
热门标签
热门文章
- 106|LangChain | 从入门到实战 -六大组件之Agent_langchain agent
- 2来自麻省理工的信息抽取
- 3软件测试基础理论_软件测试理论
- 4【Centos7下Qemu+KVM搭建虚拟机环境】_centos qemu 搭建虚拟机
- 5关于问答系统(Q&A)、对话系统(Chatbot)的学与思_q&a系统
- 6深入理解Symbol之用法及其应用场景探索_symbol标签
- 7高数-第一章-函数-极限 连续_0的多少次方等于无穷小
- 8数据结构 —— 八大排序(超详细图解 & 函数实现)_数据结构排序
- 9RuntimeError: CUDA error: no kernel image is available for execution on the device_[rank0]: runtimeerror: triton error [cuda]: device
- 10JavaScript青少年简明教程:开发工具与运行环境_javascript少儿编程 工具
当前位置: article > 正文
23.10 Django 事务的使用
作者:喵喵爱编程 | 2024-08-12 00:37:54
赞
踩
23.10 Django 事务的使用
1. 事务
事务(Transaction): 是一种将多个数据库操作组合成一个单一工作单元的机制.
如果事务中的所有操作都成功完成, 则这些更改将永久保存到数据库中.
如果事务中的某个操作失败, 则整个事务将回滚到事务开始前的状态, 所有的更改都不会被保存到数据库中.
这对于保持数据的一致性和完整性非常重要.
- 1
- 2
- 3
- 4
1.1 事务级别
事务的隔离级别是为了解决多个事务并发执行时可能出现的问题, 如脏读, 不可重复读和幻读等. 这些问题是由于不同事务之间的数据访问和修改操作未能正确隔离而产生的. 事务隔离级别的分类: * 1. Read Uncommitted(读未提交): 这是最低的隔离级别. 在这个级别下, 一个事务可以读取到另一个事务未提交的数据, 这可能导致脏读. 适用于对数据一致性要求不高, 但需要高并发的场景, 如某些购票系统. * 2. Read Committed(读已提交). 保证了事务只能读取到已经提交的数据, 从而避免了脏读的问题. 但是, 在同一个事务内, 多次读取同一数据集合时, 可能会因为其他事务的插入或删除操作而导致前后读取的结果不一致, 即不可重复读. 适用于银行转账等对数据一致性要求较高的场景. * 3. Repeatable Read(可重复读). 保证了在同一个事务内多次读取同一数据集合的结果是一致的, 避免了不可重复读的问题. 但是, 它无法完全避免幻读, 即当某个事务读取一个范围内的记录时, 另一个事务在该范围内插入了新的记录, 当原事务再次读取该范围时, 会发现新的'幻影'记录. 这是MySQL数据库的默认事务隔离级别. * 4. Serializable(可串行化): 这是最高的隔离级别. 它通过强制事务串行执行, 即一个事务执行完毕后, 其他事务才能开始执行, 从而避免了脏读, 不可重复读和幻读的问题. 但是, 这种隔离级别会严重影响数据库的并发性能, 因此在实际应用中很少使用.

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
MySQL的默认事务隔离级别取决于存储引擎.
对于最常用的InnoDB存储引擎, 默认的隔离级别是REPEATABLE READ.
这意味着在一个事务内, 多次读取同一个记录的结果是一致的, 并且该事务不会被其他事务的插入或更新操作所干扰, 直到事务提交或回滚.
但需要注意的是, 幻读(Phantom Reads)在REPEATABLE READ隔离级别下是可能发生的,
尽管InnoDB通过多版本并发控制(MVCC)和Next-Key Locks等技术减少了幻读的可能性.
SQLite的默认事务隔离级别是SERIALIZABLE,
但实际上, SQLite通过一种叫做Deferred Deferred Conflict Resolution(延迟冲突解决)的机制来实现.
SQLite尝试在每个事务开始时锁定尽可能少的资源, 并在需要时解决冲突(例如, 通过回滚一个事务).
然而, 从SQL标准的角度来看, SQLite的行为被归类为SERIALIZABLE,
因为它保证了事务的串行化执行, 即事务之间的操作是严格顺序的, 避免了脏读, 不可重复读和幻读.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.2 自动提交事务
大多数数据库系统默认处于自动提交模式下,
这意味着每个单独的数据库操作(如: INSERT, UPDATE, DELETE)都会立即被提交到数据库, 成为永久更改.
在这种模式下, 不需要显式地开始和提交事务, 因为每个操作都被视为一个独立的事务.
自增ID与回滚:
当事务中包含插入操作, 并且这些插入操作分配了自增ID, 如果事务被回滚, 则这些已分配的自增ID会被撤销, 它们会'重置'回之前的值.
这意味着, 事务回滚, 数据库的自增计数器(或称为序列)也会回退到之前的状态.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Django默认情况下会开启事务, 但这里的'开启事务'指的是Django在模型(Model)层面对数据库操作的自动管理.
Django的默认事务行为是自动提交(autocommit)模式, 即每当执行数据库写操作(如save(), delete()等)时,
Django会自动将这些操作提交到数据库, 这与很多数据库默认的自动提交事务设置相似.
这意味着, 如果在一个视图中执行了: MyModel.objects.create(name='object 1'), 那么这条记录会立即被写入数据库,
并且不会因为这个视图中的后续操作失败而自动回滚.
- 1
- 2
- 3
- 4
- 5
- 6
以下是一个完整的示例, 展示了Django ORM操作数据库的默认行为:
- 1
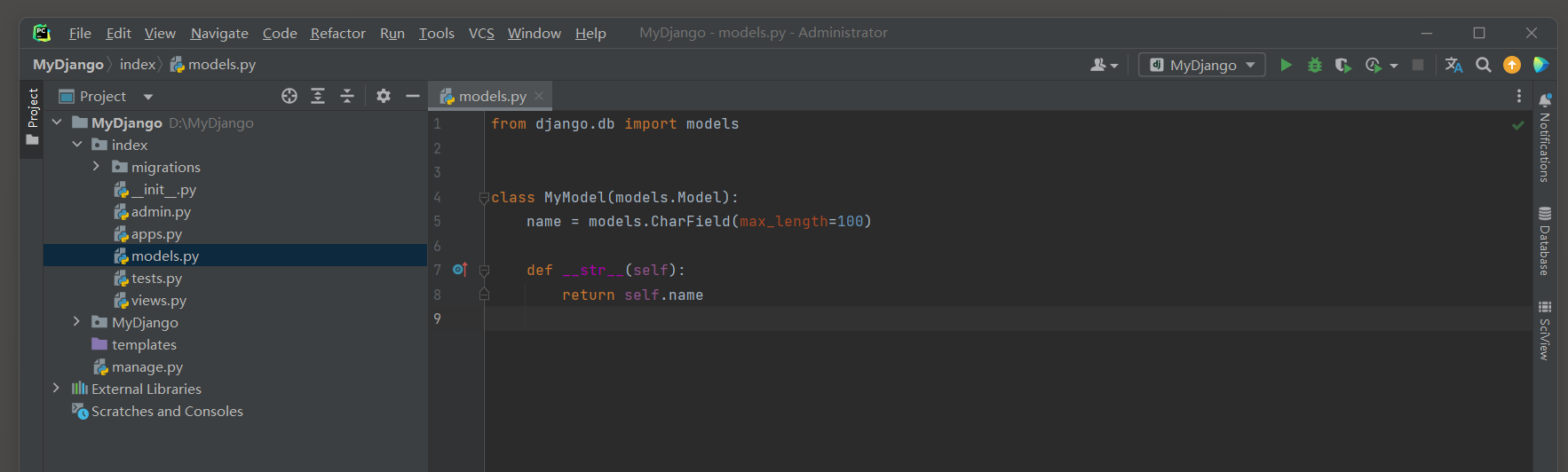
* 1. 在的Django应用的models.py文件中定义一个简单的模型.
- 1
# index/models.py
from django.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100)
def __str__(self):
return self.name
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
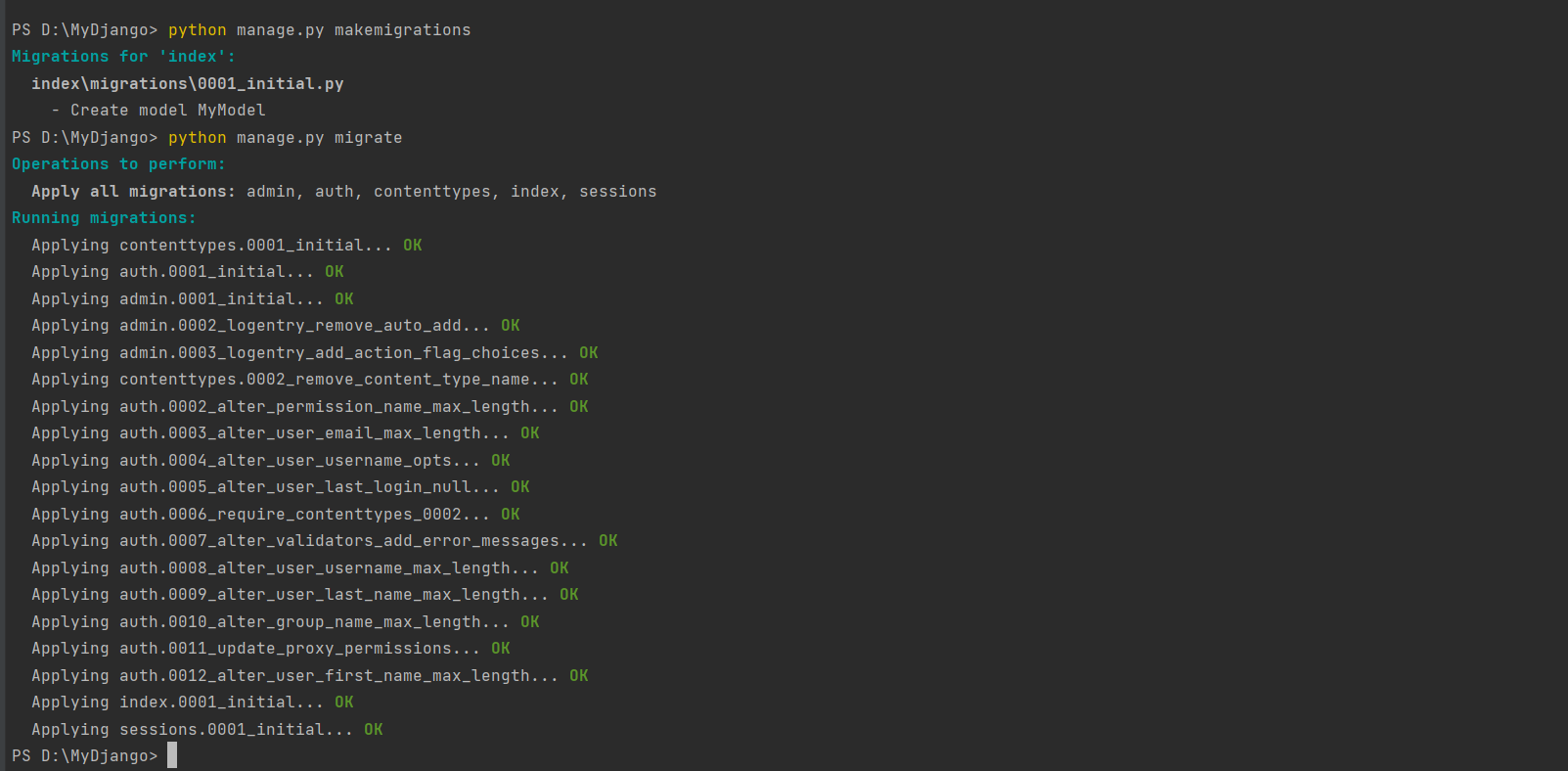
* 2. 运行: python manage.py makemigrations 和 python manage.py migrate 来创建数据库表.
- 1
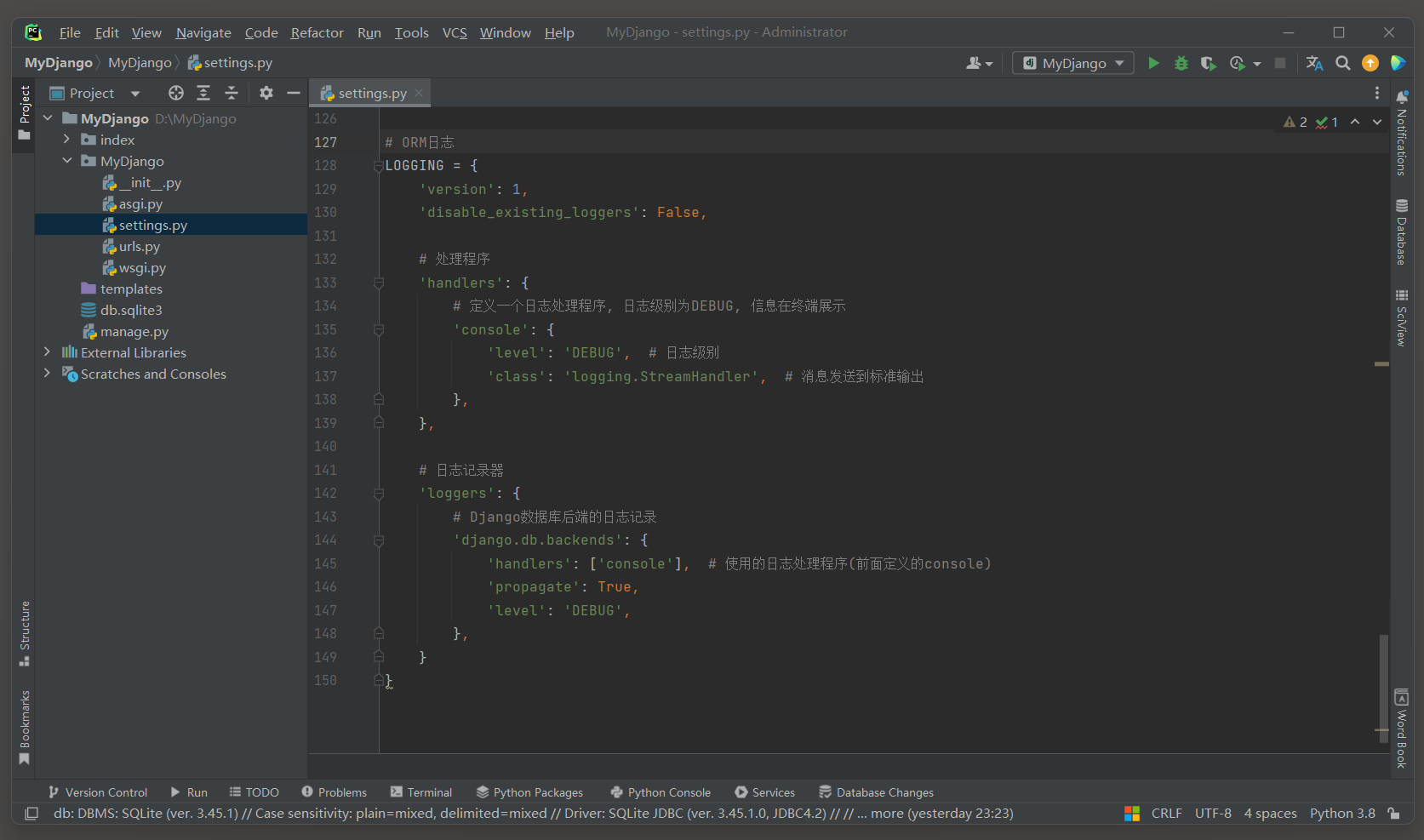
* 3. 可以在配置文件开启ORM日志查看对数据库的操作命令(灵活开启或关闭, 不能理解的时候才打开日志).
- 1
# settings.py # ORM日志配置 LOGGING = { 'version': 1, 'disable_existing_loggers': False, # 处理程序 'handlers': { # 定义一个日志处理程序, 日志级别为DEBUG, 信息在终端展示 'console': { 'level': 'DEBUG', # 日志级别 'class': 'logging.StreamHandler', # 消息发送到标准输出 }, }, # 日志记录器 'loggers': { # Django数据库后端的日志记录 'django.db.backends': { 'handlers': ['console'], # 使用的日志处理程序(前面定义的console) 'propagate': True, 'level': 'DEBUG', }, } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
* 4. 在urls.py文件中添加一个URL配置:
- 1
# MyDjango/urls.py
from django.urls import path
from index import views
urlpatterns = [
path('', views.my_view, name='my_view'),
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
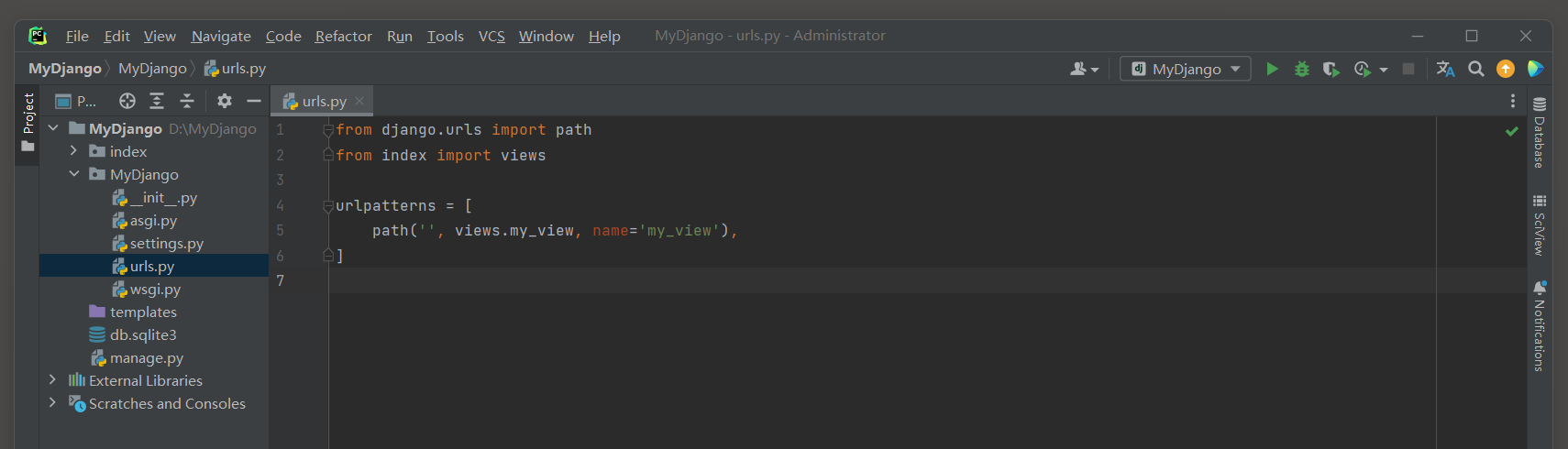
* 5. 编写一个视图函数, 创建一个数据实例, 然后抛出异常.
- 1
# index/urls.py
from django.shortcuts import HttpResponse
from .models import MyModel
def my_view(request):
try:
MyModel.objects.create(name='object 1')
# 手动触发异常
raise ValueError("数据库出错了!")
# 异常捕获
except ValueError as e:
return HttpResponse(f"{e}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
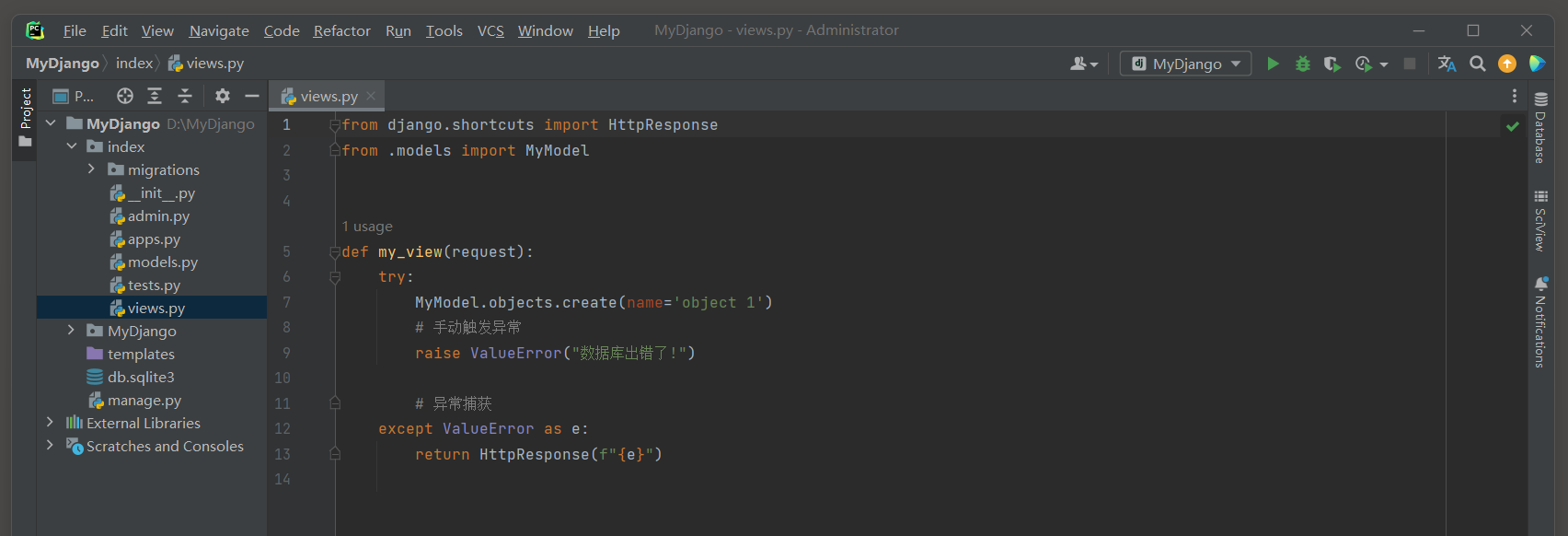
* 6. 启动项目, 访问: 127.0.0.1:8000 , 查看index_mymodel表数据.
