
- 1Redis Desktop Manager安装和使用_redisdesktopmanager
- 2【Redis系列】Redis安装与使用_redis怎么安装使用
- 3【转】深度学习在生物医学领域的应用 进展述评_深度学习在医疗与生物界的应用概述
- 4编译原理(一)——词法分析
- 5TCP三次握手与四次挥手_lished
- 6【快递100】快递时效接口获取快递预计到达时间_快递100博客
- 7Pytorch简单实现seq2seq+Attention机器人问答_pytorch seq2seq实现问答
- 8【git】idea撤销commit,回到本地更改LocalChange_idea git commit撤回到本地
- 9【开源免费】Vue+SpringBoot打造假日旅社管理系统,初学者入门实战项目
- 10深入探索C语言技术世界:全面学习路径与关键知识点
MySQL表的增删改查(进阶)_mysql增删改查关键字
赞
踩
1.数据库约束
关系型数据库一个重要的功能,需要保证数据的完整性。约束,就是让数据库帮助我们更好的检查数据是否正确。
1.1约束类型
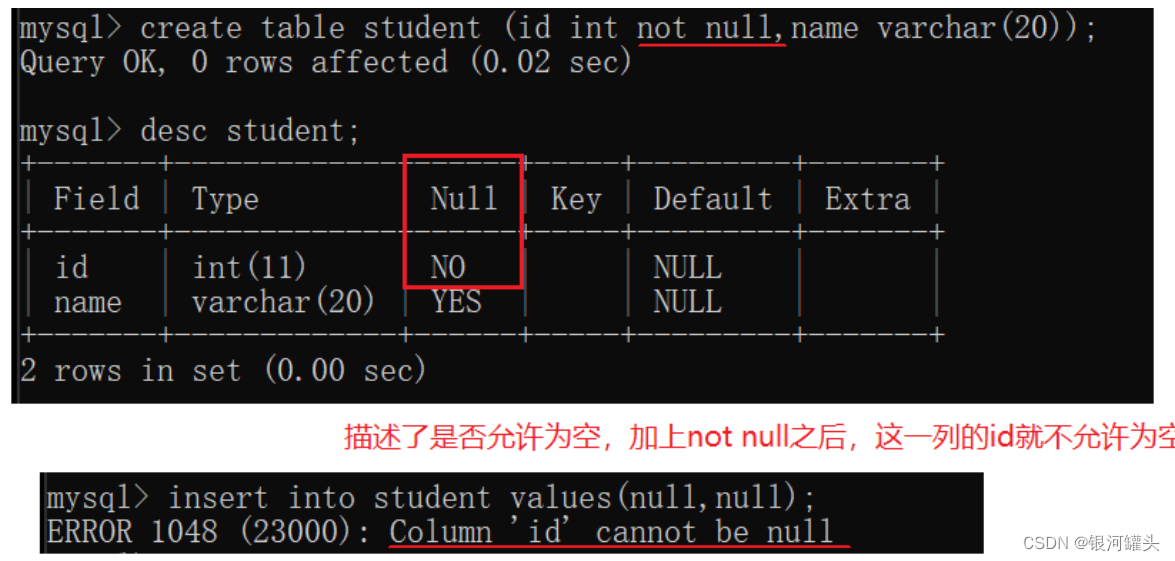
- NOT NULL - 指定某列不能存储NULL值
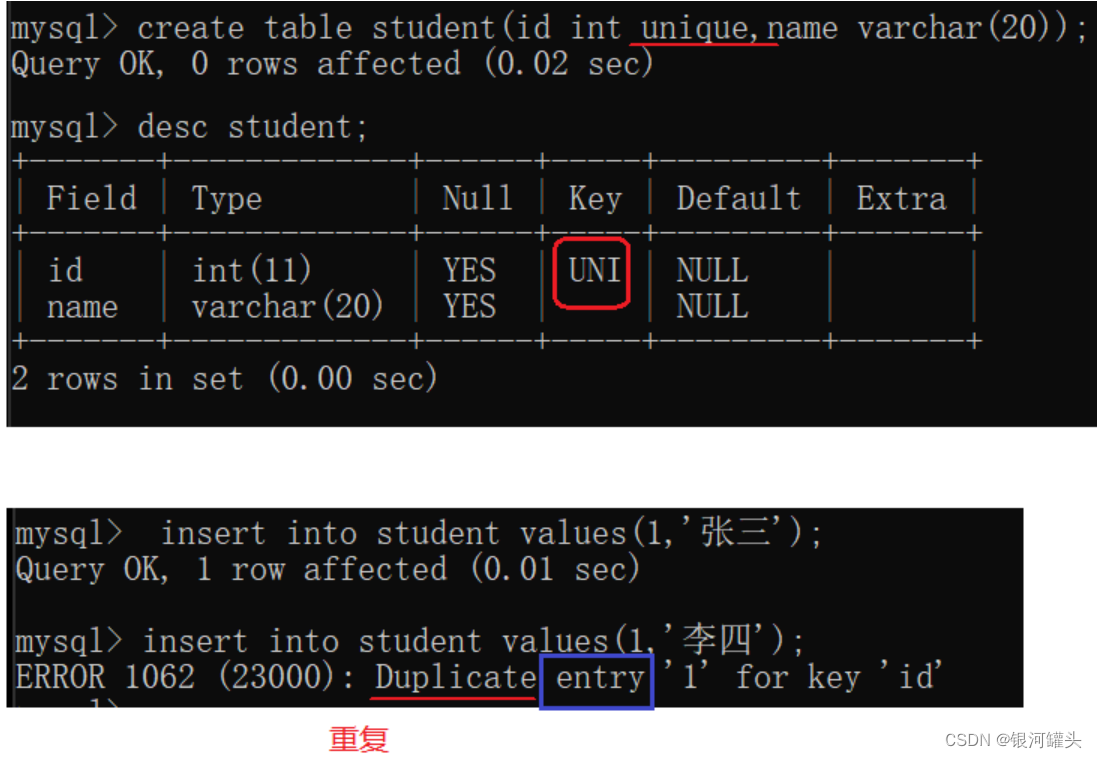
- UNIQUE - 保证某列的每行必须有唯一的值
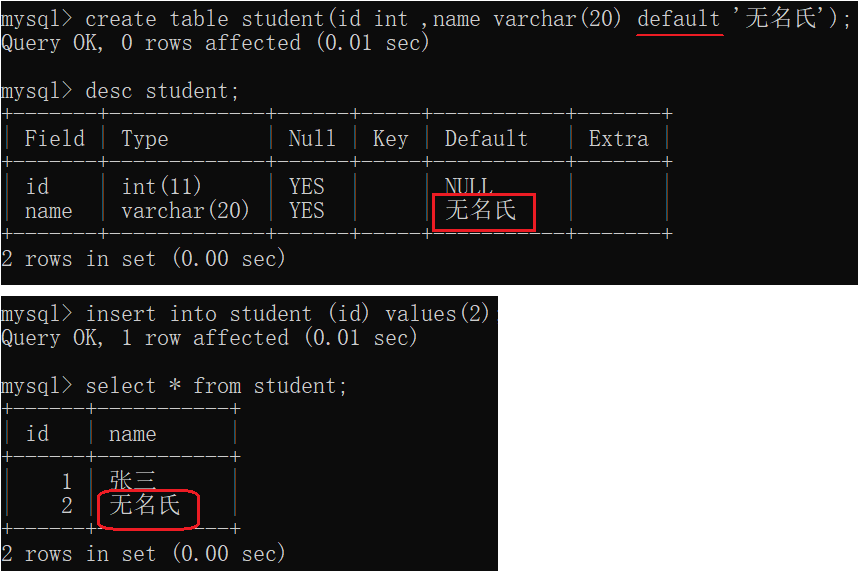
- DEFAULT - 规定没有给列赋值时的默认值
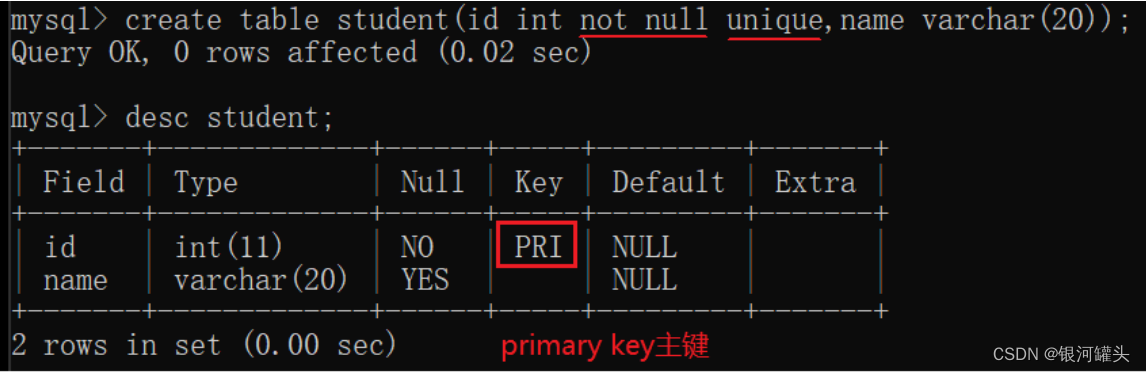
- PRIMARY KEY - NOT NULL和UNIQUE的组合。确保某列(或两个列或多个列的结合)有唯一标识,有助于更容易更快速的找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库而言,对CHECK子句进行分析,但是忽略CHECK子句。
主键是每条记录的身份标识
外键是多个表的关联关系,要求某个记录必须在另一个表里存在
CHECK显式通过条件来描述字段的取值,(MySQL不支持CHECK)
1.2 NULL约束
1.3 UNIQUE:唯一约束
entry 这个之前学过for循环遍历Map用到entrySet
entry的意思有入口,条目。
此处entry的意思是条目
数据库怎么判断当前这条数据是重复的?
