
- 1航空电子之ARINC 429总线_arinc429
- 2【文件IO】遍历指定目录下的所有文件_linux遍历文件夹所有文件内容
- 3vue数据代理
- 4动态规划入门(数字三角形模型)
- 5数据预处理_data.duplicated()
- 6Android 大姨妈、经期日历,美柚经期效果_android 自定义经期 日历
- 7智能家居革命开启,欧瑞博定义下一个十年大发展_欧瑞博 发展历程
- 8《Vue.js 3企业级应用开发实战》拆箱和导读_企业级管理后台开发实战pdf
- 9【Unity】UI界面鼠标悬停时显示多行文本(用GUI.Box实现+使用Unity富文本)_unity显示多行
- 100 职业介绍-IC芯片设计工程师(FPGA工程师进阶版)_fpga软件工程师属于芯片设计吗
SpringBoot集成Flink-CDC,实现对数据库数据的监听_flink cdc springboot
赞
踩
一、什么是 CDC ?
CDC 是 Change Data Capture(变更数据获取) 的简称。 核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、 更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
二、Flink-CDC 是什么?
CDC Connectors for Apache Flink是一组用于Apache Flink 的源连接器,使用变更数据捕获 (CDC) 从不同数据库获取变更。用于 Apache Flink 的 CDC 连接器将 Debezium 集成为捕获数据更改的引擎。所以它可以充分发挥 Debezium 的能力。
大概意思就是,Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、 PostgreSQL等数据库直接读取全量数据和增量变更数据的 source 组件。
Flink-CDC 开源地址: Apache/Flink-CDC
Flink-CDC 中文文档:Apache Flink CDC | Apache Flink CDC
三、SpringBoot 整合 Flink-CDC
3.1、如何集成到SpringBoot中?
Flink 作业通常独立于一般的服务之外,专门编写代码,用 Flink 命令行工具来运行和停止。将Flink 作业集成到 Spring Boot 应用中并不常见,而且一般也不建议这样做,因为Flink作业一般运行在大数据环境中。
然而,在特殊需求下,我们可以做一些改变使 Flink 应用适应 Spring Boot 环境,比如在你的场景中使用 Flink CDC 进行 数据变更捕获。将 Flink 作业以本地项目的方式启动,集成在 Spring Boot应用中,可以使用到 Spring 的便利性。
- CommandLineRunner
- ApplicationRunner
3.2、集成举例
1、CommandLineRunner
- @SpringBootApplication
- public class MyApp {
-
- public static void main(String[] args) {
- SpringApplication.run(MyApp.class, args);
- }
-
- @Bean
- public CommandLineRunner commandLineRunner(ApplicationContext ctx) {
- return args -> {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
- .hostname("localhost")
- .port(3306)
- .username("flinkuser")
- .password("flinkpw")
- .databaseList("mydb") // monitor all tables under "mydb" database
- .tableList("mydb.table1", "mydb.table2") // monitor only "table1" and "table2" under "mydb" database
- .deserializer(new StringDebeziumDeserializationSchema()) // converts SourceRecord to String
- .build();
-
- DataStreamSource<String> mysqlSource = env.addSource(sourceFunction);
-
- // formulate processing logic here, e.g., printing to standard output
- mysqlSource.print();
-
- // execute the Flink job within the Spring Boot application
- env.execute("Flink CDC");
- };
- }
- }

2、ApplicationRunner
- @SpringBootApplication
- public class FlinkCDCApplication implements ApplicationRunner {
-
- public static void main(String[] args) {
- SpringApplication.run(FlinkCDCApplication.class, args);
- }
-
- @Override
- public void run(ApplicationArguments args) throws Exception {
- final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- // Configure your Flink job here
- DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
- .hostname("localhost")
- .port(3306)
- .username("flinkuser")
- .password("flinkpw")
- .databaseList("mydb")
- // set other source options ...
