
- 1小程序展开收起
- 2如何在前端实现WebSocket发送和接收TCP消息(多线程模式)
- 3Elasticsearch的使用RestHighLevelClient_elasticsearch-rest-high-level-client 使用教程
- 4STM32完美移植RT-Thread实时操作系统_rtconfig.h
- 5注解处理器、ServiceLoader 开发SpringCloud启动参数拓展类_implements launcherservice
- 6带你深入浅出Vue
- 7Windows 服务资料不错_cserctrl.writetolog vc
- 8校验 ChatGPT 4.0 真实性的三个经典问题:快速区分 GPT3.5 与 GPT4,并提供免费测试网站_gpt4.0测试csdn
- 9C语言:通过自定义函数实现查找功能_c语言查找函数怎么写
- 10对于超出一行的文本进行(展开/收起)操作的vue组件,实测好用_vue 判断内容是否超过一行
通用语言模型蒸馏-GLMD
赞
踩
GLMD
一、PPT内容
论文背景
P1 Background
1.大规模的预训练语言模型对其在各种设备上的部署提出了挑战,人们越来越重视如知识蒸馏这类的模型压缩方法。
问题:
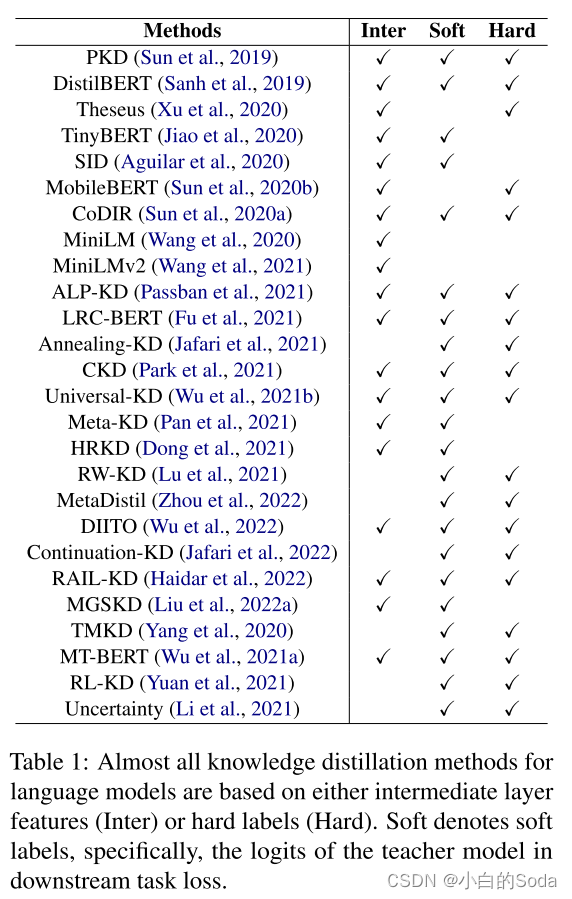
1.当前的知识蒸馏方法依赖于模型的中间层特征和黄金标签(硬标签)(通常分别需要对齐模型架构和足够的标记数据)
2.现有方法中通常忽略了词汇参数。
P2 Approach
提出了通用语言模型蒸馏(GLMD)方法,该方法执行两阶段单词预测蒸馏和词汇压缩,方法简单且性能优异。
具体地说:
1.通过消除模型之间的维度和结构约束,以及没有中间层和黄金标签而对数据集的需求,来支持更加通用的场景。
2.根据数据中词频的长尾分布,GLMD设计了一种通过减少词汇量而不是维度来进行词汇压缩的策略。
相关知识
P3 知识蒸馏
KD的目的是将教师T的知识转移给学生S。
知识和转移方法可以分别形式化为模型特征和距离度量。
语言模型的知识蒸馏通常由以下三个目标函数组成:
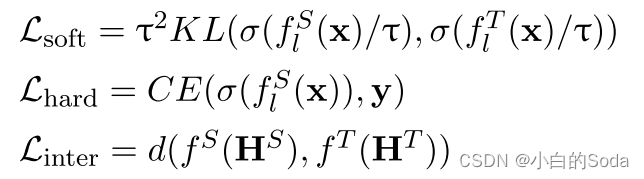
P4 语言建模词预测逻辑
语言建模通常指预训练阶段的无监督任务(GPT的因果语言建模,BERT的屏蔽语言建模,GLM的自回归填空)。