- 1
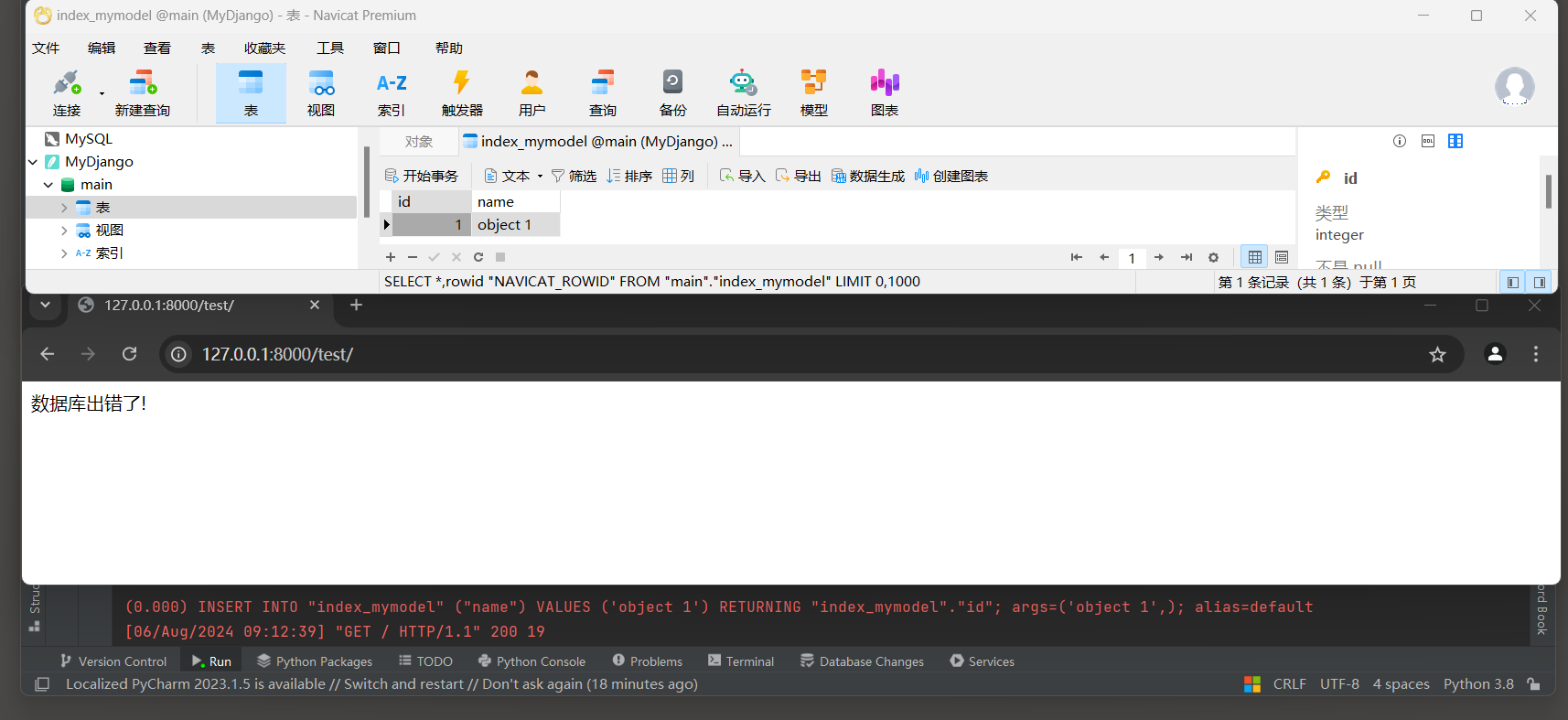
# ORM日志(Django 4.2.14):
(0.016)
INSERT INTO "index_mymodel" ("name") VALUES ('object 1') RETURNING "index_mymodel"."id";
args=('object 1',); alias=default
# 事务将自动自动提交, 这是数据库的默认行为.
- 1
- 2
- 3
- 4
- 5
- 6
SQL语句是用于向数据库中插入一条新记录, 并希望立即获取该记录的自增主键(ID).
这个语句特别适用于支持RETURNING子句的数据库系统, 如PostgreSQL.
在SQLite中, 从版本3.35开始也支持RETURNING子句, 但在早期版本中则不支持.
MySQL则使用不同的方法(如LAST_INSERT_ID()函数)来获取最后插入记录的自增ID.
- 1
- 2
- 3
- 4
2. 事务模块
2.1 模块介绍
在Django框架中, transaction模块是用于管理数据库事务的关键组件.
事务是确保数据库操作原子性, 一致性, 隔离性和持久性(ACID特性)的重要机制.
Django通过transaction模块提供了灵活的事务管理功能, 允许开发者在应用程序中根据需要手动控制事务的边界.
注意: 虽然Django ORM提供了对事务的支持,但具体的事务行为(如隔离级别, 持久性等)会根据使用的数据库后端而有所不同.
- 1
- 2
- 3
- 4
- 5
Django的ORM通过django.db.transaction模块提供了对数据库事务的细粒度控制. 默认情况下, Django在每个HTTP请求结束时自动提交事务, 这意味着在单个视图函数或中间件中执行的所有数据库操作(如模型的保存, 删除等)都将作为单个事务处理, 除非在代码中显式地进行了事务管理. transaction模块的主要功能和用法包括: * 1. 手动提交和回滚. 尽管Django鼓励使用transaction.atomic()进行事务管理. 但在某些特殊情况下, 开发者可能需要手动控制事务的提交和回滚. 这可以通过调用transaction.commit()和transaction.rollback()函数来实现, 但通常不推荐这样做, 因为这样做可能会破坏Django的自动事务管理机制. * 2. 手动事务管理. 适用于需要更细粒度控制事务的场景. Django提供了transaction.atomic()上下文管理器. 当代码块被transaction.atomic()装饰或包裹时, Django会确保该代码块内的所有数据库操作都在同一个事务中执行. 如果代码块内发生异常, 事务将自动回滚; 否则, 事务将自动提交. * 3. 自动事务管理. Django的TransactionMiddleware中间件默认在每个HTTP请求开始时自动开启一个事务, 并在请求结束时提交该事务. 如果请求处理过程中发生异常, 则事务会被回滚. 这种机制简化了大多数Web应用中的事务管理. 在Django 1.9及之前版本中是自动加载的, 但在后续版被移除. 不过可以通过数据库配置的ATOMIC_REQUESTS属性开启这个功能. 如果想要为某个特定的视图消这种自动事务行为, 可以使用@transaction.non_atomic_requests装饰视图. * 4. 事务钩子: Django还提供transaction.on_commit()函数, 允许开发者注册在事务提交时执行的回调函数. 这对于在事务提交后执行某些清理工作或异步任务非常有用. * 5. 保存点(Savepoints): 在一些复杂的场景中, 开发者可能需要在事务中设置保存点(avepoints), 以便在发生错误时能够回滚到事务中的某个特定点, 而不是整个事务. 然而, Django的transaction模块并不直接支持保存点操作, 这通常需要通过数据库底层的API来实现.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.2 手动提交或回滚
transaction.set_autocommit()方法: 用于设置自动提交模式的开启与关闭.
transaction.rollback()方法: 用于回滚当前事务.
注意:
* Django的默认事务行为是自动提交(autocommit)模式, 可以使用transaction.set_autocommit(False)关闭自动提交模式.
* 一旦提交事务, 数据将永久保存到数据库中, 并且不能通过transaction.rollback()来回滚这些更改.
* Django请求结束transaction.set_autocommit会被设置为True, 恢复自动提交.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
以下是一个使用MyModel模型手动控制事务提交和回滚的例子:
* 1. 修改views.py文件, 在视图任何适当的地方, 可以手动控制事务:
- 1
- 2
# index/views.py from django.shortcuts import HttpResponse from django.db import transaction from .models import MyModel def my_view(request): try: # 关闭自动提交行为 transaction.set_autocommit(False) # 往数据中插入数据 MyModel.objects.create(name='object 2') # 如果满足某些条件则提交事务 # transaction.commit() # 这里手动抛出异常 raise Exception("未知错误!") except Exception as e: # 回滚事务, 撤销插入数据的操作 transaction.rollback() # 处理异常或记录错误 return HttpResponse("由于错误, 事务回滚: {}".format(e)) finally: # 恢复自动提交(这通常在Django请求结束时自动发生, 但在这里显式调用以保持一致性) transaction.set_autocommit(True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
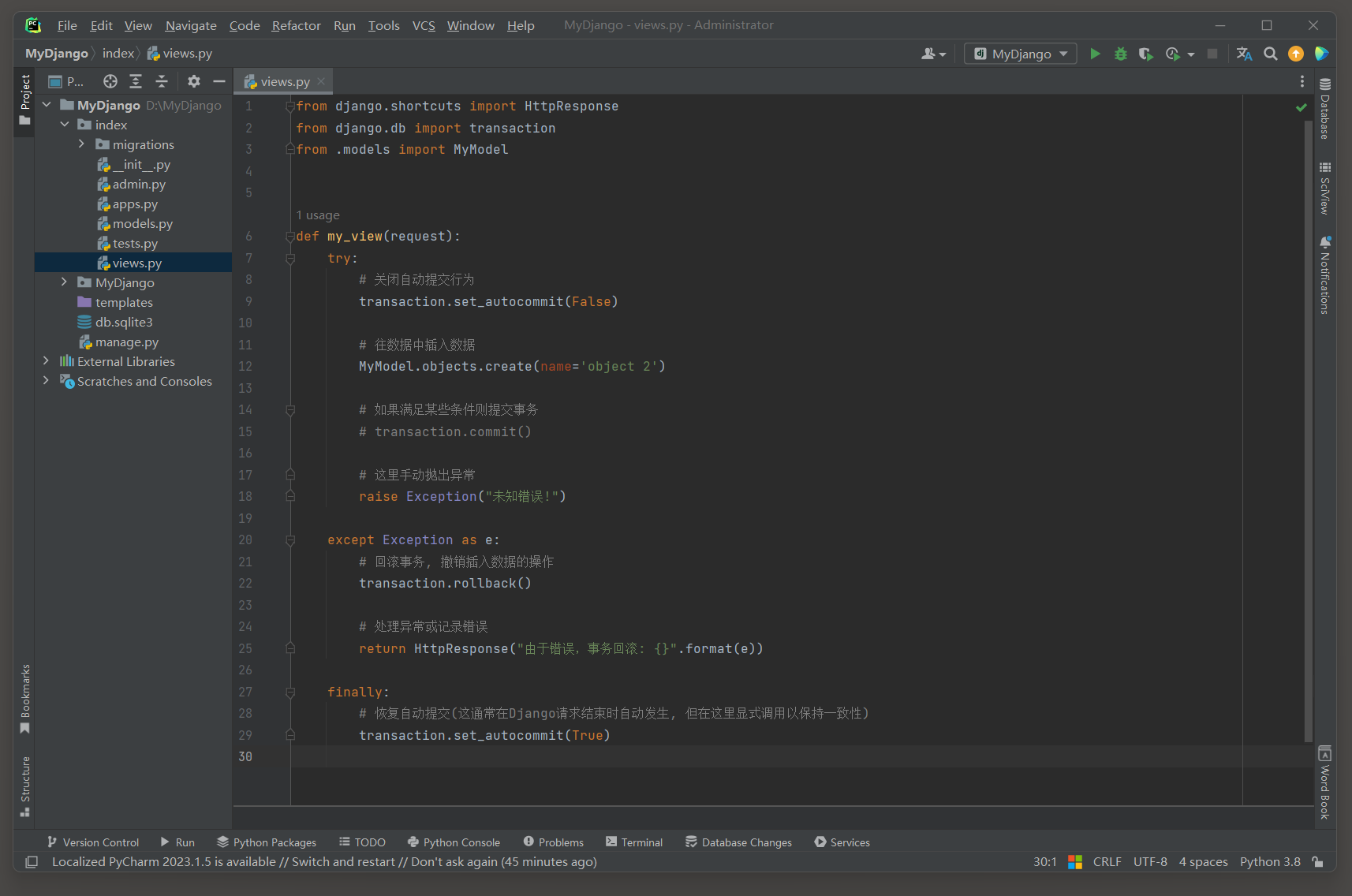
* 2. 启动项目, 访问: 127.0.0.1:8000 , 查看index_mymodel表数据.
- 1
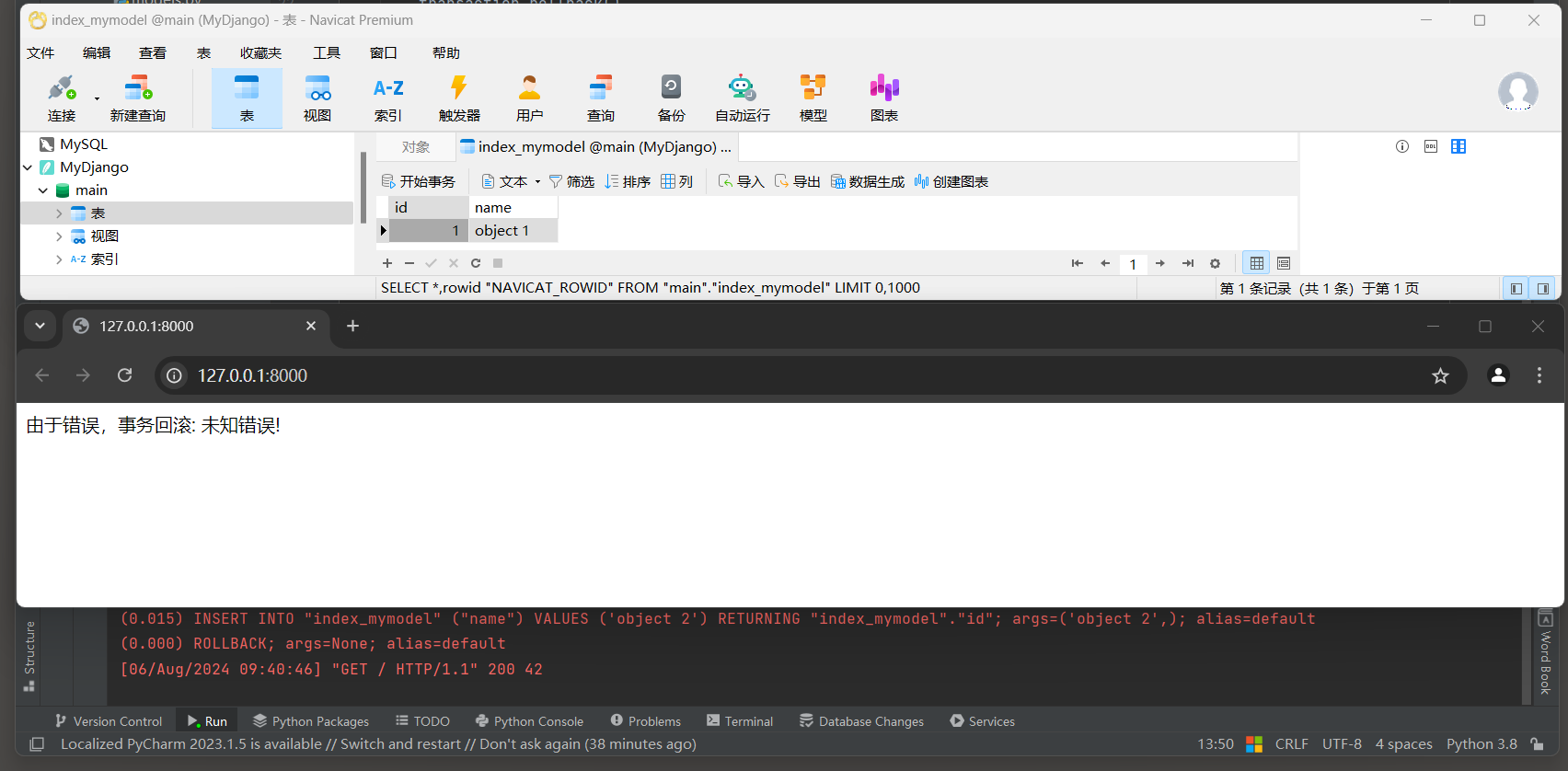
# ORM日志:
(0.015)
INSERT INTO "index_mymodel" ("name") VALUES ('object 2') RETURNING "index_mymodel"."id";
args=('object 2',); alias=default
# 回滚
(0.000)
ROLLBACK; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3 手动事务管理
transaction.atomic()是Django ORM提供的一个上下文管理器(context manager).
它用于确保数据库操作的原子性, 当将数据库操作(如插入, 更新, 删除等)包裹在transaction.atomic()块中时,
这些操作要么全部成功, 要么在发生错误时全部回滚, 从而保持数据的一致性.
总结: transaction.atomic块如果程序正常退出, 则自动提交事务, 否则回滚.
手动事务控制的两种使用方式如下:
- 1
- 2
- 3
- 4
- 5
- 6
# with语句用法(推荐): from django.db import transaction def my_view(request): try: # 以下数据库操作将在同一个事务中执行 with transaction.atomic(): # 执行一些数据库操作 pass except Exception as e: # 如果发生异常, 事务将自动回滚自动调用transaction.rollback() raise # 事务已经提交或回滚, 这里可以安全地继续执行其他操作 # 返回响应 return render(request, 'my_template.html')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
# 装饰器用法(不适用于代码块或单独的语句, 如果函数内部有多个独立的操作需要单独控制事务, 使用装饰器可能会变得不够灵活):
from django.db import transaction
@transaction.atomic
def my_view(request):
# 以下所有数据库操作将在同一个事务中执行, 如果所有操作都成功, 则事务自动提交
# transaction.atomic()装饰器会在遇到异常时自动回滚事务
# 返回响应
return render(request, 'my_template.html')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
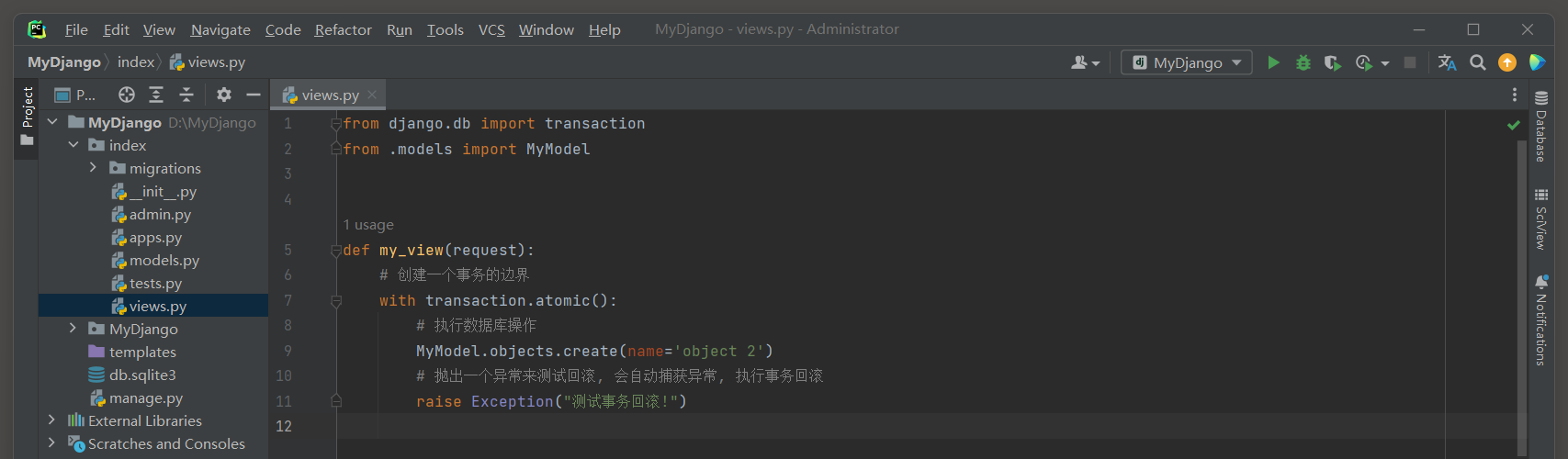
* 1. 修改views.py文件, 使用transaction.atomic()在视图中定义一个事务的边界,
在边界内创建一个模型实例, 并在发生异常时自动回滚事务.
- 1
- 2
# index/views.py
from django.db import transaction
from .models import MyModel
def my_view(request):
# 创建一个事务的边界
with transaction.atomic():
# 执行数据库操作
MyModel.objects.create(name='object 2')
# 抛出一个异常来测试回滚, 会自动捕获异常, 执行事务回滚
raise Exception("测试事务回滚!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
* 2. 启动项目, 访问: http://127.0.0.1:8000 , 测试事务处理.
- 1
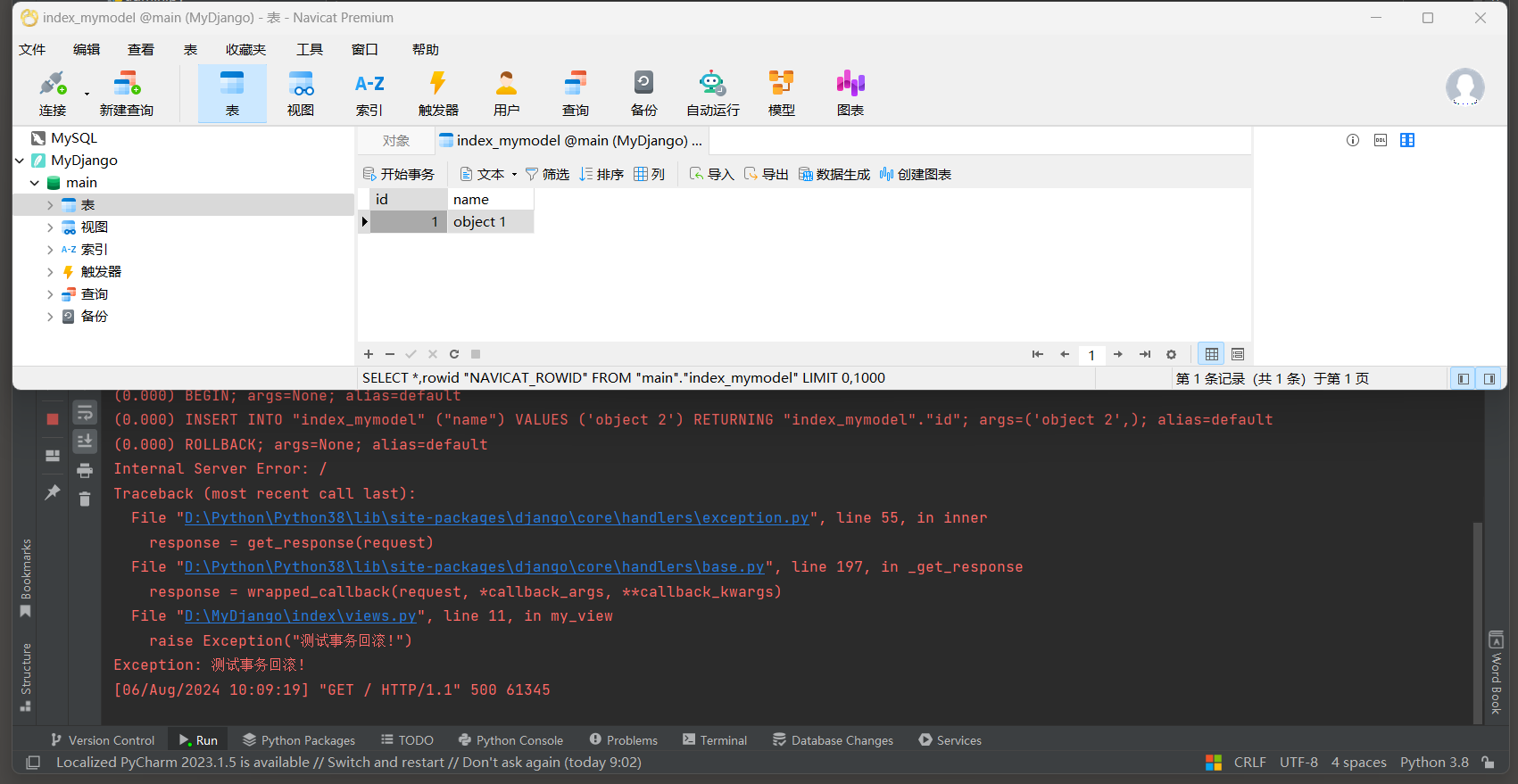
# ORM日志:
(0.016)
INSERT INTO "index_mymodel" ("name") VALUES ('object 2') RETURNING "index_mymodel"."id";
args=('object 2',); alias=default
-- 在这期间尝试通过另一个数据库连接看数据库, 是看不到object 2, 除非提交了这个事务, 不然会破坏事务的原子性.
