
- 1Autodesk AutoCAD 2025 for Mac:强大的二维三维绘图与设计工具_solid works2025
- 2Spring Boot项目实现调用腾讯云进行人脸识别
- 3如何快速学习CADD计算机辅助药物设计_药学caad如何自学
- 4MySQL 8.0 全新特性详解_mysql8.0新特性
- 5STM32F407之数字滤波_基于stm32f407的数字滤波算法,方波滤正弦波算法的设计思想
- 6最长公共子序列--LCS(dp入门)_lcs dp
- 72024年AI前20岗位薪酬出炉!搞AI大模型的远超同行?_ai什么岗位工资高
- 8使用Micronaut构建高性能微服务_micronaut consul
- 9stable diffusion AI绘图工具的安装和使用centos7.8系统_centos8 stabble diffsion
- 10力扣刷题C语言——14. 最长公共前缀_力扣 c语言 最长公共前缀
风暴眼中的ChatGPT,看NLPer怎么说?_chatgpt强大的nlu能力来源
赞
踩
当前科技领域最有热度的话题,无疑是OpenAI 新提出的大规模对话语言模型ChatGPT,一经发布上线,短短五天就吸引了百万用户,仅一个多月的时间月活已然破亿,并且热度一直在持续发酵,各行各业的从业人员、企业机构都开始体验关注甚至自研“类ChatGPT”模型。这里,笔者从一位NLP从业人员的角度谈一谈对ChatGPT的一些看法和思考。
1 ChatGPT诞生之路
1.1 BERT
2018年,谷歌提出BERT(Bidirectional Encoder Representation from Transformer)模型,一时之间疯狂屠榜,在各种自然语言处理领域建模任务中取得了最佳的成绩,NLP自此进入了大规模预训练语言模型(Large Language Model,LLM) 时代。
BERT做了一件什么样的事情呢,我们通过以下例子做个说明:_____和阿里、腾讯并称为中国互联网 BAT 三巨头。上述空格应该填什么呢?有的人说“百度”,有的人回答“字节”……不论填什么,都表明,空格处应该填写的信息是受到上下文决定和影响的。BERT所做的事就是从大规模的文本语料中,随机地MASK掉一部分字词,形成如同示例的完形填空,然后不断地学习空格处到底该填写什么。通过这种形式不断的迭代训练,并结合其它语言学任务优化微调模型,从而让BERT模型可以关注到文本语料的上下文信息。所谓语言模型,就是从大量的数据中学习复杂的上下文联系。
1.2 GPT
2018年6月,OpenAI 早于 BERT发布了一个GPT 模型,大致思想是一样的,都是基于 Transformer 编码器,获取文本内部的上下文联系。在语言模型中,编码器和解码器都是由一个个的 Transformer 组件拼接堆叠在一起形成的。BERT使用了Transformer的Encoder编码器部分进行模型训练,更适合语义理解相关任务,GPT使用了 Decoder 部分进行模型训练,更适合文本生成相关任务。

图注:Transformer编码器 Encoder-Decoder结构
1.3 GPT-2
自从 BERT炸街后,各种变体改进模型越来越多,比如 ALBERT、ROBERTA、ERNIE,BART、XLNET、T5 等等。最初,预训练任务仅仅是一个完形填空任务就可以让模型有了极大进步,那么,如果给 LLM 模型更多语言题型,应该可能会对模型训练有更大的帮助。于是。句子乱序、多项选择、判断、改错等任务题型纷纷被构建并塞到BERT模型预训练阶段,各种任务数据集如机器翻译、文本摘要、问答理解等全部添加进去提升训练阶段的复杂度和预期效果。GPT-2 就是在 GPT模型的基础上,添加了多任务学习,同时扩增了数据量和模型结构参数,进行更深的训练迭代。其整体测试效果如下:
图注:GPT-2论文实验效果图
1.4 GPT-3
GPT-3 模型所采用的数据量达到45TB,模型参数量达到1750亿,模型训练学习和计算复杂度远超以往所有模型,上一代GPT2模型参数量仅有15亿,用了40G训练数据。GPT-3的大模型计算量是 BERT的上千倍,如此巨大的模型造就了 GPT-3 在许多困难的 NLP 任务,如撰写复杂逻辑的文章,编写SQL查询语句、Python或JS代码上都有更优异的表现。
一般预训练模型的使用都是两段式的,先用大规模数据集对模型进行预训练,再利用下游任务标注数据集进行 Finetune,这也是绝大多数 NLP 模型任务的基本工作流程。GPT-3 开始颠覆了这种认知,提出了一种 in-context 学习方式,举个例子:
用户输入到 GPT-3:你觉得 Jieba是个好用的工具吗?GPT-3输出1:我觉得很好啊。GPT-3输出2:Jieba是什么东西?GPT-3输出3:你饿不饿,我给你做碗面吃……GPT-3输出4:Do you think jieba is a good tool?
