
- 1小鱼深度产品测评之:阿里云低代码开发平台魔笔,一站式的应用全生命周期管理,高效解决应用研发、迭代、运维的问题。_阿里云魔笔
- 2C#手术麻醉临床信息系统源码,自动生成麻醉记录单、各种手术麻醉相关医疗文书
- 3idea for Mac 破解_jetbrainscrack-2.7-release-str.jar下载
- 4计算机毕业设计:基于python天气数据爬虫可视化系统+气象数据+Django框架(源码)✅
- 5python flask-sqlalchemy 查询功能,添加功能,删除功能_flask-sqlalchemy 删除
- 6四次考研,终于上岸!反正我感觉很牛逼!
- 7SAP各模块优缺点和发展简析_sap五大模块有哪些
- 82024年华中杯数学建模B题思路与论文助攻_2024华中杯b题
- 9Get-ACMECertificate : Issuer certificate hasn't been resolved.windows let's Encrypt gen cert for iis_windows iis网站使用certbot生成的ssl
- 10ubuntu18 20 编译Android11源码时需要的库_clang++.real
云计算技术 实验八 数据仓库Hive的安装和使用_hive安装和常用的hiveql操作实验目的
赞
踩
参考资料为:
教材代码-林子雨编著《大数据基础编程、实验和案例教程(第2版)》教材所有章节代码_厦大数据库实验室博客
1.实验学时
4学时
2.实验目的
- 熟悉Hive的安装
- 熟悉Hive的基本用法
3.实验内容
(一)完成Hive的安装和配置Mysql接口。
先进行hive安装包的安装。
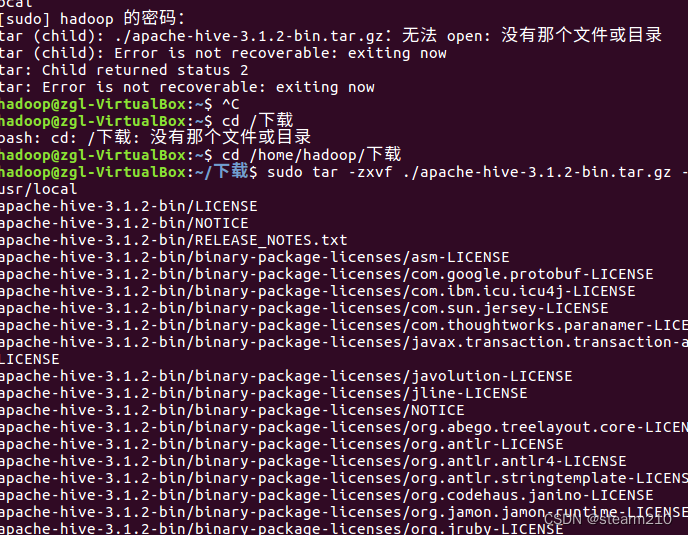
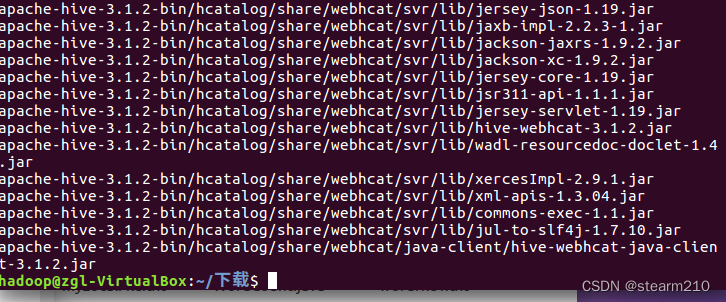
然后修改文件名和文件权限;

