
- 1Linux上运行MySQL出现“ERROR 2002 (HY000): Can't connect to
- 202、MongoDB -- MongoDB 的安全配置(创建用户、设置用户权限、启动安全控制、操作数据库命令演示、mongodb 的帮助系统介绍)_mongodb 创建用户
- 3华为OD机试2024年最新题库(Python、JAVA、C++合集)_华为od机试题库_od题库
- 4简述ECC加密算法
- 5MTK平台Android13实现三方launcher为默认_android13 系统默认launcher
- 6年终前端安全防护规范总结
- 7微信小程序slot插槽的使用
- 8Python解压7z压缩文件
- 9QT窗体间传值总结之Signal与Slot_qt 两个窗体 slot signal
- 10第三方库介绍——cJSON库_c语言json库
论文完整复现流程之异常检测的未来帧预测
赞
踩
论文完整复现流程之异常检测的未来帧预测
0.导语
本次研究论文题目为:Future Frame Prediction for Anomaly Detection -- A New Baseline。
本片文章主要分为两大块来详细阐述这篇论文,分别是:论文阅读核心点与论文复现流程及细节。
1.论文阅读
1.1 论文框架
本篇论文为GAN进行异常检测的一篇文章。在这篇论文中核心为下面的pipeline。
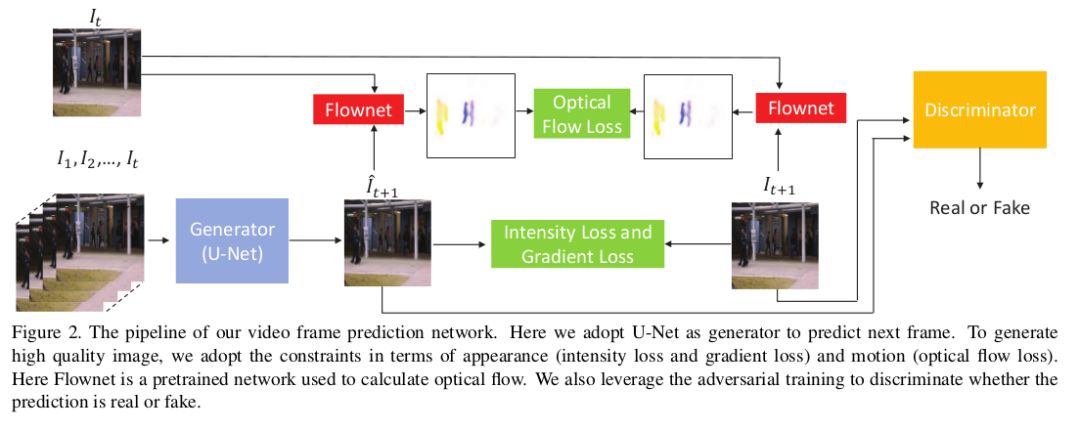
该pipeline指出:
(1)使用修改过的U-Net作为生成器,并使用训练好的Flowne2提取光流。
(2)判别器采用 Image-to-image translation with conditional adversarial networks中的判别器。
1.2 训练
【对抗训练】
生成对抗网络(GAN)包含一个生成器G与判别器D,而G学习去生成(由D很难去分类)的帧(图片),而D目标则是去判别由G生成的帧(图片),这称为对抗训练。
【训练D(判别器)】
判别器D基于CGAN构建的图像转换模型中的局部判别器Patch Discriminator。该方案先将生成图片分成N*N的小块,然后对每一块使用二分类判别器进行真假的判别。通过这一修改,不仅降低了判别器的参数量,加快模型的运行速度,也使其适应任意尺寸的输入。同时促使判别器D更加关注高频局部信息,激励生成器生成细节更清晰的图像。
其损失函数如下。其中,i,j 是图片块的索引,D(x)ϵ[0,1]:
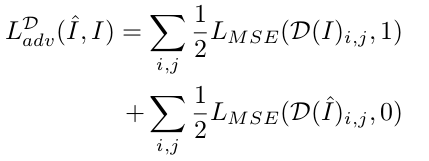
【训练G(生成器)】
生成器G使用U-Net模型,设计一个具有相同输入输出同分辨率的帧预测模型,该模型使用类似自编码器的对称结构,通过在同样分辨率大小的浅层和深层之间添加短路连接(Shortcut)。解决传统自编码器结构的梯度消失和重构时细节丢失的问题,使用该结构可以生成更加清晰的图像。
(1)U-Net模型:

