
- 1查看docker 容器的端口_docker查看容器端口
- 2分布式文件存储FastDFS介绍安装部署及相关Java代码编写_分布式文件存储代码
- 3OSPF技术连载2:OSPF工作原理、建立邻接关系、路由计算_ospf 邻接关系
- 4了解不一样的Sui NFT标准_sui ntf
- 5CoPE论文爆火!解决Transformer根本缺陷,所有大模型都能获得巨大改进
- 6开源排版软件 Scribus_scribus是开源项目
- 7创新案例 | 最全的跨境电商SHEIN获取流量和打造增长飞轮的经验借鉴_通过案例对sheinside流量来源进行分析
- 8图像匹配天花板:SuperPoint+SuperGlue复现
- 9springboot的JPA在Mysql8新增记录失败的问题_jpa insert如何抛出异常
- 10vue 配置 postcss-px2rem
最详Hive入门指南
赞
踩
本质就是一个hadoop的客户端,将HIve SQL转化成MapReduce程序
一、Hive介绍 & 配置
1、hive本质
- 基于Hadoop的⼀个数据仓库⼯具,可以将结构化的数据⽂件映射 为⼀张表,并提供类SQL查询功能。
- 本质就是一个hadoop的客户端,将HIve SQL转化成MapReduce程序
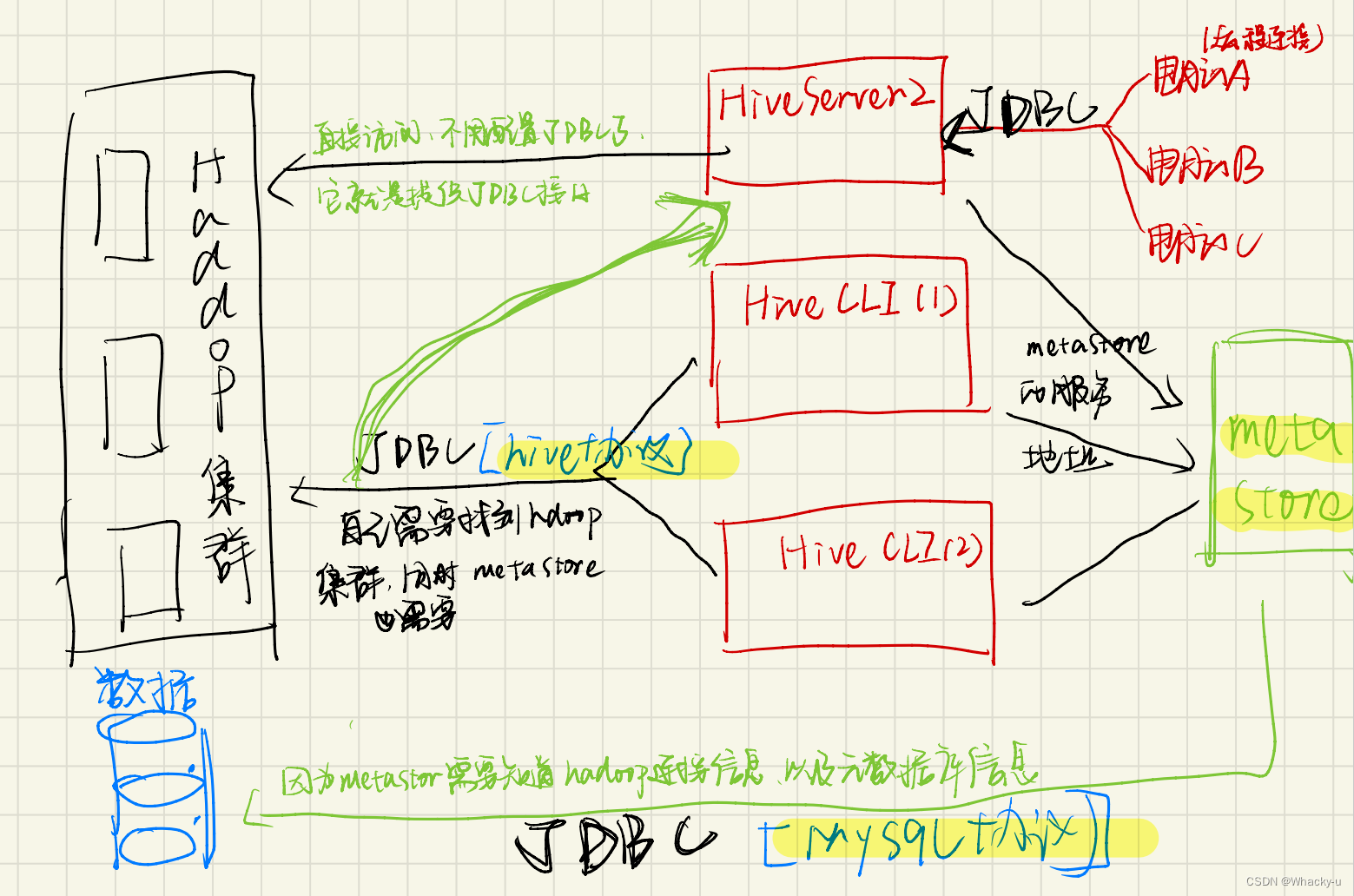
2、架构原理
主要分为三部分:用户接口Client,元数据metastore,驱动器
<img src="C:\Users\Whacky\AppData\Roaming\Typora\typora-user-images\image-2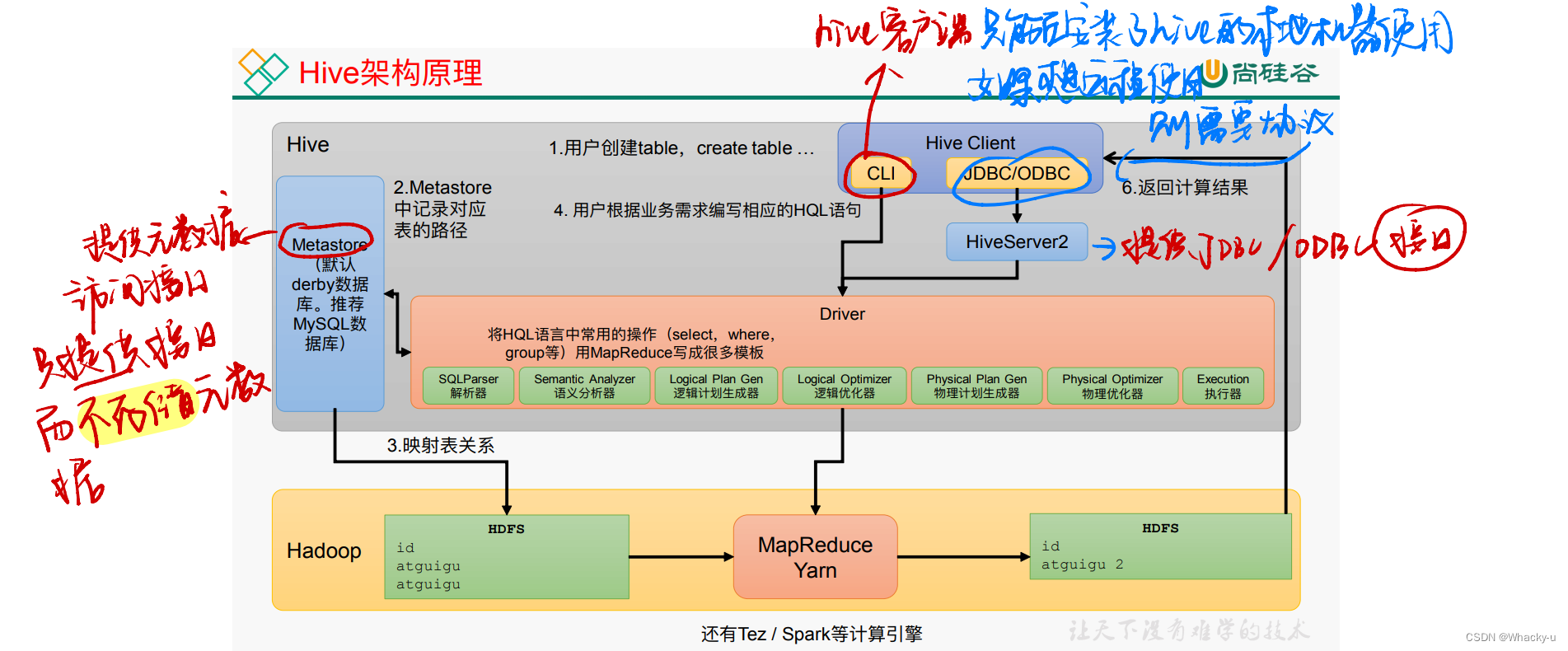
3、hive安装和部署
// 主要看讲义的第4页-20页
- 1
3.1、安装Hive
压缩包传到software,之后解压到module文件夹下
3.2、环境变量
修改/etc/profile.d/my_env.sh环境变量,增加关于hive的环境变量
// hive的部署还有一个最小化服务部署,这个主要是用来体验的
// 可以看讲义第5-7页
// 就不去整理了,我们只要部署完整版的
- 1
- 2
- 3
3.3、安装Mysql
在安装数据库的时候,我们选择的是离线安装,就是下载压缩包自己去安装依赖
但是此方法一定要按顺序安装依赖,如果安装依赖出现问题,可以去“pkgs.org”这个网站
上面先配置,右上角选择虚拟机的centos7,去找到丢失的依赖下载,然后上传虚拟机再重新安装
3.4、启动Mysql
主要为了之后找初始的默认密码
sudo systemctl start mysqld //启动
sudo systemctl status mysqld //查看状态
- 1
- 2
3.5、配置mysql
- 启动mysql后可以查看默认密码:sudo cat /var/log/mysqld.log | grep password
- 找到密码后去登录,mysql -uroot -p’密码内容’
- 重新设置密码
- 进入mysql库,查询user表,之后修改user表,把Host表的内容修改成任何主机节点都可以使用root进行访问
- quit退出MySQL
3.6、配置元数据到MySQL
-
新建Hive源数据库,这个是在MySQL中create的
-
将Mysql的JDBC驱动拷贝到Hive的lib目录下
-
hive的conf文件夹下配置hive-site.xml。主要就啥事jdbc的几条配置信息,URL【主要是数据库存放的数据名:端口号/数据库的库名】、Driver、连接的username、密码
-
初始化Hive元数据库(修改为采用MySQL存储元数据):
bin/schematool -dbType mysql -initSchema -verbose
3.7、检查配置成功没有
启动hive,使用hive创建表,插入数据,查询表。另外再打开一个hive窗口,如果jdbc配置成功的话
那么应该是可以两个窗口都操作Hive的,没有异常
3.8、查看元数据连接情况
我们也可以登录MySQL去查看之前的创建的元数据有没有连接成功,存上数据。可以使用linux还是命令行,也可以使用Navicat可视化工具去查看
3.9、Hive部署
主要是hiveserver2服务和metastore服务
这一部分具体的介绍可以看讲义
//hiveserver2 介绍可以看讲义第12-14页
//metastore 介绍可以看讲义第17-19页
- 1
- 2
- 3
3.10、配置hiveserver2服务
需要明确此功能是依赖hadoop的代理用户功能,只有hadoop集群中的主机中的某个用户被设定了有代理用户身份,才可以模拟其他用户的身份访问hadoop集群,如下图所示:
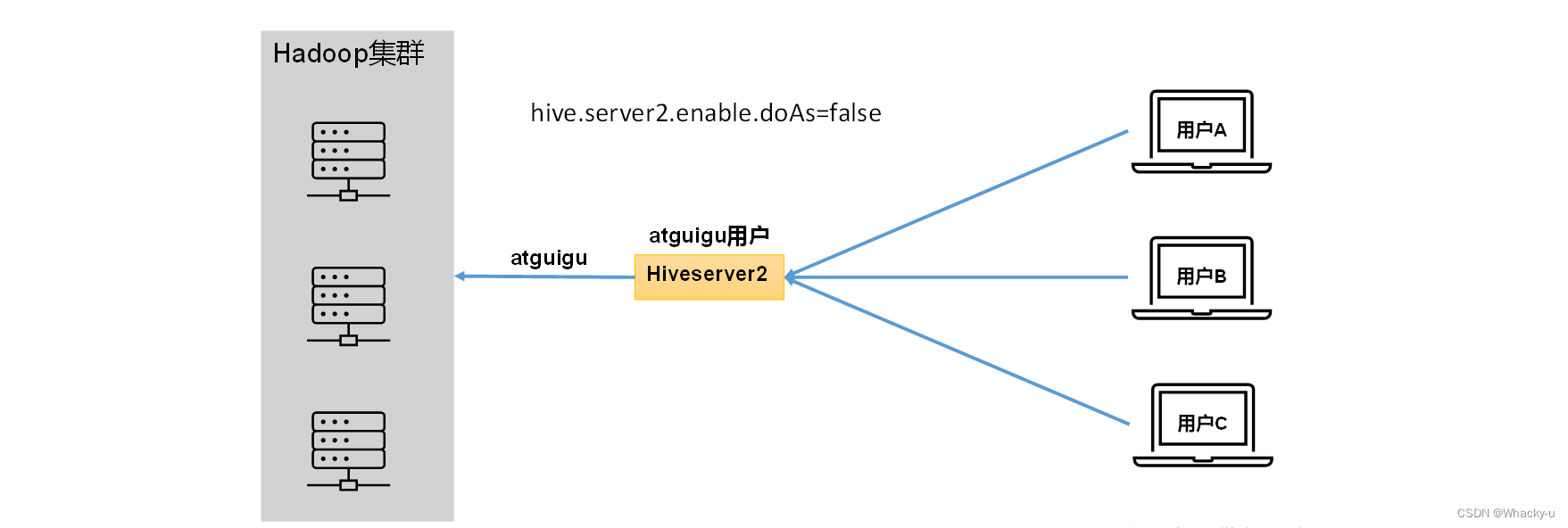
所以,需要将hiveserver的启动用户设置为Hadoop的代理用户
【重点!!!!!!!!】
也就是说我们hiveserver2连接的主机,以及启动这个服务的用户,必须是Hadoop集群中拥有代理用户权限的主机下的用户
-
配置hadoop集群,配置集群中不同主机和用户的实际用户代理功能权限。同时分发这个配置好的core-site在集群中
-
配置hive端。指定如果有其他客户端想要远程访问操作hive到hadoop集群,那个远程访问客户端可以连接的主机和端口号,在hive-site文件中
【重点理解表粗的】!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
启动此服务,记得要用:
nohup bin/hiveserver2 >/dev/null 2>&1 &
- 1
如果想要远程访问有两种选择:beeline命令行客户端、DataGrip可视化连接客户端【看讲义第15页】
3.11、metastore服务
有两种运行模式,默认是嵌入式模式,实际开发应该使用独立服务模式
metasore部署:
部署独立服务模式的时候,记得要保证如果我们使用客户端进行远程访问,如果使用了metastore服务,那么
1、必须要在hive客户端中的hive-site配置jdbc和meta store的服务地址
2、必须要在设有metastore上配置文件【其实还是jdbc那些】,**然后启动此服务,一定要启动服务!**要不然上面配置metastore地址后没法连接上地址了,注意上面配置的metastore服务地址,就是此主机的地址
Metastore并不一定需要直接部署在Hadoop集群上,但它需要与Hadoop集群通信以访问HDFS中的数据。Metastore存储Hive的元数据信息,包括表结构、分区信息等。
一般情况下,Metastore可以在独立的节点上部署,与Hive Server或Hive客户端分离。它可以连接到Hadoop集群中的HDFS,以便在执行Hive查询时能够访问数据。这意味着Metastore需要配置为能够连接到Hadoop集群的HDFS,通常需要指定HDFS的URI和相应的权限信息。