此过程需要解码器(通常是使用词汇参数作为权重的线性变换)将模型输出解码为每个单词的预测逻辑:
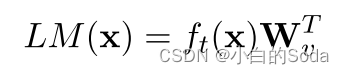
方法
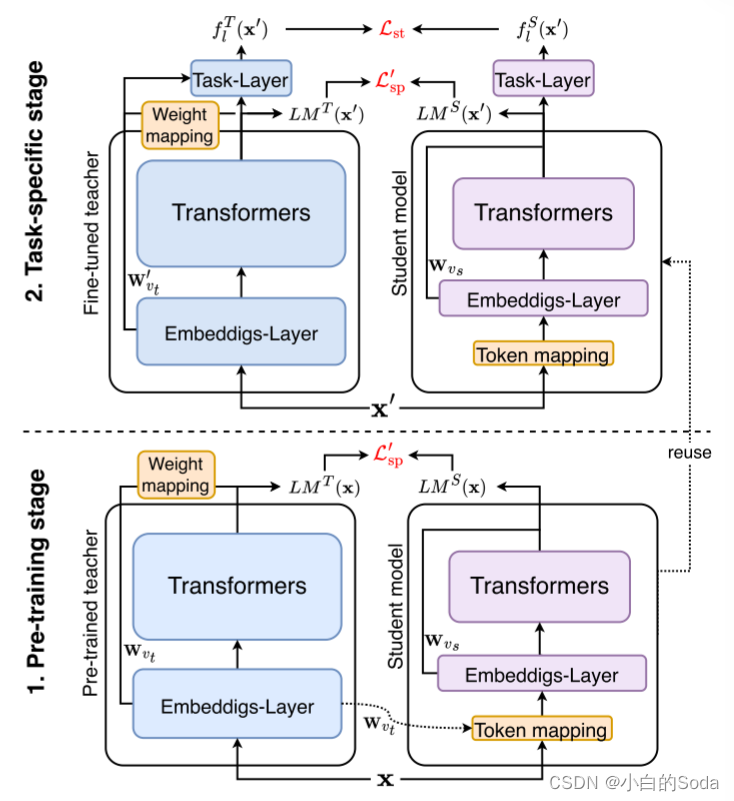
P5 两阶段词汇预测蒸馏
阶段1 预训练阶段
在预训练阶段使用 L ′ s p L^{'}~sp L′ sp 优化学生模型:
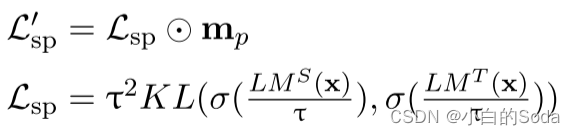
阶段2 特定任务阶段
在任务特定阶段,再次使用 L ′ s p L^{'}~sp L′ sp 优化学生模型。
P6
在这两个阶段以后,最终从任务特定阶段使用目标函数 L s t L~st~ L st 优化学生模型。
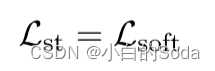
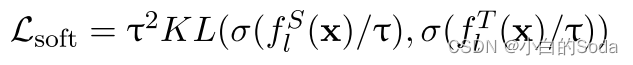
两个阶段都使用 L ′ s p L^{'}~sp L′ sp 优化学生模型是为了使两个阶段的优化目标更加一致。
P7 词汇压缩
词汇压缩策略,是为了减少词汇中的 token 数量。
由于词频具有长尾分布,一些低频词在被相似词替换后仍然可以被语言模型理解。
词汇压缩包括:通过 token 映射用相似的单词替换低频单词,通过权重对齐嵌入层的权重矩阵。
token 映射:
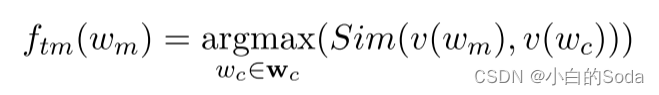
权重映射:
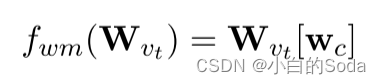
实验结果
P8 results
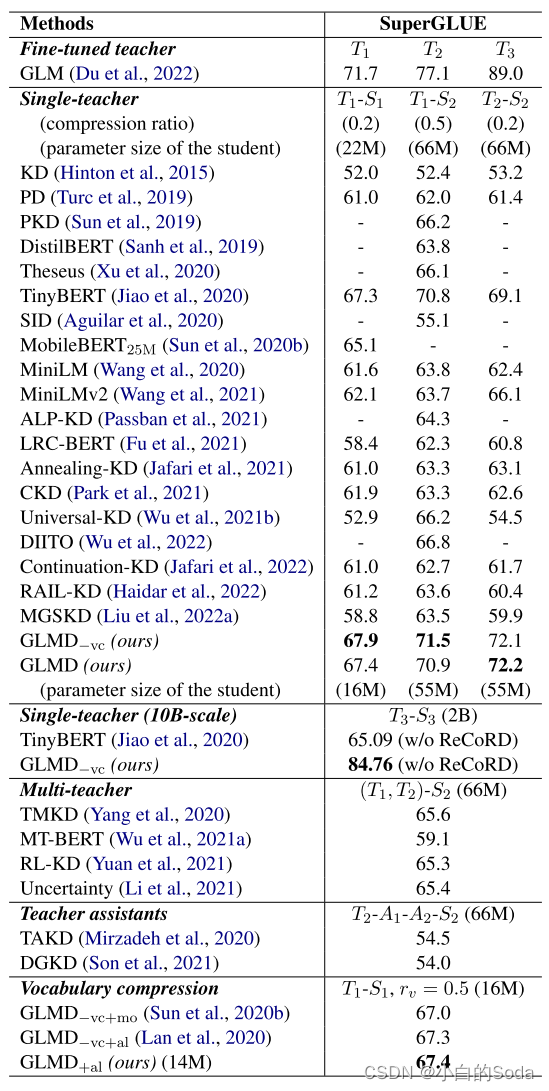
使用更加困难的任务SuperGLUE可以更好地显示不同蒸馏方法之间的差异。
GLMD在T1-S1, T1-S2, and T2-S2的尺度上的25个基线中实现了最高性能,分别比最佳方法(TinyBERT)提高了0.1%,0.1%和3.1%。
在没有词汇压缩的情况下,GLMD-vc分别比最佳方法高出0.7%,0.7%,3.0%。(表明高性能蒸馏不一定需要中间层特征或者硬标签)
二、论文泛读
快速浏览、把握概要
重点:读标题、摘要、结论、所有小标题和图表
2.1 论文要解决什么问题?