先查找再插入。
约束是可以组合一起使用。
1.4 PRIMARY KEY: 主键约束
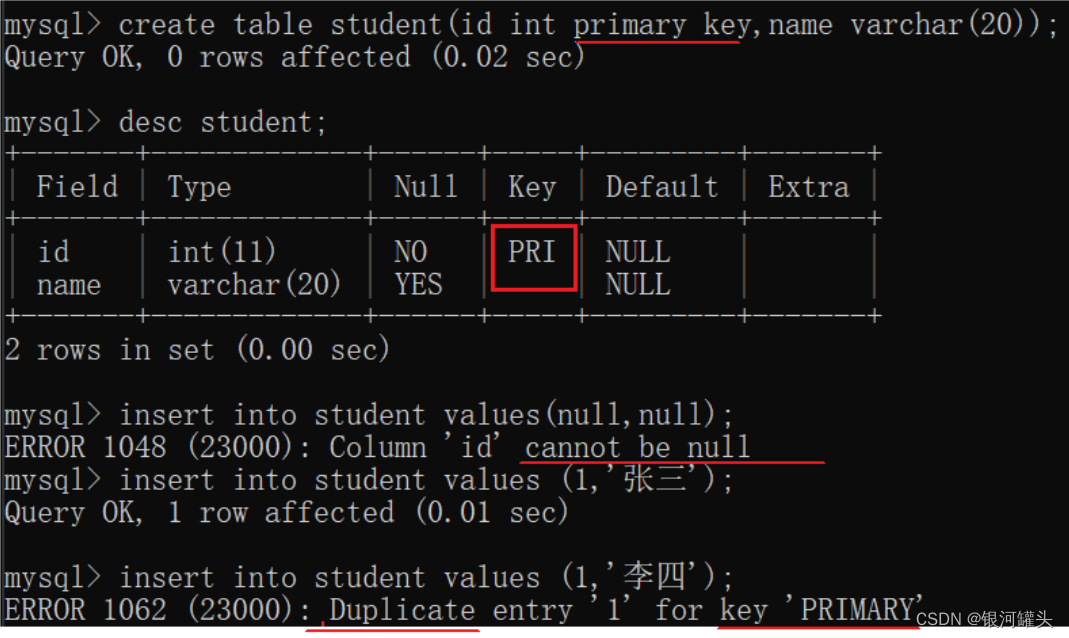
主键也是再插入记录的时候先查询再插入。正因为unique和primary key都有先查询的过程,mysql会默认给unique和primary key这样的列自动添加索引,来提高查询速度。
- 在实际开发中,大部份表都有一个主键,是一个整数表示的id.
- 在mysql中,一个表里只能有一个主键。
- mysql允许把多个列放到一起共同作为一个主键(联合主键)。
- 使用mysql自带的"自增主键"作为主键的值。
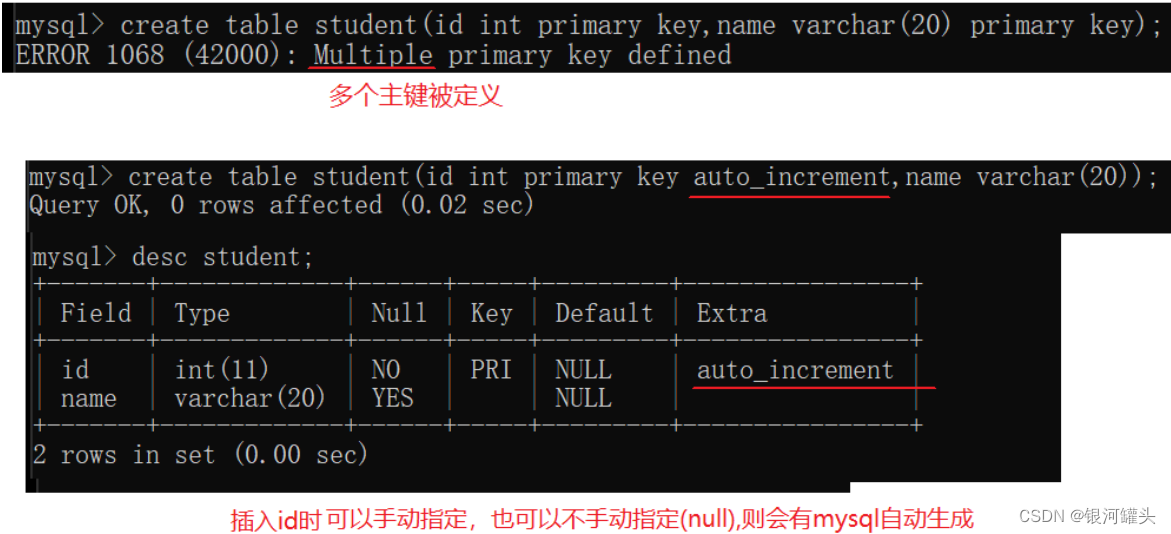
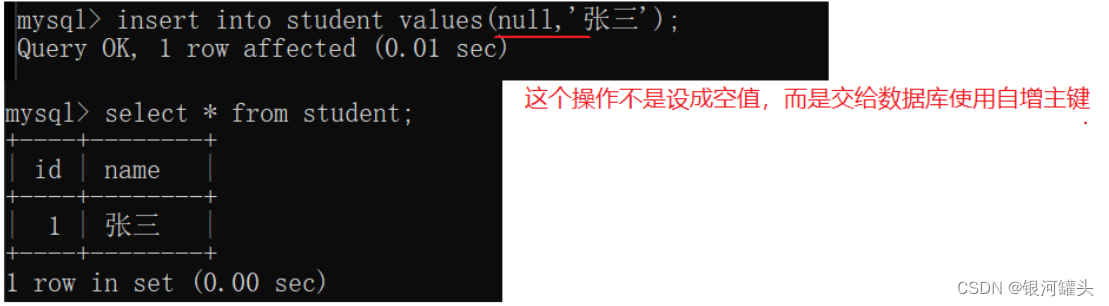
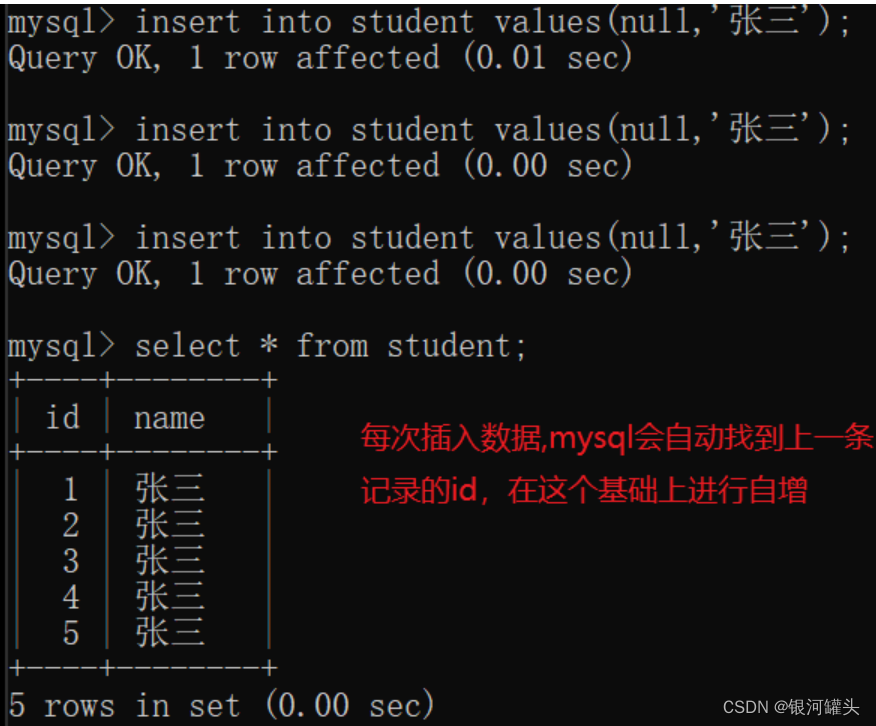
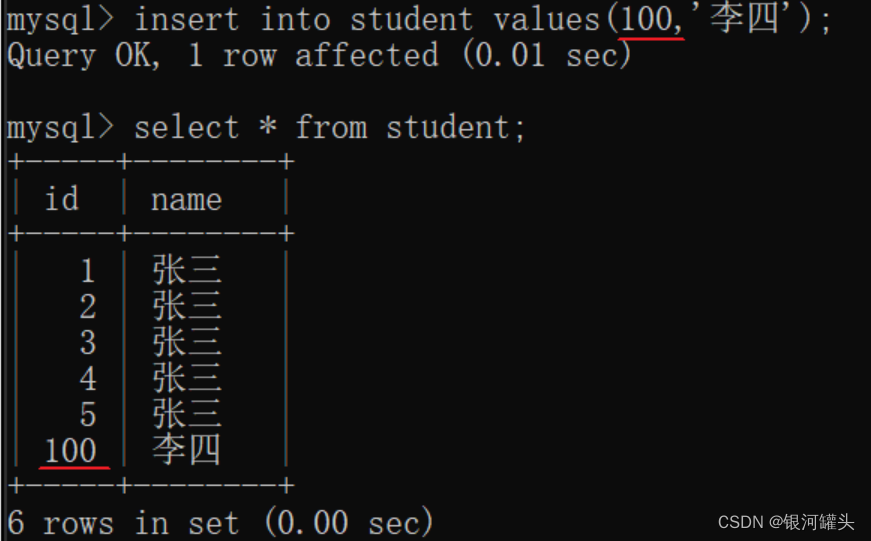
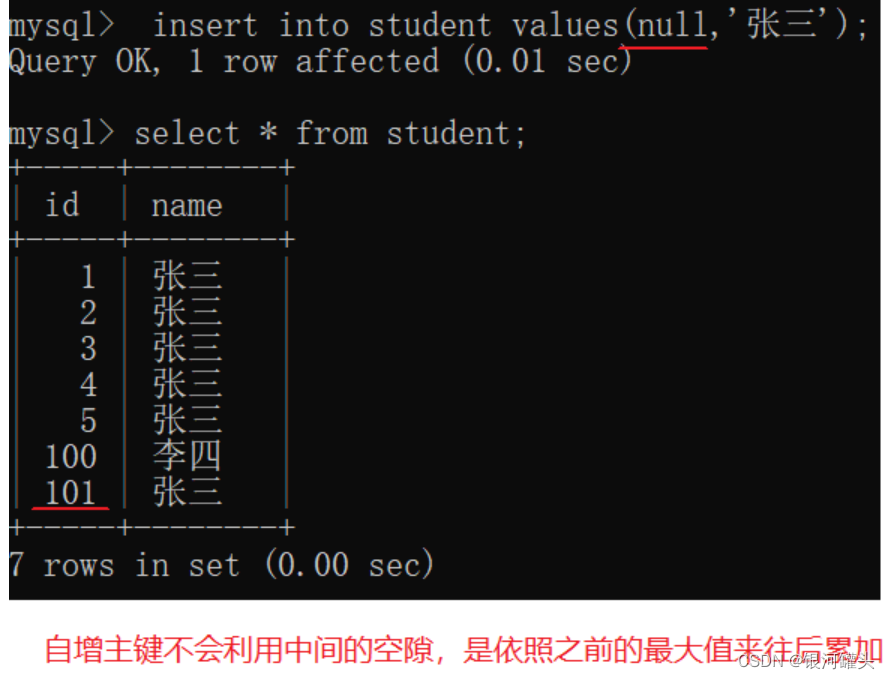
mysql的数据量比较小,所有的数据都在一个mysql服务器上,自增主键可以正常使用。
如果mysql的数据量很大,一台主机放不下,就需要分库分表,使用多个主机来进行存储,让每个服务器只存一部分数据。
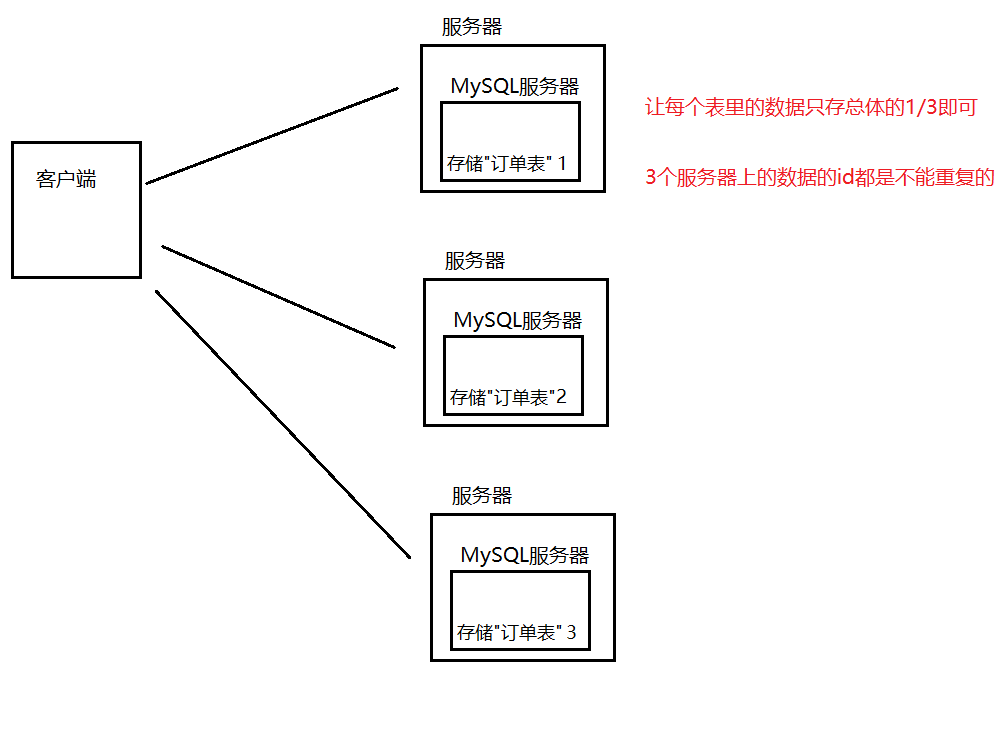
在这个场景下,如果再新插入一个数据,这个数据就会落在3个服务器之一。
新的这个数据的主键id如何分配?能否继续使用mysql自带的自增主键?
