
- 1Python基础教程(二十):SMTP发送邮件
- 2Java实现发送邮件功能_java邮件功能
- 3c#label控件_c# label
- 4【故障诊断】基于matlab EMD滚动轴承故障诊断(外圈 时域 频谱 包络图)【含Matlab源码 4389期】_emd包络谱matlab
- 5一篇文章为你揭秘pytest的基本用法_pytest.mark.run
- 6STM32H750时钟频率和功耗以及RTC功能测试
- 7一个比SDXL更快的模型——Stable Cascade【避坑指北】
- 8java 面试流程_字节跳动Java岗三面,鬼知道我经历了些什么,泪谈一下面试过程(附面试解析)!...
- 9AI 写高考作文:10 款大模型,实力水平如何?_qwen2-72b vs文心一言
- 10SQL 初级教程_sql语句分号用法
PySpark--spark local 的环境部署_pyspark local
赞
踩
Spark环境搭建-Local
环境搭建

基本原理
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task
- Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或 Local[*]
- 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力.
- 如果是local[*],则代表 Run Spark locally with as many worker threads as
logical cores on your machine.按照Cpu最多的Cores设置线程数
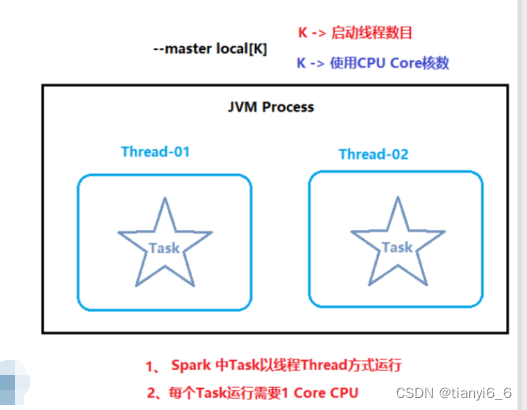
Local 下的角色分布:
- 资源管理:
Master:Local进程本身
Worker:Local进程本身
- 任务执行:
Driver:Local进程本身
Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
PS: Driver也算一种特殊的Executor, 只不过多数时候, 我们将Executor当做纯Worker对待, 这样和Driver好区分(一类是管理 一类是工人)
注意: Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行
spark-3.2.0-bin-hadoop3.2.tgz下载地址
https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
配置环境:
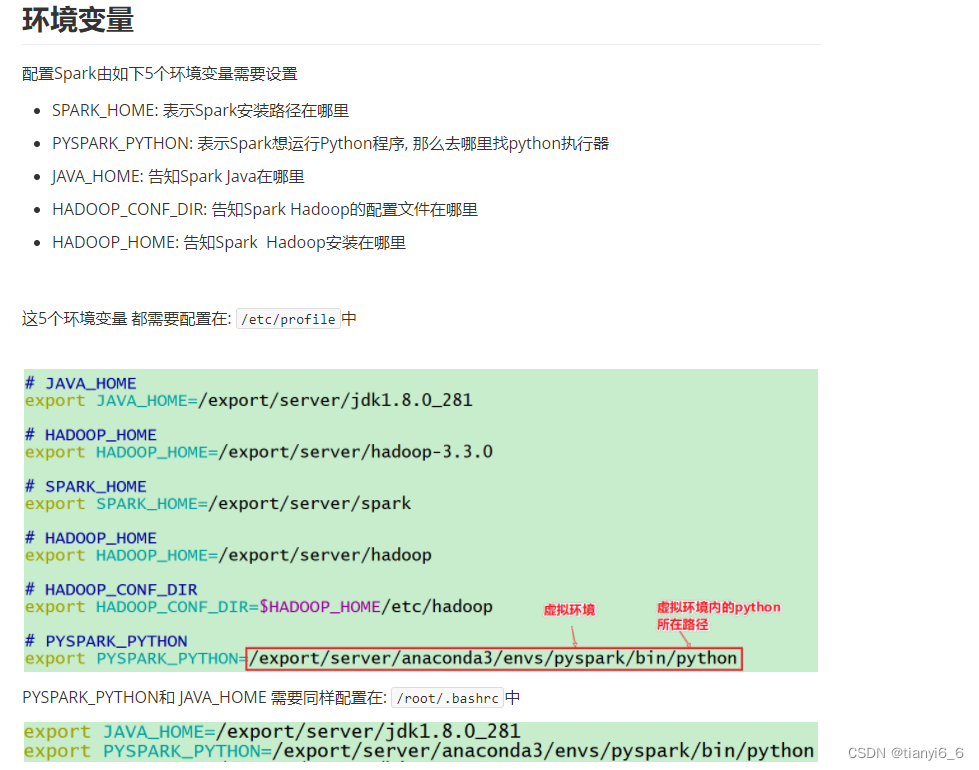
搭建操作, 可参考资料提供的部署文档:
https://gitee.com/tianyi6_6/PySpark/blob/master/Spark%E9%83%A8%E7%BD%B2%E6%96%87%E6%A1%A3.md#binspark-submit-pi

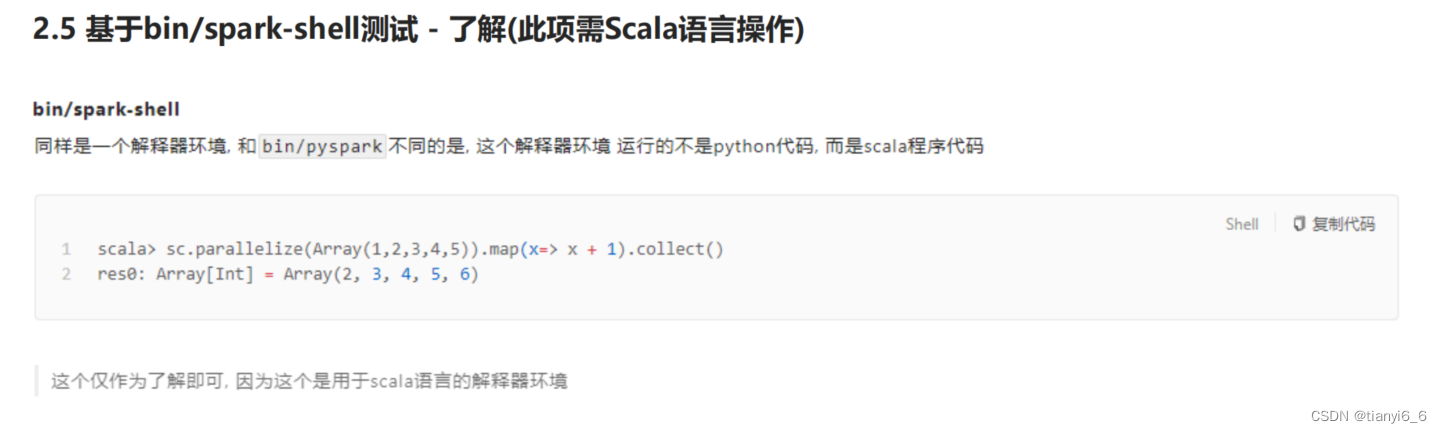
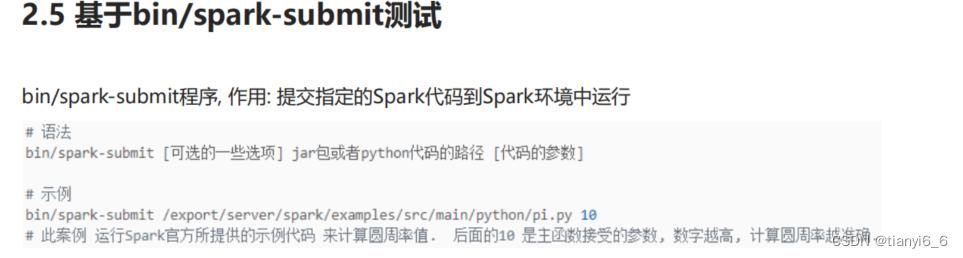
pyspark/spark-shell/spark-submit 对比
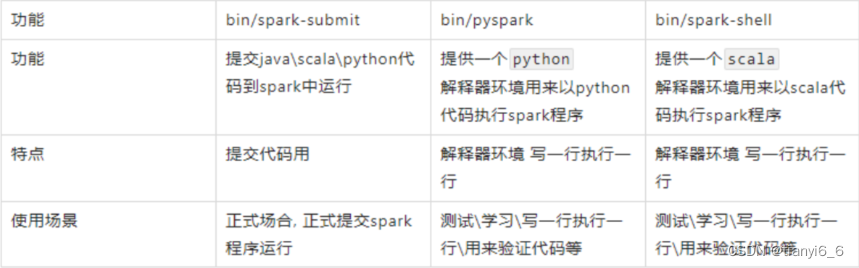
总结:
Local模式的运行原理?
