
- 1Intel SDM 之 APIC Virtualization and Virtual Interrupts
- 2SQL学习(1)——表相关操作_sql对表的操作
- 3OHIF Viewers:下一代医学影像查看器的技术解析与应用
- 4ubuntu下安装wordpress博客系统网站的详细讲解_ubuntu wordpress官网
- 5AppsFlyer 研究(五)延迟深度链接&客户端获取归因数据_appsflyer:there was an error getting deep link dat
- 6微软Edge浏览器深度解析:功能、同步、隐私与安全
- 7mysql5.7安装audit审计插件
- 8网络安全到底是什么?一篇概念详解(附学习资料)
- 9《微信小程序-基础篇》带你了解小程序中的生命周期(二)_小程序声明周期
- 10Threejs实现立体3D园区解决方案及代码_threejs3d智慧园区
基于前后端分离的博客系统 (Servlet)_基于微服务架构的前后端分离的博客系统
赞
踩
基于前后端分离的博客系统 [Servlet]
引言
本次项目用到的技术
协议:HTTP.
前端:HTML, CSS, JavaScript, JS-WebAPI, jQuery.
后端:Servlet, Jackson, JDBC.
数据库:MySQL.
测试:IDEA, Chrome, Fiddler.
本次项目的业务流程
- 搭建项目环境
- 设计数据库
- 根据数据库设计实体类
- 封装数据库
- 定好前后端交互的思路
- 实现页面
一、搭建项目环境
- 创建好目录
- 引入依赖
( Servlet、MySQL、Thymeleaf ) - 往 web.xml 文件中放入一些代码
- 部署程序
( 通过 Smart Tomcat 进行部署 ) - 验证是否就绪
( 通过一个 HelloServlet 类验证 )
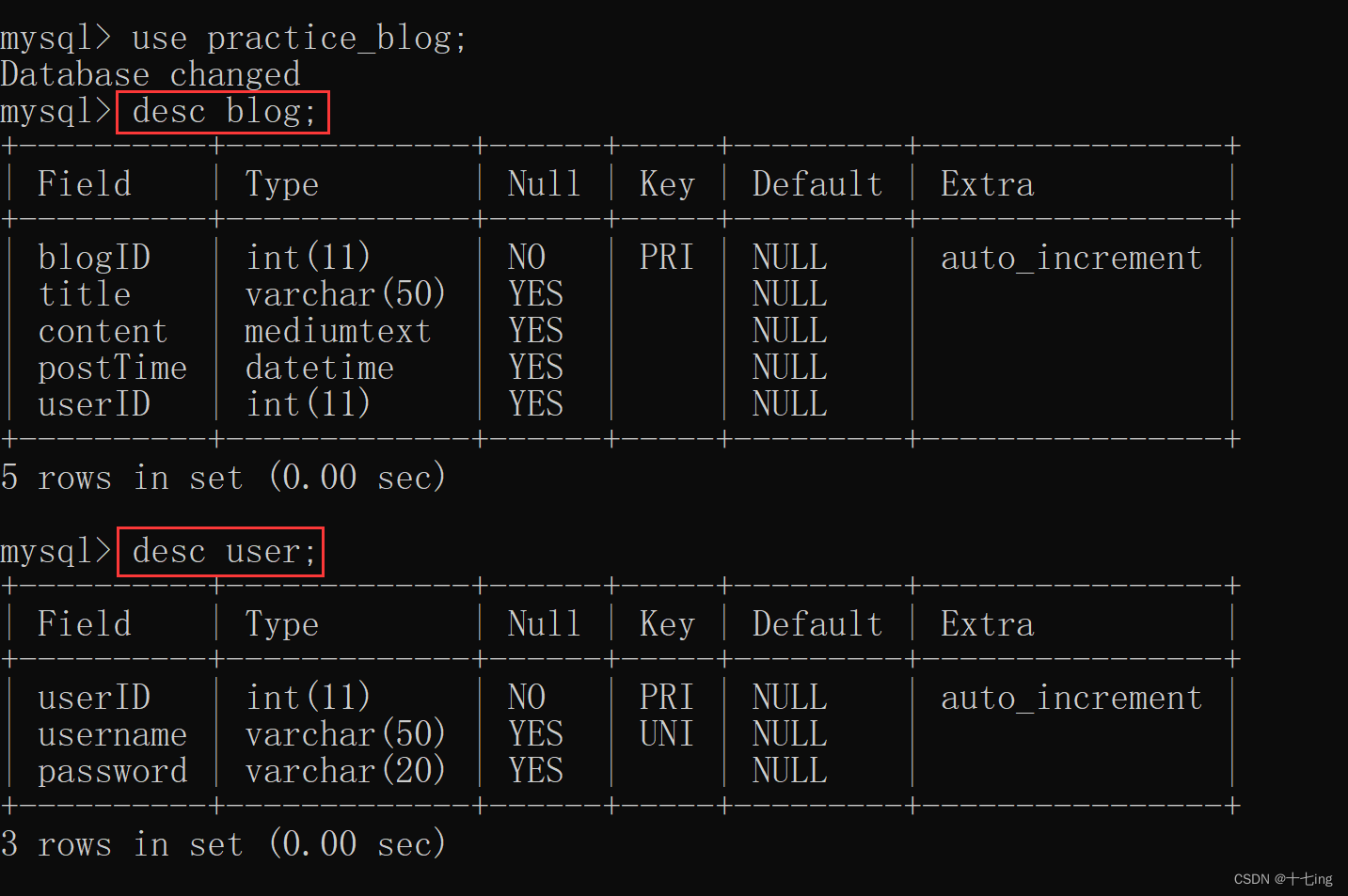
二、设计数据库
- 通过自己写的 sql 语句,往 MySQL 数据库中,插入【blog 表】、【user 表】
【blog 表】 预期用来存储博客的信息 ( 标题、内容、发布时间 )
【user 表】预期用来存储用户的信息 ( 用户账号、用户密码 )
create database if not exists practice_blog;
use practice_blog;
-- 创建博客表
drop if exists blog;
create table blog (
-- 博客 ID (自增主键)
blogID int primary key auto_increment,
-- 博客标题 (字符串类型)
title varchar(50),
-- 博客内容 (字符串类型,表示中等长度文本)
content mediumtext,
-- 博客发布的时间 (日期类型)
postTime datetime,
-- 作者的账号ID
userID int
);
-- 创建用户表
drop if exists user;
create table user (
-- 用户的账号ID (自增主键)
userID int primary key auto_increment,
-- 用户的账号 (保证用户名唯一)
username varchar(50) unique,
-- 用户的密码
password varchar(20)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
三、根据数据库设计实体类
1. Blog 类
public class Blog {
private int blogID;
private String title;
private String content;
private Timestamp postTime;
private int userID;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2. User 类
public class User {
private int userID;
private String username;
private String password;
}
- 1
- 2
- 3
- 4
- 5
四、封装数据库
JDBC 编程步骤
- 创建数据源
- 和数据库建立连接
- 构造 sql 语句并操作数据库
- 执行 sql
- 遍历结果集(select 查询的时候需要有这一步)
- 释放资源
1. 创建一个 DBUtil 类 ( Database Utility )
public class DBUtil {
private static final String URL = "jdbc:mysql://127.0.0.1:3306/practice_blog?characterEncoding=utf8&&useSSL=false";
private static final String USERNAME = "root";
private static final String PASSWORD = "123456789";
// 1. 创建数据源
private static volatile DataSource dataSource = null;
private static DataSource getDataSource() {
if (dataSource == null) {
synchronized (DBUtil.class) {
if (dataSource == null) {
dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setURL(URL);
((MysqlDataSource)dataSource).setUser(USERNAME);
((MysqlDataSource)dataSource).setPassword(PASSWORD);
}
}
}
return dataSource;
}
// 2. 建立连接
public static Connection getConnection() throws SQLException {
return getDataSource().getConnection();
// 实际上返回的是 dataSource.getConnection()
// 让外面的类能够 Connection connection = dataSource.getConnection();
// 即与数据库建立连接
}
// 代码最后,应该记得释放资源
public static void close(ResultSet resultSet, PreparedStatement statement, Connection connection) {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
DBUtil 这个类,用来封装一些数据库的方法,供外面的类使用。
好处一:外面的类需要创建一些同样的实例, 这些实例是固定的。然而,有了DBUtil这个类,外面的类就不需要每次创建额外的实例,直接从 DBUtil 类 拿即可。
( DBUtil 中的单例模式正是做到了这一点)
好处二:同样地,外面的类需要用到一些同样的方法,有了 DBUtil 这个类,对于代码与数据库之间的一些通用的操作方法,直接从 DBUtil 类 导入即可。
我们可以将 DBUtil 这个类想象成一个充电宝,而将使用这个 DBUtil 公共类的其他类,称为手机、平板、mp3…毫无疑问,充电宝就是为电子设备提供服务的,而这些电子设备其实只有一个目的:通过充电宝这个公共资源为自己充电。
2. 封装 BlogDB ( Blog Database )
(1) insert 方法
插入一篇博客,( 博客从浏览器编写,然后上传到服务器,服务器再上传到数据库 )
(2) searchAll 方法
查找所有博客,为了后续展示在博客列表页
(3) searchOne 方法
查找单篇博客,为了后续展示在博客内容页
(4) deleteOne 方法
删除博客,为了后续在浏览器页面上点击生效
(5) findCount 方法
查找当前用户的文章总数
3. 封装 UserDB( User Database )
(1) insert 方法
插入一名用户,( 从前端输入账号和密码上传到服务器,服务器再上传到数据库 )
(2) searchByUsername 方法
通过 username 来查找用户
(3) searchByUserID 方法
通过 userID 来查找用户
五、定好前后端交互的思路
1. 实现每个页面的思想
- 博客列表页
- 博客内容页
- 博客登录页
- 博客编辑页
博客列表页和博客内容页是通过 ajax 发送的 HTTP请求,之后在服务器端计算响应的。前端主要处理页面逻辑,后端主要处理返回数据。
而登录页和编辑页,我们通过 form 表单的形式来构造 HTTP请求。
必须明确:
-
列表页和内容页是通过 浏览器输入 URL 路径这种形式来构造 HTTP 请求的。这种方式,绝大多数情况下,都是一个 GET 请求,所以,我们需要在 Servlet 代码中,构造 GET 响应。
-
登录页和编辑页是通过 form 表单的形式构造 HTTP 请求的,一般和 input 标签相关的提交按钮,都是 POST 方法。
2. ajax 构造 HTTP 请求的格式
由于 ajax 的原生用法较为麻烦,工作中也不太可能用到,所以,我们就通过 JS 引入第三方库 jQuery. jQuery 其实是一个功能非常全面的库,它对 DOM API 进行了非常好的封装。我们只需要在 JS 代码中,引入 jQuery 所在的网络地址,就能直接使用,当然,如果下载到本地,也是可以使用的。(这种方式较为稳定,更为推荐)
在本篇博客中,我是下载到了本地使用,这样对于展示给用户看来说,更为稳定。
<body>
<!-- 引入 jQuery -->
<script src="js/jquery.min.js"></script></script>
<script>
//ajax 方法传参传的是一个大括号对象
$.ajax({
// url 中填写需要访问的服务器地址
url: '',
//这就表示一个 GET 方法
method: 'GET',
//data 就是响应的 body,status 就是响应的状态码
success: function(data, status) {
}
error: function(data, status) {
}
});
</script>
</body>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(1) 理解 success 回调函数
关于 success 这个回调函数:顾名思义,它表示从客户端发送 HTTP 请求成功后,浏览器调用此函数。一般来说,success 其实就意味着 HTTP 响应的状态码是 200.
回调函数并不是自己调用,而是让浏览器在合适的时机自己调用的,这一点需要格外注意。
所以,一般来说,success 这个回调函数中,需要写入的业务逻辑,一般就是为了展示给用户观看的内容。即前端开发人员决定在这里面实现什么给用户看。
问1:那么业务逻辑的数据从哪来?
答:业务逻辑的数据就是从传入的参数 data 中获取到的。
问2:那么 data 从哪来?
答:data 就是从 HTTP 响应的正文 body 来获取的。
问3:正文 body 又从哪来?