-
这个问题涉及到"分布式系统中唯一id生成算法"。
-
实现公式:时间戳+主机编号+随机因子
1.5 DEFAULT:默认值约束
1.6 FOREIGN KEY:外键约束
外键约束,针对两个表之间的约束。

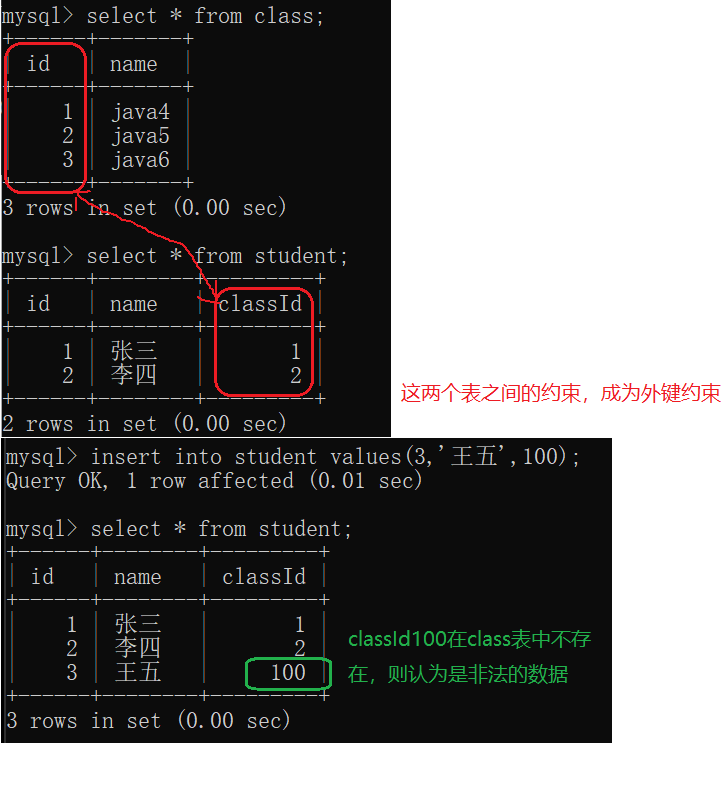
为了让mysql自动的帮我们完成检查工作,引入了"外键"约束。

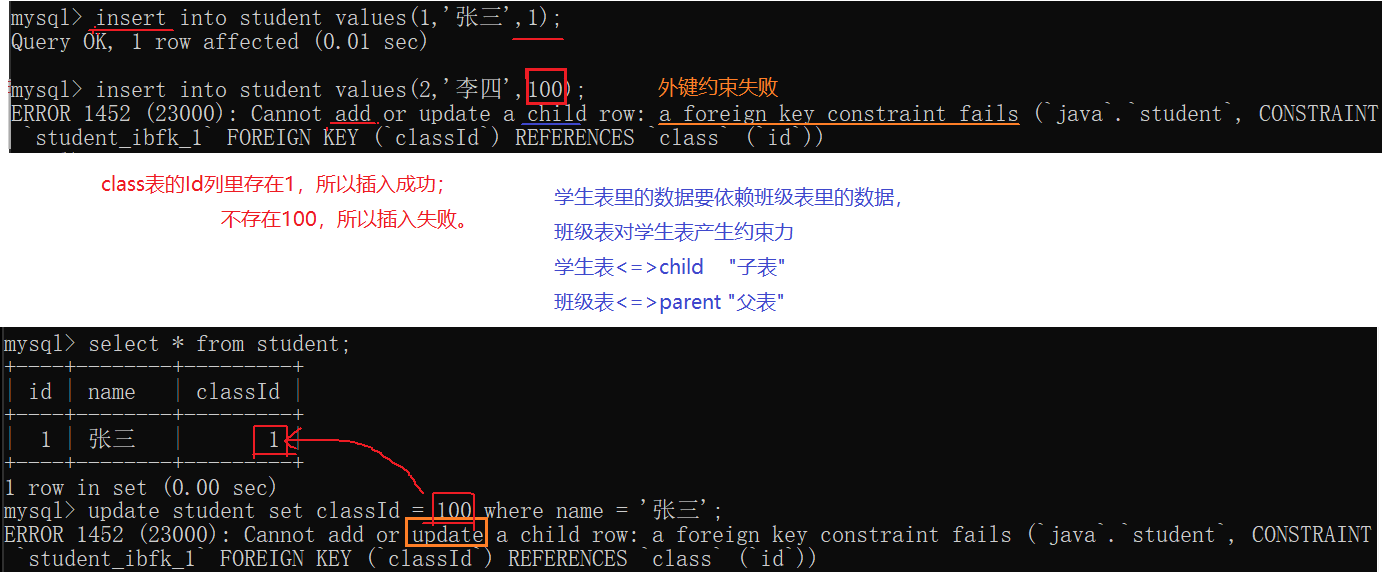
插入和修改操作都外键约束。
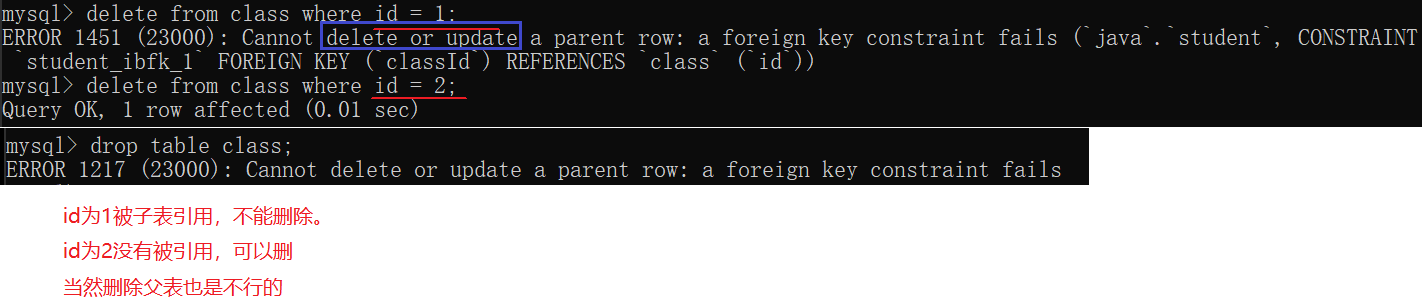
只能先删除子表,再删除父表。
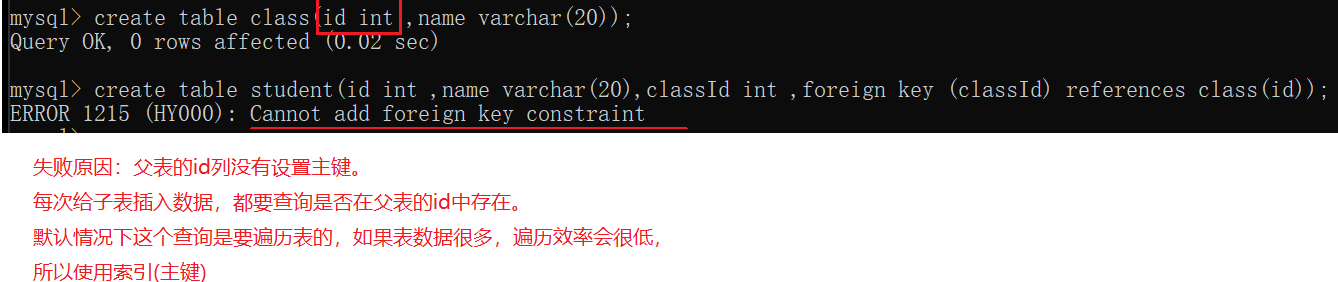
要想创建外键,就要求父表对应的列有primary key 或 unique 约束。primary key和unique都能创建索引。
考虑一个场景:电商。
假设有一个商品表和一个订单表。
goods(id , name , unitprice);
1 T恤 100
2 鞋 200
order(orderId , goodsId , time);
1 1 2022-11-07
订单表里的goodsId必须在goods表里的id里存在。(外键约束)
问:如果想要下架商品T恤,应该怎么操作?
