
- 1Mac上Flutter开发环境搭建_flutter macos (desktop) macos darwin-arm64 m
- 2ArcGIS API For JavaScript 开发(二)基础地图
- 3SpringBean默认是单例的,高并发情况下,如何保证并发安全?_单例bean的并发访问问题
- 4vue+uniapp音乐播放器系统 微信小程序hbpp0_uniapp免费音乐
- 5Ubuntu20.04 部署 k8s_ubuntu20.04虚拟机配置kubernetes
- 6数码管在c语言中显示时间,用LED数码管显示电脑中的时间
- 7容器核心技术之Namespace与Cgroup_namespace和cgroup
- 8Facebook 开源计算机视觉 (CV) 和 增强现实 (AR) 框架 Ocean
- 9oracle初级入门教程,超详细讲解,适合初学者和入门者_oracle database 教程
- 10Kafka生产与消费示例_kafka生产者实例
汽车电子嵌入式编程-【无人驾驶】QNX操作系统_通过qnx的hog指令控制车辆
赞
踩
目录
7. QNX提供Momentics IDE环境对算法进行性能分析
前言
QNX是一个基于POSIX为嵌入式系统特别设计的实时操作系统。它不仅能够让Linux开发者保持他们的编程习惯,而且还保留了Linux开源模型的关键特性。带来的好处是,这种方式能够让嵌入式开发者无论是在标准的Linux还是实时的扩展Linux都可以享受OS的服务。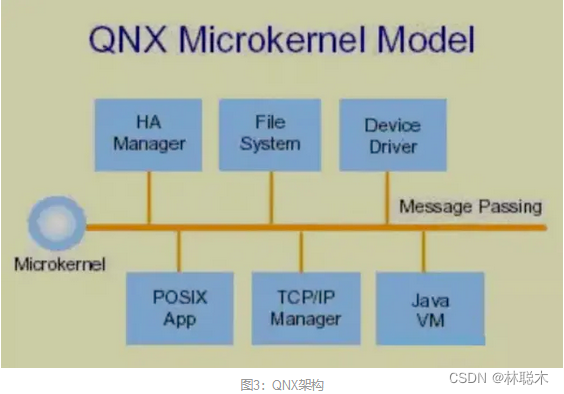
QNX是QNX Software Systems Ltd. (www.qnx.com*), Kanata, Ont.公司的商用产品。和Linux一样,QNX也是基于1970由贝尔实验室开发的UNIX。QNX和Linux都遵循LINUX POSIX标准。
QNX Neutrino微内核为实时和非实时的应用提供了一个统一的环境。QNX基于实时,微内核的架构(见图3)提供POSIX兼容的API。Neutrino微内核只包含最基础的操作系统服务。所有其他的服务都可以通过可选的,内存保护的进程来提供,可以动态的启动和停止。为了实现模块化,QNX Neutrino使用消息传递作为整个系统IPC最基本的方式。
几个相关概念
1.进程(pid)
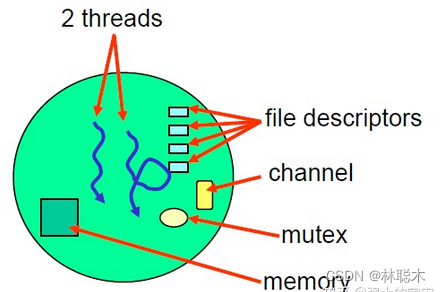
进程包含自己的一些资源,比如说ID, 内存(代码和数据),计时器,等等..., 并且这些资源是被保护的,也就是说其他进程不能访问。
2.线程
一个线程就是一个执行流或者控制流。
它也有一些属性,比如: 优先级, 调度算法,寄存器集合,CPU掩码(用于多核应用),等......
而所有的这些属性都会作用在正在运行的代码上。
几个高频面试题目
1.QNX和Linux的区别与联系
和Linux不同,QNX没有把POSIX作为附加层来实现。QNX微内核从一开始设计时就支持POSIX实时性,包括线程。ELC规范是基于现存的POSIX 1003.1标准。这个标准QNX也支持。因此,QNX能够天然支持嵌入式Linux应用。
QNX,和Linux一样,提供开源模式的好处。通过代码,开发者能够分析操作系统的架构以便更好地集成他们的代码,适配操作系统组件来满足应用特定的需求,并节省问题定位的思考时间。QNX通过两种方式来提供上面的好处。
- 通过使用高度扩展的微内核架构
- 给客户提供驱动,库和BSP(Board support package)的源码,包括为各种标准设备提供驱动开发套件
作为微内核操作系统,QNX Neutrino从根本上对定制开发。这是因为大部分操作系统层面的服务驱动,文件系统和协议栈存在于内核外的用户空间,只有少量的核心服务(比如调度,定时器,中断处理)存在内核中。因此,开发自定义驱动程序和应用程序特定的OS扩展不需要特殊的内核调试器或内核专家。事实上,作为用户空间的程序,开发OS扩展和开发标准的应用程序一样简单,因为它们可以用大家熟识的标准的源码级别的工具调试。
QNX Neutrino允许应用程序通过称之为同步消息传递这种统一的IPC方式来访问所有的驱动程序和操作系统服务。这种方式有几个好处。比如,由于QNX的消息传递是同步的,从而能够自动协调通信程序的执行,因此无需在每个进程中手动编码和调试复杂的同步服务(见图3)。消息传递本质上简化了复杂操作系统,将其划分为明确定义的可以单独开发,测试和维护的基础构建模块。通过任何提供服务的程序在路径名空间注册路径名将其广而告之给其他程序来实现。任何程序都能够通过在路径名上调用比如open(), read(), write(), 或者lseek()来访问其他服务。
举个例子。QNX串口驱动通常注册路径名/dev/ser1表示第一个串口。任何想访问这个端口的应用程序可以通过调用在/dev/se1上的open()函数来实现。对于应用程序而言,open()函数和标准的POSIX接口一样。
Neutrino C函数库将这个调用转成io_open消息并把这个消息转发给串口驱动。如果应用程序接下来要想串口写一个字符,调用序列如下:客户端调用write()函数,C函数库会构建一个io_write消息。这个消息会被转发给驱动。
这样带来的另一个好处是只要该服务支持某特定的功能,确切的消息就可以从任何客户端发送给任何服务。比如,向一个串口或磁盘文件写一个字符串,应用程序在这两种情况可以调用相同的write()函数,唯一的区别是消息要发送的地方。这意味着应用程序和它依赖的服务是解耦的。这种解耦可以使开发简单化,因为应用程序和系统服务之间所有的交互可以用一个简单的基于POSIX的编程模型来实现。
这样简化了代码移植到其他平台因为应用程序不包含任何硬件或协议特定的代码。
通过给客户提供比如库,驱动和BSP的源码,QNX Neutrino进一步简化了问题定位和OS的定制化开发。开发者可以免费下载设备驱动包(Device Drive Kits, DDKs)。DDKs包含文档和一个软件框架。这个软件框架实现了库中更高级别的独立设备的代码。
在涵盖大多数Linux源代码的GPL中未提供QNX源代码。然而,QNX软件系统基于它们自己的License协议提供源码。不像GPL,可以让开发人员自由创作衍生作品,而不必放弃知识产权(IP)。
作为宏操作系统,Linux将大部分的驱动,文件系统和协议中都绑进了内核中。因此这些模块中任何一个单一的编程错误就有可能导致致命的内核错误。在QNX Neutrino中,这些模块都运行在独立的、内存保护的地址空间中,内核崩溃很难发生。因此QNX Neutrino为实时应用程序提供了一个比Linux更健壮的环境。并且也肯定比双内核方法中使用的不受保护的实时内核强得多。
QNX发展历程
QNX成立于1980年,是全世界第一个类UNIX的符合POSIX标准的微内核的硬实时操作系统,在过去的几十年中广泛的应用在汽车、工业自动化、国防、航空航天、医疗、核电和通信等领域,提供以嵌入式操作系统为核心的中间件和基础软件解决方案。在上世纪七十年代末,QNX的两位创始人Gordon Bell和Dan Dodge根据大学时代的一些设想写出了一个能在IBM PC上运行的名叫Quick UNIX的系统,后来改名为QNX并于1980年正式发布,历经几十年的演进,QNX公司于2004年10月被哈曼集团以1.38亿美元收购,作为哈曼的一个事业部经营了六年。2010年04月,黑莓以2亿美元从哈曼处收购了QNX,一同被打包收购的还有哈曼下属的一个位于温哥华的叫Wavemaker的音效部门,也就是现在QNX acoustic方案的前身。QNX这个成立于加拿大渥太华的公司,在被美国哈曼买走6年后又重返加拿大,作为黑莓核心部门IOT技术方案事业部的最重要组成部分,承担黑莓业务中操作系统汽车基础平台软件、数据安全、物联网IOT及云计算和专利部门等重要业务内容。
在汽车领域的高性能处理和功能安全的交叉子域中,QNX是全球最大的商用操作系统提供商。自1999年进入汽车领域至今,QNX紧随并引领了汽车电子嵌入式软件领域的发展潮流和趋势热点,在多类重要的软件平台上均布局了前瞻性战略产品,为全球一线汽车供应商和制造商提供先进的基础软件和网络安全技术,被广泛应用于高级驾驶辅助系统、基于虚拟化技术的智能数字座舱系统,智能网联模块、智能网关、高性能计算平台及信息娱乐系统等汽车电子的子系统中。据知名独立调研公司Strategy Analytics在2022年初的统计,全球已有超过2.15亿辆汽车搭载BlackBerry QNX软件,平均每年新增2000万台搭载黑莓QNX的基础软件的智能汽车进入全球市场。
到目前为止,世界上几乎所有的主机厂都采用了基于QNX操作系统的软件技术。全球top 25家电动汽车厂家,其中24家在使用QNX的软件操作系统,例如,中国的小鹏汽车自动辅助驾驶系统Xpilot3.0和Xpilot3.5基于QNX通过TUV莱茵ISO26262 ASIL D功能安全的硬实操作系统,合众新能源汽车的哪吒S采用QNX Hypervisor打造其全新科技感智能座舱,并在其全栈自研的TA PILOT 3.0智能驾驶系统中搭载QNX OS for Safety操作系统,实现多种场景下的智能辅助驾驶,又如零跑汽车在其量产的第三代高端纯电SUV—零跑C11和智能纯电桥车C01中均采用了QNX Neutrino实时操作系统和QNX Hypervisor,旨在为中国消费者带来更个性化与舒适的驾驶体验。除此之外,高合即将发布的豪华纯电超跑HiPhi Z的自动辅助驾驶平台使用的是英伟达Orin-X芯片和 QNX 嵌入式硬实时操作系统。
时代周刊曾在2016年对QNX评价为“QNX对于汽车来说就像微软对于电脑一样”,诠释了QNX在汽车领域的基础软件操作系统地位以及深度的覆盖率。
什么是QNX?
QNX是一种实时操作系统;
QNX是微内核架构;其核心仅提供4种服务(大部分功能都剥离了出去),分别为:进程调度、进程间通信、底层网络通信和中断处理。驱动程序、协议栈、文件系统、应用程序等都在微内核之外内存受保护的安全的用户空间内运行,组件之间能避免相互影响,在遇到故障时也能重启。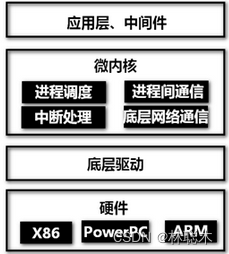
QNX体系结构
QNX是一个[微内核]实时操作系统,其核心仅提供4种服务:进程调度、进程间通信、底层网络通信和中断处理,其进程在独立的地址空间运行。
驱动程序、协议栈、文件系统、应用程序等都在微内核之外内存受保护的安全的用户空间内运行,组件之间能避免相互影响,在遇到故障时也能重启。
内核是操作系统的核心,在有些操作系统中,内核包含了很多功能,导致内核像是个完整的操作系统。而QNX的微内核是一个真正的内核,它非常小,并且只提供基本的服务.