# 回滚
(0.000)
ROLLBACK; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
隔离级别: 数据库事务的隔离级别决定了事务之间如何相互影响.
不同的隔离级别(如: 读未提交, 读已提交, 可重复读, 串行化)会影响你看到的数据状态.
例如, 在高隔离级别下(如可重复读或串行化), 当插入数据时, 其他用户可能暂时看不到这些新插入的数据, 直到当前事务提交.
- 1
- 2
- 3
* 3. 如果想要优雅的停止程序不出现异常, 可以使用try语句捕获transaction.atomic()块中的异常.
- 1
# index/views.py from django.shortcuts import HttpResponse from django.db import transaction from .models import MyModel def my_view(request): try: # 创建一个事务的边界 with transaction.atomic(): # 执行数据库操作 MyModel.objects.create(name='object 2') # 抛出一个异常来测试回滚, 会自动捕获异常, 执行事务回滚 raise Exception("测试事务回滚!") except Exception as e: # 现在可以安全地返回一个包含错误信息的响应 return HttpResponse(f"出现错误, 原因: {e}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
* 4. 启动项目, 访问: http://127.0.0.1:8000 , transaction.atomic()块中的异常被捕获.
- 1

# ORM日志:
(0.000) I
NSERT INTO "index_mymodel" ("name") VALUES ('object 2') RETURNING "index_mymodel"."id";
args=('object 2',); alias=default
# 回滚
(0.000)
ROLLBACK; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.4 注意事项
try...except与with transaction.atomic()语句块一起工作的详细解释:
在with transaction.atomic(): 语句块中, 如果发生异常会导致Python退出该块, 这时Django会自动回滚事务.
如果try...except块定义在with transaction.atomic块中, 而数据库操作实是在try块中执行的.
如果try中捕获了异常并且没有重新抛出, 那么事务将不会被回滚, 因为从Python的角度来看, 异常已经被except块'处理'了.
- 1
- 2
- 3
- 4
* 1. 修改views.py, 代码如下:
- 1
# index/views.py from django.db import transaction from .models import MyModel def my_view(request): with transaction.atomic(): try: # 执行数据库操作 MyModel.objects.create(name='object 2') # 抛出一个异常来测试回滚 raise Exception("测试事务回滚!") except Exception as e: print(f'异常信息{e}') # try中的异常被except捕获, 也应该在except中处理. # 这里不可以手动执行transaction.rollback() 会报错:事务管理错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
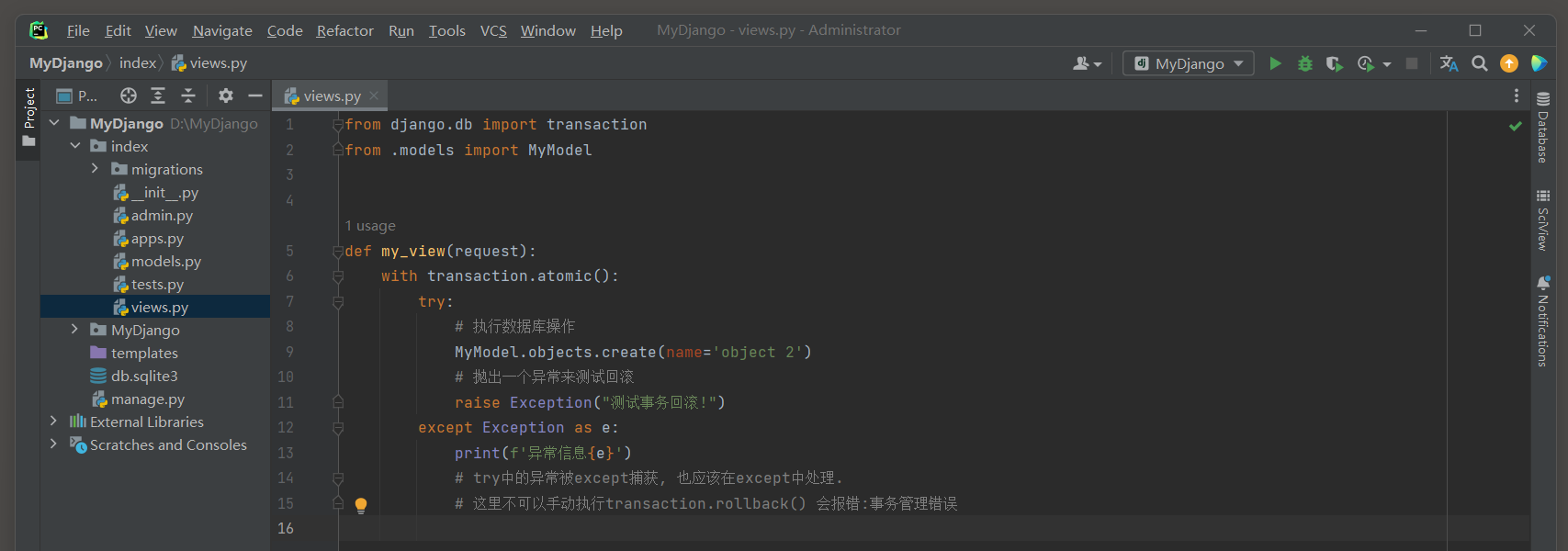
* 2. 启动项目, 访问: http://127.0.0.1:8000 , 测试事务处理.
如果try中捕获了异常并且没有重新抛出, 那么事务将不会被回滚.
transaction.atomic块没捕获到异常会在结束时会自动提交事务.
- 1
- 2
- 3
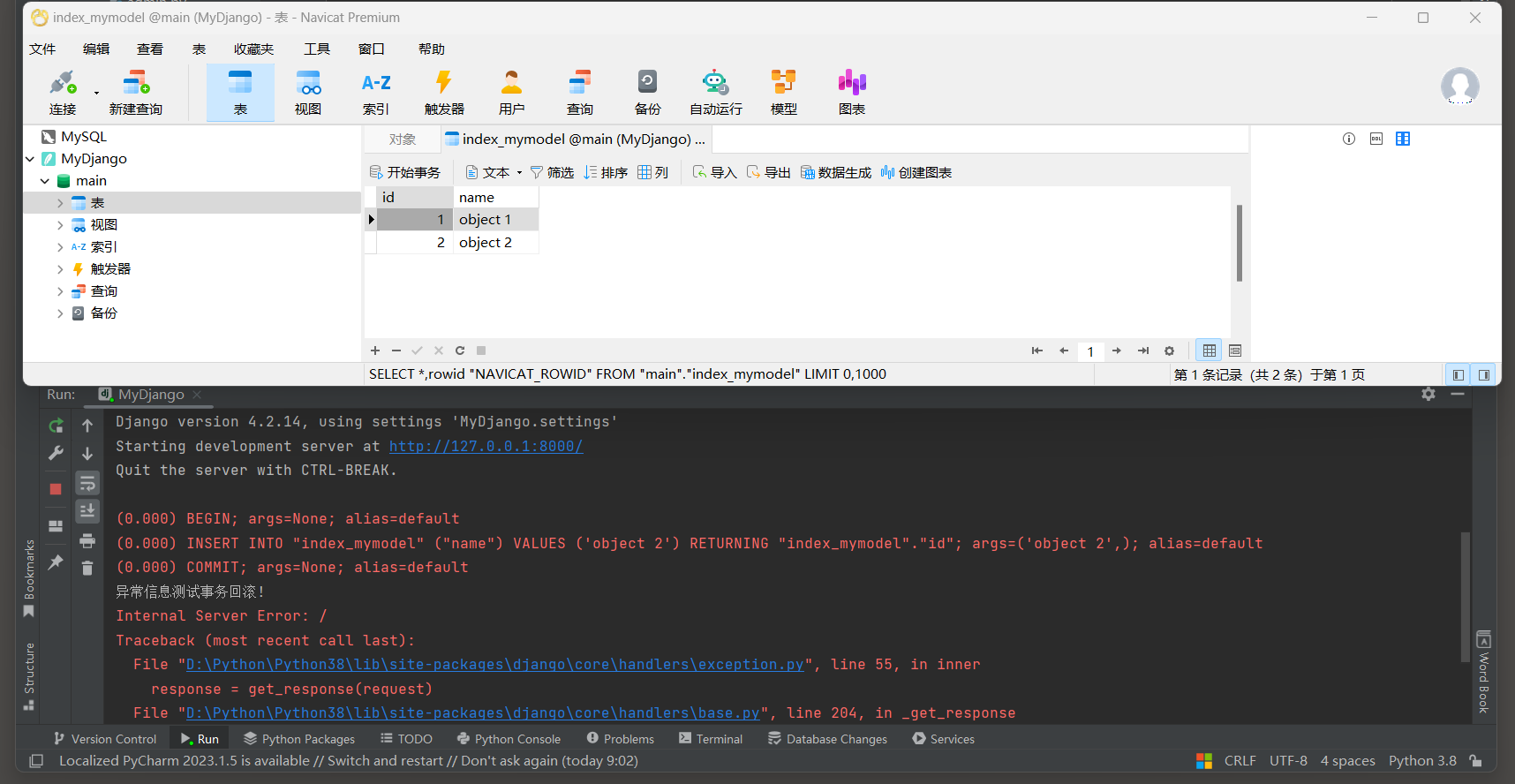
# ORM日志:
(0.000)
INSERT INTO "index_mymodel" ("name") VALUES ('object 2') RETURNING "index_mymodel"."id";
args=('object 2',); alias=default
# transaction.atomic()语句结束时提交事务
(0.000)
COMMIT; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
- 6
- 7
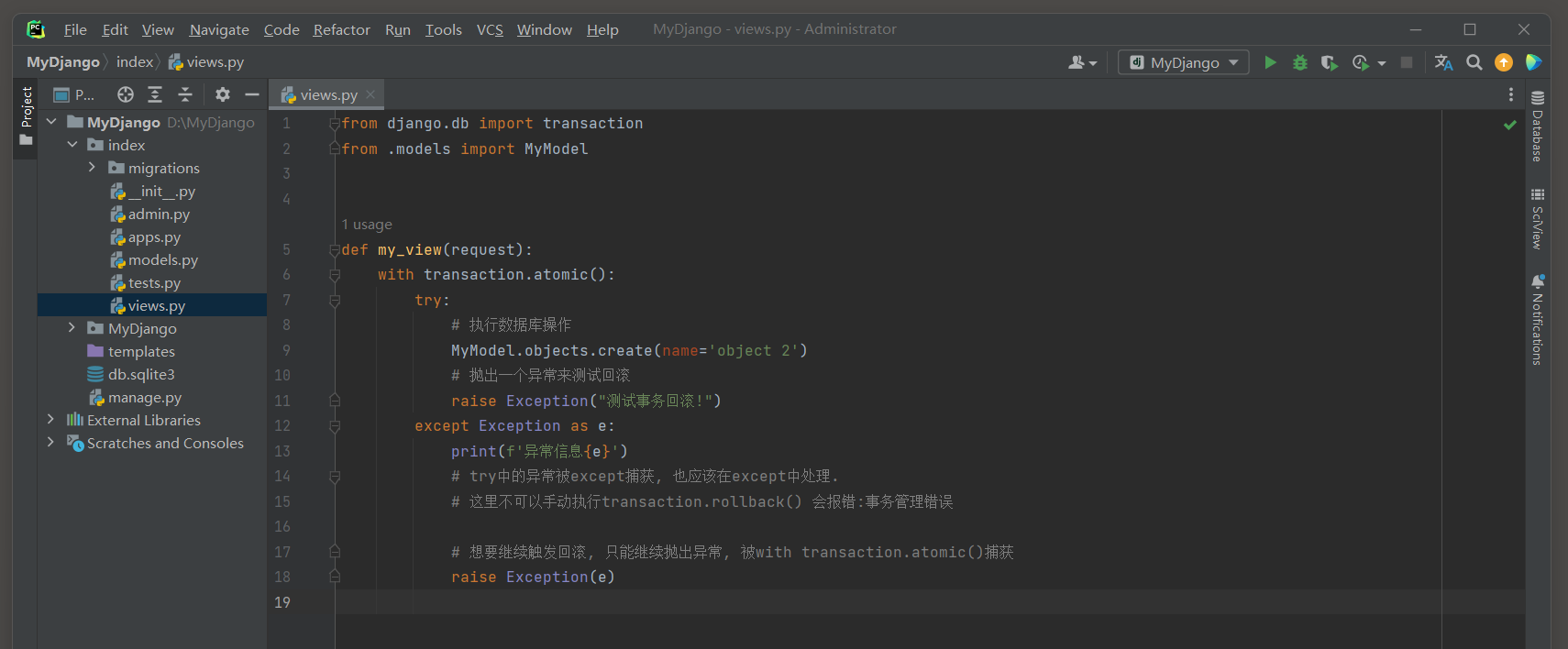
* 3. 修改views.py, 在except子句中抛出异常.
想要继续触发回滚, 只能继续抛出异常, 被with transaction.atomic()语句捕获异常, 从而触发回滚.
- 1
- 2
# index/views.py from django.db import transaction from .models import MyModel def my_view(request): with transaction.atomic(): try: # 执行数据库操作 MyModel.objects.create(name='object 3') # 抛出一个异常来测试回滚 raise Exception("测试事务回滚!") except Exception as e: print(f'异常信息{e}') # try中的异常被except捕获, 也应该在except中处理. # 这里不可以手动执行transaction.rollback() 会报错:事务管理错误 # 想要继续触发回滚, 只能继续抛出异常, 被with transaction.atomic()捕获 raise Exception(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
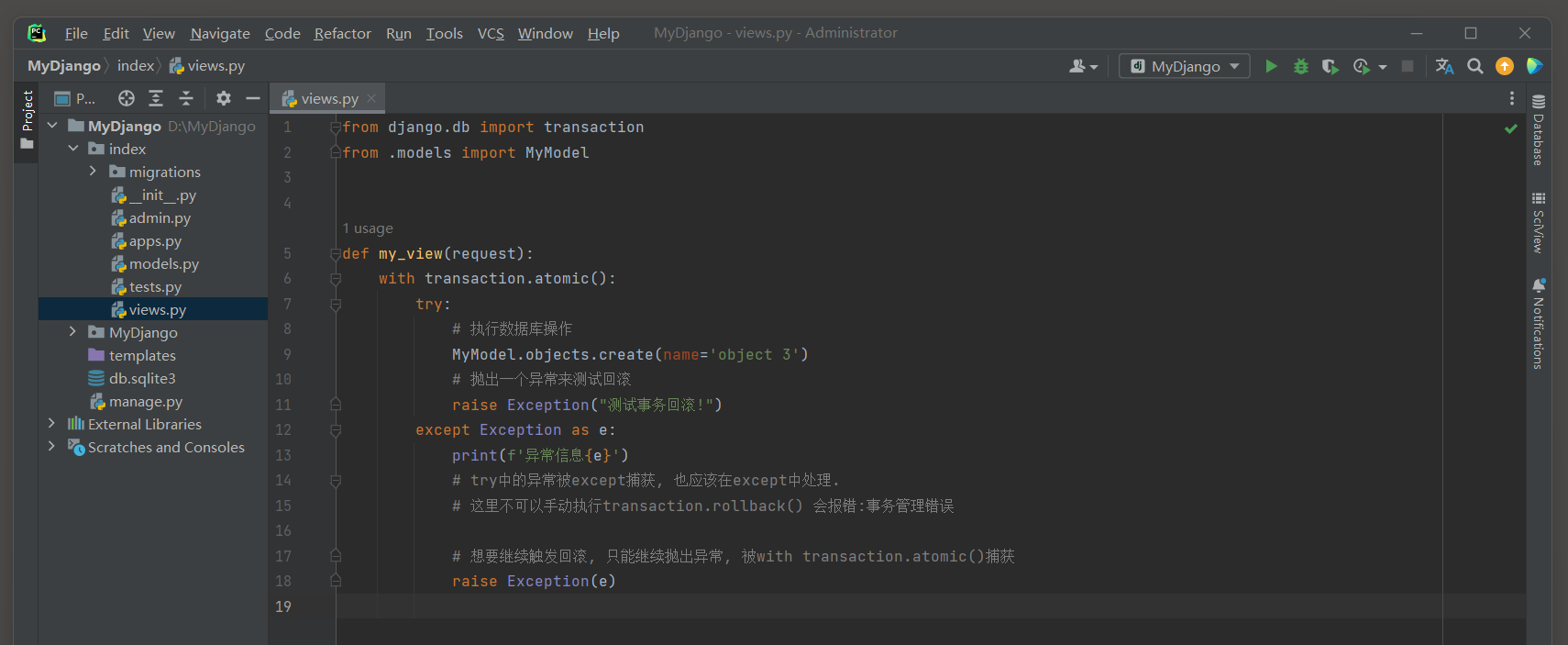
* 4. 启动项目, 访问: http://127.0.0.1:8000 , 测试事务处理.
如果不想程序报错, 可在with transaction.atomic()块外层在套一个try, 让程序优雅的结束.
- 1
- 2
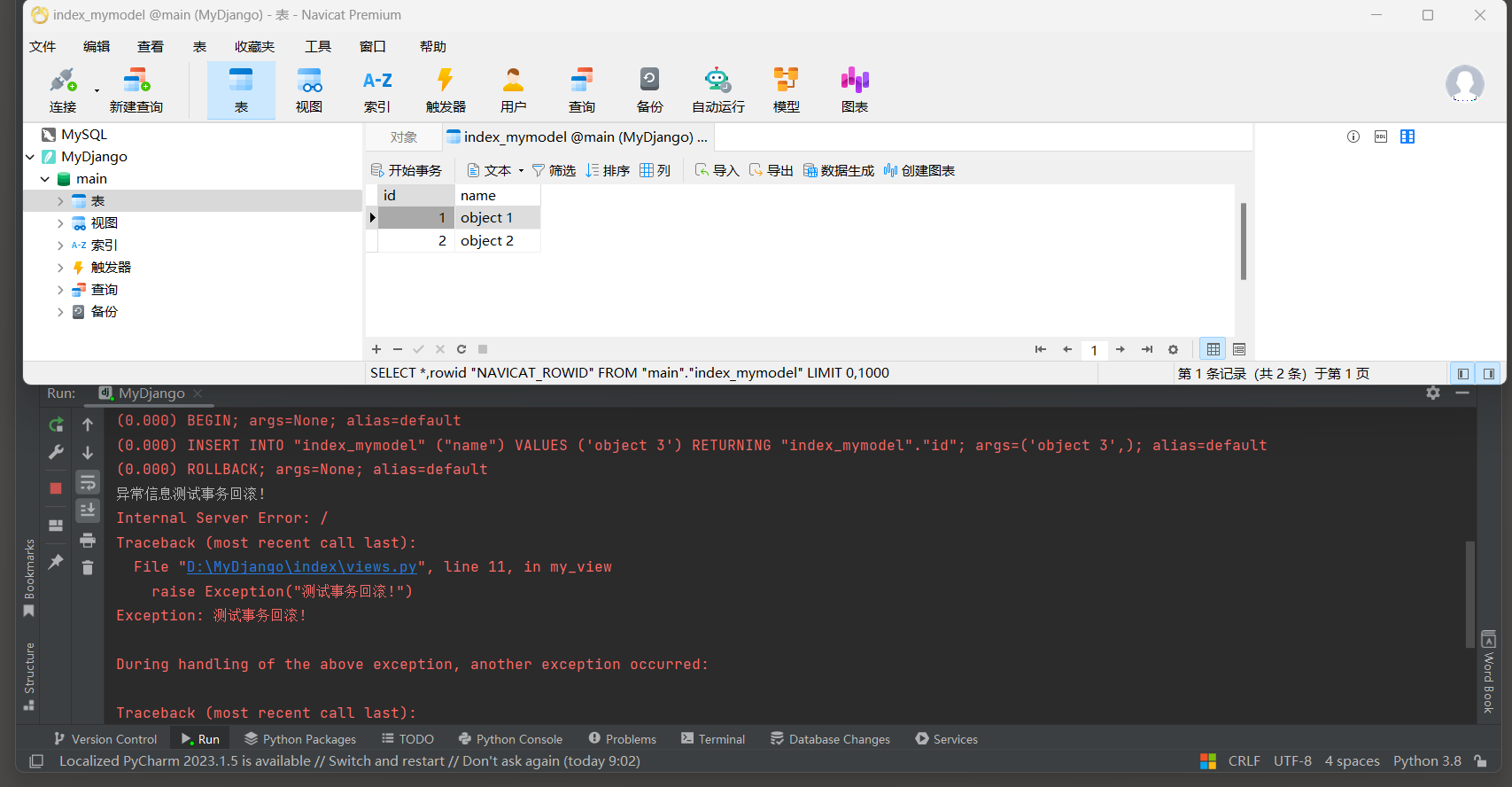
# ORM日志:
(0.000) INSERT INTO "index_mymodel" ("name") VALUES ('object 3') RETURNING "index_mymodel"."id";
args=('object 3',); alias=default
# 回滚
(0.000) ROLLBACK; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
2.5 自动事务管理
在Django中, ATOMIC_REQUESTS(原子性请求)是一个数据库设置选项,
它会在每个HTTP请求开始时自动开启一个数据库事务, 并在请求结束时提交或回滚该事务.
