- 1java-No route to host 解决办法_java no route to host
- 2记录一次开发板无法ping通外网的解决办法 ping: sendto: Network is unreachable mount: RPC: Unable to send; errno = Ne
- 3Ambari 2.1安装HDP2.3.2 之 一、HDP介绍_hdp是什么
- 4用人工智能写2024年高考作文
- 5创建弹出式菜单_pmenu->trackpopupmenu
- 6完美解决PermissionError: [Errno 13] Permission denied: ‘./data\\mnist\\train-images-idx3-ubyte‘
- 7springboot整合图像数据库Neo4j
- 8Mac查看本机IP_mac ifconfig
- 9【挺全的】git基本操作、vim基本操作、团队协作、IDEA集成Git、GitHub、gitee码云、GitLab等基本操作_git vim
- 10Android7.0 Doze模式分析(一)Doze介绍 & DeviceIdleController
(2024,动态 LoRA,LoRA Switch,LoRA Composite,组合图像生成)用于图像生成的多 LoRA 组合_动态lora堆
赞
踩
Multi-LoRA Composition for Image Generation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
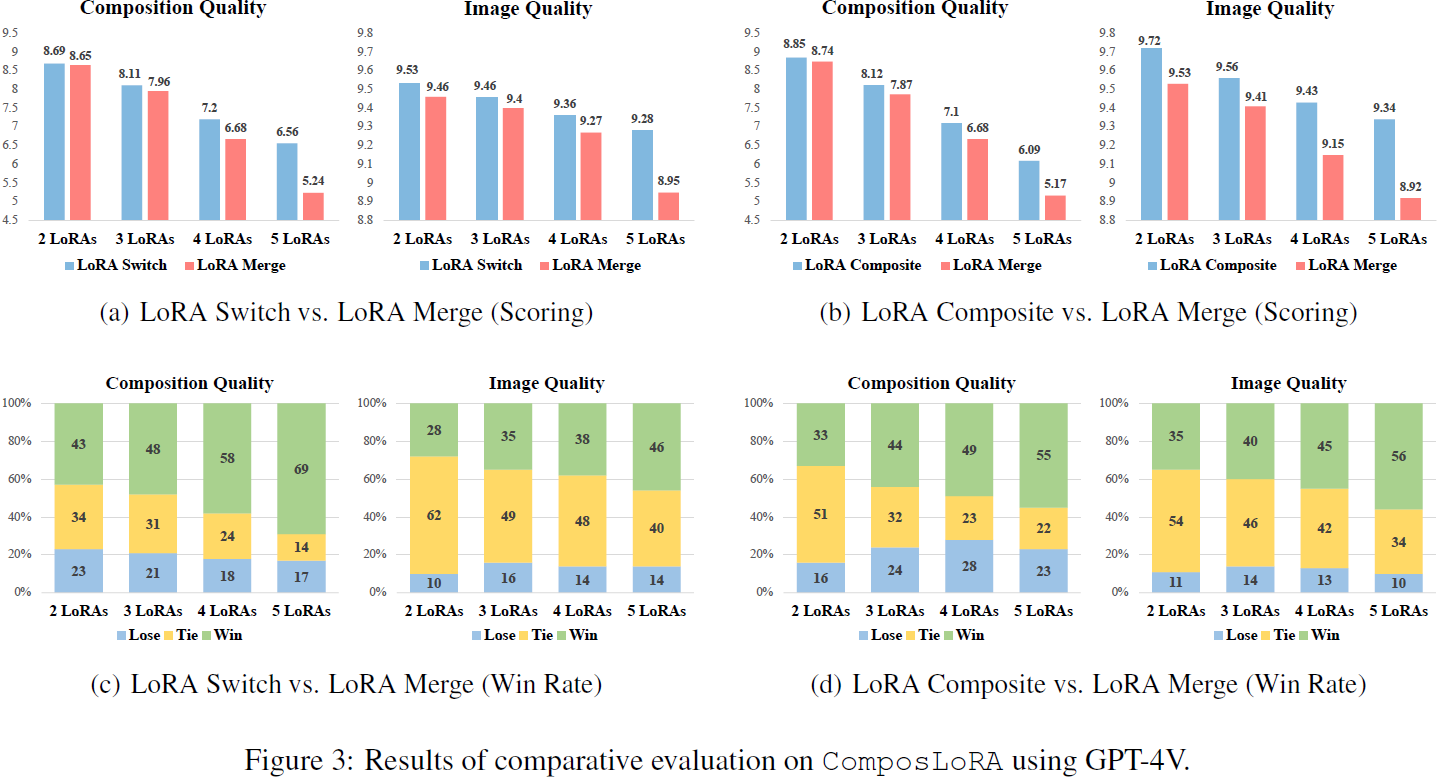
低秩适应(Low-Rank Adaptation,LoRA)在文本到图像模型中被广泛利用,以准确呈现生成图像中的特定元素,如独特的字符或独特的风格。然而,现有方法在有效组合多个 LoRA 时面临挑战,特别是随着要集成的 LoRA 数量增加,从而阻碍了复杂图像的创建。在本文中,我们通过以解码为中心(decoding-centric)的视角研究了多 LoRA 组合。