因为外键,所以不能删父表里的T恤这一行的数据。订单表里的下单记录也不能删。
要想对商品下架并不是删除记录。 而是新增一个"是否下架"的属性,下架了设成"是"。这样做可以避免触发"外键约束"的限制。这里是"逻辑删除"。
2. 表的设计
设计表/数据库基本思路:
- 先明确实体;
- 再明确实体之间的关系;
- 根据上述内容,套入相应的"公式"中
实体:需求中的关键名词
关系:没有关系/一对一/一对多/多对多
一对一关系:
比如教务系统中学生和账号:
1.学生和账号在同一个表里
student_account(id , name , username , password);
2.学生和账号在不同表里
student(studentId , name);
account(accountId , username , password , studentId);
或者:
student(studentId, name,accountId);
account(accountId , username , password);
一对多:
一个学生只在一个班级里,而一个班级里有多个学生。
1.student(id , name);
class(classId , name , studentIds);
//在MySQL中不可行,因为MySQL中没有一个像数组这样的类型。
2.student(id , name , classId);
class(classId , name);
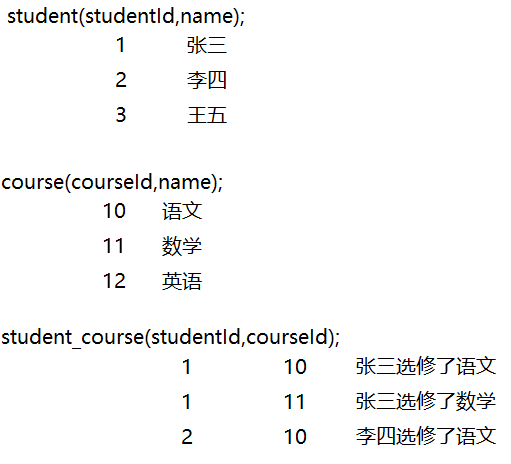
多对多:
一个学生可以选修多门课程,一门课程可以被多名学生选择。
3. 新增
-
把查询的结果插入到另一个表中
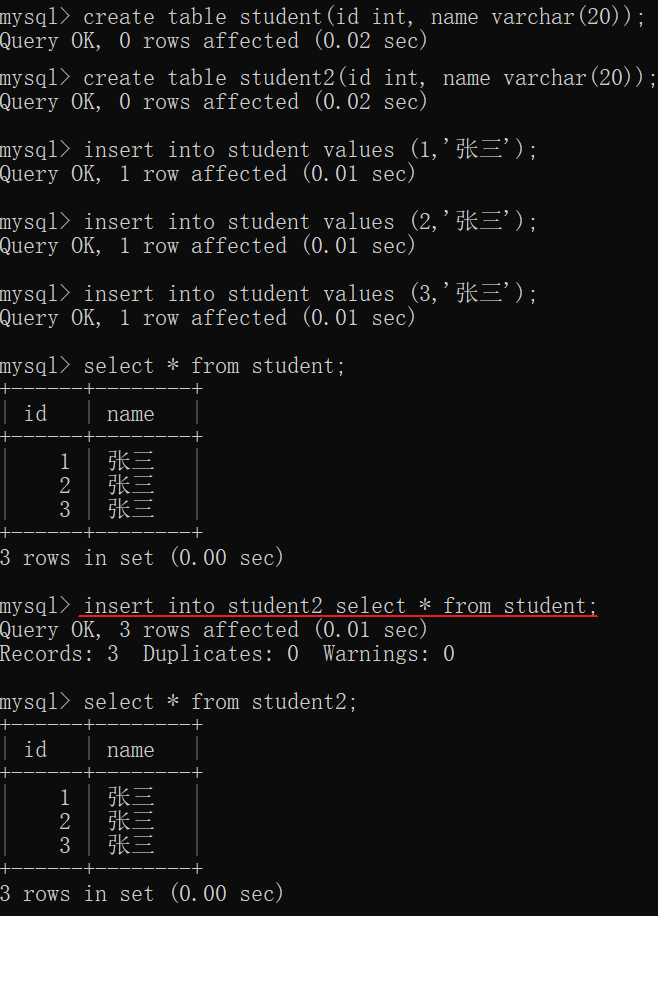
要求student表的列数和列的类型要和student2匹配
4. 查询
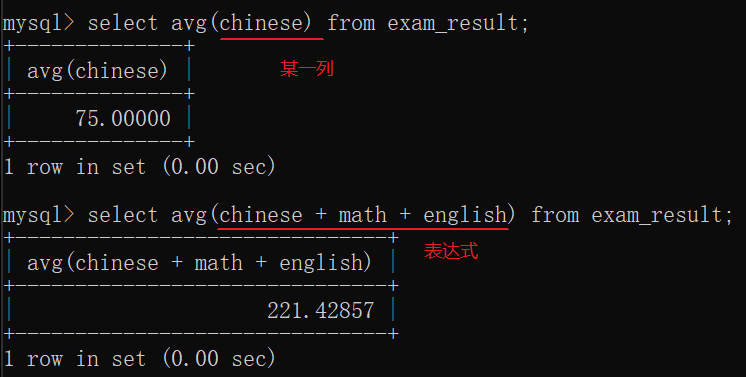
4.1 聚合查询
行和行之间运算
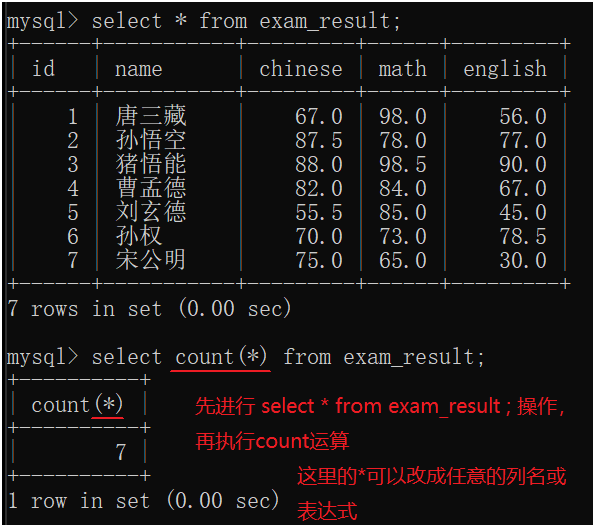
聚合函数(SQL内置的函数):
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
- count
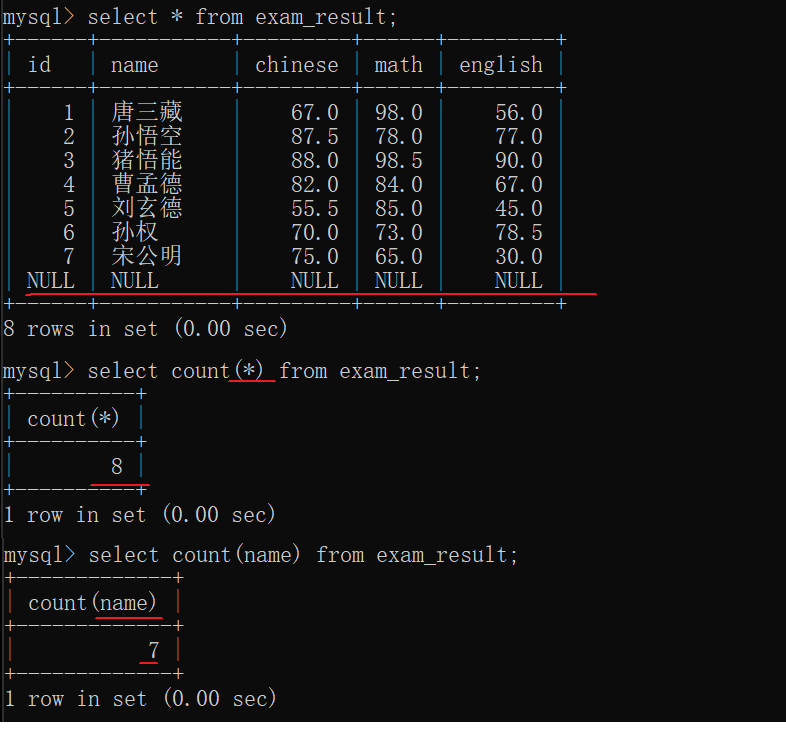

在C和Java中一个函数和()之间是可以有空格的
-
sum
把这一列中所有行进行求和,要求这个列必须是数字。
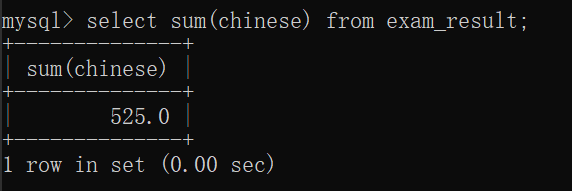
NULL和任何数据运算,结果都是NULL , sum这里是做了一个特殊处理,把为NULL的忽略了。
求和/平均值/最大/最小 这几个操作都是针对数字类型的列进行的。
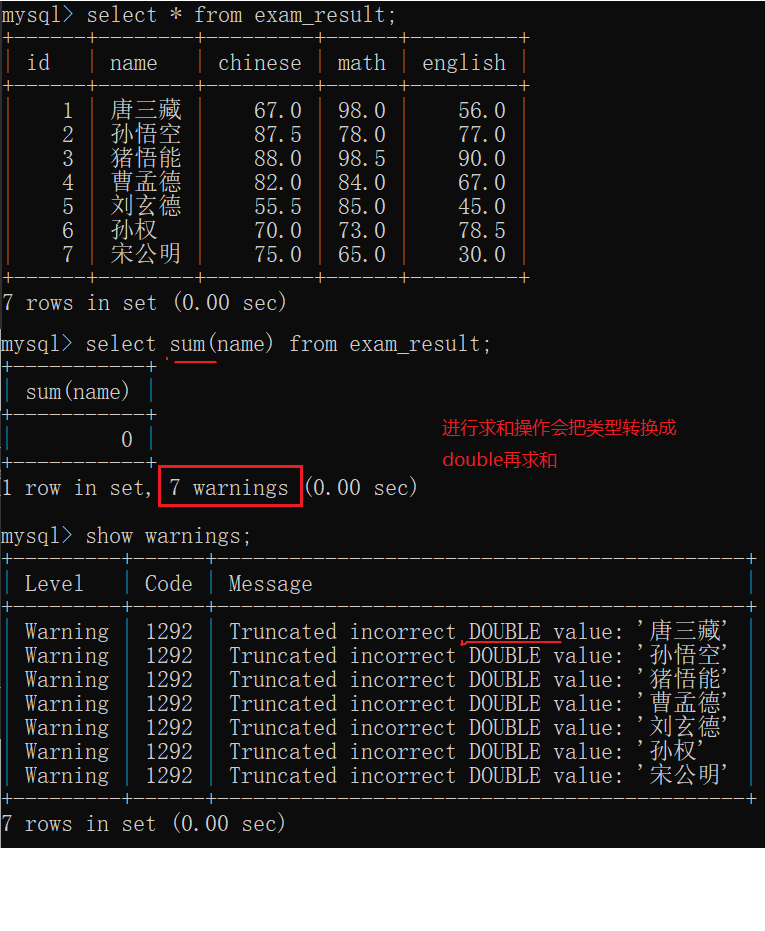
- avg
mysql命名风格
1.驼峰命名(Java/JS): ExamResult examResult
2.蛇形命名(C/C++/Python): exam_result
3.脊柱命名: exam-result
4.匈牙利命名(给比变量名前加个前缀表示类型): iNum sName dScore
- max
- min
select max(chinese) ,min(chinese) from exam_result;
- 1
4.1.2 GROUP BY子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询
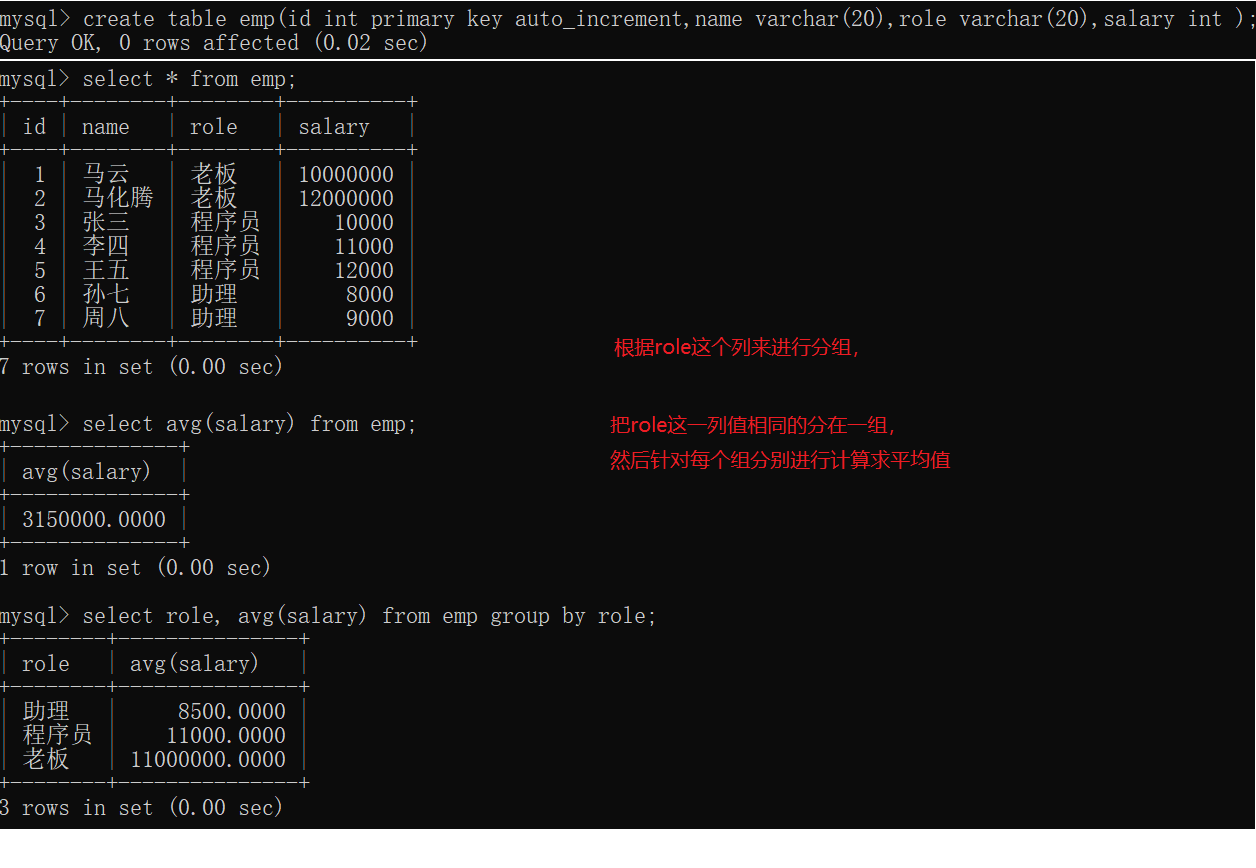
如果是不带聚合函数的普通查询,能否group by?
