- 1设计模式-组合模式_组合设计模式菜鸟
- 2Windows系统安装onlyoffice_windows安装only office
- 3Flask项目快速部署_flask部署到服务器
- 4深入理解Linux内核-磁盘IO-I/0体系结构和设备驱动程序
- 5Win10内置Ubuntu重启Docker服务_win10重启docker服务
- 6拜占庭容错共识(PBFT)
- 7数智赋能内涝治理,四信城市排水防涝解决方案保障城市安全运行
- 8Github authenticator登录问题_github-recovery-codes
- 9深入学习Java:关于List下标越界源码分析_removeall 避免数组下标越界
- 10编写测试用例标准_测试用例设计要求连贯性
Q-YOLO:用于实时目标检测的高效推理_q-yolo在做什么
赞
踩
简介
实时物体检测在各种计算机视觉应用中起着至关重要的作用。然而,由于高计算和内存需求,在资源受限的平台上部署实时目标检测器带来了挑战。本文描述了一种低比特量化方法来构建高效的onr-stage检测器,称为Q-YOLO,它可以有效地解决传统量化YOLO模型中由激活分布不平衡引起的性能下降问题。Q-YOLO引入了一种完全端到端的训练后量化(PTQ)流水线,该流水线具有精心设计的基于单边直方图(UH)的激活量化方案,该方案通过最小化均方误差(MSE)量化误差来通过直方图分析确定最大截断值。
在COCO数据集上的大量实验证明了Q-YOLO的有效性,优于其他PTQ方法,同时在精度和计算成本之间实现了更有利的平衡。这项研究有助于推动在资源有限的边缘设备上高效部署对象检测模型,实现实时检测,同时减少计算和内存开销。
背景动机
实时物体检测是各种计算机视觉应用中的关键组成部分,如多物体跟踪、自动驾驶和机器人。实时物体探测器的发展,特别是基于YOLO的检测,在精度和速度方面取得了显著的性能。以下是计算机视觉历史分享的关于Yolo相关技术:
- 改进的YOLO:AF-FPN替换金字塔模块提升目标检测精度
- FastestDet:比yolov5更快!更强!全新设计的超实时Anchor-free目标检测算法(附源代码下载)
- EdgeYOLO:边缘设备上实时运行的目标检测器及Pytorch实现
- YoloR:又一个YOLO系列新框架!速度远远高于Yolov4(代码已开源)
回归正文,例如,YOLOv7-E6目标检测器在COCO 2017上实现了55.9%的mAP,在速度和精度方面均优于基于变换器的检测器SWINL级联掩码R-CNN和基于卷积的检测器ConvNeXt XL级联掩码R-CNN。尽管它们取得了成功,但对于资源有限的边缘设备(如移动CPU或GPU)上的实时目标检测器来说,推理过程中的计算成本仍然是一个挑战,限制了它们的实际使用。