【其实不部署在集群上,还能发挥作用,就是hive-site中配置的jdbc起到的作用】
- 1
- 2
- 3
- 4
- 5
4、注意事项
-
**hive可以不部署在hadoop集群上【就是hive CLI】,**但需要与Hadoop建立联系并访问HDFS数据,可以通过以下方式实现【要么是metasore,要么是客户端去找metastore进行连接】:
- 配置Hive Metastore: Hive Metastore是Hive元数据的存储和管理服务,它可以独立于Hive服务器部署在任何节点上,包括Hadoop集群节点之外。Metastore存储了Hive表的元数据信息,比如表的结构、分区等。Hive Metastore需要配置为连接到Hadoop集群中的NameNode,以便访问HDFS中的数据。这个配置通常包括HDFS的URI和访问权限等信息。
- Hive客户端连接: 在Hive客户端,可以配置连接参数来指定Hive Metastore的位置和连接信息。这样做允许Hive客户端通过网络连接到Hive Metastore服务,查询元数据信息,并根据元数据信息来访问HDFS中的数据。通常,这些连接信息会包括Hive Metastore的地址和端口等。
【其实就都是jdbc】
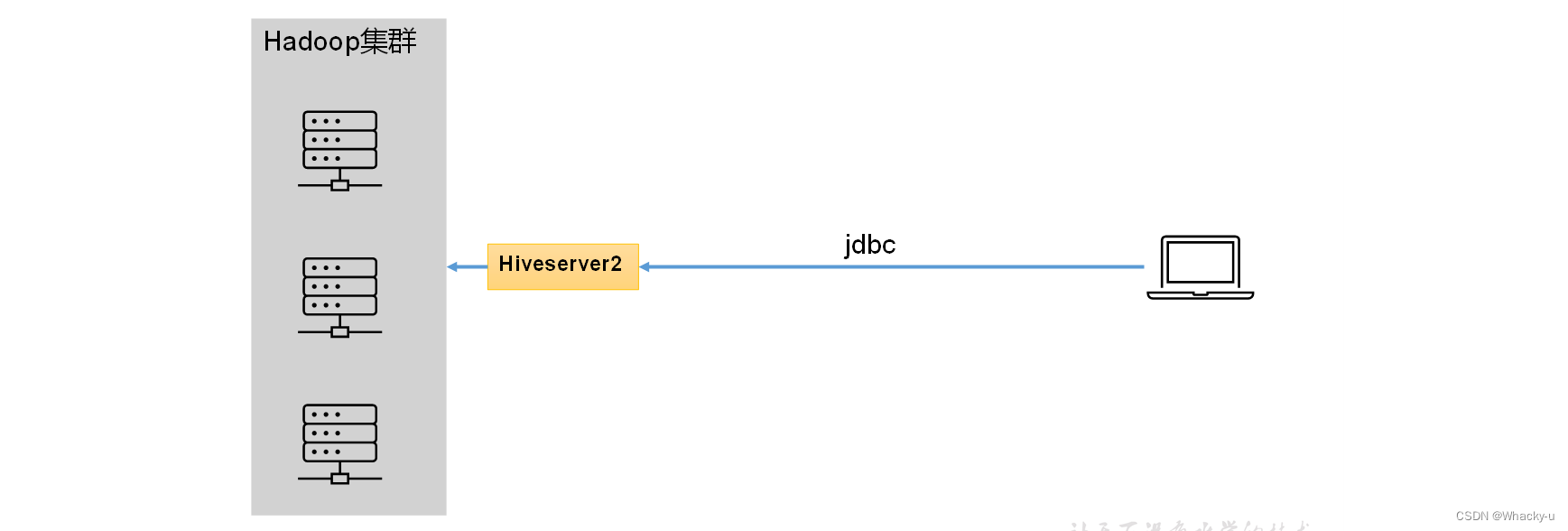
-
hiveserver2要配置在集群中的机器上
<!-- 指定hiveserver2连接的host --> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop102</value> </property>- 1
- 2
- 3
- 4
- 5
对于JDBC连接到Hive或HiveServer2,主机地址通常应该是Hadoop集群中的节点。JDBC连接的主机地址是指向HiveServer2的地址,以便客户端可以通过该地址连接到HiveServer2服务并执行查询
如果 JDBC 客户端不直接连接到集群中的节点,而是通过某种中间件、代理服务器或者其他网络配置来访问集群中的服务,那么你需要确保这些中间层可以进行有效的转发,并且允许连接到Hadoop集群中的服务。
所以JDBC中的URL连接的主机地址最好还是集群中的主机节点
-
在写MySQL和Hive语句的时候最后记得加分号
-
需要先启动hadoop集群,才能启动hive服务进行使用
5、整理一下hive使用思路
5.1、两种JDBC协议
首先明确一个概念,我们使用JDBC的URL含义,我们主要涉及到有两种协议头,见下面:
jdbc:mysql://hadoop102:10000/data1
jdbc:hive2://hadoop102:10000/default
//1、第一行的含义是:使用 JDBC 连接 MySQL 数据库,MySQL 服务器位于主机 hadoop102 的端口号为 10000 上,并连接到名为 data1 的数据库
//2、第二行的含义是:使用JDBC连接HiveServer2服务,HS2服务在主机 hadoop102 的端口号为 10000 上,连接默认的数据库default,或者可以改成避的数据库
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.2、三种客户端
**之后还需要明确有两种客户端。**一种是HIve CLI,就是装在本机的hive,使用hive命令行操作。另外一种就是电脑的远程比如datagrip、idea这种可以写hive sql的。
-
其中第一种连接集群和数据库的时候,需要使用beeline,输入JDBC的jdbc:hive2://hadoop102:10000/default。
另外此上也需要在hive-site.xml配置连接数据库的JDBC:jdbc:mysql://hadoop102:10000/data1
-
还有一种被beeline取代的HIve CLI,直接使用命令hive启动命令行,就可以访问数据进行操作,但是这个装有hive的主机必须是在装有本地hadoop集群的机器上,这样才可以访问集群的数据,【他会自动帮你运行一个RunJar进程,进程是提供thrift的RPC的,就是metastore服务】。要不就需要hiveservice2服务的启动
-
第三种直接在集群中安装有Hiveserver2的节点A上启动此服务,然后在远程输入A节点的主机地址和端口号即可
5.3、哪台主机配什么服务【重点】
【重点!!!!!!!】这些都明确后,我们还需要知道在生产中在哪个主机节点上配置什么服务。
-
一般是在hadoop集群上的active节点上,比如A安装hive,然后配置hiveserver2的服务
这样我们就可以
就是说明此服务链接的监听地址和端口号。 这个监听地址配置实际上是告诉 HiveServer2 在哪个网络接口、主机名或者 IP 地址上监听来自客户端的连接请求。 客户端通过这个地址来与 HiveServer2 建立连接,然后执行查询或其他操作。 然后在此节点上还要配置meta store的服务地址,我们可以通过地址找到元数据库 换句话说,这个监听地址决定了客户端将要连接到的位置。这个监听地址决定了客户端将要连接到的位置。 连接到了A,而A就是集群中的active节点,所以相当于客户端连接到了集群 客户端需要使用这个配置的地址和端口号来连接 HiveServer2,并与 HiveServer2 建立通信以执行查询和其他 Hive 操作。 //上面说的是metastore的独立模式,一般在生产环境中。但是我们在学习过程中还是使用嵌入模式,就是hiveserver2或者hive CLI自己连接metastore,所以还需要配置JDBC的数据库协议。jdbc:mysql://hadoop102:10000/data1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
在集群中另外节点比如节点B
(1) 安装数据库MySQL创建元数据库metastore
(2) 在此节点上部署且启动metastore服务
下载hive和MySQL建立连接,就是通过JDBC的数据库连接协议。jdbc:mysql://hadoop102:10000/data1 这个里面的hadoop102应该是安装了mysql的主机地址,比如这里是B //!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!! // 注意,metastore并不需要连接集群,只需要连接数据库,同时可以被其他客户端连接即可!!!!!!!!!!!!!!!!- 1
- 2
- 3
- 4
如果B上启动metastore服务后。由于启动hiveserver2服务的节点A中配置了metastore的地址。B:9083
那么远程电脑中比如datagrip去连接hiveserver2提供的接口,A:10000