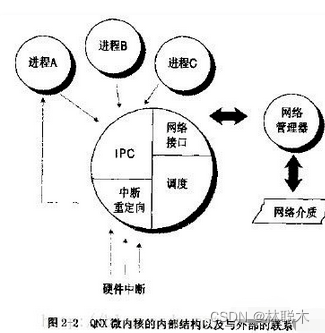
所有其它OS服务,都实现为协作的用户进程,因此QNX核心非常小巧(QNX4.x大约为12Kb)而且运行速度极快。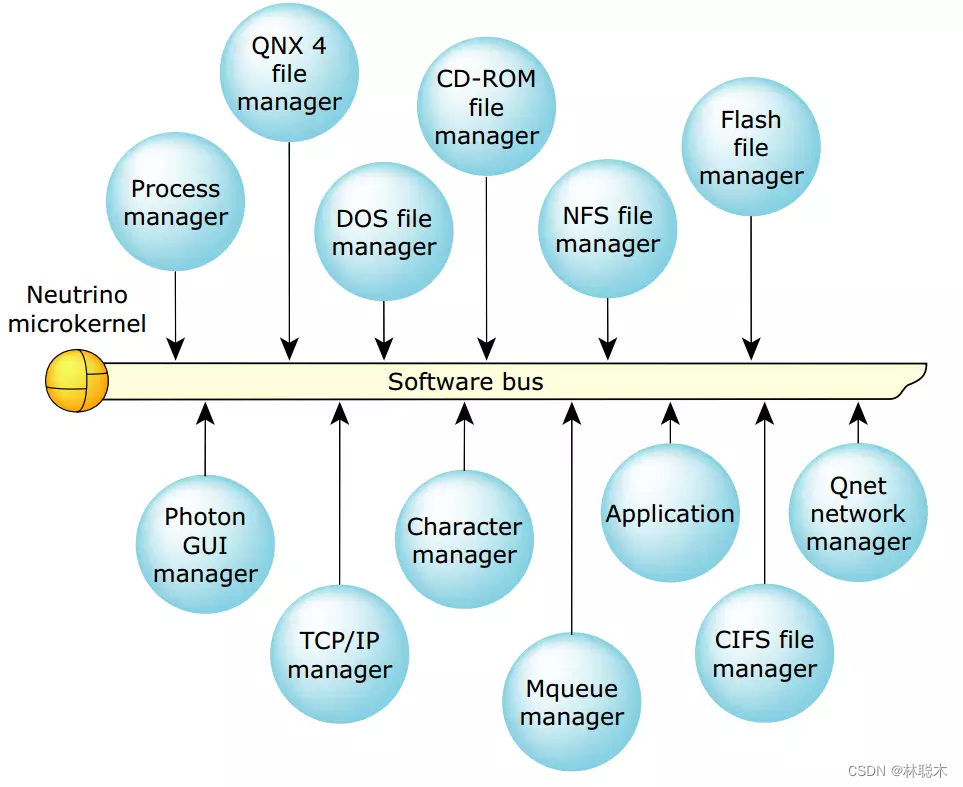
- 通过POSIX线程创建原语提供的线程服务;
- 通过POSIX信号原语提供的信号服务;
- 消息传递服务,微内核处理整个系统中所有线程之间的消息路由;
- 通过POSIX线程同步原语提供的同步服务;
- 调度服务,微内核使用各种POSIX实时调度策略来调度线程执行;
- 定时器服务,微内核提供了丰富的POSIX定时器服务集;
- 进程管理服务,微内核与进程管理器一起组成一个叫procnto的单元,进程管理器部分负责管理进程、内存,还有路径名空间。与线程不同,微内核本身不会被调度执行。处理器只在微内核中执行系统调用、异常、硬件中断响应等。
QNX操作系统优先级
Neutrino 提供了一个基于优先级驱动的抢占式的设计理念。优先级驱动意味着,我们可以为每个线程分配一个优先级,它将可以根据优先级调度策略获取CPU资源。如果一个低优先级线程和一个高优先级线程同时像获取CPU使用权,那么高优先级线程将会运行。抢占式意思是说,如果一个低优先级线程在运行,这个时候一个高优先级运行条件得到满足,将要运行,那么它将获取CPU使用权。
考虑两个准备好使用CPU的线程,如果它们拥有不同的优先级,答案很简单,内核会把CPU的使用权交给高优先级的线程。QNX线程的优先级从1开始往上加,数字越大优先级越高。需要注意的是0优先级是预留给Idle线程的,你不能使用。如果想知道你所使用的系统中线程优先级的最小值和最大值,可以使用函数schd_get_priority_min()和schd_get_priority_max()获取,它们在sched.h中声明。如果一个拥有更高优先级的线程突然变为可以占用CPU的状态,内核将会立刻加载该线程的上下文并开始执行。这个过程称为抢占,高优先级的线程抢占了低优先级线程对CPU的占用。当高优先级的线程执行完毕,内核会继续执行未执行完的低优先级线程。
现在,假设两个线程都准备好了占用CPU而且两个线程拥有相同的优先级。
线程的优先级从1-255(最高)。普通线程的优先级范围从1-63(默认)。root用户线程优先级允许设置在63之( procmgr_ability())接口。系统有一个空闲线程(位于进程管理器)有最低的优先级(0),这个空闲任务总是处于就绪状态。非特权线程优先级范围 1-63,可通过PROCMGR_AID_PRIORITY 更改特权标志,使其优先级大于63,中断优先级高于任何线程。
默认情况下子线程从父线程继承优先级。一个线程有两个优先级,一个称为真实优先级,一个成为有效优先级。系统通过有效优先级完成调
中断处理器的优先级比任何线程优先级都要搞,但是它不像线程一样被调度。如果一个中断发生了,那么:
- 1.当前正在运行的线程失去CPU占用权,开始中断异常处理(SMP issues)
- 2.硬件运行内核
- 3.内核调用中断处理程序
(1)任务状态分析
如果想要完全了解调度器的工作,首先必须了解任务在程序运行过程中的几种状态以及知道就绪队列的原理。
当一个任务从运行态转变为阻塞状态可能的原因有:
- 1.线程主动休眠
- 2.线程在等待其他线程的消息
- 3.线程在等待互斥锁
当我们设计一个应用程序的时候,必须考虑到当一个线程在等待某些事情的发生,确保不是让CPU空转。必须使用一些策略保证低优先级任务可以获取CPU使用权。
我们把各种类型阻塞统称为阻塞状态,这些阻塞类型包含:等待应答阻塞、等待消息阻塞、互斥锁阻塞、中断阻塞、休眠阻塞。
当一个线程想要湖区CPU使用权的时候我们称它为就绪状态,但是突然被其他任务打断。这个任务将会运行我们称它为运行状态。
(2)就绪队列分析
就绪队列是一个简化版本的内核数据结构,根据优先级排序的队列。每个队列节点挂着其他优先级相同的就绪的任务。
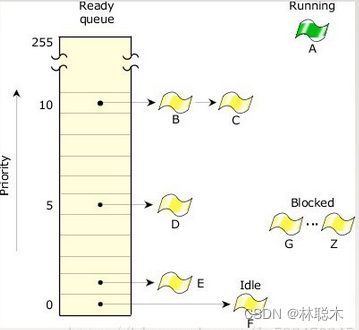
如上图所示,线程B-F都处于就绪状态。线程A正在运行。其他线程G-Z被阻塞。线程A/B/C拥有最高优先级,所以他们将基于调度策略分享处理器执行任务。
活动的线程是唯一一个处于运行状态的。内核利用一个数组(每个处理器有一个入口)去追踪当前在运行的线程。
每个线程被分配一个优先级。调度器选取处于就绪状态的最高优先级的任务准备下一次运行。
(3)挂起一个正在运行的线程
当内核进行系统调用的时候,例如:异常、硬件中断,当前正在运行的线程被短暂挂起。当任何线程的执行状态发生改变的时候调度器会进行裁决。线程将会被全局性的调度,横跨所有进程。
通常情况下,被挂起状态下的可执行程序会重新执行,但是调度器会进行上下文切换,从一个线程转到另外一个线程,当一个正在运行的线程发生:
- 1.被阻塞
- 2.被抢占
- 3.主动放弃CPU使用权
当一个线程被阻塞:当一个线程在等待其他事情的发生的时候,它将会被阻塞(IPC需要,等待互斥锁等)。被阻塞的线程从运行数组移除,同时最高优先级的任务运行。当一个阻塞的线程编程非阻塞状态时,它将会按照优先级被放置在相应队列尾部。
当一个线程被抢占:当一个高优先级的线程就绪的时候,当前正在运行的线程会被抢占。被抢占的线程按照优先级放置在对应队列的开始位置,同时高优先级任务开始执行。一个被抢占的线程在相同优先级水平的队列中的位置不会改变。
线程主动放弃CPU:一个正在运行的线程主动放弃处理器使用权(sched_yield()),那么将会按照优先级水平放置在对应就绪队列的尾部。最高优先级的线程继续运行。
QNX调度算法及策略
QNX调度算法有很多种,本质上基于优先级抢占式。QNX的线程优先级是一个0-255的数字,数字越大优先级越高。在QNX上有三种基本调度策略,可以单独使用也可以组合使用,包括基于时间片轮询Round Robin、优先级抢占式FIFO和基于时间Budget的Sporadic算法。同时QNX还提供APS自适应分区调度算法,在CPU满负荷的场景下保证低优先级的任务有调度的机会,不被“饿死”。
系统中每个线程都可以利用任意方式调度。调度方式基于每个线程为基础,而不是基于同一节点上的所有线程和进程。记住,这种调度策略适用于仅当两个或多个线程有相同的优先级都处于就绪状态下。
线程可以利用 pthread_attr_setschedparam() 或则 pthread_attr_setschedpolicy() 设置调度参数和策略,对于所有线程在创建的时候都有效。
虽然子线程继承父线程优先级,线程可以调用pthread_setschedparam()去请求内核调度策略和算法,或者调用 pthread_setschedprio()仅仅修改优先级。一个线程可以调用 pthread_getschedparam()获取当前调度策略和算法,可以调用pthread_self()获取线程ID。例如:
- struct sched_param param;
- int policy, retcode;
-
- /* Get the scheduling parameters. */
-
- retcode = pthread_getschedparam( pthread_self(), &policy, ¶m);
- if (retcode != EOK) {
- printf ("pthread_getschedparam: %s.\n", strerror (retcode));
- return EXIT_FAILURE;
- }
-
- printf ("The assigned priority is %d, and the current priority is %d.\n",
- param.sched_priority, param.sched_curpriority);
-
- /* Increase the priority. */
-
- param.sched_priority++;
-
- retcode = pthread_setschedparam( pthread_self(), policy, ¶m);
- if (retcode != EOK) {
- printf ("pthread_setschedparam: %s.\n", strerror (retcode));
- return EXIT_FAILURE;
- }

当你获取调度器参数,sched_param结构体里面的sched_priority 参数用于修改指定的优先级,而sched_curpriority由于修改线程当前优先级(这个优先级可能会因为优先级继承发生改变)。
QNX调度算法
调度算法,是基于优先级的。QNX的线程优先级,是一个0-255的数字,数字越大优先级越高。所以,优先级0是内核中的idle线程。同时,优先级64是一个分界岭。就是说,优先级1 – 63 是非特权优先级,一般用户都可以用,而64 – 255必须是有root权限的线程才可以设。这个“优先级64”分界线,如果有必要,还可以通过启动Procnto时传 –P <priority> 来改变。
调度算法的对像是线程,而线程在QNX上,有大约20个状态。(参考 /usr/include/sys/states.h)在这许多状态中,跟调度有关的,其实只有 STATE_RUNNING和STATE_READY两个状态。STATE_RUNNING是线程当前正在使用CPU,而STATE_READY是等着被执行(被调度)的线程。其他状态的线程,处于某种“阻塞”状态中,调度算法不需要关注。
所以在调度算法看来,整个系统里的线程像这样: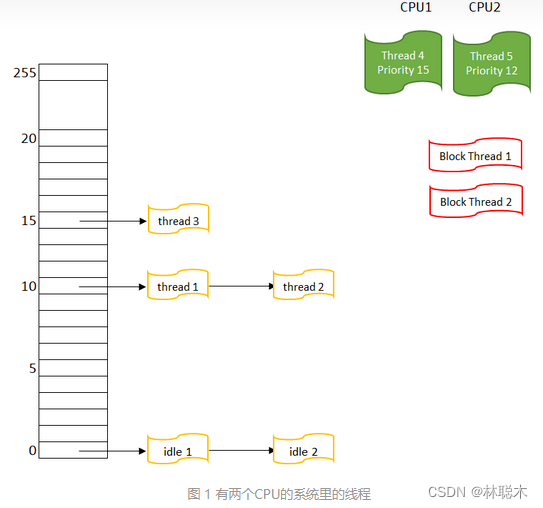
