
热门标签
热门文章
- 1【Qwen2部署实战】探索Qwen2-7B:通过FastApi框架实现API的部署与调用_qwen2 api调用
- 2秋招面试题系列- - -Java 工程师(六)
- 3【SQL】索引过多的缺点_索引过多的副作用
- 4拉格朗日插值法在数据分析中的应用——Python插值scimpy,lagrange_拉格朗日插值在数据清洗的应用
- 5美的集团计算机综合面试群面,世界500强美的集团群面经验分享
- 6Python基础学习:序列数据结构(列表与元组)_python a sequence结构
- 7冒泡排序(不断将大的数字向下沉)_冒泡排序大数下沉
- 8并行CRC计算HDL代码生成工具的秘密(六字真言)_并行crc在线计算
- 9AIGC-Stable Diffusion发展及原理总结_aigc生成训练数据
- 10c++初级-2-引用
当前位置: article > 正文
多粒度在研究中的应用_多粒度学习
作者:喵喵爱编程 | 2024-07-24 05:27:02
赞
踩
多粒度学习
FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning
存在的问题
现有的字体生成方法虽然取得了令人满意的性能,但在处理复杂字和风格变化较大的字符(尤其是中文字符)时,仍会出现严重的笔画缺失、伪影、模糊、结构布局错误和风格不一致等问题,如上图4所示。
原因分析
-
大多数方法都采用基于 GAN 的框架,由于其对抗训练的性质,可能会出现训练不稳定的问题。
-
这些方法大多只通过单一尺度的高维特征来感知内容信息,而忽略了对保留源内容(尤其是复杂字符)的细粒度细节。
-
许多方法利用先验知识来帮助字体生成,例如字符的笔画或部件组成;然而,对于复杂的字符来说,获取这些细粒度信息的成本很高;
-
在过去的方法中,目标风格通常由一个简单的分类器或判别器来进行特征表示学习,这种分类器或判别器很难学习到合适的风格,在一定程度上阻碍了在风格变化较大时的风格转换。
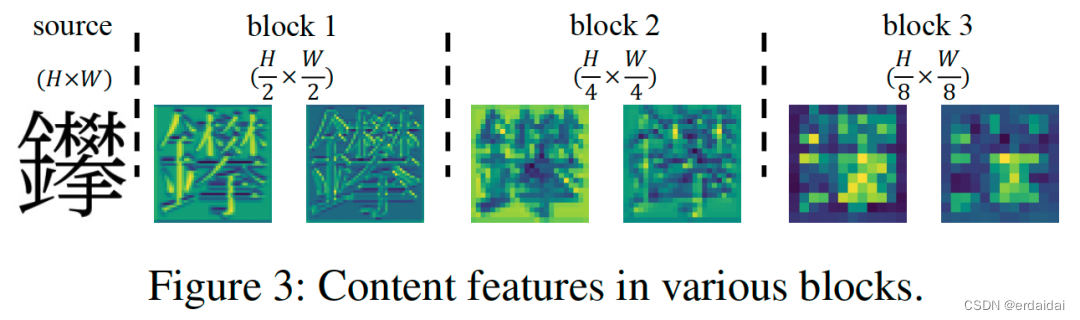
图1 在内容编码器中不同尺度的特征图
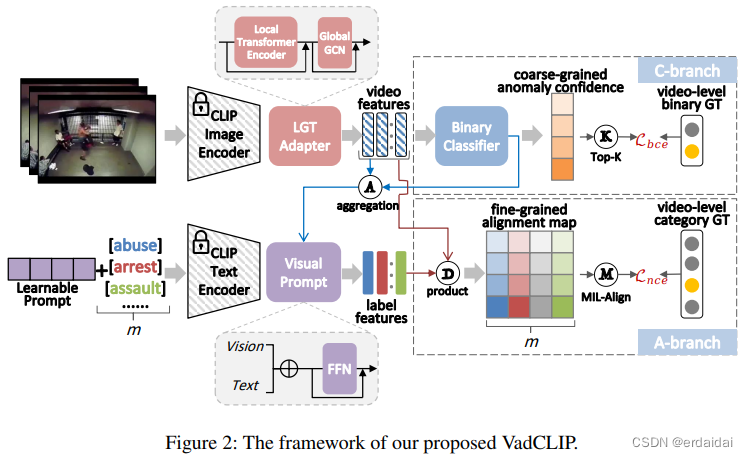
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
将视觉语言模型应用于弱监督视频异常检测
「简述:」VadCLIP是利用对比语言-图像预训练(CLIP)模型进行弱监督视频异常检测的新方法。它通过直接利用冻结的CLIP模型,无需预训练和微调,简化了模型适应过程。与现有方法不同,VadCLIP充分利用CLIP在视觉和语言之间的精细关联,采用双分支结构。一个分支进行粗粒度二分类,另一个分支则充分利用语言-图像对齐进行细粒度分析。通过双分支结构,VadCLIP实现了从CLIP到WSVAD任务的迁移学习,实现了粗粒度和细粒度的视频异常检测。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/873118
推荐阅读
相关标签

