
- 12024中国AI Agent行业研究报告
- 2在 Android 上恢复已删除文件的 5 种简单方法_安卓文件恢复
- 3springboot项目 Spring Security 302 问题 loginProcessingUrl 无效
- 4安卓期末课程设计、一款刷小视频的App 包含源代码、使用手册和心得体会_android结课作业开发一个简易app
- 5thinkphp框架源码交易系统资源网站源码_tp开发源码交易系统 网站交易
- 6导出数据提示--secure-file-priv选项问题的解决方法
- 7【Flink 面试指南】Flink 详解(一):基础篇(架构、并行度、算子)_flink 架构
- 8【MySQL】mysql访问
- 9腾讯云部署SD_sd不用web ui如何部署
- 10自然语言处理技术(Natural Language Processing)知识点_基于自然语言处理的数据加工
微调 Florence-2 - 微软的尖端视觉语言模型
赞
踩
Florence-2 是微软于 2024 年 6 月发布的一个基础视觉语言模型。该模型极具吸引力,因为它尺寸很小 (0.2B 及 0.7B) 且在各种计算机视觉和视觉语言任务上表现出色。
Florence 开箱即用支持多种类型的任务,包括: 看图说话、目标检测、OCR 等等。虽然覆盖面很广,但仍有可能你的任务或领域不在此列,也有可能你希望针对自己的任务更好地控制模型输出。此时,你就需要微调了!
本文,我们展示了一个在 DocVQA 上微调 Florence 的示例。尽管原文宣称 Florence 2 支持视觉问答 (VQA) 任务,但最终发布的模型并未包含 VQA 功能。因此,我们正好拿这个任务练练手,看看我们能做点什么!
预训练细节与模型架构
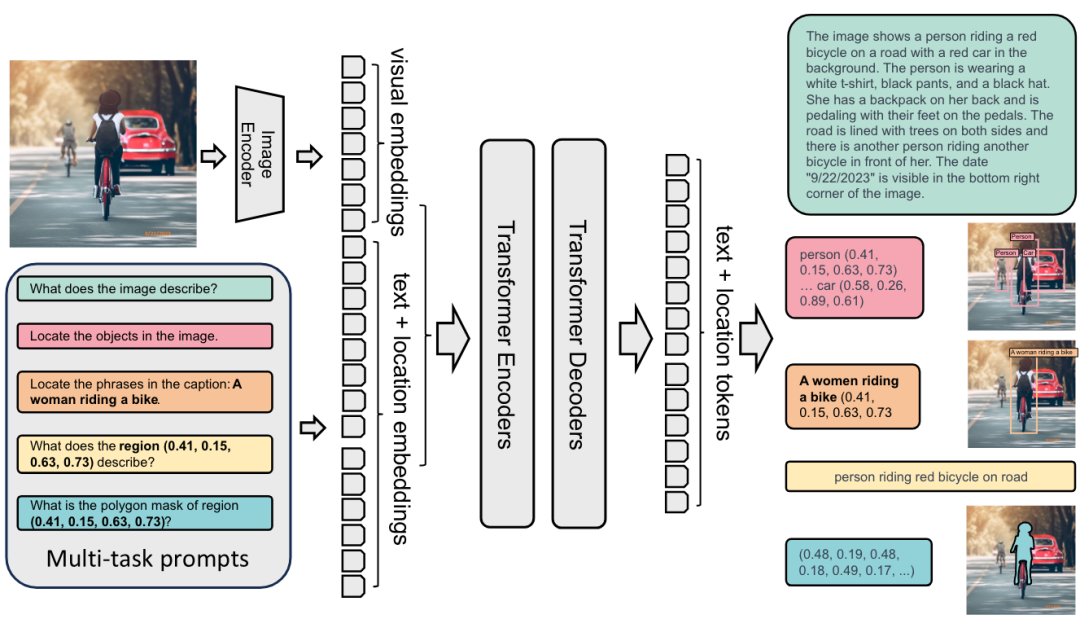
Florence-2 架构
无论执行什么样的计算机视觉任务,Florence-2 都会将其建模为序列到序列的任务。Florence-2 以图像和文本作为输入,并输出文本。模型结构比较简单: 用 DaViT 视觉编码器将图像转换为视觉嵌入,并用 BERT 将文本提示转换为文本和位置嵌入; 然后,生成的嵌入由标准编码器 - 解码器 transformer 架构进行处理,最终生成文本和位置词元。Florence-2 的优势并非源自其架构,而是源自海量的预训练数据集。作者指出,市面上领先的计算机视觉数据集通常所含信息有限 - WIT 仅有图文对,SA-1B仅有图像及相关分割掩码。因此,他们决定构建一个新的 FLD-5B 数据集,其中的每个图像都包含最广泛的信息 - 目标框、掩码、描述文本及标签。在创建数据集时,很大程度采用了自动化的过程,作者使用现成的专门任务模型,并用一组启发式规则及质检过程来清理所获得的结果。最终生成的用于预训练 Florence-2 模型的新数据集中包含了 1.26 亿张图像、超过 50 亿个标注。
SA-1Bhttps://ai.meta.com/datasets/segment-anything/
VQA 上的原始性能
我们尝试了各种方法来微调模型以使其适配 VQA (视觉问答) 任务的响应方式。迄今为止,我们发现最有效方法将其建模为图像区域描述任务,尽管其并不完全等同于 VQA 任务。看图说话任务虽然可以输出图像的描述性信息,但其不允许直接输入问题。
我们还测试了几个“不支持”的提示,例如 “<VQA>”、“<vqa>” 以及 “<Visual question answering>”。不幸的是,这些尝试的产生的结果都不可用。
微调后在 DocVQA 上的性能
我们使用 DocVQA 数据集的标准指标Levenshtein 相似度来测量性能。微调前,模型在验证集上的输出与标注的相似度为 0,因为模型输出与标注差异不小。对训练集进行 7 个 epoch 的微调后,验证集上的相似度得分提高到了 57.0。
Levenshtein 相似度https://en.wikipedia.org/wiki/Levenshtein_distance
我们创建了一个
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