- 1
- 2
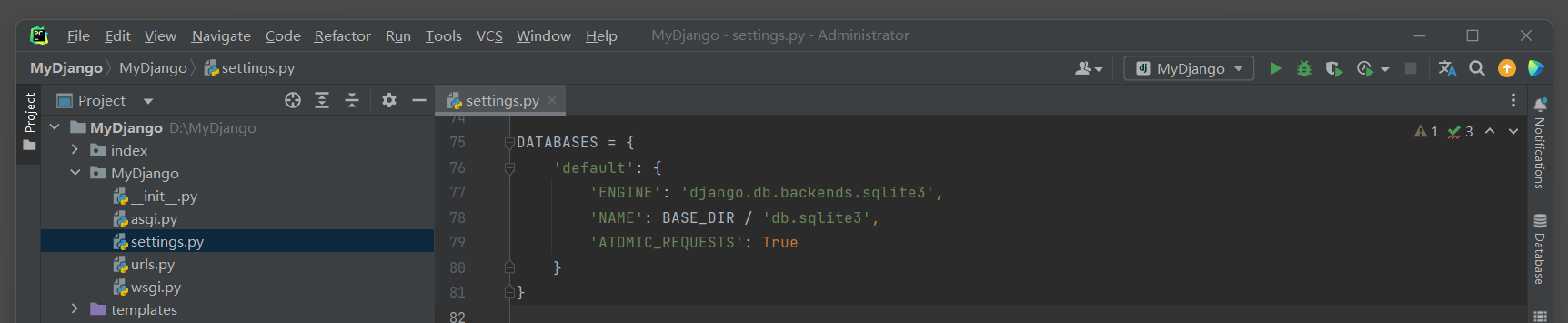
* 1. 在配置文件的添加ATOMIC_REQUESTS(原子性请求)属性:
- 1
# settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
'ATOMIC_REQUESTS': True
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
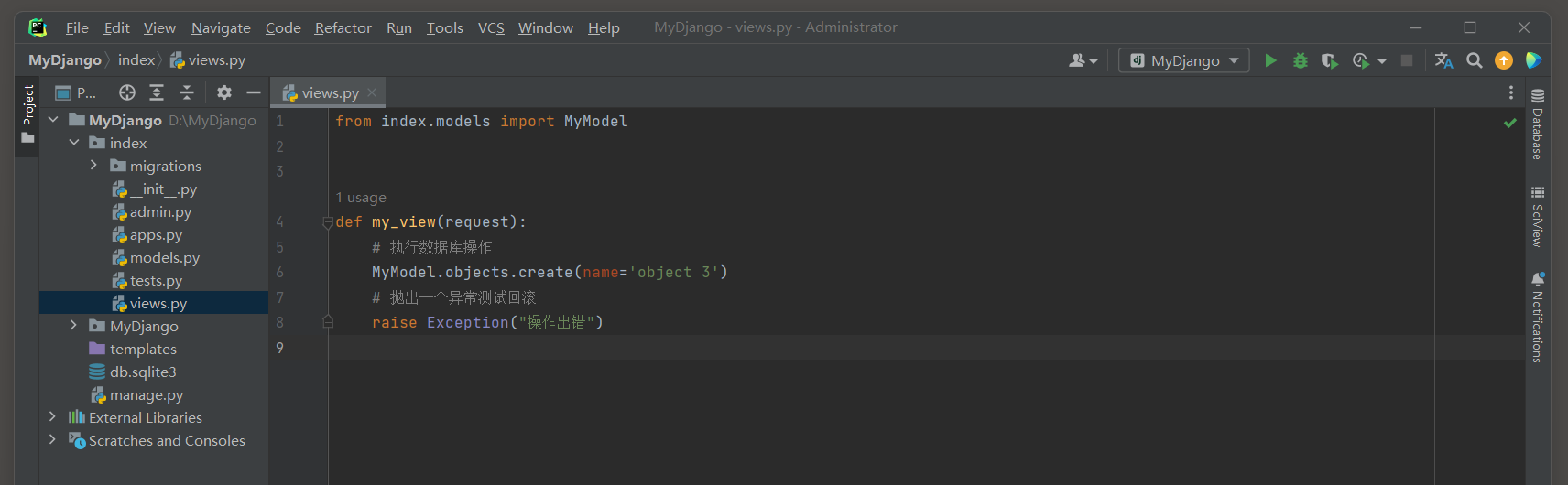
* 2. 修改上面示例的视图函数:
- 1
# index的views.py
from index.models import MyModel
def my_view(request):
# 执行数据库操作
MyModel.objects.create(name='object 3')
# 抛出一个异常测试回滚
raise Exception("操作出错")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
* 3. 启动项目, 访问: http://127.0.0.1:8000 , 测试事务处理.
- 1
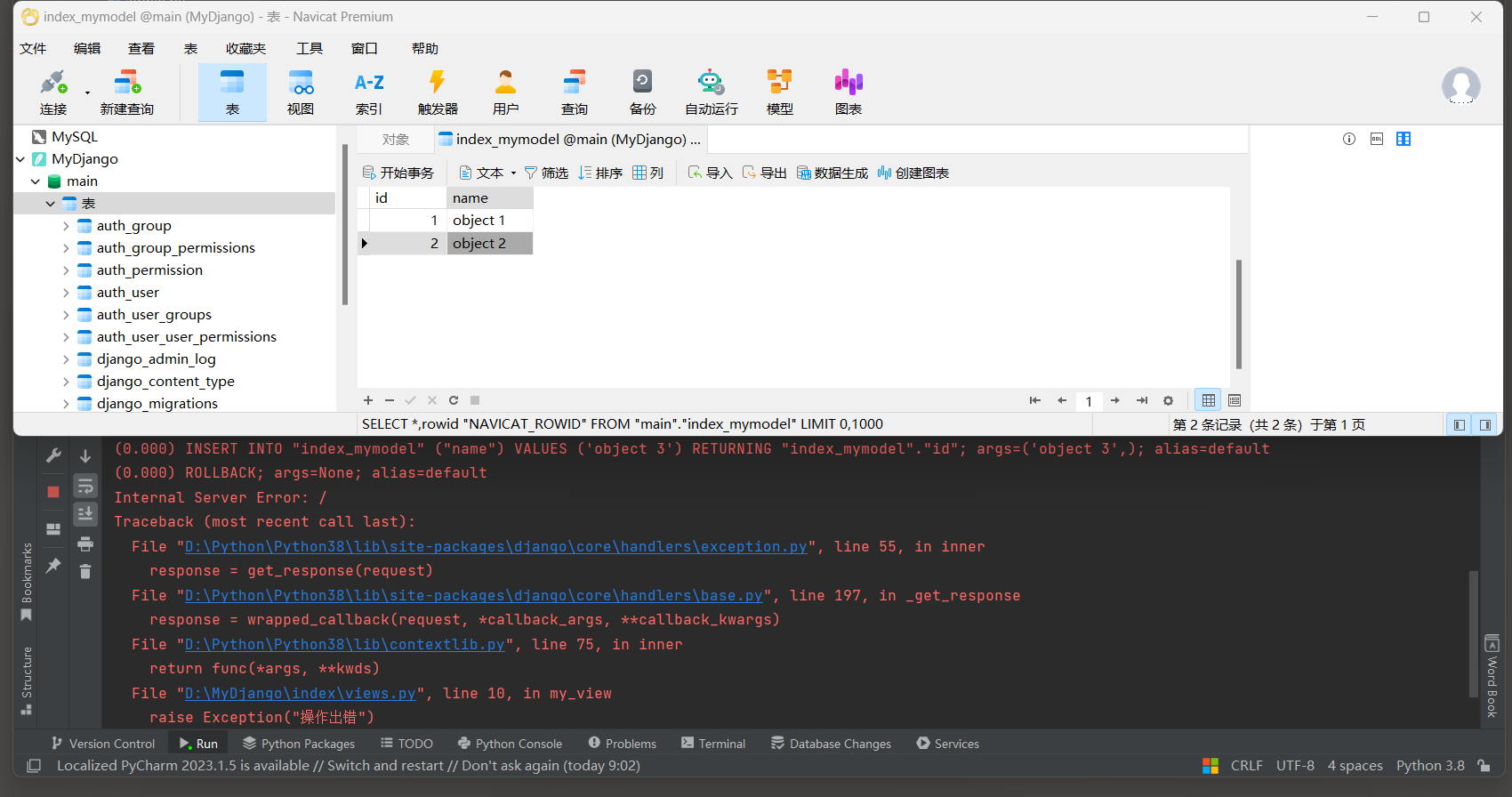
# ORM日志:
(0.000)
INSERT INTO "index_mymodel" ("name") VALUES ('object 3') RETURNING "index_mymodel"."id";
args=('object 3',); alias=default
# 回滚
(0.000) ROLLBACK; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
- 6
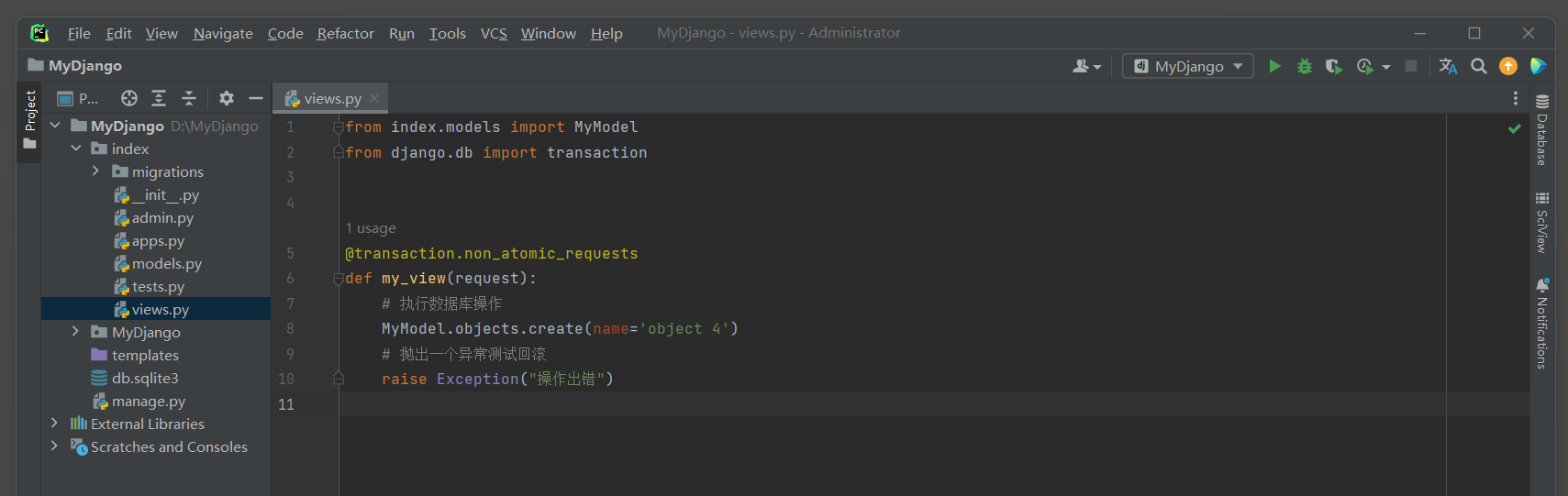
* 4. 如果想要为某个特定的视图消这种自动事务行为, 可以使用@transaction.non_atomic_requests装饰视图.
- 1
# index的views.py
from index.models import MyModel
from django.db import transaction
@transaction.non_atomic_requests
def my_view(request):
# 执行数据库操作
MyModel.objects.create(name='object 4')
# 抛出一个异常测试回滚
raise Exception("操作出错")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
* 5. 启动项目, 访问: http://127.0.0.1:8000 , 测试事务处理.
- 1
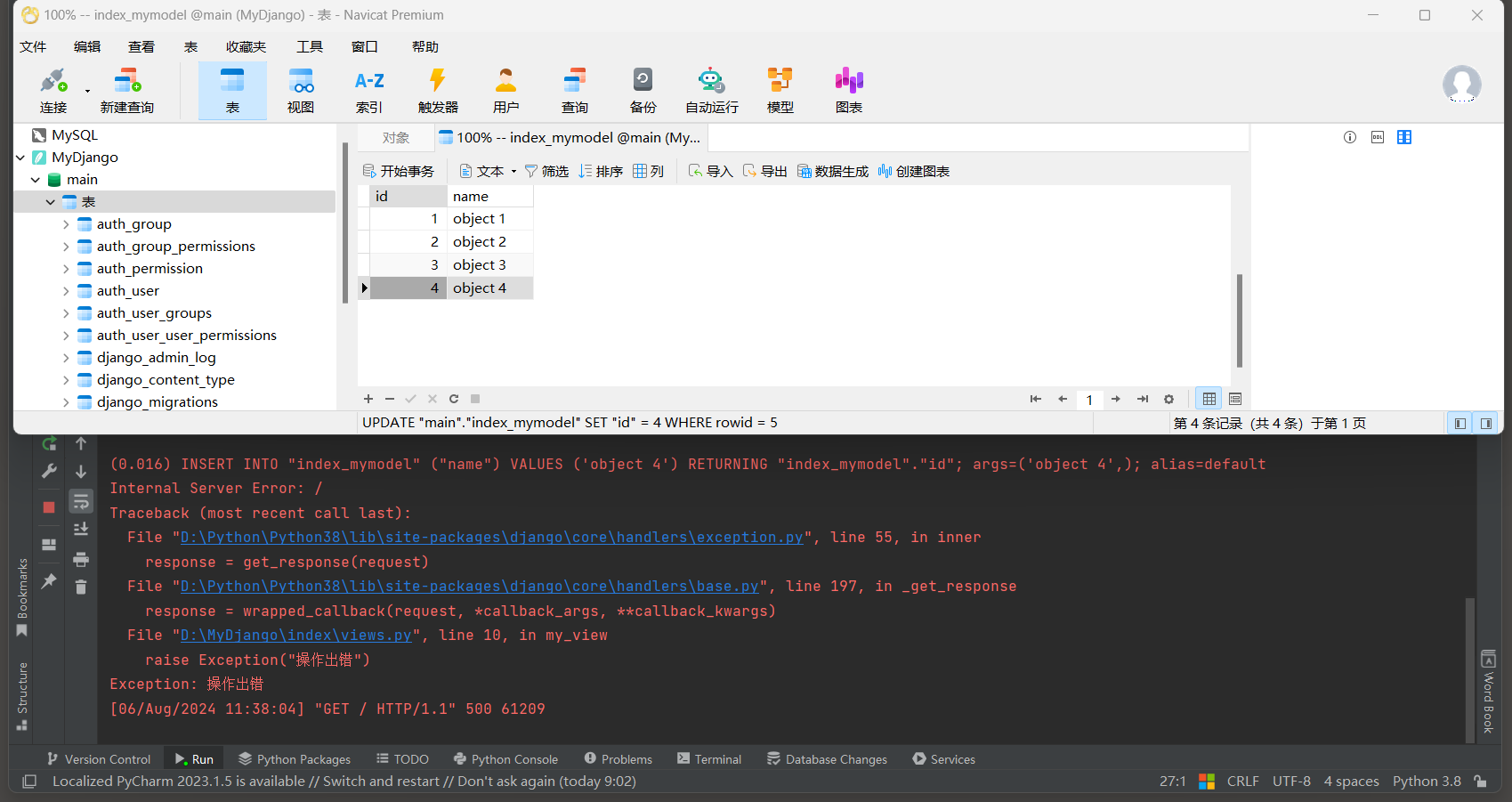
# ORM日志:
(0.000)
INSERT INTO "index_mymodel" ("name") VALUES ('object 4') RETURNING "index_mymodel"."id";
args=('object 3',); alias=default
# 事务将自动自动提交, 这是数据库的默认行为.
- 1
- 2
- 3
- 4
- 5
- 6
2.6 事务钩子
transaction.on_commit()是Django提供的一个非常有用的函数,
它允许注册一个回调函数, 该回调函数将在当前数据库事务成功提交后执行.
这对于在事务完成后执行清理工作, 发送通知, 触发异步任务等场景特别有用.
- 1
- 2
- 3
下面是一个使用transaction.on_commit()的例子:
* 1. 在视图或任何数据库操作函数中, 可以使用transaction.on_commit()来注册一个任务, 它会在事务提交后执行:
- 1
- 2
# index/views.py from django.http import HttpResponse from django.db import transaction from .models import MyModel def my_view(request): # 在数据库事务中创建一个新的 MyModel 实例 with transaction.atomic(): MyModel.objects.create(name="object 5") # 使用 @transaction.on_commit 装饰器来注册一个回调函数 # 该回调函数将在当前事务提交后执行 @transaction.on_commit def send_email_after_commit(): # 这里发送一封电子邮件 # 注意:在实际应用中,你应该使用更安全的方式来处理敏感信息,比如使用 Django 的 EmailBackend print("交易提交后发送的电子邮件.") # 手动异常 # raise ValueError("数据库出错了!") # send_email_after_commit 函数会在当前数据库事务提交后被自动调用 return HttpResponse("记录已创建, 交易提交后将发送电子邮件.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
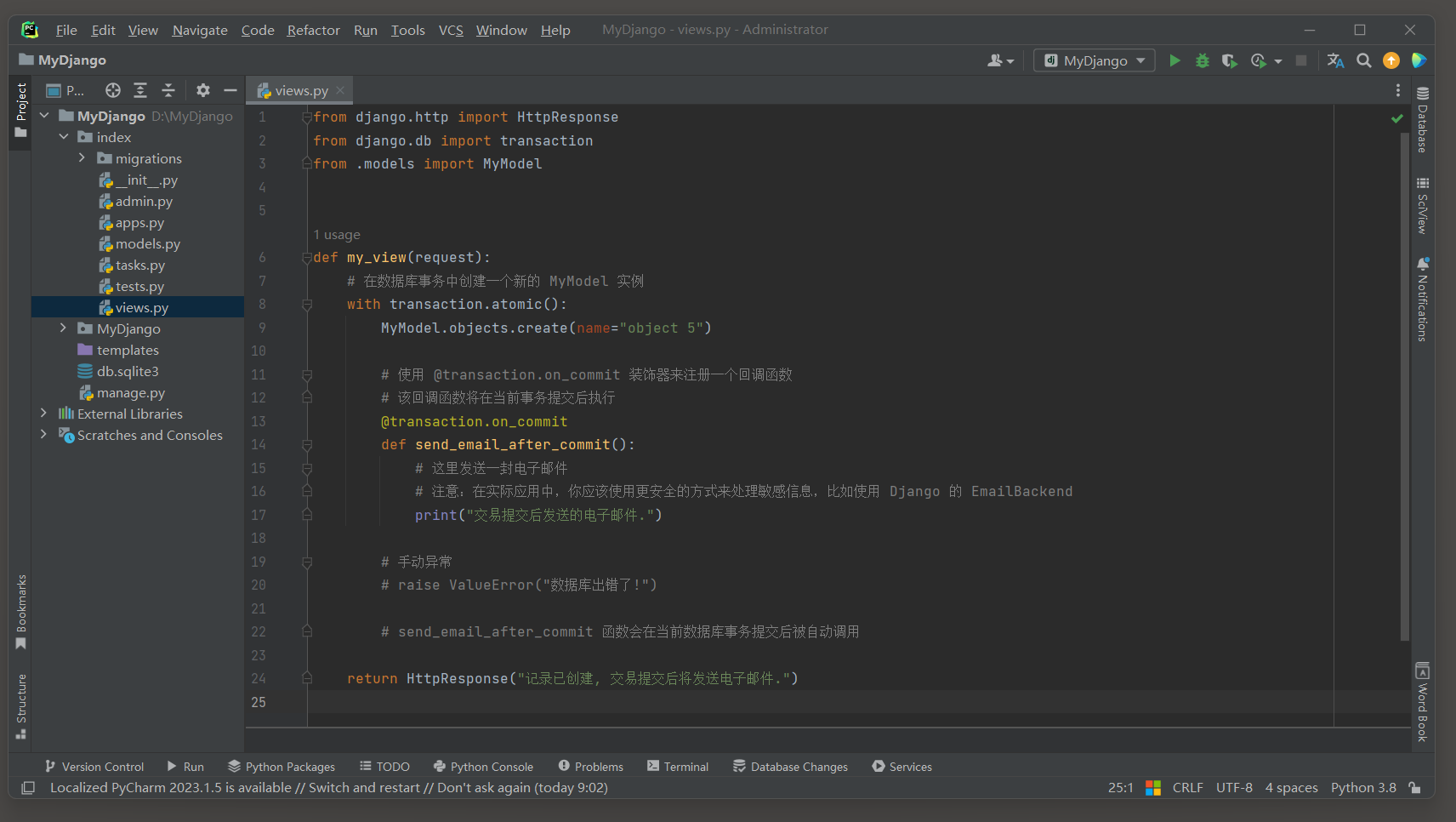
* 2. 启动项目, 访问: http://127.0.0.1:8000 , 查看事务钩子.
- 1

# ORM日志:
(0.000) INSERT INTO "index_mymodel" ("name") VALUES ('object 5') RETURNING "index_mymodel"."id";
args=('object 5',); alias=default
# 提交事务
(0.016) COMMIT; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
* 3. 修改代码, 在with transaction.atomic()块中手动抛出异常, 事务边界块捕获到异常后会执行回滚操作.
- 1
# index/views.py from django.db import transaction from .models import MyModel def my_view(request): # 在数据库事务中创建一个新的 MyModel 实例 with transaction.atomic(): MyModel.objects.create(name="object 6") # 使用 @transaction.on_commit 装饰器来注册一个回调函数 # 该回调函数将在当前事务提交后执行 @transaction.on_commit def send_email_after_commit(): # 这里发送一封电子邮件 # 注意:在实际应用中,你应该使用更安全的方式来处理敏感信息,比如使用 Django 的 EmailBackend print("交易提交后发送的电子邮件.") # 触发异常, 事务回滚, 事务钩子函数不会被触发 raise ValueError("数据库出错了!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
* 4. 重新启动项目, 访问: http://127.0.0.1:8000 , 查看事务钩子的执行情况.
在没有提交事务的时候不会被触发钩子函数.
