
- 1在 Llama 3.1 构建多种AI应用_llama3.1可以当嵌入模型吗
- 2某能源化工巨头:加快央国企数字化转型,夯实新型基础设施安全根基
- 3Javascript嵌套函数的调用
- 4黑神话悟空游戏攻略大全 黑神话悟空内存占用多少 国产3A级游戏《黑神话:悟空》评测代码已发 黑神话悟空测试画质130g MacBook可以玩黑神话悟空吗_黑神话悟空测试画质达到130g
- 5Maven所有版本下载地址&注意事项
- 6姿态解算篇——mahony互补滤波算法
- 7必备linux命令和C语言基础_c语言执行linux命令行
- 8centos7 通过 Yum 安装 NodeJS & NPM & Yarn_centos7 安装npm
- 9neo4j 添加属性_Neo4j:动态添加属性/设置动态属性
- 10腾讯云Linux云主机SSH远程连接_腾讯能检测到ssh协议吗
AI 绘画大模型群雄并起,新秀 FLUX.1 来袭,最会画手的 AI 绘画大模型来啦!_flux大模型
赞
踩
前言
前 言
最近这几天最火的模型应该就是 FLUX.1 了,由 Stable Diffusion 的原创团队推出的开源 AI 绘画大模型。
相比 SD3 拥有更优秀的提示词理解能力,更强的文字生成功能、更复杂的构图以及人体结构理解能力,以及终于解决了 AI 开源绘画模型被诟病很久的不能生成正常人手的问题。
FLUX.1 包含了三种变体 FLUX.1 [pro]、FLUX.1 [dev] 和 FLUX.1 [schnell]。
FLUX.1 [pro] 效果最好,但是没有开源,只能使用通过 API 接口调用,或者去 FLUX.1 官网体验。
FLUX.1 [dev] 是从 FLUX.1 [pro] 提炼而来,生成图片的质量会有一些影响,但是基本也不太看的出来,不过不支持商用。
FLUX.1 [schnell] 是一个加速版本,只需要 4 步就可以生成图像,效果上就会差些意思,这个是真的差些意思,不过支持商用。
好了,话不多说,我们直接开整。
—
直接来看效果吧:
提示词:filmic photo of a group of three women on a street downtown, they are holding their hands up the camera
- 1
来看看 FLUX.1 直出的手,虽然不能说完美吧,但是也挑不出来太多的毛病,这效果真的是相当可以了,终于可以把手大方的露出来了。

提示词:The text "Do one thing at a time,and do well." generated by flowing milk
- 1
关于文字的生成,都不需要抽卡,每次生成都是相当的准确。

提示词:A future robot writes ' Do one thing at a time,and do well.' on the blackboard
- 1
再来个稍微复杂一些的结合文字的场景,输出也很 OK。

提示词:There is a blue table on the red grass, with four exquisite bottles on it. From left to right, the bottles are labeled with "F", "L", "U", and "X" in sequence
- 1
颜色以及空间理解能力也到位。

提示词:cinematic still a tiny astronaut hatching from an egg on the moon . emotional, harmonious, vignette, highly detailed, high budget, bokeh, cinemascope, moody, epic, gorgeous, film grain, grainy
- 1
画面的表现力也是相当不错。

提示词:beautiful anime artwork, a cute anime girl’s silhouette, double exposure, iridescent nebula galaxy, black background, ethereal glow, bloom, hdr
- 1

提示词:anthropomorphism. Create a portrait of a eagle dressed in 18th-century men's attire. The eagle wears an elaborate, ornate waistcoat, a ruffled cravat, and a classic tricorn hat, all rendered in rich fabrics and intricate patterns. , photography, Natural geographic photo, Hyper-realistic, 16k resolution, (masterpiece, award winning artwork), many details, extreme detailed, full of details, Wide range of colors, high Dynamic,
- 1