答:HTTP 响应的正文 body 其实就是服务器端的代码构造的,常用的就是 json 格式数据,因为 json 格式的数据是可以将很多复杂的文本组合在一起。所以,后端的开发人员,一般通过将 Java 对象转换成 json 格式的数据,放到 响应的 body 中。在本篇博客中,就是以 json 格式的数据放置的,后面会进行细说。
(2) error 回调函数
success 一般对应着 状态码 200,而 error 一般对应着 除 200 之外的状态码。因为顾名思义,在回调函数的业务逻辑中,就是用来处理【客户端发送 HTTP 请求失败的情况】,这些情况可能是路径问题,可能是密码错误问题,也可能是用户权限问题等等…
3. 服务器端往 HTTP 响应中写入 json 格式的数据
问1:为什么在这里写入 json 格式的数据
答:因为 json 格式的数据可以将很多复杂的文本组合在一起,或者说,将一些杂乱无章的字符串组合在一起。此外,实际上我们不可能直接将 Java 对象直接就放入到响应的 body 中。
综上所述,我们可以将 Java 对象转换成一个 json 格式,Java 对象或变量,或数组,或字符串等等…都可以转化成一个 json 格式的数据。也就是说,json 格式的数据能够很好的与 Java 对象进行形式切换,但数据的内容相同,只是格式不同罢了。
这就好像:美国人用英语说 “hello”,中国人用中文说 “你好”,其实是一个意思,但是中国人需要出国留学,就要入乡随俗,此时,中国人也要说英语,才能与美国本土人进行正常沟通。
然而,json 格式本身,是比较复杂的,因为 json 大括号中,可以嵌套很多层的数据,如果直接通过代码解析,这就会增大任务量。所以,更好的办法,就是直接使用第三方库。在 Java 中,能够解析 json 格式的第三方库有很多,这些库的用法和性能方面其实都差不多,在这里,我们使用 Jackson 这样的库,因为 Jackson 是 Spring全家桶中,指定使用的 json 库,后期学习到 Spring 框架的时候,也能够很好地联系起来。
格式:
public class BlogServlet extends HttpServlet {
// jackson 提供的核心类
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置 【写入 HTTP 响应的正文 body 格式】为 json 类型
resp.setContentType("application/json; charset=UTF-8");
// 将 Java 对象转换成一个 json 格式的类型
String jsonData = objectMapper.writeValueAsString(blog);
// 写入 HTTP 响应的正文 body 中
resp.getWriter().write(jsonData);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
六、实现页面
1. 博客列表页
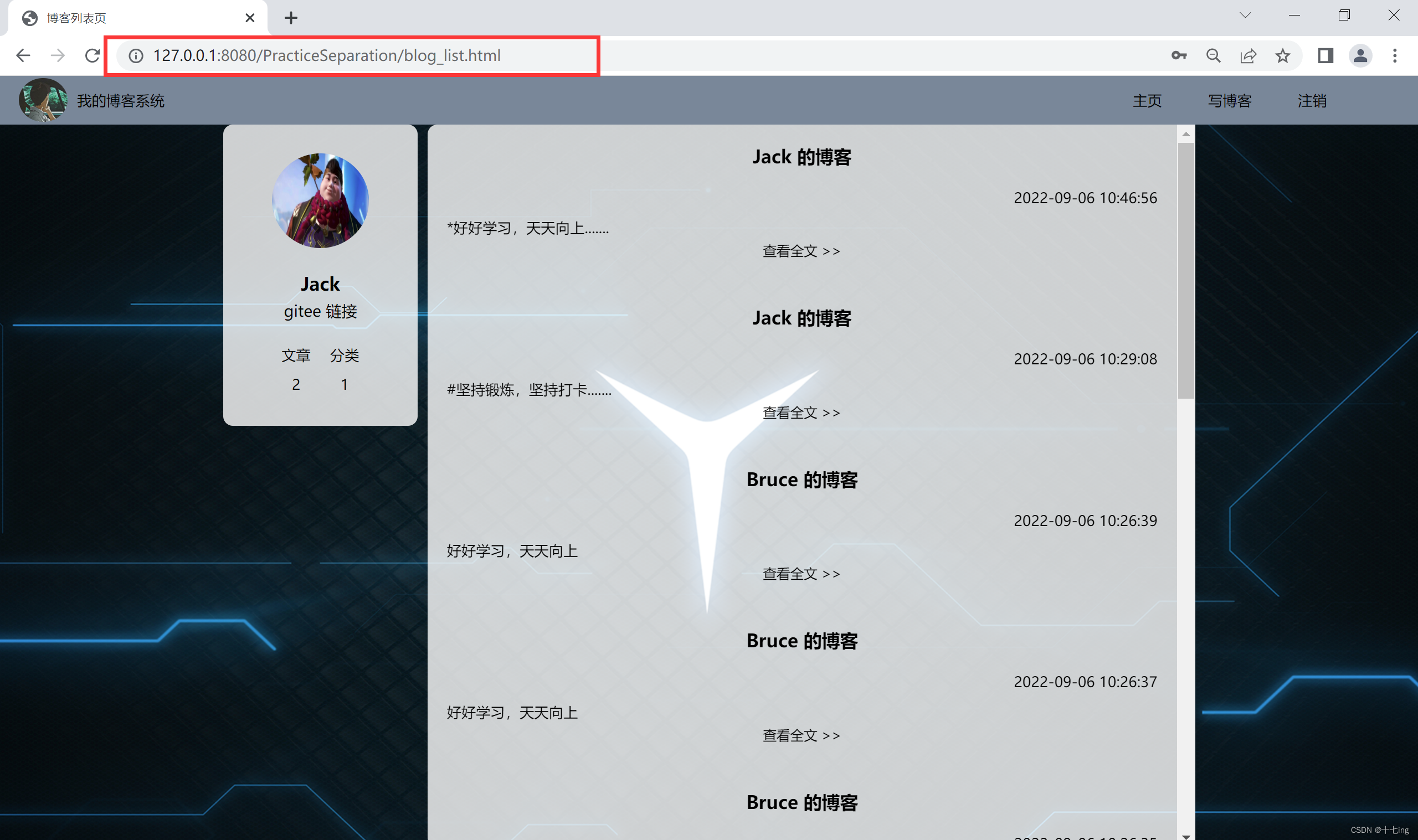
(1) 作用:博客列表页主要用来展示所有博客的摘要
(2) 约定 GET 请求 的路径:" /BlogList "(前端通过 ajax 这种方式来构造请求)
思想:先按照纯前端代码创建相应的节点,之后再挂在 DOM 树上。
这里需要注意一个点: 为什么这里的节点需要先创建,再往 DOM 树上插入呢?难道直接进行 innerHTML 这个方法进行替换不行吗?答案是否定的,因为一旦进行替换,只能更换固定几行代码,而这里是要展示所有的博客摘要,这需要对应着纯前端代码,一个一个创建出来。
<script src="js/jquery.min.js"></script>
<script>
$.ajax({
url: 'BlogList',
method: 'GET',
success: function(data, status) {
// 思想: 先按照纯前端代码创建相应的节点, 之后再挂在 DOM 树上
let blogs = data;
let rightDiv = document.querySelector('.type_area .right');
for (let blog of blogs) {
let blogDiv = document.createElement('div');
blogDiv.className = 'blog';
// 博客标题
let titleH3 = document.createElement('h3');
titleH3.innerHTML = blog.title;
titleH3.className = 'title';
// 博客格式化日期 (年月日-时分秒)
let dateDiv = document.createElement('div');
dateDiv.innerHTML = formatDate(blog.postTime); // 此处的 postTime 原先是一个毫米级的时间戳, 应该转换成格式化的日期
dateDiv.className = 'date';
// 博客摘要
let abstractDiv = document.createElement('abstract');
abstractDiv.innerHTML = blog.content; // 这里在服务器端已经将截取了字符串
abstractDiv.className = 'abstract';
// 跳转博客内容页的链接
let linkA = document.createElement('a');
linkA.innerHTML = '查看全文 >>';
linkA.href = 'blog_content.html?blogID=' + blog.blogID;
// 最后,将所有准备好的节点挂在 DOM 树上
blogDiv.appendChild(titleH3);
blogDiv.appendChild(dateDiv);
blogDiv.appendChild(abstractDiv);
blogDiv.appendChild(linkA);
// 最后最后一步, 将 blogDiv 这样的一个一个 blog 盒子挂在博客展示栏上
rightDiv.appendChild(blogDiv);
}
}
})
<script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
(3) 针对服务器端代码:创建一个 BlogListServlet 来处理计算响应,在此类中,我们为 HTTP 响应的正文 body 写入 json 格式的数据。
@WebServlet("/BlogList")
public class BlogListServlet extends HttpServlet {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置 【写入 HTTP 响应的正文 body 格式】为 json 类型
resp.setContentType("application/json; charset=UTF-8");
BlogDB blogDB = new BlogDB();
List<Blog> blogList = blogDB.searchAll();
// 将 Java 对象转换成一个 json 格式的类型
String jsonData = objectMapper.writeValueAsString(blogList);
resp.getWriter().write(jsonData);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
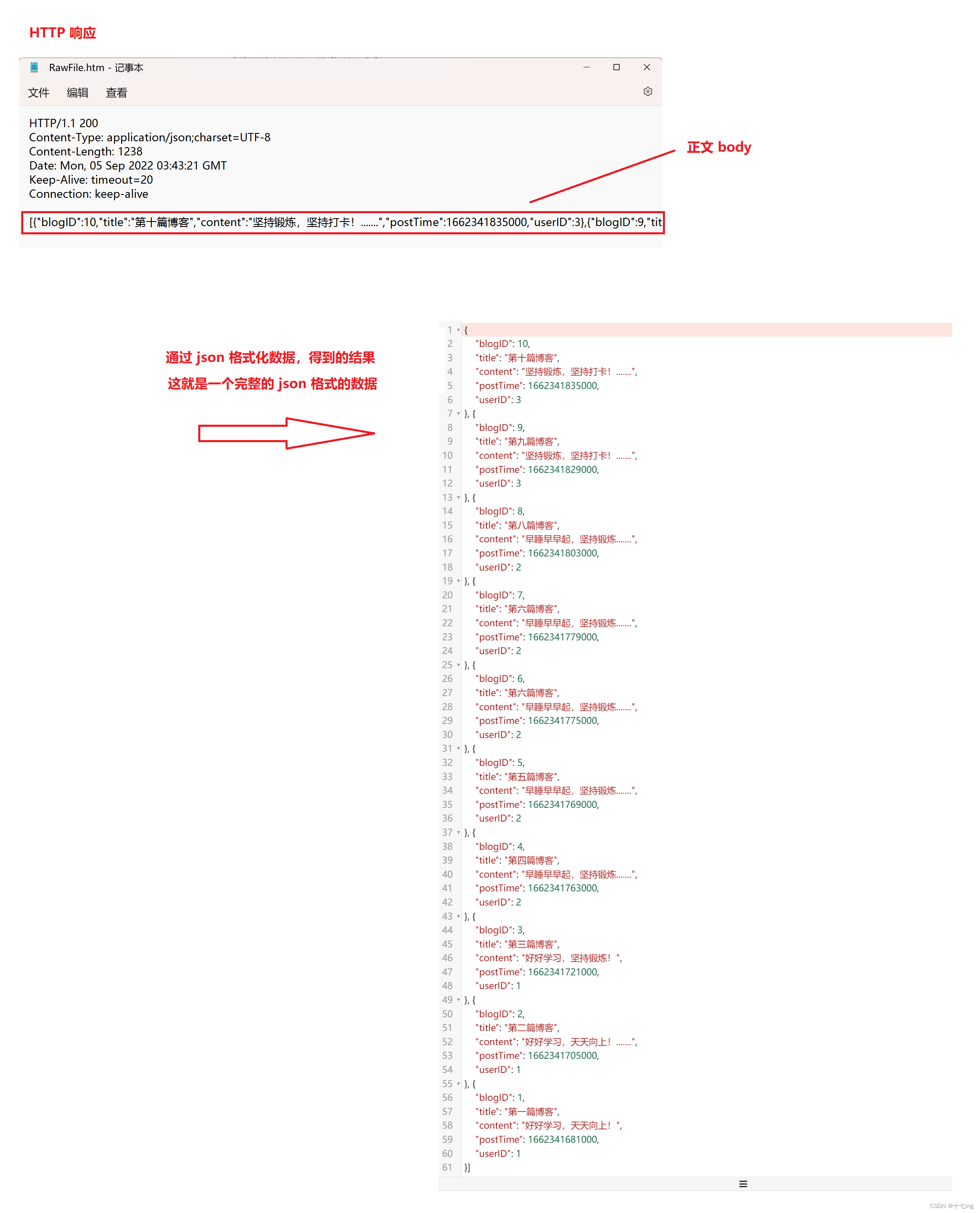
抓包结果:
可以发现,json 中的内容形式实际上是以一种 json 数组的形式呈现出来的。
(4) 通过字符串截取的方式,来控制页面为用户展示的博客字数
(5) 由于页面的内容过长,这就可能导致溢出页面,或者说,内容溢出版心,此时,我们就可以通过设置 CSS 文件来弥补这一缺点。
如下代码:当内容溢出页面的时候,就会自动设置滑动栏,这很实用。
overflow: auto;
- 1
2. 博客内容页
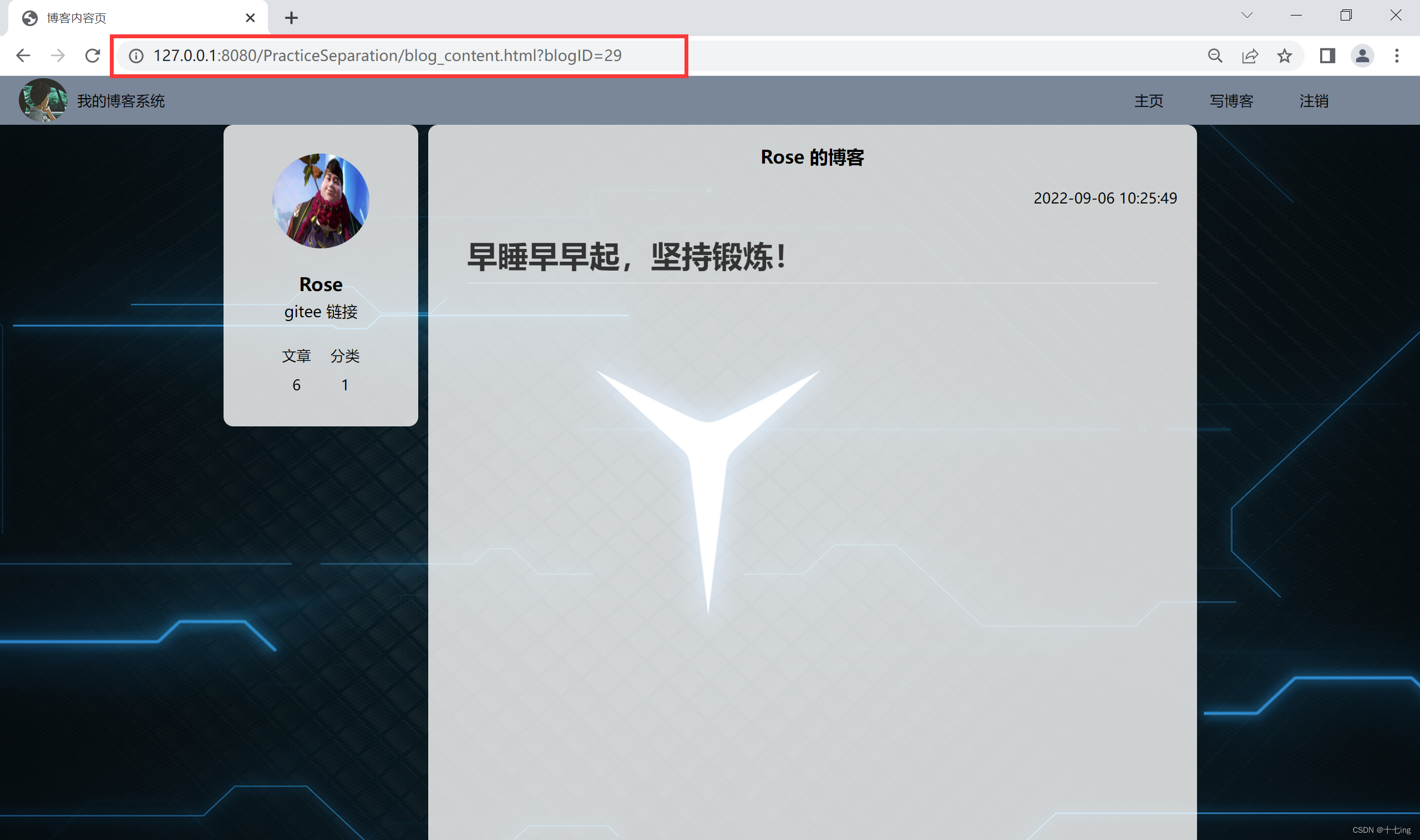
(1) 作用:博客内容页用来展示文章的所有信息
(2) 约定 GET 请求 的路径:" /BlogContent "(前端通过 ajax 这种方式来构造请求)
思想:直接按照前面的纯前端代码,通过 innerHTML 进行替换即可。
这里需要注意一个点: 这里与博客列表页 ajax 中的 success 回调函数不同,由于这里只需要展示一篇博客,所以直接使用 innerHTML 这样的操作,就可以对标签值进行替换。这给人一种模板渲染的感觉,只不过,这里的实现方式都是需要通过 前端的 JavaScript 代码进行完成的,而模板引擎需要前后端配合才行。
<!-- 基于 ajax 的方式来从服务器中获取数据 -->
<script src="js/jquery.min.js"></script>
<!-- 当前的 ajax 请求是期望展示单篇博客的内容 -->
<script>
$.ajax({
url: 'BlogContent' + location.search,
method: 'GET',
success: function(data, status) {
let blog = data;
// 博客标题
let titleH3 = document.querySelector('.blog .title');
titleH3.innerHTML = blog.title;
// 博客格式化日期
let dateDiv = document.querySelector('.blog .date');
dateDiv.innerHTML = formatDate(blog.postTime);
// 单篇博客的内容
let contentDiv = document.querySelector('.blog .content');
contentDiv.innerHTML = blog.content;
}
})
<script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
注意:
关于 ajax 代码,我们还需注意一个点,为什么博客内容页 ajax 对应的 url 是下面这样的?