这是一个有两个CPU的系统,所以可以看到有两个RUNNING线程;对于 BLOCK THREAD,它们不参于调度,所以不需要考虑它们的优先级。
进程调度
1.Introduction
在QNX Neutrino中,微内核与进程管理器一起组成procnto模块,所有运行时系统都需要这个模块。
进程管理器可用于创建多个POSIX进程(每个进程可能包含多个POSIX线程),它的主要职责包括:
- 进程管理,管理进程的创建、销毁、属性处理(用户ID和组ID)等;
- 内存管理,管理一系列的内存保护功能、共享库、进程间POSIX共享内存等;
- 路径名管理,管理资源管理器可能附加到的路径名空间;
用户进程可以通过内核调用访问微内核函数,也可以通过向procnto发送消息来访问进程管理器函数。
在procnto中执行线程去调用微内核的方式与其他进程中的线程完全相同,进程管理器代码和微内核共享相同的地址空间并不意味着有一套特殊的或私有的接口,系统中的所有线程共享相同的内核接口,并且在调用内核时执行特权切换。
2. Process management
procnto的首要任务就是动态创建新进程,创建的进程也会依赖procnto提供的内存管理和路径名管理相关功能。
进程管理包括进程创建、销毁、属性(进程ID、用户ID、组ID)管理。包含以下接口:
-
posix_spawn(),POSIX接口,通过直接指定要加载的可执行文件来创建子进程。熟悉UNIX系统的人可能知道,这个函数相当于在fork()之后调用exec*(),但是更高效,因为不需要在像fork()函数中那样需要复制地址空间,而是在exec*()调用时直接销毁和替代; -
spawn(),QNX Neutrino接口,功能类似于posix_spawn(),使用这个接口可以控制进程的属性信息,比如文件描述符、进程组ID、信号、调度策略、调度优先级、堆栈、运行掩码(SMP系统); -
fork(),POSIX接口,创建子进程,子进程与父进程共享相同的代码,并复制父进程的数据。大多数的进程资源都是继承的,不能继承的资源包括:进程ID、父进程ID、文件锁、pending信号和alarms,定时器。fork()函数可以在两种情况下使用:
- 创建当前执行环境的新实例,可用
pthread_create()替代; - 创建一个运行不同程序的新进程,可用
posix_spawn()来替代;
-
vfork(),UNIX BSD扩展接口,vfork()只能在单线程进程中调用。vfork()函数与fork()函数不同之处在于,它与父进程共享数据段,在调用exec*()或exit()函数之前数据都是共享的,调用exec*()或exit()函数之后父进程才能运行; -
exec*(),POSIX接口,exec*()系列函数,会用可执行文件加载的新进程,替换当前进程,由于调用进程被替换,因此不会有成功返回。这些函数通常用在fork()或vfork()之后,用于加载子进程。更好的方式是使用posix_spawn()接口。
3.Memory management
在某些实时内核中,会在开发环境中提供内存保护支持,却很少为运行时配置提供内存保护,原因是内存和性能的损失。随着内存保护在很多嵌入式处理器中越来越普遍,内存保护的好处远远超过了它带来的性能损失,最关键的一点就是提高了软件的鲁棒性。
内存保护对地址空间进行了隔离,避免了一个进程中的错误影响其他进程或内核。启用MMU后,操作系统可以在发生内存访问冲突时中止进程,并立刻反馈给程序员,而不是在运行一段时间后突然崩溃。
(1)MMU
典型的MMU操作方式是将物理内存划分为4KB页面,在内存中会存储一组页表,页表里存放着虚拟地址到物理地址的映射关系,CPU根据页表内容来访问物理内存。
Virtual address mapping(on an X86)
为了提高性能,通常会使用TLB来提高页表条目的查找效率。页表条目中会对页面进行读写等权限控制。当CPU进行上下文切换的时候,如果是不同进程之间,则需要通过MMU来切换不同的地址空间,如果是在一个进程内部,则不需要这步操作。
(2)Memory protection at run time
在许多嵌入式系统中,会使用硬件看门狗来检测是否有软件或硬件异常,在出现异常时则进行重启。
在内存保护系统中,有一种更好的方式,可以称为软件看门狗。当软件出现间歇性错误时,操作系统可以捕获事件,并将控制权交给用户线程,而不是直接进行内存转储。用户线程则可以有选择的做决定,而不是像硬件看门狗那样直接重启。软件看门狗可以做:
- 中止由于内存访问冲突而失败的进程,并在不关闭系统其余部分的情况下重启该进程;
- 中止失败进程以及任何相关进程,将硬件初始化为安全状态,再重启相关进程;
- 如果故障很严重,则关闭整个系统,并发出警报;
很显然,软件看门狗能更好的进行控制,还可以收集有关软件故障的信息,有利于事后的诊断。
(3)Quality control
通过将嵌入式系统划分成一组协作的、受内存保护的进程,我们可以很容易重用这些组件。加上有明确的接口定义,这些进程可以放心的集成到应用程序中,确保它们不会破坏系统的整体可靠性。当然,应用程序不可能做到完全没有bug,系统应该设计成能够容忍并从故障中恢复的架构,而利用MMU提供内存保护正是朝着这个方向迈出了良好的一步。
(4)Full-protection model
在全保护模型中,QNX Neutrino首先会将image中的所有代码重定位到一个新的虚拟空间中,使能MMU,设置好初始页表。这就允许procnto在支持MMU的环境中启动,随后,进程管理器便会接管该环境,再根据启动的进程来修改页表。

Full protection VM
(5) Locking memory
QNX Neutrino支持内存锁定,进程可以通过锁定内存来避免获取内存页的延迟。
内存锁定分为以下几级:
- Unlocked,未锁定的内存可以换入换出,内存在映射时完成分配,但是不会创建页表条目。当第一次访问内存时会失败,内存管理器会进行内存的初始化并创建页表条目,此时线程的状态为
WAITPAGE; - Locked,被锁定的内存不能被换入换出,会在访问时发生页面错误;
- Superlocked,QNX Neutrino的扩展实现,不允许任何错误,所有内存都必须初始化和私有化,并且在内存映射时设置权限,覆盖整个线程的地址空间;
(Defragmenting physical memory
就像磁盘碎片一样,程序的运行也有可能带来内存碎片问题。
碎片整理的任务包括更改现有的内存分配和映射,以便使用不同的底层物理页面。通过交换底层的物理内存单元,操作系统可以将碎片化空间合并成连续的区域,但是在移动某些类型的内存时需要小心,因为这类内存的映射表不能被安全的修改。
- 内核分配的一对一映射的内存区域不能移动,因为操作系统不能在不更改虚拟地址的情况下更改物理地址;
- 被应用程序锁定(
mlock()/mlockall())的内存不能移动; - 具有IO特权的应用程序默认会锁定所有页面,因为设备驱动通常需要物理地址;
- 目前没有移动具有互斥锁对象的内存页,互斥锁对象通过物理地址向内核注册,如果移动带有互斥锁对象的页面,则需要重新编写这些对象。
4. Pathname management
procnto允许资源管理器通过提供标准的API接口,管理路径名空间子集作为自己的“授权域”。当一个进程打开一个文件时,兼容POSIX的open库函数会向procnto发送路径名消息,procnto会根据路径的前缀来判断由哪一个资源管理器来处理。当一个前缀被重叠注册时,会使用与最长的前缀关联的资源管理器来处理。
启动时,procnto会创建以下路径名:

1 Resolving pathnames
可以举个例子来说明一下最长路径名匹配,假设有以下路径名进行了注册,并有对应的模块:

下表展示了路径名解析的最长匹配规则:

(2)Single-device mountpoints
假设有三个服务器:
- 服务器A,QNX 4文件系统,挂载点是
/,包含两个文件bin/true和bin/false; - 服务器B,Flash文件系统,挂载点是
/bin/,包含文件ls和echo; - 服务器C,产生数字的设备,挂载点是
/dev/random;
在进程管理器内部,挂载点列表如下:
假设一个客户端想往服务器C发送消息,客户端的代码如下:
- int fd;
- fd = open("/dev/random", ...);
- read(fd, ...);
- close(fd);
在这种情况下,C库代码会请求进程管理器提供处理路径/dev/random的服务器,进程管理器将返回服务器列表:
- 服务器C(可能性最大,最长路径匹配)
- 服务器A(可能性最小,最短路径匹配)
根据这些信息,C库将以此与每个服务器进行联系,并发送open的消息和路径组件,而服务器会对路径组件进行验证: - 服务器C收到空路径,因为请求与挂载在同一个路径下;
- 服务器A收到路径
dev/random,因为它的挂载点是/;
一旦一个服务器确认了请求,C库就不会联系其他服务器,这意味着只有服务器C拒绝请求时,才会去联系服务器A。
(3)Unioned filesystem mountpoints
假设有两个服务器:
- 服务器A, QNX 4文件系统,挂载点是
/,包含两个文件bin/true和bin/false; - 服务器B, Flash文件系统,挂载点是
/bin,包含两个文件ls和echo;
两个服务器都有/bin路径,但是包含不同的内容,当两个服务器都挂载后,可以看到联合挂载点如下: /,服务器A;/bin,服务器A和B;/bin/echo,服务器B;/bin/false,服务器A;/bin/ls,服务器B;/bin/true,服务器A;
当执行以下代码,路径解析跟之前一样,但是不是将返回限制成一个连接ID,而是去联系所有的服务器并询问它们对路径的处理。
- DIR *dirp;