- 1
- 2
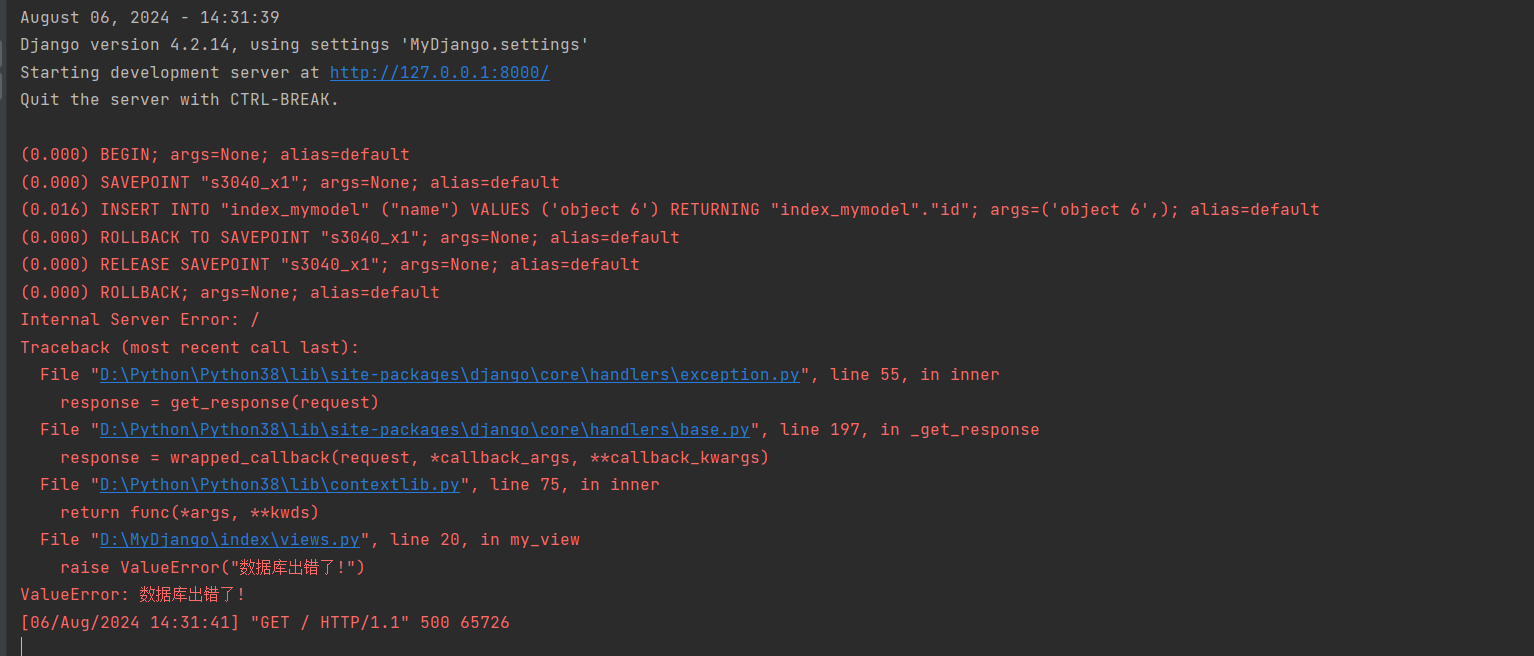
# ORM日志
(0.016) INSERT INTO "index_mymodel" ("name") VALUES ('object 6') RETURNING "index_mymodel"."id";
args=('object 6',); alias=default
# 回滚事务
(0.000) ROLLBACK; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
2.7 保存点
在Django的数据库事务管理中, transaction.savepoint()是一个用于在事务中创建保存点的函数.
保存点允许在事务中设置一个点, 之后可以回滚到这个点, 而不是回滚整个事务.
这对于复杂的数据库操作非常有用, 尤其是当需要在事务的某个特定部分失败时能够恢复状态, 而不是放弃整个事务.
- 1
- 2
- 3
下面是一个使用ransaction.savepoint的例子, 演示保存点的使用.
* 1. 修改views.py文件中使用transaction.atomic()装饰器来装饰一个视图函数, 为其开启事务功能.
在该视图函数中创建一个保存点, 并创建两个模型实例, 最后在发生异常时能够回滚事务.
- 1
- 2
- 3
# index/views.py from django.shortcuts import HttpResponse from index.models import MyModel # 导入事务 from django.db import transaction # 以装饰器形式开启事务 @transaction.atomic def my_view(request): # 开启事务(创建一个保存点), 调用 transaction.savepoint() 时, 会返回一个表示该保存点的对象或标识符 sid = transaction.savepoint() try: # 执行一些数据库操作 MyModel.objects.create(name='object 6') # 假设这里需要基于某些条件来决定是否回滚到保存点 raise Exception("需要回滚到保存点") except Exception as e: # 事务回滚 transaction.savepoint_rollback(sid) print(f'操作失败, 原因为: {e}') return HttpResponse('保存点测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
* 2. 启动项目, 访问: http://127.0.0.1:8000 , 查看保存点效果.
- 1
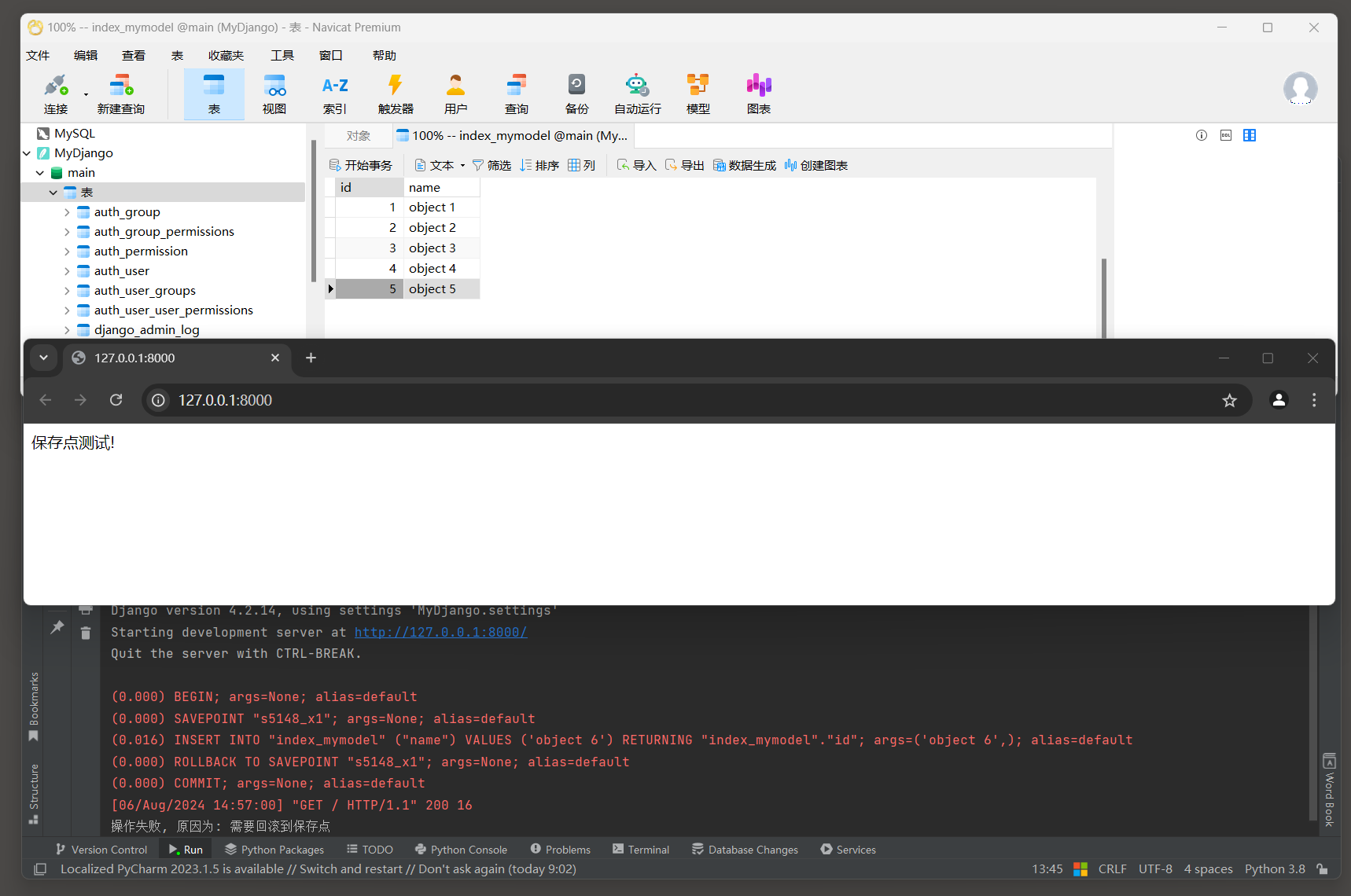
# ORM日志:
(0.000) BEGIN; args=None; alias=default # 标记一个事务的开始
(0.000) SAVEPOINT "s5148_x1"; args=None; alias=default # 创建保存点
(0.016) INSERT INTO "index_mymodel" ("name") VALUES ('object 6') RETURNING "index_mymodel"."id"; ...
(0.000) ROLLBACK TO SAVEPOINT "s5148_x1"; args=None; alias=default # 恢复保存点
(0.000) COMMIT; args=None; alias=default # 提交事务
- 1
- 2
- 3
- 4
- 5
- 6
注意事项: 在一个全局事务的上下文中工作时, 再使用@transaction.atomic装饰器来包裹特定的代码块,
Django的ORM会在这个@transaction.atomic块开始时自动创建一个保存点(savepoint).
不管代码块正常还是异常结果都是释放保存点提交事务...
- 1
- 2
- 3
- 4
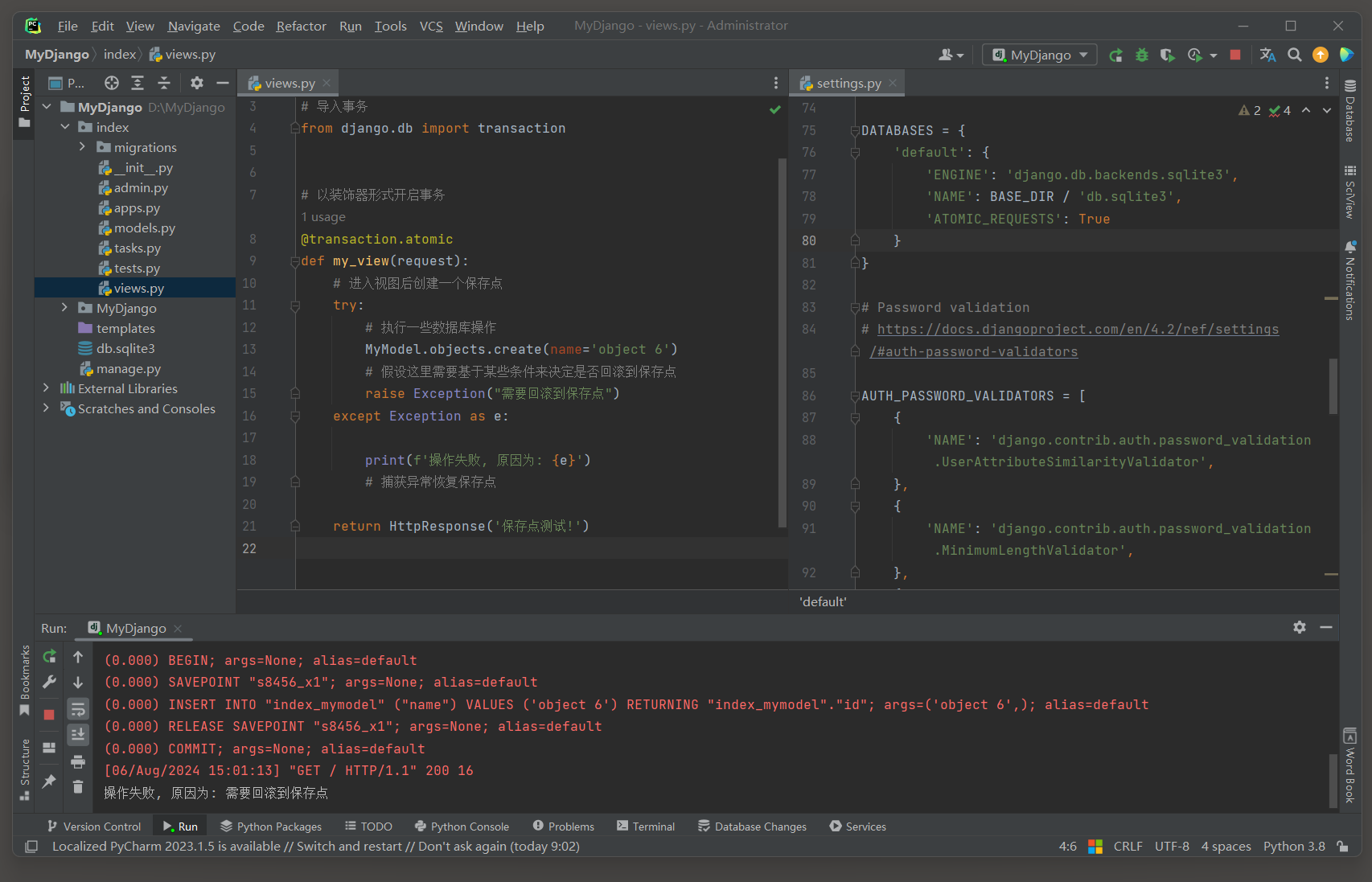
# ORM日志:
(0.000) BEGIN; args=None; alias=default # 标记一个事务的开始
(0.000) SAVEPOINT "s8456_x1"; args=None; alias=default # 创建保存点
(0.000) INSERT INTO "index_mymodel" ("name") VALUES ('object 6') RETURNING "index_mymodel"."id"; ...
(0.000) RELEASE SAVEPOINT "s8456_x1"; args=None; alias=default # 释放保存点
(0.000) COMMIT; args=None; alias=default # 提交事务
- 1
- 2
- 3
- 4
- 5
- 6
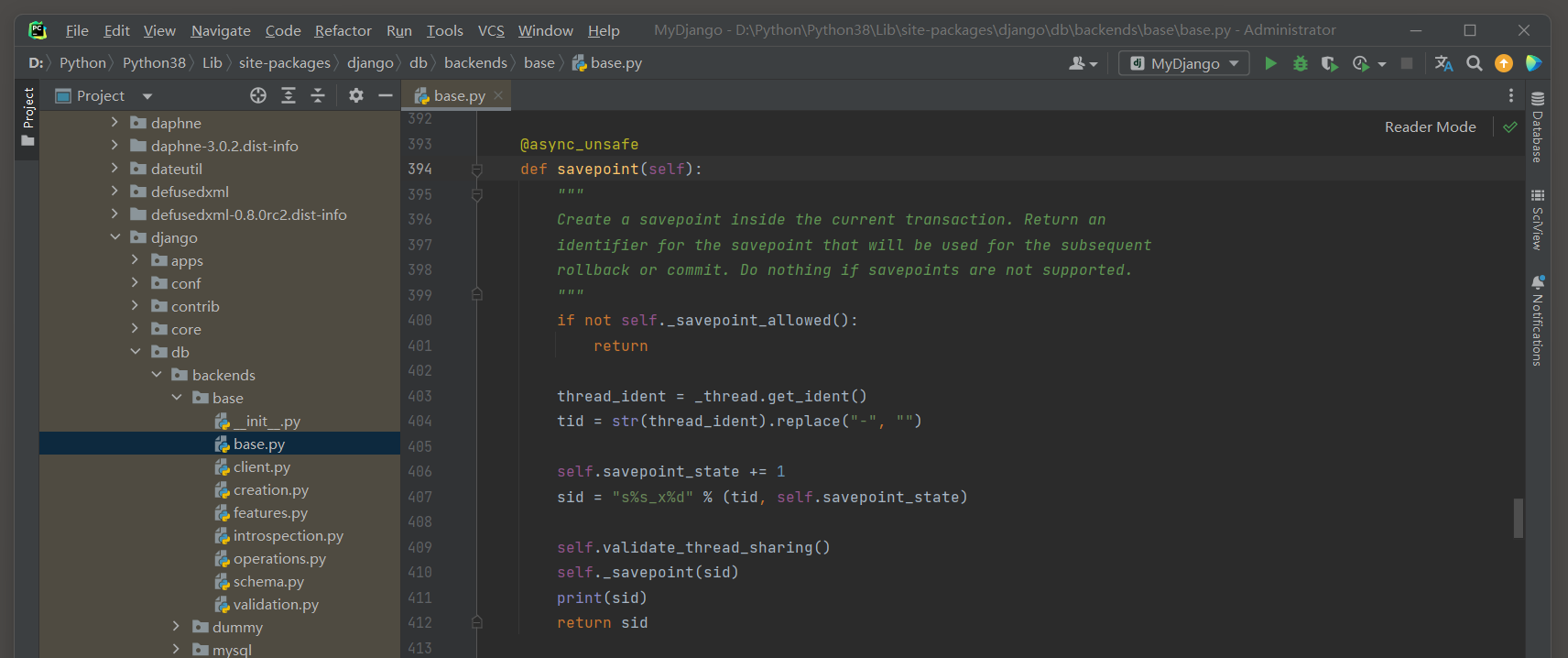
拿不到保存点, 觉得好玩就去修改源码, 想办法在视图中获取这个保存点,,,
- 1
3. 并发问题
在Django ORM中, 如果多个请求处理流程同时操作同一张数据库表, 可能会遇到一些与并发和数据一致性相关的问题. 这些问题主要包括: * 1. 数据竞争(Race Conditions): 当多个事务几乎同时尝试修改同一数据时, 会出现数据竞争. 例如, 两个用户同时尝试更新库存数量, 如果没有适当的锁定机制, 可能会导致库存数量被错误地减少. * 2. 脏读(Dirty Reads): 一个事务读取了另一个事务未提交的数据. 这可能导致读取到不一致的数据状态. * 3. 不可重复读(Non-repeatable Reads): 在同一个事务内, 多次读取同一数据集合时, 由于其他事务的修改, 导致每次读取的数据不一致. 换句话说, 即使在同一事务内, 也无法'重复'地读取到完全相同的数据集, 因为其他事务可以已经改变了这些数据. * 4. 幻读(Phantom Reads): 在同一个事务内, 当某个事务两次执行相同的查询时, 第二次查询的结果集包含了第一次查询中未出现的额外行(因为其他事务插入了新行). 解决方法: * 1. 使用数据库事务: 可以为每个请求开始时开启一个数据库事务, 并在请求结束时提交事务(如果没有异常发生). 这有助于确保单个请求内的操作是原子的. 然而, 对于跨请求或跨视图的事务, 可能需要显式地管理事务. * 2. 使用悲观锁(适用于写多读少的场景): 在数据库层面, 可以使用悲观锁来防止数据竞争. 例如, 在PostgreSQL中, 可以使用SELECT ... FOR UPDATE来锁定选定的行, 直到当前事务结束. 然而, Django ORM没有直接支持这种查询的简便方法, 可能需要编写原生SQL或使用第三方库. * 3. 使用乐观锁(适用于读多写少的场景): 乐观锁通常通过版本号或时间戳来实现. 在每次更新数据时, 检查版本号或时间戳是否自上次读取以来已更改. 如果已更改, 则拒绝更新并可能重试操作或通知用户. Django ORM没有内置的乐观锁支持, 但可以通过添加额外的字段(如: version)并在模型更新时检查该字段来实现. * 4. 使用缓存: 在某些情况下, 使用缓存可以减少对数据库的访问次数, 并可能间接地减少并发问题. 然而, 缓存本身并不解决并发问题, 只是减少了直接访问数据库的频率. * 5. 数据库级别的隔离级别: 可以调整数据库的事务隔离级别来减少并发问题. 然而, 这可能会影响到性能, 并且需要仔细考虑具体需求. * 6. 序列化访问: 在某些情况下, 可能需要确保对特定资源的访问是序列化的. 这可以通过在应用程序级别实现锁(如使用: Redis锁)来实现. 总之, 解决Django中多个视图操作同一张表时出现的问题通常涉及到数据库事务, 锁, 隔离级别以及应用程序级别的同步机制. 选择哪种方法取决于你的具体需求, 性能考虑以及所使用的数据库类型.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3.1 同步阻塞
在Django中, 默认情况下, 它使用了一个名为runserver的开发服务器, 它是为了开发和测试而设计的, 并非用于生产环境.
runserver使用的是wsgiref模块, 这是一个简单的Python模块, 用于创建简单的WSGI服务器.
wsgiref服务器是同步阻塞的, 这意味着在处理请求时, 服务器会阻塞其他请求.
这是因为在任何时间点, 只有一个线程在处理请求.
这是为了简化和开发方便而设计的, 但并不适合生产环境.
- 1
- 2
- 3
- 4
- 5
- 6
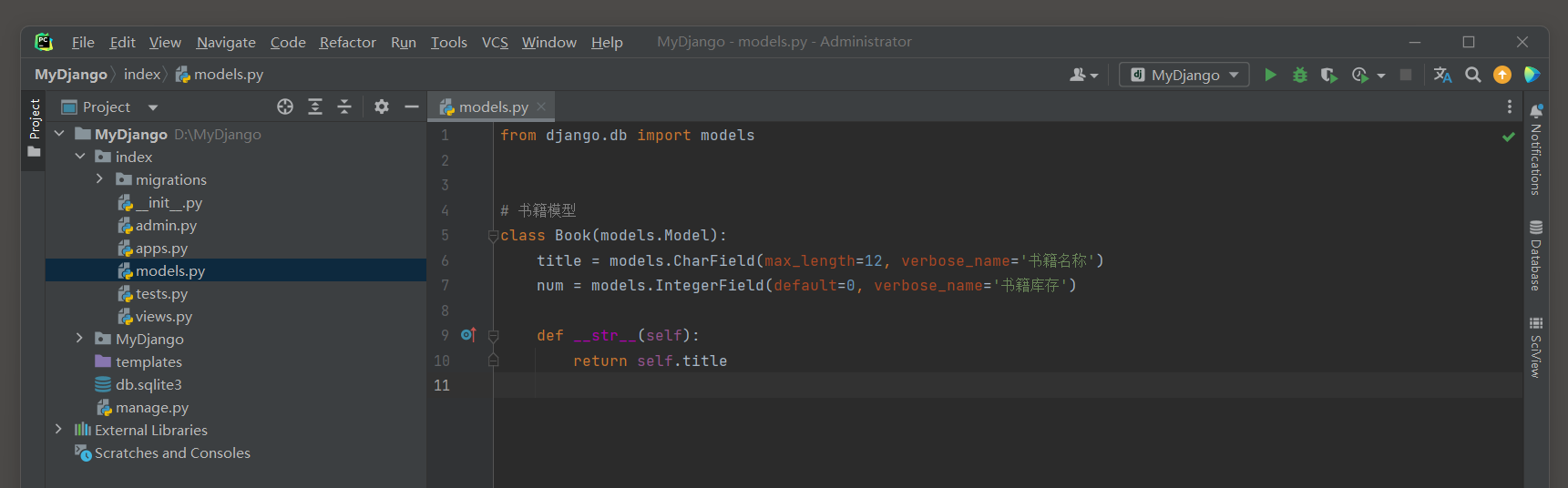
* 1. 创建一个模型.
- 1
# index/views.py
from django.db import models
# 书籍模型
class Book(models.Model):
title = models.CharField(max_length=12, verbose_name='书籍名称')
num = models.IntegerField(default=0, verbose_name='书籍库存')
def __str__(self):
return self.title
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
* 2. 运行: python manage.py makemigrations 和 python manage.py migrate 来创建数据库表.