url: 'BlogContent' + location.search,
- 1
而博客列表页的 ajax 中的 success 函数的跳转链接又是为什么写成下面这样的?
linkA.href = 'blog_content.html?blogID=' + blog.blogID;
- 1
其实 【 location.search 】其实就是对应着【 blog.blogID 】,只不过这是通过 JS 代码的方式呈现出来的而已,它代表获取当前 HTTP请求的参数。
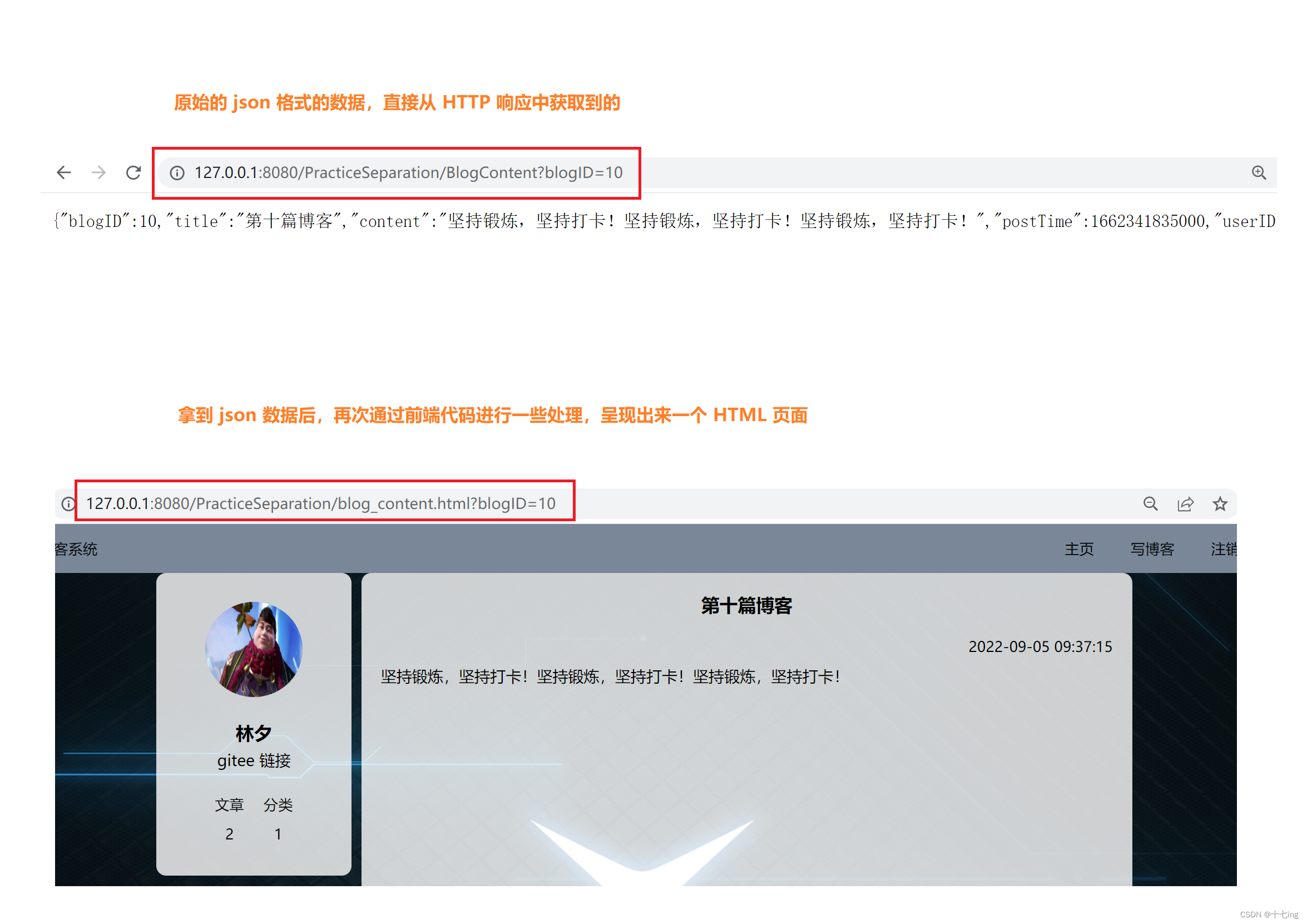
而为什么 url 中是 ’ BlogContent ',而 href 中的路径是 ’ blog_content.html ’ 呢?
实际上,这两者从访问路径的角度看是一样的,但从展示给用户的角度看,却是不一样的,因为 前者拿到的是一个未经过任何处理的 json 文本数据,而后者是通过 JS 代码中的 success 处理后的 HTML界面。
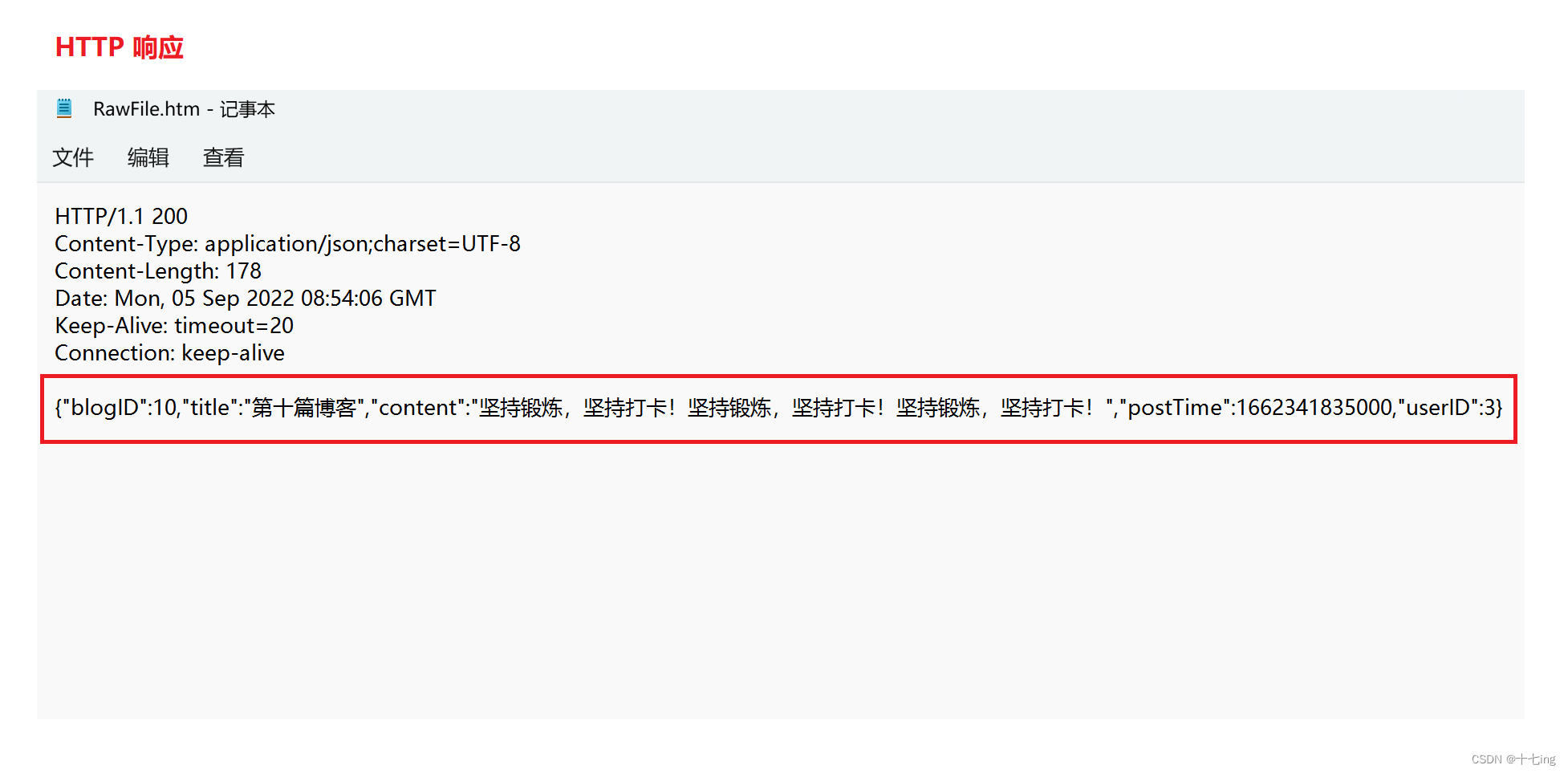
(3) 针对服务器端代码:创建一个 BlogContentServlet 来处理计算响应,在此类中,我们为 HTTP 响应的正文 body 写入 json 格式的数据。显而易见,这里的 json 数据只是对应着 Java 一个 blog 对象。
@WebServlet("/BlogContent")
public class BlogContentServlet extends HttpServlet {
ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setCharacterEncoding("UTF-8");
resp.setContentType("application/json; charset=UTF-8");
String blogID = req.getParameter("blogID");
BlogDB blogDB = new BlogDB();
Blog blog = blogDB.searchOne(Integer.parseInt(blogID));
// 将 Java 对象转换成 json 格式的数据格式
String jsonData = objectMapper.writeValueAsString(blog);
resp.getWriter().write(jsonData);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
抓包结果:
3. 博客登录页
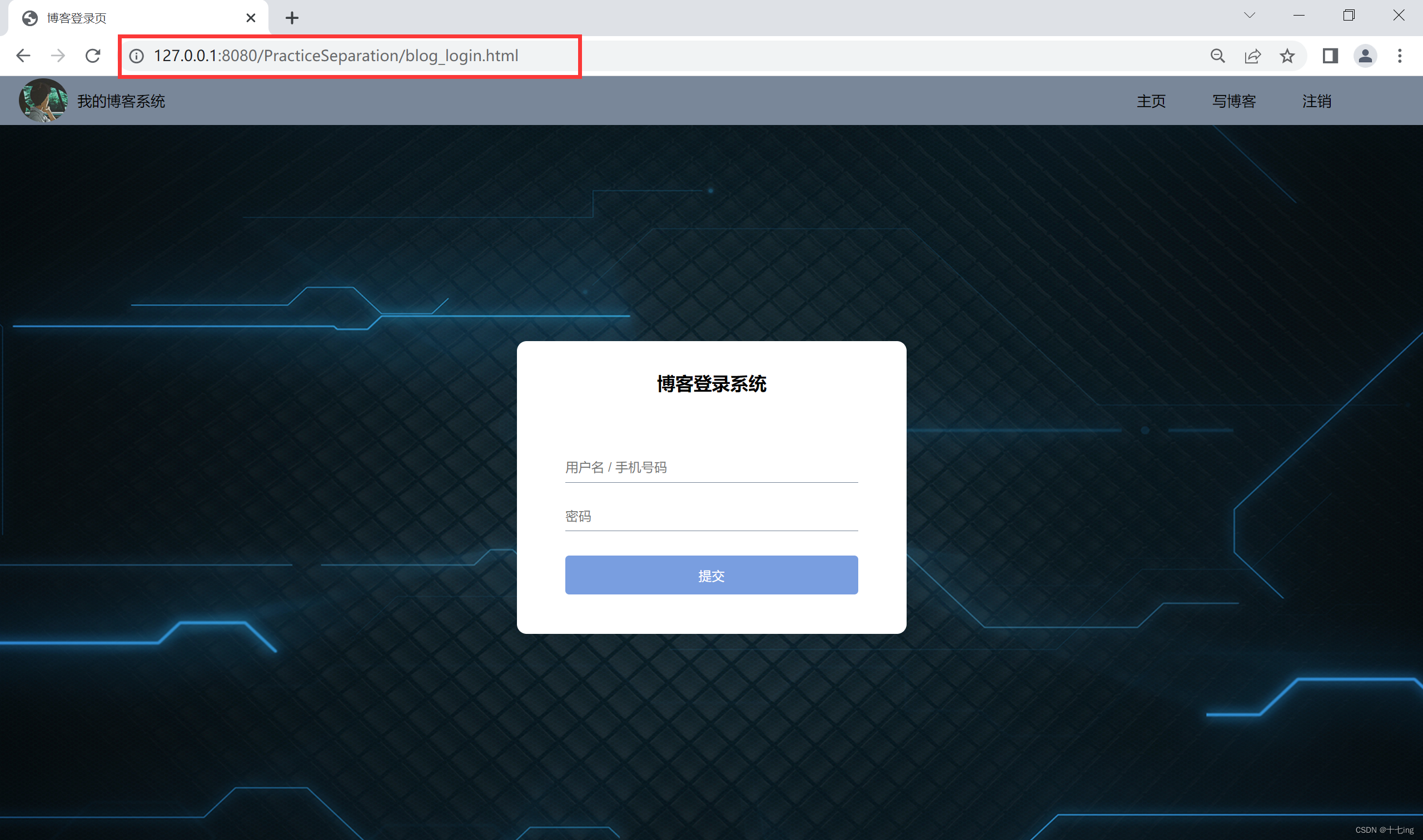
(1) 作用:博客登录页是用于实现用户登录的页面,它可以判断用户名和密码各自是否正确。
(2) 约定 POST 请求 的路径:" /BlogLogin "
我们打开写死的博客登录页面,点击【登录】,浏览器自然就发送了 POST 请求,因为我们将【登录】放在了 form 表单下,通过 input 标签实现的。
(3) 针对前端代码:通过 form 表单进行 HTTP 请求的提交,在提交的过程中,需要带上 【username】 和【password】这两个参数,以便于服务器端进行验证。
(4) 针对服务器端代码:创建一个 BlogLoginServlet 来实现 HTTP 响应,登录成功后,预期跳转到博客列表页。
(5) 博客登录页这里,并不需要展示什么,所以,此页面也无需通过 ajax 的方式进行构造 HTTP 请求,直接通过 form 表单的形式提交请求,这会让整个登录流程变得更加简单。此外,这里的 if 语句进行判断,我们应该考虑到所有的意外情况与不合理的情况
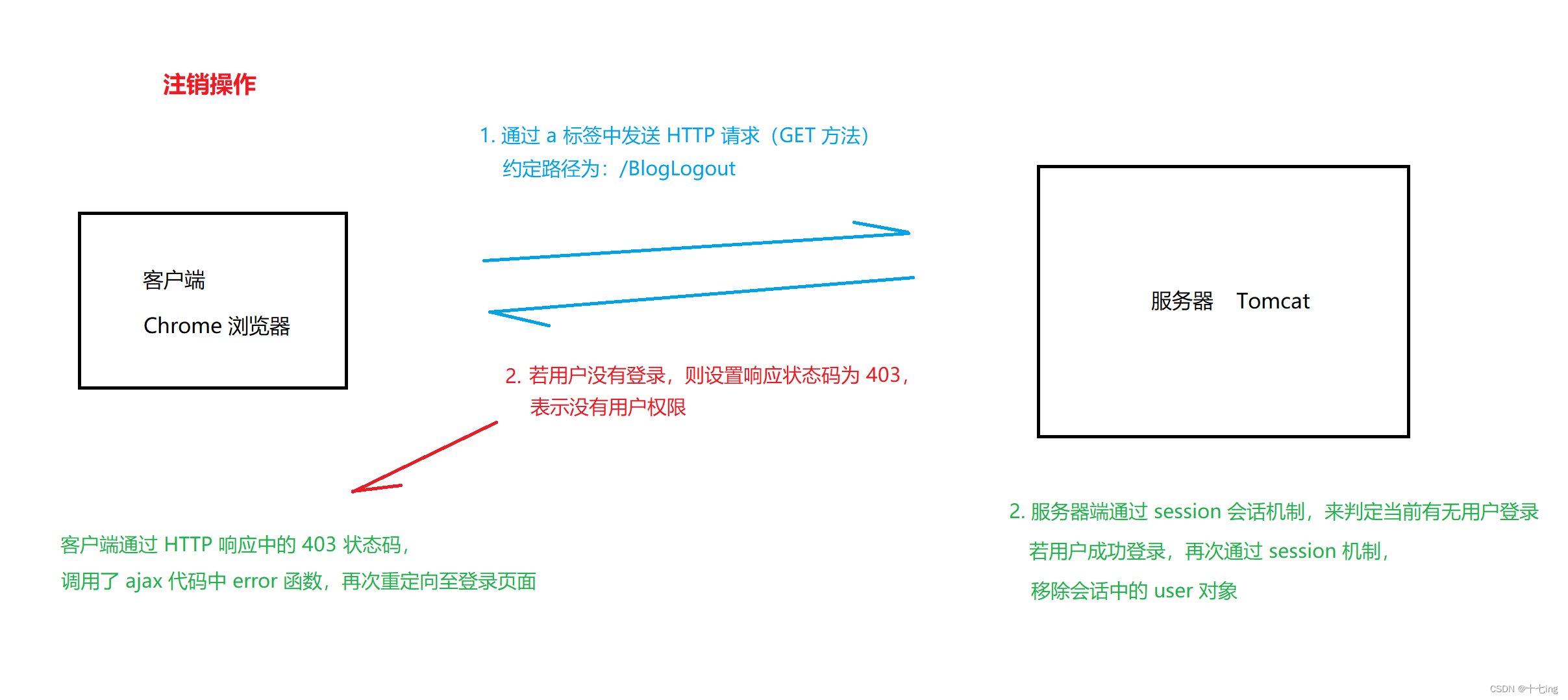
(6) 登录页面的时候,我们可以利用 session 机制。
若登录成功,就将 session 会话创建出来,并将当前登录的用户,以 Java 对象的方式放入会话 session 中,以备后用。若登录失败,就不将 session 会话创建出来。
我们也可以反过来思考:若 session 会话未被创建出来,那就意味着登录失败。
session 机制就和之前的 ServletContext 机制差不多,我们可以将其想象成一个冰箱,随拿随放。
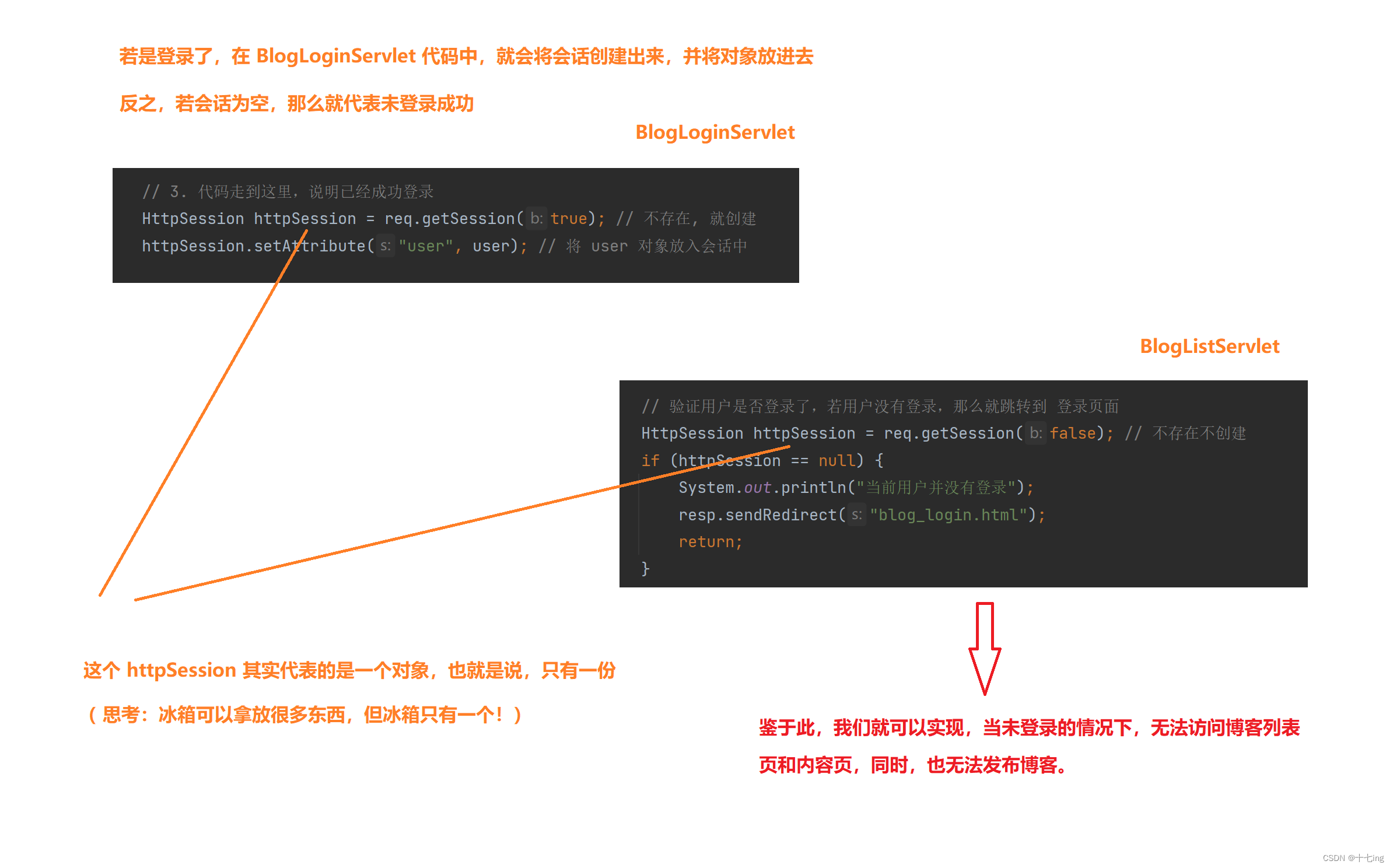
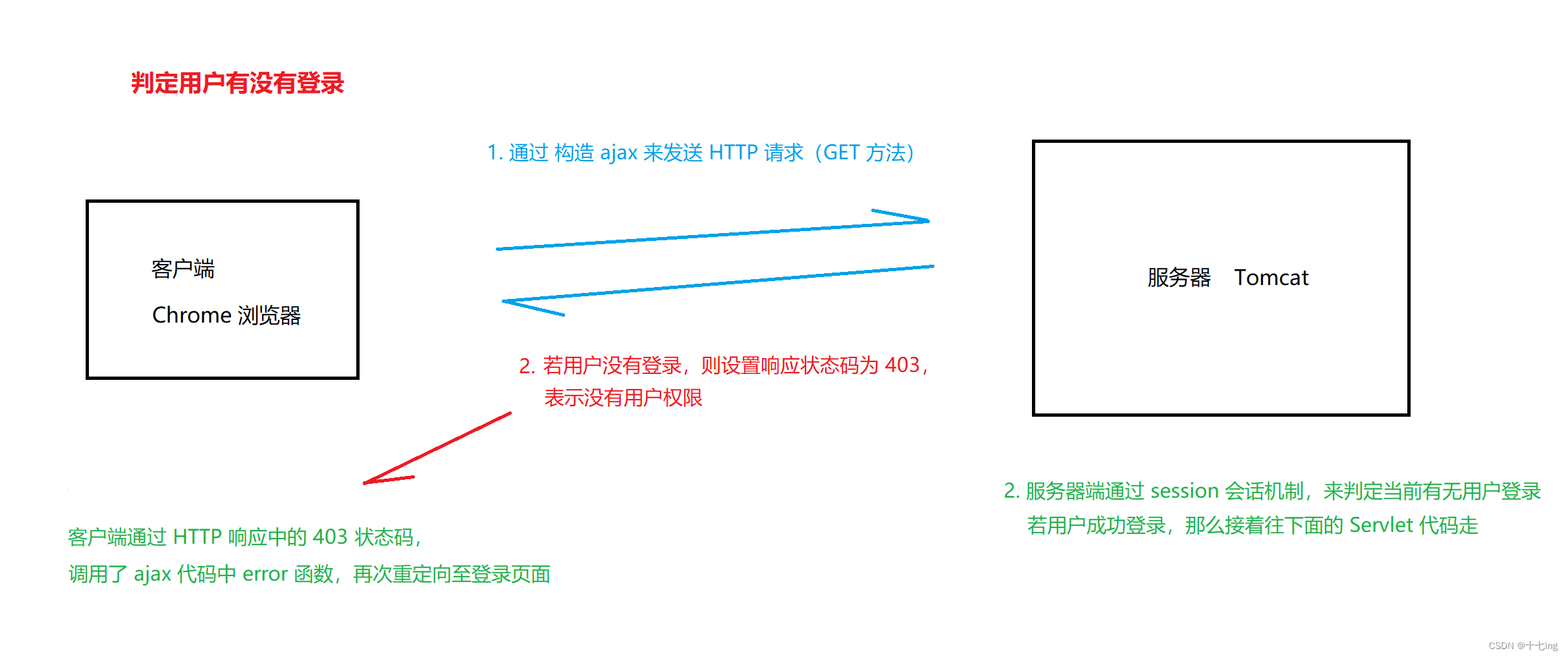
(1) 判定登录与注销操作
鉴于上面的思想,我们不仅可以用当前的 session 会话机制判断博客列表页,也可以用它来判断博客内容页,博客发布页的用户登录情况。此外,通过会话机制,也能够应用于注销操作。