- dirp = opendir("/bin", ...);
- closedir(dirp);
结果为:
- 服务器B将收到一个空路径,因为请求与挂载在同一个路径下;
- 服务器A将收到
bin,因为挂载点是/bin;
结论是,对于处理路径/bin的服务器(本例中A和B),我们有一组文件描述符,当调用readdir()时,可以依次读取实际的目录名条目。如果目录中的任何名称都是通过常规的open访问,那就会执行正常的解析过程,并且只能访问一个服务器。
(4)Symbolic prefixes
类似于Linux系统中的链接,在QNX中,可以通过ln -s来建立链接,比如:ln -Ps /net/neutron/bin /bin
此时,/bin/ls会被替换成/net/neutron/bin/ls,在进行路径名匹配时,会匹配到/net上,而/net指向的是lsm-qnet,lsm-qnet资源管理器会去解析neutron组件,并将进一步的解析请求发送到叫neutron的网络节点上,从而在neutron节点上完成/bin/ls的解析。符号链接允许我们像访问本地文件系统一样访问远程文件系统。
执行重定向不需要运行本地文件系统,无磁盘工作站的路径名组织可能如下图,本地设备(如;dev/ser1或/dev/console)将被路由到本地字符设备管理器,而对其他路径的请求将会被路由到远程文件系统。
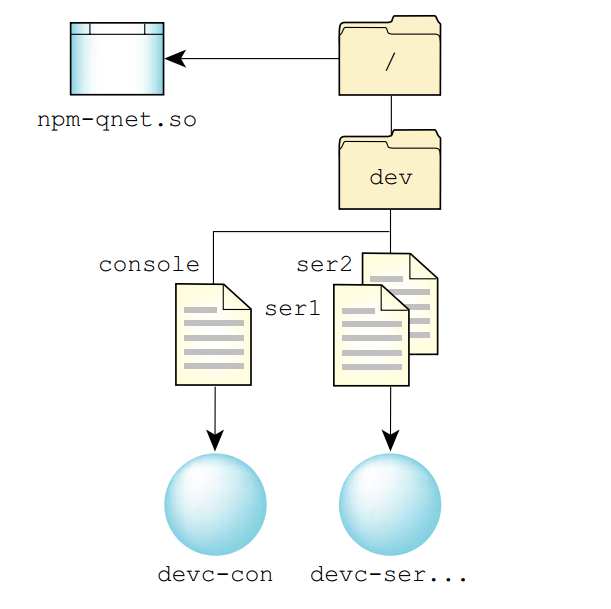
文件描述符空间属于进程内部资源,资源管理器通过使用SCOID(Server Connection ID)和FD(File Descriptor)来标识OCB(open control block),其中在IO管理器中,使用稀疏矩阵完成三者之间的映射:
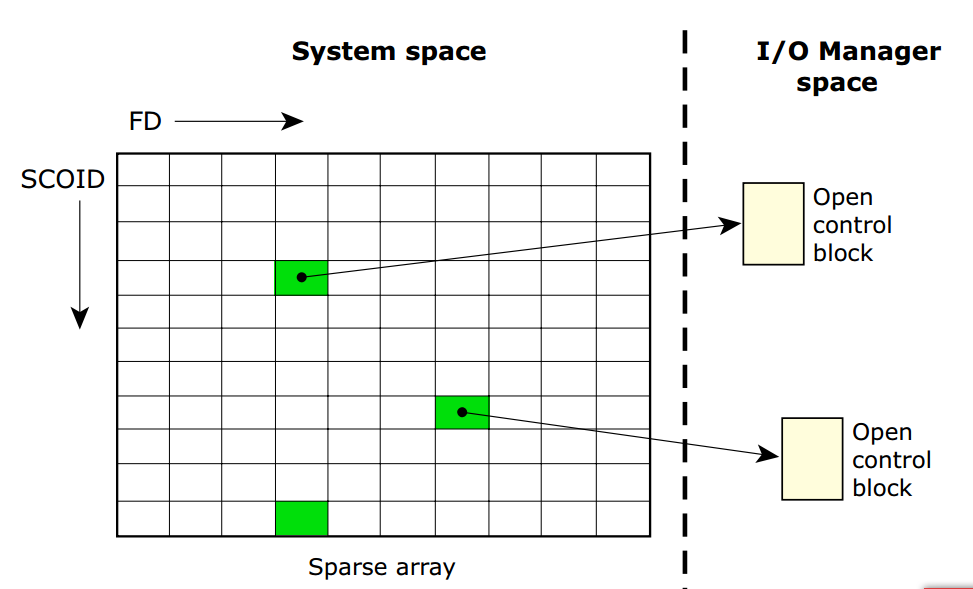
Sparse array
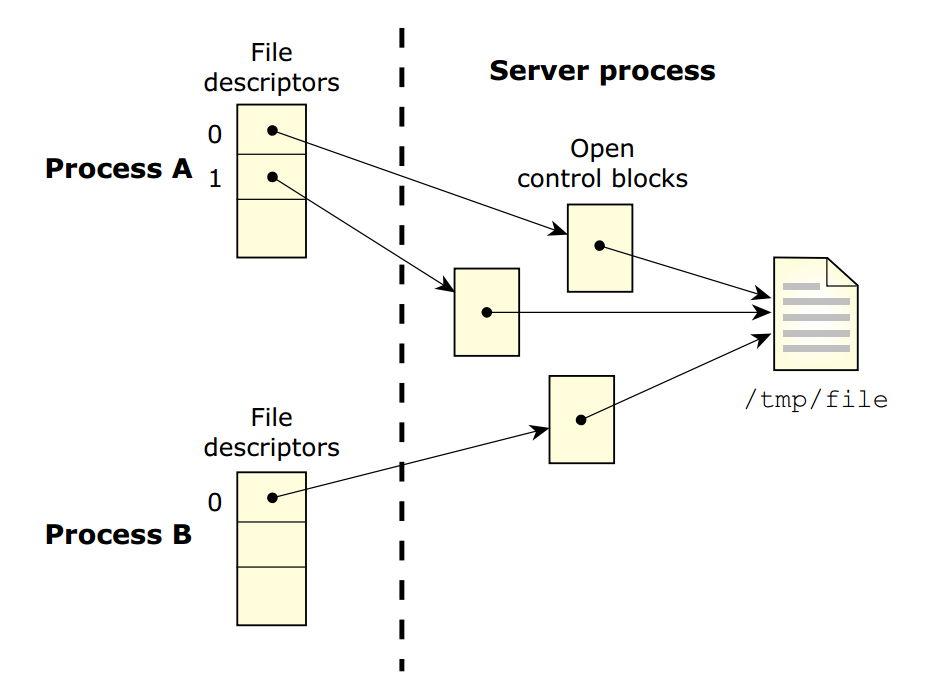
OCB结构包含了打开资源的活动信息,下图中表示一个进程打开文件两次,另一个进程打开同一文件一次:
Two processes open the same file
也可以多个不同进程之间的描述符指向同一个OCB结构,通常是在dup()/dup2()/fcntl()或者vfork()/fork()/posix_spawn()/spawn()接口调用时产生的,此时一个进程对OCB操作可能会影响与之关联的进程,如下图:
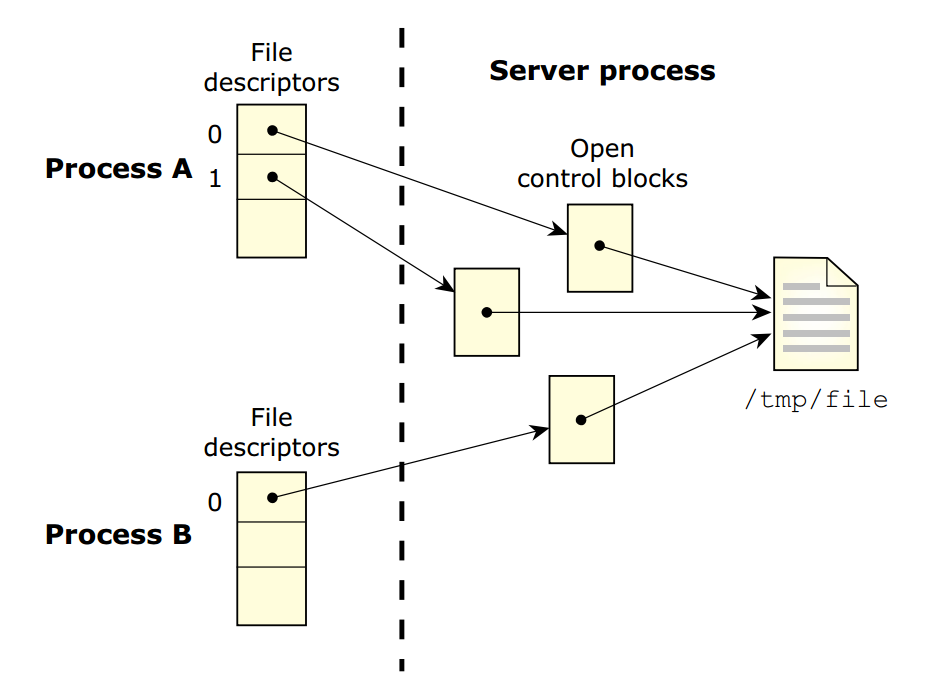
QNX调度策略
在QNX上实质上只有三种基本调度策略,“轮询”(Round Robin),“先进先出”(First in first out)和"零星调度”(Sporadic) 算法。虽然形式上还有一个“其他”,但“其他”跟“轮询”是一样的。这些调度策略,在 /usr/include/sched.h 里有定义。(SCHED_FIFO, SCHED_RR, SCHED_SPORADIC, SCHED_OTHER)
强调一下,调度策略只限于在READY队列里的线程,优线级最高的线程有不止一个时,才会用到。如果线程不再 READY,或是有别的更高优先级的线程 READY了,那就高优先级线程获取CPU,没有什么策略可言。
调度的总体规则(基于一个CPU)
- 某个时刻只能有一个任务处于运行状态
- 最高优先级的Ready任务将获得CPU的使用权
- 一个任务将会运行直到它退出或者被阻塞
- 一个Round Robin任务将会运行一个时间片的时间,结束后操作系统会再次调度它(如果需要的话)
1.FIFO调度策略
同优先级线程采用FIFO策略调度
在FIFO调度策略中,一个在运行的线程将会持续运行直到:
主动放弃CPU;被高优先级线程抢占
FIFO(First In First Out),顾名思义谁先来(谁先变为Ready状态)的就先执行谁,这有点像我们在医院排队看病,谁排在前面就先给谁看(有生命危险的病人可以插队,相当于优先级比较高的任务)。
在FIFO策略中,一个线程可以一直占用CPU,直到它执行完。这意味着如果一个线程正在做一个非常长的数学计算而且没有其他更高优先级的线程就绪,这个线程就会一直执行下去。拥有相同优先级的线程会怎么样呢?它们会一直等待,当然更低优先级的线程也得不到执行。如果运行中的线程退出或者自愿放弃CPU的使用权,此时内核会寻找其他拥有相同优先级的就绪线程。如果没有这样的线程,内核会继续寻找更低优先级的就绪线程。自愿放弃CPU有以下两种情况。如果线程进入sleep,或被信号量阻塞,此时更低优先级的线程可以运行。另外一个是一个系统调用sched_yield(),仅仅让渡CPU给相同优先级的线程。如果一个线程调用了sched_yield(),而且没有相同优先级的线程就绪,此时会继续执行调用sched_yield()的线程。
假如有一个任务在做一个非常长的数学运算,又没有更高优先级的任务处于Ready状态,这个任务将会一直执行直到运算完毕。如同前面的一个病人病情十分复杂,占用了医生很长时间,此时排在后面的病人只能等着。那么和它相同优先级的任务会如何呢?答案是一直处于等待状态,同理更低优先级的任务也是一直处于等待状态。
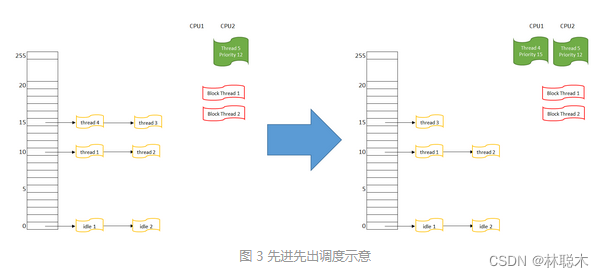
- 首先在CPU 1上运行的线程4,被挪入优先级15的队列队首
- 然后重新搜索可执行的最高优先级线程,这里有优先级15队列上的线程4和3
- 线程4因为在队列最前端,它被选择得到CPU,线程4的状态变为RUNNING,在CPU1上执行
可以看到,在这个调度算法下,如果没有别的状态发生,事实上线程4就会一直占据CPU1。
如果在优先级15上的线程3和线程4都是FIFO会怎样?按上面的描述,线程3还是始终无法获得CPU1,因为线程4每次都会插在3的前面,再调度就又是4获得CPU1。除非线层4进入了阻塞状态(从而不在READY队列里了),那么线程3才能获得CPU。
如果执行中的任务退出或者自愿放弃CPU,此时操作系统会寻找排在前面的相同优先级的Ready任务来运行,如果没有这样的任务,操作系统会继续寻找更低优先级的Ready任务来使用CPU。需要注意的是,任务自愿放弃CPU有两种情况:
- 任务进入睡眠状态或者被信号量阻塞(需要访问的资源此时被别的任务占用)。这种情况下如果没有相同优先级的Ready任务,更低优先级的任务是可能被执行的。
- 任务调用sched_yield()让出CPU。此时仅仅是把CPU的使用权让给具有相同优先级的Ready任务,如果没有相同优先级的任务处于Ready状态,最初的任务(调用sched_yield()的任务)将继续运行。由此可见,sched_yield()的作用是,有效率地把CPU的使用权让给其他具有相同优先级的Ready任务。
2基于时间片的轮询调度策略(Round-robin)
同优先级线程采用时间片轮转策略。其中对于高于40MHz主频CPU,轮转时间片默认为1ms。除了加入时间片限制,轮转策略其他部分与FIFO一致。如果一个线程用完时间片就会被中断运行,移到队列尾部。
Round Robin的调度策略和FIFO类似,不同的是一个任务不会一直占用CPU(如果当前有相同优先级的任务)。一个任务只会运行事先定义好的固定的一段时间,这一段时间被称为时间片,时间片的值可以通过调用sched_rr_get_interval()来进行设置。但是如果有相同优先级的线程就绪的话,当前线程不会永远执行下去。当前线程只执行一个系统定义好的时间片的时长,时间片的长度可以使用函数sched_rr_get_interval()获取。时间片的长度通常是4ms,不过实际上是ticksize的4倍,ticksize的值可以通过ClockPeriod()查询。内核启动一个RR线程的时候会开始计时,RR线程运行一段时间后分配给它的时间片将会用完。此时内核会检查是否有相同优先级的线程处于就绪状态,如果有,内核会让该线程开始执行,否则内核会继续让之前的线程执行并会再分配一个时间片给该线程。
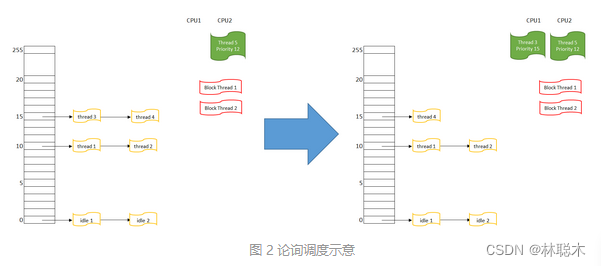
- 首先在CPU 1上运行的线程4,被挪入优先级15的队列末尾
- 然后重新搜索可执行的最高优先级线程,这里有优先级15队列上的线程3和4
- 线程3因为在队列最前端,它被选择得到CPU,线程3的状态变为RUNNING,在CPU1上执行
可以预期,当下一次调度发生时,线程3会被挪入优先级15队列末尾,而线程4会被调度执行,这样线程3和4会分别得到CPU1.
当操作系统启动一个任务时,它会同时开始计时。当时间片设定的时间到了之后,操作系统会去查看是否有相同优先级的任务处于Ready状态。如果有,操作系统将启动该任务,否则操作系统将会继续让之前的任务运行,该任务又重新获得了一个时间片。
3适应式调度策略Sporadic scheduling
是QNX中比较特殊的调度策略,用于同时处理周期性事件与非周期性事件。该策略下,线程的优先级是动态调整的。适应调度( adaptive scheduling) 也存在QNX的其他版本中,如果一个线程在消耗完了自己的时间片时仍在运行,那么他的优先级就减一(优先级降低);即使他消耗完了另一时间片,此时他优先级也不会再下降,即只将一级;如果该线程被阻塞了,那么他的优先级立即回复为原来的优先级。
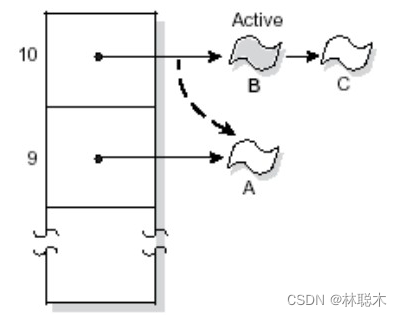
上图中A线程消耗完了自己的时间片后被降级,此时处于就绪状态的B线程获得了CPU资源。
由此可见这种算法不适合实时控制系统,它主要应用在后台有计算密集的任务并同时又要响应用户的交互信息,此时 ,计算计算线程可以有足够的CPU资源,同时对用户的请求又有很快的响应。
