
热门标签
热门文章
- 1代码随想录算法训练营第六天|242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
- 2接口测试必备的,2种常⽤的JSON解析⽅法_测试json接口
- 3鼠标滚轮失灵怎么办?电脑用户必备教程(4个方法)_鼠标滚轮上下失灵修复小技巧
- 4解决浏览器滚动条导致的页面闪烁问题_macchrome浏览器滑动闪屏
- 5【C++风云录】进化计算框架全览:遗传算法与优化_演化算法通用框架
- 6【ChatGPT】比尔·盖茨最新分享:ChatGPT的发展,不止于此_盖茨博客 chatgpt
- 7微信营销和微博营销有什么不同_微信营销和微博营销的区别
- 8网上竞拍系统-数据库大作业_网上拍卖系统数据库设计
- 9springboot学习02-[热部署和日志]
- 10Mac OS下Docker的安装与配置_mac安装docker以及配置
当前位置: article > 正文
Es结合springboot(笔记回忆)
作者:在线问答5 | 2024-07-02 09:09:03
赞
踩
Es结合springboot(笔记回忆)
导包
- <!--导入es-->
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-data-elasticsearch</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-test</artifactId>
- </dependency>
配置
- data:
- elasticsearch:
- cluster-name: elasticsearch
- cluster-nodes: 127.0.0.1:9300
9200,可以查看es信息
9300 内部用
9300是TCP协议端口号,ES集群之间通讯端口号
9200端口号,暴露ES RESTful接口端口号
searchAnalyzer 查的时候分词器
analyzer 存入的时候分词器
GET _cat/indices 相当于查询所有库
导入工具类
-
-
- import org.elasticsearch.client.transport.TransportClient;
- import org.elasticsearch.common.settings.Settings;
- import org.elasticsearch.common.transport.TransportAddress;
- import org.elasticsearch.transport.client.PreBuiltTransportClient;
- import org.springframework.stereotype.Component;
-
- import java.net.InetAddress;
- import java.net.UnknownHostException;
- @Component
- public class ESClientUtil {
-
- public TransportClient getClient(){
- TransportClient client = null;
- Settings settings = Settings.builder()
- .put("cluster.name", "elasticsearch").build();
- try {
- client = new PreBuiltTransportClient(settings).addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
- } catch (UnknownHostException e) {
- e.printStackTrace();
- }
- return client;
- }
-
- }

创建实现增删改查的ES工厂,这个接口估计是模仿mybatis那个mapper,东施效颦罢了。
- package org.example.utils;
-
- import org.example.domain.EmpDoc;
- import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
- import org.springframework.stereotype.Repository;
-
- //要穿一个类,然后文档对象id的类型,我们需要自己写一个接口类,并在接口类上打一个注解,注入到spring容器
-
- /**
- * 这个Repository 类似与mybatis中的mapper接口
- * 这个接口不需要实现类,我们到时候如果想对文档crud,只需要注入这个接口类就可以了。