所以,我们对上面的代码改进一下,封装一个 Check 类,让上面所说的页面都能够通过这个 Check 类来判断当前用户是否登录了。
public class Check {
public static User CheckLogin(HttpServletRequest req) {
HttpSession httpSession = req.getSession(false);
if (httpSession == null) {
// 会话未创建出来,意味着用户未登录
return null;
}
User loginUser = (User) httpSession.getAttribute("user");
if (loginUser == null) {
// 就算会话创建出来了,但是里面没有对象,也意味着用户未登录
return null;
}
return loginUser;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意 if 语句的顺序,为什么先要判定 httpSession 存在与否呢?这是为了防止空指针异常。【 若 httpSession 为 null,那么,httpSession.getAttribute(“user”) 这行代码就会出现空指针异常 】。
这很好理解:当冰箱都没有的时候,我们怎么从冰箱拿东西呢?所以说,一定是先有冰箱了,我们才能从里面拿东西,才能往里面放东西。
图解验证登录与注销用户的思想:
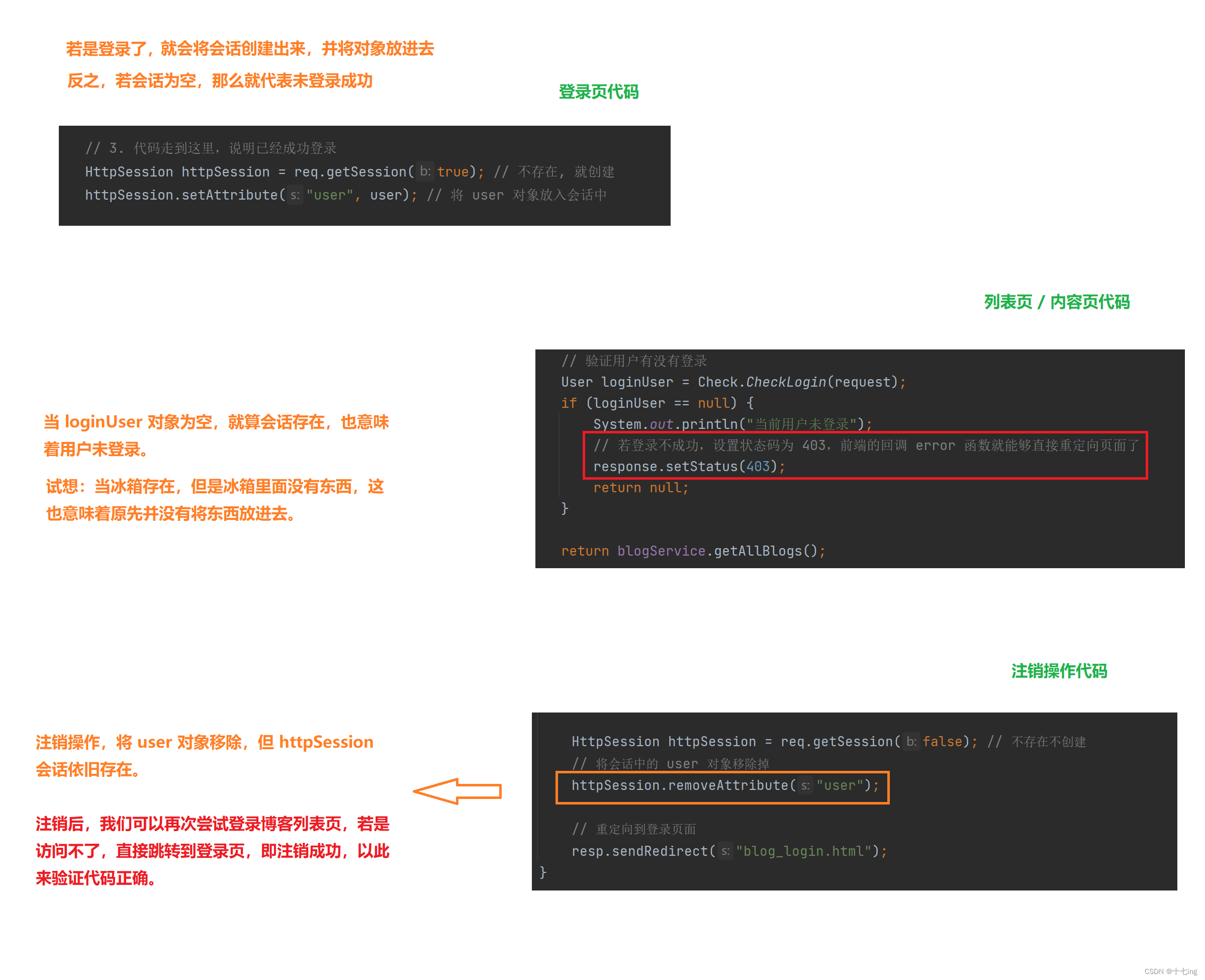
① 注意
这里需要注意一件事情,当用户没有登录的时候,就访问了博客列表页或博客内容页,应该马上让 HTML 页面再次重定向至登录页面。而在当前的 ajax 方式,我们应该让前端去处理重定向操作。这里我们并不建议在后端进行重定向操作,为什么呢?
因为,使用 ajax 这种方式构造 HTTP 请求的时候,服务器端只负责在 HTTP 响应中写入数据,比方说:它应该写入状态码、正文 body、body 格式等等…而前端就应该根据拿到的 HTTP 响应的数据,决定实现什么样的前端页面与样式,所以说,在这里,所有展现给用户看的内容和格式,都应该由前端负责。
然而,如果我们通过服务器端的重定向操作来实现也不是不可以,但会出现一定的问题,例如:重定向之后的页面,展示的效果可能不是一个 HTML 页面,而是一些未经处理的文本数据。
在【基于模板引擎的博客系统】的那个版本中,通过服务器端实现重定向是可以的,因为模板渲染的所有逻辑都是由 Servlet 代码实现的,而前端只是负责提供模板。
② 正确的前后端判定代码
服务器端自定义写入状态码:
403 这个状态码表示的是访问被拒绝,页面通常需要用户具有一定的权限才能访问。
(403 Forbidden)
// 验证用户有没有登录
User loginUser = Check.CheckLogin(req);
if (loginUser == null) {
System.out.println("当前用户未登录");
// 若登录不成功,设置状态码为 403
// 跳转页面的操作,应该在前端写
resp.setStatus(403);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
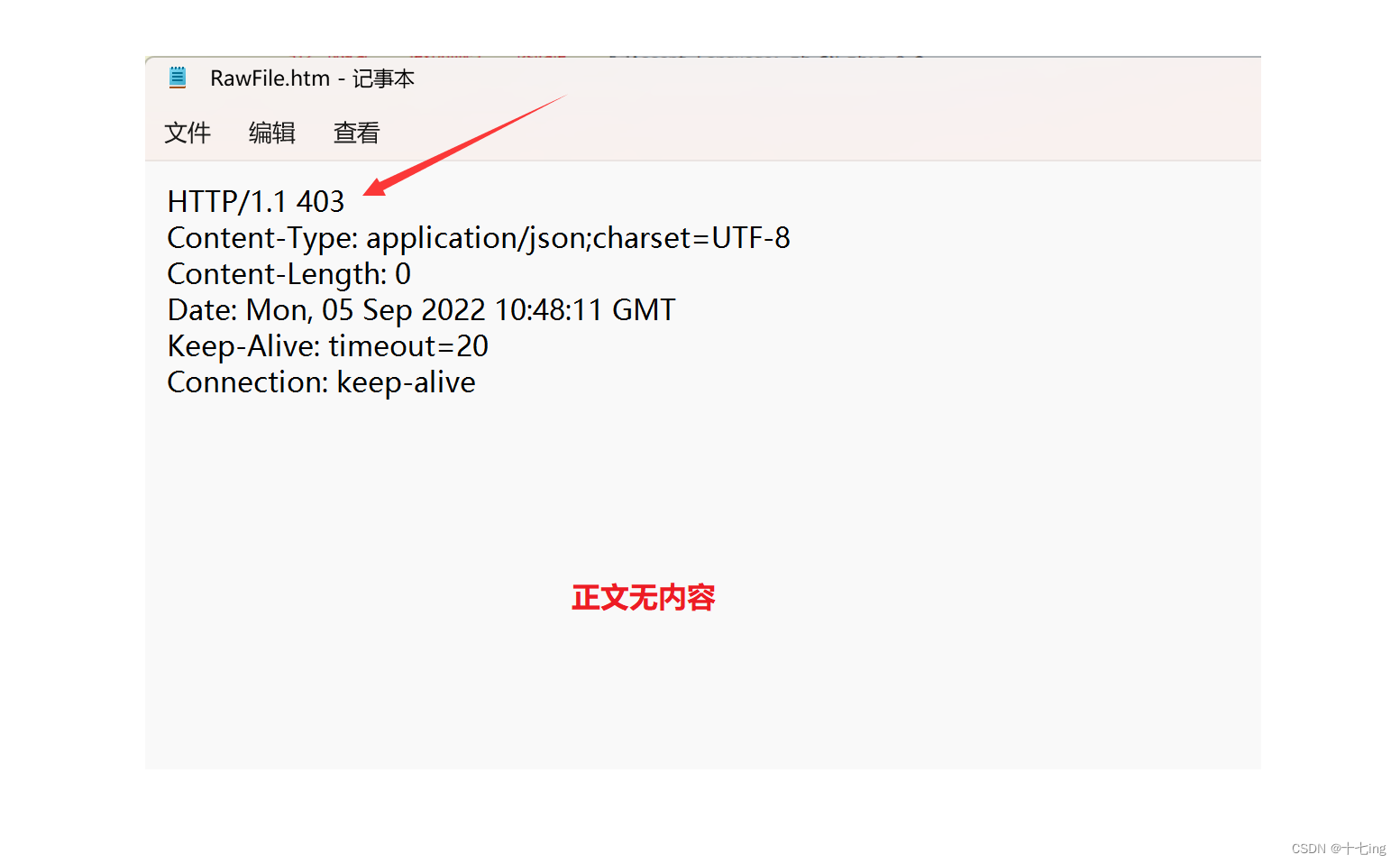
前端重定向操作:
error: function() {
// 此处表示前端形式的重定向, 相当于后端的 resp.sendRedirect()方法
location.assign('blog_login.html');
}
- 1
- 2
- 3
- 4
我们前面提到:error 这个回调函数,表示的是:当发送 HTTP 请求失败的时候,就会被浏览器执行。显然,它会执行了除 【200】 额外的一些状态码,所以,在 error 中的业务逻辑,我们就可以实现一个重定向操作。
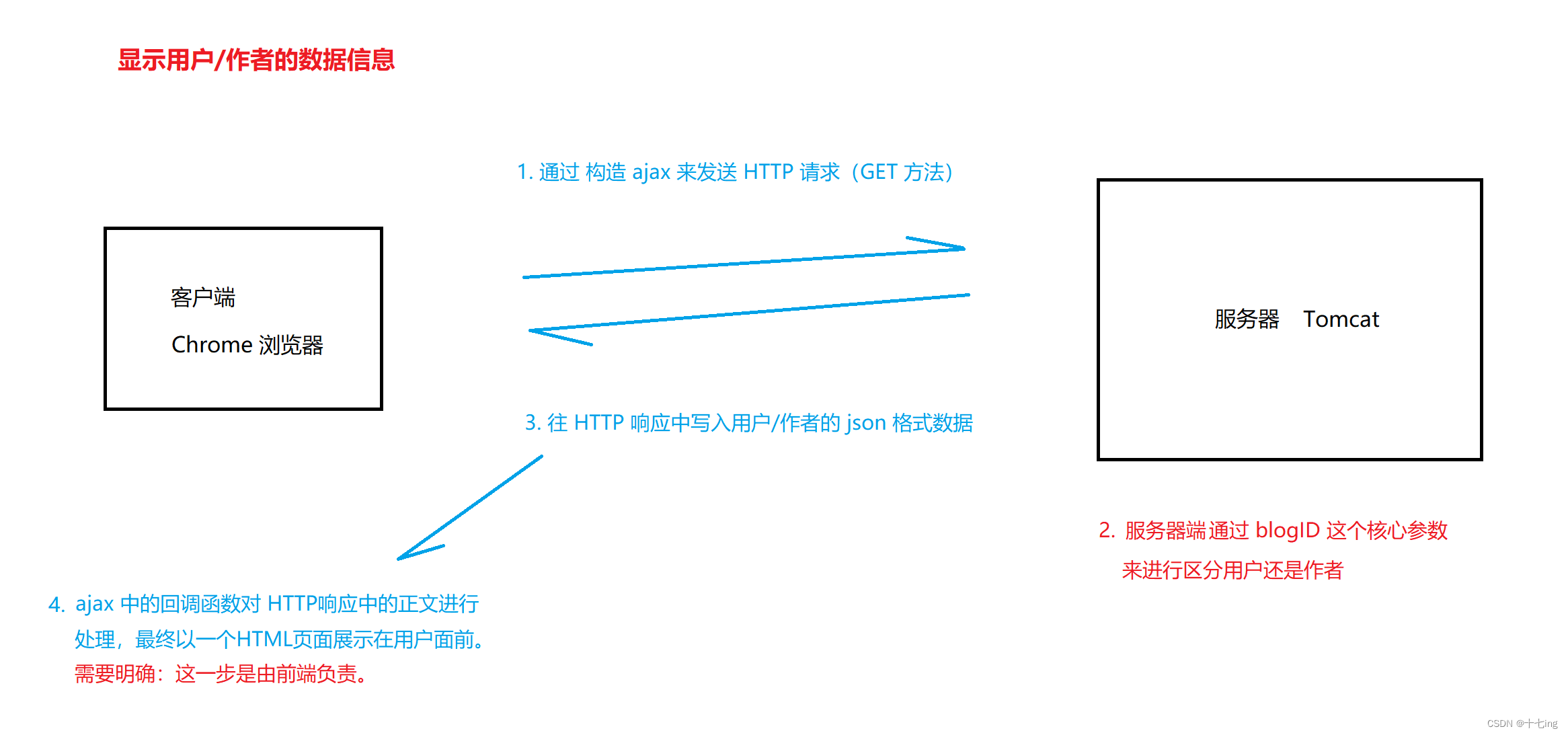
(2) 登录用户与文章作者的数据信息
当用户登录成功后,首先跳转到的是博客列表页,那么,博客列表页就应该显示当前用户的一些信息:头像、昵称、文章总数…接着,若用户点击【查看全文】后,就可以跳转到某一篇博客全文,此时,页面显示的应该是作者信息。
鉴于此,
(1) 将博客列表页展示当前登录者的用户信息
(2) 将博客内容页展示文章作者的用户信息
这里就不再展示代码了,它的思想其实和上面的博客内容页的 ajax 思想是相同的,先选中 DOM 树的节点,再对其标签的内容进行更改。同样地,后端应该利用 blogID 这个参数和 session 会话机制,来确定谁是作者,谁是当前登录的用户。