- 1
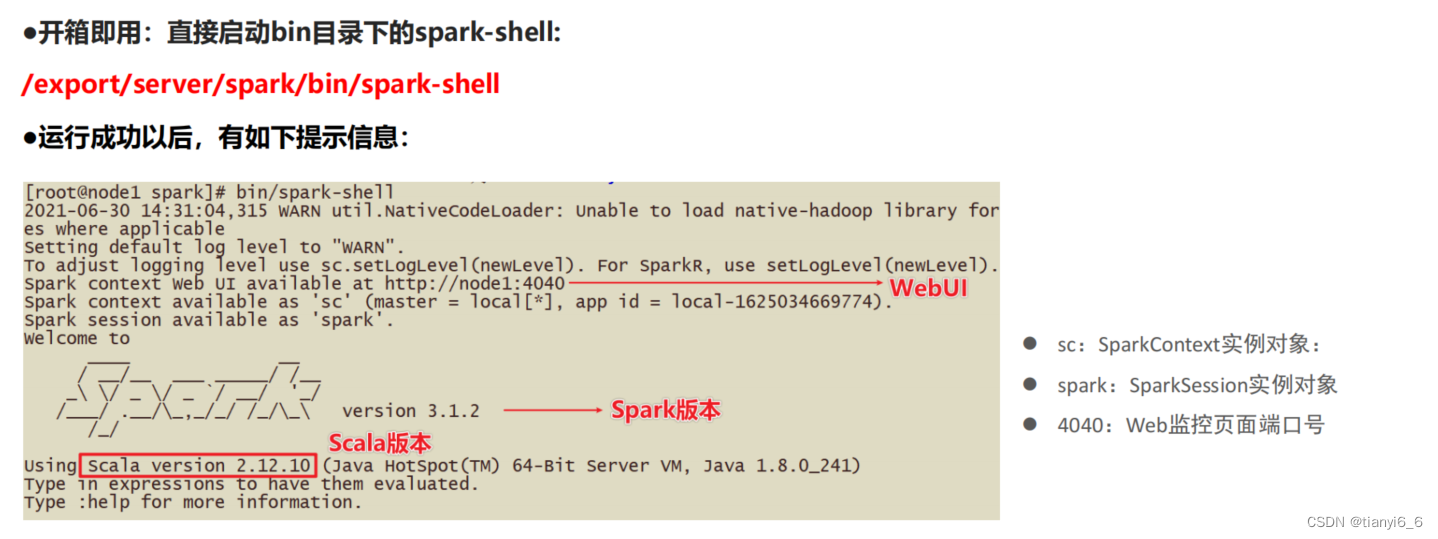
Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境. Local模式可以通过spark-shell/pyspark/spark-submit等来开启
bin/pyspark是什么程序?
- 1
是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,可以运行Python代码去进行Spark计算,类似Python自带解释器
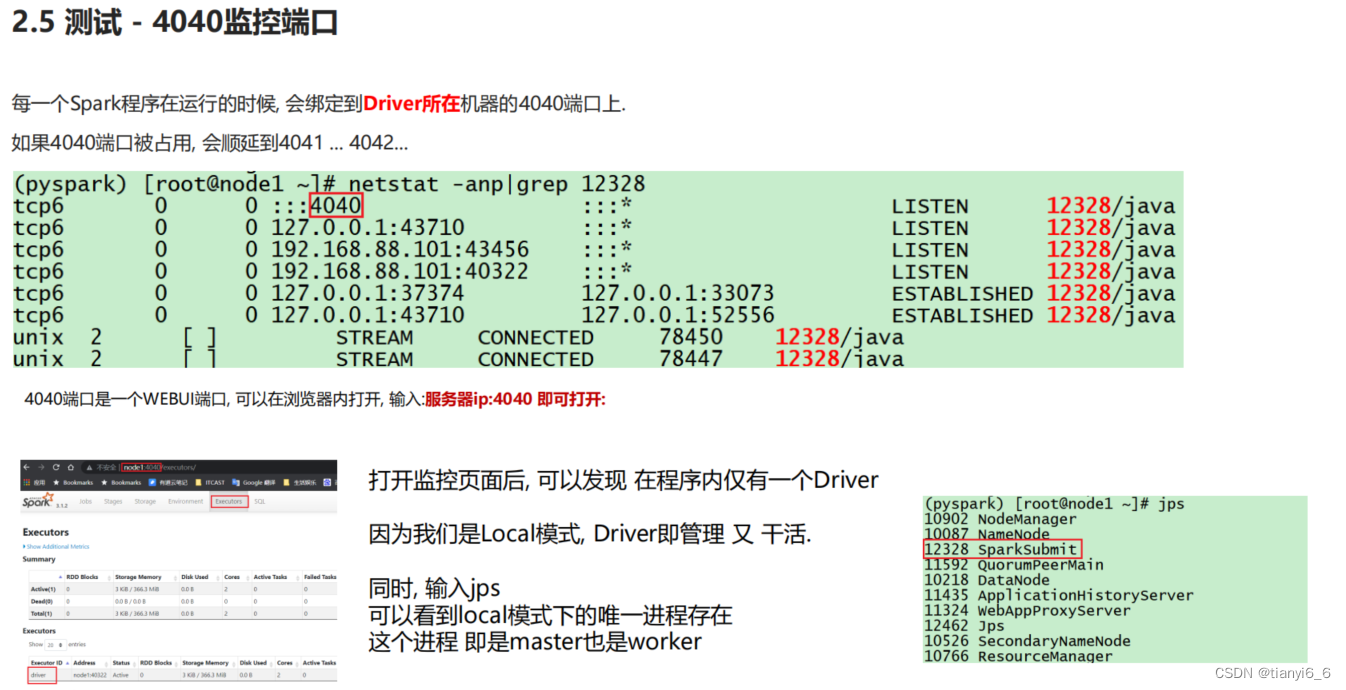
Spark的4040端口是什么?
- 1
Spark的任务在运行后,会在Driver所在机器绑定到4040端口,提供当前任务的监控页面供查看