(2)强度损失:预测帧(生成图片)与真实帧(原图片)的L2距离。

(3)梯度损失:边缘形状的约束,使得生成图像更加锐化,其中,i、j 表示二维视频帧中的像素位置。加入该损失后,使得生成图片中每个像素点与相邻像素点的差值与原图片更一致,对于中色彩转换边界有更大影响。

(4)光流损失:预测帧与真实帧与前一帧的光流之间的L1距离。
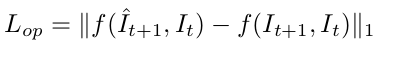
(5)均方误差损失:生成出来的帧希望全部都被判别器判定为1。在训练G时固定D的权重。其中i, j 是图片块的索引,D(x)ϵ[0,1]。

1.3 目标函数
【生成器G】
生成网络的目标函数是:强度损失,梯度损失,光流损失,均方误差损失,最后对抗损失为按比例求和:

【判别器D】
对抗网络的目标函数是:仅有对抗损失:

具体的训练参数设置,可以看原文。
1.4 测试
使用峰值信噪比(PSNR)评估预测帧的质量(计算预测帧和真实帧的像素级相似度),越接近正常,分数越高。越低的PSNR越可能有异常:
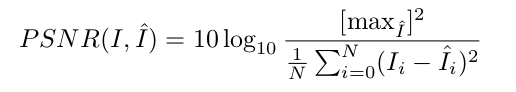
最后,将每个测试视频中所有帧的PSNR归一化到[0,1]的范围内,计算正则分数:

1.5 实验结果
在数据集CUHK Avenue , UCSD Pedestrian, ShanghaiTech上,该方法均超过baseline。

2.论文复现
复现直接使用论文官方的github数据集与代码。复现流程及思路如下:
【数据集】
本次实验训练step非常大,8w步,当然也可以自己设置,如果电脑是数字1000以下GPU,就不要跑了,会卡死。
实验中有三个数据集,而在这次复现中仅使用了ped2数据集做训练与测试。复现的具体流程在官网github上有详细流程,下面重点来看复现结果与代码分析。
【复现结果】
训练step对应的异常事件图:

训练过程中的loss:

模型选择后,测试数据上的AUC精度对比:
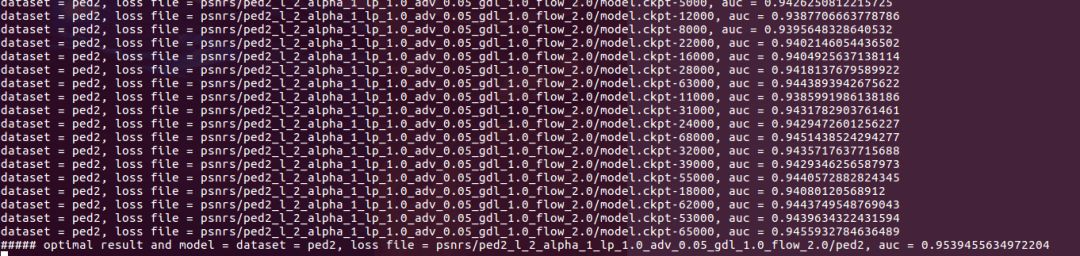
对比上述AUC得出95.4%!
【代码分析】
该篇论文的代码写的非常优雅!非常值得学习!
论文复现代码中使用了如下深度学习技术:
PatchBatch
U-Net
CGAN
Pix to Pix
Flownet2-tf
flownet2文件夹下的代码源自:
https://github.com/sampepose/flownet2-tf
pix2pix.py源自:
https://github.com/tensorflow/models/blob/master/research/slim/nets/pix2pix.py
【数据集与运行】
(1)对视频做帧提取(ffmpeg提取),提取方式:
ffmpeg -i 01.avi frames/frames_%05d.jpg
-i 后是输入文件名,最后是输出结果,以frame_为前缀,以五位数字为编号(不够前边用0补齐),图片格式为jpg。
(2)服务器后台运行
当使用nohup与&将训练放在后台后,使用tail -f追踪数据时,不显示输出结果,原因在于数据数据未能及时写入log中,此时需要python运行加-u参数即可实现。
最后,继续去琢磨代码,改代码,深入改写。。。