展示效果:
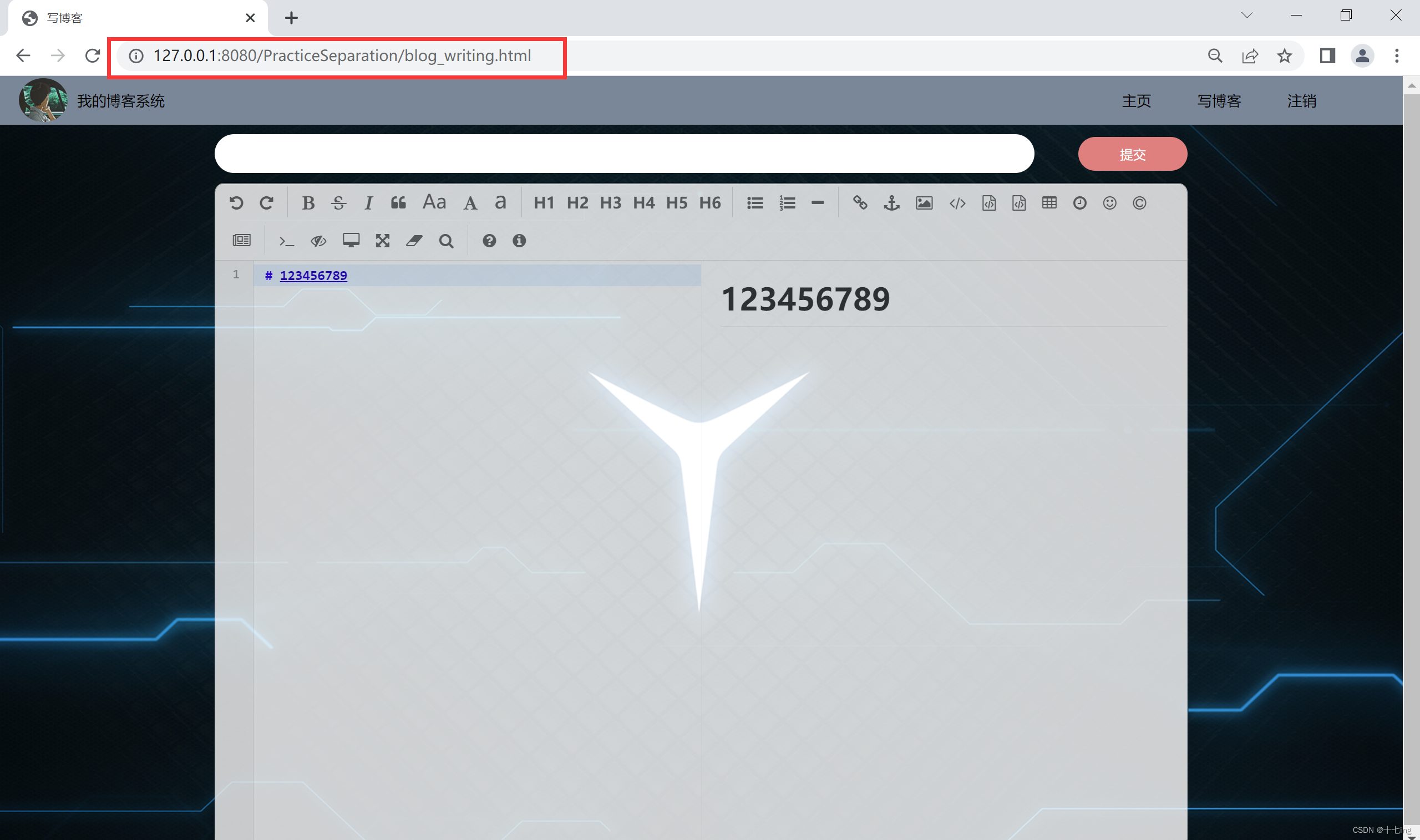
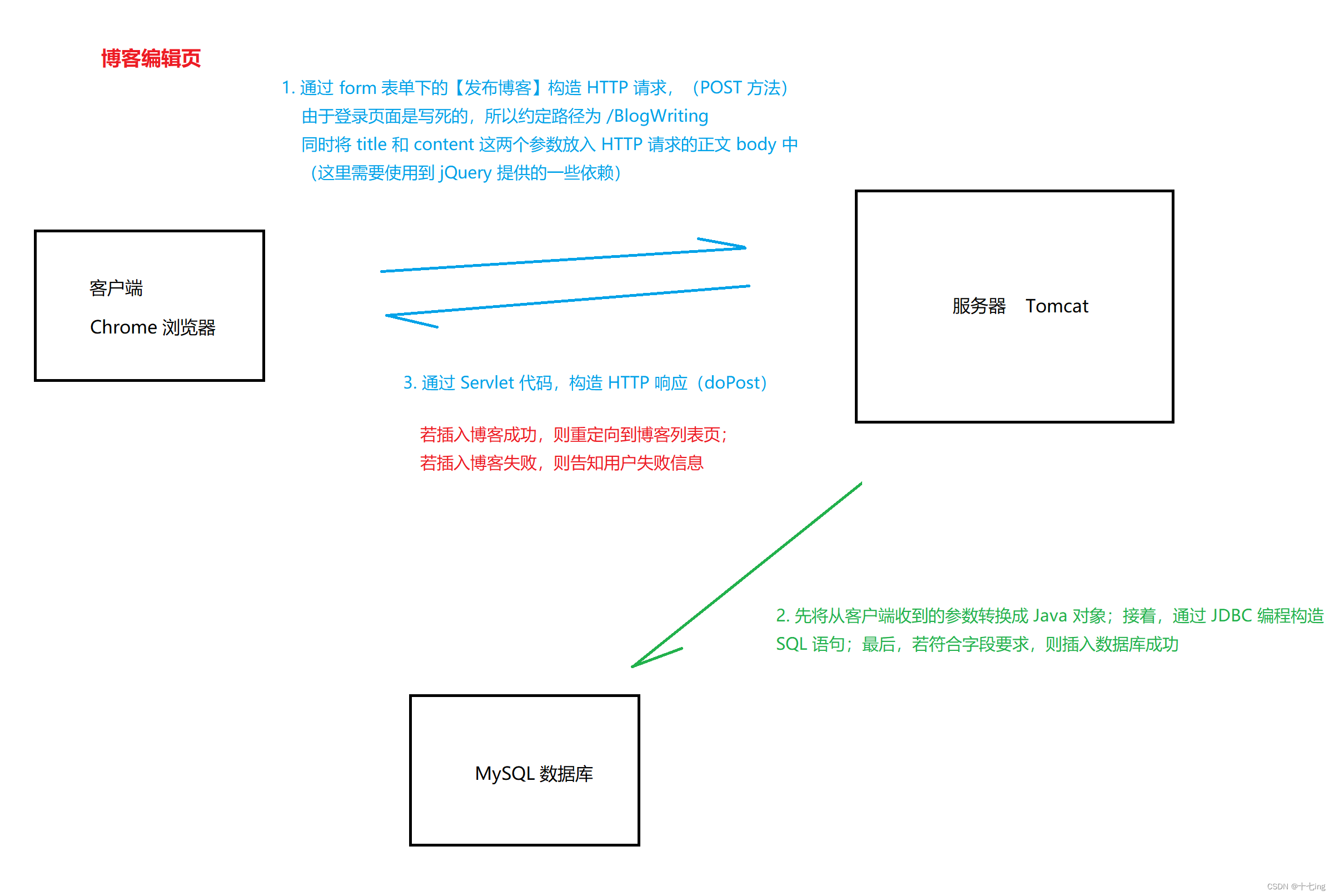
4. 博客编辑页
(1) 作用:博客编辑页是实现让用户用来撰写博客的,它可以在浏览器上进行提交,而后,服务器经过一些处理,让博客的一些数据放入数据库中。
(2) 约定 POST 请求 的路径:" /BlogWriting "
我们打开写死的博客编辑页面,点击【发布文章】,浏览器自然就发送了 POST 请求,因为我们将【发布文章】放在了 form 表单下,通过 input 标签实现的。
(3) 针对前端代码:通过 form 表单进行 HTTP 请求的提交,在提交的过程中,需要带上 【title】 和【content】这两个参数,以便于服务器端进行验证。
然而,这里的代码较为少见,因为当前是根据 jQuery 提供的依赖,才会有这个编辑页面的展示效果,所以,写死的 HTML页面同时需要配合 JS 代码,并且需要基于 【editor.md】的一些写法规则。
</body>
<!-- 版心 -->
<div class="mark">
<form action="BlogWriting" method="POST" style="height: 100%;">
<!-- 标题编辑区 -->
<div class="headline">
<input type="text" class="title" name="title">
<!-- <button class="submit">发布文章</button> -->
<input type="submit" class="submit">
</div>
<!-- mardown 编辑区 -->
<div id="editor">
<textarea name="content" style="display : none"></textarea>
</div>
</form>
</div>
<script>
// 初始化编译器
let editor = editormd("editor", {
//这里的尺寸必须在这里设置,设置样式会被 editormd 覆盖掉
width: "100%",
//设置编译器高度
height: "calc(100% - 60px)",
//编译器的初始内容
markdown: "# 在这里写下一篇博客",
//指定 editor.md 依赖的插件路径
path: "editor.md/lib/",
// 加上这个选项之后,编辑器中的内容才会被放到 textarea 里面
saveHTMLToTextArea: true
});
</script>
</body>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
(4) 针对服务器端代码:创建一个 BlogWritingServlet 来实现 HTTP 响应,登录成功后,预期跳转到博客列表页。
(5) 博客编辑页这里,和博客登录页是一样的思路,并不需要展示什么,所以,此页面并不需要基于 ajax 构造请求。此外,这里的 if 语句进行判断,我们应该考虑到所有的意外情况与不合理的情况。
(6) 由于编辑博客的时候,它是依据 markdown 的语法规则,可以让一些字体变成我们想要的格式,例如:一级标题,二级标题,加粗,删除线等等…
我们当前的 CSDN 就是拥有这样的规则。
而在之前的博客列表页显示博客的时候,它是一种素的、原始的文字。就算经过博客发布了,但展示给用户看的时候,并没有经过博客编辑器处理,所以,同样地,我们为博客列表页引入 【editor.md】这样的依赖,并通过 JS 代码,让文字变成处理后的结果。
success: function(data, status) {
let blog = data;
// 博客标题
let titleH3 = document.querySelector('.blog .title');
titleH3.innerHTML = blog.title;
// 博客格式化日期
let dateDiv = document.querySelector('.blog .date');
dateDiv.innerHTML = formatDate(blog.postTime);
// // 单篇博客的内容
// let contentDiv = document.querySelector('.blog .content');
// contentDiv.innerHTML = blog.content;
