
- 1第二弹!谷歌大脑2017总结下篇:Jeff Dean梳理6大领域研究
- 2北大计算机专硕毕业,悔!两年多前,我考上了北大的研究生……
- 3【Git】TortoiseGit上传时忽略文件配置_tortoisegit 忽略文件
- 4Oracle存储过程详解(四)-Oracle中Cursor介绍_存储过程cursor用法
- 5使用 IDEA 创建 SpringBoot 项目时报错 Error parsing JSON response 解决方案【全】
- 6kafka常见问题_kafka常见问题及解决
- 7js获取按钮的文字_js 寻找没有id的button
- 8完整步骤进行Git连接GitHub操作
- 9yolov5模型剪枝_yolov5离线剪枝
- 10机器学习数据预处理1:独热编码(One-Hot)及其代码
分布式系统的SLA如何定义_系统sla
赞
踩
1. 什么是SLA(服务等级协议)?
SLA(Service-Level Agreement)服务等级协议,是指系统服务提供者(Provider)对客户(Customer)的一个可量化的服务承诺,常见于大型分布式系统中,用于衡量系统服务是否稳定健康的常见方法。
2. SLA(服务等级协议)常用的衡量指标有哪些?
SLA是一种服务承诺,因此指标具备多样性, 业界主流常用指标包含:可用性、准确性、系统容量和延迟。
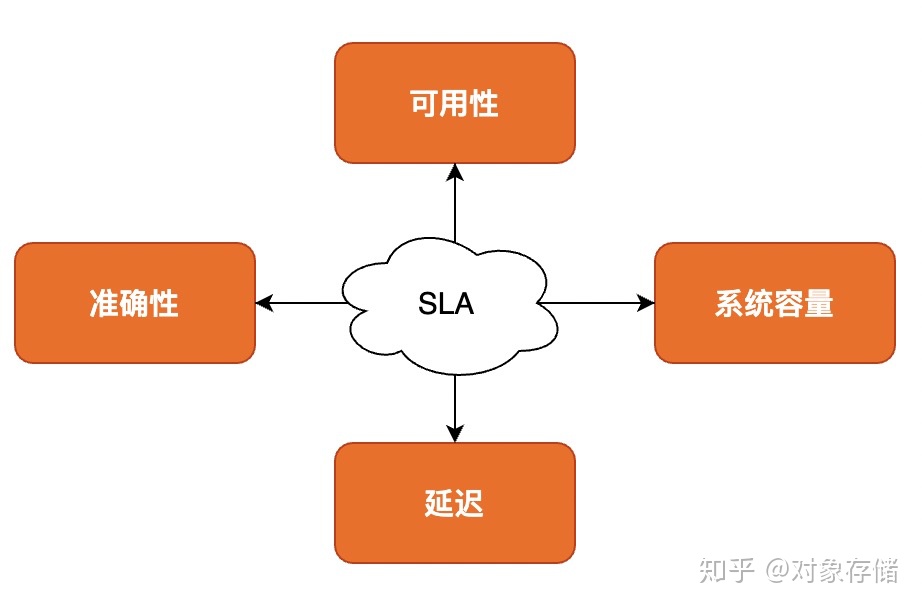
2.1 Availability(可用性)
系统服务能正常运行所占的时间百分比,业界对可用性的描述,通常采用年故障时长。比如,数据中心机房划分为不同等级,如 T1~T4 机房,它们的 可用性 及年平均故障时间如下:

网络服务的可用性,通常也会折算为不能提供服务的故障时间长度来衡量,比如典型的 5 个 9 可用性就表示年故障时长为 5 分钟,如下表所示。

对于许多系统而言,四个9的可用性(99.99%),或每年约52.6分钟的系统中断时间,即可以被认为是具备高可用性。
2.2 Accuracy(准确性)
准确性是指系统服务中,是否允许某些数据是不准确或者丢失,如果允许这样的情况发生,用户的容忍度(百分比,可以接受的概率)是多少,常见的衡量方式为:基于服务周期内的错误率计算准确性。

例如,我们在一分钟内发送100个有效请求到系统中,其中有5个请求导致系统返回内部错误,那我们可以说这一分钟系统的错误率是 5 / 100 = 5%,准确率为1 - 5% = 95%。
对于云服务而言,计算请求错误率时,计算时间范围越长越有利,因为时间越长,总请求数越多,错误率越有可能降得更低,一般有实力得服务商都会 从客户角度计算错误率,按照5分钟的粒度来计算,因为5 分钟是业界典型的机器故障恢复时间,能够快速修复机器,降低系统的错误率。

最终准确率为:

2.3 Capacity(系统容量)
指系统能够支持的负载量,一般会以每秒的请求数为单位来表示,与CPU的消耗、外部接口、IO等等紧密关联,常见衡量指标:
- QPS(Query Per Second):每秒处理的查询数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,也即是最大吞吐能力。
- TPS(Transactions Per Second):每秒处理的事务个数,是软件测试结果的测量单位,一个事务是指一个客户机向服务器发送请求到服务器做出反应的全过程,客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,系统整体处理能力取决于处理能力最低模块的TPS值。
- 并发数: 系统可以同时承载的正常使用系统功能的用户的数量(同一时间处理的请求/事务数),与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标
- 响应时间: 一般取平均响应时间。
常用评估公式:

峰值QPS或峰值TPS计算原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间。
示例:公司早上8:00上班,7:30到8:00这30分钟的时间内用户需登录签到系统进行签到,公司员工总数为1000人,平均每一个员上登录签到系统的时长为5分钟。
- QPS = 1000/(30*60) 事务/秒
- RT(平均响应时间为) = 5*60秒
- 并发数= QPS*平均响应时间 = 1000/(30*60) *(5*60)=166.7
2.4 Latency(延迟)
延迟(Latency),指系统收到用户请求到响应请求之间的时间间隔,在定义延迟的SLA时,常用p95和p99这样的延迟声明,这里的p指的是percentile,也就是百分位的意思,如果p95是1秒的话,那就表示在100个请求里面有95个请求的响应时间会少于1秒,而剩下的5个请求响应时间会大于1秒,P99同理。
3. 世界顶级SLA“长”什么样?
3.1 世界顶级的SLA评判标准和基本能力
这里以业界领先的分布式系统 - 阿里云对象存储OSS为例,看看一个世界最顶级的SLA长什么样