我们就可以从元数据库中拿到表的地址,然后对表中数据进行修改查询,操作结果就可以对应到集群中的数据中
5.4、此次课程实际配置情况
但是我们学习过程中,还是使用的嵌入模式
所以相当于在hiveserver2上配置了metastore的连连接,就是数据库连接协议,这样的话就可以先启动hiveserver2服务
然后远程访问的时候输入提供的接口,A:10000。
我们也可以使用这个metastore元数据库,因为使用JDBC的MySQL连接协议,在节点A上连接了元数据库,相当于是嵌入模式
5.5、启动顺序
所以我们的启动顺序是:
先是启动hadoop集群,然后在创建了hiveserver2服务的节点上启动此服务
之后再在hive客户端上启动hive【或者就是idea之类的】即可使用
如果另外需要metastore就再配置和启动metastore
5.6、两种metastore模式下的整体流程图
主要是为了画整体的流程,知道彼此间关系,以及这些东西到底是怎么连接到集群的
1、嵌入模式,也是本次课程中使用的模式。metastore和hiveserver2都安装在了集群中的active节点上
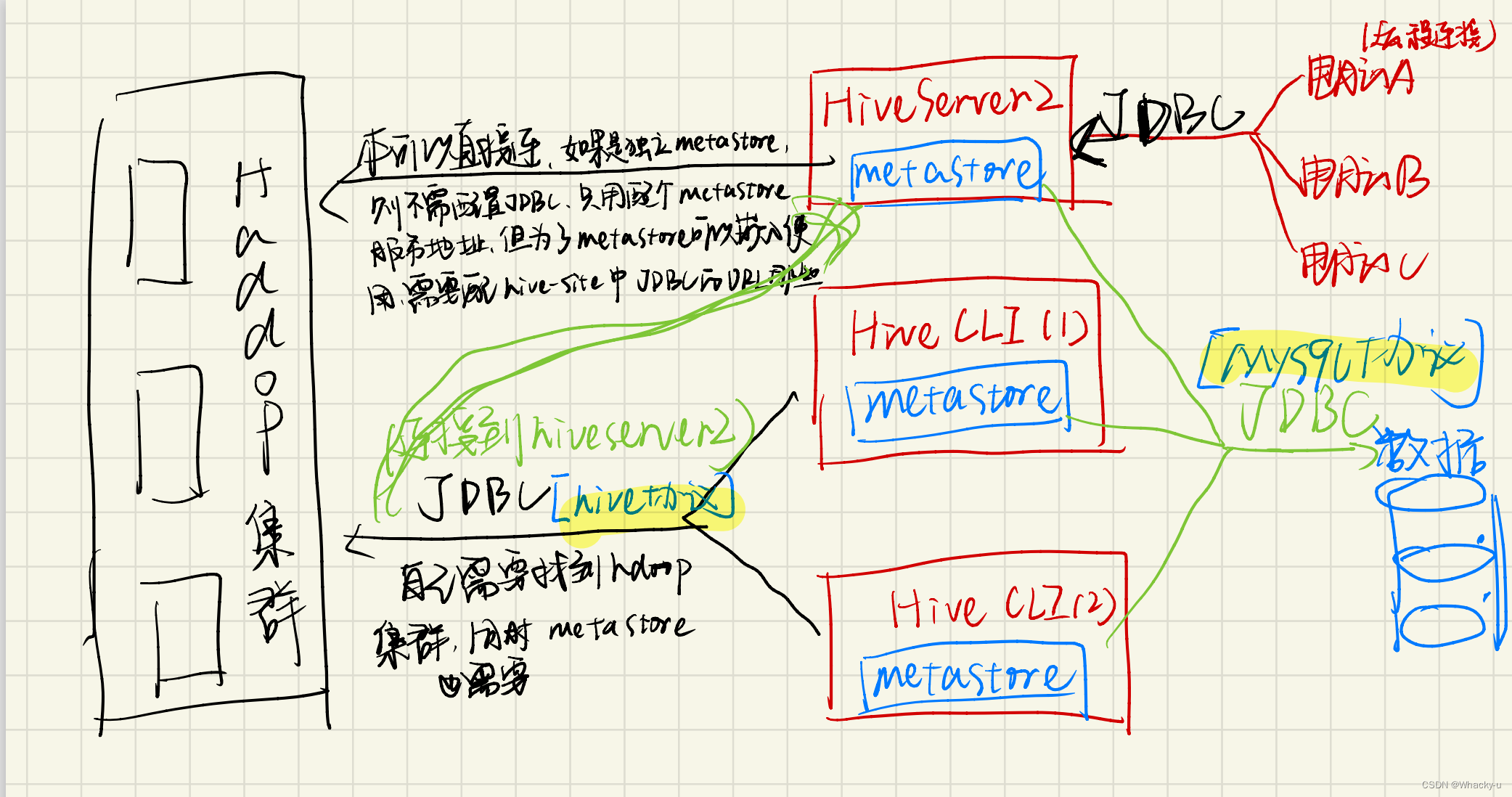
2、独立模式。是实际生产中使用的安装方法
二、DDL(库和表这些数据的定义)
如果不指定地址,那么就是默认地址下的自己构建的表名字,在此默认路径下创建了这么一个表的目录
然后我们只要和表中对应数据格式一样的数据传到hdfs下的表目录下,就可以将数据存储到表中了
但是如果我们自己写的表名字是stu1,路经规定为/user/hive/warehouse/stu2,那么实际存储在hdfs中的表文件名字还是stu2,所以我们如果上传hdfs数据的话,也要传到/user/hive/warehouse/stu2,这个路径下
1、数据库
// 讲义的26-27页
主要是创建、删除、修改、查询
- 1
- 2
2、表
2.0、数据类型的显示转换
里面显示转换是cast(‘1’ as bigint),借助cast函数
2.1、创建【重点】-【数据类型】
需要注意的是,我们上传的数据必须要和表种的格式和字段信息匹配。在上传数据种不能有空行和回车
另外,如果是json文件,需要压平,放在同一行,因为我们使用的全类名序列化的时候,就是Row format那部分,是针对json的一行文本数据去处理的
// 主要学习创建,讲义的第28-31页
- 1
涉及三种创建表的方法:
- 第一种是主要的
- 第二种是查询基础上CTAS
- 第三种是Create Table Like复制表,不包括数据
其中第一种表的创建中
一共有九个关键字,重点学习以下四个:
- PARTITIONED BY**(重点):创建分区表
- **CLUSTERED BY … SORTED BY…INTO … BUCKETS(重点)****:创建分桶表
- ROW FORMAT(重点):使用SERDE序列化和反序列化每行数据。其中json有专门的的参数,引用全类名,在下面实例中有介绍
- STORED AS(重点):指定文件格式,常用的文件格式有,textfile(默认值),sequence file,orc file、parquet file等等。
2.2、查看
// 在讲义33页-34
- 1
2.3、修改
需要注意的是,修改列信息的时候,并不会对hdfs中的数据产生影响,我们只会改变元数据信息
比如之前表中存有数据,表结构中有三个字段A B C,现在更改列的顺序为C B A,但是hdfs中的数据顺序还是A B C
所以会发生数据错乱
// 在讲义34-35页
- 1
2.4、删除
// 在讲义35页
- 1
2.5、清空
只对内部表有效。外部表没有效果
清空内部表中对应的表中数据,也就是hdfs中的数据
// 在讲义第35页
- 1
三、DML(数据操作的定义)
主要涉及Load和Insert
本来针对数据应该是增删改查,之所以没有讲解删除和更新改变
是因为这个大数据主要针对海量数据的分析和计算。基本不需要进行对数据的修改。如果需要的话再去官网看
1、Load
// 在讲义第36页
- 1
有点类似之前把数据使用hadoop -fs put操作
这里需要使用关键字【local】判断是否是从本地加载的,加上表示从本地加载,否则是从HDFS中加载数据到hive表
需要明确:
- 从本地加载,相当于是从本地执行了hadoop -fs put操作,可以理解成是一个复制操作
- 不是本地加载,从hdfs中加载,可以看作是一个拖拽操作,直接剪切,所以hdfs源路径中那个数据就没有了
另外我们需要知道本地的概念,注意区分两种本地客户端的本地数据来源s:
因为有两种客户端:JDBC远程连接的比如Datagrip,还有Hive命令行的客户端
- JDBC的本地数据指的就是hiveserver2那台主机上的数据
- hive命令行的客户端本地数据指的是,命令行所在的主机上数据
2、Insert
// 在讲义第37页
- 1
主要涉及以下三种插入数据的操作
- 将查询结果插入表中
- 将给定Values插入表中
- 将查询结果写入目标路径 【注意这个就是insert overwrite 没有into】
3、export & import
// 在讲义的第38页
- 1
主要是用于两个hadoop集群,也就是两个不同的hdfs,不同的元数据下进行导表
四、查询
// 主要在讲义第39-54页
- 1
如果我们是进行测试和学习。可以在datagrip窗口,或者hive命令行那里设置“本地模式”
**这样就是只会在当前会话有效。并且可以使查询速度变快。**因为相当于是map和reduce都在本地。
set mapreduce.framework.name = local;
- 1
1、基本查询【基础语法】
需要注意的是,我们可以对列起一个列别名,通过as关键字,但是可以省略
所以之后如果在查询中看到列名后面跟着一个新名字,别看不懂
比如下面的dep:
select
deptno dep,
ename
from emp;
- 1
- 2
- 3
- 4
1.1、Limit语句
典型的查询会返回多行数据。limit子句用于限制返回的行数。
其实limit发挥作用是在map到reduce阶段,每一个maptask,都是只把limit中设置的行数传给reduce端,而不是默认的将map的所有数据都传给reduce
这个东西在之后的order by中结合使用会避免进行全局排序的时候内存溢出
select *
from emp
limit 5;
select *
from emp
limit 2,3; -- 表示从第2行开始,向下抓取3行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2、Where语句
过滤条件
1.3、关系 & 逻辑运算符
// 在讲义的第41-42页
- 1
1.4、聚合函数
通常是和分组操作结合使用

其中,count(*),里面是count(1),2,3都是一样的含义,只要不为空都表示统计所有行数
