
- 1使用idea连接gitee(码云)_idea登录gitee
- 2Linux开发工具之make/makefile和git怎么样
- 3python车牌识别系统开源代码_python实现车牌识别的示例代码
- 4Caused by: redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool_caused by: redis.clients.jedis.exceptions.jedisdat
- 5OpenTofu路在何方:定量分析Terraform issue数据,洞察用户需求|OpenTofu Day 闪电演讲
- 6mySQL笔记_csdn mysql笔记
- 7【Python】使用Opencv裁剪指定区域,再重构大小和保存示例_cv2裁剪特定区域
- 8commitizen 的使用_commitizen使用
- 9Golang面向对象编程(二)
- 10C++架构之美:设计卓越应用_c++ 开发架构
华为昇腾AI芯片加持,9.1k Star 的 Open-Sora-Plan,国产Sora要来了吗_opensora-plan
赞
踩
Aitrainee | 公众号:AI进修生
哇,今天Github趋势榜第一啊,为了重现Sora,北大这个Open-Sora-Plan,希望通过开源社区力量的复现Sora,目前已支持国产AI芯片(华为昇腾),这回不用被卡脖子了吧,这个项目吸引了众多开发者的智慧和热情,目前在github上的星标已经高达9.1k,不过当前版本离目标差距还很大,仍需持续完善和快速迭代,团队热烈欢迎志同道合的你加入,这是一个汇聚相同技术热忱与求知欲的人们的号召。国产版的Sora还是离我们越来越近了。
下面我们带入开发者(我们)的视角,介绍一下技术报告:
VideoGPT和Video VQ-VAE
想象一下你有一堆乐高积木,每个积木都是视频的一小部分。Video VQ-VAE的工作就像是找到最少的积木数量,同时确保用这些积木还能重建原始视频。这样做可以让视频占用更少的空间,而且我们还可以创造新的视频,就像用积木搭建新东西一样。VideoGPT则是用来指导如何搭建这些积木,以创造新的视频内容。
