
- 1AI基准测评(下):视频生成、代码能力、逻辑推理,AI是否已经超越人类?_王加龙 阿里云
- 2QMS-云质-质量管理软件-QMS软件-如何选择质量管理软件?_云质qms操作手册
- 3Jenkins入门——安装docker版的Jenkins & 配置mvn,jdk等 & 使用案例初步 & 遇到的问题及解决_docker jenkins jdk
- 4高质量的SQL优化技巧_sql语句csdn
- 5视觉机器学习20讲-MATLAB源码示例(1)-Kmeans聚类算法
- 6Ubuntu18 通过Anaconda安装cuda, cuDNN, pytorch
- 7机器学习算法汇总_机器学习算法总结
- 8Apache2.4 + PHP 5.5 源码编译安装_apache2.4.59编译源码安装configure: warning: *** lua 5.4
- 9Mysql的日志管理,备份与回复_mysql登录日志
- 10Faker库详解 - Python中的随机数据生成器
无缝对接私有数据源!Amazon Bedrock 知识库为 RAG 技术提供强大支持
赞
踩

本文作者 Antje Barth
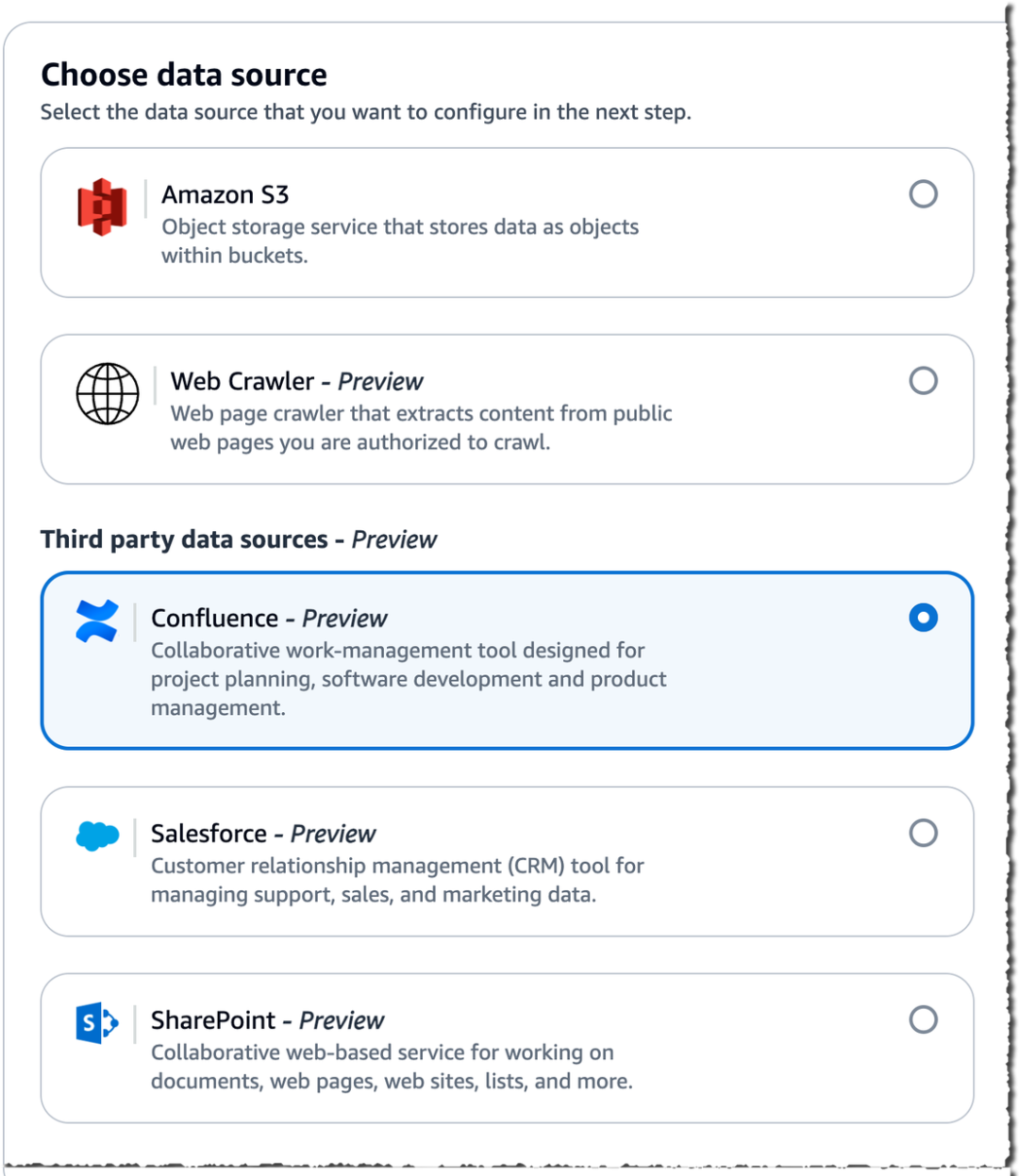
我们非常高兴地宣布,除了 Amazon Simple Storage Service(Amazon S3)之外,您现在可以将网站域名、Confluence、Salesforce、SharePoint 作为数据源直接连接到您的 RAG 应用程序(预览版)。
Amazon Bedrock 的知识库和基础模型(FM)现已实现与您企业私有数据源的无缝对接,为检索增强生成(RAG)技术提供强大支持。这一创新使得基础模型在生成回应时更加贴近用户需求,确保信息的相关性、准确性和个性化。