但是需要注意,如果是统计某列,那么不会统计出来其中是空值的行数
这个聚合函数统计出来的结果通常会跟着分组选中的列,放在其后面
2、分组Group by & having
2.1、Group by
如果使用了分组,那么select后面跟着的列名必须是进行分组的列名,以及聚合函数
比如,第二行是不可以的,不能有dename这个列:
select
t.deptno,
t.dename,
avg(t.sal) avg_sal
from emp t
group by t.deptno;
- 1
- 2
- 3
- 4
- 5
- 6
上面查询语句的逻辑其实相当于是:
- 先分组,执行最下面的分组语句
- 然后再在每一个组内应用聚合函数。!注意是每一个组内使用聚合
2.2、Having
where语句是针对数据中每一行进行过滤的
而Having是针对分的组进行过滤的,相当于是根据条件去判断每一组是否符合条件,而不是一行了
比如:
select -- 求每个部门的平均薪水大于2000的部门
deptno,
avg(sal) avg_sal
from emp
group by deptno
having avg_sal > 2000;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3、Join
主要区分为内连接、外连接和多表连接
可以使用别名简化查询,同时方便区分字段的来源
-- 看讲义的第46页-50页
- 1
3.1、内连接
join 和 inner join的含义一样,可以省略inner
3.2、左外连接 & 右外连接
使用内连接的时候有可能有些数据并没法连接上,就会需要外连接
比如想要根据学号连接两个表,但是左表中存在的一些学号,在右表中并未找到。
-- 具体的画图可以看讲义中第47页,有手绘和分析
- 1
3.3、满外连接
就是左+右连接,具体看图可以在讲义48页
from 表A
full join 表B
on xx = yy
- 1
- 2
- 3
3.4、多表连接
就是连续多个表一起连接**,n个表连接,至少需要n-1个join**
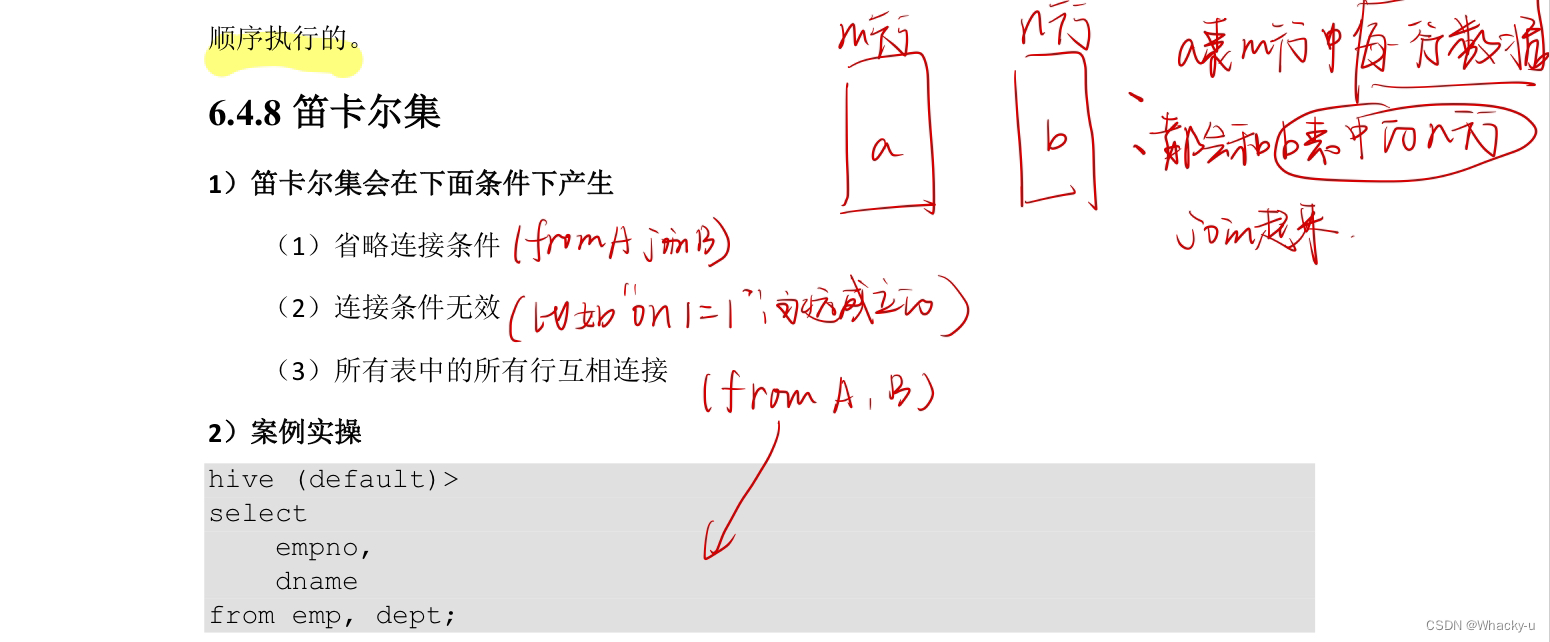
3.5、笛卡尔集
A表m行数据,B表n行数据
A表中的每一行数据都会和B表中的n行数据join起来
产生条件有三个:
4、联合Union
和join的不同之处在于,他是两张表上下拼接
所以会要求:
- 两个表的字段个数(列数)是一样的
- 两个表对应的字段类型要一样,不过名字可以不一样,最后虚拟表中该位置的字段名字和最上面一张表名字一样
-- 同时需要注意的是,这个是连接的两个查询语句,而不是两个表
-- 具体可以看讲义的48-49页有手写注意事项
- 1
- 2
- 3
5、Order by全局排序
-- 在讲义的第50页-53页
后面的三个by不常用,了解即可,可以看讲义
重点掌握order by
- 1
- 2
- 3
全局排序,默认asc升序
desc是降序
五、函数
1、单行函数
-- 注意:单行函数,就是针对表中的每一行都执行这个函数的操作
- 1
比如select sal + 1,那就是对表中sal这个字段中的每一行都执行一次加一操作
同理sum(if(sal,1,0)),意思就是对sal这个字段的每一行先进行 if 判断,如果当前行的sal是null,就赋值为0,否则为1,这样相当于sal字段的每一行现在不1,就是0,然后对所有行再进行聚类和求和操作
1.1、算数运算函数 & 数值函数
-- 在讲义第55页
- 1
- 加减乘除那些运算符
- 以及四舍五入的round函数,向上取整的ceil函数,向下取整的foor函数
一个数和null做运算,结果也是null
1.2、字符串函数
-- 在讲义55-58页
- 1
-
**substring:**截取字符串
substring(string A, int start, int len) // 注意这里的start是从1开始的,不像是数组是从0开始的- 1
-
**replace:**替换
replace(string A, string B, string C) // B是被替换的子字符串- 1
-
**regexp_replace:**正则替换【重要!!!】有三个参数
regexp_replace(string A, string B, string C) //正则表达式B的部分,替换为C。注意,在有些情况下要使用转义字符。- 1
因为B首先是被java去当作字符串去看的
虽然我们被要求是去写正则表达式,在写了正则表达式之后计算机也能帮我们识别他的含义
但是首先还是会被当作字符串来处理的,所以你的正则表达式A里面如果有“ \ ”开头的符号,需要再在A外面加一个“ \ ”,变为“ \ A”,否则会被认为一开始的A就是有转义字符的。
举个例子:
正则里面的一个注意点:
在使用正则表达式的时候,如果我们单纯的想要用“ 。”,这个符号,但是正则里面 “ 。”表示任意字符,也就是说,我们不想要用这个含义,但是我们的函数规则参数要是正则表达式。我们就会想到用转义字符 \ 来处理,也就是 “ \\. ”,但是可以发现还是不可以 是因为 正则表达式用 “点” 来表示任意字符,所以表示 “点” 需要用 \. 而正则表达式用字符串表示,字符串里面\表示转义字符,所以JVM处理时,\. 不在转义字符表里面 无法处理 所以需要用\\. 表示。这样JVM先处理\\. 为\. 再通过正则表达式的转义,转换成 我们要的“点” 。- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
**regexp:**正则匹配
返回值是true,false
举个例子:select ‘dfsaaaa’ regexp ‘dfsa+’
-
**repeat:**重复字符串
repeat(string A, int n)- 1
-
**spilt:**字符串切割
split(string str, string pat)- 1
-
以pat分割,pat是正则表达式
-
返回形式是数组
-
**nvl:**替换null值
nvl(A,B) // 若A的值不为null,则返回A,否则返回B // 具体可以见讲义57页,有手写例子- 1
- 2
这个用到的比较多
正常来说A和B就是表中的一个字段名
-
可以多表连接的时候,用作判断第三个表用来和前面两个表哪个连接比较好
-
也可以当作赋默认值,select nvl(score,0)。
如果score存在那就是原数据,如果不存在那就是0。因为是针对行数据一行一行去判断的,所以可以对score字段中的所有行进行判断和赋值
-
**concat:**拼接字符串
concat(string A, string B, string C, ……) //我们也可以使用 || 进行拼接,效果一样 比如A||B||C- 1
- 2
- 3
-
concat_ws:以指定分隔符拼接字符串或者字符串数组
concat_ws(string A, string…| array(string)) //使用分隔符A拼接多个字符串,或者一个数组的所有元素。- 1