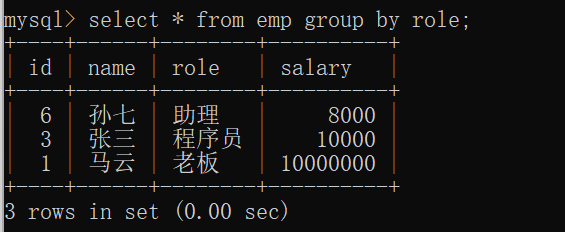
得到每个组的第一条记录。
(mysql如果没有order by 那么结果里顺序是不可预期的)
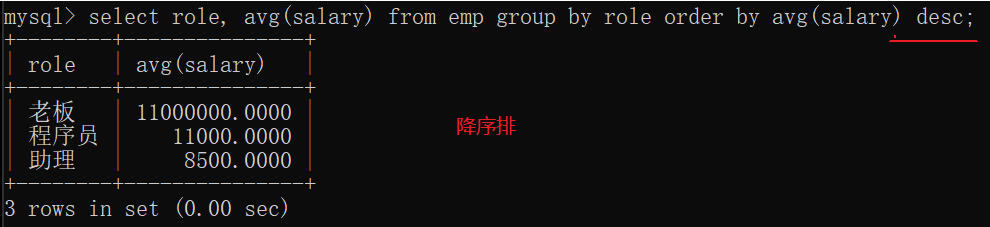
分组查询也可以指定条件
- 分组之前指定条件,先筛选再分组,where
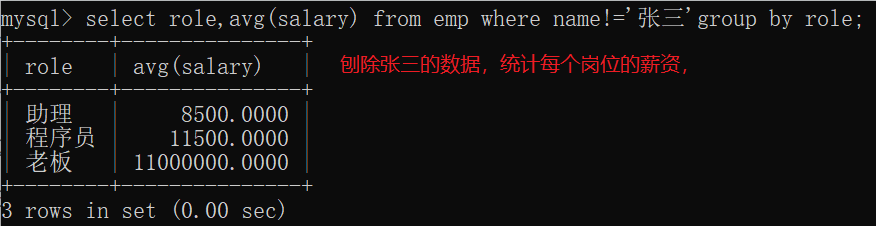
2.分组之前指定条件, 先分组再筛选,having


3.分组之前和之后都指定条件

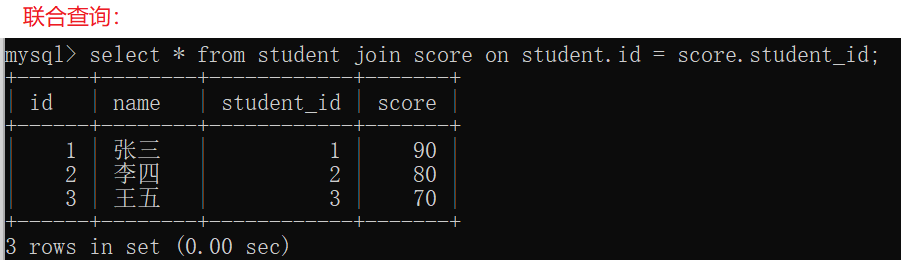
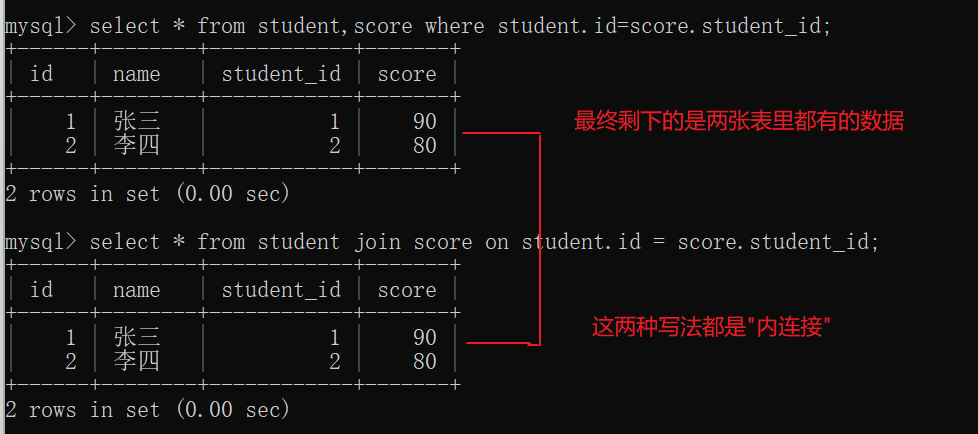
4.2 联合查询
4.2.1内连接
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:
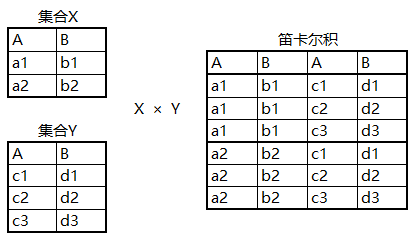
笛卡尔积就是把这两张表放在一起计算
得到一张更大的表,列数是两张表的列数之和,行数是两张表行数之积。
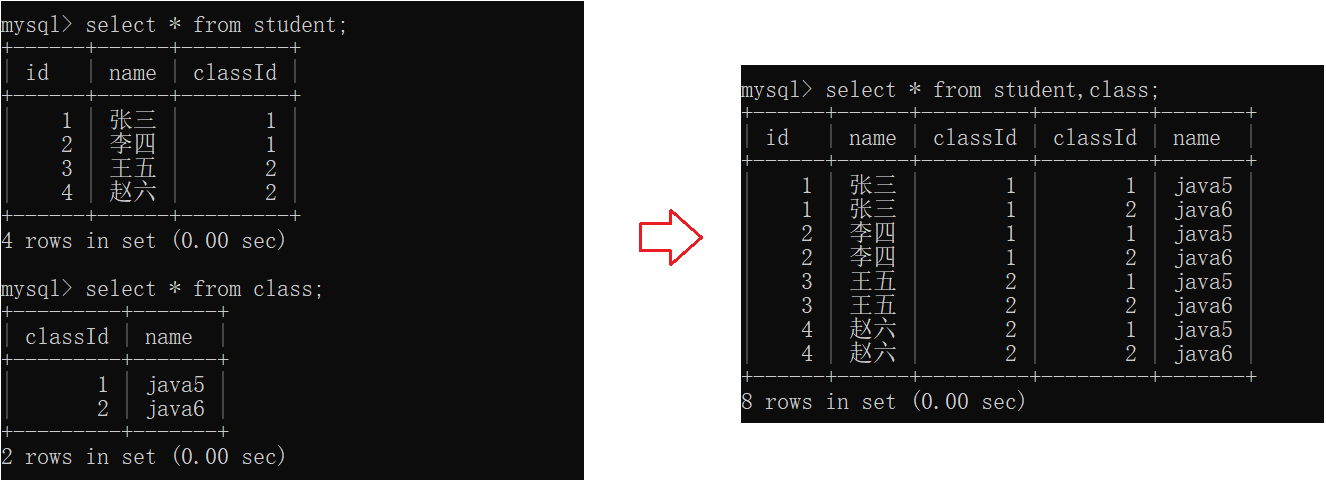
发现结果中很多数据是无效的。需要把无效数据去掉。
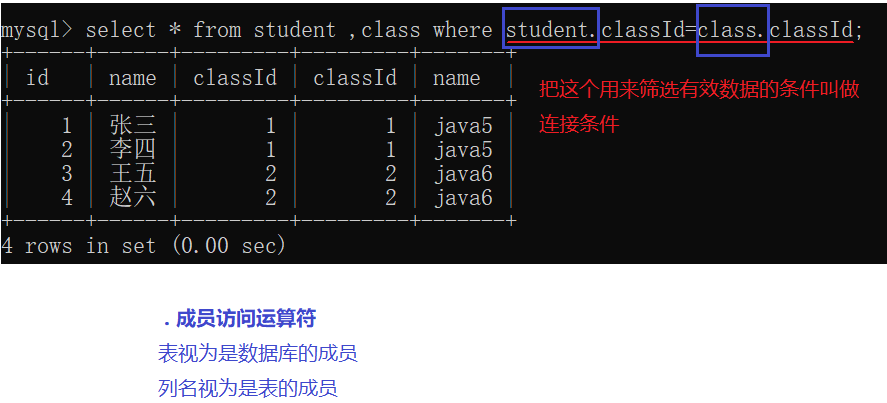

指定列查询去掉多的一个classId列
