
- 1jmeter常用函数
- 2NLP学习总结|ChatGLM模型架构_chatglm 架构
- 3运维之docker启动失败Failed to start Docker Application Container Engine(1)
- 4C++/Qt 信号槽机制详解_qt 定义信号 和 连接信号
- 5springboot中使用redis及redis常用方法_redis maven
- 6「网络安全」SQL注入攻击_sql注入漏洞代码
- 7M3芯片macbook pro安装Maven时出现错误提示zsh: command not found: brew的解决办法#homebrew
- 8信创应用软件之邮箱_信创邮箱
- 9花卉培育信息管理系统设计与实现_园林花卉管理系统设计与开发
- 10HashMap(一)——HashMap put方法原理_hashmap lut
字节豆包大模型API吞吐、函数调用能力、长上下文能力测试总结_豆包 api
赞
踩
离开模型能力谈API价格都是耍流氓,豆包大模型作为API最便宜的模型之一,最近向个人开发者开放了,花了300元和一些时间对模型的API吞吐、函数调用能力、长上下文能力等进行了深度测试,看看它的能力究竟适合做 AI 应用开发吗?
本文首发自个人博客 豆包系列大模型能力深度体验,除了便宜,还有哪些亮点?
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读,此书围绕LangChain梳理了AI应用开发的范式转变,除了LangChain,还涉及其他诸如 LIamaIndex、AutoGen、AutoGPT、Semantic Kernel等热门开发框架。

本文首发自个人博客 豆包系列大模型能力深度体验,除了便宜,还有哪些亮点?
测试指标
测试指标选哪些,这里以我自己实际接触到的一次企业客户技术咨询为例,抛开大模型厂商自己作为宣传的跑分榜单,看看企业选型究竟关注什么,下面是对方当时抛出的问题:
我们想跟大模型公司合作,通过 api 调用他们的大模型,在找这样的公司时主要考虑什么哪些因素呢,我列了下面几点:
1、模型性能和能力:参数规模、训练数据集的来源和大小、上下文长度
2、模型类型(模型能力):有哪些模型类型,文本模型、语音模型,是否有向量化模型
3、易用性和接入方式:API 的接入方式、文档的完整性、SDK 的支持情况等。
4、成本:定价策略,包括计算资源的计费方式,token 如何收付
5、安全性和合规性:数据隐私保护、是否符合相关法律法规和标准
6、性能稳定性和故障率:模型运行的稳定性,系统故障和崩溃的频率
7、并发处理能力:模型能够处理的并发请求量
8、调用 API 的响应时间
9、可扩展性:是否具有良好的可扩展性,能够随着企业业务的发展而不断升级和优化。
我本篇内容会围绕这些点展开。
模型类型
进入模型广场,火山方舟当前支持接入 14 个大语言模型,模型提供商除了字节,还有 Moonshot、智谱 AI、Mistral AI(开源)、Meta(开源),除此之外还提供了面向向量检索场景的向量模型 doubao-embedding,用于声音克隆的语音模型 ve-voiceclone,不过这里我们主要关注豆包系列 6 个语言模型,即 Doubao-lite-4k 、Doubao-lite-32k 、Doubao-lite-128k 、Doubao-pro-4k 、Doubao-pro-32k 、Doubao-pro-128k 。
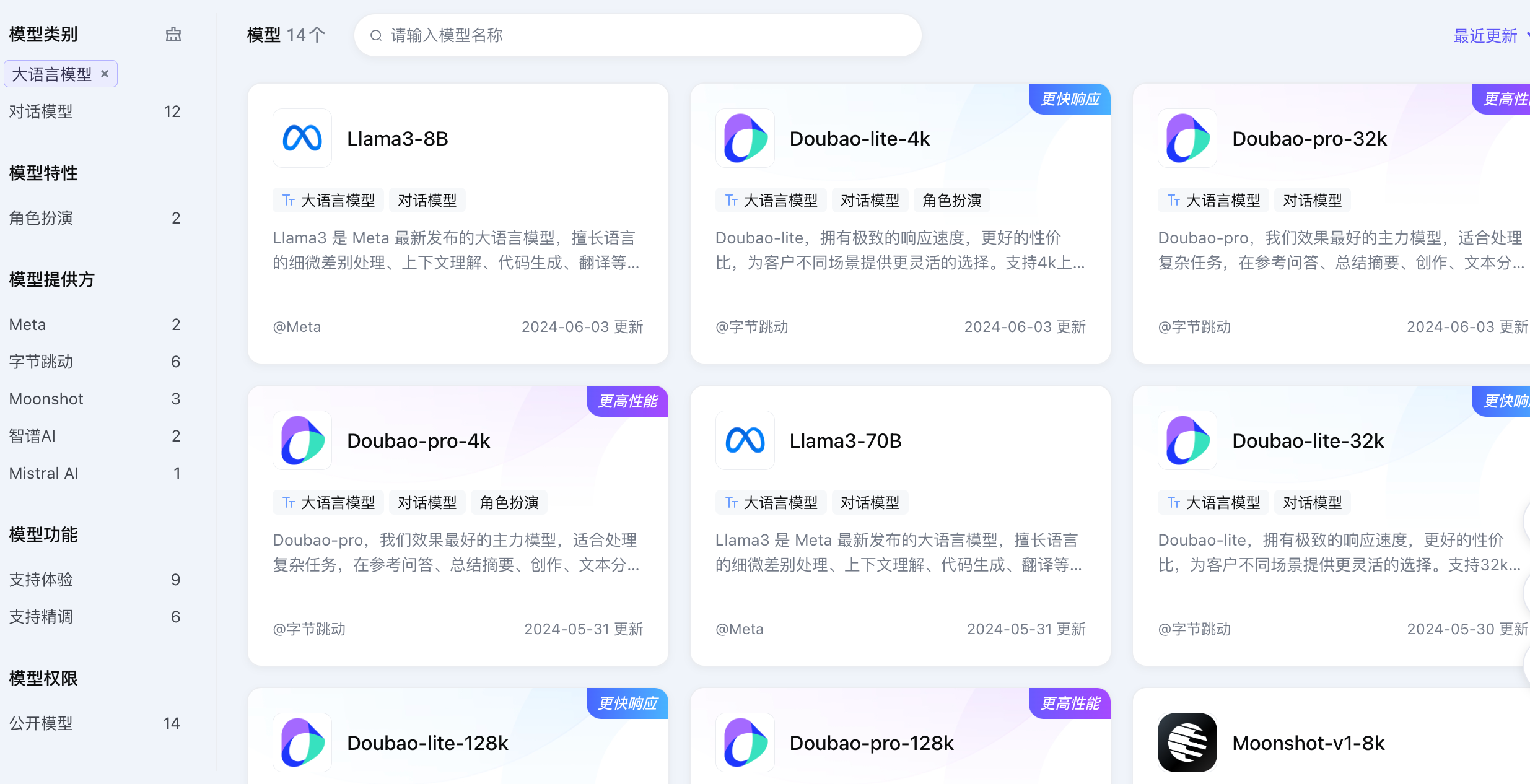
下面是它们的区别,来自官网介绍:
- Doubao-pro-4k 我们效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持 4k 上下文窗口的推理和精调。
- Doubao-pro-32k 我们效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持 32k 上下文窗口的推理和精调。
- Doubao-pro-128k 我们效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持 128k 上下文窗口的推理和精调。