解决大规模预训练语言模型在不同设备上的部署问题,以及不损失性能的模型压缩问题。
2.2 论文采用了什么方法?
采用了两阶段的词预测蒸馏方法和词表压缩策略。具体的说,两阶段的词预测蒸馏方法不依赖于中间层特征和hard labels,通过消除模型维度和结构的限制以及中间层和hard labels,支持更加通用的应用场景;通过减少词表大小而不是维度进行词表压缩。
2.4 论文达到什么效果?
论文所采用的方法在SperGLUE上超过了25种SOTA的方法,并且平均得分超过了最好的方法3%。
三、论文精读
选出精华,仔细阅读
目标及效果自测:所读段落是否详细掌握
3.1 模型精讲
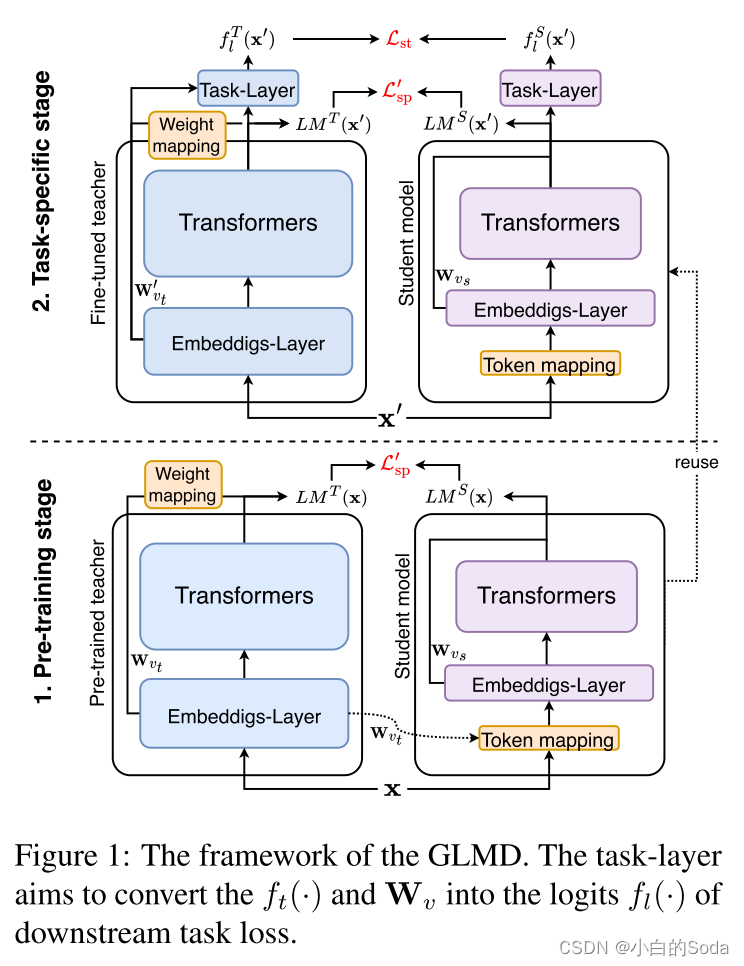
框架概览:
3.1.1 两阶段词预测蒸馏
两阶段的词预测允许教师模型和学生模型拥有不同的模型架构,并且不需要选择中间层。该过程使得蒸馏目标与模型任务更紧密地结合在一起,并使模型的蒸馏在预训练和微调阶段更加一致。
在预训练阶段,使用目标函数 L s p ′ L^{'}_{sp} Lsp′ 优化学生模型:
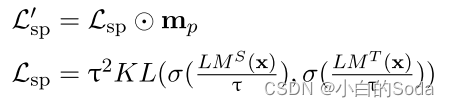
其中⊙代表Hadamard积。 m p ∈ R l m_{p}∈R^{l} mp∈Rl 是掩码向量,在这个掩码向量中,它的作用是将填充标记(pad tokens)进行掩码,但同时保留未掩码的标记和被掩码的标记。“mask the pad” 意味着在处理序列数据时,将填充标记(通常是为了使不同句子长度一致而添加的无效标记)进行掩码处理,以防止它们对模型的预测产生影响。填充标记在模型训练过程中可能会引入噪声,所以将它们掩码可以提高训练效果。掩码向量 m_p 的作用是保留被掩码的标记和未被掩码的标记。这意味着掩码操作不会影响到模型应该学习的有用信息,即模型可以通过保留某些标记和掩码其他标记来学习。
σ代表softmax函数,τ是蒸馏的温度。
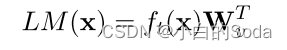
LM(x)是语言模型词预测logits。公式 L M ( x ) = f t ( x ) W v T LM(x) = f_t(x)W_v^T LM(x)=ft(x)WvT 的含义是,通过将最后一层的特征表示 f t ( x ) f_t(x) ft(x)乘以词表权重矩阵 W v W_v Wv 的转置 ,可以得到一个向量,其中每个维度对应于词表中一个词的得分。这些得分可以被解释为模型认为下一个词属于每个可能词的概率。然后,可以应用softmax函数将这些得分转化为概率分布,从而得到LM(x)。
f t ( x ) ∈ R l × h f_t(x)∈R^{l×h} ft(x)∈Rl×h , W v ∈ R v × h W_v∈R^{v×h} Wv∈Rv×h , l l l 表示输入文本序列长度, v v v 表示词表中token的数量, h h h 表示隐藏层的维度。