我们提出了两种无需训练的方法:LoRA Switch,它在每个去噪步骤中在不同的 LoRA 之间交替,以及 LoRA Composite,它同时整合所有 LoRA 以引导更一致的图像合成。为了评估提出的方法,我们建立了ComposLoRA,这是一个新的全面测试平台。它包含了 480 个组合集的各种 LoRA 类别。利用基于 GPT-4V 的评估框架,我们的研究结果表明,相对于流行的基准线,在使用我们的方法时性能有明显提高,特别是在增加组合中 LoRA 的数量时。
项目页面:https://maszhongming.github.io/Multi-LoRA-Composition

2. 方法
2.1 基础
LoRA Merge(Ryu,2023)的概念通过线性组合多个 LoRA 以合成一个统一的 LoRA 来实现,随后将其插入扩散模型中。具体而言,在引入 k 个不同的 LoRA 时,随后更新的矩阵 W' 在 ϵθ 中表示为
其中,i 表示第 i 个 LoRA 的索引,wi 是一个标量权重,通常是通过经验调整确定的超参数。LoRA Merge 已经成为在图像中协调呈现多个元素的主导方法,为各种应用提供了一个简单的基准。然而,一次合并太多个 LoRA 可能会破坏合并过程(Huang等,2023a),并且它完全忽视了在生成过程中与扩散模型的交互,导致图 2 中汉堡和手指的变形。
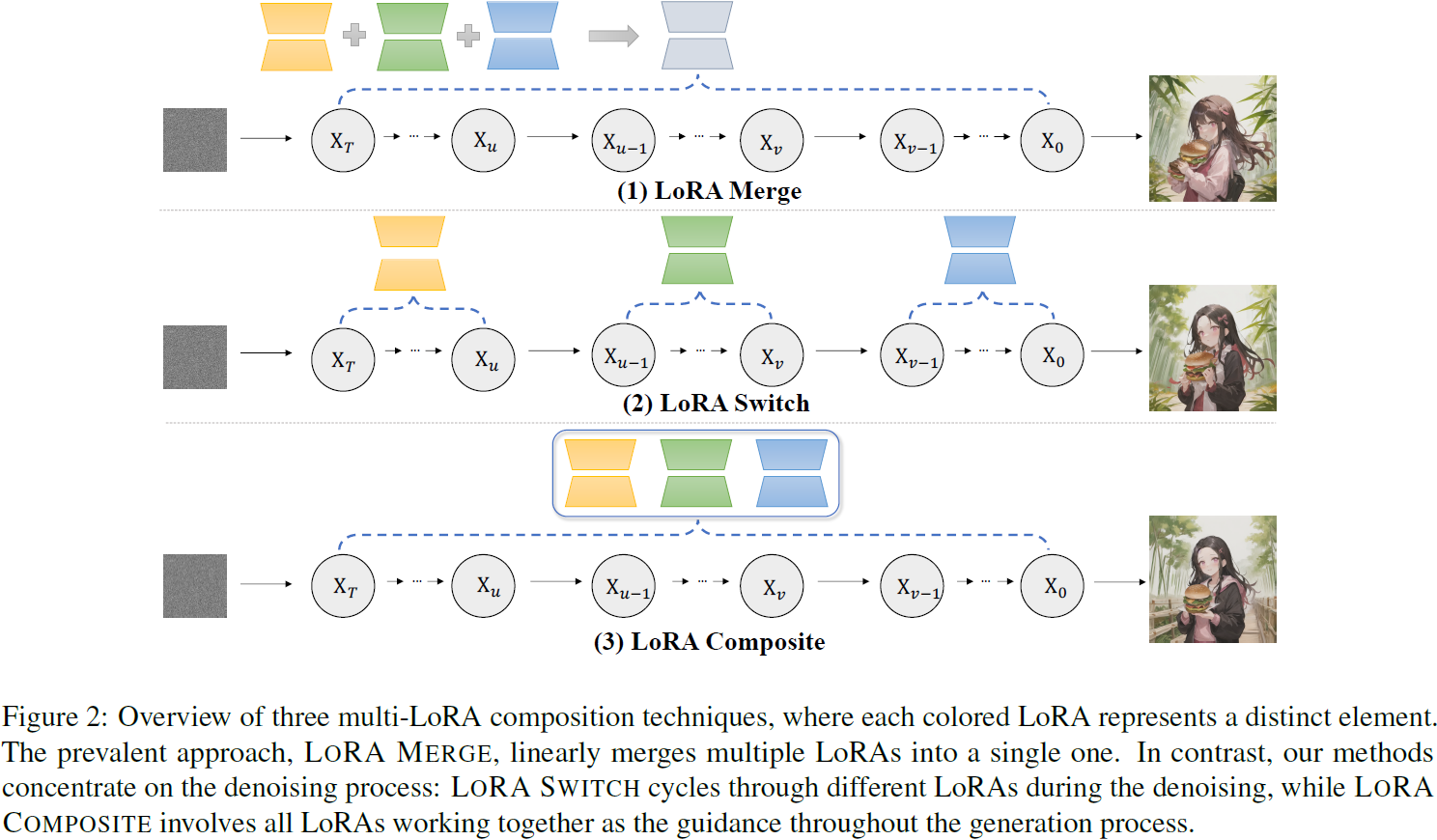
2.2. 通过以解码为中心的视角进行多LoRA组合
为了解决上述问题,我们的方法基于扩散模型的去噪过程,并研究在保持 LoRA 权重不变的情况下如何进行组合。具体分为两个视角:在每个去噪步骤中,要么仅激活一个 LoRA,要么同时激活所有 LoRA 来引导生成。
LoRA Switch(LoRA-S)。为了探索在每个去噪步骤中激活单个 LoRA,我们提出了 LORA Switch。该方法在扩散模型中引入了一个动态适应机制,通过在生成过程中在指定的间隔内顺序激活单个 LoRA。如图 2 所示,每个 LoRA 由一个与特定元素相对应的独特颜色表示,每个去噪步骤只激活一个 LoRA。