-
get_json_object:解析json字符串
get_json_object(string json_string, string path) // 解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL- 1
- 2
这个path,相当于就是json对象中的key
需要先$一下,比如 $[0].name
用法就是,先$一下,如果是数组,就用【i】来表示第几个,然后里面是结构体对象的话,就用点来找对应的key
1.3、日期函数
-- 主要看讲义的第58-60页
- 1
这里需要注意的就是时间戳的概念,和他返回的时间戳是以零时区为基础返回的,但是我们目前所处的是东八区,也就是他会自动默认你现在的时间是零时区的,并没有当作东八区
这里举几个会常用的:
-
**current_date:**当前日期
-
**current_timestamp:**当前日期加时间,考虑到时区了,精确到毫秒
-
**month(date):**返回日期中的月份。同理year、day、hour、second、minute等
-
**datediff(date1,date2):**返回相差的天数
-
**date_format:**将标准日期解析成指定格式
select date_format('2022-08-08','yyyy年-MM月-dd日')- 1
重点!!!!需要注意!
我们的日期格式都是 yyyy-MM-dd hh-MM-ss,大小写固定的啊,然后再去可以更改连接符号之类的
另外我们输入函数的时间date参数,必须是2022-08-08类似这样的,用横线分隔符
1.4、流程控制函数
一般都是跟在select后面的字段部分,进行筛选判断,或者判断的基础上进行赋值
-- 在讲义的第61页,有手写笔记很详细
- 1
- Case when
- if 三元运算符
1.5、集合函数
-- 在讲义的第61-63页,有手写笔记很详细
- 1
-
map
-
map_keys: 返回map中的key
-
map_values: 返回map中的value
-
-
array
-
array_contains: 判断****array中是否包含某个元素**。第二个参数为被判断的字符元素
-
sort_array:将array中的元素排序
-
-
struct
struct(‘name’,‘age’,‘weight’);这里的参数只用传值,名字默认是col1、col2等等,如果想要自己命名
named_struct声明struct的属性和值:
named_struct(‘name’,‘xiaosong’,‘age’,18,‘weight’,80);
-
size计算长度
2、聚合函数
多进一出 (多行传入,一个行输出)。
其逻辑就是:将指定的一列,中的每一行的值聚合成一个数组
下面两个函数的区别就是是否去重
返回值都是数组
- collect_list 收集并形成list集合,结果不去重
- collect_set 收集并形成set集合,结果去重
select
sex,
collect_list(job)
from
employee
group by
sex
-- 结果:
女 ["行政","研发","行政","前台"]
男 ["销售","研发","销售","前台"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3、炸裂函数
-- 具体见讲义第69页到70页
- 1
具体是叫,UDTF制表函数。
接收一行数据,输出一行或多行数据,其实就是返回一个表(多行多列)
需要注意,炸裂函数里面的参数只能收原表名,不能是别名。如果想用别名,可以使用子查询
3.1、三个内涵
-
把数据由少变多
-
UDTF表示一类函数,有很多个,而不是一个
-
通常和lateral view一起使用,比如:
select * from table1 lateral view explode(hobbies) tmp as 别名 -- 这里tmp相当于就是这个炸裂函数求出来的新的表,这个虚拟表的别名 -- 后面跟着的是打算将这个表的所有字段放进前面的 table1 中显示的字段名- 1
- 2
- 3
- 4
- 5
3.2、四个具体函数
-
explode(ARRAY< T > a)
给一个数组,炸裂成一列,再通过lateral view,进行join操作与原表拼接到一起
-
explode(MAP< K,V > m)
给一个MAP,炸成两列,一列key,一列value
-
posexplode(ARRAY< T > a)
炸成两列多行,一列pos位置,一列数组元素
-
inlinie(ARRAY< STRUCT< f1:t1…> > a)
炸成多行多列。每一行是一个结构体,每一列是结构体中的每个属性的值
3.3、举个例子
这里具体举个例子,根据上述电影信息表,统计各分类的电影数量,由表一变到表二:
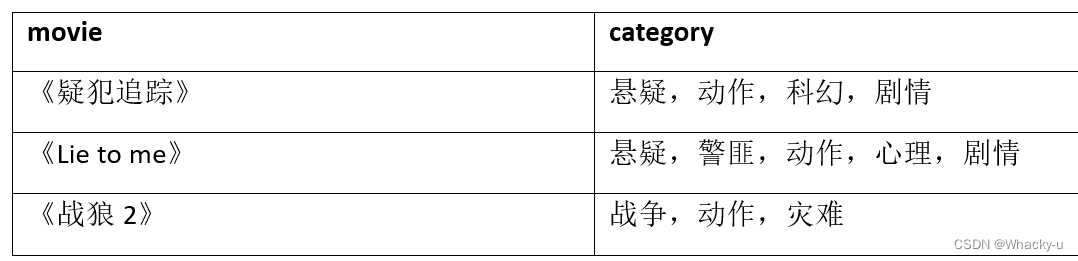
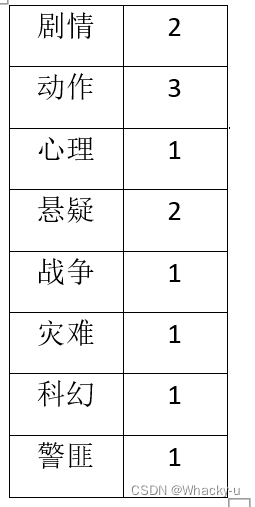
select cate, count(*) from ( select movie, cate from ( select movie, split(category,',') cates from movie_info )t1 lateral view explode(cates) tmp as cate )t2 group by cate;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4、窗口函数
主要划分两部分:窗口范围、窗口函数
-- 具体见讲义69-73页
- 1
4.1、窗口范围
主要划分两类:基于行、基于值
这里除了看下面的图,再补充一下基于值的意思,其实相当于如果当前值是5,然后我们的窗口范围是当前值-1到当前值的话那就是,去该字段中寻找属于此范围的字段【当前值-1,当前值】,左闭右闭

-
另外再说一下语法: 1. 基于行是,over(order by 字段名 rows between ---------- and -------------) 2. 基于值是,over(order by 字段名 range between ---------- and -------------)- 1
- 2
- 3
- 4
这里有四个需要明白的
1、order by 的范围
order by在两类划分串口范围中起到的作用
1、如果是基于行:
我们需要明白一点,我们窗口范围针对的是实际 Mapreduce 计算阶段的字段顺序,如果不使用order by
进行排序,那么最后如果我们窗口范围划分是上一行到当前行,那上一行随机可能是任意行了,没有任何意义
2、如果是基于值:
我们order by后面跟着的就是告诉要根据哪个字段进行划分窗口
而且需要注意的是!!!!!!!!!!!!!!!!!!!