该策略下,线程其每周期T内,在时间片长度C中,其优先级为正常状态N。超过C后,其优先级被降级为L。而在T周期后,其优先级再次提升为正常优先级N。
因此该策略的主要目的是使得特定线程能周期性处理事件且其每次处理的事件长度固定,使得系统其他线程能够运行。
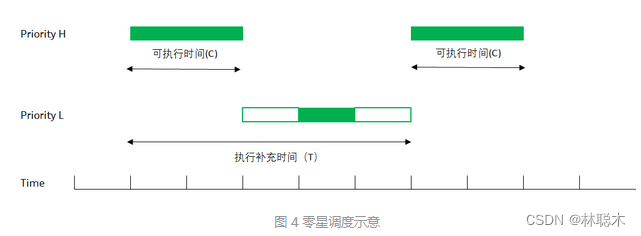
- 开始的时候,线程在比较高的(正常)优先级 H 上运行,一直到把预先分配给零星调度的时间用完(sched_ss_init_budget)
- 这时,线程会被自动调整为低优先级L(sched_ss_low_priority);一旦被调低,线程也可能运行(如果优先级L依然是系统里最高优先级的线程),也可能无法运行呆在READY队列里(系统里有比L更高的优先级)
- 不管线程有没有执行,从最开始运行时间点算起,当线程“执行补充时间"(sched_ss_repl_period)过了以后,线程的优先级被重新提到优先级H,并试图取得CPU来。
“零星调度”看上去比较“公平”,但是实际在用QNX的项目中,这个调度算法很少被用户用到。主要是因为一般来说在QNX上很少有线程能够“连续占用CPU”的。而且当系统变得复杂,线程数成百上千后,这种上下调优先级的做法,很容易出现别的后遗症。
实时任务可分为周期任务、非周期任务和零星任务。对于非周期任务和零星任务的调度方法通常是利用空闲时间及利用一个周期任务作为其服务器,定期地处理就绪的零星任务和非周期任务。
POSIX详细规定了适用于处理非周期性事件和零星事件以及静态优先级抢占调度条件下线程的零星调度策略。
系统调度零星事件的方法基本上有两种:基于空闲时间和基于服务器,无论哪种调度情况,首先要做可接受测试,进而对测试任务进行调度。
基于服务器的零星事件调度是指使用一个带宽预留服务器(p,e)专门调度零星事件,这个服务器一其他周期任务一起按照系统应用的调度策略被调度。消耗和补充规则确保每次到来的SS(零星服务器)都有确定的周期p和执行时间e。对于SS而言,最重要的是资源消耗和补充规则。负责的消耗和补充规则可以是SS的资源留更长的时间,补充资源更有竞争性,还可以平衡响应时间与执行时间的开销间的矛盾。
QNX在进程调度中新增加了此调度算法,采用是基于服务器的零星调度策略:
在这种算法之下一个线程动态可执行于正常优先级下和低优先级下。主要的可设定参数有:初始预算值(C) ,在正常优先级下允许执行的时间;低优先级(L) ,由于某种原因不可能再以正常优先级运行了,就将该线程的优先级降至此优先级;补充周期(T),只有在这个时间内线程才被允许消耗完它的初始预算值;最大补充周期数(M),对补充周期的发生次数进行限制。
实际上也主要是下面的这个结构体定义:
- struct sched_param {
- int32_t sched_priority;
- int32_t sched_curpriority;
- union {
- int32_t reserved[8];
- struct {
- int32_t __ss_low_priority;
- int32_t __ss_max_repl;
- struct timespec __ss_repl_period;
- struct timespec __ss_init_budget;
- } __ss;
- } __ss_un;
- }
- #define sched_ss_low_priority __ss_un.__ss.__ss_low_priority
- #define sched_ss_max_repl __ss_un.__ss.__ss_max_repl
- #define sched_ss_repl_period __ss_un.__ss.__ss_repl_period
- #define sched_ss_init_budget __ss_un.__ss.__ss_init_budget
各参数关系如下图所示:
当线程的优先级降低到低优先级时它有可能会被执行也有可能不被执行, 这取决于系统当时的其他线程的优先级了。一旦一个补充周期 T 的到来,该线程的优先级立即升至正常的优先级,这样只要适当的配置系统各主要线程的 C 和 T 就可以使得每个线程都可以在每个补充周期 T 内被执行 C 时间值,保证了该线程运行在正常优先级状态下消耗了 C/T% 系统资源。
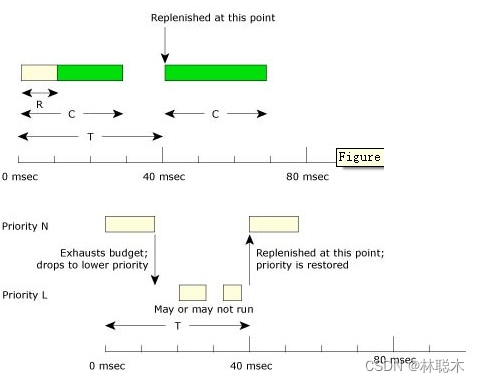
下面从一个具体的实例来分析零星调度算法的工作过程: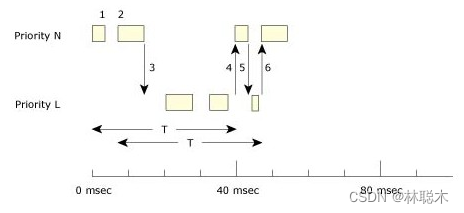
在这个例子中预算值 C为 10msec,补偿周期T为40msec:
- 1、开始时本线程无阻塞的运行了3ms, 因此对应于这次运行的一个补充周期将会在第40ms处开始
- 2、该线程在第 6ms时又开始运行,此时它启动标记了另一个补充周期,并且在此期间它连续运行了 7ms,即消耗完了预算值 C;
- 3、由于预算值C被消耗完了,该线程的优先级主动降至设定的低优先级;另外一个补偿周期在46msec是发生;
- 4、在 40ms的时候,第一个补充周期结束了,此时它的优先级升至正常优先级;
- 5、该线程执行3ms然后又降至低优先级;
- 6、到 46ms 的时候重新给一个补充周期,此时它的优先级升至正常优先级,并执行 7ms
然后又转入低优先级
在这个调度算法控制之下,将一个线程需要执行的时间分拆成了若干段进行执行(这也就是
它名字的来由)。
这种算法通常应用在一个周期内具有执行时间上限的线程,可以使一个线程对非周期的事件进行服务而不要担心影响其他硬实时线程的执行期限。
总之:
- 第一:零星事件可以说都是实时事件
- 第二:保证每个补充周期可以搞定零星事件的执行时间,他也是可以被抢占的
- 第三:估计每个补充周期都有一次零星事件
下面是对此算法的一个验证结果: 
测试代码
三种调度策略:SCHED_FIFO, SCHED_RR,SCHED_SPORADIC。默认为SCHED_RR,常用的为SCHED_RR和SCHED_FIFO。
根据官方文档的介绍,可以大致理解两者的区别是:SCHED_RR首先看优先级,同一优先级下,多个线程轮流调度,不会让一个线程长时间独占CPU资源。SCHED_FIFO则是同优先级下线程执行,直到一个可以调度点才退出占用资源。
- #include <stdlib.h>
- #include <stdio.h>
- #include <stdint.h>
- #include <sys/mman.h>
- #include <errno.h>
- #include <unistd.h>
- #include <pthread.h>
- #include <unistd.h>
- #include <string.h>
- #include <time.h>
- #include <gulliver.h>
- static int thread_sched_policy()
- {
- struct sched_param param;
- int policy, retcode;
- /* Get the scheduling parameters. */
- retcode = pthread_getschedparam( pthread_self(), &policy, ¶m);
- if (retcode != EOK) {
- printf ("pthread_getschedparam: %s.\n", strerror (retcode));
- return EXIT_FAILURE;
- }
- printf ("The assigned priority is %d, and the current priority is %d,policy is %d\n",
- param.sched_priority, param.sched_curpriority, policy);
- /* Increase the priority. */
- // param.sched_priority++;
- policy = SCHED_RR;
- retcode = pthread_setschedparam( pthread_self(), policy, ¶m);
- if (retcode != EOK) {
- printf ("pthread_setschedparam: %s.\n", strerror (retcode));
- return EXIT_FAILURE;
- }
- }
-
- void* thread_test_func2(void* arg)
- {
- thread_sched_policy();
- int count = 2500000000;
- while(count>0)
- {
- count-- ;
- }
- }
- int testthreadschedpolicy()
- {
- pthread_t tid=0;
- pthread_create(&tid, NULL, thread_test_func2, NULL);
- return 0;
- }
-
- int main(int argc, char *argv[]) {
- printf("Welcome to the QNX Momentics IDE\n");
-
- if(1)
- testthreadschedpolicy();
-
- printf("test ok!");
- while(1)
- {
- static int count = 0;
- printf("main thread %d!\n", ++count);
- sleep(5);
- }
- return EXIT_SUCCESS;
- }
测试程序有个2个线程,当子线程的调度策略为SCHED_RR时,console中有主线程中printf的打印信息;当子线程的调度策略为SCHED_FIFO时,则完全没有主线程中的打印信息。