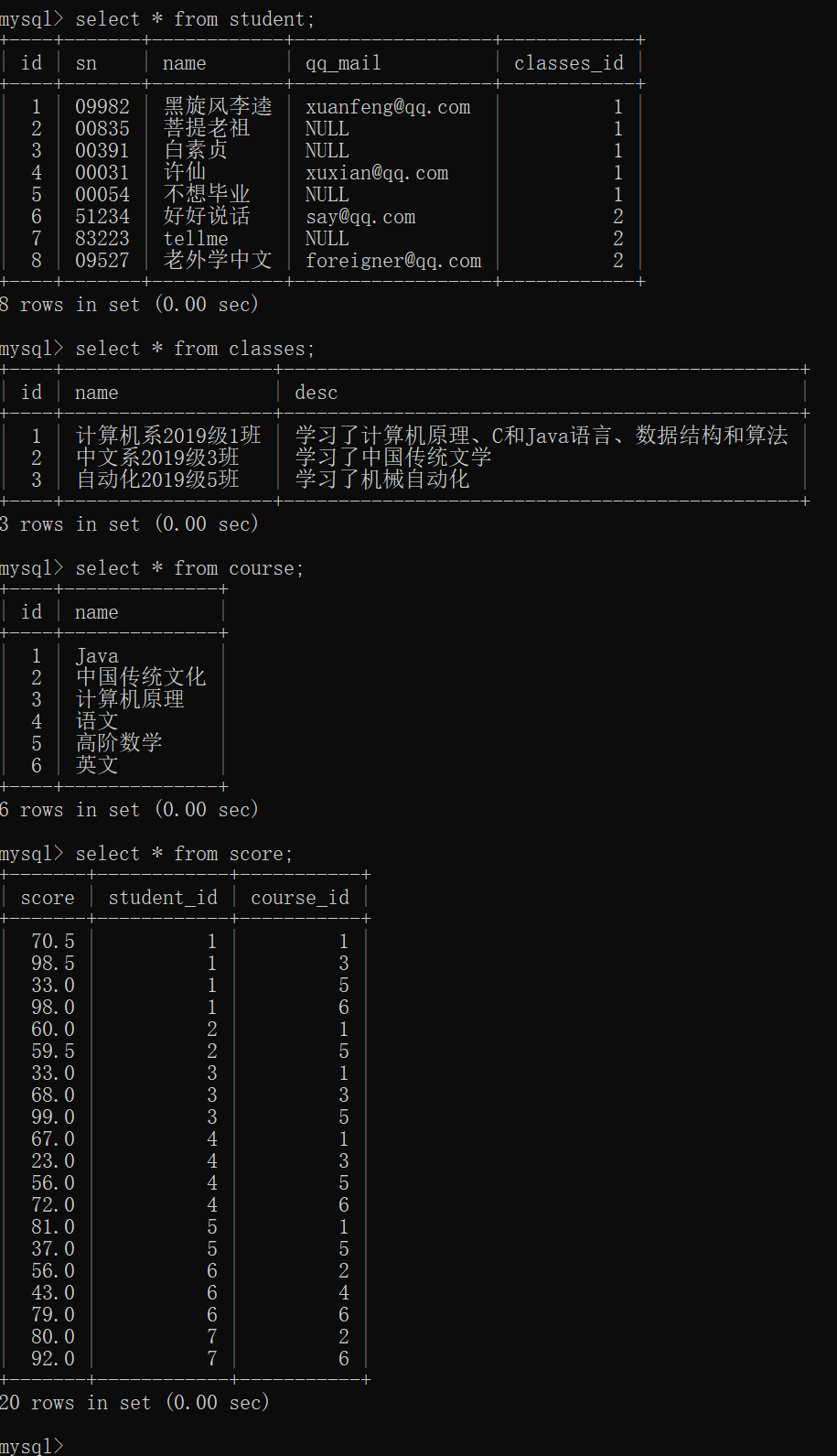
如何进行联合查询?
1.先计算笛卡尔积
select * from student,score;
- 1
2.引入连接条件
select * from student,score where student.id=score.student_id;
- 1
3.再根据需求加入必要的条件
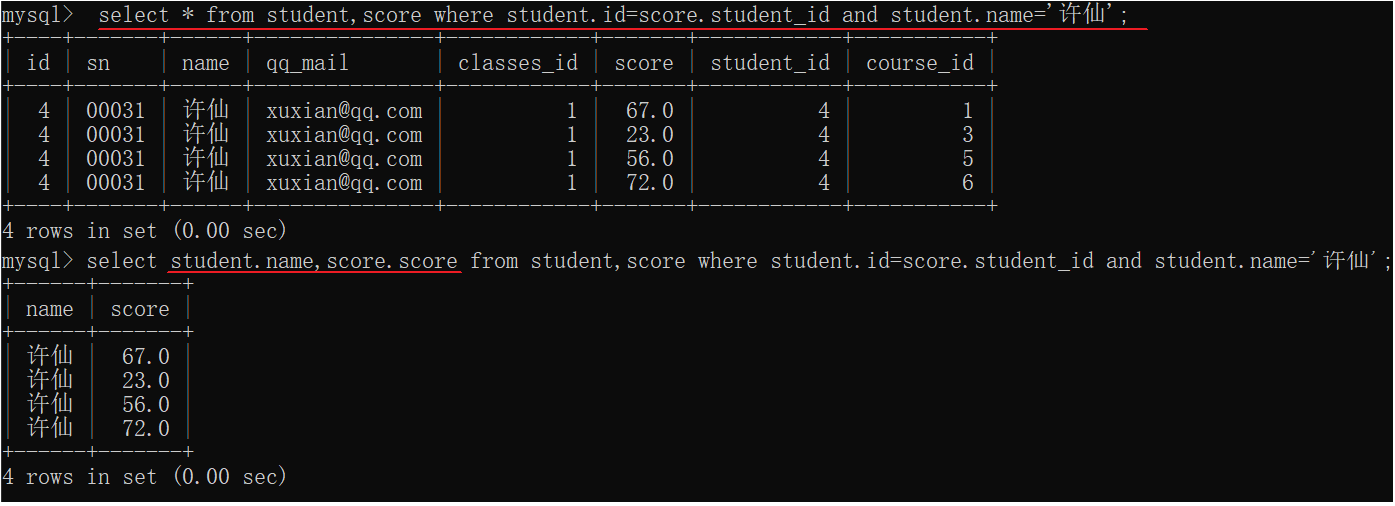
select * from student,score where student.id=score.student_id and student.name='许仙';
- 1
4.把不必要的列去掉,保留需要的列
select student.name,score.score from student,score where student.id=score.student_id and student.name='许仙';
- 1
联合查询还可以通过
join来完成
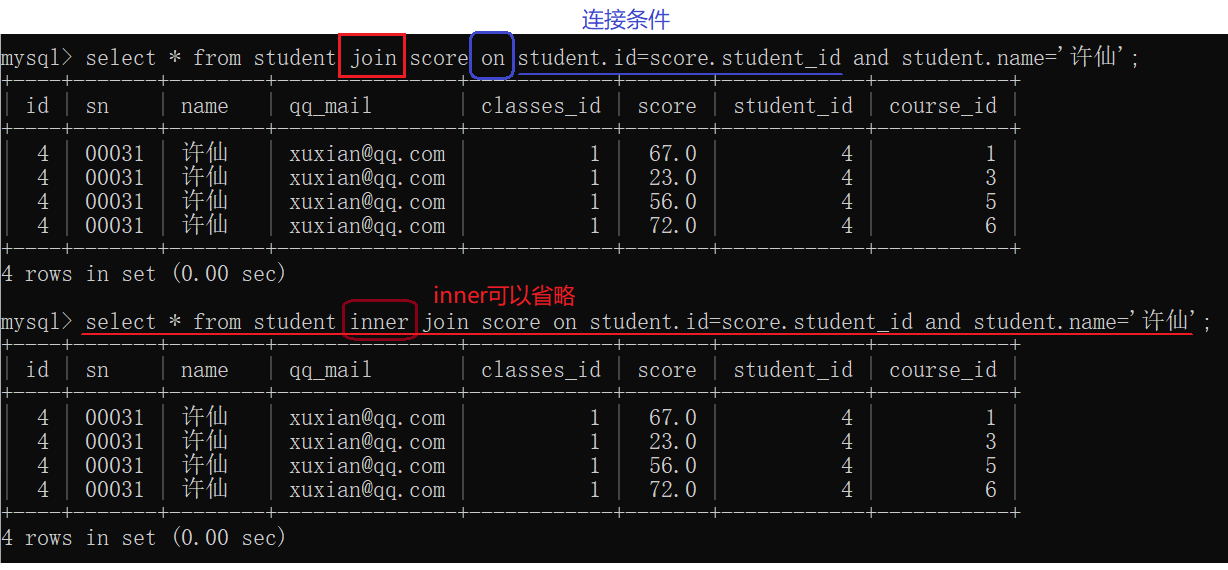
from多个表只能实现内连接。join on既可以实现内连接,也能实现外连接。
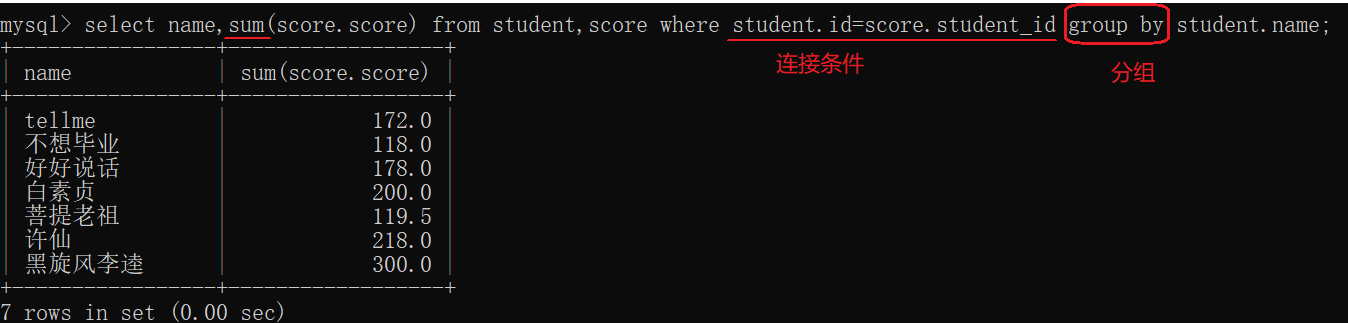
(2)查询所有同学的总成绩,及同学的个人信息
步骤:
1.算笛卡尔积
2.连接条件
3.分组,聚合查询,筛选列