如果我们在基于值使用order by的时候,这个字段的数据类型需要注意一下
-- 基于值的情况下。后面between中跟的是【num】preceding的时候,这个order by后面跟着的字段必须是整数类型
-- 且num也要是整数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2、range & rows
到底是range还是rows
-- range表示基于值划分
-- rows表示基于行划分
- 1
- 2
3、between和and中的内容怎么填写
**between后什么样的颜色,对应and 后面什么样的颜色。**不能混乱搭配
-- 在基于行中:
1、unbounded preceding表示是第一行、unbounded following表示最后一行
2、[num] preceding 表示前num行、[num] following 表示后num行
-- 在基于值中:
1、unbounded preceding表示是负无穷、unbounded following表示正无穷
2、[num] preceding 表示当前值减去num值、[num] following 表示当前值加上num值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
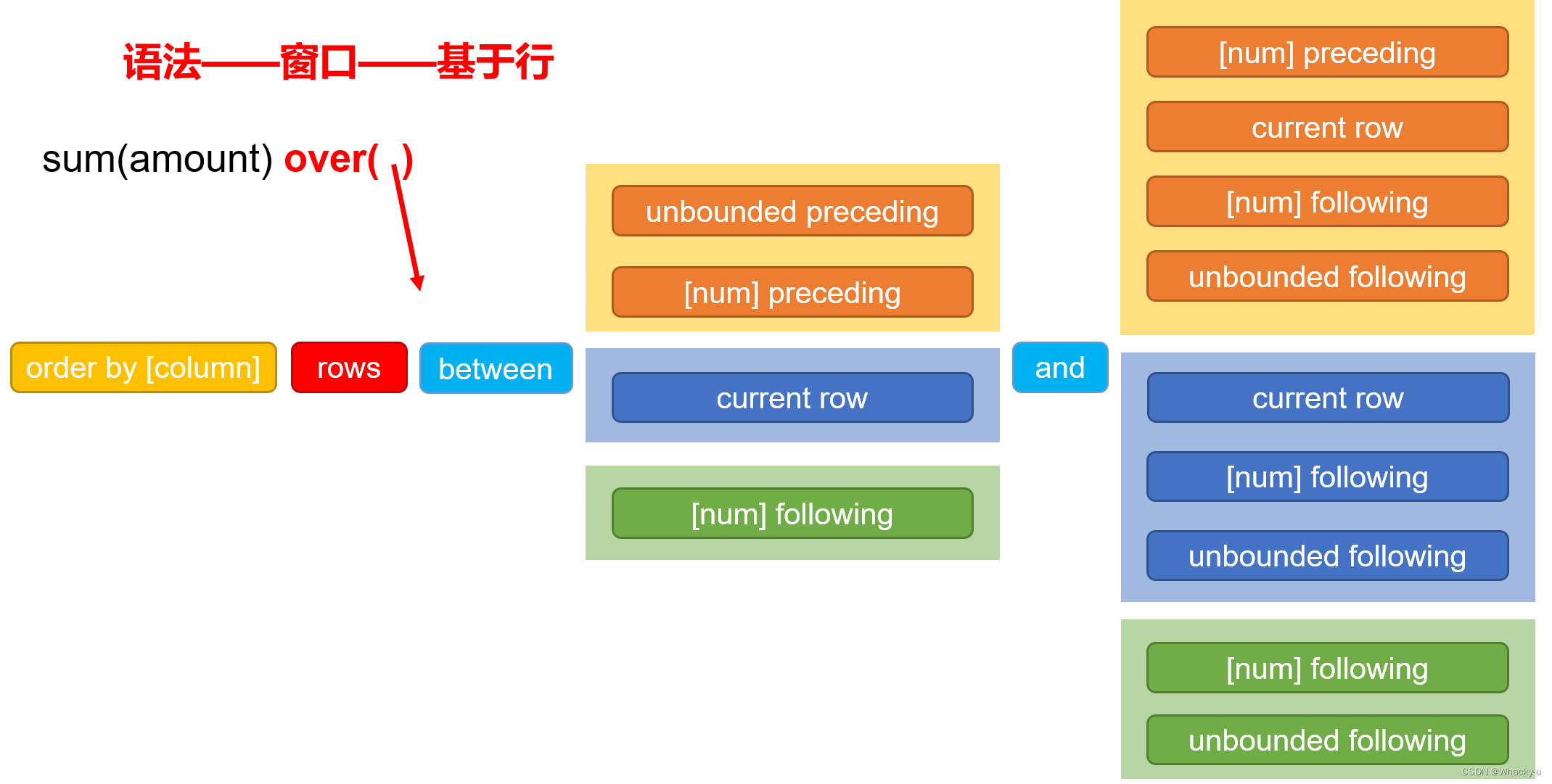
4、分区和缺省
可以进行分区划分
也可以进行某些缺省


4.2、窗口函数
主要涉及聚合函数、跨行取值函数、排名函数
其中跨行取值函数中的lead和lag,以及排名函数不支持自定义窗口
1、聚合函数 & 高级聚合函数
2、跨行取值函数
(1)lead 和 lag
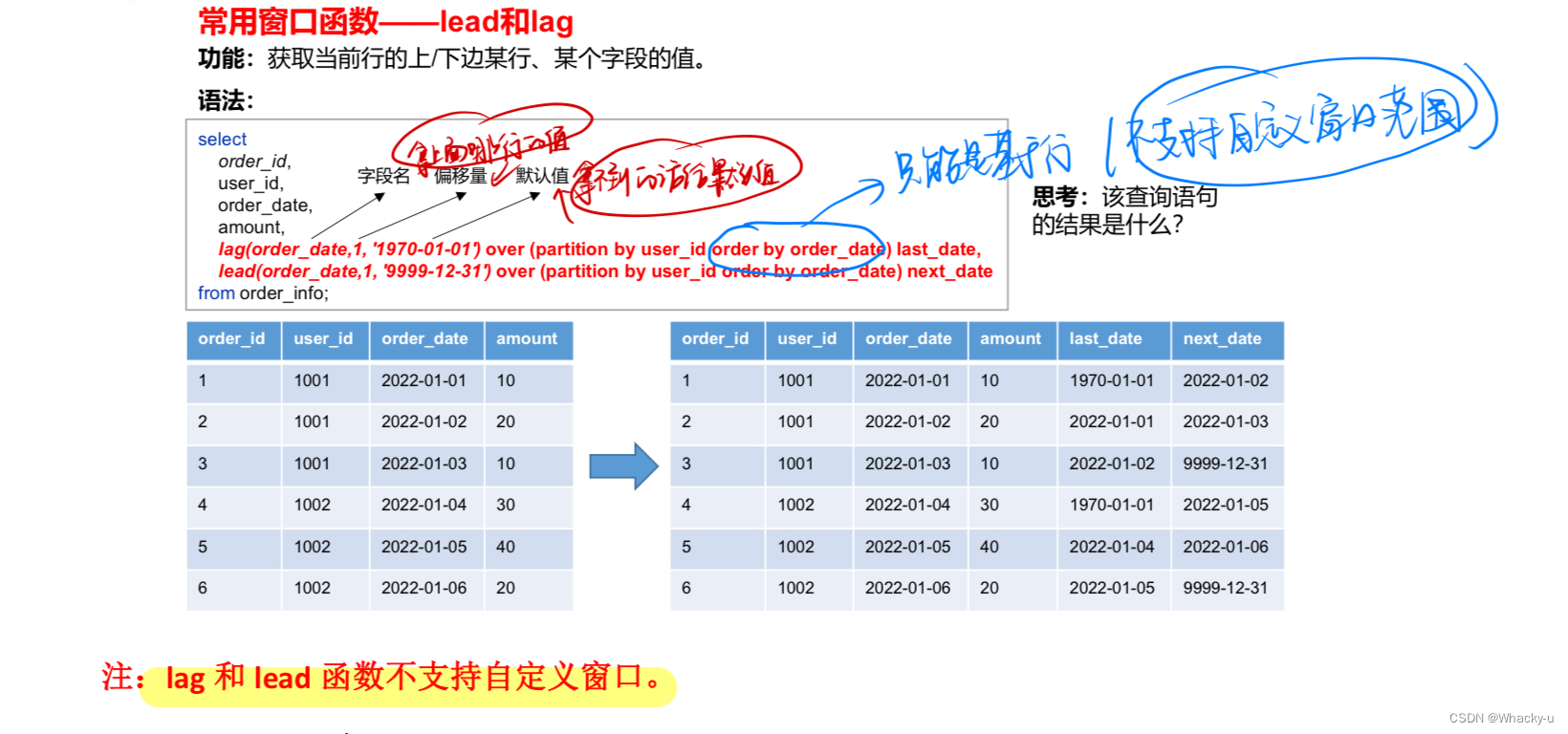
(2) first_value 和 last_value

3、排名函数

这个可以用在 分组TopN
就是找到成绩中排名前几的,我们就可以借助窗口函数里的排名函数 + 子查询加一个where条件
比如:
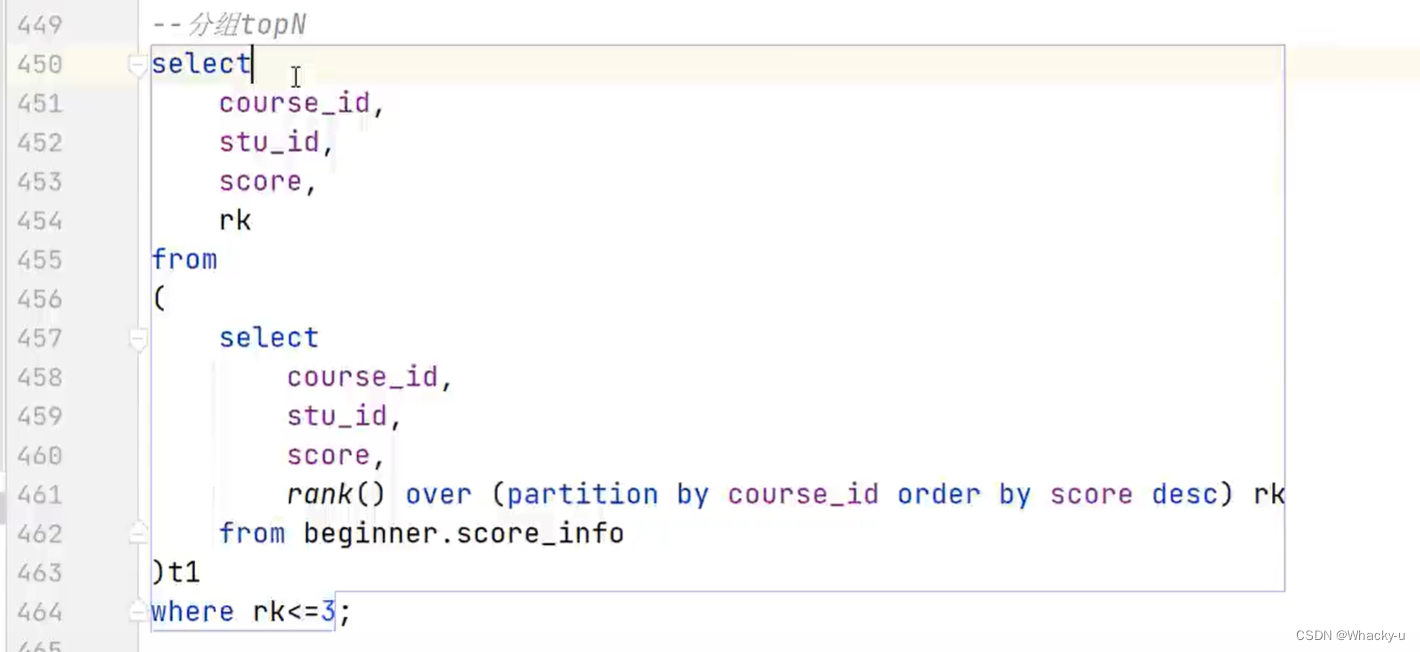
4.3、三个例子
1、基于行
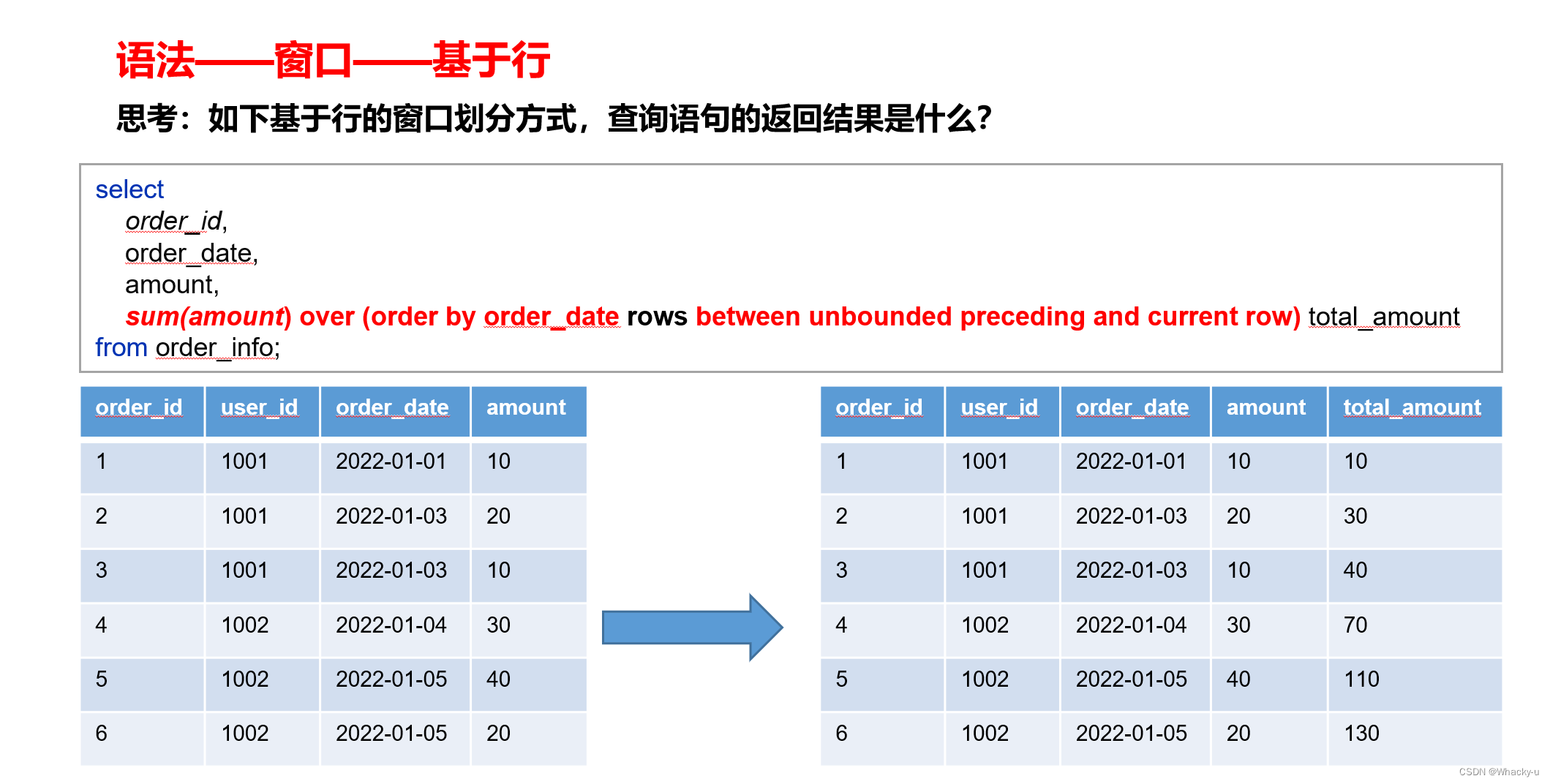
2、基于值
重点理解一下,和基于行的对比order_id中对应是2和3,基于行和基于值的total_amount的值不一样

3、分区
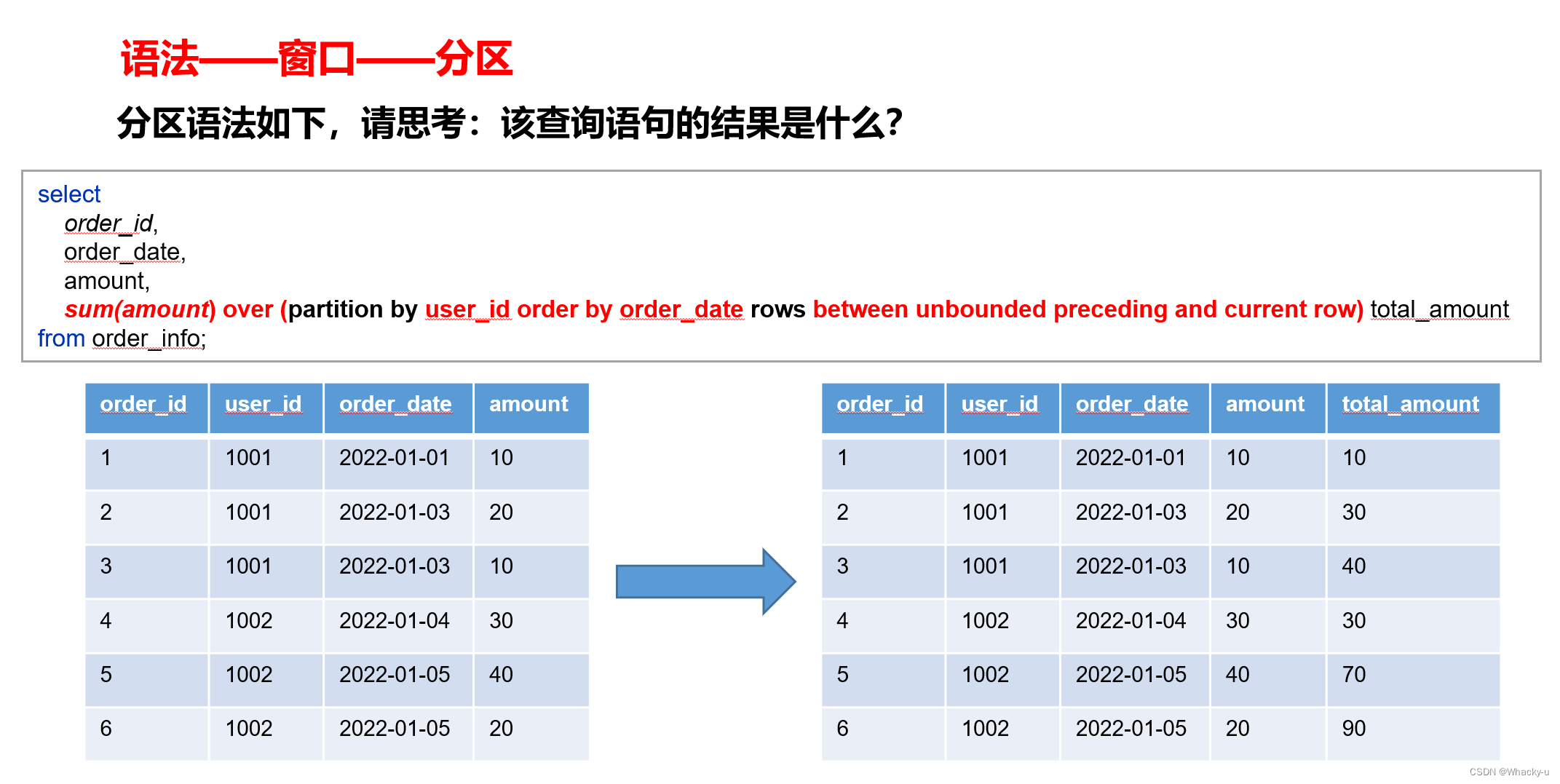
六、去重三部曲