- * 反正就是动态代理嘛,自动生成动态代理类,自动将代理实现类交给spring管理,所以我们注入这个接口类
- * 就可以使用这个接口类的方法,实现文档的crud
- */
- @Repository
- public interface UserDocRepository extends ElasticsearchRepository<EmpDoc,Long> {
-
- }
我们创建索引库的话,可以通过注解实体类来创建es库
- package org.example.domain;
-
- import lombok.AllArgsConstructor;
- import lombok.Data;
- import lombok.NoArgsConstructor;
- import org.springframework.data.annotation.Id;
- import org.springframework.data.elasticsearch.annotations.Document;
- import org.springframework.data.elasticsearch.annotations.Field;
- import org.springframework.data.elasticsearch.annotations.FieldType;
- import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
- import org.springframework.stereotype.Repository;
-
- @Data
- @AllArgsConstructor
- @NoArgsConstructor
- //这里指明了
- @Document(indexName = "test",type = "emp")
- public class EmpDoc{
- @Id //文档id字段
- private Long id;
- @Field(type = FieldType.Keyword) //不分词
- private String name;
- @Field(type = FieldType.Integer)
- private Integer age;
- @Field(type = FieldType.Text,analyzer = "ik_smart"
- ,searchAnalyzer = "ik_smart")
- private String intro;
- }
-
-
@Document(indexName = "test",type = "emp")
指明了在es中的位置和地址,text分词查询,keyword不分词哈。
开始操作
- @Autowired
- private ElasticsearchTemplate elasticsearchTemplate;
创建索引库
- @Test
- public void test05(){
- // boolean index = elasticsearchTemplate.createIndex("spring-demo");
- // System.out.println(index);
- elasticsearchTemplate.createIndex(EmpDoc.class);
- elasticsearchTemplate.putMapping(EmpDoc.class);
-
- }
- @Test
- public void test06(){
- EmpDoc empDoc = new EmpDoc();
- empDoc.setAge(12);
- empDoc.setIntro("zzzz");
- empDoc.setId(1l);
- empDoc.setName("zs");
- userDocRepository.save(empDoc);
- }
- @Test
- public void test07(){
- System.out.println(userDocRepository.findById(1l).get());
- }
其余操作就很简单了,简单的增删改查没意思,直接快进到聚合查询,我就是为了回忆聚合查询,才开始又慢慢看es的
- @Test
- public void test08(){
- // 创建一个查询构建器对象
- NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
- // Page<EmpDoc> search = userDocRepository.search(builder.build());
- NativeSearchQuery build = builder.build();
