
>CONFIG SET maxmemory-policy allkeys-lru
- 1
- 2
3.1 什么是LRU算法
LRU(Least Recently Used) 是一种常用的页面置换算法, 主要用于缓存系统中淘汰对象的策略。
其核心思想是: 最近最少使用的对象会被优先淘汰。
即当缓存已满时, 会优先删除最久未被访问的对象, 以腾出空间缓存热点数据。
其基本思路是:
3.1.1 按对象的访问时间来排序, 最近访问的对象排在前面, 最久未访问的排在后面。
3.1.2 当需要淘汰对象时, 选择列表尾部的对象(最久未访问的)进行淘汰。
3.1.3 当一个对象被访问时, 将其从原位置删除, 并重新插入列表头部。
这样随着访问过程的演变, 列表头部始终为热点数据, 列表尾部始终为最冷的数据。
3.2 用java 实现一个LRU算法
import java.util.HashMap; import java.util.Map; class LRUCache { private int capacity; private Map<Integer, Node> cache; private Node head; private Node tail; class Node { int key; int value; Node prev; Node next; Node(int key, int value) { this.key = key; this.value = value; } } public LRUCache(int capacity) { this.capacity = capacity; cache = new HashMap<>(); head = new Node(0, 0); tail = new Node(0, 0); head.next = tail; tail.prev = head; } public int get(int key) { if (cache.containsKey(key)) { Node node = cache.get(key); removeNode(node); addToHead(node); return node.value; } return -1; } public void put(int key, int value) { if (cache.containsKey(key)) { Node node = cache.get(key); node.value = value; removeNode(node); addToHead(node); } else { if (cache.size() == capacity) { cache.remove(tail.prev.key); removeNode(tail.prev); } Node newNode = new Node(key, value); cache.put(key, newNode); addToHead(newNode); } } private void removeNode(Node node) { node.prev.next = node.next; node.next.prev = node.prev; } private void addToHead(Node node) { node.next = head.next; node.next.prev = node; node.prev = head; head.next = node; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
4.持久化数据
可以使用Redis的持久化机制将数据写入磁盘,以释放内存空间。Redis支持两种持久化方式:RDB(Redis Database)和AOF(Append-Only File)。可以根据实际需求选择适合的持久化方式。
5.分片数据
可以将数据分片存储在多个Redis实例中,以减少单个实例的内存压力。可以使用Redis的分片技术,如Redis Cluster或者使用第三方的分片方案。
6.优化数据结构
可以通过优化数据结构来减少内存占用。例如,使用Redis的数据结构中最适合的类型,避免使用不必要的数据结构。
7.监控和调优
可以使用Redis的监控工具来监控内存使用情况,并根据监控结果进行调优。可以使用Redis的命令行工具或者第三方的监控工具。
需要根据具体情况选择适合的解决方案,并根据实际需求进行调整和优化。
总结
Redis内存满是一个常见的问题,但我们可以采取一些措施来应对这个问题。首先,合理配置Redis的内存大小,确保它能够容纳所需的数据量。其次,设置合理的键过期时间,及时清理过期的键值对,避免内存不断增长。此外,定期监控Redis的内存使用情况,及时发现并解决内存泄漏、内存碎片等问题。最后,根据实际需求进行性能调优,例如使用持久化机制、使用压缩算法等,以减少内存占用。通过以上措施,我们可以有效应对Redis内存满的问题,保证系统的稳定性和性能。
写在最后
感谢您的支持和鼓励!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