- Doubao-lite-4k 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持 4k 上下文窗口的推理和精调。
- Doubao-lite-32k 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持 32k 上下文窗口的推理和精调。
- Doubao-lite-128k 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持 128k 上下文窗口的推理和精调。
挺废话的,开发者关注的模型性能和能力说明基本没有,只提到了上下文长度,不过这部分后面我会有具体的测试。
模型初体验
这里以最强的 Doubao-pro-128k 作为测试,使用 API 调用使用前,需要先创建推理接入点,需要注意的是,当前只有华北 2(北京)这一个 region 可选,对 TTFT(首 token 输出耗时)敏感的应用接入时需要特别注意
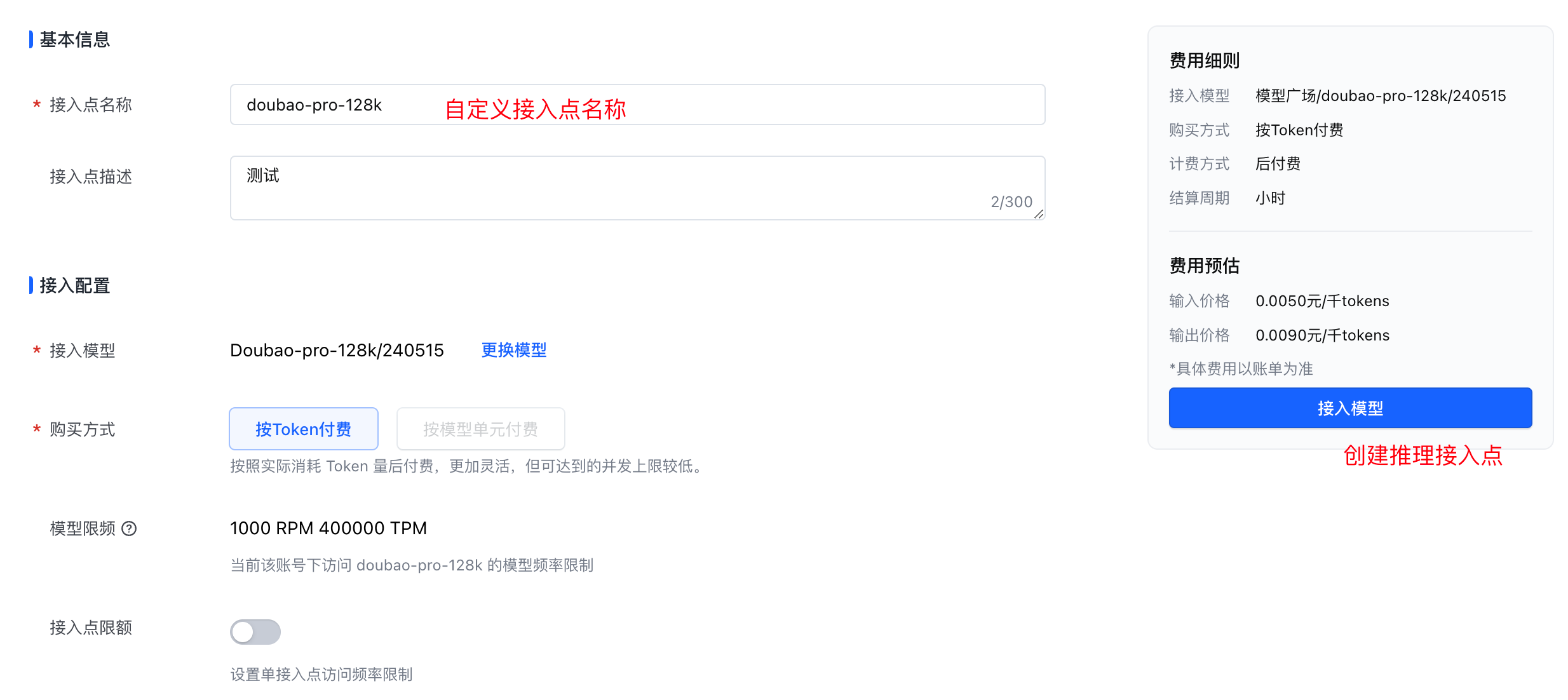
然后在模型推理的入口就可以看到我们的刚刚创建的推理点,大概 1 ~ 3s 等待状态从调度中切换为健康就可以通过 API 方式调用了。

API 调用时支持两种授权方式,一种是采用直接生成的 API Key 授权(推荐个人开发者采用),一种是火山引擎 IAM 授权(推荐企业开发者采用),我这里选用 API Key 授权方式调用:
import os
import requests
import json
# 从环境变量中获取API密钥和模型ID
api_key = os.getenv("API_KEY")
model = os.getenv("MODEL")
url = "https://ark.cn-beijing.volces.com/api/v3/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": model,
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "你好!"