然后在微调阶段再次使用 L s p ′ L^{'}_{sp} Lsp′ 优化学生模型。在这两个阶段之后,使用目标函数 L s t L_{st} Lst 对学生模型进行优化:
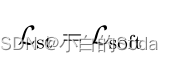
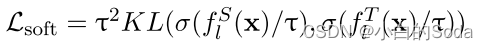
至于下游任务的logits,将 f t ( x ) f_t(x) ft(x) 和 W v T W_v^T WvT 输入到任务特定的层(如全连接层)中可以生成与下游任务相关的预测。这个任务特定的层将特征表示 f t ( x ) f_t(x) ft(x) 转化为适合特定任务的形式,并计算出与任务相关的得分(logits)。例如,如果下游任务是文本分类,这个任务特定的层可能会将ft(x)映射到各个类别上的得分,用于分类决策。
f l S ( x ) 和 f l T ( x ) f^S_l(x) 和 f^T_l(x) flS(x)和flT(x) 表示学生和教师模型在计算任务损失之前的输出。这里应该是loft logits。
3.1.2 词表压缩
词表压缩减少了词表当中的token数量。单词频率具有长尾分布,用相似的词替代之后一些低频词仍然可以被理解。设词表压缩率为 r v r_v rv 压缩之前token的数量为 v v v,然后对预训练语料中的所有token按照出现的频率进行排序,排在前 v r v vr_v vrv 的token为压缩之后的token 即 w c w_c wc,剩余的token为 w m w_m wm 就是被map的token。
token mapping:将低频词用相似的词进行替换。
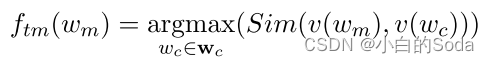
v ( w m ) 和 v ( w c ) v(w_m) 和 v(w_c) v(wm)和v(wc) 代表预训练的教师模型的词表矩阵 W v t W_{v_t} Wvt 中的 w m w_m wm 和 w c w_c wc 的token 向量, S i m ( ⋅ , ⋅ ) Sim(·, ·) Sim(⋅,⋅) 是使用内积计算相似度的函数,与 L M ( x ) = f t ( x ) W v T LM(x) = f_t(x)W_v^T LM(x)=ft(x)WvT 相似,使用线性变换。
weight mapping:对齐嵌入层的权重矩阵。
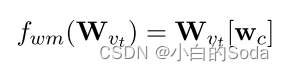
weight mapping是为了从矩阵 W v t W_{v_t} Wvt 中移除 W m W_m Wm , [ ⋅ ] [·] [⋅] 表示切片操作,从矩阵 W v t W_{v_t} Wvt 中获取所有的 w c w_c wc 向量。
对教师模型进行weight mapping是为了将嵌入层的矩阵进行对齐,只有将教师模型的嵌入层矩阵的维度变成与学生模型的嵌入层矩阵一致,才能求loss。