在一组 k 个 LoRA 中,该方法从一个预先排列的排列序列开始;在图中的示例中,序列从黄色到绿色再到蓝色的 LoRA。从第一个 LoRA 开始,模型每 τ 步过渡到下一个 LoRA。这种循环持续进行,允许每个 LoRA 在 kτ 步之后轮流应用,从而使每个元素能够重复为图像生成做出贡献。每个去噪时间步 t(从 1 到所需的总步数)的激活 LoRA 由以下方程确定:
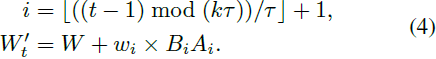
在这个公式中,i 表示当前激活的 LoRA 的索引,迭代从 1 到 k。取整函数(floor function) ⌊·⌋ 确保 i 的整数值在 t 时得到适当的计算。得到的权重矩阵 W'ₜ 被更新以反映来自激活的 LoRA 的贡献。通过每次选择一个 LoRA 进行启用,LORA SWITCH 确保将关注点集中在与当前元素相关的细节上,从而在整个过程中保持生成图像的完整性和质量。
LoRA Composite (LoRA-C)。为了探索在每个时间步骤中合并权重矩阵的情况下整合所有LoRA,我们提出了 LORA COMPOSITE (LORA-C),这是一种基于无分类器引导范式的方法。该方法涉及在每个去噪步骤中分别计算每个 LoRA 的无条件和有条件的得分估计。通过聚合这些分数,该技术确保在整个图像生成过程中实现平衡的引导,促进了由不同 LoRA 表示的所有元素的协同整合。
形式上,设有 k 个 LoRA,让 θ′ᵢ 表示在整合第 i 个 LoRA 后的扩散模型 eθ 的参数。基于文本条件 c 得到的集体引导 ˜e(zt, c) 通过聚合每个 LoRA 的分数而得到:
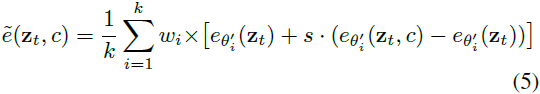
在这里,wi 是分配给每个 LoRA 的标量权重,旨在调整第 i 个 LoRA 的影响。对于我们的实验设置,我们将 wi 设置为1,赋予每个 LoRA 相等的重要性。LORA-C 确保每个 LoRA 在去噪过程的每个阶段都能有效地发挥作用,解决了常与合并 LoRA 相关的鲁棒性和细节保留的潜在问题。
3. 实验