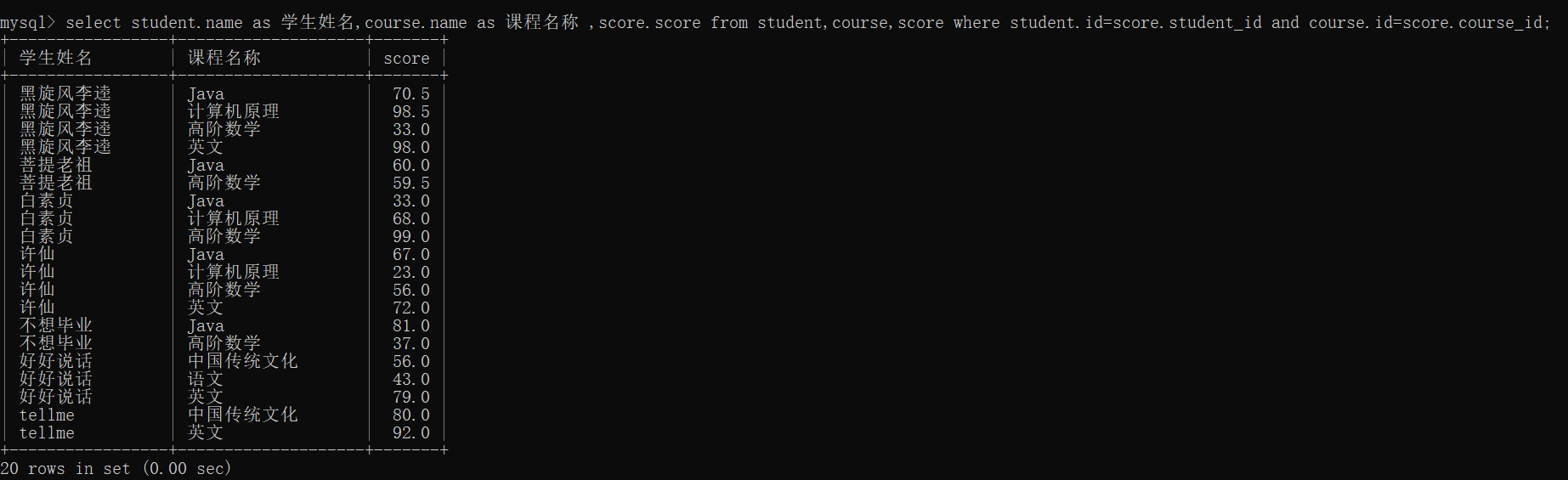
(3)查询所有同学的成绩及个人信息
期望查询结果中有姓名,课程名称,分数
步骤:
1)3张表进行笛卡尔积
select * from student , course , score;
(问题:这个查询结果出来很慢,原因是?答:不是服务器查询速度慢,也不是打印慢,而是windows的终端程序cmd导致的)
2)连接条件
select * from student, course,score where student.id= score.student_id and course.id= score.course_id;
3)对列进行精简
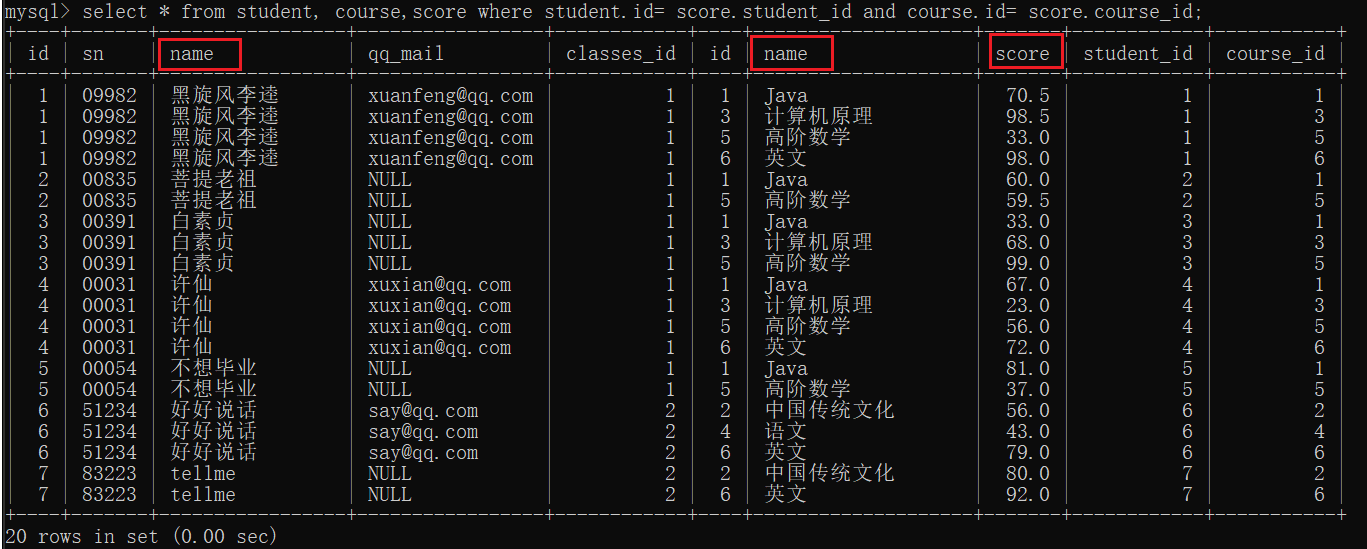
join on 也能实现对3张表的查询
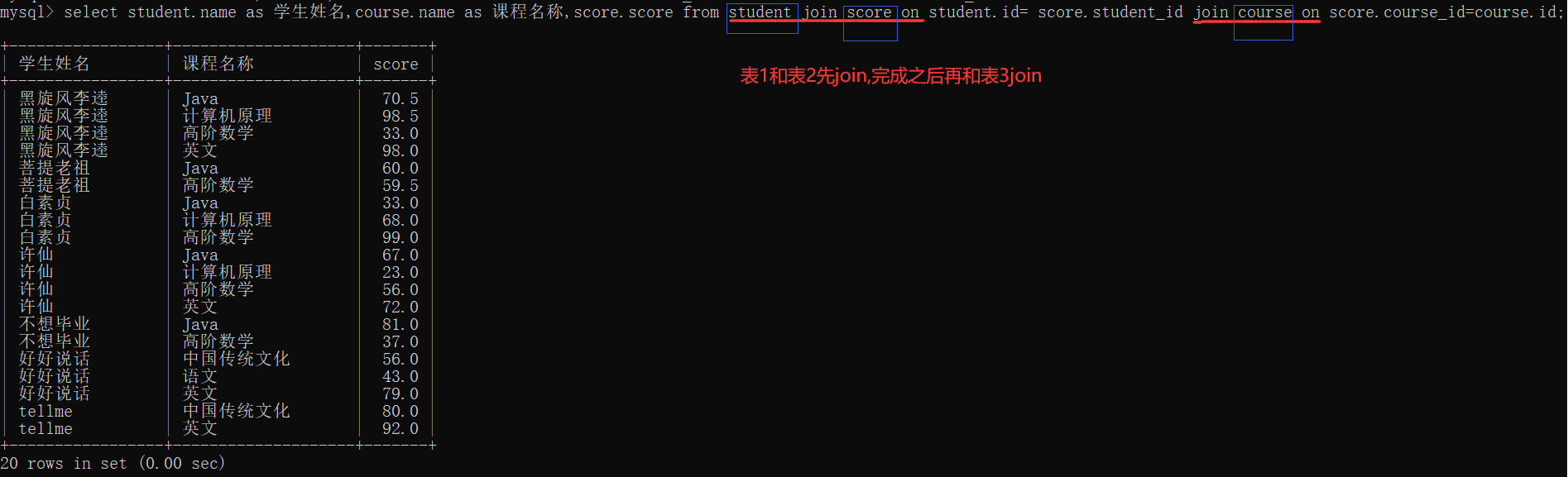
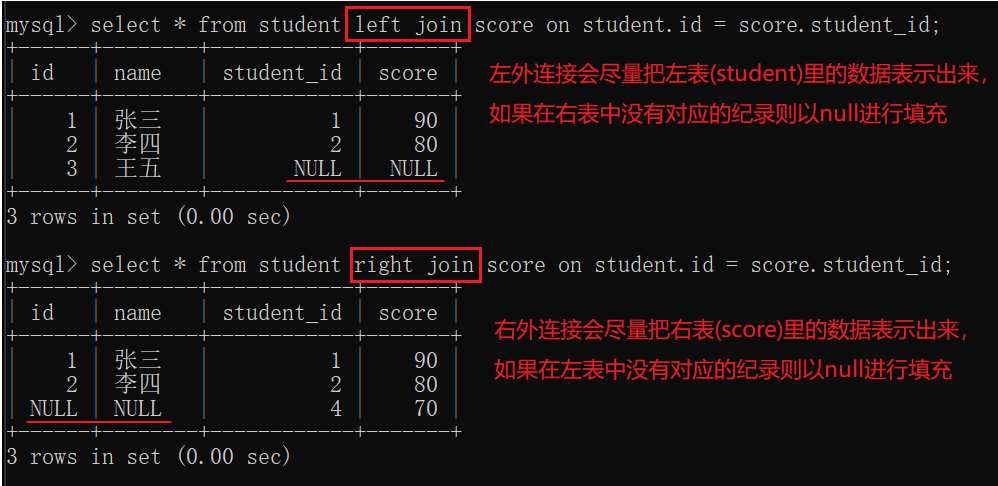
4.2.2外连接
内连接和外连接大多数情况下没有区别。(如果要连接的两张表的内容是一一对应的就没区别,如果不是一一对应的就有区别)
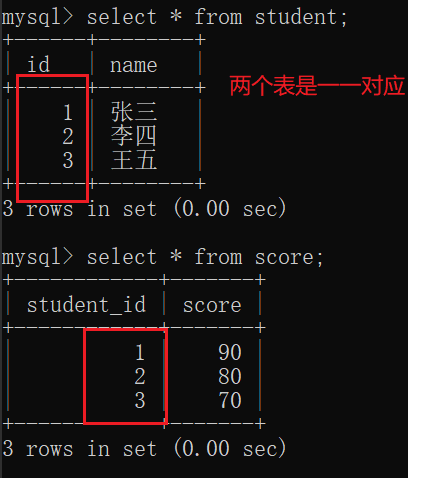
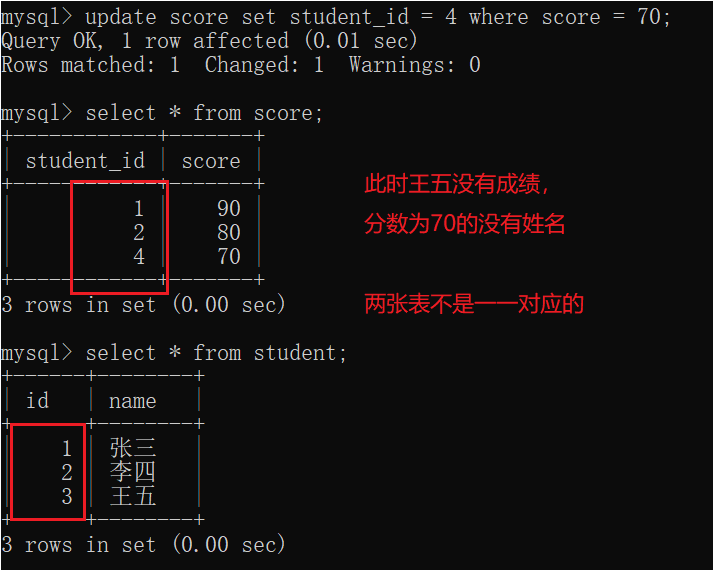
如果使用外连接,结果就不一样,join前面+left/right.