// 把得到的 json 数据按照 markdown 的方式处理好,放到 id 为 content 的标签中
editormd.markdownToHTML('content', {markdown: blog.content});
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
实现思想:
markdown 的原始内容,放在上面的 div 中,我们可以将这个 div 中的内容通过 markdownToHTML 函数进行替换。
展示效果:

删除博客
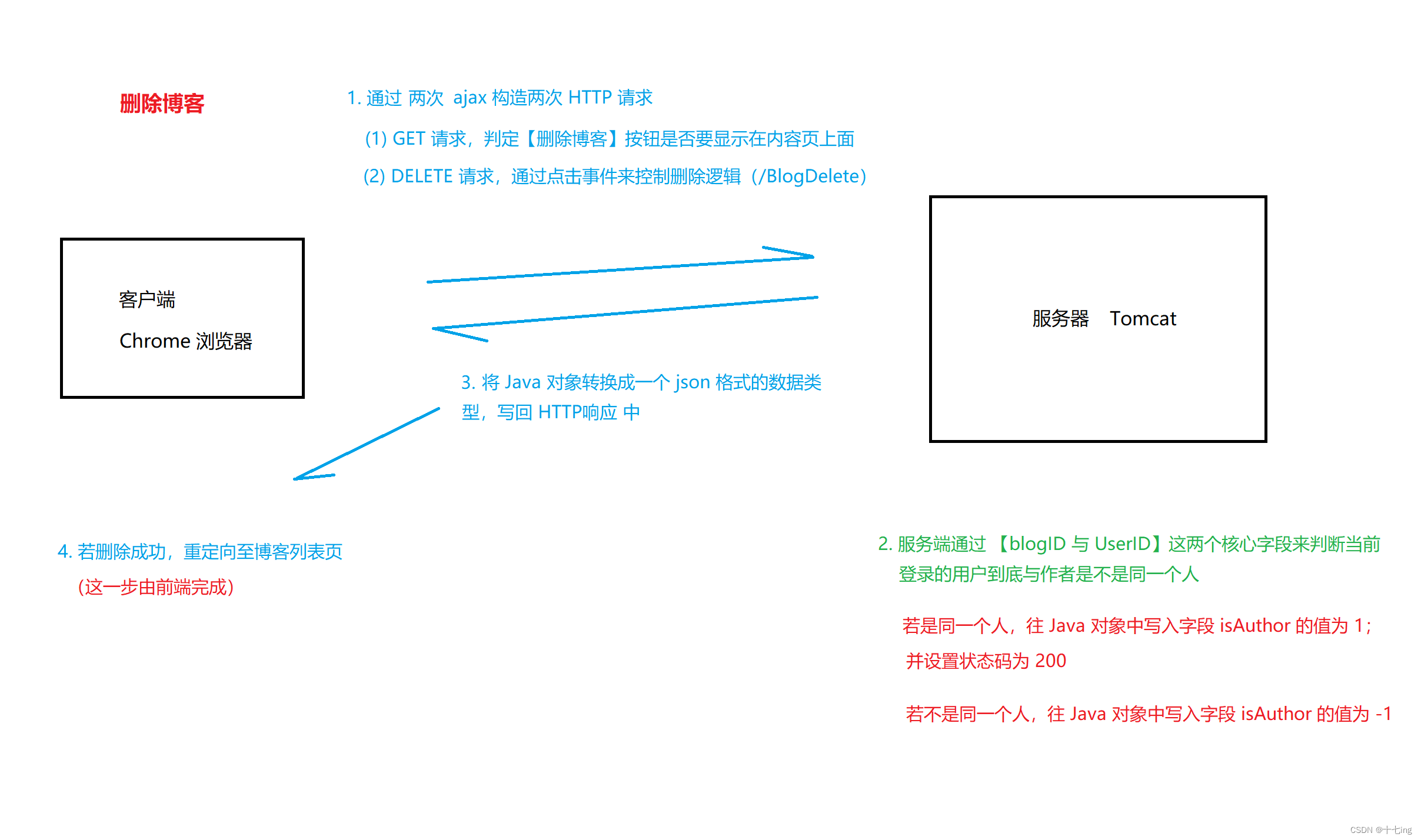
删除博客,通过 a 标签构造 DELETE 请求,之后在服务器端进行处理。
思想:在博客内容页,若当前登录用户和博客作者是同一个人,即可以删除;若不是同一个人,则不能删除,只能观看。
ajax 构造的 HTTP 请求:
<!-- 当前的 ajax 请求是期望删除一篇博客 -->
<script>
$.ajax({
url: 'BlogContent' + location.search,
method: 'GET',
success: function(data, status) {
let blog = data;
// 如果 传入的 blog.isAuthor 数据为1,那么就执行下面的语句
// 以此来区分当前博客到底是登录用户还是文章作者
// 如果是文章作者,就显示删除链接,反之,则不显示
if (blog.isAuthor == 1) {
// 删除节点
let deleteA = document.createElement('a');
deleteA.innerHTML = '删除博客';
deleteA.href = '#';
// 因为 a 标签的 href 属性只能生成 GET 请求
// 所以,此处,我们将将 a 标签生成一个点击事件,用 deleteBlog 函数来申请 DELETE 请求
deleteA.onclick = deleteBlog;
// 将删除节点挂在注销节点之前
let navDiv = document.querySelector('.nav');
let logoutA = document.querySelector('.nav .logout');
navDiv.insertBefore(deleteA, logoutA);
}
}
})
function deleteBlog() {
// 在这个函数中,再次通过 ajax 构造请求
$.ajax({
url: 'BlogDelete' + location.search,
method: 'DELETE',
success: function(data, status) {
// 如果删除成功,就让页面重定向到博客列表页
location.assign('blog_list.html');
}
})
}
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
服务器端构造的响应:
@WebServlet("/BlogDelete")
public class BlogDeleteServlet extends HttpServlet {
@Override
protected void doDelete(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setCharacterEncoding("UTF-8");
//resp.setContentType("application/json; charset=UTF-8");
resp.setContentType("text/html; charset=UTF-8");
// 验证用户有没有登录
User loginUser = Check.CheckLogin(req);
if (loginUser == null) {
System.out.println("当前用户未登录");
// 若登录不成功,设置状态码未 403
// 跳转页面的操作,应该在前端写
resp.setStatus(403);
return;
}
// 从 HTTP 请求中读取参数
String blogID = req.getParameter("blogID");
if (blogID == null || blogID.equals("")) {
resp.getWriter().write("<h3> 您未选择要删除哪篇文章 </h3>");
return;
}
BlogDB blogDB = new BlogDB();
Blog blog = blogDB.searchOne(Integer.parseInt(blogID));