3.2 实验分析和讨论
清华GLM具有以下几点特色:
- 它是第一个真正意义上的多语种通用预训练语言模型。支持中文、英文、韩文、日文四种语言。
- 它训练数据集覆盖面广,使用了670亿词的高质量中文及英文数据进行预训练。
- 它的模型规模非常大,基础模型参数量达到137亿。
- 它支持多样的下游任务 Fine-tuning,包括阅读理解、文本分类、句子相似度等。效果优于BERT等模型。
- 它是一个持续迭代的开源项目,会保持定期更新,并支持用户自定义训练。
综上,清华GLM之所以说是通用模型,是因为其支持多语言、训练数据覆盖面广、模型规模大、下游任务适应性强等特点。这使得它成为一个强大的通用预训练语言模型。
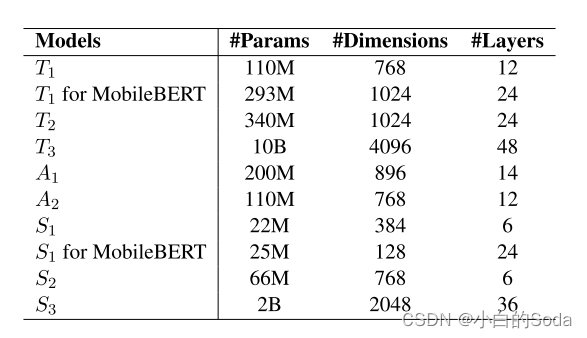
作者在110M,340M,10B参数的模型上进行了验证,所有的实验在40张 A100上完成,耗时4个月,使用Pytorch框架。
3.2.1 实验设置
- 测试集:使用更有挑战性的SuperGLUE,这样更够让各个蒸馏方法的性能差距变得更明显。
- 语料库:BooksCorpus,English Wikipedia (19GB)
- Baselines:25种SOTA方法
- 语言模型:GLM,GLM更加先进,继承了自编码和自回归的优点。选择原因:比通常使用的BERT和RoBERTa表现更好;开源了模型(从10B-100B)。除了MobileBERT之外,其余的方法基于GLM。教师和学生都使用fp16的精度进行训练。
- 超参数: L s p ′ 和 L s t L'_{sp} 和 L_{st} Lsp′和Lst 的蒸馏温度分别设置为15和1;所有的baseline使用的参数都是相应论文中最优的参数;所有需要预训练的方法:batch_size=64,peak learning rate=4e-4,迭代次数=150000;所有单一教师模型,在微调阶段使用网格搜索寻找最优参数,学习率为{5e-6,1e-5,2e-5},batch_size为{16,32};使用多教师和助教的方法在核心方法上与单一教师方法相似,但在教师的权重和辅助方面存在差异;微调阶段使用GLM提供的最佳参数;所有的实验结果均为3个随机种子的平均结果。
3.2.2 主要结果
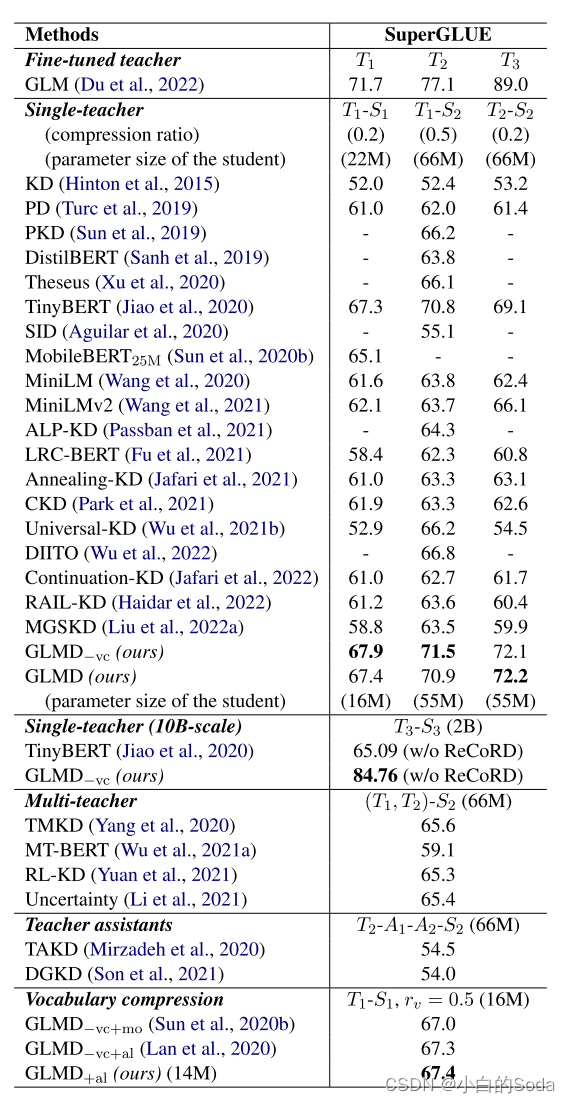
其中, G L M D − v c GLMD_{-vc} GLMD−vc 表示没有词表压缩策略的GLMD, G L M D − v c + m o GLMD_{-vc+mo} GLMD−vc+mo 表示MobileBERT的词汇压缩策略的GLMD, G L M D − v c + a l GLMD_{-vc+al} GLMD−vc+al 表示使用了ALBERT的词汇压缩策略的GLMD, G L M D + a l GLMD_{+al} GLMD+al 表示结合了ALBERT和GLMD的词汇压缩策略。