在网络压缩方面已经做出了大量努力来实现高效的在线推理。方法包括增强网络设计、进行网络搜索、网络修剪和网络量化。尤其是量化,通过使用低位格式表示网络,在人工智能芯片上的部署变得非常流行。有两种主流的量化方法,量化感知训练(QAT)和训练后量化(PTQ)。尽管QAT通常比PTQ获得更好的结果,但它需要在量化过程中对所有模型参数进行训练和优化。对预训练数据和大量GPU资源的需求使得QAT的执行具有挑战性。另一方面,PTQ是用于量化实时目标检测的更有效的方法。
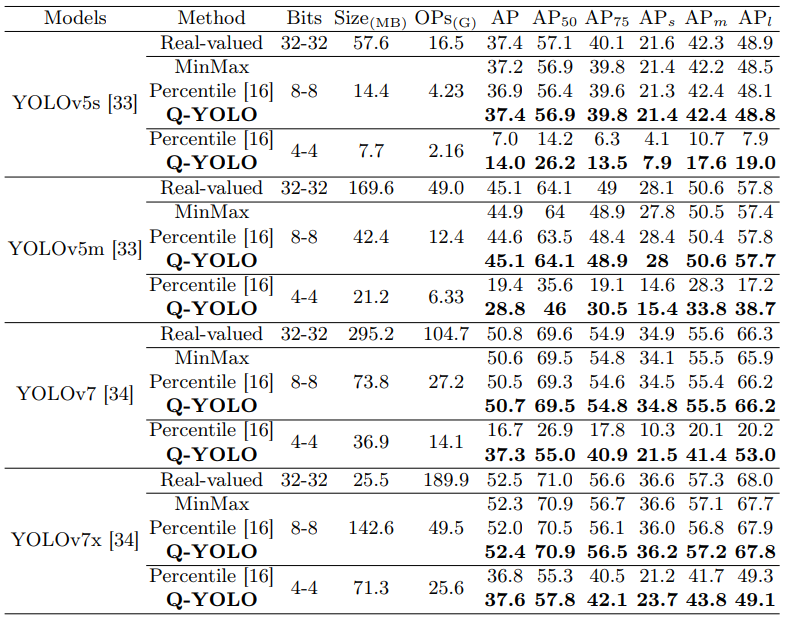
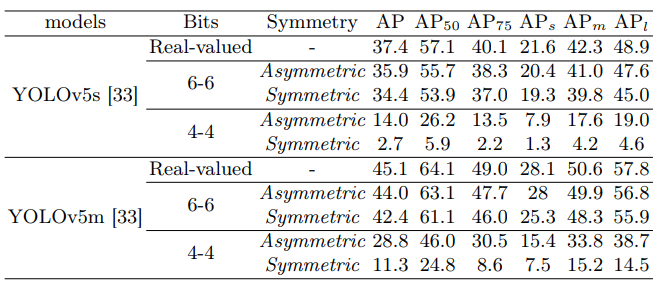
为了检查实时目标检测的低位量化,首先使用最先进的目标检测器YOLOv5建立PTQ基线。通过对COCO 2017数据集的实证分析,观察到量化后的性能显著下降,如上表所示。例如,采用Percentile的4位量化YOLOv5s仅实现7.0%mAP,与原始实值模型相比,导致30.4%的性能差距。
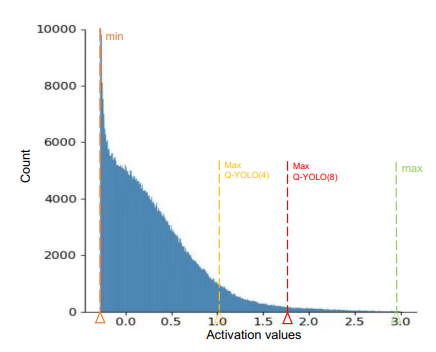
发现量化YOLO的性能下降可归因于激活分布的不平衡。如下图所示,观察到接近下限的值的高浓度,并且在零以上的发生率显著降低。当使用诸如MinMax之类的固定截断值时,以极低的概率表示激活值将在有限的整数位宽内消耗相当多的比特,从而导致信息的进一步丢失。
新框架分析
鉴于上述问题,我们介绍了Q-YOLO,一种用于实时目标检测的完全端到端PTQ量化架构,如下图所示。
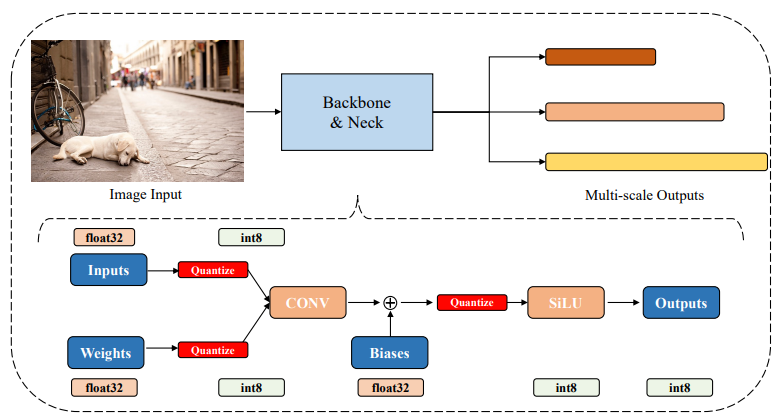
Q-YOLO量化YOLO模型的主干、颈部和头部模块,同时对权重采用标准MinMax量化。为了解决激活分布不平衡的问题,引入了一种新的方法,称为基于单边直方图的(UH)激活量化。UH通过直方图迭代地确定使量化误差最小化的最大截断值。该技术显著减少了校准时间,并有效地解决了量化引起的差异,优化了量化过程以保持稳定的激活量化。通过减少激活量化中的信息损失,确保了准确的目标检测结果,从而实现了精确可靠的低比特实时目标检测性能。
网络量化过程。首先回顾了训练后量化(PTQ)过程的主要步骤,并提供了详细信息。首先,使用全精度和浮点算法对权重和激活进行训练或将网络提供为预训练模型。随后,权重和激活的数值表示被适当地变换用于量化。最后,将完全量化的网络部署在整数算术硬件上或在GPU上模拟,在保持合理精度水平的同时,能够在减少内存存储和计算需求的情况下进行高效推理。
量化范围设置。量化范围设置是建立量化网格的上限和下限限幅阈值的过程,分别表示为u和l。范围设置中的关键权衡在于两种类型的误差之间的平衡:剪裁误差和舍入误差。如下等式所述。
