
- 1【MSP432电机驱动学习—上篇】TB6612带稳压电机驱动模块、MG310电机、霍尔编码器
- 2如何刷Leetcode?【从400到700到900的全网总结篇】_带你刷leetcode
- 3多示例学习相关知识_多彁的知识,弽集多彁的实例,反复分析体会多彁的彃用
- 4mysql保存数据提示:Out of range value for column错误_mysql执行sql 提示 out of range
- 5php curl 连接超时,phpcurl超时设置详解
- 6基于linux的网络编程_linux 网络编程
- 7前端项目使用docker编译发版和gitlab-cicd发版方式
- 8什么是SLA服务可用性
- 9火焰识别python_基于Python的火焰识别程序
- 10构建Web UI自动化测试平台
LLM batch
赞
踩
LLM
核心内容
- 介绍大型语言模型(LLM)推理的基础知识,强调传统批处理策略的不足之处。
- 引入“连续批处理”的概念,并讨论现有批处理系统的基准测试结果,例如HuggingFace的文本生成和推理以及vLLM。
- 利用vLLM,用户可以实现23倍的LLM推理吞吐量,同时降低p50延时。vLLM
LLM推理的基础
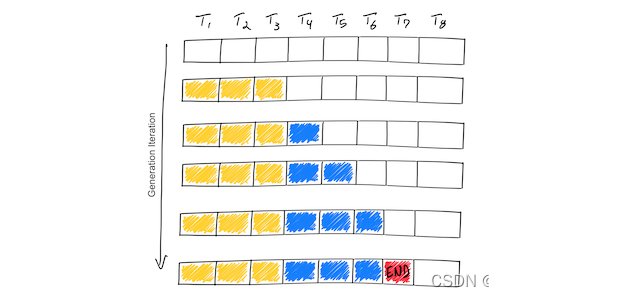
GPT风格的模型被训练来预测给定先前tokens的下一个token(1.3 tokens ~= 1 word)。要使用它们生成文本,请向其提供prompt,然后要求它预测下一个token,将生成的token附加到提示中,然后要求其预测下一token,这样反复。为了做到这一点,在每次预测下一个token时将所有参数从RAM传输到处理器。
这个示例显示了一个假设模型,该模型支持8个tokens(T1,T2,…,T8)的最大序列长度。从prompt tokens(黄色)开始,迭代过程一次生成一个token(蓝色)。一旦模型生成序列结束标记(红色),生成循环就会停止。此示例显示了一个只有一个输入序列的batch,因此batch size为1。
内存-IO受限
LLM模型文件一般都比较大。占用内存一般是其参数的倍数关系(FP16=2字节parameter number, INT8=1字节parameter number)。比如 13B的模型FP16的占内存大约25G多,INT8的占内存13G。
对一个13B的模型1 token的output占用内存就达到1MB.最大长度是512的一个请求就占了512MB.