Open-Sora-Plan v1.0.0的改进
- CausalVideoVAE的训练与推理: 想象你正在尝试用一张巨大的网捕捉时间的流逝,其中网眼代表视频中的每个小片段。我们现在有了一个更大更紧密的网(4×8×8的尺寸),它可以更有效地捕捉视频的细节,无论是在空间上(像是画面的广阔景象)还是时间上(像是动作的连贯性)。
- 图片视频联合训练: 这就像是训练一只鸟同时在水里游泳和在空中飞翔。我们教会了模型不仅能理解静态的图片,还能理解动态的视频。这使得模型能够更好地把握时间和空间的细节,从而创造出更高质量的视觉内容。
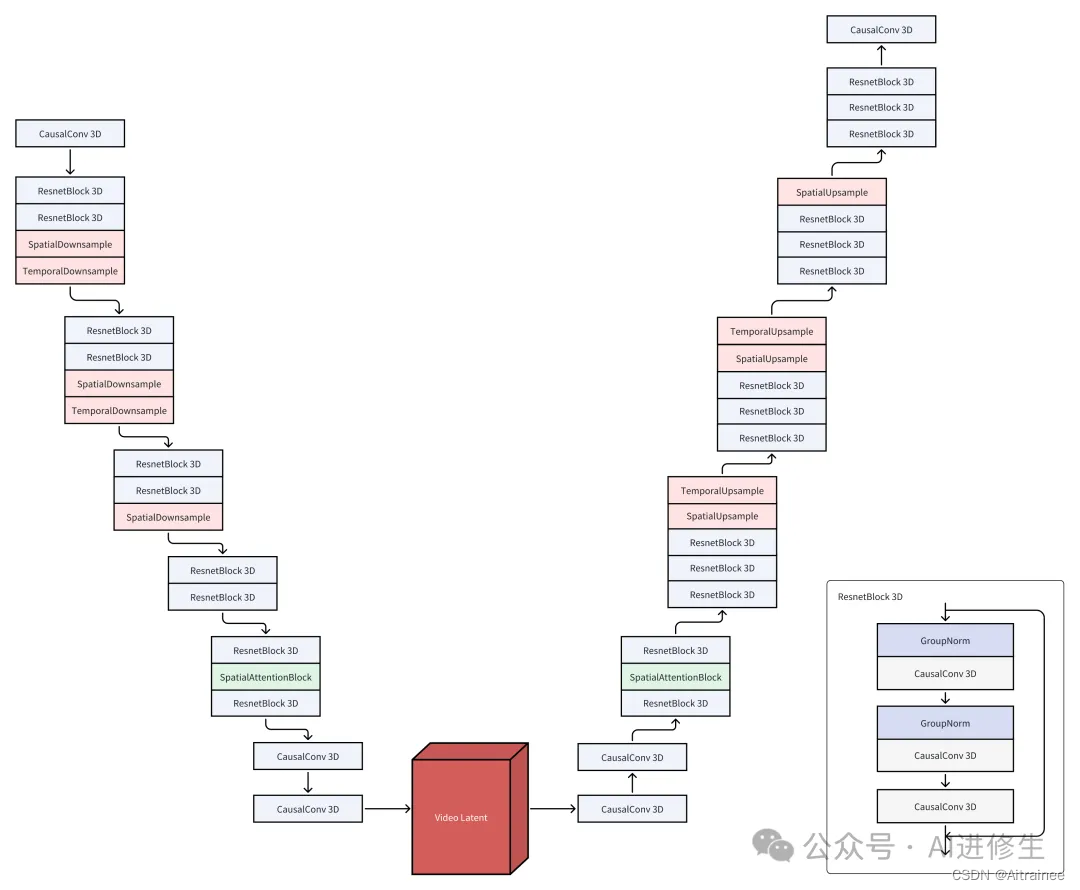
CausalVideoVAE的架构细节
-
CausalConv3D: 如果说之前我们用2D拼图解决问题,现在我们升级到了3D,让模型能同时理解图片(2D)和视频(3D)。特别地,模型会对视频的第一帧给予特别处理,因为那是整个视频故事的开头。
-
初始化方法: 我们使用了一种特别的“尾部初始化”方法,让模型能够在没有任何额外训练的情况下就能处理图片和视频。
训练与推理技巧
-
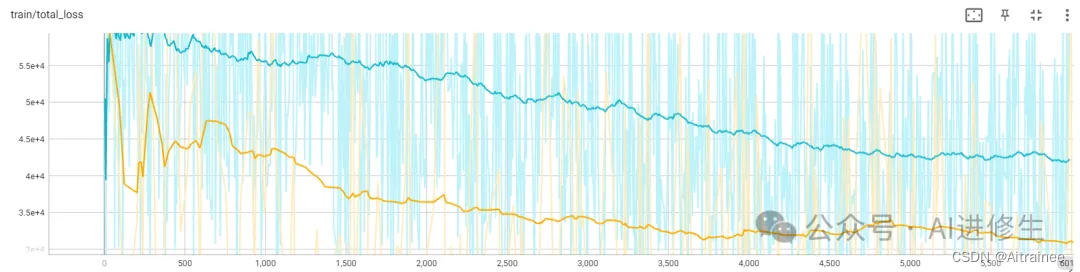
损失曲线: 我们展示了两种不同初始化方法的效果。黄色赛车(尾部初始化)明显跑得更快更稳定,这告诉我们它是一个更好的起点。
-
推理技巧: 采用了一种称为tile convolution的技术,这样可以大大节省资源。
数据构建
-
视频数据集: 我们收集了大量高质量的视频,确保它们没有不相关的水印,并且都是单一场景,这样数据就更加干净、专注。

-
文本注释: 我们还给这些视频配上了高质量的文字说明,有助于模型更好地理解视频内容,并在创造新视频时参考这些描述。
✨ AI算法工程师 | AIGC技术实践者
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