* 3. 往书籍模型中插入一条数据.
- 1
- 2
# index/tests.py
import os
if __name__ == "__main__":
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'MyDjango.settings') # !!!需要修改为自己的配置文件
import django
django.setup()
from index.models import Book
# 创建模型
Book.objects.create(title='Python基础', num=10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
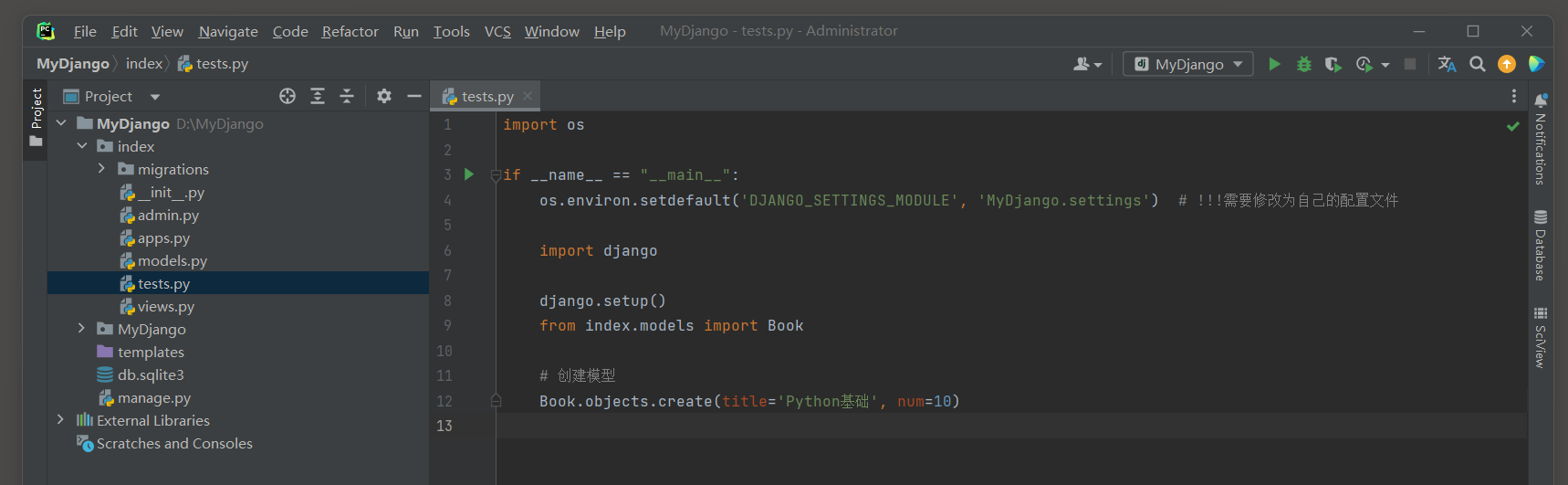
* 4. 查看index_book表数据.
- 1
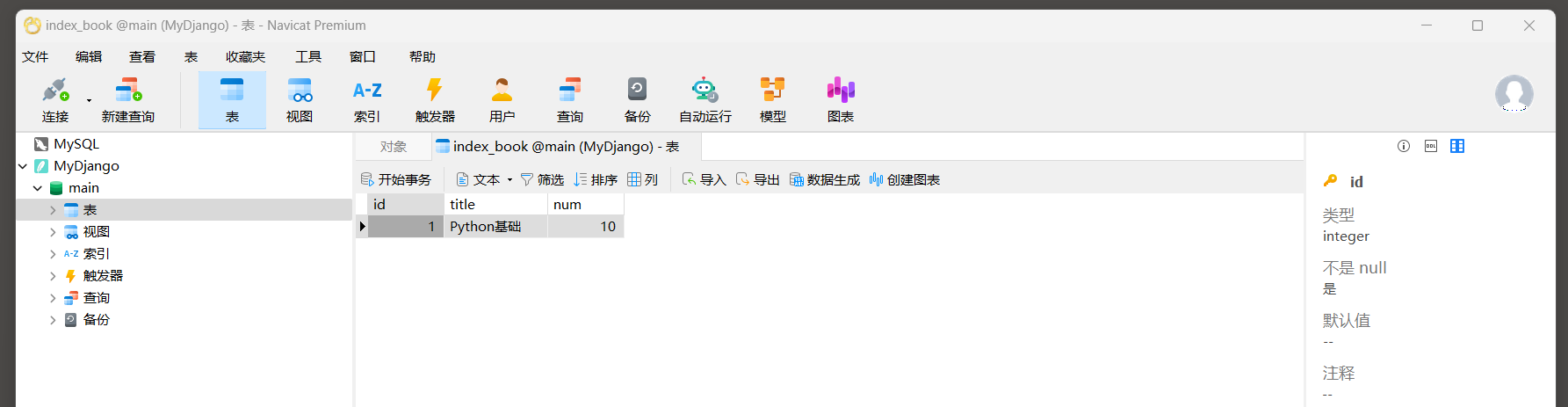
* 5. 编写视图函数, 视图从请求中获取数据并购买书籍:
- 1
# index/views.py from django.http import HttpResponse from index.models import Book def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 # 查询书籍实例 book = Book.objects.get(id=book_id) print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - int(num) # 延时, 等待另一个请求访问 import time time.sleep(5) # 更新数据 book.save() res_msg = '购买成功!' else: res_msg = '库存不足, 购买失败!' return HttpResponse(res_msg)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
* 6. 启动项目, 访问两次: http://127.0.0.1:8000/?book_id=1&num=5 , 由于同步阻塞, 在处理请求时, 服务器会阻塞其他请求.
- 1
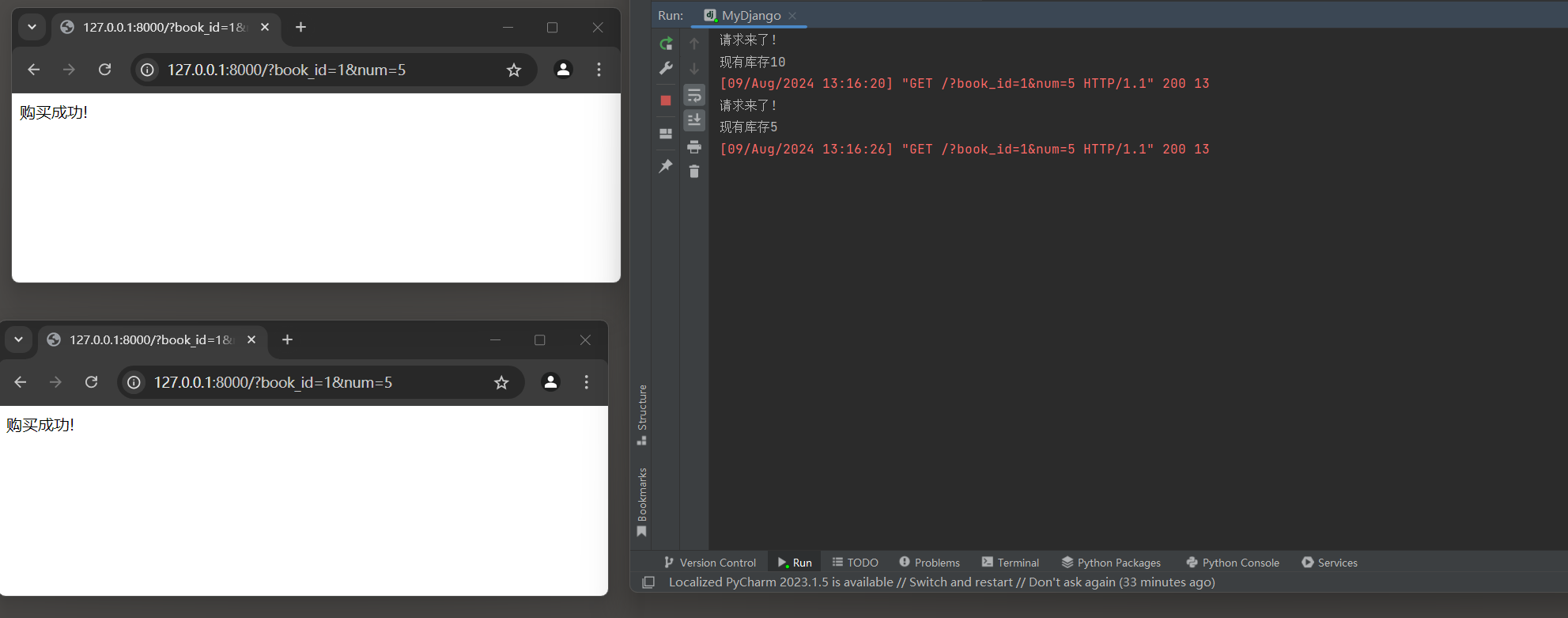
如果想在生产环境中使用Django, 应该使用像gunicorn或uWSGI这样的服务器, 它们是非阻塞的, 可以处理多个并发请求.
- 1
3.2 数据竞争
在高并发环境下, 当多个用户几乎同时发起对同一数据资源的查询与修改操作时, 会面临严峻的资源竞争问题.
如果多个用户几乎同时查询到某商品仍有库存, 并紧接着发起购买请求(即修改库存数量),
由于系统处理这些请求的时间差极短, 就可能导致库存数据被不恰当地多次减少, 从而引发最终库存数据异常的现象, 如库存出现负数或超卖等.
具体操作:
* 1. A用户开始操作: A用户首先检查库存量, 假设库存足够, 然后决定进行购买.
然而, 在A用户实际减少库存之前, 有一个时间间隙.
* 2. B用户介入: 在这个间隙期间, B用户也检查了库存, 并同样发现库存量足够, 因此也决定进行购买.
* 并发问题: 如果A用户和B用户都基于各自检查时的库存量来减少库存,
而没有适当的锁定或同步机制来确保在这段时间内只有一个用户能够修改库存, 那么两个用户都可能成功减少库存,
从而导致库存最终出现负数或低于实际应有的数量, 这显然是错误的.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个示例不好模拟出来, Django本身运行在单线程WSGI服务器, 等后续项目部署使用uwsgi启动项目的时候, 才好测试.
下面通过Python的多线程库(如threading)来模拟并发请求(实际中不应在视图函数中启动线程).
- 1
- 2
# index/views.py from django.http import HttpResponse from index.models import Book import threading def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 def set_book(): # 查询书籍实例 book = Book.objects.get(id=book_id) print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - num # 延时, 等待另一个请求访问 import time time.sleep(5) # 更新数据 book.save() print('购买成功!') else: print('库存不足, 购买失败!') # 创建多个线程来模拟并发 threads = [threading.Thread(target=set_book) for _ in range(3)] # 启动所有线程 for t in threads: t.start() return HttpResponse('测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
视图函数中, 多个线程被创建来执行set_book函数, 该函数访问并修改数据库中的书籍库存数量.
- 1
先把num恢复为10, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 ,
视图中多个线程几乎同时执行到book.num = book.num - num这一行,
它们会基于相同的初始库存数量来计算新的库存值, 然后各自更新数据库.
这会导致库存数量被错误地减少, 因为每个线程都不知道其他线程也在进行相同的操作.
- 1
- 2
- 3
- 4
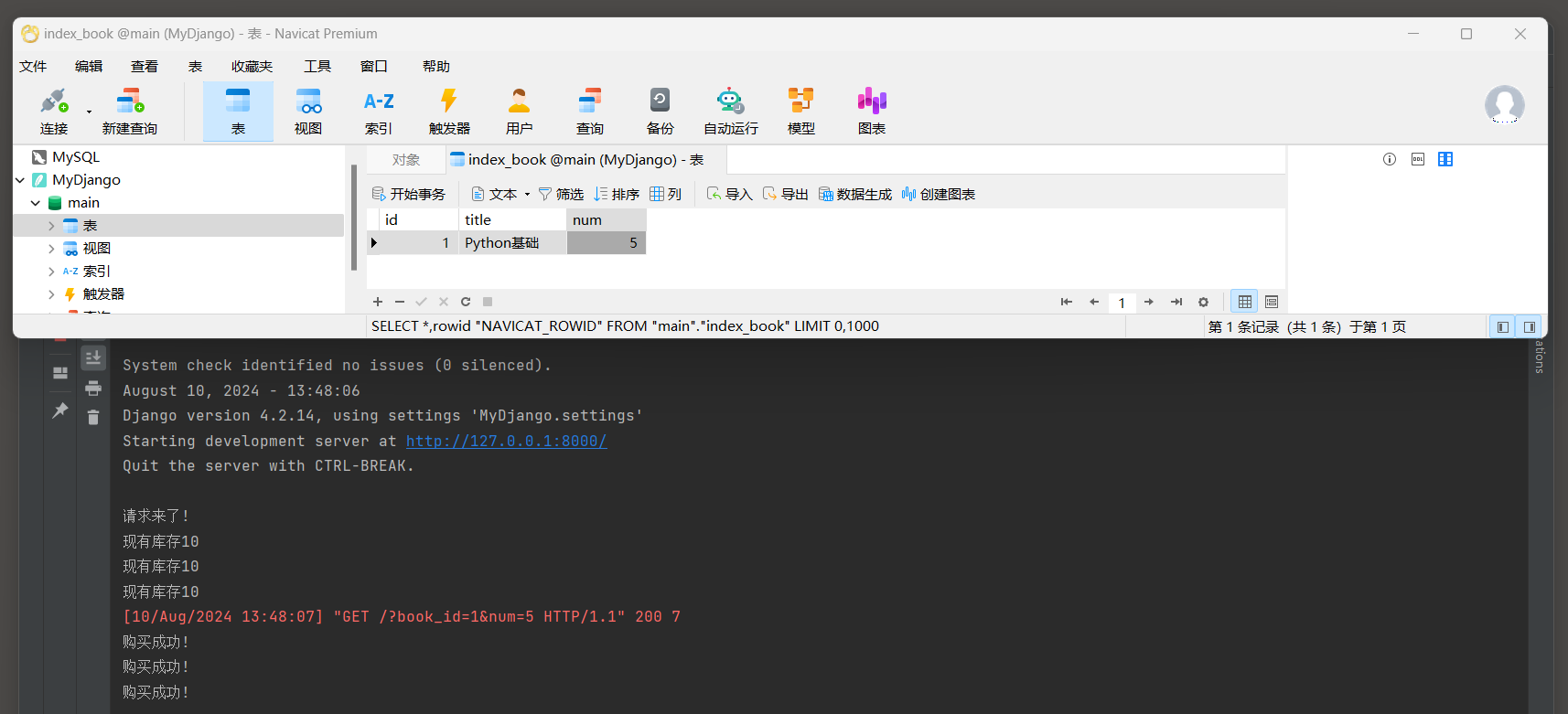
3.3 排他锁
在SQLite中, 默认情况下, 当一个事务正在修改表时, 它会锁定该表以阻止其他事务(包括只读事务)对该表的访问, 直到当前事务提交或回滚.
这种锁定机制(排他锁)是为了防止数据在并发修改时出现不一致的情况.
排他锁(Exclusive Lock), 也称为'FOR UPDATE'锁, 含义: 排除其他事务对同一数据资源执行某些操作的锁.
当某个事务对数据库中的某个数据行执行了排他锁(FOR UPDATE)操作时,
它会阻止其他事务对该数据行进行更新, 删除或再次加上排他锁(FOR UPDATE)操作, 直到该事务提交或回滚.
- 1
- 2
- 3
- 4
- 5
- 6
# index/views.py from django.http import HttpResponse from index.models import Book import threading from django.db import transaction def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 def set_book(): try: with transaction.atomic(): book = Book.objects.filter(id=book_id).first() print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - num # 延时, 等待另一个请求访问 import time time.sleep(5) # 更新数据, 加上排他锁!!! book.save() print('购买成功!') else: print('库存不足, 购买失败!') except Exception as e: print(e) # 创建多个线程来模拟并发 threads = [threading.Thread(target=set_book) for _ in range(3)] # 启动所有线程 for t in threads: t.start() return HttpResponse('测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
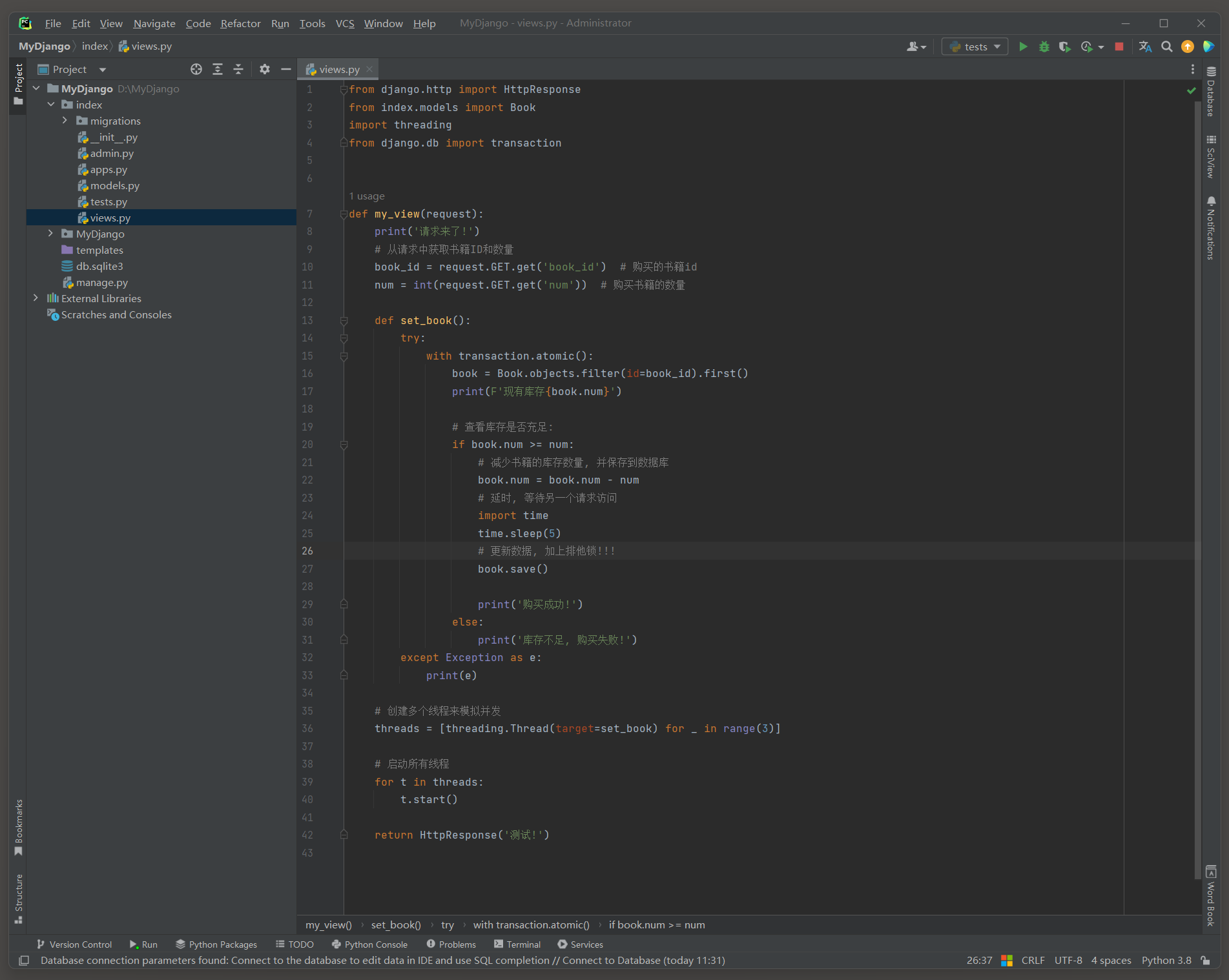
修改num为10, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 , 查询排他锁的情况.
三个线程在获取数据的时候没问题, 直到某一个线程修改数据, 这时会上锁, 其他线程修改数据的操作则报错.
- 1
- 2
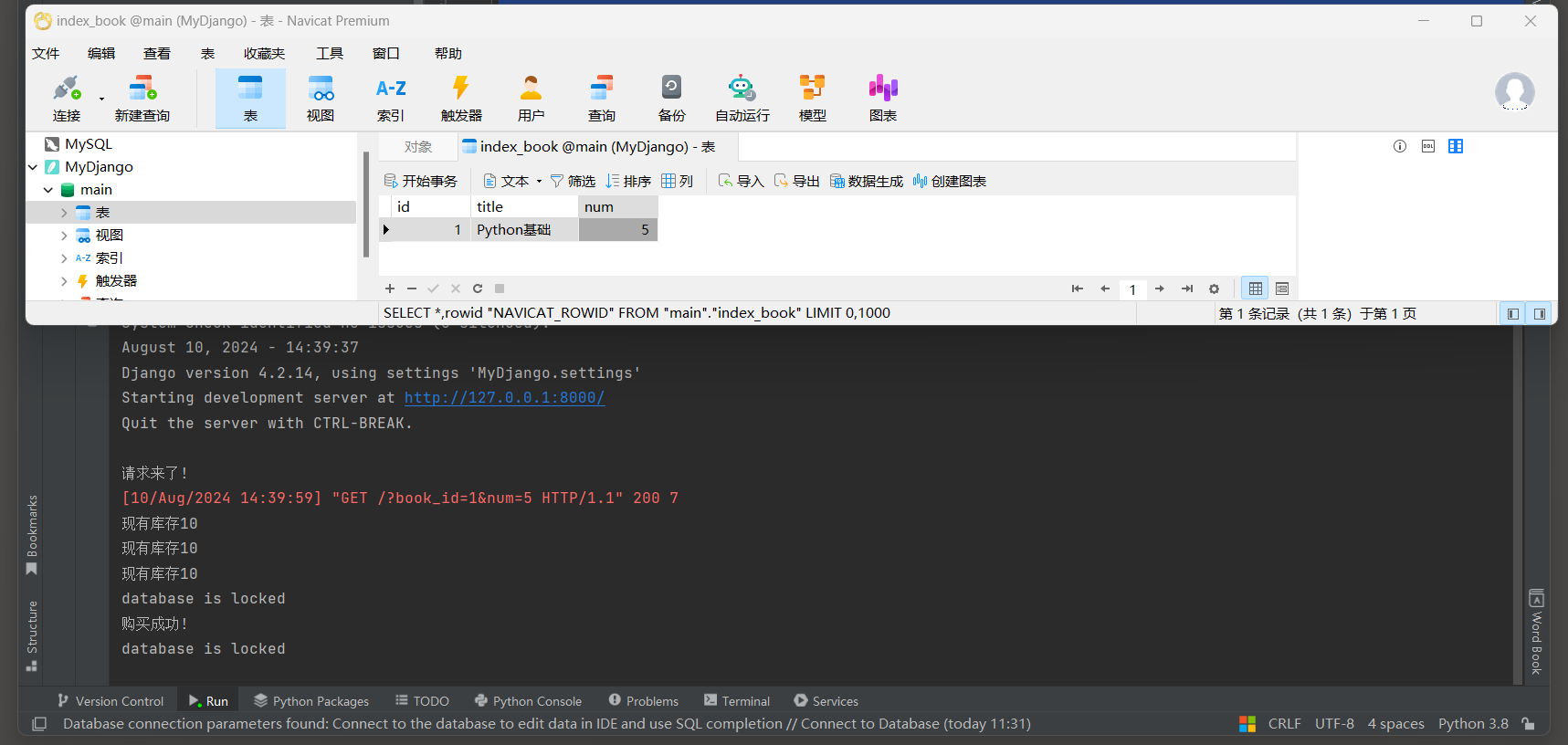
3.3 悲观锁
悲观锁是数据库并发控制的一种方式.