-- distinct去重 select distinct user_id, create_date from order_info; -- group by去重 select user_id, create_date from order_info group by user_id,create_date; -- 窗口函数中的排序函数row_number去重 select user_id, create_date from ( select user_id, create_date row_number() over(partion by userid,create_date) rn from order_info )t1 where rn=1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
七、join中的null值使用
在使用join连接的时候
可以通过join连接,找到两个表的补集,其实意思就是,可以找到A表中存在,但是在B表中不存在的元素
比如A left join B的时候,如果左边A表中的元素在B表中没有存在,那么就是null
这时候我们可以通过看哪些元素有null,就知道哪些是A表中存在,但是在B表中不存在的元素
八、自定义函数UDF
当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数
(UDF:user-defined function)。
一般都是自定义单行函数
不过还可以自定义聚合函数,以及自定义表生成函数【炸裂函数】
1、步骤
(1)继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
- 1
- 2
- 3
(2)实现类中的抽象方法
一共有三个,重点掌握前两个,第一个是完成一些初始化操作,比如参数类型和个数的校验,以及函数输出结构的数据类型确定一下
(3)在hive的命令行窗口创建函数
添加jar。
add jar linux_jar_path
- 1
创建function。
create [temporary] function [dbname.]function_name AS class_name;
- 1
(4)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
- 1
2、编码举例
-- 具体看讲义79-80页
-- 代码中也有讲解。主要编写前两个方法的内容即可
- 1
- 2
- 3
3、上传hive、创建临时函数
临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,
在当前会话下,任意一个库都可以使用,其他会话全都不能使用
-
jar包打包后上传服务器。注意只能是上传到HiveServer2 所在节点的路径!!!!!!!