- .deserializer(new StringDebeziumDeserializationSchema()) // Converts SourceRecord to String
- .build();
-
- DataStream<String> cdcStream = env.addSource(sourceFunction);
-
- // Implement your processing logic here
- // For example:
- cdcStream.print();
-
- // Start the Flink job within the Spring Boot application
- env.execute("Flink CDC with Spring Boot");
- }
- }
这次用例采用 ApplicationRunner,不过要改变一下,让 Flink CDC 作为 Bean 来实现。
四、功能实现
4.1、功能逻辑

总体来讲,不太想把 Flink CDC单独拉出来,更想让它依托于一个服务上,彻底当成一个组件。
其中在生产者中,我们将要进行实现:
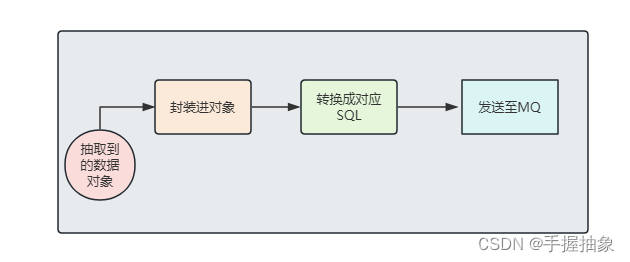
4.2、所需环境
- MySQL 5.7 +:确保源数据库已经开启 Binlog 日志功能,并且设置 Row 格式
- Spring Boot 2.7.6:还是不要轻易使用 3.0 以上为好,有好多jar没有适配
- RabbitMQ:适配即可
- Flink CDC:特别注意版本
4.3、Flink CDC POM依赖
- <flink.version>1.13.6</flink.version>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_2.12</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.12</artifactId>
- <version>${flink.version}</version>
- </dependency>
- <!--mysql -cdc-->
- <dependency>
- <groupId>com.ververica</groupId>
- <artifactId>flink-connector-mysql-cdc</artifactId>
- <version>2.0.0</version>
- </dependency>
-
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <version>1.18.10</version>
- </dependency>
- <dependency>
- <groupId>cn.hutool</groupId>
- <artifactId>hutool-all</artifactId>
- <version>5.8.5</version>
- </dependency>
- <dependency>
- <groupId>org.apache.commons</groupId>
- <artifactId>commons-lang3</artifactId>
- <version>3.10</version>
- </dependency>
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>fastjson</artifactId>
- <version>2.0.42</version>
- </dependency>
上面是一些Flink CDC必须的依赖,当然如果需要实现其他数据库,可以替换其他数据库的CDC jar。怎么安排jar包的位置和其余需要的jar,这个可自行调整。
4.4、代码展示
核心类
- MysqlEventListener:配置类
- MysqlDeserialization:MySQL消息读取自定义序列化
- DataChangeInfo:封装的变更对象
- DataChangeSink:继承一个Flink提供的抽象类,用于定义数据的输出或“下沉”逻辑,sink 是Flink处理流的最后阶段,通常用于将数据写入外部系统,如数据库、文件系统、消息队列等
(1)通过 ApplicationRunner 接入 SpringBoot
- @Component
- public class MysqlEventListener implements ApplicationRunner {
-
- private final DataChangeSink dataChangeSink;
-
- public MysqlEventListener(DataChangeSink dataChangeSink) {
- this.dataChangeSink = dataChangeSink;
- }
-
- @Override
- public void run(ApplicationArguments args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- DebeziumSourceFunction<DataChangeInfo> dataChangeInfoMySqlSource = buildDataChangeSourceRemote();
- DataStream<DataChangeInfo> streamSource = env
- .addSource(dataChangeInfoMySqlSource, "mysql-source")
- .setParallelism(1);
- streamSource.addSink(dataChangeSink);
- env.execute("mysql-stream-cdc");
- }
-
- private DebeziumSourceFunction<DataChangeInfo> buildDataChangeSourceLocal() {
- return MySqlSource.<DataChangeInfo>builder()
- .hostname("127.0.0.1")
- .port(3306)
- .username("root")
- .password("0507")
- .databaseList("flink-cdc-producer")
- .tableList("flink-cdc-producer.producer_content", "flink-cdc-producer.name_content")
- /*
- * initial初始化快照,即全量导入后增量导入(检测更新数据写入)
- * latest:只进行增量导入(不读取历史变化)
- * timestamp:指定时间戳进行数据导入(大于等于指定时间错读取数据)
- */
- .startupOptions(StartupOptions.latest())
- .deserializer(new MysqlDeserialization())
- .serverTimeZone("GMT+8")
- .build();