它基于'悲观的态度'认为在数据处理过程中很可能会发生冲突, 因此在数据处理前就通过加锁的方式来避免冲突.
Django中常用的悲观锁实现方式是使用select_for_update()方法, 这个方法会在查询时加上排他锁.
这意味着在事务提交或回滚之前, 其他事务无法修改这些被锁定的数据行.
- 1
- 2
- 3
- 4
- 5
select_for_update()方法可以接受一些参数来定制锁的行为: * 1. nowait: 布尔值, 默认为False. 如果设置为True, 则如果所选的行已被其他事务锁定, 则查询将立即引发DatabaseError异常, 而不是等待锁释放. * 2. skip_locked: 布尔值, 默认为False. 如果设置为True, 则查询将跳过已被其他事务锁定的行, 只返回未锁定的行. 注意事项: * 使用方式: select_for_update()必须在数据库事务的上下文中使用, 否则锁将不会生效. 可以使用Django的transaction.atomic()装饰器或上下文管理器来定义事务. * 数据库支持: 不是所有的数据库都支持select_for_update()方法, Django的select_for_update()方法主要支持PostgreSQL, MySQL(InnoDB引擎)和Oracle等数据库. * 锁的范围: select_for_update()加锁的范围是整个查询集(QuerySet), 如果查询集包含多行数据, 则这些行都会被锁定. * 锁的粒度: 在使用悲观锁时, 需要注意锁的粒度, 过细的粒度可能会导致性能下降, 而过粗的粒度则可能会限制并发性能. 锁的粒度(锁覆盖的范围)分类: 表级锁, 页级锁, 行级锁, 段级锁, 细粒度锁. * 死锁: 在多个事务互相等待对方释放锁时, 可能会发生死锁. Django和数据库管理系统通常会提供死锁检测和解决的机制, 但在设计并发控制策略时仍需要注意避免死锁的发生.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
以下是一个使用select_for_update()方法实现悲观锁的简单示例(使用MySQL数据库, sqlite不支持):
- 1
# index/views.py from django.http import HttpResponse from index.models import Book import threading from django.db import transaction def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 def set_book(): try: # 开启事务 with transaction.atomic(): # 获取书籍对象并加锁, 会阻塞其他使用表的进程 book = Book.objects.select_for_update().filter(id=book_id).first() print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - num # 延时, 等待另一个请求访问 import time time.sleep(5) # 更新数据 book.save() print('购买成功!') else: print('库存不足, 购买失败!') except Exception as e: print(e) # 创建多个线程来模拟并发 threads = [threading.Thread(target=set_book) for _ in range(3)] # 启动所有线程 for t in threads: t.start() return HttpResponse('测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47

先把num恢复为10, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 ,
第一个进程使用排他锁后, 其他进程会阻塞并等待锁的释放..., 终端显示(加上日志太乱了, 就不截图了):
- 1
- 2
请求来了!
现有库存10
购买成功!
现有库存5
购买成功!
现有库存0
库存不足, 购买失败!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
READ COMMITTED(读取已提交): 是数据库事务的一个隔离级别.
在这个隔离级别下, 事务只能读取到已经被其他事务提交(committed)的数据更改.
这意味着, 如果一个事务正在修改数据但尚未提交, 那么其他事务将无法读取到这些未提交的数据更改.
这种隔离级别有助于避免脏读(dirty reads), 即读取到尚未被提交的数据.
- 1
- 2
- 3
- 4
# ORM日志 # 设置会话事务隔离级别: READ COMMITED (0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None; alias=default (0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None; alias=default (0.000) SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; args=None; alias=default # 读取数据并上锁(排他锁) (0.000) SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`num` FROM `index_book` WHERE `index_book`.`id` = 1 ORDER BY `index_book`.`id` ASC LIMIT 1 FOR UPDATE; args=(1,); alias=default # 更新数据, 库存为5 (0.000) UPDATE `index_book` SET `title` = 'Python基础', `num` = 5 WHERE `index_book`.`id` = 1; args=('Python基础', 5, 1); alias=default # 提交事务 (0.016) COMMIT; args=None; alias=default # 被排他锁阻塞, 看时间被阻塞了5秒, 可以设置nowait参数控制是否等待锁的释放 (5.031) SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`num` FROM `index_book` WHERE `index_book`.`id` = 1 ORDER BY `index_book`.`id` ASC LIMIT 1 FOR UPDATE; # 上锁 args=(1,); alias=default # 更新数据, 库存为5 (0.000) UPDATE `index_book` SET `title` = 'Python基础', `num` = 0 WHERE `index_book`.`id` = 1; args=('Python基础', 0, 1); alias=default # 提交事务 (0.016) COMMIT; args=None; alias=default # 被排他锁阻塞, 看时间被阻塞了10秒 (10.047) SELECT `index_book`.`id`, `index_book`.`title`, `index_book`.`num` FROM `index_book` WHERE `index_book`.`id` = 1 ORDER BY `index_book`.`id` ASC LIMIT 1 FOR UPDATE; args=(1,); alias=default # 提交事务 (0.000) COMMIT; args=None; alias=default
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
3.4 乐观锁
总是认为不会产生并发问题, 每次去取数据的时候总认为不会有其他线程对数据进行修改,
因此不会上锁, 但是在更新时会判断其他线程在这之前有没有对数据进行修改.
在Django中, 默认没有直接支持乐观锁(Optimistic Locking)的内置机制, 但可以通过自定义模型字段和逻辑来实现乐观锁.
乐观锁主要用于解决在高并发环境下, 多个事务同时更新同一数据资源时可能导致的更新丢失问题.
乐观锁的基本思想是, 在读取数据时不加锁, 而在更新数据时通过某种机制来检测数据是否在此期间被其他事务修改过.
如果数据未被修改, 则执行更新操作; 如果数据已被修改, 则通常选择回滚事务或抛出异常.
在Django中实现乐观锁的一种常见方法是添加一个版本号(version)或时间戳(timestamp)字段到模型中,
并在每次更新数据时检查这个版本号或时间戳是否变化.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
示例, 现在有一个Book模型, 并希望使用版本号来实现乐观锁:
- 1
# index/views.py from django.db import models # 书籍模型 class Book(models.Model): title = models.CharField(max_length=12, verbose_name='书籍名称') num = models.IntegerField(default=0, verbose_name='书籍库存') # 版本号 version = models.IntegerField(default=0, editable=False, verbose_name='版本号') def __str__(self): return self.title # 重写save方法, 在保存之前, 检查版本是否已更改 def save(self, *args, **kwargs): # 内部属性, 用于指示当前的模型实例是否是一个新创建的实例, 即是否正在被添加到数据库中. if self._state.adding: pass # 如果是新创建的实例, 则无需检查版本 # 更新数据 else: # 获取目前版本, 例: {'version': 1} current_version = Book.objects.filter(id=self.id).values('version').first() # 非空 and x and y if current_version and current_version['version'] != self.version: raise Exception("数据已被其他事务修改") # 更新版本号 self.version += 1 super().save(*args, **kwargs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

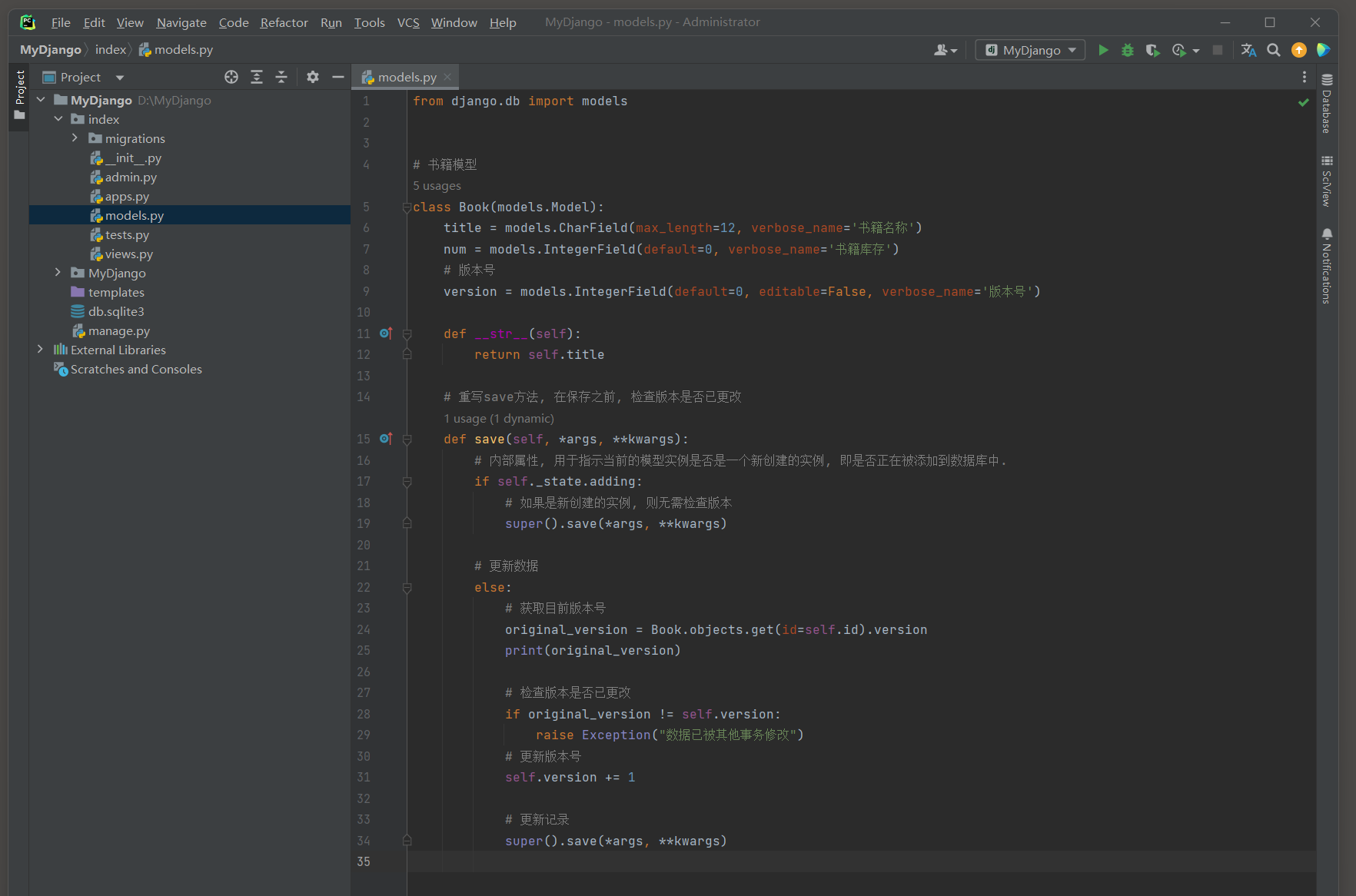
运行: python manage.py makemigrations 和 python manage.py migrate 来更新数据库表.
- 1
# index/models.py from django.db import models # 书籍模型 class Book(models.Model): title = models.CharField(max_length=12, verbose_name='书籍名称') num = models.IntegerField(default=0, verbose_name='书籍库存') # 版本号 version = models.IntegerField(default=0, editable=False, verbose_name='版本号') def __str__(self): return self.title # 重写save方法, 在保存之前, 检查版本是否已更改 def save(self, *args, **kwargs): # 内部属性, 用于指示当前的模型实例是否是一个新创建的实例, 即是否正在被添加到数据库中. if self._state.adding: # 如果是新创建的实例, 则无需检查版本 super().save(*args, **kwargs) # 更新数据 else: # 获取目前版本号 original_version = Book.objects.get(id=self.id).version print(original_version) # 检查版本是否已更改 if original_version != self.version: raise Exception("数据已被其他事务修改") # 更新版本号 self.version += 1 # 更新记录 super().save(*args, **kwargs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
# index/views.py from django.http import HttpResponse from index.models import Book import threading from django.db import transaction import time def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 def set_book(): with transaction.atomic(): book = Book.objects.filter(id=book_id).first() print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - num # 延时... time.sleep(1) # 更新数据 book.save() print('购买成功!') else: print('库存不足, 购买失败!') # 创建多个线程来模拟并发 threads = [threading.Thread(target=set_book) for _ in range(3)] # 启动所有线程 for t in threads: # 时间太块就会出问题, 所以延时启动 time.sleep(1) t.start() return HttpResponse('测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
把num恢复为10, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 , 查看乐观锁的使用情况.
测试中出现的问题, 请求操作太快, 导致多次读操作获取了同一个值, 写操作的时候也没有检查出version字段的变化.
- 1
- 2
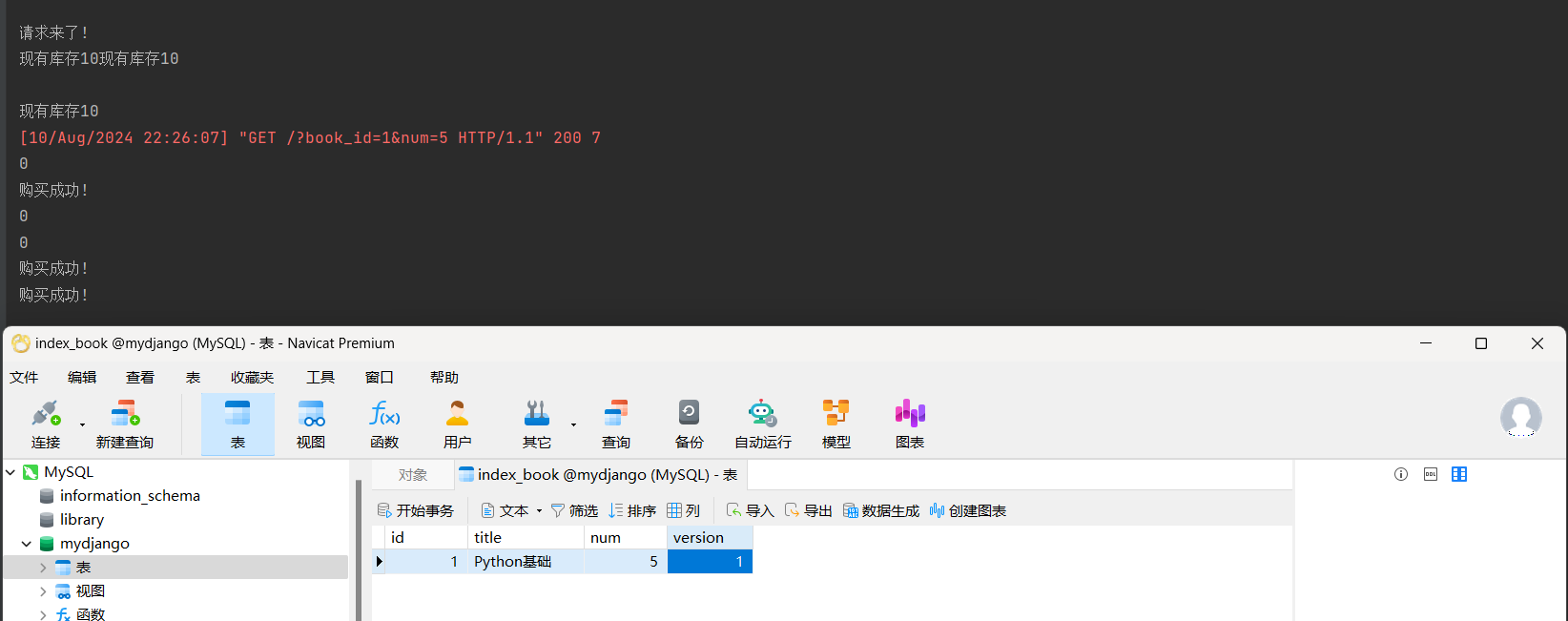
乐观锁的使用场景主要集中在那些数据冲突较少, 读操作远多于写操作的场景中.
测试中由于线程执行速度过快导致版本号(或时间戳)在多个线程中读取到的值相同, 从而无法正确检测数据变化,
这通常是因为这些线程几乎同时读取了数据行, 并在几乎相同的时间点尝试更新它.
- 1
- 2
- 3
在读取数据之后, 在尝试更新之前, 可以在每个线程中引入一些随机或固定的延迟.
这虽然不是一个优雅的解决方案, 但可以作为临时措施来测试问题是否确实由于速度过快引起.
注意:
如果使用是sqlite数据库数据在写入的时候会上锁, 可能会导致: django.db.utils.OperationalError: database is locked 错误.
如果使用的mysql数据库, 则会出现之前描述的错误, 无法正确检测数据变化(下面为mysql的).
- 1
- 2
- 3
- 4
- 5
- 6
# index/views.py from django.http import HttpResponse from index.models import Book import threading from django.db import transaction import time def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 def set_book(): with transaction.atomic(): book = Book.objects.filter(id=book_id).first() print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - num # 延时, 等待其他请求 time.sleep(1) # 更新数据 book.save() print('购买成功!') else: print('库存不足, 购买失败!') # 创建多个线程来模拟并发 threads = [threading.Thread(target=set_book) for _ in range(3)] # 启动所有线程 for t in threads: # 时间太块就会出问题, 所以延时启动 time.sleep(1) t.start() return HttpResponse('测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
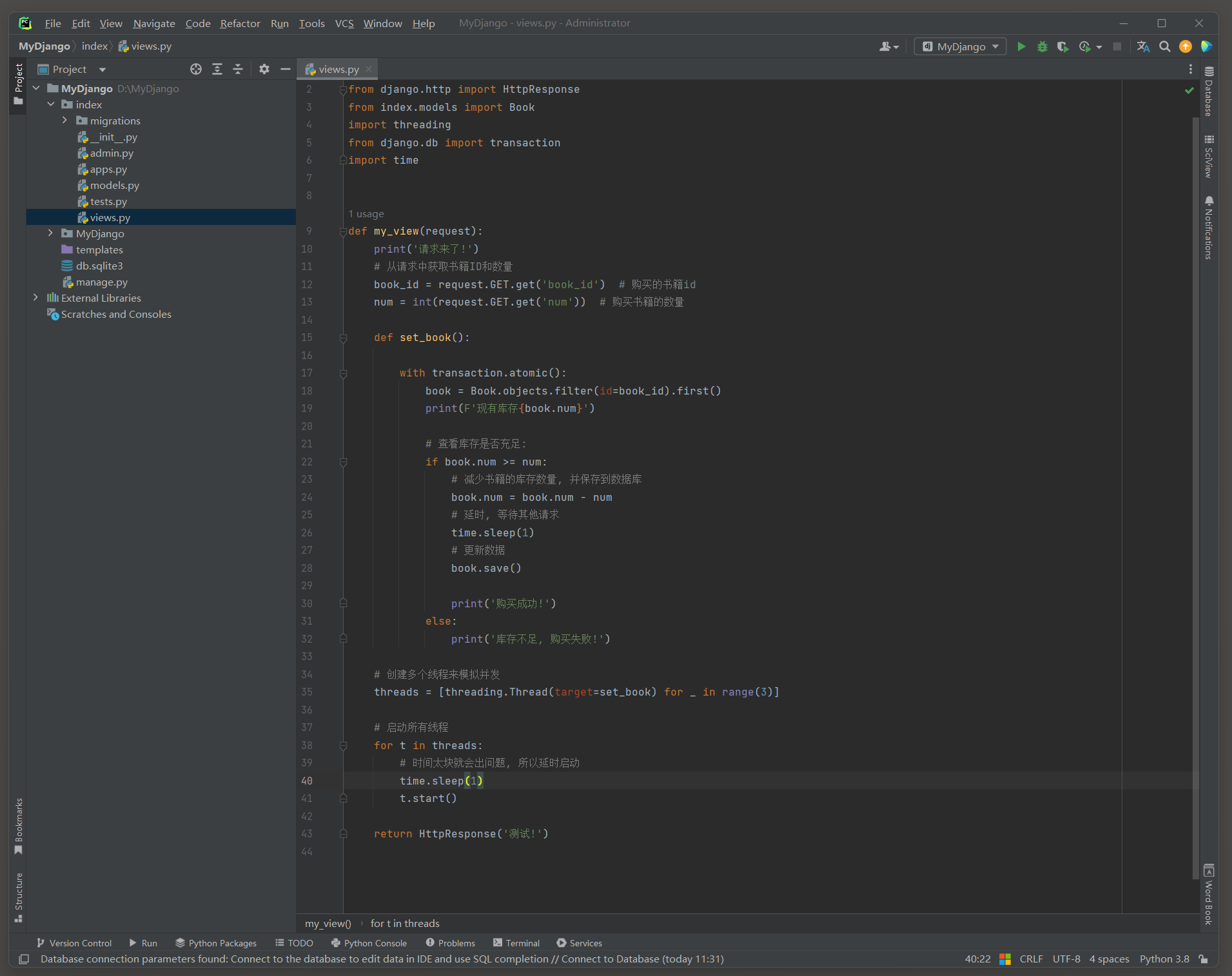
把num恢复为10, version恢复为0, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 , 查看乐观锁的使用情况.
时间调整的不太好, 不过效果也体现出来了, 在检测到版本变化的时候抛出了一次.