left join 左外连接
right join右外连接
4.2.3自连接
自己和自己进行笛卡尔积
自连接的效果是把行转成列。
- SQL中无法对行和行之间进行条件比较。
问:显示所有“计算机原理”成绩比“Java”成绩高的成绩,姓名。
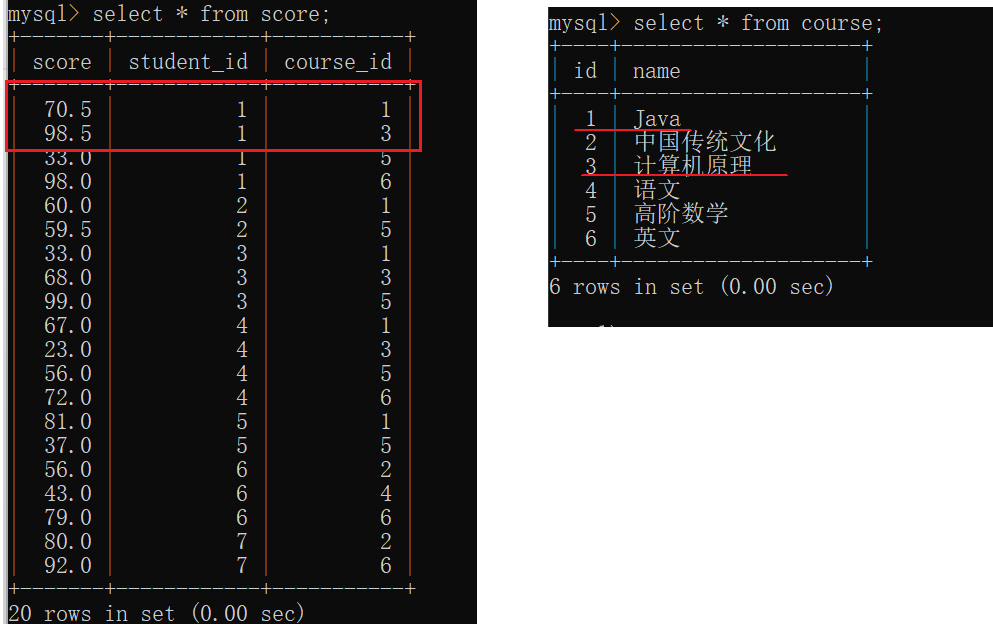
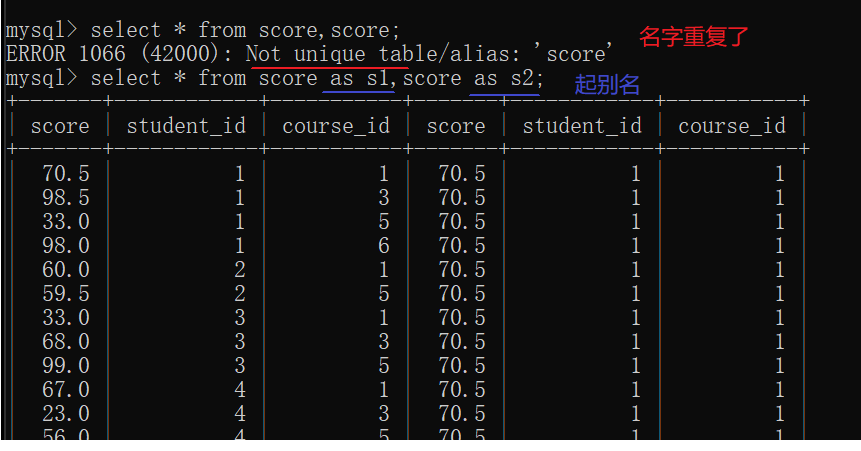
起别名不仅可以针对列,还可以对表起别名。
起别名时as可以省略,但是不建议
此处是要求每个学生自己的两门课程成绩之间进行比较,所有连接条件是student_id。保证每行记录所有列都是针对同一个学生描述的。
让左边是计算机原理,右边显示Java。

然后把计算机原理>Java的筛选出来。

4.2.4子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
(子查询可能会造成代码可读性低和代码执行效率低)
- 单行子查询
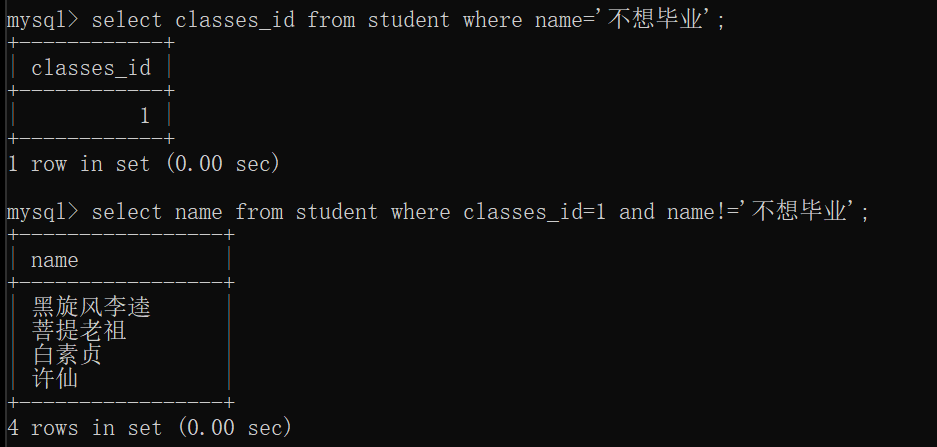
问:查询与“不想毕业” 同学的同班同学
步骤:
1.查询“不想毕业” 同学的班级id
2.查询这个班级id的其他同学

-
多行子查询
in 关键字
返回多行记录的子查询
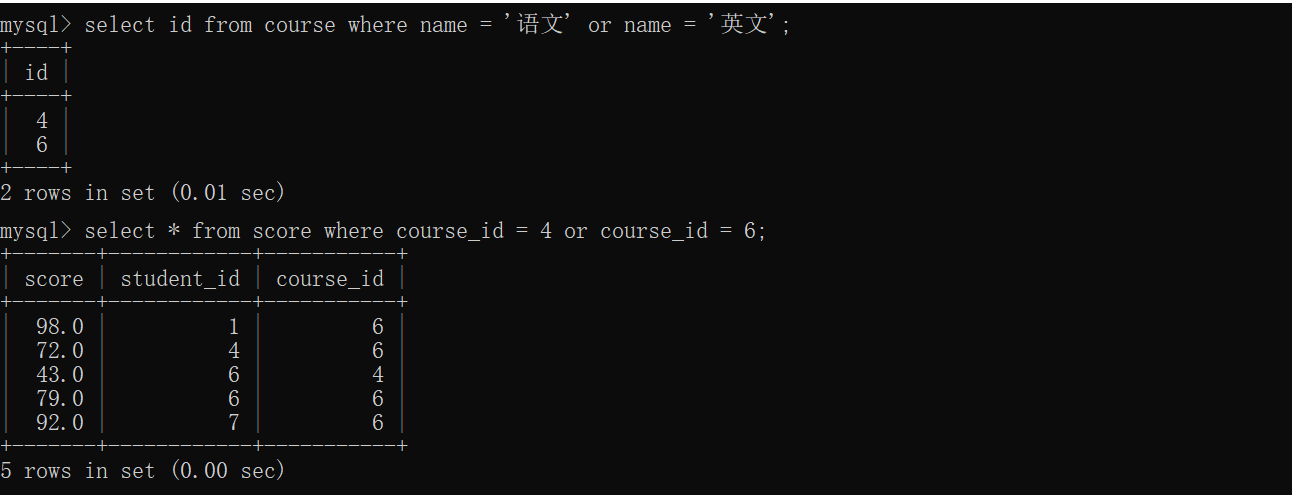
问:查询"语文"或"英文"的成绩信息
步骤:
1.先根据课程名称查询课程id2.再根据课程id查询课程成绩
或
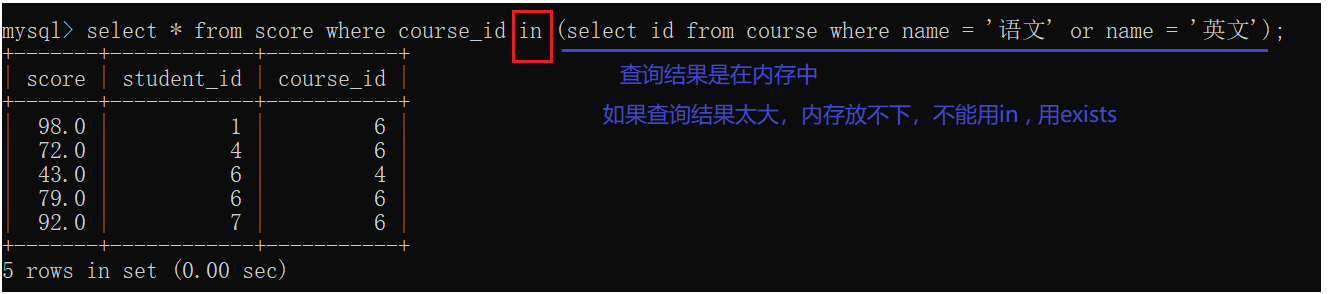
exists 关键字
可读性差,代码执行效率也低于in
4.2.5合并查询
关键字:union , union all
把两个查询的结果集合并成一个
(要求这两个结果集的列一致)
问:查询id小于3,或者名字为“英文”的课程
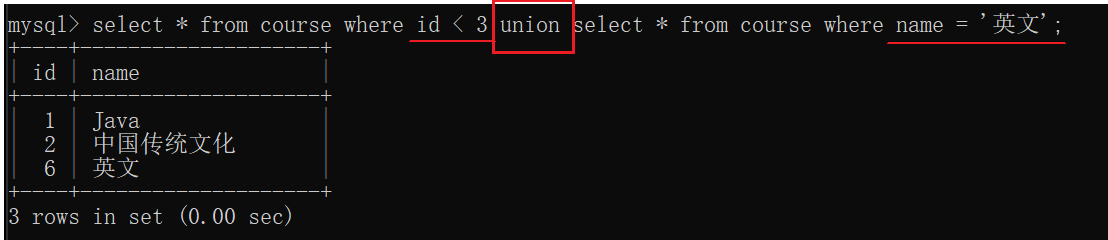
问:union和or的区别:
答:or要求查询结果只能来自同一个表。union查询结果可以来自不同的表,只要列匹配即可。
union 是会进行去重,重复的行只保留一份。union all不去重。