在过去的几个月里,我们不断扩充知识库的深度与广度,引入了多种嵌入模型、向量存储技术,并丰富了基础模型的选项,以满足不同行业和场景的需求。现在,除了 Amazon S3 之外,我们的 RAG 应用程序现支持更多类型的数据源。
使用 Amazon Bedrock 的知识库,基础模型和代理可以从企业私有数据源中检索上下文信息,用于 RAG。RAG 可帮助基础模型提供更相关、更准确和更个性化的响应。在过去几个月中,我们不断增加将模型、向量存储和基础模型嵌入知识库的选择。现在,Amazon Bedrock 知识库扩展了数据连接器(预览版)。
用于网站域名、Confluence、Salesforce 和 SharePoint 的新数据源连接器
通过将您的网站域名纳入 RAG 应用程序,您的应用将能够访问到包括公司社交媒体的更多公共数据源,这将提高对用户输入的响应的相关性、及时性和全面性。使用新的连接器,您现在可以将 Confluence、Salesforce 和 SharePoint 中现有的公司数据源添加到您的 RAG 应用程序中。
在下面的示例中,我将使用网页爬虫(Web Crawler)添加一个网站域名,并将 Confluence 作为数据源连接到知识库。同样,将 Salesforce 和 SharePoint 连接为数据源的模式与此类似。
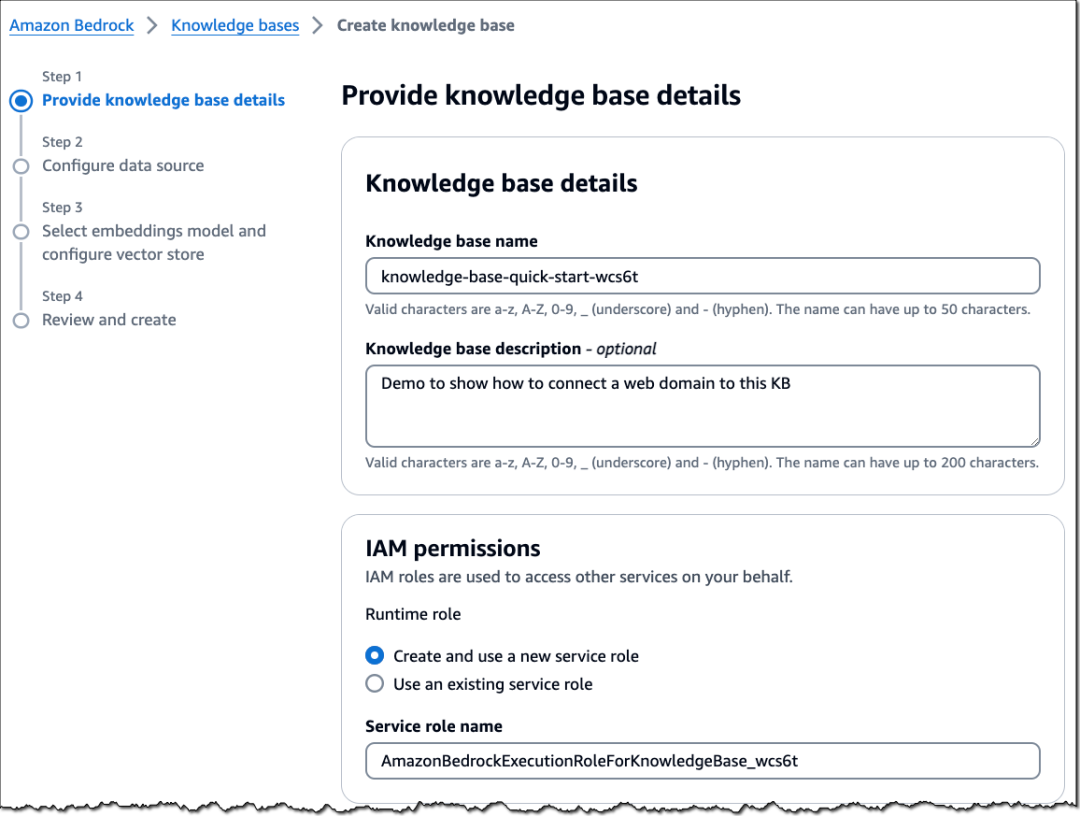
然后,选择您要使用的数据源。此处我选择的是网页爬虫(Web Crawler)。
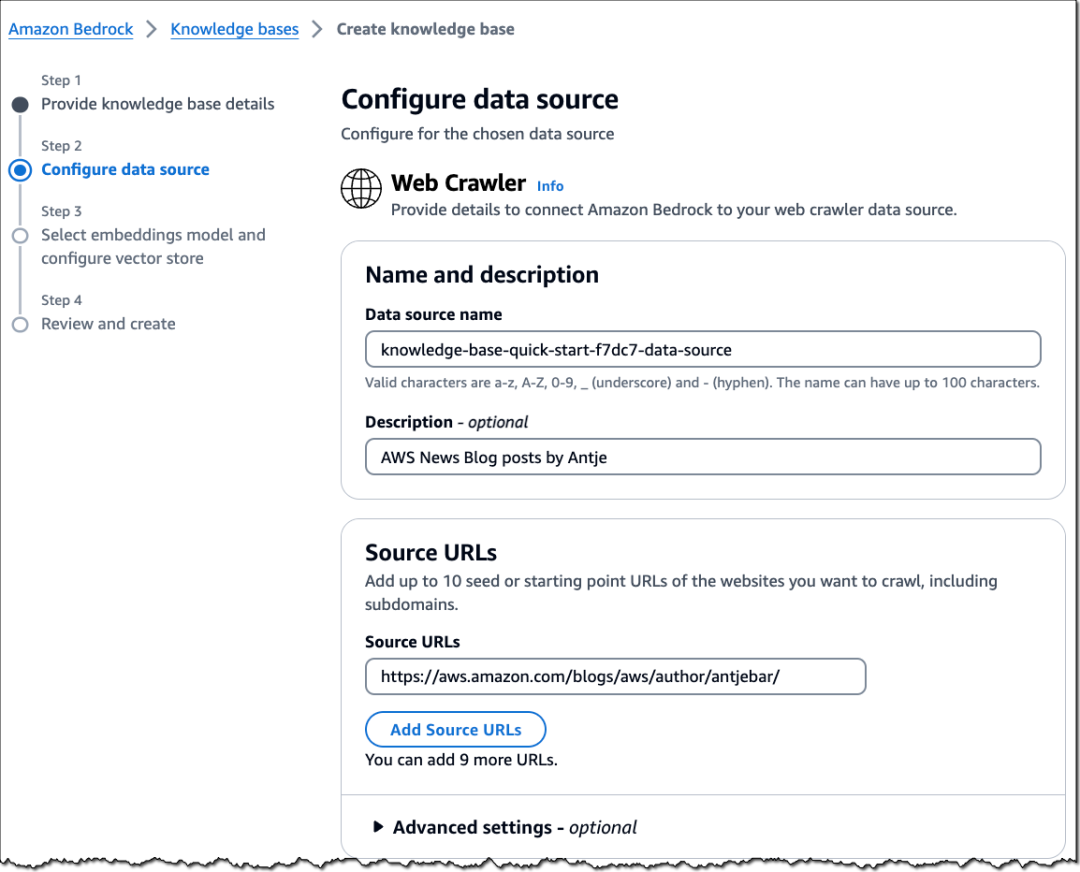