- 1
- 2
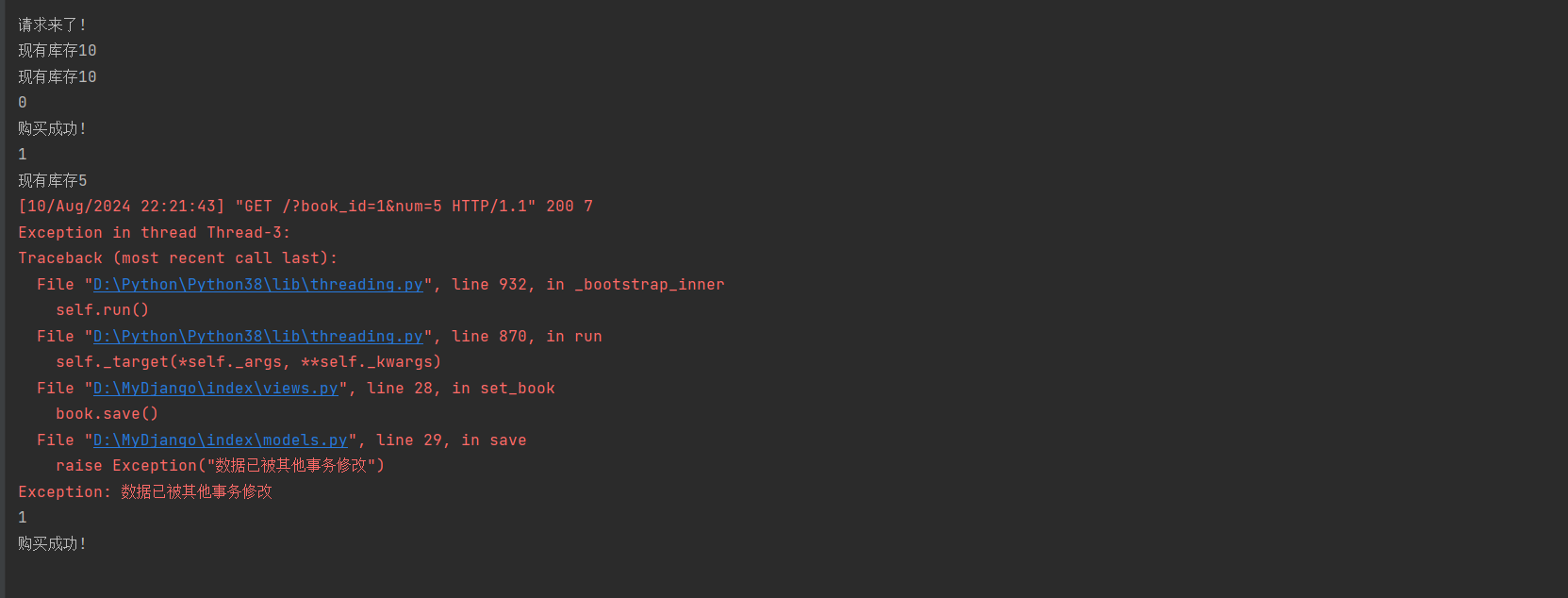
重行条件启动线程的时间, 最后这个延时期间, 前一个线程能够结束.
- 1
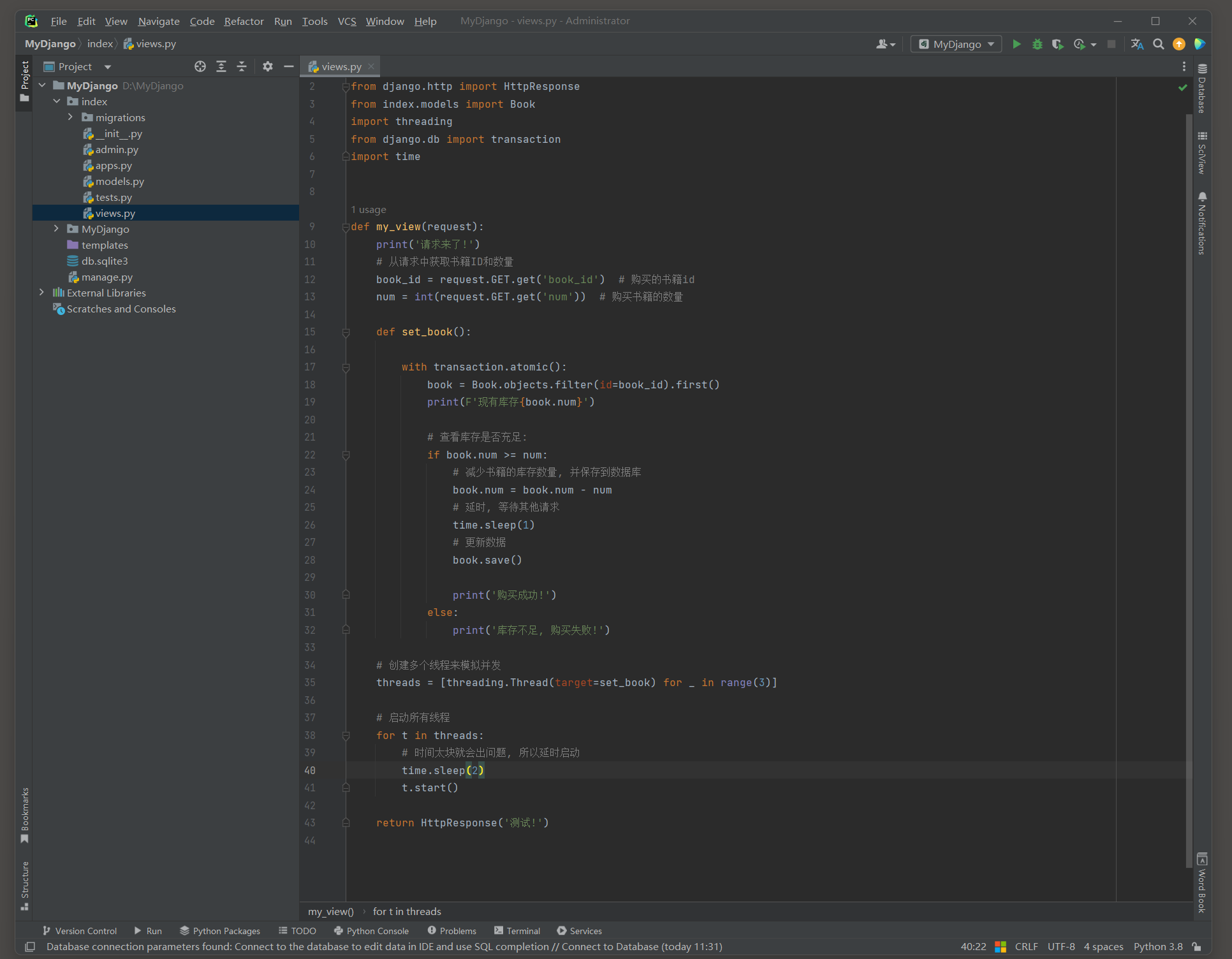
把num恢复为10, version恢复为0, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 , 查看乐观锁的使用情况.
这样的做法牺牲了响应的速度, 但是保证了数据的安全.
- 1
- 2
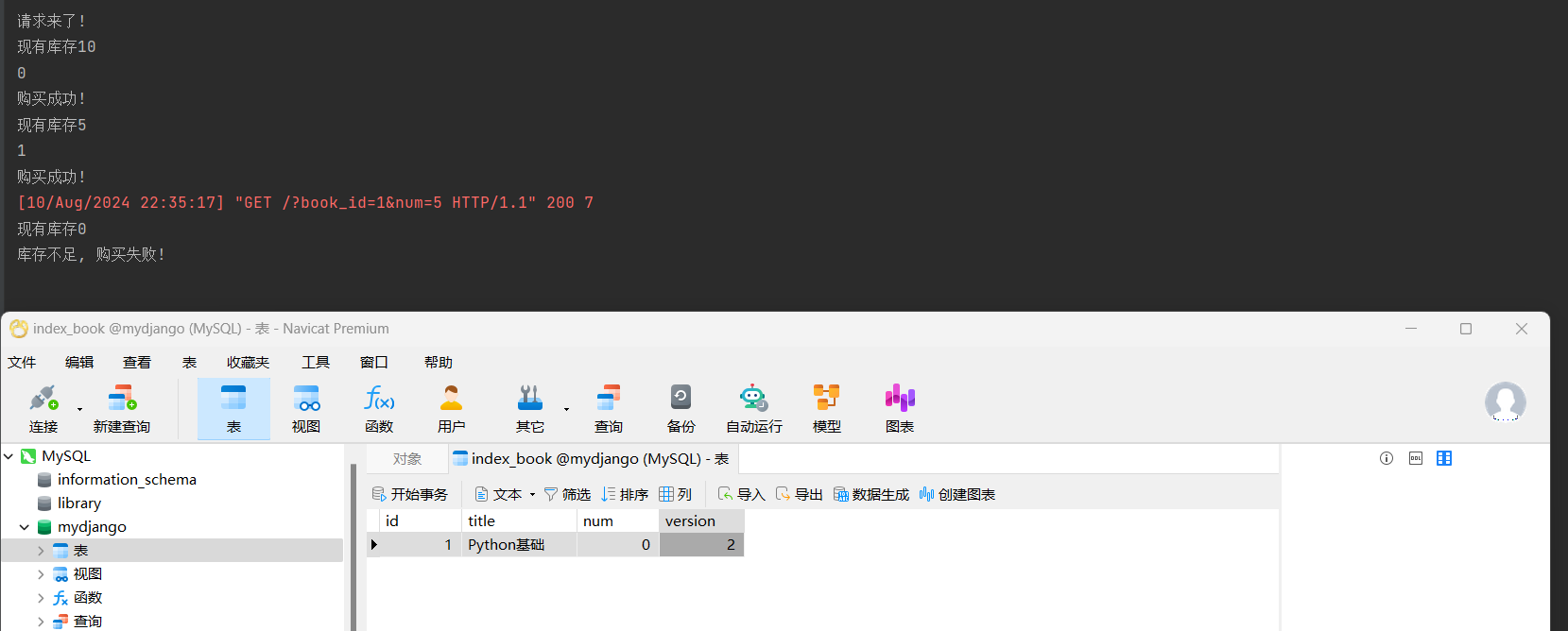
将启动线程之间的延时代码注销掉, 把num恢复为10, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 , 查看情况.
- 1
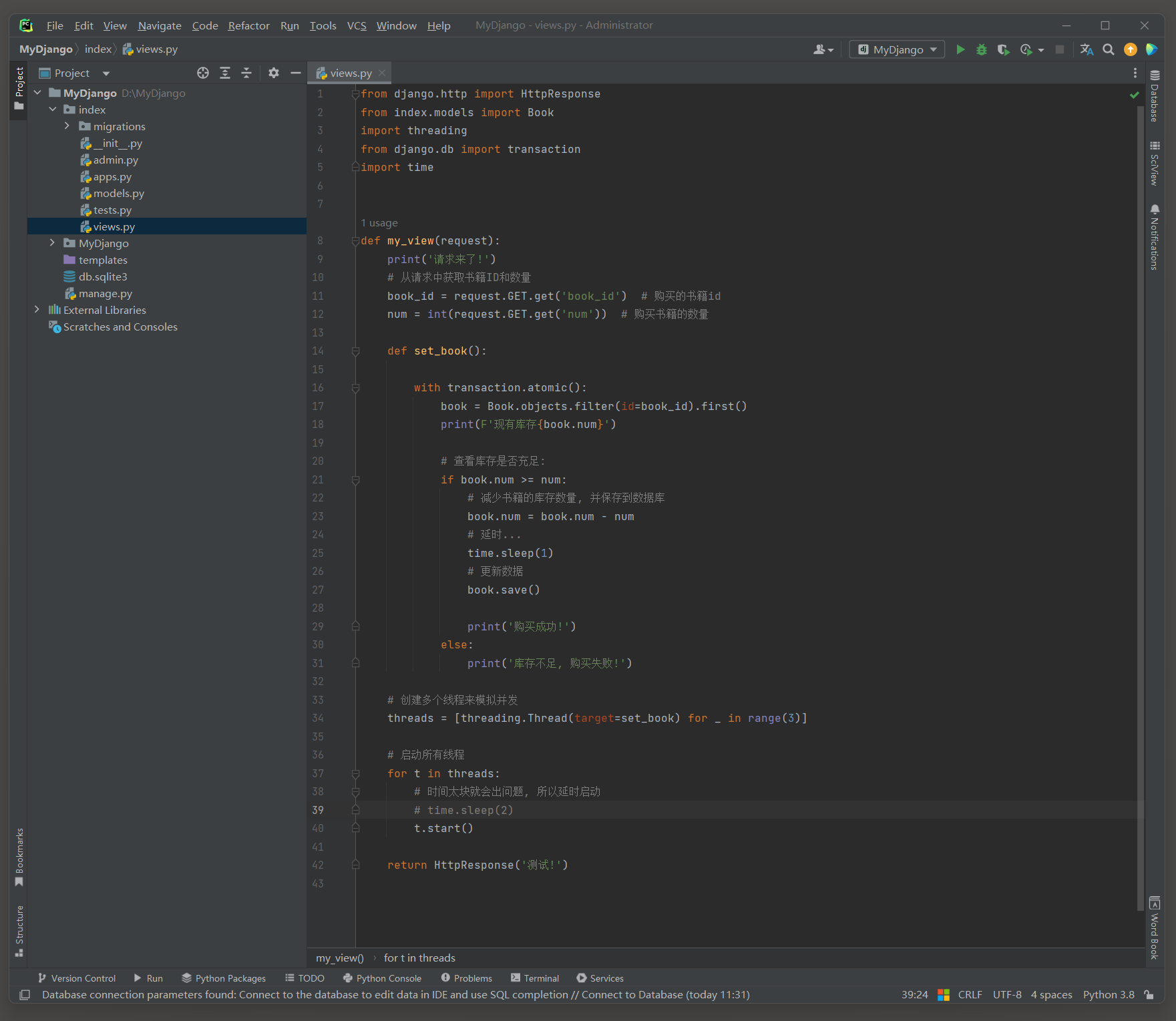
一个更合适的做法是在更新查询时直接使用F()表达式.
- 1
from django.db.models import F
Book.objects.filter(id=some_id, version=F('version')).update(num=new_num, version=F('version') + 1)
- 1
- 2
- 3
- 4
# index/views.py from django.http import HttpResponse from index.models import Book import threading from django.db import transaction import time from django.db.models import F def my_view(request): print('请求来了!') # 从请求中获取书籍ID和数量 book_id = request.GET.get('book_id') # 购买的书籍id num = int(request.GET.get('num')) # 购买书籍的数量 def set_book(): with transaction.atomic(): book = Book.objects.filter(id=book_id).first() print(F'现有库存{book.num}') # 查看库存是否充足: if book.num >= num: # 减少书籍的库存数量, 并保存到数据库 book.num = book.num - num # 延时... time.sleep(1) # 更新数据 Book.objects.filter(id=book_id, version=F('version')).update(num=book.num , version=F('version') + 1) print('购买成功!') else: print('库存不足, 购买失败!') # 创建多个线程来模拟并发 threads = [threading.Thread(target=set_book) for _ in range(3)] # 启动所有线程 for t in threads: # 时间太块就会出问题, 所以延时启动 time.sleep(2) t.start() return HttpResponse('测试!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
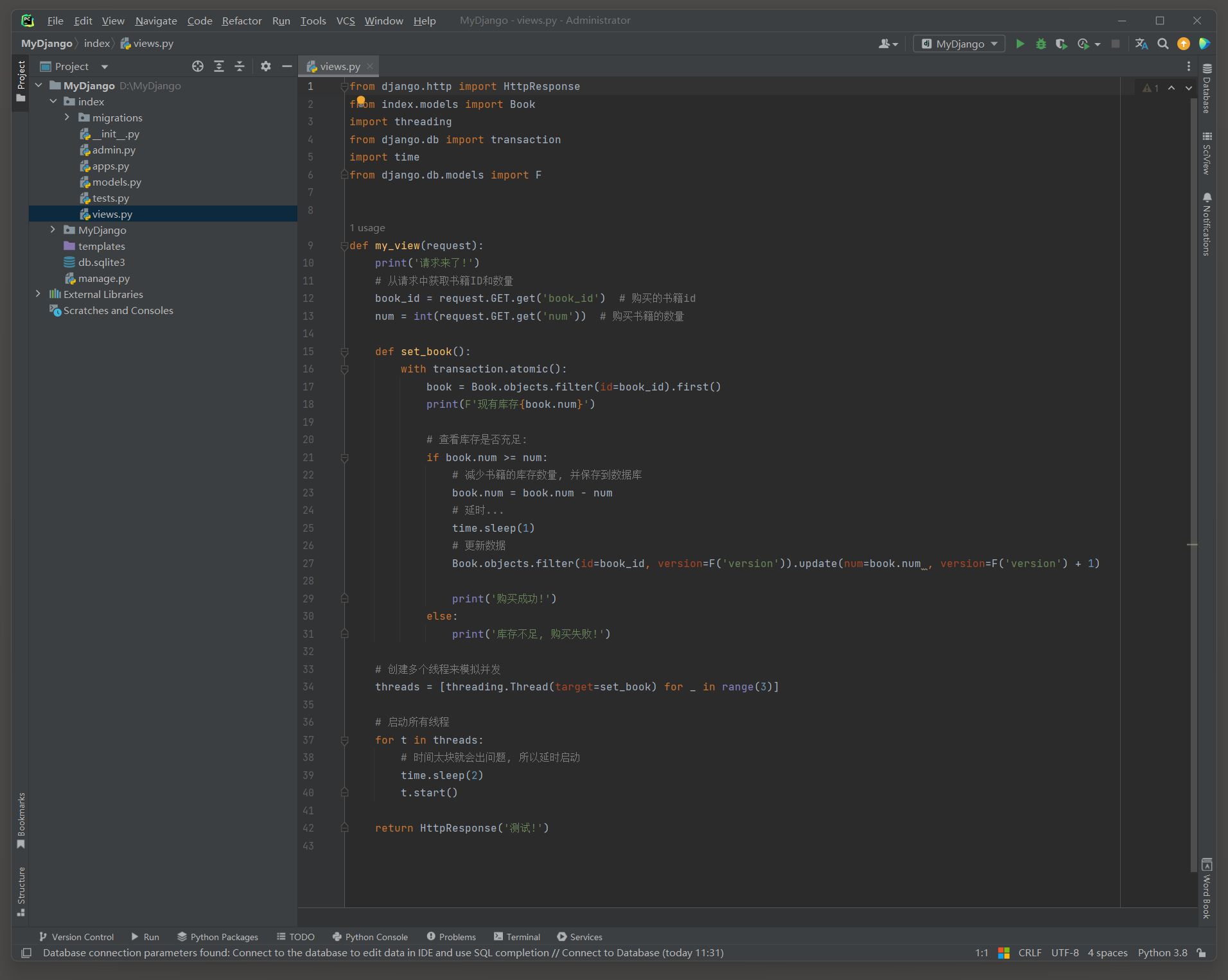
把num恢复为10, version恢复为0,, 启动项目, 访问: http://127.0.0.1:8000/?book_id=1&num=5 , 查看情况.
- 1
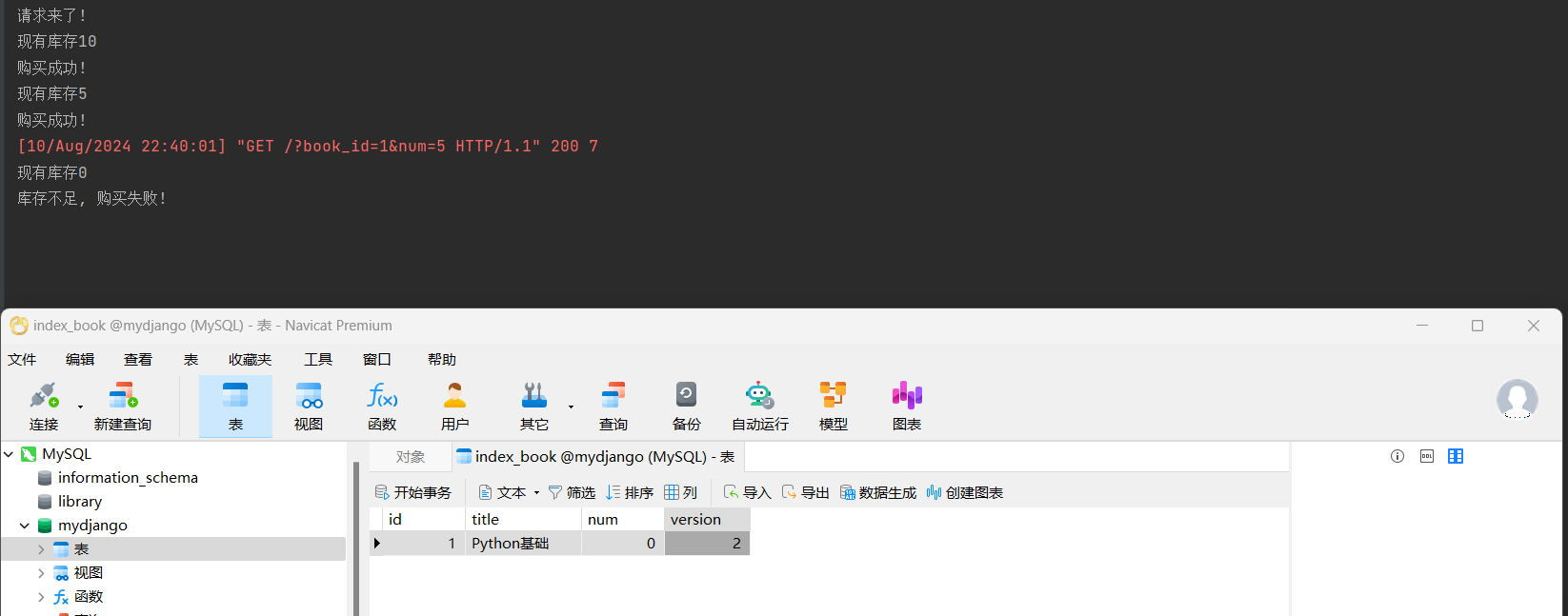
这个操作的详细效果描述:
* 1. 条件筛选: Book.objects.filter(id=some_id, version=F('version')),
这部分首先会查找所有id等于some_id且version字段值等于当前记录version字段值的Product实例.
这里的关键是F('version, 它告诉Django在数据库层面进行比较, 而不是在Python代码中.
这意味着, Django会生成一个SQL查询, 该查询会查找数据库中id和version字段都匹配当前记录对应值的行.
SQL: SELECT "index_book"."id", "index_book"."title", "index_book"."num", "index_book"."version"
FROM "index_book" WHERE ("index_book"."id" = 1 AND "index_book"."version" = ("index_book"."version")) LIMIT 21;
* 2. 更新操作: .update(num=new_num, version=F('version') + 1), 这部分会对上一步筛选出来的记录进行更新.
它将num字段更新为new_stock(这是一个Python变量, 表示新的库存数量), 并将version字段增加1.
这里再次使用了F()表达式来确保version的更新是基于数据库中的当前值, 而不是Python代码中的某个旧值.
SQL: UPDATE "index_book" SET "num" = 1, "version" = ("index_book"."version" + 1)
WHERE ("index_book"."id" = 1 AND "index_book"."version" = ("index_book"."version"));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/966875
推荐阅读
相关标签