QNX IPC通讯机制
QNX除了支持Native的IPC机制如Massage passing、Signal等,同时还提供POSIX标准的IPC例如MessageQ、Piple、Shared Memory等IPC通讯方式,多种IPC方式供用户在不同的应用场景下进行选择。
QNX 的IDE集成开发环境
QNX提供基于Eclipse的Momentics IDE集成开发环境,供用户进行基于以太网Software GDB的代码级的编译调试或系统性能分析,可实时以图形化的方式,查看进程资源、系统日志、CPU占用情况,内存使用情况,进程间通信以及Coredump等。
QNX特点
- 高效率:内核小巧,运行极快;可任意裁剪成适合自己的最小方案;
- 易操作:应用程序接口完全符合 POSIX 标准,Linux用户可快速上手QNX。
- 实时性:多种基于优先级的抢占式调度算法让QNX 能够实现实时任务调度和预测任务响应时间,确保不论系统负载如何,高优先级任务总是能按时完成。
- 微内核:地址空间隔离,保证任何一个部分出了错误不会影响其他部分和内核, 并且可自动重启恢复。
(1)QNX是嵌入式硬实时的微内核操作系统
有硬实时、微内核、模块化、弱耦合、分布式的特点,从1980年诞生之初就是基于SOA架构设计,基于Client-Server的模型,具体表现为:
- 硬实时:任何切换时间和中断时延速度快,所有的任务响应均为确定性deterministic行为。
- 微内核:除调度、进程管理、中断及操作系统核心的功能外,其余部分都处于用户态,包括驱动、协议栈、文件系统及功能模块等。
- 模块化:操作系统的各个功能单元都模块化设计,内存保护,并且相互隔离,可按照需要动态加载或卸载,基于消息机制通信,按照Client-Server的架构设计。
- 弱耦合:模块与模块之间互不影响,都在独立的虚拟地址空间运行。
- 分布式:局域网内的QNX系统对于用户角度可以认为是一台QNX系统,资源可以复用。
(2)QNX是类UNIX操作系统
遵循POSIX的最高级别PSE54标准(注:POSIX标准有四个等级PSE51, PSE52, PSE53和 PSE54, 在RTOS实时操作系统的世界里,只有QNX操作系统是PSE54标准的,因为QNX诞生之初就是类UNIX系统按照POSIX标准编写),因此基于开源的应用程序以及一些开源的中间件都可以无缝的移植到QNX系统之上。QNX Microkernel和Process Manager组成QNX最小系统Procnto,其他如驱动程序、协议栈、文件系统、应用程序都作为一个独立的模块运行在QNX系统之上。
(3)QNX是功能安全和信息安全的操作系统
QNX通过功能安全TUV莱茵ISO 26262 ASIL D最高等级道路车辆最高功能等级安全认证,包括QNX 操作系统、QNX Hypervisor虚拟化和Graphic Monitor图形监控子系统以及QNX IPC通讯机制black channel,同时黑莓是网络信息安全标准ISO/SAE 21434 委员会基础软件组唯一成员。
QNX性能
在QNX中,实时和非实时环境是一样的。实时应用程序可以充分使用POSIX API和访问系统服务。POSIX/Linux应用程序可以立刻获得确定的行为。由于实时和非实时应用程序运行在相同的基于消息的环境中,进程之间的通信就非常简单了。减少重复工作。像之前讨论的,双内核方式会逼迫开发者使用不熟悉的API开发定制驱动。在大部分的操作系统环境中,开发这些驱动要求内核调试工具(非常难用),内核重新编译(非常耗时)和内核编程(成本高)。QNX Neutrino通过几种方式解决了这个问题。首先,像任何已具有大量用户群的OS一样,QNX支持各种用于标准硬件的现成驱动程序。并且,就像我们看到的,QNX在用户空间运行驱动,因此可以使用标准的代码级别的工具和技术。QNX DDKs让开发变得更简单了。DDK提供文档,库文件,头文件和可定制的各种驱动程序源。除了微内核的功能,由于微内核实时操作系统的设计是为了满足嵌入式系统的要求,QNX Neutrino还为Linux开发人员提供标准Linux或实时Linux扩展均不具备的功能。
与QNX相比,Linux有更大的开发人员社区,软件社区和真正的开源代码,以及更大的平台社区。ELC和CELF正在使嵌入式Linux标准化。 嵌入式Linux的最新版本要求具有完全POSIX兼容性的硬RTOS。
- QNX Neutrino提供了QNX微网络服务,允许消息在处理器边界之间透明地流动。这意味着任何进程都可以访问任何资源任何网络节点就好像它们在本地一样。如果驱动的路径名在本地,QNX微内核可以直接路由这个消息。如果这个驱动在远程节点上,QNX微网络会透明的将这个消息转发给对应节点。
- 网络流量可以在所有可用链路上实现负载均衡,从而提高吞吐量。该服务是内置的,应用程序不需要任何特殊的网络代码。
- QNX微内核体系结构的细粒度可扩展性使得运行时环境比Linux小得多。
- Photon microGUI也使用微内核的架构。因此,设计人员可以轻松地“拔出”内存受限设备不需要的GUI服务。
- QNX支持TCP/IP, NFS和Linux文件系统。因此使用QNX和Linux混合工作站的开发商店可以在这两种环境中分享资源。简而言之,Linux和QNX Neutrino不仅可以共存,还可以做更多的事情。相反,跟其他实时或通用的操作系统相比,它们为开发人员提供了更广泛的在应用程序中使用相同的API,源代码和技能点的机会。
- QNX 支持 MIPS, PowerPC, SH4, StrongArm, xScale, and x86硬件架构。它可以从受约束的嵌入式平台扩展到多处理器平台。该体系结构提供多任务处理,优先级驱动的抢先式调度,同步和TCP/IP协议。同时还提供了包括PPP,DHCP,NFS,RPC和SNMP的实用程序。
- QNX具有称为Qnet的基于消息的本机网络。
- Photon microGUI桌面系统是一个内存占用很小的GUI。
- 对于GUI应用程序,QNX有一个叫Photon Application Builder(PhAB)的集成开发环境。不像Visual Basic,它没有拖拽控制。
- 自我托管功能简化了开发
- QNX使用GNU GCC编译器
- QNX RTP支持GCC-2.95 C和C++。而且QCC作为一个GCC前端的抽象层屏蔽了不同编译器(GNU GCC, Watcom和Metrowerks)之间的差异。还有一个CC端用来屏蔽可用编译器之间的差异。该前端还可以基于文件扩展名调用对应的编译器(C或C ++)。目前它调用GCC/G++。对于项目代码管理,QNX的发行版本中包含了make, CVS和RCS这些工具。
- 支持GCC编译器的交叉编译版本,允许开发者在Windows平台上开发Neutrino应用程序。
QNX的微内核结构
微内核操作系统(Microkernel Operating System)结构,是20世纪80年代后期发展起来的。由于它能有效地支持多处理机运行,故非常适用于分布式系统环境。
QNX采用微内核结构,也就是说,内核非常非常非常小。这样一方面启动速度非常快,另一方面安全性稳定性大大提高。
QNX构架是有一个微型内核,然后又包含许多相关进程。这样的好处是,即使有一个进程出错,也不会影响内核。
内核独立自处于一个被保护的地址空间;驱动程序、网络协议和应用程序处于程序空间中。
微内核结构的优点: ①驱动程序、网络协议、文件系统等操作系统模块和内核相互独立,任何模块的故障都不会导致内核的崩溃; ②驱动程序、网络协议、文件系统和应用程序都处于程序空间,都调用相同的内核API,开发与调试和应用程序没有区别; ③操作系统功能模块可以根据需要动态地加载或卸载,不需要编译内核。
在具有高可靠性内核的基础上,QNX的创新设计使它同样具有很高的效率。
QNX最为引人注目的地方是,它是UNⅨ的同胞异构体,保持了和UNⅨ的高度相似性,绝大多数UNⅨ或LINUX应用程序可以在QNX下直接编译生成。
这意味着为数众多的稳定成熟的UNⅨ、LINUX应用可以直接移植到QNX这个更加稳定高效的实时嵌入式平台上来。
各个服务进程以及应用进程之间通过内部进程通信IPC的方式进行沟通。
微内核操作系统特点
(1)足够小的内核 微内核不是一个完整的OS,他拥有操作系统中最基本的部分,保证操作系统的内核做到足够小。
- 实现与硬件紧密相关的处理
- 实现一些较基本的功能
- 负责客服端和服务器之间的通信
(2)基于 C/S 模式 将操作系统中最基本的部分放入内核中,把操作系统的绝大部分功能放在微内核外面的一组服务器(进程)中实现。
这些服务器运行在用户态,客户与服务器之间借助微内核提供的消息传递机制来实现通信。如:
- 用于对进程(线程)进行管理的进程(线程)服务器
- 提供虚拟存储器管理功能的存储器服务器
- 提供I/O设备管理的I/O设备管理服务器
(3) "机制与策略分离"原理 机制:指实现某一功能的具体执行机构 策略:在机制的基础上,借助某些参数和算法来实现该功能的优化,或者达到不同的功能目标。
在传统的OS中,机制通常放在OS的内核较低层,策略放在内核的较高层。而在微内核的OS中,通常将机制放在OS的微内核中。这样微内核才能够做的更小。
(4)采用面向对象技术
- 抽象、隐蔽:控制系统的复杂性
- 对象、封装、继承:确保系统的正确性、可靠性、易修改性、易扩展性,提交操作系统的设计速度。
QNX的透明分布式处理
QNX透明分布式处理,原理很简单,就是打通两个QNX之间的消息传递,让一个QNX系统里的进程 ,可以跟另一个QNX系统里的进程,进行“透明“的信息传递。透明的意思是,进程不需要做什么特殊的更改,就可以直接和远程的进程通信了。
我们来看看,在两个QNX系统之间的播放器可以怎么工作?