您还可以选择配置自定义加密设置和数据删除策略,以定义在删除数据源时是保留还是删除向量存储数据。我保留了默认的高级设置。
在同步范围部分,您可以配置要使用的同步域级别、每分钟要抓取的最大 URL 数量,以及包含或排除某些 URL 的正则表达式模式。
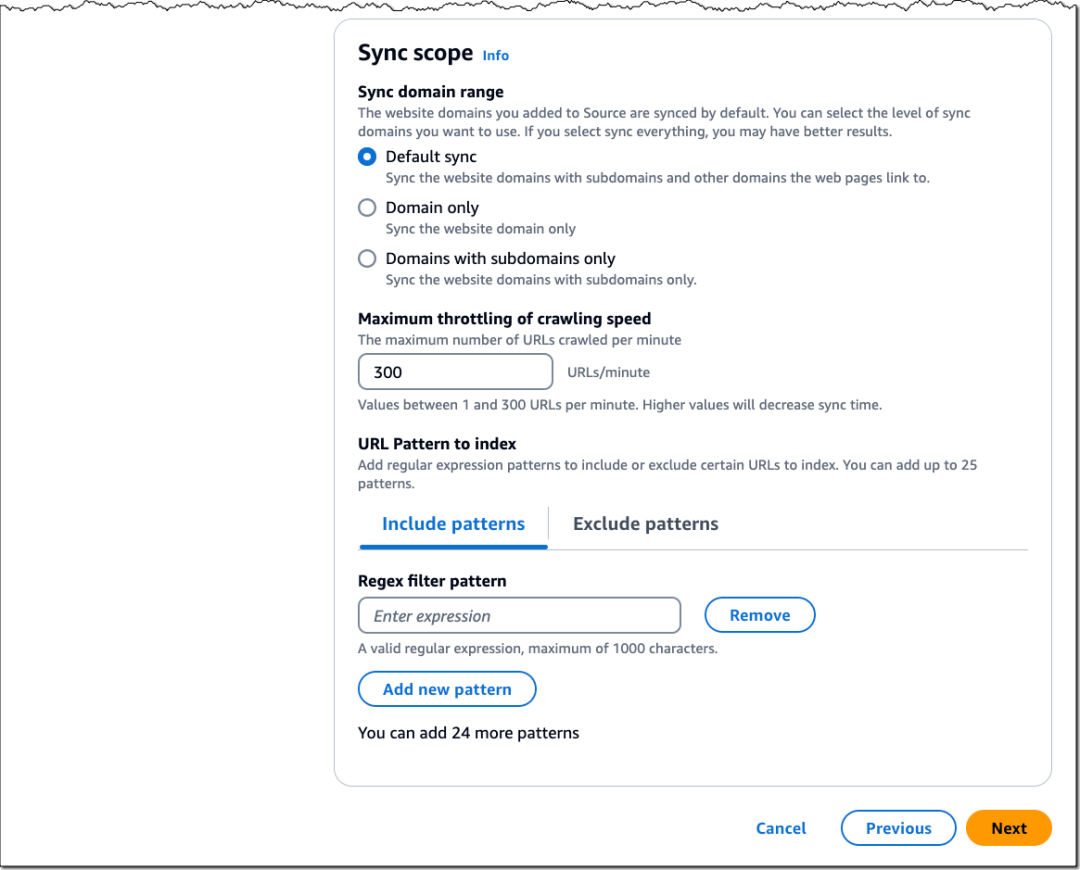
完成网页爬虫数据源配置后,通过选择嵌入模型并配置所选的向量存储来完成知识库设置。创建后,您可以检查知识库详情以监控数据源同步状态。同步完成后,您可以测试知识库,并查看带有网页 URL 引用的基础模型响应。
如果您想以编程方式创建数据源,您可以使用亚马逊云科技命令行界面(Amazon CLI)或 Amazon SDK。相关代码示例请查看 Amazon Bedrock 用户指南。

相关代码
扫码了解更多
