
热门标签
热门文章
- 1小程序自定义头部,返回按钮,指定返回某页面_小程序自定义头部之后怎么返回
- 2Git回滚操作,工作区和暂存区恢复修改删除的文件_git命令行回滚本地文件
- 3【网络协议】应用层协议HTTPS
- 42024-04-05 问AI: 介绍一下深度学习中的Leaky ReLU函数_leakyrelu
- 5TCP/IP协议栈的基本工作原理
- 6人工智能第三版|chap01|task01
- 702H5C3-4. 常用样式_h5inherit
- 8Mac 安装php7.2+和composer_mac php7.2
- 9风光储并网协同运行模型研究(Simulink仿真实现)_风光储并网协同运行研究历史
- 10AI PC开发英才公开课_恭喜您已被英特尔 ai pc开发英才公开课选中是假的
当前位置: article > 正文
第五章重采样方法
作者:喵喵爱编程 | 2024-06-26 18:45:52
赞
踩
第五章重采样方法
目录
第二题
我们现在将推导一个给定观测值是引导样本一部分的概率。假设我们从n个观测值中获得一个引导样本。
(a) 第一个引导观测值不是原始样本中第j个观测值的概率是多少?请证明你的答案。
(b) 第二个引导观测值不是原始样本中第j个观测值的概率是多少?
(c) 论证原始样本中第j个观测值不在引导样本中的概率是(1 − 1/n)^n。
(d) 当n = 5时,第j个观测值在引导样本中的概率是多少?
(e) 当n = 100时,第j个观测值在引导样本中的概率是多少?
(f) 当n = 10,000时,第j个观测值在引导样本中的概率是多少?
回答:
(a) 第一个引导观测值不是原始样本中第j个观测值的概率: 每个观测值被选中的概率是1/n。因此,第j个观测值不被选中的概率是1 - 1/n。
(b) 第二个引导观测值不是原始样本中第j个观测值的概率: 由于每次选择都是独立的,第二次选择和第一次选择相同,因此概率也是1 - 1/n。


第三题
k折交叉验证的实现步骤:
- 划分数据集:将整个数据集随机分成k个等大小的子集(folds)。
- 训练与验证:对于每个子集:
- 使用其中的k-1个子集作为训练集。
- 使用剩下的1个子集作为验证集。
- 训练模型并在验证集上进行评估,记录模型的评估结果(例如误差)。
- 重复:重复上述过程k次,每次选择不同的子集作为验证集。
- 计算平均性能:将所有k次验证结果的评估指标取平均值,作为模型的最终性能指标。
通过这种方式,可以有效利用数据进行模型评估和调优,减少过拟合的风险。
(b) k折交叉验证相对于其他方法的优点和缺点:
i. 相对于验证集方法:
- 优点:
- 更稳定和可靠的性能估计:验证集方法仅使用一次划分,评估结果可能对数据划分方式非常敏感。而k折交叉验证通过多次划分,得到的评估结果更为稳定和可靠。
- 更充分利用数据:验证集方法将一部分数据作为验证集,导致训练数据减少。而k折交叉验证每次只用1/k的数据作为验证集,其余数据用于训练,因此更充分地利用了所有数据。
- 缺点:
- 计算开销更大:k折交叉验证需要进行k次训练和验证,计算量是验证集方法的k倍。
- 实现复杂度较高:相较于验证集方法,k折交叉验证的实现稍微复杂一些。
第四题
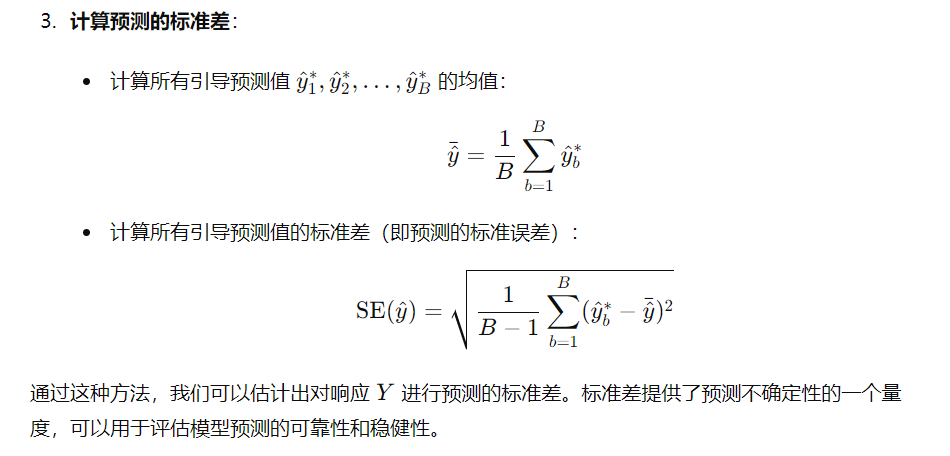
假设我们使用某种统计学习方法对特定的预测变量X进行响应Y的预测。请详细描述如何估计我们预测的标准差。
回答:
为了估计对响应 YYY 的预测的标准差,我们可以采用以下步骤:
-
使用训练集训练模型:使用现有的数据训练一个统计学习模型,得到预测模型 f^(X)\hat{f}(X)f^(X)。
-
获取多次预测:为了估计预测的标准差,可以采用重采样方法,例如引导法(bootstrap)或k折交叉验证(k-fold cross-validation)来获得多个预测值。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

