
- 1SpringCloudAlibaba:消息驱动之RocketMQ学习_spring cloud alibaba rocketmq
- 2蓝牙遥控器 – 将手机模拟为键盘、鼠标、翻页笔、遥控器_把备用机当键盘
- 3未来十年,机器学习工程师会消失吗?_机器学习被淘汰了吗
- 4SpringBoot:集成机器学习模型进行预测和分析_springboot 预测算法
- 5手把手教你搭建微信聊天机器人系列(四):多轮对话支持_微信bot 聊天机器人
- 6网络毕业设计--基于华为ensp园区多出口带宽资源调配和管理_企业园区网规划与实现毕设
- 7chatgpt赋能python:Python如何正确导入自己编写的模块_python怎么引用自己写的模块
- 8vue3.0项目中运用vant的以及移动端的适配_vant vue3
- 9【C++】函数重载原理 + 引用 + 内联函数 - 详解 — 入门篇(2)_rider 分析类引用
- 10ICLR 2022—你不应该错过的 10 篇论文(下)_iclr2022
机器学习面试题——支持向量机SVM_支持向量机题库
赞
踩
机器学习面试题——支持向量机SVM
提示:机器学习面试题汇总与解析——SVM
这些知识点可能经常会出现在互联网大厂的笔试中,因此不仅是面试可以用,笔试也会用的,阿里,京东都会考这样的题
题目
考场上,面试官可能会问你这些问题:
推导SVM
LR 和 SVM 联系与区别
svm介绍一下
讲一下SVM的原理
如果特征比较多,用LR还是SVM?
介绍SVM
SVM是否可以用随机梯度下降
SVM优缺点
为什么要将求解 SVM 的原始问题转换为其对偶问题
为什么SVM对缺失数据敏感
SVM怎么防止过拟合 ?
一、推导SVM
SVM(Support Vector Machine,支持向量机)定义:
是二十世纪初使用广泛的分类算法,可以处理非线性和高维的机器学习问题。
SVM目标是找到分类的最大间隔,
为了更好的求解,针对SVM基本型使用拉格朗日方法找到其对偶问题,从而找到解。
SVM只和支持向量有关,所以SVM对异常值不敏感,适合小数据集。
【京东就考过这个知识点】
对于不易分类的情况,可以采用软间隔。
高维问题甚至可以采用核函数方法来更好的分类。
定义初始变量
假设定义超平面为:
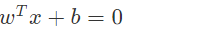
那么两条边界线分别为: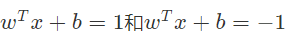
则两边界线之间的距离可以表示为:
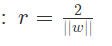
求目标函数:
我们希望样本点均位于两条边界线之外,这样我们的超平面是最鲁棒的,即两边界线之间的距离越大越好

构造拉格朗日函数:
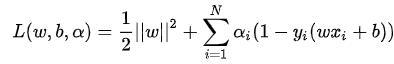

得到SVM的基本模型:
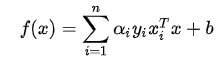 、
、
二、LR 和 SVM 联系与区别
LR与SVM的相同点和不同点:
LR与SVM的相同点:
(1)都是有监督的分类算法;
(2)如果不考虑核函数,LR和SVM都是线性分类算法。它们的分类决策面都是线性的。
(3)LR和SVM都是判别式模型 【这些知识点可能经常会出现在互联网大厂的笔试中,因此不仅是面试可以用,笔试也会用的,阿里,京东都会考这样的题】
【啥玩意是判别式,啥玩意是生成式???】
判别式模型 (Discriminative Model):
直接对条件概率**p(y|x)**进行建模,请问你给定x,其类别y是啥?就直接建模映射了。
常见判别模型有:线性回归(LR)、决策树、支持向量机SVM、k近邻、神经网络等;
说白了就是直接判别了,我们的美学也这么干的。
生成式模型 (Generative Model):
对联合分布概率**p(x,y)**进行建模,而不是条件概率
常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
这知识点,是我在大厂笔试中见过的
判别式和生成式的区别:
——生成式模型更普适;判别式模型更直接,目标性更强
——生成式模型关注数据是如何产生的,寻找的是数据分布模型;
判别式模型关注的数据的差异性,寻找的是分类面
——由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型(注意哦)
LR与SVM的不同点:
(1)本质上是loss函数不同,或者说分类的原理不同。
(2)SVM是结构风险最小化,LR则是经验风险最小化。
(3)SVM只考虑分界面附近的少数点,而LR则考虑所有点。
(4)在解决非线性问题时,SVM可采用核函数的机制,而LR通常不采用核函数的方法。
(5)SVM计算复杂,但效果比LR好,适合 小 数据集;
LR计算简单,适合 大 数据集,可以在线训练。
【看完本题,并不知道LR是啥东西,线性回归,还需要了解一下什么是线性回归LR】
如果特征比较多,用LR还是SVM?
如果特征比较多,最好采用SVM。
因为从SVM基本型可以看出来,只和样本数量有关【适合小样本数据集】,和特征无关,不易过拟合; 【不易过拟合这个事京东考过的】
而特征过多时,LR容易过拟合。
SVM是否可以用随机梯度下降
答:可以的
SVM本质上是一个带约束的二次规划问题,
但是通过拉格朗日法或Hinge Loss的方式可以转换成一个无约束的优化问题。
而不论是梯度下降还是二次规划,都是能够用来优化这个问题的。
甚至Hinge Loss定义下的损失函数是个凸函数,也是可以优化得到最优解的。
故答案是可以。
SVM优缺点
优点:
(1)理论完善,逻辑优美。
(2)SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。【京东考过】
(3)SVM 对异常值不敏感
(4)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本【适合小样本数据集】
(5)SVM 目标是求解最大间隔超平面,算法分类具有较好的“鲁棒”性。
(6)SVM可以利用核函数解决逻辑回归解决不了的高维分类问题。(比LR骚呗)
缺点
(1)SVM算法对大规模训练样本难以实施,不适合大规模数据,LR才适合大规模数据集
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。
故需要优化算法(往外就看条件,一定条件下这个方法合适,但是很多情况下,这个就不合适,比如当今大数据时代)
(2)经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
为什么要将求解 SVM 的原始问题转换为其对偶问题
一是对偶问题往往更易求解,当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。
二是可以自然引入核函数,进而推广到非线性分类问题。
为什么SVM对缺失数据敏感
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。
SVM 没有处理缺失值的策略。
而 SVM 希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。
缺失特征数据将影响训练结果的好坏。
SVM怎么防止过拟合 ?
(1)引入松弛变量(松弛,放松条件呗)
(2)正则化——这个也是神经网络的防止过拟合的方法
总结
提示:重要经验:
1)SVM经常在大厂的笔试题中考,因此准备这个知识点,不仅有利于面试,还有利于笔试
2)多积累,多复习,慢慢滴就准备好了秋招所需的知识点,所谓算法八股文就这些东西