将 Confluence 连接为数据源
现在,我们在知识库设置中选择 Confluence 作为数据源。
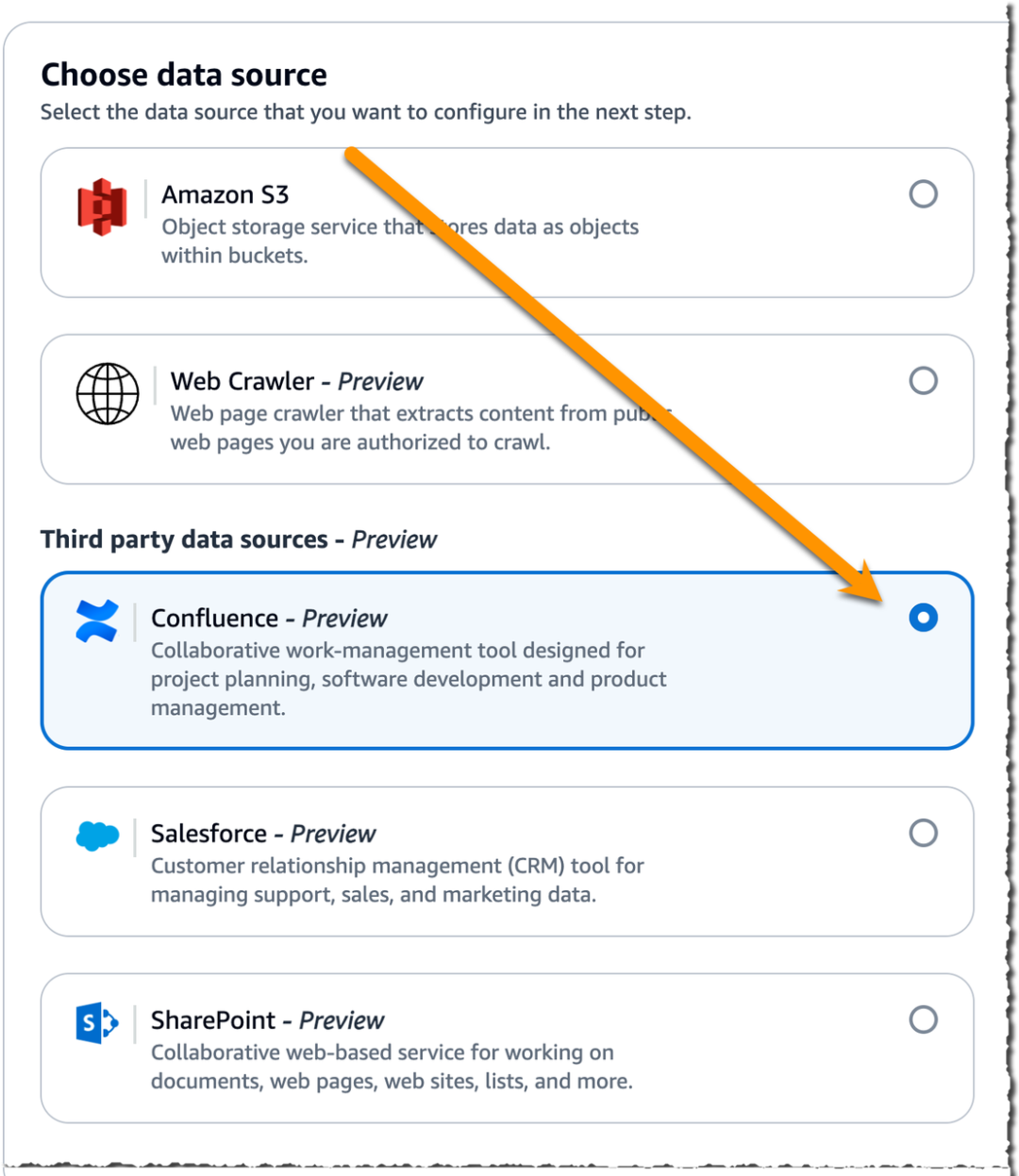
要将 Confluence 配置为数据源,我需要再次为数据源提供名称和描述,选择托管方式,并输入 Confluence URL。
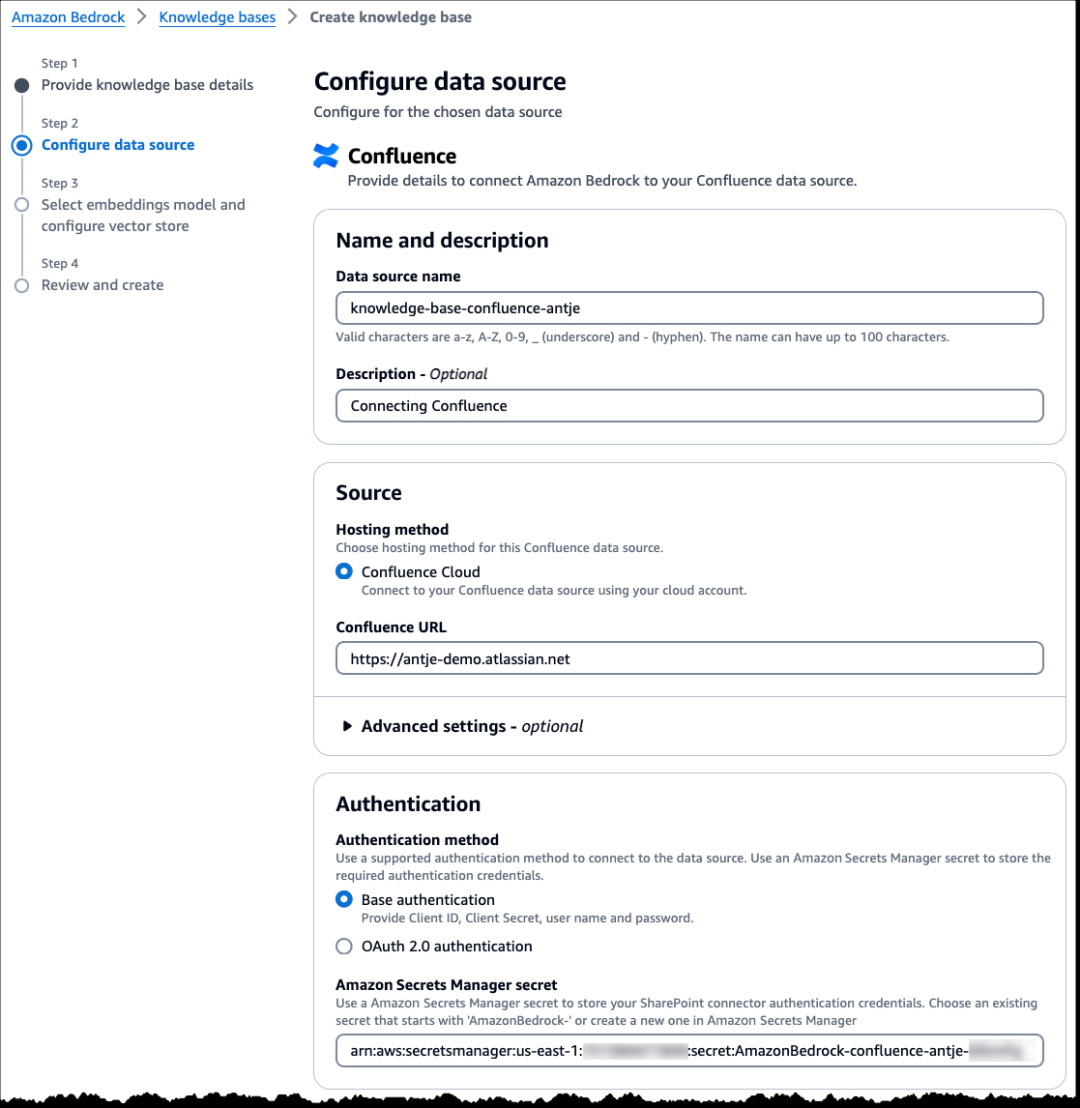
要连接到 Confluence,您可以选择基本身份验证或 OAuth 2.0 身份验证。在此演示中,我选择基本身份验证,它需要用户名(您的 Confluence 用户帐户电子邮件地址)和密码(Confluence API token)。我将相关凭据存储在 Amazon Secrets Manager 中,并选择该密文。