ALBERT(A Lite BERT)对嵌入参数化进行因式分解。大的词汇嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与嵌入层的分离开。这种分离使得隐藏层的增加更加容易,同时不显著增加词汇嵌入的参数量。(不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,先映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。)
MobileBERT在嵌入层进行压缩(在嵌入层将维度降低到128),需要在计算训练损失时恢复词汇维度来保证输入输出的维度一致性。
GLMD在 T 1 − S 1 , T 1 − S 2 , T 2 − S 2 T_1 - S_1, T_1 - S_2, T_2 - S_2 T1−S1,T1−S2,T2−S2 规模的25个baseline的实现了最高的成绩,分别比最优方法(TinyBERT)提高了0.1%,0.1%,3.1%;在没有词汇压缩的公平环境中, G L M D − v c GLMD_{-vc} GLMD−vc 比最优方法分别提高了0.7%, 0.7%, 3.0%。由此证明了,高性能的蒸馏不需要中间层特征或者hard labels,减少了学生模型的层数或者维度。
GLMD在10B to 2B的蒸馏上显著优于TinyBERT表明TinyBERT不适用于在SuperGLUE上的超大规模的模型蒸馏。
使用词汇压缩的情况下仍然优于很多模型。GLMD在 T 1 − S 1 T_1 - S_1 T1−S1 规模上比最优的词汇压缩策略 G L M D + a l GLMD_{+al} GLMD+al 表现高出0.1%,表明词汇压缩是一个有效的策略。在与其他压缩策略联合使用时,比如 G L M D + a l GLMD_{+al} GLMD+al ,在保持原始性能不变的情况下,词汇表参数只有原来的1/4。
3.2.3 消融实验
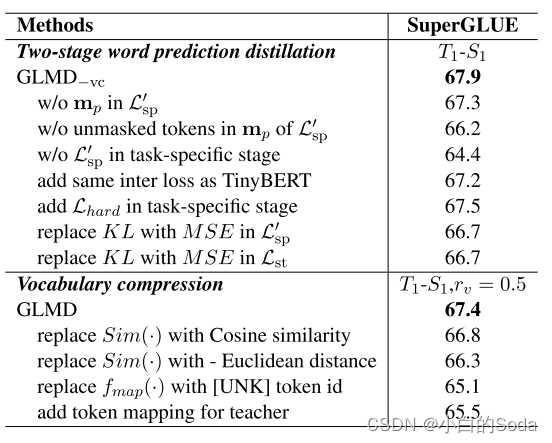
(1)两阶段的词预测蒸馏
结果表明删除 m p m_{p} mp 或者删除 m p m_{p} mp 中的unmasked token表现都不如 G L M D − v c GLMD_{-vc} GLMD−vc,验证了 m p m_{p} mp 的有效性。
在 G L M D − v c GLMD_{-vc} GLMD−vc中加入了中间层特征或者hard labels之后,性能进一步下降,说明中间层和hard labels不是必须的。
KL散度要比均方误差的效果好。
(2)词表压缩
在进行token映射时,作者尝试使用余弦相似度,欧几里得距离或者直接替换为[UNK],这些方法都不如GLMD,可能是因为GLMD中使用的映射方法更接近于语言建模任务中的解码方法。
实验表明,token映射只适用于学生模型。
3.2.4 分析
(1)为什么GLMD work?