LLM服务的性能受到内存的限制,为内存和IO受限型memory-IO bound,计算资源不是瓶颈。就是说,当前将1MB的数据加载到GPU的计算核心所花费的时间比这些计算core对1MB数据执行LLM计算所花费的更多。这意味着LLM推理吞吐量在很大程度上取决于您可以将多大的batch放入高带宽GPU内存。参见(understand-perf),以了解更多详细信息。
在自回归解码过程中,LLM的所有输入tokens产生它们的attention key and value tensors,并且这些tensors被保存在GPU存储器中以生成下一个token。这些缓存的key and value tensors通常被称为KV缓存。
KV缓存facts
占内存大:LLaMA-13B中单个序列最多需要1.7GB。
动态分配:其大小取决于序列长度,这是高度可变和不可预测的。因此,有效地管理KV高速缓存是一个重大挑战。由于碎片和过度预留,现有系统浪费了60%-80%的内存。
优化方法
模型量化
模型量化AutoGPTQ SmoothQuant等通过将16位表示移动到8位表示来将内存使用量减半,那么可以将较大批量大小的可用空间增加一倍。
减少内存IO操作
FlashAttention 发现通过重新组织attention计算以需要更少的内存IO来显著提高吞吐量。
Continuous batching
连续批处理是另一种不需要修改模型的GPU内存优化技术。
LLM 组batch
batch推理
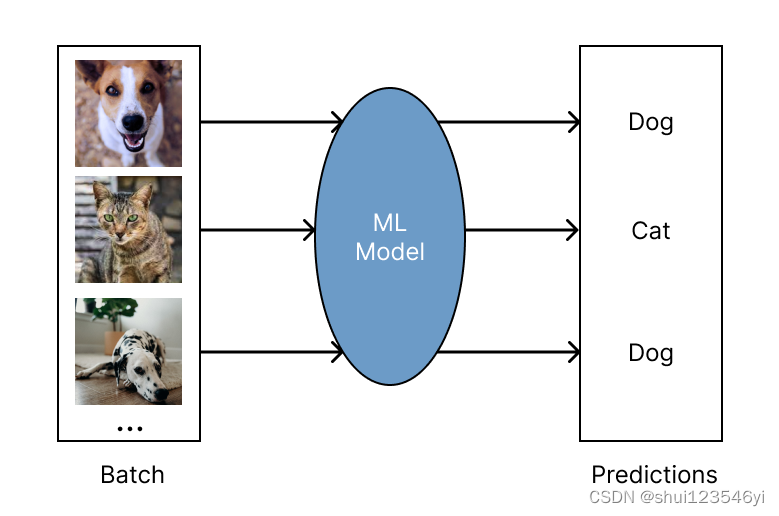
GPU是大规模并行计算架构,计算速度teraflop浮点运算(A100)甚至是petaflop级(H100)范围。尽管计算量惊人,由于内存都用在了加载模型参数上,LLM推理在计算方面仍难以达到饱和。
Batching是改善这种情况的有效方法;加载一次模型参数,然后使用它们来处理许多输入序列。有效地利用了芯片的内存带宽,从而提高了计算利用率、吞吐量和降低LLM推理成本。batch能将吞吐量最高提高10倍
##组Batch类型
静态 batching
我们将这种传统的批处理方法称为静态批处理,因为在推理完成之前,批处理的大小保持不变。
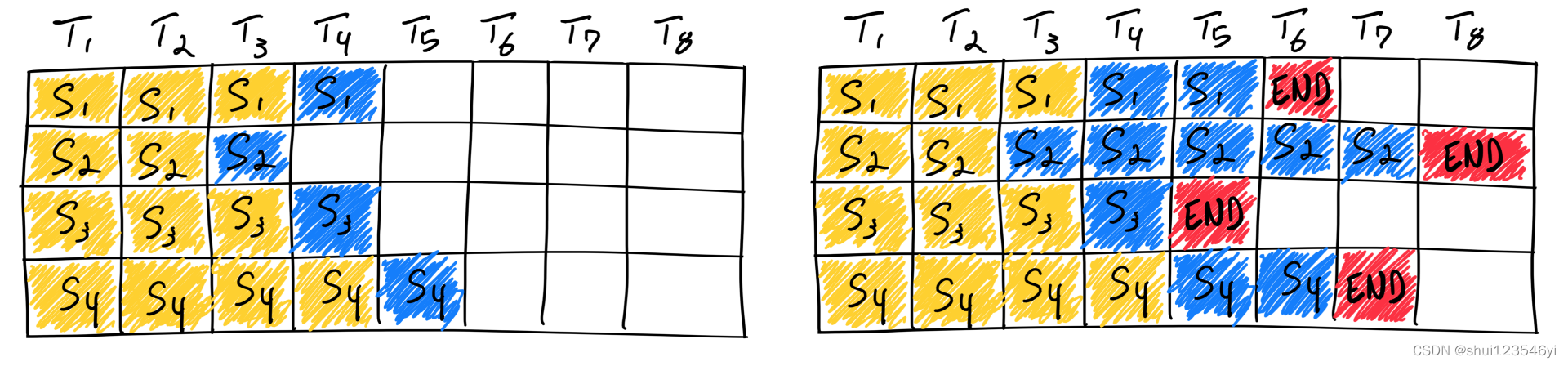
以下是LLM推理上下文中的静态批处理示例:
使用静态批处理完成四个序列。在第一次迭代(左)中,每个序列从提示标记(黄色)中生成一个标记(蓝色)。经过几次迭代(右)后,完成的序列每个都有不同的大小,因为每个序列在不同的迭代中发出序列结束标记(红色)。即使序列3在两次迭代后完成,静态批处理意味着GPU将未被充分利用,直到批处理中的最后一个序列完成生成(在本例中,是六次迭代后的序列2)。