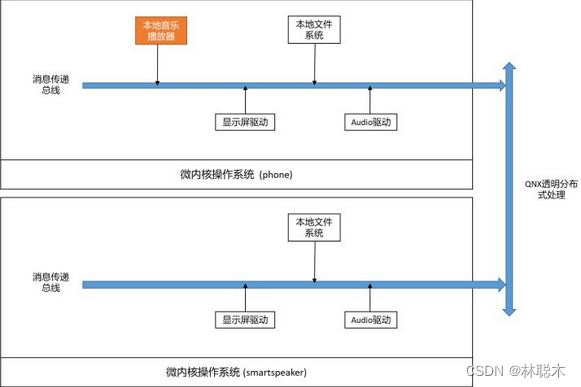
比如上图,我们有一个叫 “phone” 的QNX系统,还有一个叫“smartspeaker”的QNX系统,通过透明分布式处理已经互相连上了。这意味着,“phone”里的进程 ,除了可以通过“phone”里的消息传递总线,跟phone里的驱动、子系统通信外;还可以直接跟smartspeaker里的驱动、子系统进行通信
我们可以看到,只有phone里有本地音乐播放器。这个播放器,可以如前述一样在phone里播放本地音乐。
- 发消息给 phone 的Audio 驱动,请求使用Audio通道
- 发消息给phone的文件系统,请求打开被选中的歌(文件)
- 发消息给phone的文件系统,请求顺序读取被打开的文件
- 解码读取到的数据
- 把数据发给phone的Audio驱动,由Audio驱动去控制Audio芯片,播放歌曲
- 发消息给phone的显示屏,更新显示屏上的信息(播放时间,剩余时间,歌词 …)
- 重复上述3-6,直到文件读完为止
但如果在7)里面,突然决定这首歌需要在smartspeaker上播出会怎么样呢?
- 发消息给smartspeaker的Audio驱动,请求使用Audio通道
- 发消息给phone的文件系统,请求顺序读取被打开的文件
- 解码读取到的数据
- 把数据发给准备好了的smartspeaker的Audio驱动,由Audio驱动去控制Audio芯片,播放歌曲
- 发消息给phone的显示屏,更新显示屏上的信息(播放时间,剩余时间,歌词 …)
- 重复9-12,直到文件读完为止
所以,只要把数据(通过消息传透,经过透明分布总线)发送给另一台机器的Audio驱动,就可以在远程播放出声音来了。而播放器程序本身,不需要做任何的更改。甚至不需要专门的网络通信代码。
QNX线程调度策略优先级时钟频率同步
-
-
- /*
- * barrier1.c
- */
-
- #include <stdio.h>
- #include <unistd.h>
- #include <stdlib.h>
- #include <time.h>
- #include <pthread.h>
- #include <sys/neutrino.h>
- #include <timer.h>
-
- pthread_barrier_t barrier; // barrier synchronization object
-
- void *thread1 (void *not_used)
- {
-
- int policy;
- struct sched_param param;
- pthread_getschedparam(pthread_self(),&policy,¶m);
- if(policy == SCHED_OTHER)
- printf("SCHED_OTHER 1 \n");
- if(policy == SCHED_RR);
- printf("SCHED_RR 1 \n");
- if(policy==SCHED_FIFO)
- printf("SCHED_FIFO 1 \n");
- if(policy==SCHED_SPORADIC)
- printf("SCHED_SPARODIC 1 \n");
-
- setprio(0, 11); //设置线程优先级 越大优先级越高 0 代表当前进程
- printf("thread1 priority is %d\n",getprio(0));
-
- time_t now;
-
- time (&now);
- printf ("thread1 starting at %s", ctime (&now));
-
- // do the computation
- // let's just do a sleep here...
- while(1)
- {
- delay (100);
- pthread_barrier_wait (&barrier);
- // after this point, all three threads have completed.
- time (&now);
- printf ("barrier in thread1() done at %s", ctime (&now));
- }
- }
- void *thread2 (void *not_used)
- {
- //查看线程的调度策略 默认为轮询
- int policy;
- struct sched_param param;
- pthread_getschedparam(pthread_self(),&policy,¶m);
- if(policy == SCHED_OTHER)
- printf("SCHED_OTHER 2 \n");
- if(policy == SCHED_RR);
- printf("SCHED_RR 2 \n");
- if(policy==SCHED_FIFO)
- printf("SCHED_FIFO 2 \n");
- if(policy==SCHED_SPORADIC)
- printf("SCHED_SPARODIC 1 \n");
- setprio(0, 10); //设置线程优先级 越大优先级越高 0 代表当前进程
- printf("thread2 priority is %d\n",getprio(0));
- time_t now;
- time (&now);
- printf ("thread2 starting at %s", ctime (&now));
- // do the computation
- // let's just do a sleep here...
- while(1)
- {
- delay (200);
- pthread_barrier_wait (&barrier);
- // after this point, all three threads have completed.
- time (&now);
- printf ("barrier in thread2() done at %s", ctime (&now));
- }
- }
-
- int main () // ignore arguments
- {
-
- pthread_t threadID1,threadID2;
-
- setprio(0, 12); //设置线程优先级 越大优先级越高 0 代表当前进程
- printf("Main priority is %d\n",getprio(0));
- //CPU 时钟频率
- struct _clockperiod timep;
- timep.nsec = 10*1000;
- timep.fract = 0;
- int ErrCode = 0;
- ErrCode = ClockPeriod(CLOCK_REALTIME, &timep, NULL, 0);
- if(ErrCode!=0)
- {
- printf( "Error: %s\n", strerror(ErrCode));
- }
- /****************************************/
- int ret = -1;
- int timer_interrupt_id = -1;
- ret = InitializeTimerInterrupt(0, 300, &timer_interrupt_id); //设置时钟中断,10ms
- /*****************************************/
- time_t now;
-
- // create a barrier object with a count of 3
- pthread_barrier_init (&barrier, NULL, 3);
-
- // start up two threads, thread1 and thread2
- pthread_create (&threadID1, 0, thread1, 0);
- pthread_create (&threadID2, NULL, thread2, NULL);
- // at this point, thread1 and thread2 are running
-
- // now wait for completion
- time (&now);
- printf ("main() waiting for barrier at %s", ctime (&now));
- while(1)
- {
- InterruptWait(0, NULL);
- pthread_barrier_wait (&barrier);
- // after this point, all three threads have completed.