相比于其他只使用soft或者hard labels的方法, G L M D − v c GLMD_{-vc} GLMD−vc中 L s p ′ L'_{sp} Lsp′ 提供了更多的知识,但是仍不清楚为什么中间层特征不是必须的。作者假设 L s p ′ L'_{sp} Lsp′ 减少了感应偏置,并且允许模型自发学习与教师相似的中间层特征。为了验证此假设,作者计算了预训练阶段 G L M D − v c GLMD_{-vc} GLMD−vc的教师和学生中间层特征的距离度量(如KL散度)以及 L s p ′ L'_{sp} Lsp′的斯皮尔曼相关性。但是随着 L s p ′ L'_{sp} Lsp′的减小,并不是所有的教师和学生之间的特征距离在蒸馏过程中都在变近,可能没有必要像现有的方法那样将所有中间特征绘制得很接近,从而支持作者的假设。
作者假设词汇压缩的策略的成功基于token的长尾分布,其中一些低频token在被替换以后仍然可以被语言模型理解。实验表明,教师模型使用token映射会降低性能,验证了即使当一些token被替换,学生仍然可以从老师那里学到这些标记的含义,从而老师模型无需进行token 映射。
(2)限制
由于时间限制,作者只在GLM和SuperGLUE上进行了实验。
G L M D − v c GLMD_{-vc} GLMD−vc (10B–>2B)的性能略低于GLM-2B,但是,GLM-2B在预训练阶段使用了更大的batch_size、迭代次数、GPU数量等。
四、总结
总览全文、归纳总结
总结文中的创新点、关键点、启发点等重要信息
4.1 关键点
在预训练阶段,只使用语言模型词预测的logits对模型进行蒸馏,这个阶段的关键是对masked和unmasked的token都进行蒸馏。
- Masked Tokens(掩码标记): 在BERT等预训练模型中,一种训练方式是进行“掩码语言建模”(Masked Language Modeling)。在这种情况下,输入的句子中的一些词会被随机地替换为特殊的“掩码”标记,而模型的任务是预测这些掩码标记的原始词。在知识蒸馏中,对于教师模型和学生模型,都可以通过预测掩码标记来进行蒸馏。这有助于学生模型学习教师模型的语言表示能力。
- Unmasked Tokens(未掩码标记): 与此同时,知识蒸馏也可以包括对未掩码标记的蒸馏。未掩码标记是原始句子中的标记,没有被掩码替换。在知识蒸馏中,教师模型和学生模型都可以被要求预测这些未掩码标记。这有助于传递教师模型在理解原始文本内容方面的知识。
在task-specific(fine-tuning)阶段,对语言模型词预测的logits和soft labels都进行蒸馏。这个阶段的关键是语言模型词预测的logits,其使得两阶段的蒸馏更加一致。
4.2 创新点
运用两阶段的词预测蒸馏和基于词频分布的词汇压缩方法对模型进行蒸馏,消除了模型蒸馏中对复杂的中间层和hard labels的依赖,不需要选择中间层和大量标记数据。
作者通过实验证明,不依赖中间层特征和hard labels以及标记数据等,依然能够让模型自主学习到与教师模型相似的中间层特征。
本文提出的词汇压缩策略是基于数据中词汇的长尾分布,不需要降低模型维数,并且可以与其它降维的词汇压缩策略联合使用以降低性能损失。
本文第一次探索了超大规模的模型压缩(10B-scale)。
中间层选择:
- 复杂的深度学习模型通常包含多个层,每个层都提取不同层次的特征表示。在蒸馏过程中,选择教师模型的中间层作为知识传递的来源是因为这些层往往包含了丰富的语义信息,同时不太容易受到训练数据的噪声影响。
- 中间层的特征表示更抽象,这些表示可能会捕捉到数据的潜在结构和模式,对于学生模型来说,这些特征可以是更有效的表示。
- 使用中间层有额外的限制,比如需要教师模型和学生模型拥有相同的模型结构或者需要进行线性转换以确保教师和学生模型之间的维度一致性。
大量标记数据:
- 蒸馏的目标之一是让学生模型在不同于教师模型训练数据的情况下表现得更好。因此,使用大量的标记数据可以增加学生模型的泛化能力,使其在实际应用中更具有鲁棒性。
- 大量的标记数据可以减轻过拟合问题,使得学生模型更能够从教师模型的知识中受益,同时避免仅仅在教师模型的预测上拟合。
- 在蒸馏中,使用不同于教师模型预训练数据的标记数据,可以促使学生模型更广泛地理解语言和任务,而不仅仅局限于教师模型已见过的数据。
在模型蒸馏的上下文中,标记数据指的是用于训练学生模型的数据,这些数据与教师模型训练数据可能不同。模型蒸馏的目标是让学生模型通过观察教师模型的预测来学习,以便学生模型在不同于教师模型训练数据的情况下也能够表现良好。因此,这些用于训练学生模型的标记数据可以是在不同领域、来源或方式下获得的,以提高学生模型的泛化性能。
4.3 启发点
1)模型压缩的时候,不一定需要使用复杂的中间层特征,仅仅使用输入输出信息也可以取得很好的效果;
2)虽然论文中设计的词表压缩策略是一个很好的方法,但是如同词表中某些最高频的词可能是一些语气词、虚词等等,这样的话会不会有一些潜在的问题;
3)两阶段的策略可以同时使学生模型获得不同阶段的知识。
4)论文中的实验部分非常详实,对比非常广泛,很有说服力。
5)论文所使用的语料为英文,如果使用的语料库是中文,因为中文分词和英文有一些区别,如2)中所说,按照论文的词汇压缩,会不会导致性能下降。
6)如果中间层特征和hard labels都不是必须的,那么未来改进的方向在哪里?