LLMs的batch处理相对较困难,因为batch中不同序列的生成长度与批量中最大的生成长度不同,早完成的要等最长的结束后才能释放资源,这种情况会导致GPU利用率不足。示例中S1,S2,S4就是先于S2结束
Continuous batching
nvidia的TensorRT LLM称之为in-flight-batching
书生浦语称之为Persistent Batch(下面的gif来自书生)
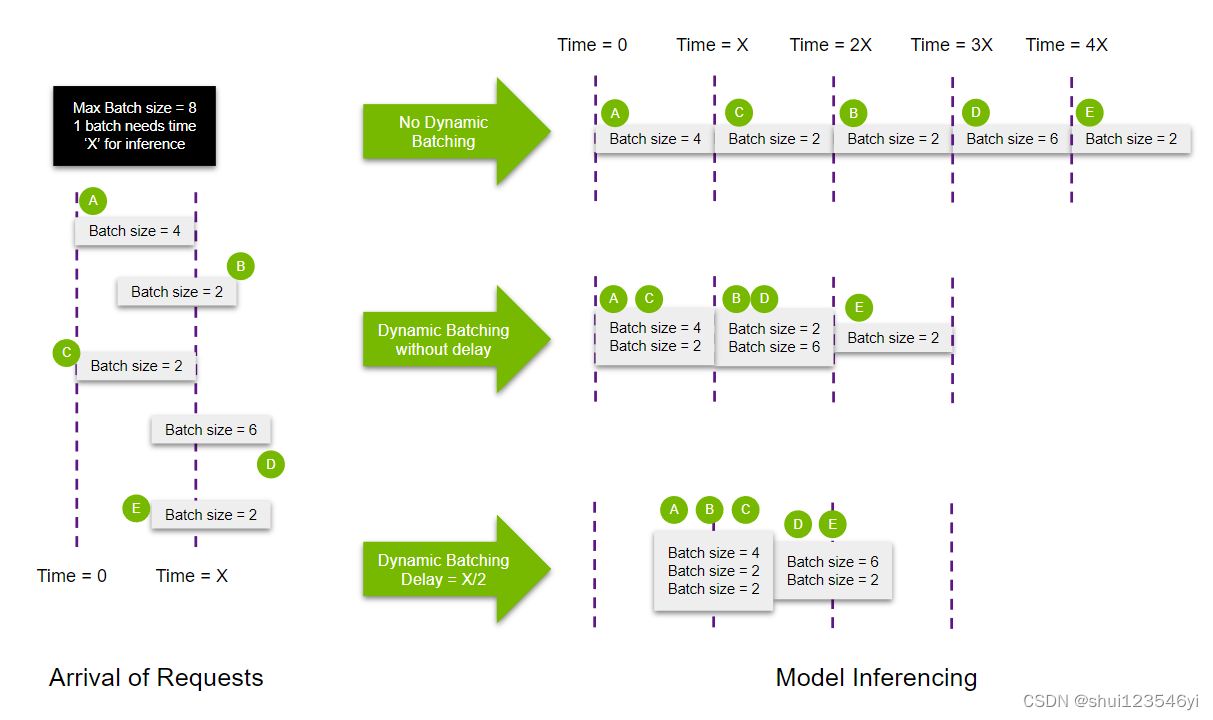
- 动态批处理(dynamic batching):系统会动态地根据输入数据的大小来决定batch的大小,以便更有效地利用计算资源。例如,如果有一些小的输入数据和一些大的输入数据,系统可能会选择将多个小的输入数据组合在一起进行处理,而单独处理大的输入数据。这样可以确保计算设备的并行处理能力被充分利用,从而提高推理速度。
- 迭代级调度(iteration-level scheduling)迭代级调度是并行计算中的一种技术,任务的调度是在循环的迭代级别进行的。这种技术经常用于动态批处理,以优化计算资源的利用。
在动态批处理的上下文中,可以使用迭代级调度根据当前迭代动态调整batch size。例如,如果系统检测到当前的输入batch size过大并且正在造成瓶颈,它可以决定在下一次迭代中减少batch size。相反,如果系统检测到当前的输入batch size过小并且没有充分利用计算资源,它可以决定在下一次迭代中增加batch size大小

Continuous batching不是等到一个批次中的每个序列都完成了生成,而是实现了迭代级别调度,其中批次大小由每次迭代决定。这样一旦batch中的序列有完成生成的,就可以在其位置插入新的序列,从而比静态批处理更高的GPU利用率。
使用Continuous batching完成七个序列推理。左侧显示单次迭代后的批次,右侧显示多次迭代后的批。一旦序列发出序列结束标记,我们就在其位置插入一个新序列(即序列S5、S6和S7)。这实现了更高的GPU利用率,因为GPU在开始新的序列之前不等待所有序列完成。
现实比这个简化的模型复杂一点:由于预填充阶段需要计算,并且具有与生成不同的计算模式,因此无法容易地与token的生成进行批量处理。
各个Frameworks的batch类型
batch size权衡
