
热门标签
热门文章
- 1你好GPT-4o——对GPT-4o发布的思考与看法_gpt-4o global deployment128k的发布时间
- 2vue-cli3.0配置不同的网址(根据不同的环境进行网址切换)_vue3怎么切换接口地址用的是env还是env.dev
- 3各科目考试成绩可视化项目_学生成绩分布情况数据集
- 4大数据基础知识之什么是服务器什么是集群_集群和服务器有什么区别
- 5苹果Mac安装adobe软件报错“installer file may be damaged”解决方案
- 6SEO工具,SEO优化人员必备工具
- 7【Elasticsearch】Elasticsearch索引创建与管理详解_elasticsearch 设置字段索引
- 8安装git、git与pycharm结合使用_pycharm中git没装会咋样
- 9Python中的pyserial介绍
- 10应急响应靶机-Linux(1)_应急响应靶机训练-linux1题解
当前位置: article > 正文
模型过拟合原因及解决办法_模型容易过拟合的原因
作者:喵喵爱编程 | 2024-07-02 06:57:00
赞
踩
模型容易过拟合的原因
过拟合现象
对于样本量有限、但需要使用强大模型的复杂任务,模型很容易出现过拟合的表现,即在训练集上的损失小,在验证集或测试集上的损失较大
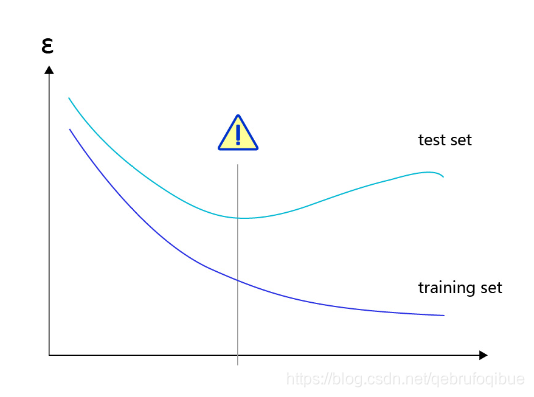
反之,如果模型在训练集和测试集上均损失较大,则称为欠拟合。过拟合表示模型过于敏感,学习到了训练数据中的一些误差,而这些误差并不是真实的泛化规律(可推广到测试集上的规律)。欠拟合表示模型还不够强大,还没有很好的拟合已知的训练样本,更别提测试样本了。因为欠拟合情况容易观察和解决,只要训练loss不够好,就不断使用更强大的模型即可,因此实际中我们更需要处理好过拟合的问题。
导致过拟合原因
- 情况1:训练数据存在噪音,导致模型学到了噪音,而不是真实规律。
- 情况2:使用强大模型(表示空间大)的同时训练数据太少,导致在训练数据上表现良好的候选假设太多,锁定了一个“虚假正确”的假设。
回归模型的过拟合,理想和欠拟合状态的表现
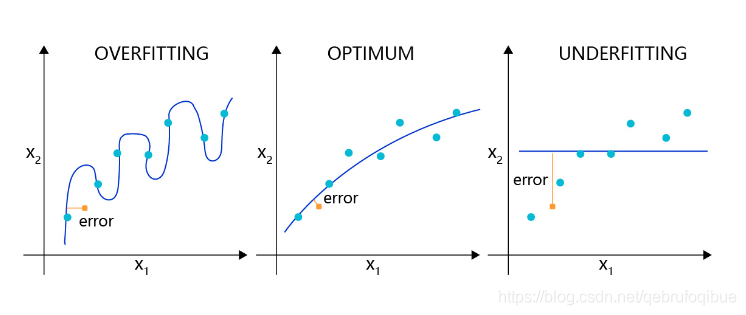
理想的回归模型是一条坡度较缓的抛物线,欠拟合的模型只拟合出一条直线,显然没有捕捉到真实的规律,但过拟合的模型拟合出存在很多拐点的抛物线,显然是过于敏感,也没有正确表达真实规律。
分类模型的欠拟合,理想和过拟合状态的表现
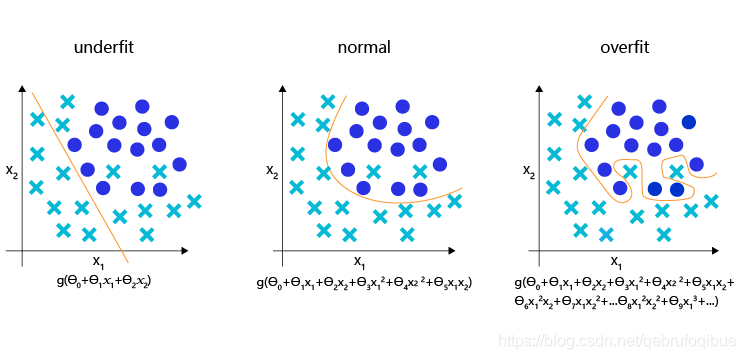
理想的分类模型是一条半圆形的曲线,欠拟合用直线作为分类边界,显然没有捕捉到真实的边界,但过拟合的模型拟合出很扭曲的分类边界,虽然对所有的训练数据正确分类,但对一些较为个例的样本所做出的妥协,高概率不是真实的规律。
解决办法
对于情况1,我们使用数据清洗和修正来解决。 对于情况2,我们或者限制模型表示能力,或者收集更多的训练数据。
而清洗训练数据中的错误,或收集更多的训练数据往往是一句“正确的废话”,在任何时候我们都想获得更多更高质量的数据。在实际项目中,更快、更低成本可控制过拟合的方法,只有限制模型的表示能力。为了防止模型过拟合,在没有扩充样本量的可能下,只能降低模型的复杂度,可以通过限制参数的数量或可能取值(参数值尽量小)实现。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
- 第一种方法
[详细] -->赞
踩
相关标签