之后加入环境变量的路径:
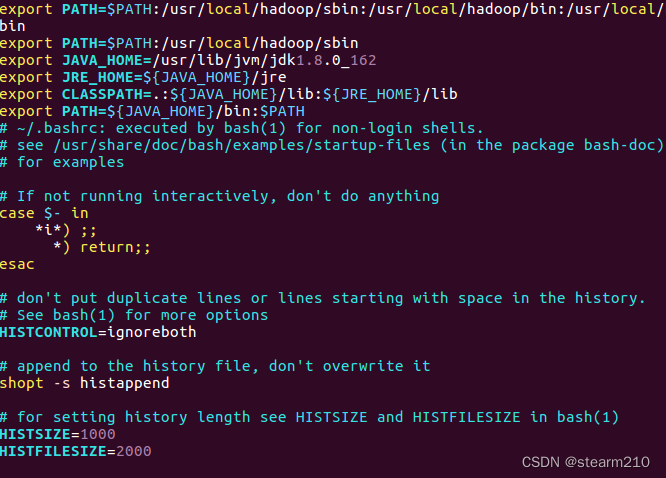
加入:
![]()
然后输入命令使得配置立即生效。
之后进入对应文件夹修改文件名:

然后创建一个新的文件.xml
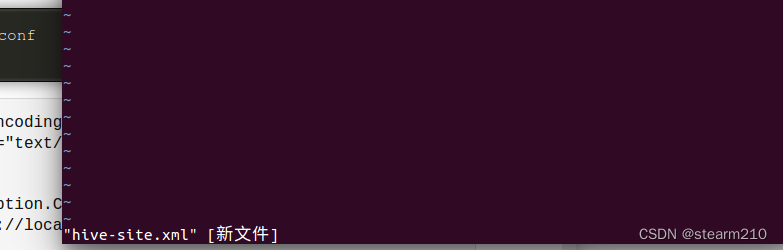
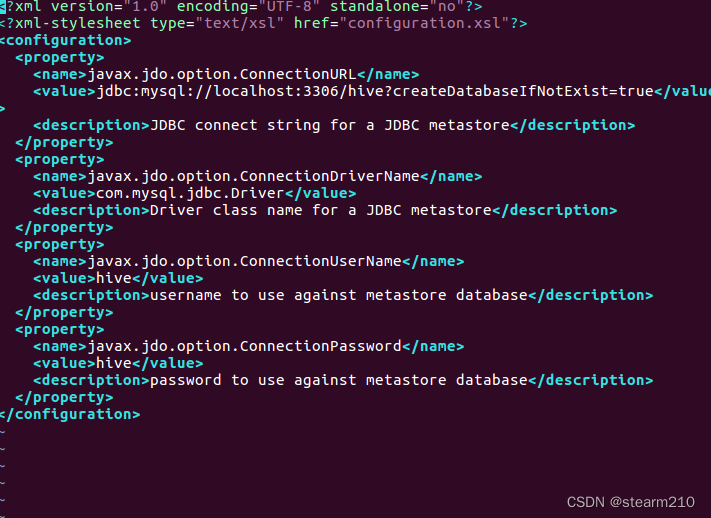
输入信息:
- <?xml version="1.0" encoding="UTF-8" standalone="no"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
- <description>JDBC connect string for a JDBC metastore</description>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- <description>Driver class name for a JDBC metastore</description>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>hive</value>
- <description>username to use against metastore database</description>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>hive</value>
- <description>password to use against metastore database</description>
- </property>
- </configuration>

之后配置MySQL:
先把压缩包压解,之后将压缩包复制到对应文件夹内;


先安装MySql数据库:
关闭然后重新启动数据库:

成功进入数据库:

进入sql的shell命令
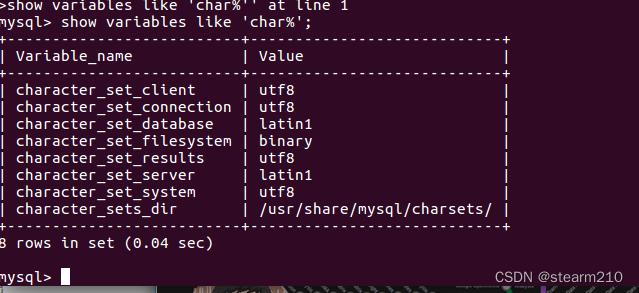
测试几个功能:
查看sql当前字符格式:
临时设置编码格式:

通过修改配置文件来进行编码格式的永久修改:
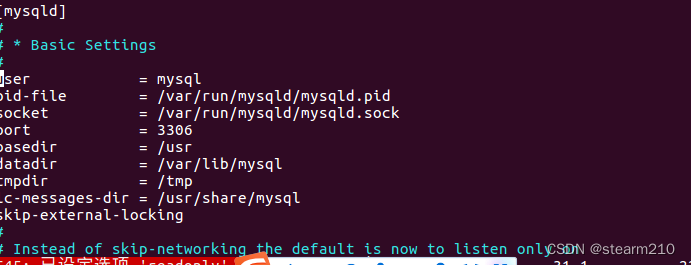
在下面加上character_set_server=utf8即可
这里要注意,需要修改文件权限才可以进行修改,添加代码的操作。
之后进入mysql查看发现已经修改utf8(character_set_server)成功:

之后是mysql数据库的基本操作:
显示数据库:

使用use命令打开数据库:

使用下面的命令显示数据库中的表:


显示user表中的记录:


创建数据库aaa:

创建表:
创建表并使得建立表person,表中有id、xm(姓名)、xb(性别)、csny(出生年月)等信息。

打印对应的信息:

增加对应的记录:
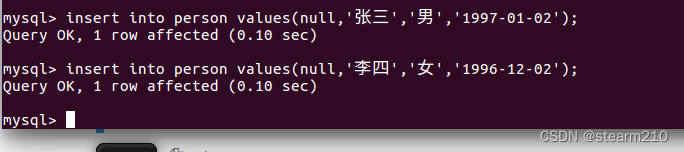
由于设置了id自增,所以对应的增加的信息会自动的加入到下一个列表之中。
使用select命令查看插入是否成功:
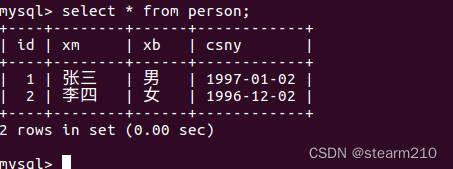
修改数据库中的信息:

删除信息:

删除对应的数据库以及表可以使用命令drop database+对应库名
drop table+对应表格
配置完成mysql数据库之后,开始配置接入hive数据库。
然后将mysql接入hive数据仓库:

然后配置允许mysql接入hive数据仓库:
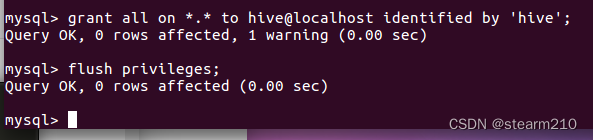
然后可以开始启动hive数据仓库:
不过启动之前先要启动hadoop。
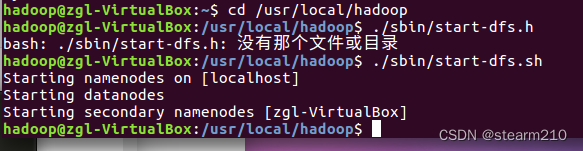
启动完成之后就可以启动hive数据仓库:
发现出现了问题:
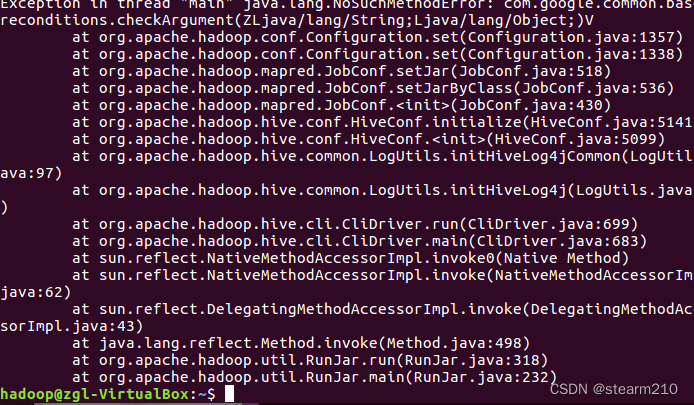
这时可以使用架构升级软件来进行版本的提升适配:
但是还是出现了报错,这个时候需要修改对应的版本号来进行错误清除。
查看发现对应的hadoop和hive两个的版本号是不一样的。这个时候就可以将两个guava版本修改成一样的就可以了。


