
热门标签
热门文章
- 1已解决(pymysqL连接数据库报错)pymysqL.err.ProgrammingError: (1146,“Table ‘test.students‘ doesn‘t exist“)_raise errorclass(errno, errval) pymysql.err.progra
- 2vue 报错this.$Api.sendEmail is not a function 和TypeError: Cannot set property 'pageCode' of undefined_vue this.$api.不存在
- 3自用的8款AI工具!提升学习/工作/赚钱效率,轻松超过99%的人!
- 4数据结构与算法——归并排序_数据结构归并排序
- 5使用 Xcode 运行 python等脚本语言(perl, ruby)_伊织code
- 6深入理解Elasticsearch的索引映射(mapping)_elasticsearch 类型 映射
- 7三分钟掌握PHP操作数据库_php数据库
- 8远程仓库——GitHub
- 9Hadoop之HBase基本简介_hadoop hbase
- 10[深度学习]yolov8+pyqt5搭建精美界面GUI设计源码实现一_yolo pyqt界面设计代码
当前位置: article > 正文
Hadoop和Hive的关系_hive和hadoop的关系
作者:凡人多烦事01 | 2024-05-03 10:32:10
赞
踩
hive和hadoop的关系
1.Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop最核心的设计就是hdfs和mapreduce,hdfs提供存储,mapreduce用于计算。
2.Hive是Hadoop的延申。hive是一个提供了查询功能的数据仓库核心组件,Hadoop底层的hdfs为hive提供了数据存储,mapreduce为hive提供了分布式运算。
两者的关系:
hdfs上存储着海量的数据,我们要对这些数据进行计算和分析,则需要使用Java编写mapreduce程序来实现,但Java编程门槛较高,且一个mapreduce程序写起来要几十上百行。
Hive可以直接通过sql操作Hadoop,sql简单易写,可读性强,hive将用户提交的sql解析成mapreduce任务供Hadoop直接运行。过程如下图所示:
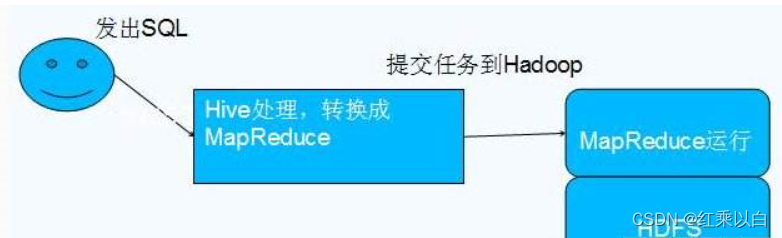
拓展:
1.hive不存储数据,hive只是对数据进行分析计算,以及计算后的结果数据实际存放在分布式系统上,如HDFS;
2.hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑,通过sql编程提交后解释成mapreduce程序,然后将这个MR程序提交给yarn进行调度执行。所以实际进行分布式运算的是mapreduce程序。
3.因为hive需要操作hdfs上的数据集,那么它需要知道数据的切分格式,如行列分隔符,存储类型,是否压缩,数据的存储地址等信息。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/529169
推荐阅读
相关标签