对于不同的任务场景,GPT-3模型输出不同的答案更符合预期。in-context 学习方式正是对此添加了情境引导:如用户输入到GPT3:“请把以下中文翻译成英文:你觉得 Jieba是个好用的工具吗?”显而易见,GPT3模型可以针对性的回答输出4是最优答案。整个学习机制类似于前不久比较火爆的Prompt-Learning,使得GPT-3模型异常强大。
1.5 ChatGPT
GPT系列模型都是采用Transformer模型结构的 Decoder部分进行训练的,更加适合文本生成任务。即输入一句话,输出也是一句话的形式,可以称之为对话模式。这引出了本文的主角ChatGPT,一种优化的大规模对话语言模型,新一代GPT-3.5。ChatGPT 模型结构上和之前的 GPT-3模型没有太大变化,最主要变化的是训练策略变了,引入了强化学习(Reinforcement Learning, RL)进行模型训练,添加合理的奖励机制让模型能更好的理解和适应各种场景。

2017年,AlphaGo围棋博弈击败了柯洁,引起了一波新的人工智能浪潮和思考,强化学习如果在适合的条件下,完全有可能打败人类,不断的成长,逼近极限完美的状态。强化学习是一种新的学习机制,就像生物进化一样,模型在给定的环境场景中,不断地根据环境的惩罚和奖励(reward),拟合到一个最适应环境的状态。AlphaGo就是一个典型的成功示例。同时这也引发了新的思考,NLP + RL,可以做吗?怎么做?很多人可能都会觉得不太合适,自然语言处理所依赖、所研究的环境,是整个现实世界,是一个通用场景,这使得无法设计反馈惩罚和奖励函数能够很好的与之相匹配。除非人们一点点地人工反馈,或者把研究目标场景限定在某一个垂直限定领域。OpenAI 提出的 ChatGPT 把这件事实现了,他们雇用40个外包,进行人工标注反馈和奖励,参与模型的迭代训练,这种带人工操作的 reward机制,被称之为 RLHF(Reinforcement Learning from Human Feedback)。整体操作过程如下:
(1)搜集说明数据(prompt训练方式,引入人工),训练监督策略;
(2)搜集比较数据(引入人工排序),训练奖励模型机制;
(3)搜集说明数据(新的prompt抽样),使用PPO强化学习优化迭代模型;经过不断的训练、学习、迭代反馈,ChatGPT模型不断优化提升并最终呱呱落地,开启对外公众测试,成功赢得了全球相关科研及从业人员的掌声,诸多企业及研究机构开始投入自己的“ChatGPT模型”研究。
2 ChatGPT 引发思考
ChatGPT使用了Transformer神经网络架构,即GPT-3.5架构,拥有语言理解和文本生成能力,尤其是它会通过连接大量的语料库来训练模型,这些语料库包含了真实世界中的对话,使得ChatGPT具备上知天文下知地理,还能根据聊天的上下文进行互动的能力,做到与真正人类几乎无异的聊天场景进行交流。ChatGPT不单是聊天机器人,还能进行撰写邮件、视频脚本、文案、翻译、代码等NLP领域建模任务。
- 理解乱序文本(语言模型)
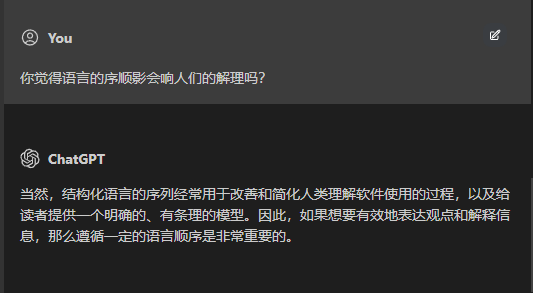
- 信息抽取
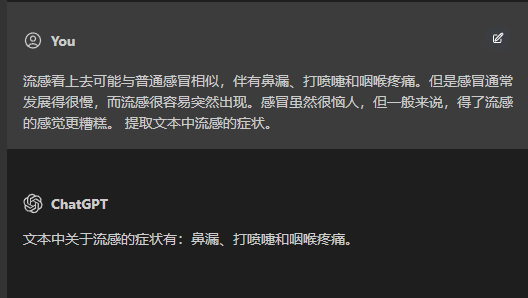
- 问答理解