- }
- }
(2)自定义 MySQL 消息读取序列化
- public class MysqlDeserialization implements DebeziumDeserializationSchema<DataChangeInfo> {
-
- public static final String TS_MS = "ts_ms";
- public static final String BIN_FILE = "file";
- public static final String POS = "pos";
- public static final String CREATE = "CREATE";
- public static final String BEFORE = "before";
- public static final String AFTER = "after";
- public static final String SOURCE = "source";
- public static final String UPDATE = "UPDATE";
-
- /**
- * 反序列化数据,转为变更JSON对象
- */
- @Override
- public void deserialize(SourceRecord sourceRecord, Collector<DataChangeInfo> collector) {
- String topic = sourceRecord.topic();
- String[] fields = topic.split("\\.");
- String database = fields[1];
- String tableName = fields[2];
- Struct struct = (Struct) sourceRecord.value();
- final Struct source = struct.getStruct(SOURCE);
- DataChangeInfo dataChangeInfo = new DataChangeInfo();
- dataChangeInfo.setBeforeData(getJsonObject(struct, BEFORE).toJSONString());
- dataChangeInfo.setAfterData(getJsonObject(struct, AFTER).toJSONString());
- //5.获取操作类型 CREATE UPDATE DELETE
- Envelope.Operation operation = Envelope.operationFor(sourceRecord);
- // String type = operation.toString().toUpperCase();
- // int eventType = type.equals(CREATE) ? 1 : UPDATE.equals(type) ? 2 : 3;
- dataChangeInfo.setEventType(operation.name());
- dataChangeInfo.setFileName(Optional.ofNullable(source.get(BIN_FILE)).map(Object::toString).orElse(""));
- dataChangeInfo.setFilePos(Optional.ofNullable(source.get(POS)).map(x -> Integer.parseInt(x.toString())).orElse(0));
- dataChangeInfo.setDatabase(database);
- dataChangeInfo.setTableName(tableName);
- dataChangeInfo.setChangeTime(Optional.ofNullable(struct.get(TS_MS)).map(x -> Long.parseLong(x.toString())).orElseGet(System::currentTimeMillis));
- //7.输出数据
- collector.collect(dataChangeInfo);
- }
-
- private Struct getStruct(Struct value, String fieldElement) {
- return value.getStruct(fieldElement);
- }
-
- /**
- * 从元数据获取出变更之前或之后的数据
- */
- private JSONObject getJsonObject(Struct value, String fieldElement) {
- Struct element = value.getStruct(fieldElement);
- JSONObject jsonObject = new JSONObject();
- if (element != null) {
- Schema afterSchema = element.schema();
- List<Field> fieldList = afterSchema.fields();
- for (Field field : fieldList) {
- Object afterValue = element.get(field);
- jsonObject.put(field.name(), afterValue);
- }
- }
- return jsonObject;
- }
-
-
- @Override
- public TypeInformation<DataChangeInfo> getProducedType() {
- return TypeInformation.of(DataChangeInfo.class);
- }
- }
(3)封装的变更对象
- @Data
- public class DataChangeInfo implements Serializable {
-
- /**
- * 变更前数据
- */
- private String beforeData;
- /**
- * 变更后数据
- */
- private String afterData;
- /**
- * 变更类型 1新增 2修改 3删除
- */
- private String eventType;
- /**
- * binlog文件名
- */
- private String fileName;
- /**
- * binlog当前读取点位
- */
- private Integer filePos;
- /**
- * 数据库名
- */
- private String database;
- /**
- * 表名
- */
- private String tableName;
- /**
- * 变更时间
- */
- private Long changeTime;
-
- }
这里的 beforeData 、afterData直接存储 Struct 不好吗,还得费劲去来回转?