注意:确保秘密名称以“AmazonBedrock-”开头,并且您为知识库的 IAM 服务角色在 Secrets Manager 中具有访问此秘密的权限。

Amazon Secrets
Manager
扫码了解更多
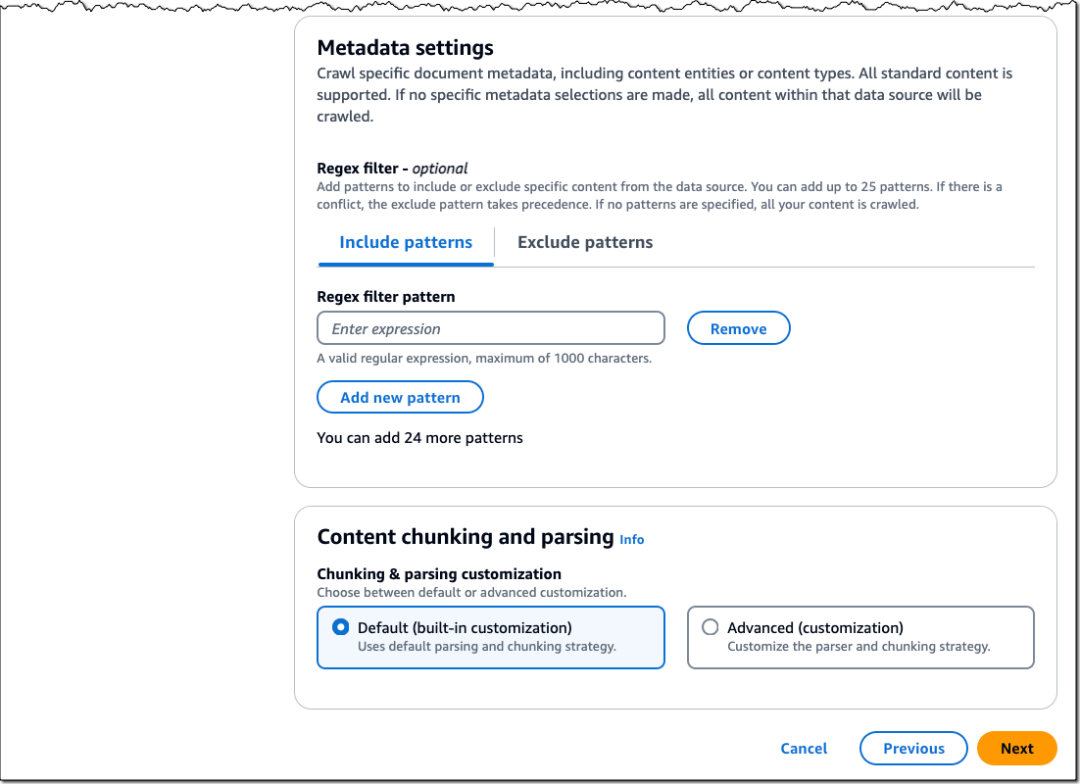
在元数据设置中,您可以使用正则表达式的包含和排除模式来控制要爬取的内容范围,并配置内容分块和解析策略。
完成 Confluence 数据源配置后,通过选择嵌入模型并配置所选的向量存储来完成知识库设置。
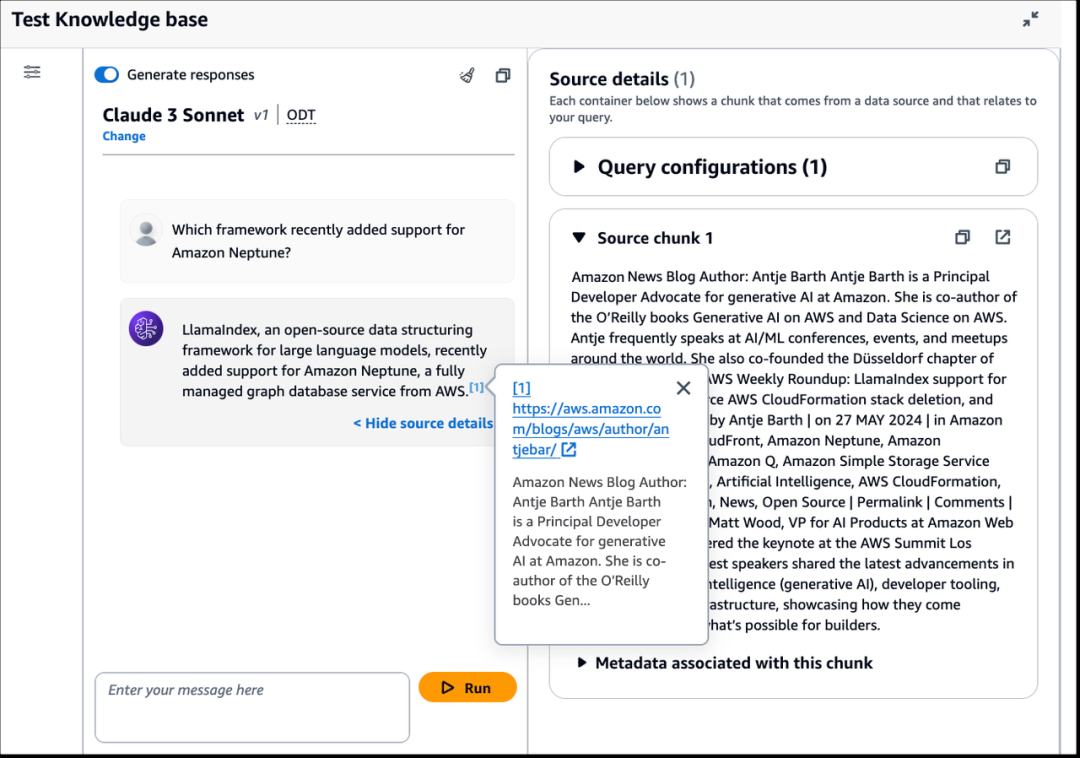
创建后,您可以检查知识库的详细信息,以监控数据源同步状态。同步完成后,就可以测试知识库了。在这个演示中,我在 Confluence 空间中添加了一些虚构的会议记录。让我们来了解其中一次会议的行动项目!