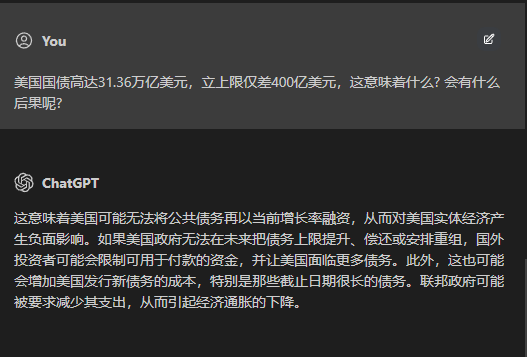
- 做高数题(文本理解)

- 写文章(文本生成)

ChatGPT 预训练语言模型集自然语言理解(NLU)、自然语言生成(NLG)于一身,它的影响在 NLP 领域可以划分为三个层级:
(1)语言理解:ChatGPT 模型的 NLU 能力是通过对大规模数据集的训练来构建的,拥有非常强大的解释力和语义理解能力;
(2)技术整合:ChatGPT 不仅可以应用在 NLU 领域,还能够跟其他领域的技术整合,如机器视觉、机器翻译等等,以实现多种场景模态沟通融合;
(3)对话管理:ChatGPT 能够有效的模拟真实对话场景,可以实现自然的语句转换和上下文恢复,能够更准确的回答用户的查询和了解用户的意图。
传统 NLP 技术依赖于大量数据集和算法,这意味着技术的设计实现,需要开发者们耗费大量的时间和精力来整理和准备数据,以便计算出有效的输出结果。ChatGPT模型为用户提供了一种全新的方式,该方式可以在更短时间内生成出更具有代表性的结果,这对于 NLP 迅速应用落地和迭代具有重要作用。ChatGPT 还可以很好地处理大量未标记的数据,从而极大地提升了 NLP 技术的灵活性和可扩展性。同时,ChatGPT 模型可以弥补 NLP 技术在语义理解准确率上的不足,以更精准的方式处理复杂问题,从而使机器学习更加准确和全面。
此外,ChatGPT 的出现会给安全问题带来巨大挑战,ChatGPT 技术的准确性和先进性可能会威胁到一些有关网络和数据安全领域的要求,鉴于其高准确率,ChatGPT 可能会更容易被滥用。例如,ChatGPT 技术可能受到不法分子的滥用,从而加强他们利用自然语言处理进行入侵和盗取信息的行为,并带来许多安全风险,以及使用 ChatGPT 引发的文本识别隐私可能性等等。特斯拉CEO马斯克也感叹:“我们可能离强大到危险的人工智能不远了”。
虽然ChatGPT模型可能会带来一定程度的安全问题隐患,它对安全领域发展的推动和促进作用有着更重要的意义。以ChatGPT模型在数据安全领域的应用为例,我们来考虑一个敏感关键信息识别的任务,当模型可以在任意场景下准确的识别出敏感信息数据,我们就可以更有效的保护重要数据避免意外泄露,造成用户潜在损失。ChatGPT模型在这里会有怎么样的效果呢?考虑到它的RLHF训练学习奖惩机制,我们可以通过不断的投喂数据进行迭代反馈,告知模型哪些属于敏感信息,哪些文本数据非敏感,ChatGPT会逐渐的学会对敏感文本信息的识别和判定,甚至对于新的场景和类型文本也会拥有挖掘定义及识别敏感信息的能力。接下来,敏感信息识别的问题就转化为了数据问题,这似乎是一个可行的解决思路?
无可厚非,ChatGPT模型目前针对明确的任务及问题,很多时候会给出甚至比人类更专业、更合理的答案,远超预期,可能给我们的工作和生活会带来诸多便利;但是它有时候也会写出看起来似是而非的答案,可能会出现一些重复的词句,无法分清楚事实等等,其创新性和创造性也有待更精细的考验。同时,ChatGPT模型带来的风险和诸多问题也是我们不容忽视的着力点,甚至已经在我们的日常社会生活中产生了一些不好的影响,如果你有关注相关新闻消息的话。当然,未来的ChatGPT肯定会更加强大。数据+算力+算法,当所有的条件都水到渠成,ChatGPT模型可以走多远呢,我们可以把它交给时间来见证。