我曾尝试过使用 Struct 存放在对象中,但是无法进行序列化。具体原因可以网上搜索,或者自己尝试一下。
(4)定义 Flink 的 Sink
- @Component
- @Slf4j
- public class DataChangeSink extends RichSinkFunction<DataChangeInfo> {
-
- transient RabbitTemplate rabbitTemplate;
-
- transient ConfirmService confirmService;
-
- transient TableDataConvertService tableDataConvertService;
-
- @Override
- public void invoke(DataChangeInfo value, Context context) {
- log.info("收到变更原始数据:{}", value);
- //转换后发送到对应的MQ
- if (MIGRATION_TABLE_CACHE.containsKey(value.getTableName())) {
- String routingKey = MIGRATION_TABLE_CACHE.get(value.getTableName());
- //可根据需要自行进行confirmService的设计
- rabbitTemplate.setReturnsCallback(confirmService);
- rabbitTemplate.setConfirmCallback(confirmService);
- rabbitTemplate.convertAndSend(EXCHANGE_NAME, routingKey, tableDataConvertService.convertSqlByDataChangeInfo(value));
- }
- }
-
- /**
- * 在启动SpringBoot项目是加载了Spring容器,其他地方可以使用@Autowired获取Spring容器中的类;但是Flink启动的项目中,
- * 默认启动了多线程执行相关代码,导致在其他线程无法获取Spring容器,只有在Spring所在的线程才能使用@Autowired,
- * 故在Flink自定义的Sink的open()方法中初始化Spring容器
- */
- @Override
- public void open(Configuration parameters) throws Exception {
- super.open(parameters);
- this.rabbitTemplate = ApplicationContextUtil.getBean(RabbitTemplate.class);
- this.confirmService = ApplicationContextUtil.getBean(ConfirmService.class);
- this.tableDataConvertService = ApplicationContextUtil.getBean(TableDataConvertService.class);
- }
- }
(5)数据转换类接口和实现类
- public interface TableDataConvertService {
-
- String convertSqlByDataChangeInfo(DataChangeInfo dataChangeInfo);
- }
- @Service
- public class TableDataConvertServiceImpl implements TableDataConvertService {
-
- @Autowired
- Map<String, SqlGeneratorService> sqlGeneratorServiceMap;
-
- @Override
- public String convertSqlByDataChangeInfo(DataChangeInfo dataChangeInfo) {
- SqlGeneratorService sqlGeneratorService = sqlGeneratorServiceMap.get(dataChangeInfo.getEventType());
- return sqlGeneratorService.generatorSql(dataChangeInfo);
- }
- }
因为在 dataChangeInfo 中我们有封装对象的类型(CREATE、DELETE、UPDATE),所以我希望通过不同类来进行不同的工作。于是就有了下面的类结构:
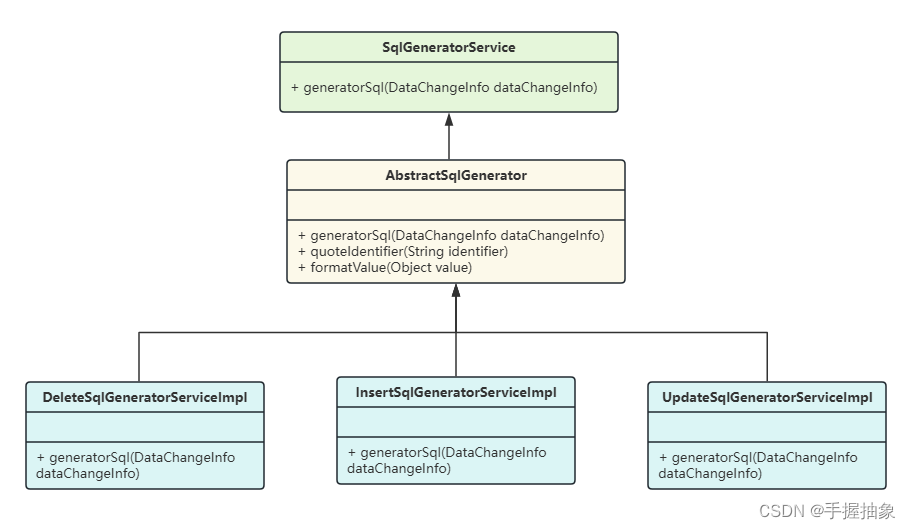
根据 dataChangeInfo 的类型去生成对应的 SqlGeneratorServiceImpl。
这是策略模式还是模板方法?