五、十问十答
Q1论文试图解决什么问题?
论文试图解决大规模预训练语言模型在不同设备上的部署问题,以及不损失性能的模型压缩问题。
Q2这是否是一个新的问题?
这个问题不是全新的,模型压缩是自深度学习兴起以来一个持续的研究课题。但针对大规模预训练语言模型的压缩仍然具有挑战性。
Q3这篇文章要验证一个什么科学假设?
论文要验证不需要中间层特征和标注数据就可以进行有效的语言模型压缩的假设。
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关研究包括基于中间层特征的压缩方法、只使用软硬标签的方法等。
语言模型蒸馏:第一次将KD引入预训练语言模型的是PKD(2019)(通过使用中间层特征);在早期的研究中,PD(2019)简单的运用了soft targets,模型迁移的知识相对有限;随后的研究中,主要集中在中间层特征的使用上,包括在预训练阶段蒸馏、微调阶段蒸馏和两阶段蒸馏。也有只使用soft 和 hard targets进行蒸馏的研究,可能需要额外的用来分区的数据集。
词表压缩:语言模型的蒸馏中,减少模型的参数主要被用来减少模型层数或者维数。MobileBERT和ALBERT减少词表的维数来实现词表的压缩。MobileBERT需要在计算训练损失时恢复词汇维度来保证输入输出的维度一致性;ALBERT使用一个线性层来改变模型的输出维度。
主要研究员有Geoffrey Hinton等。
Q5论文中提到的解决方案之关键是什么?
论文的关键是提出两阶段词预测蒸馏和基于词频分布的词表压缩。
Q6论文中的实验是如何设计的?
在SuperGLUE基准测试上比较多个模型规模下的方法。
Q7用于定量评估的数据集是什么?代码有没有开源?
SuperGLUE,代码开源。
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
实验结果显示该方法优于所有对比方法,验证了不需要中间层和标注的数据就可以进行压缩的假设。
Q9这篇论文到底有什么贡献?
主要贡献是提出简单高效的压缩框架,并证实中间层特征不是必需的。词表压缩也具有借鉴意义。
Q10下一步呢?有什么工作可以继续深入?
后续可在更多模型和任务上验证泛化能力,继续优化词表压缩,探索100B级模型压缩等。
六、相关知识点
6.1 Soft labels,Hard labels, Soft logits,logits,Soft Targets,Hard targets以及它们的区别
- Hard Labels(硬标签):是指在分类问题中,每个样本都被分配一个确定的类别标签。例如,在图像分类任务中,一张狗的图片可能会有一个硬标签“狗”。
- Soft Labels(软标签):是指为每个样本分配一个概率分布,表示它属于不同类别的可能性。概率分布中的值可以是连续的,反映了模型对不同类别的置信度。软标签通常用于一些特殊的训练策略,如知识蒸馏(knowledge distillation)。
- Logits:是模型输出的原始值,还没有经过softmax激活函数。它们表示模型在各个类别上的得分或分数,通常是一个向量。在多分类问题中,每个类别都对应一个logit。
- Soft Logits(软logits):类似于软标签,软logits是模型在各个类别上的得分,但这些得分并没有经过softmax激活函数。它们可以用于一些特殊的训练技术,如生成对抗网络(GANs)中的生成器输出。
- Hard Targets(硬目标):指训练模型时使用的真实标签,也就是真实的类别标签。在监督学习中,通常使用硬目标来计算损失函数,以便训练模型。
- Soft Targets(软目标):是指在训练过程中使用的类似于软标签的概率分布,但用于指导模型的训练,是教师模型的预测结果。常见的用例是知识蒸馏,其中一个复杂模型(教师模型)的软目标被用于训练一个简化模型(学生模型)。
假设有一个图像分类任务,涉及两个类别:猫和狗。
- 硬标签:每张图像都被分配一个明确的类别,比如猫或狗。
- 软标签:每张图像的标签是一个包含猫类别概率和狗类别概率的分布,如[0.7, 0.3],表示模型更有信心这是一只猫,但也有一些可能是狗。
- Logits:模型在猫和狗类别上的原始得分,可能是[2.5, 1.8],表示模型认为这张图更可能是猫。
- 软logits:模型在猫和狗类别上的未经过softmax激活函数的得分,可能是[5.2, 2.7],表示猫类别得分更高,但没有归一化。
- 硬目标:训练时使用的真实标签,例如这张图是一只猫。
- 软目标:在知识蒸馏中,可能使用从一个复杂模型得到的软标签,以便训练另一个模型。
文献来源:Are Intermediate Layers and Labels Really Necessary? A General Language Model Distillation Method