在LLM推理中,Batch Size、Latency和Throughput之间存在密切的关系:
- Batch Size(批量大小):这是一次通过模型的样本数量。较大的batch size可以提高GPU的利用率,因为更多的样本可以同时在GPU上进行计算。然而,如果batch size过大,可能会超出GPU的内存限制,也可能导致训练不稳定。用于推理的硬件必须达到高利用率, 否则推理的花费会非常高。高延迟低吞吐的场景可以将多个用户的prompts组合在一起来达到提高硬件利用率的作用。
- Latency(延迟):这是处理一批数据所需的时间。Latency–模型必须在合理的时间内做出响应。我们不想在开始在聊天应用程序中进行流式传输之前等待几秒钟。input tokens和解码需要不同的处理时间。增加batch size会增加延迟,因为需要处理更多的数据。然而,由于GPU的并行性,增加batch size并不一定会导致延迟成比例增加。
- Throughput(吞吐量):这是单位时间内处理的数据量。增加batch size通常会增加吞吐量,因为可以同时处理更多的数据。然而,如果batch size过大,可能会超出GPU的内存限制,导致吞吐量下降。一般人类每秒大概需要33tokens。可以根据不同的业务场景调整吞吐量
总的来说,Batch Size、Latency和Throughput之间的关系是一个平衡和优化的问题。需要根据你的硬件配置、模型需求和特定的性能目标(例如,最小化延迟或最大化吞吐量)来调整batch size。
参考
https://www.anyscale.com/blog/continuous-batching-llm-inference
https://github.com/NVIDIA/FasterTransformer/issues/696
https://vllm.ai
https://vllm.readthedocs.io/en/latest/
https://arxiv.org/pdf/2301.08721.pdf
https://www.anyscale.com/blog/model-batch-inference-in-ray-actors-actorpool-and-datasets
https://github.com/ray-project/llm-numbers
https://www.anyscale.com/blog/offline-batch-inference-comparing-ray-apache-spark-and-sagemaker