策略模式(Strategy Pattern)允许在运行时选择算法的行为。在策略模式中,定义了一系列的算法(策略),并将每一个算法封装起来,使它们可以相互替换。策略模式允许算法独立于使用它的客户端进行变化。
InsertSqlGeneratorServiceImpl、UpdateSqlGeneratorServiceImpl 和 DeleteSqlGeneratorServiceImpl 各自实现了 SqlGeneratorService 接口,这确实表明了一种策略。每一个实现类表示一个特定的SQL生成策略,并且可以相互替换,只要它们遵守同一个接口。
模板方法模式(Template Method Pattern),则侧重于在抽象类中定义算法的框架,让子类实现算法的某些步骤而不改变算法的结构。AbstractSqlGenerator 作为抽象类的存在是为了被继承,但如果它不含有模板方法(即没有定义算法骨架的方法),那它就不符合模板方法模式。
在实际应用中,一个设计可能同时结合了多个设计模式,或者在某些情况下,一种设计模式的实现可能看起来与另一种模式类似。在这种情况下,若 AbstractSqlGenerator 提供了更多的共享代码或默认实现表现出框架角色,那么它可能更接近模板方法。而如果 AbstractSqlGenerator 仅仅作为一种接口实现方式,且策略之间可以相互替换,那么这确实更符合策略模式。
值得注意的是,在 TableDataConvertServiceImpl 中,我们注入了一个 Map<String, SqlGeneratorService> sqlGeneratorServiceMap,通过它来进行具体实现类的获取。那么他是个什么东西呢?作用是什么呢?为什么可以通过它来获取呢?
@Resource、@Autowired 标注作用于 Map 类型时,如果 Map 的 key 为 String 类型,则 Spring 会将容器中所有类型符合 Map 的 value 对应的类型的 Bean 增加进来,用 Bean 的 id 或 name 作为 Map 的 key。
那么可以看到下面第六步,在进行DeleteSqlGeneratorServiceImpl装配的时候进行指定了名字@Service("DELETE"),方便通过dataChangeInfo获取。
(6)转换类部分代码
- public interface SqlGeneratorService {
-
- String generatorSql(DataChangeInfo dataChangeInfo);
- }
-
-
-
- public abstract class AbstractSqlGenerator implements SqlGeneratorService {
- @Override
- public String generatorSql(DataChangeInfo dataChangeInfo) {
- return null;
- }
-
- public String quoteIdentifier(String identifier) {
- // 对字段名进行转义处理,这里简化为对其加反引号
- // 实际应该处理数据库标识符的特殊字符
- return "`" + identifier + "`";
- }
- }
- @Service("DELETE")
- @Slf4j
- public class DeleteSqlGeneratorServiceImpl extends AbstractSqlGenerator {
-
- @Override
- public String generatorSql(DataChangeInfo dataChangeInfo) {
- String beforeData = dataChangeInfo.getBeforeData();
- Map<String, Object> beforeDataMap = JSONObjectUtils.JsonToMap(beforeData);
- StringBuilder wherePart = new StringBuilder();
- for (String key : beforeDataMap.keySet()) {
- Object beforeValue = beforeDataMap.get(key);
- if ("create_time".equals(key)){
- SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- beforeValue = dateFormat.format(beforeValue);
- }
- if (wherePart.length() > 0) {
- // 不是第一个更改的字段,增加逗号分隔
- wherePart.append(", ");
- }
- wherePart.append(quoteIdentifier(key)).append(" = ").append(formatValue(beforeValue));
- }
- log.info("wherePart : {}", wherePart);
- return "DELETE FROM " + dataChangeInfo.getTableName() + " WHERE " + wherePart;
- }
- }
核心代码如上所示,具体实现可自行设计。
五、源码获取
Github:incremental-sync-flink-cdc