if (blog.getUserID() != loginUser.getUserID()) {
resp.getWriter().write("<h3> 您所删除的并不是本人的文章 </h3>");
return;
}
// 删除操作
blogDB.deleteOne(Integer.parseInt(blogID));
// 删除成功,设置好状态
// 重定向在前端页面完成
resp.setStatus(200);
resp.getWriter().write("<h3> 删除成功 </h3>");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
注意:
删除博客这里的实现逻辑通过两次 ajax 请求来实现的,第一次是为了显示【删除博客】按钮,第二次才是真正的发送删除请求。此外,由于这里是由 ajax 构造的 HTTP 请求,我们期望重定向的操作应该放在前端实现,后端只需要设置状态和删除操作的提示即可。
页面展示效果
备注:这里我就截几张图片展示一些内容,由于页面之间的相互配合是一个动态的过程,所以说,很难演示逻辑。
1. 博客列表页
2. 博客内容页
3. 博客登录页
4. 博客编辑页
总代码
总结页面之间的交互逻辑
1. 博客列表页
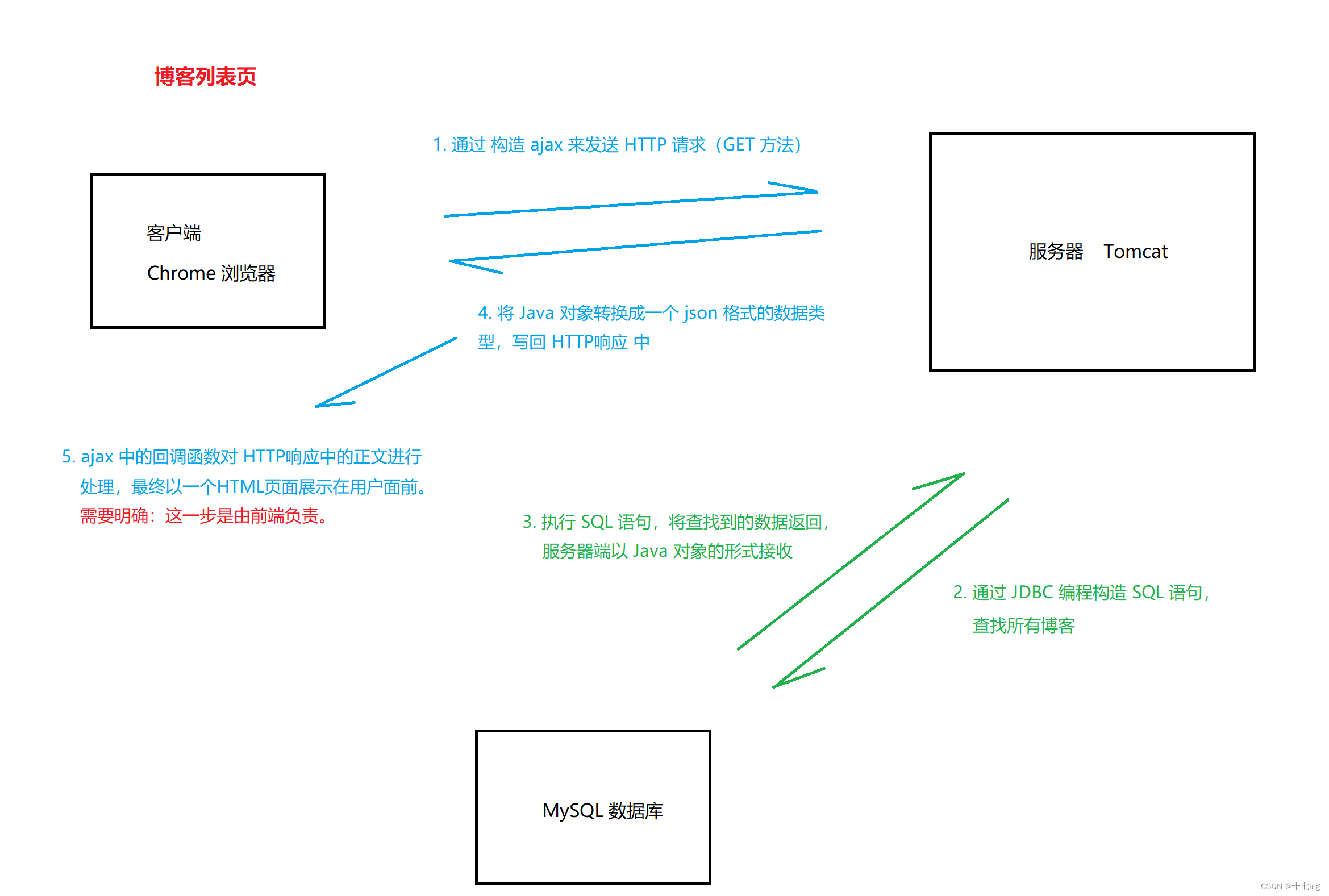
2. 博客内容页
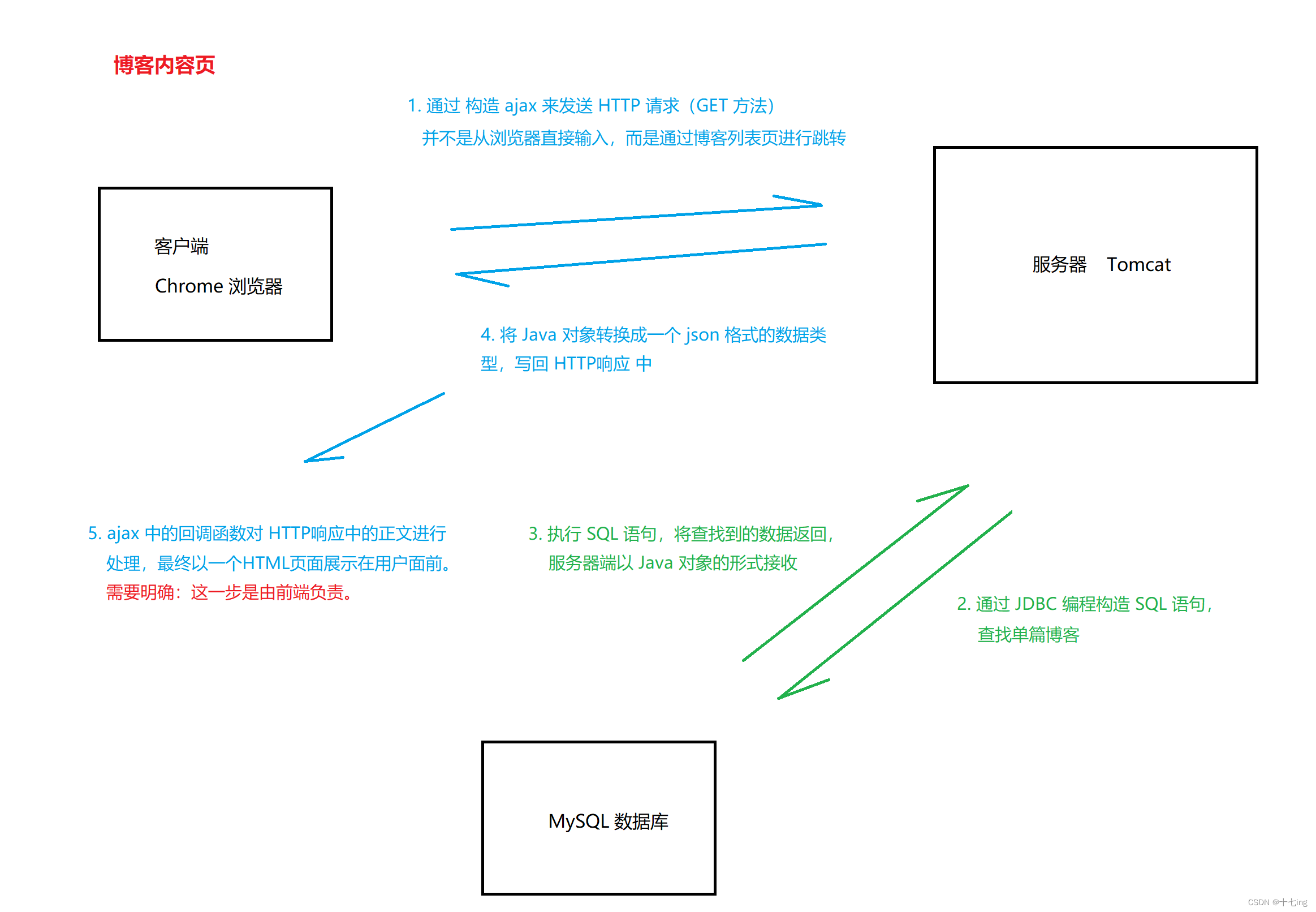
3. 博客登录页
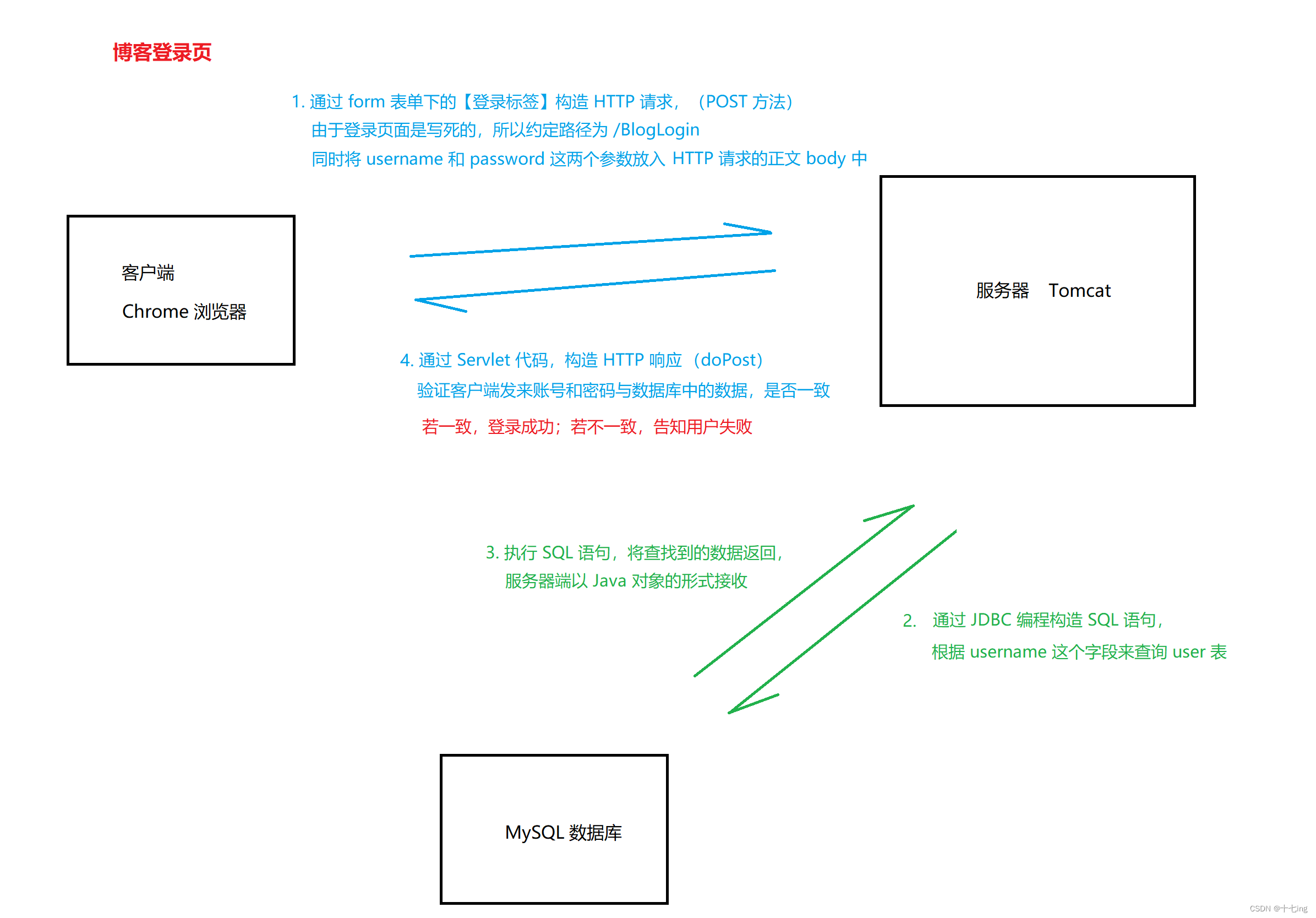
判定用户有没有登录
注销操作
显示用户/作者信息
4. 博客编辑页
删除博客
谈一谈我的感受
当前的博客系统,我写了两个版本,先是写的【基于模板引擎】,后写的【基于前后端分离】,虽然现在的【基于前后端分离】更加流行,但是有好有坏。
在写【基于模板引擎】的时候,只需要把模板文件做好,后面在服务器端按照固定写法进行替换变量即可,所以,我认为,当前的项目,是【基于模板引擎】更加的简单,因为前端代码少,后端代码多。
在写【基于前后端分离】版本的时候,主要接触的前端还是太少,总是被 JS 代码绊住脚,但相对来说,这里的后端代码就更少了。
然而,不论哪个版本,它都是一种实现 Web 开发的一种方式。
所以我认为,
最核心的是:前后端交互的逻辑以及 HTTP 协议。
最难的是:两者以什么样的方式来进行交互,我们需要根据一种【事先约定】来设计好整个流程框架。
如果没有事先约定好一个【协议】,那么,如果在编程的过程中,一个地方出错了,那么整个设计全部崩盘。这种出错的地方包括:临时添加一个功能、临时除去一个功能、跳转接口出错了等等…
令我最深的印象就是:有一次,我在写后端代码的时候,发现没有按照 HTML 页面的标签顺序来写逻辑,这就导致了,后来在展示的时候,浏览器控制台爆出来很多很多的红色报错…
此外,在这个小小的项目中,我更加体会到了 Java 面向对象编程的思想,不管与前端交互,还是与数据之间的连接,都需要用 Java 对象作为中间桥梁。所有的变量,引用等等…都应该赋给一个对象的属性,而后,下次需要的时候,从 Java 对象中取。
而在前端呢,我认为最重要的是,刚开始设计的 HTML 页面,要把整个版心的内容想清楚了,才能够下手进行构造。
而数据库呢,我认为最重要的是,SQL 语句,不管使用什么样连接服务器的方式,最重要的,你得能够直接对数据库生效才行。
此外,当前项目中,也让我更加体会到了测试的关键,利用 Fiddler 抓包,可以很清楚地看到 HTTP 协议的信息。
此外,出现了问题,能不能快速地找到问题,前端或是后端,哪里出错了,这都需要很敏锐地做出判断,令我一个深刻的印象就是:在基于前后端分离版本的【删除博客】功能中,我代码写的很快,但是调试了一个多小时,最后才发现,是后端的重定向错误。
不管怎样,这个小项目还是花了我很长时间的,两个版本各做了两次,我认为,只有动手实践了,才能够真正掌握整个 Web 开发的流程。
补充功能
博客注册页
博客注册页是我后来想起来的一个功能,我心想,既然用户能登录,但不能注册,未免太不合理了,所以我就临时加上了这个页面。
(1) 作用:博客注册页是用于实现用户注册的页面,它不直接出现在用户面前,而是通过点击登录页面的【注册账号】这个链接,来进行跳转。
(2) 约定 POST 请求 的路径:" /BlogRegister "
客户端通过 form 表单来给服务器发送请求。
(3) 针对前端代码:通过 form 表单进行 HTTP 请求的提交,在提交的过程中,需要带上 【username】 、【password1】、【password2】这三个参数,以便于服务器端进行验证。