}
],
"stream": False
}
response = requests.post(url, headers=headers, json=data)
result = json.loads(response.content)
print(result["choices"][0]["message"]["content"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
当然也可以选择 OpenAI 兼容的方式访问:
import os
from openai import OpenAI
# 从环境变量中获取API密钥和模型ID
api_key = os.getenv("API_KEY")
model = os.getenv("MODEL")
url = "https://ark.cn-beijing.volces.com/api/v3"
client = OpenAI(base_url=url, api_key=api_key)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好!"}
]
)
print(response.choices[0].message.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
官网也提供了官方 SDK 调用方式,默认走火山引擎 IAM 授权,且每次调用都包括一次 token 获取刷新操作,可以自行可以在这里直接生成 token(https://api.volcengine.com/api-explorer),token最长有效时间可以设置为30天,SDK版本分为 V3 和 V2 两个版本。
V3 版本目前暂且只支持 cURL(原生 HTTP 请求)和 Python SDK 方式,暂不支持 Go SDK、Java SDK 及 JS SDK 方式调用,并且 Python SDK 方式也暂不支持 Function Call 能力(文档未说明,但测试下来未生效)。
V2 版本虽然支持 Go SDK 及 Java SDK,也支持 Function Call 能力,但是接口设计极其丑陋,下面是官网 API 调用示例,大家可以自行评价。
import os
from volcengine.maas.v2 import MaasService
from volcengine.maas import MaasException, ChatRole
def test_chat(maas, endpoint_id, req):
try:
resp = maas.chat(endpoint_id, req)
print(resp)
except MaasException as e:
print(e)
if __name__ == '__main__':
maas = MaasService('maas-api.ml-platform-cn-beijing.volces.com', 'cn-beijing')
maas.set_ak(os.getenv("VOLC_ACCESSKEY"))
maas.set_sk(os.getenv("VOLC_SECRETKEY"))
req = {
"messages": [
{
"role": ChatRole.USER,
"content": "你好"
}
]
}
endpoint_id = "{YOUR_ENDPOINT_ID}"
test_chat(maas, endpoint_id, req)
test_stream_chat(maas, endpoint_id, req)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
而且 MaaS 当前不对个人开发者开放,所以 V2 版本的 SDK 基本是没法用的。
总结起来,使用官方 SDK,目前是无法使用 Function Call 能力的,所以只有曲线救国,按照 OpenAI 兼容的方式去调用了,这个我会在后面测试 Function Call 能力的部分放出来。