修改之后,再次启动hive。
不过还是报错。

这里的报错意思是hadoop现在在安全模式下,这个时候无法创建文件!!!
这个时候需要关闭hadoop的安全模式!!!!
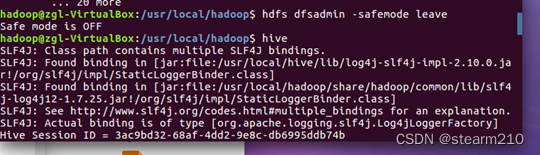
关闭之后,就可以重新启动hive,之后就可以重新进入hive进行编程。

(二)了解Hive的基本数据类型。列出各种数据类型。
这里的hive基本数据类型有多种。
| TINYINT | 1B(8b)有符号整数 | 1 |
| SMALLINT | 2B(16b)有符号整数 | 1 |
| INT | 4B(32b)有符号整数 | 1 |
| BIGINT | 8B(64b)有符号整数 | 1 |
| FLOAT | 4B(32b)单精度浮点数 | 1.0 |
| BOUBLE | 8B(64b)双精度浮点数 | 1.0 |
| STRING | 字符串,可以指定字符串 | “smu” |
| TIMESTAMP | 整数、浮点数或者字符串 | 127383728193 |
| BINARY | 字节数组 | [0,1,0,1,0,1] |
| BOOLEAN | 布尔类型:true/false | true |
同时还有Hive支持的集合数据类型:
| ARRAY | 一组有序字段,字段类型必须相同 | Array(1,2) |
| MAP | 一组无序的键值对,键的类型必须是原子的,值可以是任何数据类型,同一个映射的健和值的类型必须相同 | Map(‘a’,1,2) |
| STRUCT | 一组命名的字段,字段的类型可以不同 | Struct(‘a’,1,1,0) |
(三)完成Hive的基本操作,参考8.3节。
然后开始hive的编程基本操作:
1.首先是创建数据库hive:,创建的指令与mysql数据库相似:

2.创建表:需要在创建好的hive数据库中才创建一个表:

在hive中创建一个表的同时,还可以指定对应的路径进行表的创建。

当然,还可以在外部创建一个表,创建的这个表可以读取路径/usr/local/data下以”.”分割的数据。
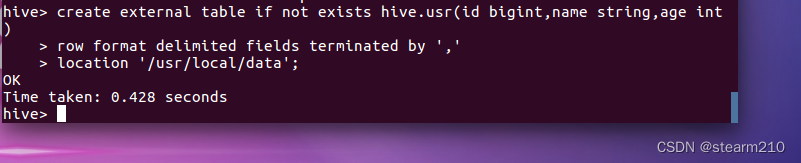
然后在hive数据库中创建分区表uerl,这个表通过复制usr表得到:

3.创建视图:

之后是删除操作:
1.删除数据库:
![]()

这里的意思是说这个库中有其他的信息,需要将这些信息删除之后才可以删除库。
可以在代码中加入if exists代码,如果不存在也不会产生异常
当然,也可以在代码后面加上caseade,这样删除当前数据库和数据库中的表。

2.删除表:
如果删除内部表,那么所有的信息都会被删除,如果是外部表,那么只会删除元数据而不会删除实际数据。
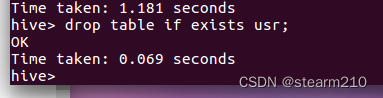
3.删除视图:
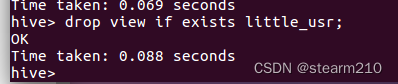
之后是修改数据库中的元素的操作:
1.修改数据库:
先创建一个数据库,然后在数据库中设置键值对属性进行操作。

2.修改表:
重命名:

为usr增加分区:
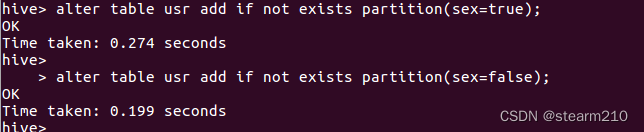
删除分区:

将usr表中的name修改为username,并且将name放在age之后
![]()
在usr分区字段前面增加一个新的列sex:
![]()
删除usr表中的所有字段之后重新定义字段:

描述对应的属性信息:

3.修改视图:
首先创建一个a的表,然后将视图继承于这个表:


然后修改视图

之后是查看数据库、表、视图:
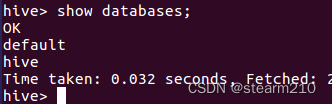
1.查看数据库:
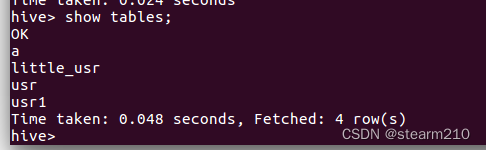
2.查看表和视图:
描述数据库、表、视图:
1.描述数据库基本信息:

查看数据库详细信息:

2.描述表和视图:
查看表usr和视图的基本信息:
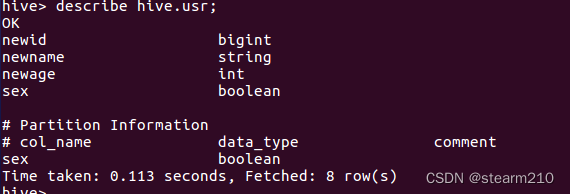

查看详细信息:


然后是查看usr列中的id信息:
![]()
然后是向表中装载数据:
首先打开hive库,然后写入路径中的数据:
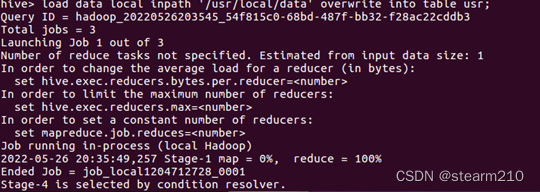

将HDFS路径下的数据文件装入表中并且覆盖原来数据:

导出数据:
首先创建一个新的分区表,然后创建一个新的表,让这个新的表继承这个分区表,
然后向新的分区表装载信息。


然后导出信息:
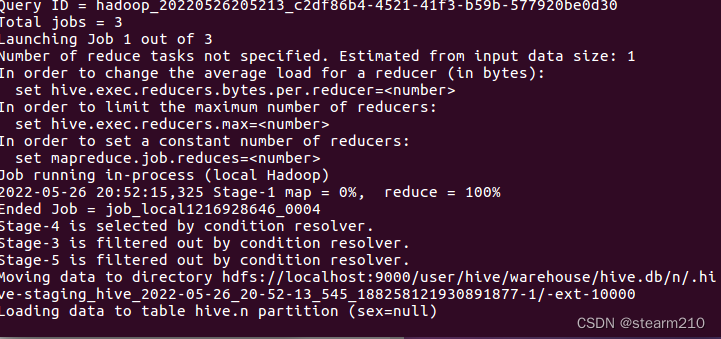
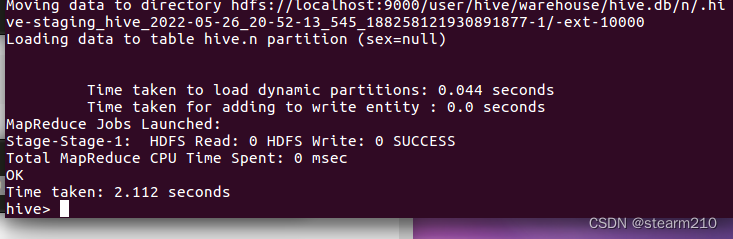
可以选择追加原有数据:
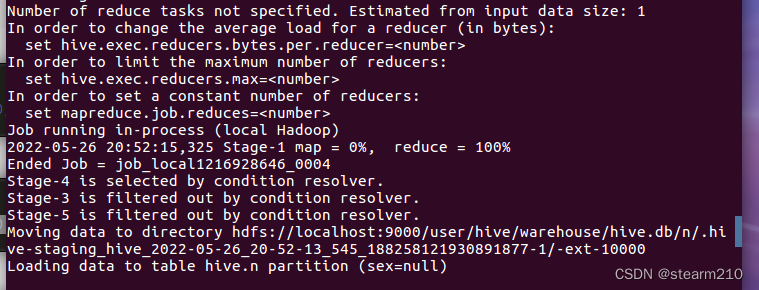