- time (&now);
- printf ("barrier in main() done at %s", ctime (&now));
- }
- pthread_exit( NULL );
- return (EXIT_SUCCESS);
- }
多开发系统对比
1:QNX的可靠性很好,协议栈、各种外设驱动稳定,只是运行所需资源有些多,需要MMU。如果需要高可靠性应用,QNX可能是最好的选择,本人公司现在就是基于QNX开发RTOS的。
2:RTLinux的实时性与其它RTOS相比有些差。但是,因为好多Linux资源可以利用,是RTLinux的优点。但是运行所需资源比QNX还多,也是需要MMU。可以选用开源的RTLinux或内容新的商用RTLinux。
3:uC/OS-II比较小巧,移植容易,网上资源很多,核心可以做得很小。但不是免费的,并且驱动需要自己编写,协议栈、图形驱动都要另外加。
4:Nucleus Plus比uC/OS-II庞大,另外提供了文件系统、协议栈、图形界面等许多东西。当然也是分开卖的,不是免费的东西。使用起来比较容易上手。
5:VRTX是一款比较早的RTOS,现在使用的人已经很少。运行还是比较可靠。配套的文件、协议栈等模块很少。
6:VxWorks是RTOS中的大牛,国内外用的人很多,开发工具功能强大,使用方便,但是价格昂贵。也有基于MMU的高可靠性的产品。所需资源比QNX小,比uC/OS、eCos多。对于一些私企或者好似小公司来说,可用性值得商榷。
7:eCos是开源的RTOS。针对不同的CPU已经做了许多现成的移植。代码尺寸比Nucleus的略大。如果不用USB host等,并且不想花费太多的金钱,应该是不错的选择。
应用案例
1.QNX算法移植以及性能优化举例
QNX提供ADAS reference平台产品,里面涵盖了Sensor Framework,networking,open source modules,第三方的SDK以及一些参考设计,其中sensor Framework提供了ADAS的一些基本库。
2.算法移植
自动辅助驾驶以开源的算法居多,由于QNX符合POSIX PSE54标准,API兼容基本一致,因此各类开源算法可以很方便的移植到QNX的平台上,使用QNX的工具链进行编译并运行,但是虽然API是一致的,但由于实时操作系统的特性,表现的行为会有所差异,需要对系统进行优化调整。
QNX有专门的team来根据roadmap以及客户需求移植一些开源软件,比如ROS/ROS2,比如OpenCV和vSomeIP。
3.分享常见的QNX性能优化项
1. IPC优化
QNX支持绝大部分主流POSIX系统常见的IPC方式,同时也有其独特的原生IPC方式,Message-passing。在自动辅助驾驶方案设计中,常有公司会将UDS、DDS做为软件通信总线的架构方案原封不动地从Linux照搬到QNX上。从功能上看,这样的跨平台方案可以使得代码重用并且功能没有区别。但从性能角度考虑,由于QNX独特内核架构,这并不是高效的解决方案。不同于Linux的宏内核架构,QNX为了安全性和实时性采用了微内核架构,绝大部分的系统服务,比如网络协议栈,它是完全运行在内核之外以服务(Resource Manager)的方式运行。如果采用UDS(Unix Domain Socket)这用基于网络服务(严格意义上讲,UDS并不需要经过网络协议栈,但也是需要经过QNX的网络服务io-pkt支持)的通讯方式,那么所有的数据报都需要经过网络服务中转,相比直接通讯多了一次IPC,这就带来了系统资源的浪费。建议的优化方案是采用更高效的IPC方式,一般情况下,中小量的数据量传输建议使用message-passing,特别大的数量使用shared memory方式。另外,一些开源软件也会大量使用FIFO,PIPE等IPC,尽管QNX支持这类使用,但是我们也建议改成更高效的message passing方式,以减少单次IPC的开销。
2. 编译选项优化
QNX采用GCC的框架,出于安全性的考虑,QNX的编译器版本更新相比没有开源社区激进,相比会慢一些。比如SDP 7.0采用的是GCC 5.4.0,SPD 7.1采用的GCC 8.3.0,即将推出的SDP Moun会采用GCC 11.X。有时候会发现,运行同样一个算法库,QNX性能会比开源低,那很有可能是由于编译版本或编译优化选项差异的原因。因为在Linux系统上默认的ARMv8的编译优化选项是满级的,而QNX默认不打开ARMv8的优化选项,因此程序编译时候需要打开相关编译选项才能获得最佳性能,因为QNX基于安全性考虑某些编译选项在默认编译的时候并没有打开会导致性能问题。
3. 驱动级别优化
如网络/存储设备驱动,根据以往的经验,大部分的性能问题的瓶颈在设备驱动这层。特别是新的硬件、新的驱动,要注意根据QNX系统服务层做好适配,驱动的好坏,往往是除硬件本身之外最主要的性能影响因素。我们遇到非常多的来自驱动层面的空等,忙等,最终导致系统机能的冗余浪费。
4. 网络协议栈优化
除了网络驱动的优化,QNX的网络协议栈io-pkt本身也提供了丰富的参数,可以根据具体使用的应用场景来达到性能的最优化。另外,使用QNX SDP 7.1及后续版本的用户,可以使用最新的版本网络协议栈io-sock,它对多核CPU的利用和大并发小包数据的处理能力有显著地提升。两个协议栈各有千秋,实际上大量的案例证明,用户并没有达到io-pkt的性能瓶颈,socket buffer 不足导致丢包,typed memory pool分配的不够导致收发阻塞等等,这些都可以通过配置以及API层面的优化达到性能提升。
5. 系统API优化
如memory allocation,memory copy等,QNX提供jemalloc根据实际应用场景提供额外内存泄漏手段,提供更多的功能,jemalloc比default的malloc效率更高,特别是对于大量线程高并发调用的场景。
6. 用户接口优化
QNX 提供的底层接口,尤其是一些自有API,是有不少细微差别的,比如sendmsg()和sendmmsg(), 用户往往会比较熟悉前者,用于socket的发包,但是后者提供了message 队列来实现不增加IPC的基础上提高了整体的吞吐率。又比如mmap(),我们提供了一些QNX独有的flag来应对不同的memory mapping 场景,如MAP_ANON与MAP_PHYS的配合,才代表申请物理连续memory region而MAP_LAZY 更会延迟内存的申请分配。了解并熟悉每个接口的参数配置以及相近命名接口的应用场景会对开发帮助很大。我们的在线文档有专门的章节完整并详细的介绍了每一个接口的参数以及相关使用。
7. QNX提供Momentics IDE环境对算法进行性能分析
如memory leak,application profile等,同时提供kernel trace进行分析,在抓取的时间段中可以获得每个时间点的事件、中断响应,给出优化建议。我们也支持自定义的kernel 事件,来让用户可以精确的了解代码片段的运行情况。
8.QNX提供onboard debug
QNX提供了onboard debug也支持应用程序调用栈的实时保存及相应的GDB,在调查一些忙等的现场会有很大的帮助。
最后总结一下,即便作为ISO26262 ASIL-D安全认证的硬实时性操作系统,QNX在系统性能上也并没有落后宏内核系统。只要合理地使用和优化,它的性能表现同样非常优秀,同时占用更低系统资源。QNX有着丰富的算法移植和优化经验能给到用户,同时QNX提供一系列的手段和工具去定位算法性能的瓶颈。
应用场景
(1)QNX在自动辅助驾驶领域的应用
由于QNX实时性、确定性行为和功能安全的特性,契合自动辅助驾驶对功能安全ISO26262 ASIL D的安全等级要求,因此由于国内外主机厂项目的需求,QNX被广泛的应用于自动辅助驾驶领域,作为基础软件承载上层的各种实时和高可靠性应用。由于在自动辅助驾驶领域,芯片和基础软件越来越成为一个整体方案,因此QNX也被包含在主流的高性能自动辅助驾驶芯片的整体基础软件平台方案中,作为关键的一部分提供给最终用户。
(2)英伟达与黑莓QNX的合作
英伟达的一系列高性能芯片广泛的应用在自动辅助驾驶领域,例如Xavier、Orin和Thor等。英伟达作为顶尖的自动辅助驾驶芯片平台整体解决方案商,在平台软件层面上提供以DriveOS为核心的基础软件平台,早在五年前,英伟达就选定QNX,双方深入合作,QNX作为英伟达DriveOS功能安全ISO26262 ASIL D版本唯一的RTOS合作伙伴,由英伟达提供基于QNX的功能安全版本的DriveOS的一站式方案,例如在Xavier平台上,因为整体平台软件要达到ASIL D级别,DriveOS只提供QNX SafetyOS安全内核版本。英伟达极其重视功能安全,黑莓QNX作为英伟达平台中唯一RTOS操作系统合作伙伴,包含在Driver OS的整体方案,由英伟达提供一站式的方案和服务支持,即服务工程支持由英伟达统一接口。
(3)高通与黑莓QNX的合作
高通作为IOT和手机领域芯片方案的翘首,在车载汽车电子的中高端智能座舱领域占了绝大多数的份额,黑莓QNX作为高通Snapdragon座舱芯片整体解决方案的一部分,也是唯一的Hypervisor合作伙伴和高通一起支持了全世界近百个汽车电子的客户,同样在自动辅助驾驶领域,高通Snapdragon Ride也定点了许多全球领先的主机厂项目,例如官宣的大众、宝马、通用以及长城汽车等,黑莓QNX作为高通自动辅助驾驶芯片平台的基础软件底座部分,由高通提供一站式的ISO 26262 ASIL D功能安全等级的整体软件平台方案。
(4)国内自动辅助驾驶芯片公司与黑莓QNX的合作
近年来高性能的国产芯片层出不穷,在自动辅助驾驶领域,也有越来越多有潜力的国产公司展露头角,黑莓QNX目前已经完成适配黑芝麻A1000和地平线J5等芯片,由芯片公司提供一站式的整体解决方案。值得一提的是,后续还有多家重视功能安全的顶级国产大算力高性能自动辅助驾驶芯片合作,将于明年正式发布。
QNX的生态环境
在BlackBerry的解决方案中,连接接口(如USB,蓝牙,Wi-Fi)、总线(如CAN总线)以及其他资源(包括浏览器和媒体文件)均由更均在安全的QNX VM之上并受之管理。同时,无论内容在何处生成(Android VM,QNX VM或其他),系统设计人员都可以使用QNX的屏幕功能来管理内容显示类型和方式。
由于汽车制造商希望将车载信息娱乐系统、远程信息处理系统和数字仪表盘等方面的功能整合到虚拟驾驶舱控制器中,QNX SDP 提供了实时操作系统,支持ARMv8的64位计算平台和Intel x86-64架构,以及真正的1型管理程序虚拟化功能。
BlackBerry QNX的基础软件平台让汽车制造商在全球范围自由选择汽车平台应用程序(Android应用程序,Apple CarPlay,百度CarLife)。
如今有40多家汽车制造商(包括奥迪、宝马、菲亚特-克莱斯勒、福特、通用汽车、本田、现代、捷豹路虎、起亚、玛莎拉蒂、奔驰、保时捷、丰田、大众)部署BlackBerry QNX的软件。
此外,BlackBerry QNX与安波福、博世、日本电装、哈曼、麦格纳、松下、TT Tech、伟世通等众多汽车一级供应商建立了合作关系,并与英特尔、高通、恩智浦、瑞萨、英伟达、三星、德州仪器等高科技公司共同为前述车用设备企业和汽车制造商提供车用子系统。
-
德尔福与BlackBerry QNX合作开发自动驾驶操作系统平台
2017年9月,BlackBerry QNX和德尔福宣布建立合作关系。安波福自动驾驶系统将采用BlackBerry QNX操作系统,并共同研发交钥匙(Turnkey)自动驾驶平台,该端对端的平台预计于2019年发布。
-
黑莓与百度建立了合作,打开国内市场
2018年1月,百度宣布选择由BlackBerry QNX开发并通过ISO26262 ASIL-D安全认证的操作系统作为百度阿波罗自动驾驶开放平台的基础架构。
-
拜腾首款量产车将采用黑莓QNX技术
2018年6月,黑莓与拜腾达成合作并宣布,拜腾的首款量产车型将采用黑莓的QNX技术其中包括:QNX SDP 7.0实时操作系统及2.0版Hypervisor软件。
QNX未来展望
近年来自动辅助驾驶领域非常火爆,许多国内外的主机厂都逐步在量产项目中开发以及发布L2+的功能,当我们回顾这几年来快速发展会发现,大多数的自动辅助驾驶的人才都来自于Robotaxi,自动驾驶算法初创公司或大学研究机构,特别是算法人才。这就有个显著的特点,在这些公司里面的大多数项目,最初都是基于工控机+英伟达显卡(大多数用英伟达的GPU,少数用AMD的)+开源的操作系统+来自于开源的算法,其实和汽车电子的安全性本身毫无关系,唯一的好处就是快,容易尽早演示,尽快融资。
这些算法人才加入主机厂之后,更倾向于用以前最熟悉的开发方式,这样好尽快的出演示成果,也就是英伟达的SOC+开源的操作系统+来自于开源的算法。另一方面,在自动辅助驾驶项目中,一般主机厂会把控制器平台即硬件和平台软件外包给外部的Tier1来做,类似于一台PC电脑,而自己开发应用和算法。
一般主机厂也有平台组,负责部分的驱动及驱动以上的中间件的整合,系统组负责系统设计统筹,功能安全团队负责整体的功能安全,而算法团队负责算法应用的开发和实现,那么问题就来了,除纯算法团队外,一般国外的主机厂都会有一个成建制的叫算法嵌入式工程实现的团队,负责算法在非工控机的嵌入式环境和实时操作系统的优化实现落地,这样的团队即要懂一点算法架构,又要懂嵌入式软件的开发和硬件特性,又要对操作系统有足够的理解。
而在中国的许多主机厂,没有看到有这样一个团队,甚至这样的人才存在。因此不少项目由于开发周期紧,人员不具备嵌入式系统开发的经验,会采用更接近于robotaxi的方式开发,即英伟达SOC中的处理器(类似工控机),SOC中的GPU(类似显卡)和开源操作系统+未经优化的各种开源算法,在满足基本功能和有限性能的前提下,功能安全团队的建议通常会被直接忽略,因为要满足极短的量产时间,在国内主机厂军备竞赛中领先才是最重要的,这在欧美的主机厂是不可想象的。在这一点上,中国也有许多人才储备充足并且付责任的主机厂做的非常好,特别是有专门的经验丰富的算法工程实现的团队负责优化落地。期待在不久的将来,能够有更多的主机厂重视起这个问题,在中国有更多的行业人才能够填补这一空白。