模型成本
豆包模型从最便宜的的 0.3 元每百万 tokens 的 lite-4k 到最贵的 9 元每百万 tokens 的 pro-128k,计费方式分为后付费和预付费方式,后付费通常限制 TPM(每分钟 token 数)和 RPM(每分钟请求数)的最高值,豆包大模型相较其他大型厂商,其后付费模式的 TPM 和 RPM 上限也非常高(见下图,当然也可以通过申请工单的方式在此基础上提额度),足以满足大多数公司的业务需求。
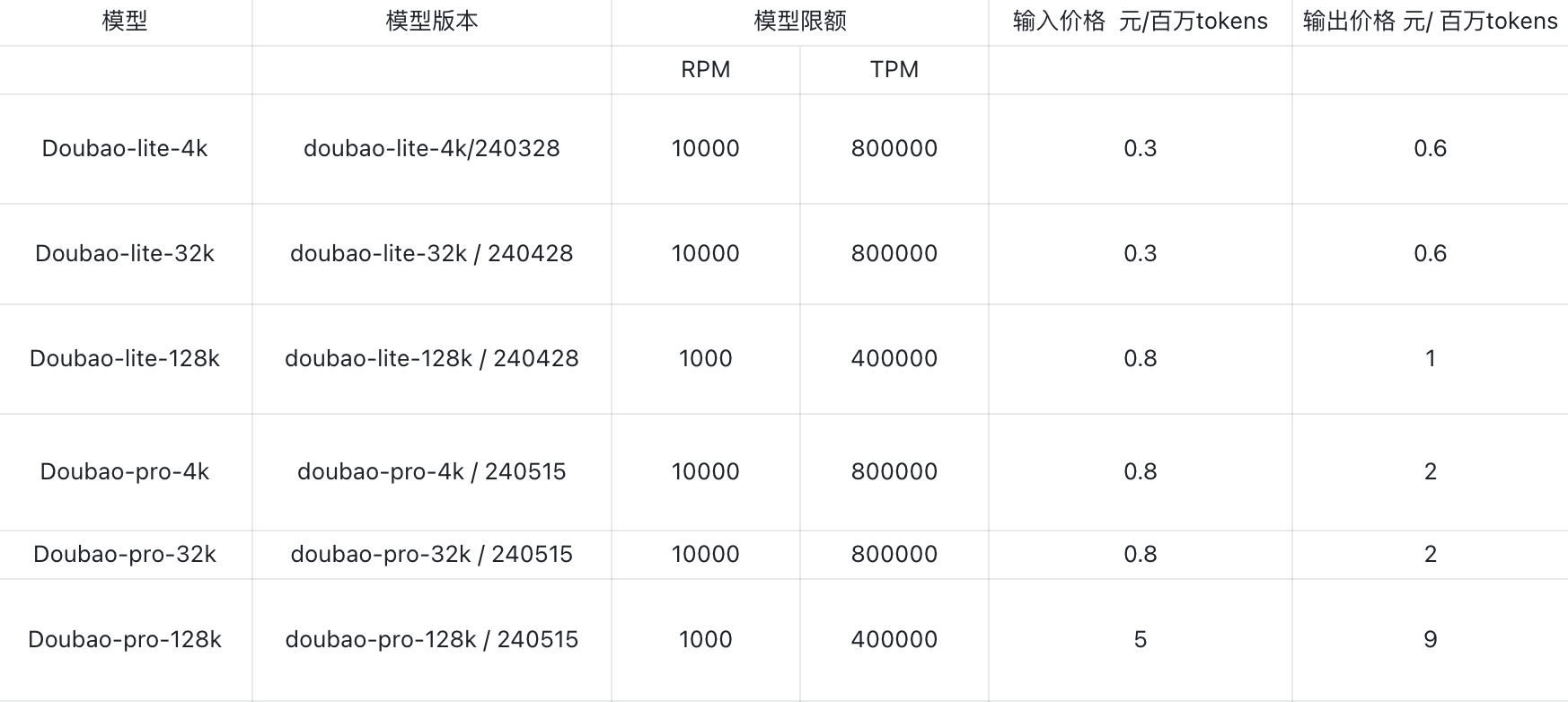
预付费模式提供更多附加服务,价格相对后付费更昂贵,但预付费通常享有大幅折扣,按行业标准打折下来大致为预付费两三倍,这种模式主要适用于少数需要高并发保障的大客户,预付费模式可以选择的有包天、包月,由于后付费方式的 API 吞吐已经能够支撑绝大多数场景,这里不再详细展开。
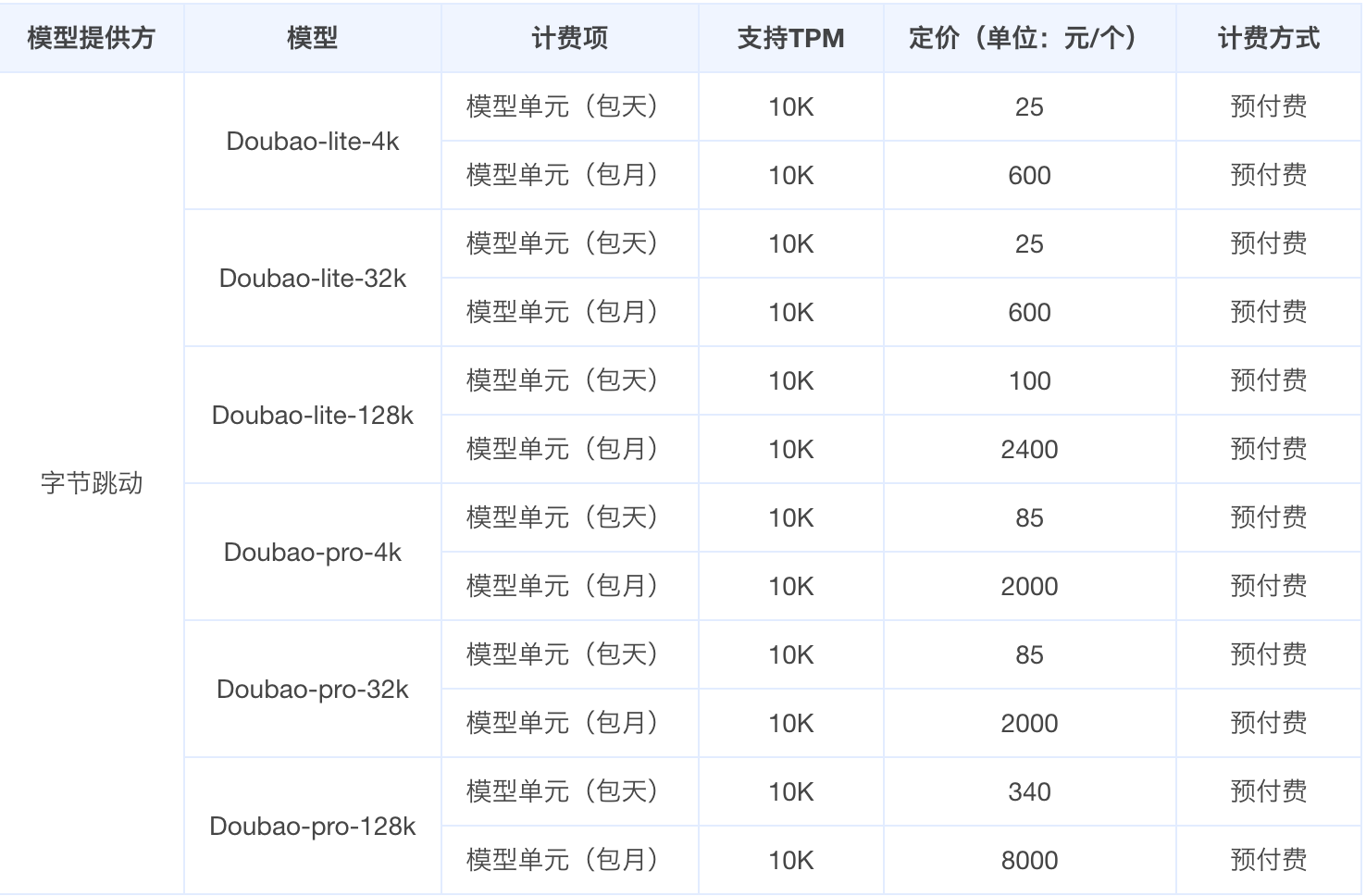
模型能力
离开模型能力谈成本那就是耍流氓,我在大模型价格战是浑水摸鱼的噱头吗?仔细分析过,否则你再便宜,如果不能用那都是营销噱头。做应用最关注的就是有效的长上下文能力(用于多轮对话记忆保持、各种阅读助手、长文本理解等常见场景)和 Function Call 能力(工具调用,构建智能体应用的基础),这两种底层能力决定 AI 应用的效果,另一个关键点就是 API 吞吐,决定了 AI 应用的体验,下面我将逐个对豆包模型这三方面进行测试。
API 吞吐
首先是 API 吞吐,明确下我的测试环境:
测试环境:请求所在地的 Region 在西南 1(成都),模型推理服务所在的 Region 在 华北 2(北京),测试时间是 2024 年 6 月 11 日 21:00,由于使用 SDK 的方式调用,每次都会刷新 API Key,有额外的耗时,所以这里选择直接生成持久 API Key(https://api.volcengine.com/api-explorer),然后构造原生HTTP请求的方式调用模型API接口,每轮测试前都会请求五次接口,下面是其中一组数据:
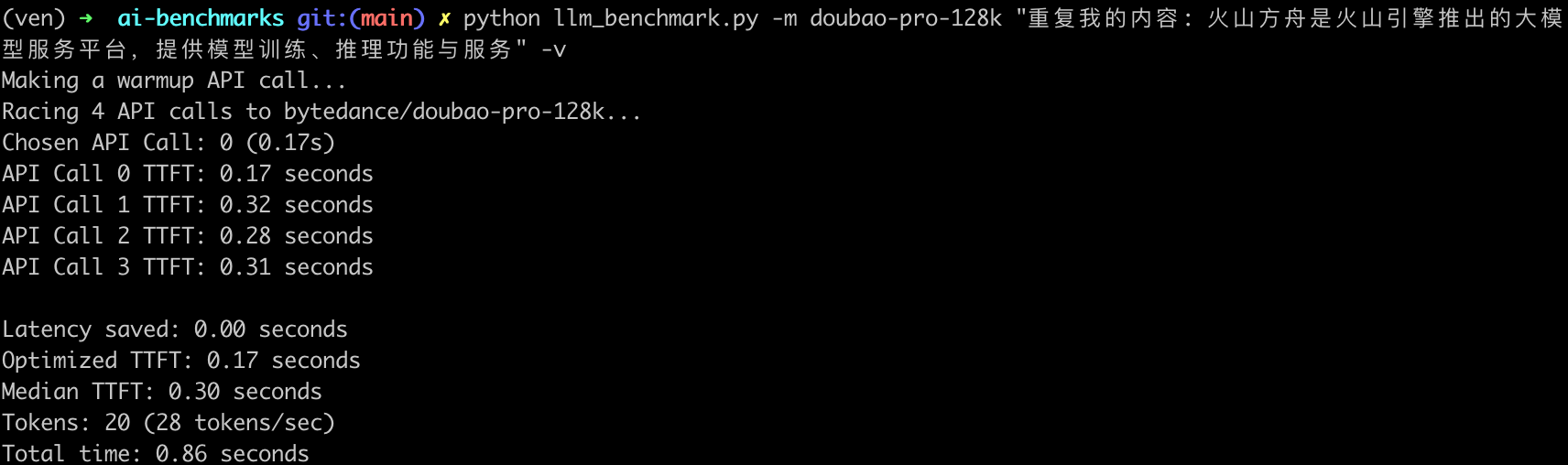
指标说明
测试时的输入提示词「重复我的内容: 火山方舟是火山引擎推出的大模型服务平台,提供模型训练、推理功能与服务」,使用豆包模型的分词器,输出 20 个 token,对应大约 34 个中文字符。
- 首次响应时间与最快响应时间差(
Latency saved 0.00s): 表示首次响应时间与最快响应时间之间的差异,这个指标可以反映出大模型 API 服务在处理请求时的波动。 - 首 token 最短耗时(
Optimized TTFT 0.17s):是指在多次请求中,最快的一次首 token 响应时间。 - 首 token 耗时中位数(
Median TTFT 0.30s):是指在所有请求中,首 token 响应时间的中位数,即一半的请求首 token 响应时间比这个值快,另一半比这个值慢。中位数可以提供一个更稳健的性能指标,因为它不受极端值的影响。 - token 总数(
Tokens: 20):表示在请求过程中生成的 token 总数。(输出 token 数被设置为 20 个,对应 34 个中文字符是日常正式对话常见句子长度) - token 生成速率(
28 tokens/sec): 表示每秒生成的 Token 数量(TPS),这是衡量大模型 API 服务处理能力的一个指标。 - 总耗时(
Total time: 0.86s): 表示从开始发送 HTTP 请求到接收到最后一个 token 的时间,这是整个请求处理过程的总耗时。总耗时声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/866621

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