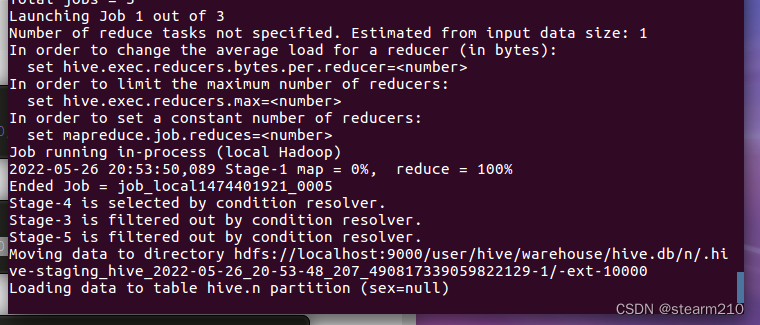
(四)在hive中实现wordcount。
创建一个input文件作为输入:

进入这个文件夹之后创建两个文件:

然后进入hive界面编写实现wordcount算法:


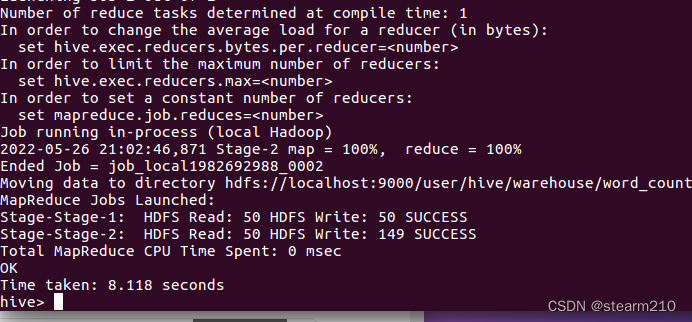
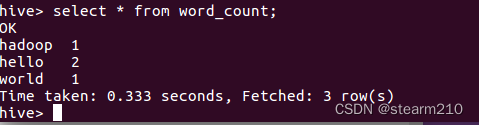
之后使用select语句查看结果:
4.思考题
(一)为什么要设计Hive?
1.在使用hive的时候,可以比mapreduce使用更少的代码量,在mapreduce中需要实现产生jar包,但是在使用hive的时候不需要使用jar包。用户不用实现具体的细节。
2. 大多数数据仓库应用程序都是使用关系数据库进行实现的,并使用SQL作为查询语言。Hive降低了将这些应用程序转移到Hadoop系统上的难度。
3. 另外,相比其他工具,Hive更便于开发人员将基于SQL的应用程序转移到Hadoop中。如果没有Hive,那么开发者将面临一个艰巨的挑战,如何将他们的SQL应用程序移植到Hadoop上。
(二)在hive中实现wordcount和直接写java程序有什么区别和相似?
相似:
使用的时候与直接在java程序中一样先要创建两个测试文件,也是需要进入到相同的目录和路径之下。
不同:
实现wordcount时hive已经将sql封装成mapreduce,简化了编写mapreduce的时间,相当于执行了两次mapreduce。但是使用java编写的时候,将会调用各种包,之前还需要进行各种包的导入以及代码的编写,远远没有wordcount便利简洁。
5.实验结论或体会
1.实验的时候,需要事先安装好mysql,下载的时候如果速度太慢,可以更换对应的下载网站。
2.在安装好hive并且想要启动的时候,有可能会报错。这里需要注意,可以使用架构升级软件来进行版本的提升适配:
但是还是出现了报错,这个时候需要修改对应的版本号来进行错误清除。
查看发现对应的hadoop和hive两个的版本号是不一样的。这个时候就可以将两个guava版本修改成一样的就可以了。


修改之后,再次启动hive。
不过还是报错。

这里的报错意思是hadoop现在在安全模式下,这个时候无法创建文件!!!
这个时候需要关闭hadoop的安全模式!!!!

关闭之后,就可以重新启动hive,之后就可以重新进入hive进行编程。

3.建议每次使用hive的时候,启动hadoop的时候需要启动hadoop的安全模式。进行删除数据库的时候,需要匹配对应的路径才可以。
4.需要注意路径有中文符号的问题。