接下来,我们来看看具体如何使用,ComfyUI 已经原生支持 FLUX.1,所以我们只需要把 ComfyUI 更新到最新版本就可以了,工作流以及模型听雨会放在文末的网盘里,需要的小伙伴可以自取。
模型比较大,dev 和 schnell 模型都有 24G,所以对本地配置的要求也比较高,全量版本 4090 都够呛,但是我们可以使用 FP8 版本,显存大概 16G 的样子。
小伙伴们只需要把网盘中的模型放在在 ComfyUI 模型目录「models」中对应的目录下即可。
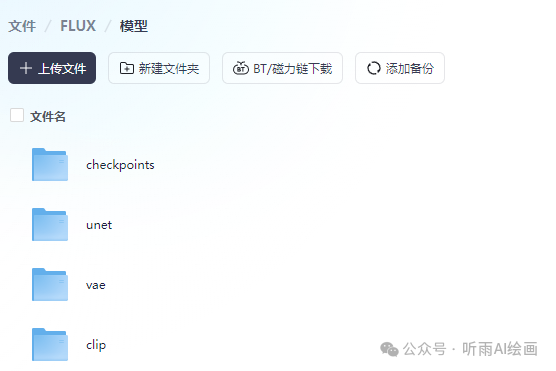
网盘中的模型并不需要都下载,clip 中的模型如果之前玩过 SD3 的小伙伴应该是已经下载过的,如果本地有同样的文件那就不需要下载了。
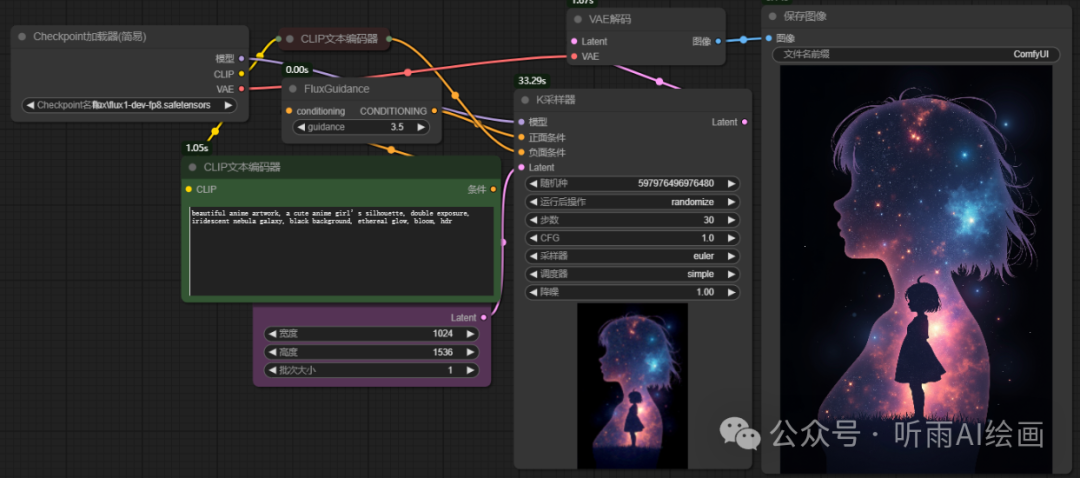
ComfyUI 现在提供了两种模型加载方案,也就是两个不同的工作流来加载 FLUX.1,我们可以选择只下载 「checkpoints」 中的 fp8 版本的模型,然后用正常模型的加载方式来使用 FLUX.1,和基础文生图工作流稍稍有些区别,CFG 值推荐使用 1.0。
模型大小总共 16G,显存占用大概 14G 的样子。
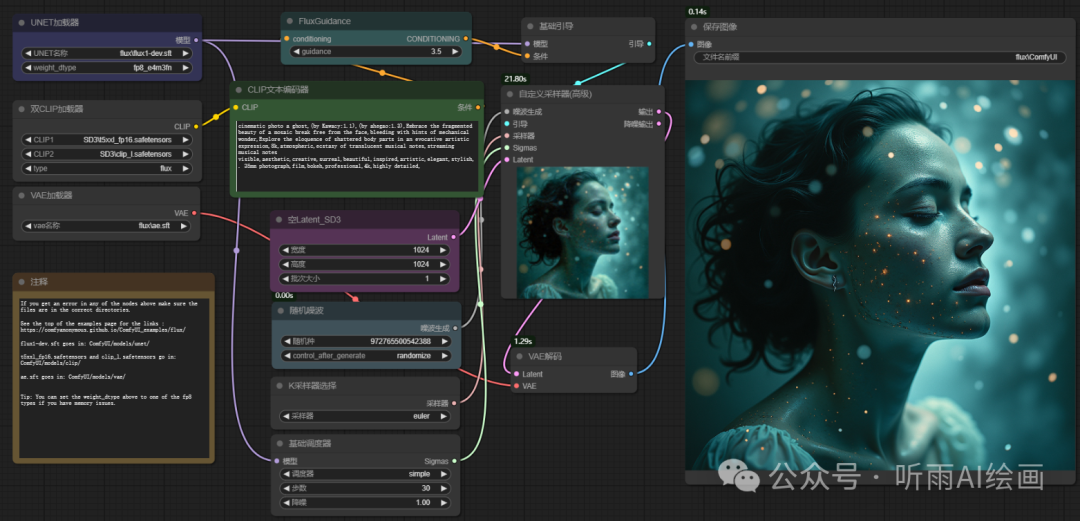
还有一种是下载「unet」、「vae」、「clip」这三个文件中的模型,并放在指定位置,可以使用全量模型,模型就是有点大,不算 [schnell] 版本,差不多有 30 多个G。
想跑全量,显存起码要大于 24G,官方的意思是需要 32G 显存才可以。
不过这里虽然是全量的模型,但是可以把「weight_dtype」设置为 fp8,也可以实现和第一个工作流相同的效果,如果选择默认那就是全量。
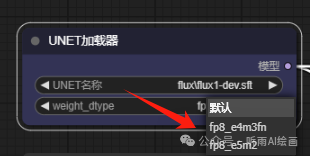
如果都是使用 fp8 的话,这两种模型加载方式的出图效果其实都差不多,显存占用也都一样,所以如果本地配置不够的小伙伴还是建议直接使用第一种就可以了,而且第一种工作流出图速度更快。
好了,今天的分享就到这里了,感兴趣的小伙伴快去试试吧!
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