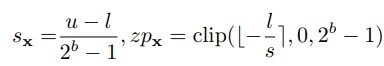
当数据被截断以适应预定义的网格限制时,会出现剪裁错误。这样的截断导致信息损失和所得到的量化表示的精度降低。另一方面,由于舍入操作过程中引入的不精确性,会出现舍入误差,如下等式所述。
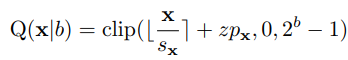
这种误差可能随着时间的推移而累积,并对量化表示的总体精度产生影响。以下方法在两个量之间提供了不同的权衡。
MinMax
在实验中使用MinMax方法进行权重量化,其中削波阈值lx和ux公式化为:
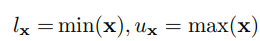
这样就不会产生剪切错误。然而,这种方法对异常值很敏感,因为强异常值可能会导致过多的舍入误差。
均方误差(MSE)
缓解大异常值问题的一种方法是采用基于MSE的范围设置。在该方法中,确定使原始张量和量化张量之间的均方误差(MSE)最小化的lx和ux:
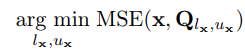
Unilateral Histogram-based (UH) Activation Quantization
为了解决激活值不平衡的问题,提出了一种新的方法,称为基于单边直方图的(UH)激活量化。首先通过校准数据集对正向传播后的激活值进行了实证研究。如上面的图所示,在下界附近观察到值的集中分布,同时在零以上出现的次数明显减少。对活化值的进一步分析表明,-0.2785的经验值作为下限。这种现象可归因于YOLO系列中频繁使用Swish(SILU)激活功能。

实验及可视化
激活值量化对称分析的比较。不对称表示使用非对称激活值量化方案,而对称表示激活值的对称量化。
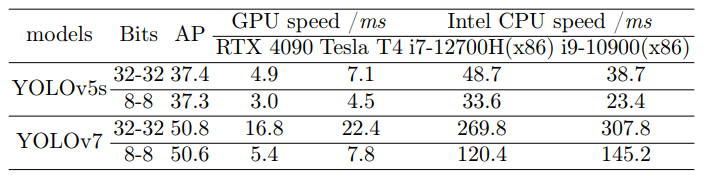
为了实际验证量化方案带来的加速效益,在GPU和CPU平台上进行了推理速度测试。对于GPU,选择了常用的GPU NVIDIA RTX 4090和NVIDIA Tesla T4,它们通常用于计算中心的推理任务。
由于CPU资源有限,只测试了英特尔的产品i7-12700H和i9-10900,这两款产品都具有x86架构。对于部署工具,选择了TensorRT和OpenVINO。整个过程包括将torch框架中的权重转换为具有QDQ节点的ONNX模型,然后将它们部署到特定的推理框架中。推理模式设置为单图像串行推理,图像大小为640x640。由于目前大多数推理框架只支持对称量化和8位量化,不得不选择对称的8位量化方案,这导致与非对称方案相比,精度下降幅度极小。如下表所示,加速度非常显著,尤其是对于较大的YOLOv7模型,其中使用GPU时的加速比甚至超过了全精度模型的3倍。这表明在实时检测器中应用量化可以带来显著的加速。