-
将jar包添加到hive节点的path路径:add jar /opt/module/hive/datas/名字.jar;
-
创建临时函数和开发哈后的java class关联:
create temporary function my_len as "com.atguigu.hive.udf.MyUDF"; -- 这个是jar包中的全类名,就是自己编写的代码全类名- 1
- 2
4、上传hive、创建永久函数
永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。
永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名
1、因为add jar本身也是临时生效,所以在创建永久函数的时候,
需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
也就是说和上面不同的是,jar包需要存放在hdfs路径上
2、并且在创建函数和开发好的java class的时候也不一样
create function my_len2 -- 这个是函数名,但是实际的名字是create这个函数的所在库名.my_len2
as "com.atguigu.hive.名字.MyUDF" -- 全类名
using jar "hdfs://hadoop102:8020/udf/名字.jar"; -- 这是hdf中jar包实际存放的位置
- 1
- 2
- 3
接下来的内容就是和优化性能相关了
1)存储优化:分区分桶、文件格式和压缩
2)配置优化:企页调优、算法
九、分区表和分桶表
1、分区表
-- 主要在讲义第82-86页
- 1
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录【多个hdfs存储目录】
每个目录就称为该表的一个分区。每一个路径名:“ 分区字段名 = 分区名【这个就是分区字段属性值】 ”
这样的好处是:
对数据划分后,不用对全表进行全局搜索,只用定位到需要的部分所在目录即可
关键语法就是,在建表的时候加上partitioned by (day string) 这个也可以看作是表中的一个字段,不过分区后,这个字段中的值都是一样的,因为我们就是基于这个值进行分区的,所以当前分区的这个字段的值肯定是一样的。且一般都是string类型
create table dept_partition
(
deptno int, --部门编号
dname string, --部门名称
loc string --部门位置
)
partitioned by (day string) -- 这里就是关键!!!!!!!!!!!!!!!!!
row format delimited fields terminated by '\t';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.1、分区表load和insert插入数据
都需要在表名后面加上partition (分区字段名=’ 字段值,也就是分区的名字 ')
需要注意的是,在load和insert的时候,**分区字段不用写入数据!!!**因为,相当于在括号里赋值了
-- load
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition
partition(day='20220401');
-- insert 我们使用insert加载数据的话,一般是基于查询进行插入数据
insert overwrite table dept_partition partition (day = '20220402')
select deptno, dname, loc
from dept_partition
where day = '20200401';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.2、分区表读数据
查询分区表数据时,可以将分区字段看作表的伪列,可像使用其他字段一样使用分区字段。
可以直接**where day = ‘2020-04-01’;**用作过滤条件,不同这样相当于只能查到分区为2020-04-01的表数据
1.3、分区表基本操作
-- 主要看讲义第83页
- 1
-
查看所有分区信息:show partitions 分区表名;
-
增加分区
可以增加单个分区、增加多个分区
就是alter … add…语法
alter table dept_partition add partition(day='20220403'); alter table dept_partition add partition(day='20220404') partition(day='20220405');- 1
- 2
- 3
- 4
- 5
- 6
-
删除分区
同理上面,分为两类,把add换成drop
-
修复分区
我们需要明白,有元数据与HDFS上的分区路径一致时,分区表才能正常读写数据。
所以如果路径不一致,就会有问题
这里说的恢复分区也只是用于,参照HDFS路径的信息,去补充恢复元数据路径
也就是说,如果元数据路径在,但是hdfs路径消失,那我们是没有办法恢复的!!!!!!!!!
有三种,前两种分别是再次进行add,和drop,就是上除的增加和删除分区操作,这个需要指定分区,针对某一个出问题的分区
第三种是msk,其中msk是不需要指定分区,一下全部都恢复,并且不论是少或者多:
msck repair table table_name [add / drop / sync partitions];- 1
1.4、二级分区表
-- 主要看讲义第84页
- 1
相当于一层一层的建下去,比如一开始分区是按天分区的,每一天一个区。字段就是day
现在再对每一天的数据按小时进行分区,也就是hour
这种语法就是,在建表的时候partition by那里多加一个字段,如下:
create table dept_partition2(
deptno int, -- 部门编号
dname string, -- 部门名称
loc string -- 部门位置
)
partitioned by (day string, hour string) -- 建立分区!!!!!!二级分区
row format delimited fields terminated by '\t';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
同理
数据加载也是在括号内多加了一个字段
load data local inpath '/opt/module/hive/datas/dept_20220401.log'
into table dept_partition2
partition(day='20220401', hour='12'); -- 看这里!!!!!!!!!!!!!!!!!!!!
- 1
- 2
- 3
1.5、动态分区
-- 主要看讲义第85页
- 1
动态分区是指向分区表insert数据时,被写往的分区不由用户指定,而是由每行数据的最后一个字段的值来动态的决定。
使用动态分区,可只用一个insert语句将数据写入多个分区。
【动态分区是在使用insert往分区表中插入数据时候的一个概念】
所以我们没有指定划分为几个,没有为每个划分的区起名字,就是没有根据自定义分区字段进行赋值
而是在insert语句的时候,看其查询语句的最后一个字段,根据不同的字段,一个字段值分一个区,在动态分区insert的时候,我们并没有在insert into 表名 partition (分区字段名 = 字段属性值)
而是nsert into 表名 partition (分区字段名),之后依据select的查询语句的最后一个字段来分区
create table dept_partition_dynamic(
id int,
name string
)
partitioned by (loc int)
row format delimited fields terminated by '\t';
insert into table dept_partition_dynamic
partition(loc) -- 看这里,我们并没有为其指定分区的名字
select
deptno,
dname,
loc -- 而是依据这里的loc的字段值,一个loc值分区一个
from dept;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
另外,需要注意动态分区的相关参数,有时候报错,或者不起作用是参数的问题,一般记得还是要设置非严格模式,默认是严格模式
2、分桶表
-- 主要在讲义第86-88页
- 1
将一张表的数据分散到不同文件中,相当好与对一个表进行哈希分区
为每行数据计算一个指定字段的数据的hash值,然后模以一个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)。
1、分桶表建表
主要看建表语法,我们需要定义分桶个数,其实分几个桶就是分了几个文件
create table stu_buck(
id int,
name string
)
clustered by(id) -- 主要看这两行
into 4 buckets
row format delimited fields terminated by '\t';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2、分桶排序表
至于分桶排序表,就是在上述建表的基础上加一个sorted by
这样在加载数据的时候,加载到表中的数据既是划分好不同文件的,也就是桶数相同的文件个数中,不同文件中的数据还进行了排序
create table stu_buck_sort(
id int,
name string
)
clustered by(id) sorted by(id) -- 需要注意分桶的字段和sort的字段可以不同,并且sort中的字段可以是多 -- 个,比如sorted by(id,name)
into 4 buckets
row format delimited fields terminated by '\t';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
十、文件格式和压缩
1、文件存储
文件格式是为了我们可以读取数据更快,平常我们都是从文本文件中读取数据,但是实际生产中,常用的是orc和parquet类型的文件
这两种文件都是按列存储,在讲义中详细讲解了他们的存储构造和存储逻辑,会可以更快地读取数据,这点主要是针对数据优化上来说地,不影响我们实际查询,只需要在建表的时候 stored as 文件类型 声明一下文件类型即可
-- 具体可以看讲义的88-92页
- 1
create table orc_table
(column_specs)
stored as orc -- 这里也可以是parquet
tblproperties (property_name=property_value, ...);
-- 最后一行是加参数 比如是tblproperties(参数名字 = 参数值)
- 1
- 2
- 3
- 4
- 5
可以多看看讲义中记得笔记,那两个文件存储的基本格式图!!!!!!!!!!!!!!
2、压缩
主要是压缩数据文件,和在计算过程中,就是mapreduce阶段的压缩。
保持数据的压缩,对磁盘空间的有效利用和提高查询性能都是十分有益的。
-- 具体看讲义的第92-93页
- 1
主要看讲义中是怎么配置参数进行设置压缩的
其中在对表数据进行压缩的text文本文件中,划分两种数据加载方式
- 如果是load,那我们可以直接把压缩好的数据文件load到表里,这样之后也可以查询,hive会自动识别解压
- 如果是insert,想要插入表中的数据是压缩的,需要配置参数。就在窗口set一下即可
另外两种文件格式,只要在建表的时候加上,tblproperties (“parquet.compression”=“snappy”);,里面的parquet可以换成orc
数据插入的时候就会变成压缩格式,查询读取的时候也可以自动识别