(4) 针对服务器端代码:创建一个 BlogRegisterServlet 来实现 HTTP 响应,登录成功后,预期跳转到博客登录页。
在前后端交互的过程中,我们要注意很多事项。例如:
注册的用户名与数据库中的用户名不能重合;重复输入一次密码,以此保障注册的密码不会失败;注册完成后,页面不能呆在原地,而是要进行跳转登录页。
而以上的这些问题,基本上都是要通过服务器端使用 if 语句进行控制,既要理解面向对象的思想,又要想清楚服务器如何与数据库进行交互。
前端代码和之前的博客登录页是一样的思想,我就不展示了,主要展示一下后端的代码:
@WebServlet("/BlogRegister")
public class BlogRegisterServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setCharacterEncoding("UTF-8");
resp.setContentType("text/html; charset=UTF-8");
// 从 HTTP 请求中获取 name 参数
String username = req.getParameter("username");
String password1 = req.getParameter("password1");
String password2 = req.getParameter("password2");
if (username == null || username.equals("")) {
resp.getWriter().write("<h3> 您未输入用户名 </h3>");
return;
}
if (password1 == null || password1.equals("")) {
resp.getWriter().write("<h3> 您未输入密码 </h3>");
return;
}
if (password2 == null || password2.equals("")) {
resp.getWriter().write("<h3> 您未再次输入密码 </h3>");
return;
}
// 判断第二次密码是否输入正确
if (!password1.equals(password2)) {
resp.getWriter().write("<h3> 您两次输入的密码不一致,请返回,并重新输入 </h3>");
return;
}
// 判断数据库中,是否有重名的用户
// 若用户名重名,那么就返回
UserDB userDB = new UserDB();
User user = userDB.searchByUsername(username);
// 这里 if 语句中不应该使用 ( user.getUsername() != null )
// 因为这 user 这个对象本身就不为空 ( 有 userID 的存在 )
// 由于 MySQL 数据库中的 userID 是自增主键,那么必然是从 1 开始的
// 如果 userID 为 0,说明数据库中没有重复的用户了
if (user.getUserID() != 0) {
resp.getWriter().write("<h3> 非常抱歉,你注册的用户名已经被其他用户使用,请换一个试试吧~ </h3>");
return;
}
// 代码走到这里,说明一切都符合条件
// 开始往数据库中插入数据
User newUser = new User();
newUser.setUsername(username);
newUser.setPassword(password1);
userDB.insert(newUser);
// 一切都完成后,重定向至 登录页面
resp.sendRedirect("blog_login.html");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
展示效果
再次总结
这次临时添加页面,也给我带来了感触。如果在原有项目进行添加页面,可能并不仅仅就是 " 添加一个页面 " 这个事,因为它涉及到,对于之前页面的改动。这就好像:牵一发动全身一样。
这次添加新页面,我独立完成了 HTML、CSS、后端的这些代码,虽然整体框架不变,但改动的地方依然很多。总之,不管如何修改,都要遵循前后端的交互规律,也要考虑到数据库与服务器端的连接问题。
近两天,我完成了 Linux 的学习,下一篇博客就会详细介绍 Linux 和 Web 部署,我准备将此项目放到公网上,这样就算得上是一个真正的《网站》了。由于当前博客写的是基于 " 127.0.0.1 " 这样的环回 IP,所以说,也就只能自己进行本机的练习,学习了 Web 部署之后,就可以进行将项目公开到公网上,供用户使用了。