- Page<EmpDoc> search = userDocRepository.search(build);
- // 添加查询条件,添加排序条件,添加分页条件,将es的分页对象转换为自己的对象
- PageList<EmpDoc> empDocPageList = new PageList<>(search.getTotalElements(), search.getContent());
- System.out.println(empDocPageList);
-
- }
build去拿searquery对象,为什么要去拿searchquery对象呢?因为search方法要searchquery,才会返回值。
然后这个返回的值里面有很多方法,就可以拿到totals啥的。
分页
queryBuilder.withPageable(PageRequest.of(0,10));
对了,这个方法要的是接口,所以我们要找接口的实现类。是这个方法是要接口吗,我有点记不清了。
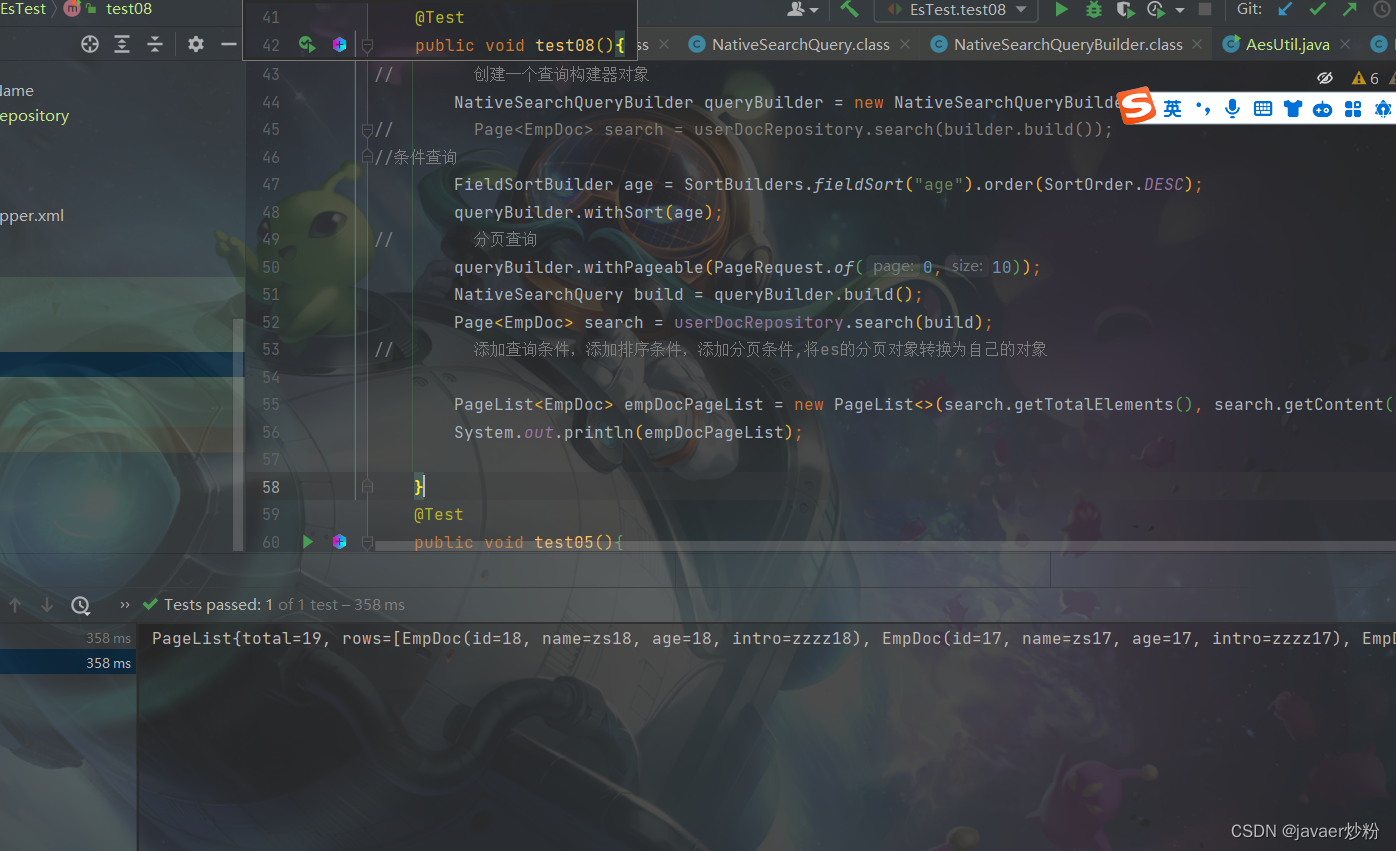
成功哈
关键字查询,范围查询,条件查询
我们要先搞清楚
query -> bool -> must(match)/filter(term/range)的顺序
然后
queryBuilder.withQuery(boolQuery);
这个方法可以放入一个boolQuery,这个boolQuery我们可以弄很多的聚合查询在其中
bool中有must关键查询和filter范围查询和过滤查询
must 多个属性都可以关键字查询
mutiMatchQuery 匹配多个字段,多字段分词查询
must——》match关键字查询
filter-》term 是条件查询
filter-》range是范围查询
反正一切都在代码中了哈
- @Test
- public void test08(){
- // 创建一个查询构建器对象
- NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
- // Page<EmpDoc> search = userDocRepository.search(builder.build());
- //条件查询
- FieldSortBuilder age = SortBuilders.fieldSort("age").order(SortOrder.DESC);
- queryBuilder.withSort(age);
- // 分页查询
- queryBuilder.withPageable(PageRequest.of(0,10));
- // 关键字,分词查询还是不分词查询,是分词查询,包含关键字会查询出来。
- // dsl结构,要记得住,不然理解不到
- // query -> bool -> must(match)/filter(term/range)
- // mutiMatchQuery 多字段
- // 直接先到bool层
- BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
- // List<QueryBuilder> must = boolQuery.must();
- // must.add(QueryBuilders.matchQuery("age","15"));
- // queryBuilder.withQuery()
- List<QueryBuilder> filter = boolQuery.filter();
- // filter.add(QueryBuilders.termQuery("id",3));
- // 词元查询
- // 年龄
- filter.add(QueryBuilders.rangeQuery("age").gte(15).lte(20));
- queryBuilder.withQuery(boolQuery);
- NativeSearchQuery build = queryBuilder.build();
- Page<EmpDoc> search = userDocRepository.search(build);
- // 添加查询条件,添加排序条件,添加分页条件,将es的分页对象转换为自己的对象
-
- PageList<EmpDoc> empDocPageList = new PageList<>(search.getTotalElements(), search.getContent());
- System.out.println(empDocPageList);
-
- }
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/779156
推荐阅读
相关标签