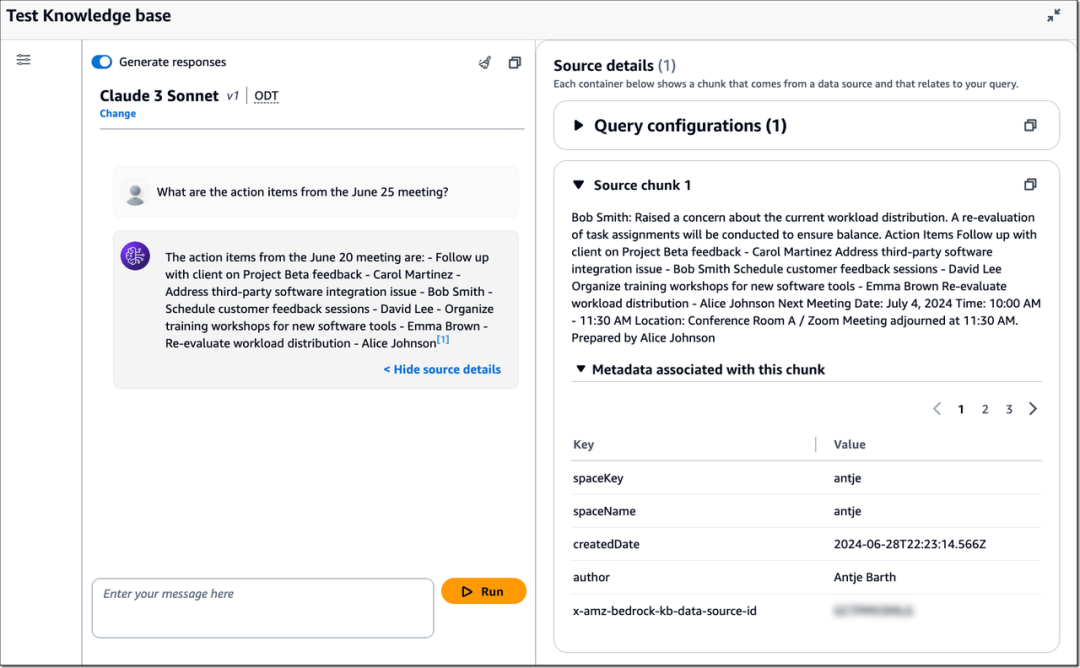
关于如何将 Salesforce 和 SharePoint 连接为数据源的说明,请查看 Amazon Bedrock 用户指南。

Amazon Bedrock 用户指南
扫码了解更多
注意事项
包含和排除过滤器 - 所有数据源都支持包含和排除过滤器,因此您可以对从给定源爬取的数据进行精细控制。
网页爬虫 - 请记住,您必须只在自己的网页或有权限爬网的网页上使用网页爬虫。
立即上手体验

本篇作者

Antje Barth
亚马逊云科技生成式 AI 的首席开发推广师。她是 O 'Reilly 的书籍《亚马逊云科技的生成 AI》和《亚马逊云科技的数据科学》的合著者。Antje 经常在世界各地的人工智能与机器学习会议、活动中发表演讲。她还共同创立了“大数据中的女性”塞尔多夫分会。


星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
听说,点完下面4个按钮
就不会碰到bug了!

点击阅读原文查看博客,获得更详细内容

