
- 1外包干了8天,技术退步明显......
- 2【转】数据安全无小事:揭秘华为云GaussDB(openGauss)全密态数据库_数据库软件产品的安全架构
- 3世界上最强大的人工智能软件工程师——Genie_ai程序员genie
- 4STM32烧写hex及bin文件的五种方法_keil直接烧写bin文件
- 5银联支付(一)申请测试环境,并运行测试demo(在线网关支付)_银行在线支付demo
- 6PCI、PCIe 一篇搞定_pci pcie
- 7大模型是这样炼成的_大模型是怎么训练出来的
- 8Beyond Compare 软件如何永久试用?_beyond compare无限试用
- 9鸿蒙界面开发_鸿蒙页面逻辑怎么写
- 10kafka 消费组 分区分配策略
Python爬虫(2) --爬取网页页面_爬虫抓取页面介绍
赞
踩
爬虫
Python 爬虫是一种自动化工具,用于从互联网上抓取网页数据并提取有用的信息。Python 因其简洁的语法和丰富的库支持(如 requests、BeautifulSoup、Scrapy 等)而成为实现爬虫的首选语言之一。
Python爬虫获取浏览器中的信息,实际上是模仿浏览器上网的行为。完成获取信息需要完成三步:
- 指定url
- 发送请求
- 获取你想要的数据
比如我们爬取一个网站的页面:
https://www.sogou.com/
- 1
URL
URL(Uniform Resource Locator,统一资源定位符)是互联网上用来标识资源的字符串,它告诉Web浏览器或其他网络程序如何访问特定的文件或网页。简单来说,URL就是网页的地址。
那我们怎么寻找网页的url呢?
浏览器中找到网页页面,点击按钮F12进入开发者控制台(Developer Console)。

第一步点击Network,第二步刷新页面,第三步滚动滚轮找到最上面的一项打开:
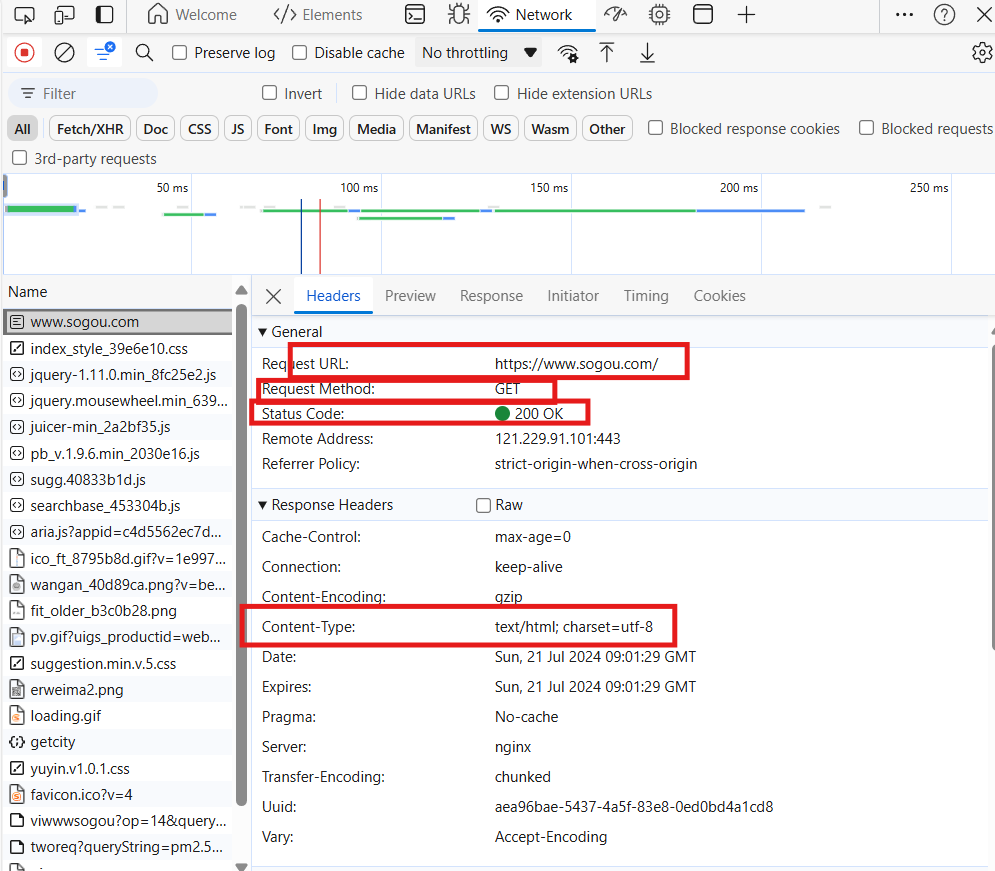
我们可以看到:网页的url地址、以及它的请求方式是get请求、Status Code在200和300是属于正常的、类型是text/html形式的。
好,那我们先指定url地址:
url = "https://www.sogou.com/"
- 1
发送请求
找到网址之后,我们当然得要获取它,这样我们就需要申请访问它的网址。
访问别人,当然自己得有个身份,怎么为自己伪装一个身份呢?
UA伪装
在python内下载fake_useragent包,这里面是别人以及写好的UA,使用这个包会为我们随机提供一个身份。
pip install fake_useragent
- 1
下载好之后导入包:
import fake_useragent
- 1
接下来运用这个包来进行UA伪装:
head = {
"User-Agent":fake_useragent.UserAgent().random #"User-Agent"固定写法哦
}
- 1
- 2
- 3
这样我们就有身份来发生请求啦!
requests
在Python中,发生请求使用requests方法。使用这个方阿飞之前呢,我们也还需要安装一个requests包:
pip install requests
- 1
下载好之后导入包:
import requests
- 1
接下来我们来使用这个包来发送请求:
response = requests.get(url,headers=head)
#以head的伪装身份访问url,将返回的数据放在response对象内
- 1
- 2
这样我们就请求完成了。
获取想要的数据
之前我们在开发者控制台中看到,网页的类型是text/html形式的。
请求完成之后,我们将请求到的内容接收一下:
res_text = response.text
print(res_text)
--------------------
print(response.status_code)
#可以加上这个代码,验证请求是否成功:
200:请求成功。通常表示服务器成功返回了请求的网页。
404:未找到。通常表示服务器无法找到请求的资源(网页)。
500:内部服务器错误。通常表示服务器遇到了一个意外情况,导致其无法完成对请求的处理。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将接收到的内容打印出来。
打开网页
在PyCharm中,建立一个HTML文本,将接收打印出来的数据内容复制进HTML文本中:
进入HTML文本,右上角会有浏览器浮现,选择你要使用的浏览器打开,就会进去获取的网页中。
总结
本篇介绍了:如何爬取网页的一个页面。
- 指定url
- 发送请求:requests请求方法
- UA伪装:使用fake_useragent包,为自己提供身份
- 获取想要的数据:将数据接收处理
完整代码
import fake_useragent import requests if __name__ == '__main__': #UA伪装 让你认为我是一个浏览器 head = { "User-Agent":fake_useragent.UserAgent().random } # 1、指定url url = "https://www.sogou.com/" # 2、发送请求 返回的数据在response对象内 response = requests.get(url,headers=head) #3、获取想要的数据 res_text = response.text print(res_text)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18


