
- 1企业im(即时通讯)作为安全专属的移动数字化平台的重要工具
- 2springboot 开启一个异步线程_springboot启动一个线程
- 3AI Agent智能体概述及原理
- 4电子元器件物料编码_电子元器件物料编码规则
- 5在AI大模型中全精度和半精度参数是什么意思?_半精度和全精度
- 6RabbitMQ安装教程(非常详细)从零基础入门到精通,看完这一篇就够了_rabbitmq安装详细教程
- 7Github账号开启账号双重验证_github双重认证
- 8Maven IDEA环境搭建(MapReducer、Spark)_idea mapreduce maven
- 9基于 Native 技术加速 Spark 计算引擎
- 10干了十年的程序员告诉你:这个问题根本没有讨论的必要_提需求 不过脑
什么是SQL,什么是MYSQL?MYSQL的架构以及SQL执行语句的过程是什么?有哪些数据库的类型?一篇文章带你弄懂!_sql和mysql
赞
踩
前言
数据库的定义:
数据库是结构化信息或数据的有序集合,一般以电子形式存储在计算机系统中。通常由数据库管理系统 (DBMS) 来控制。在现实中,数据、DBMS 及关联应用一起被称为数据库系统,简称为数据库。
一、为什么需要数据库
为什么有了文件还要有数据库呢?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
数据库和电子表格(Excel)的区别:
数据库和电子表格(例如 Microsoft Excel)都可以便捷地存储信息,两者的主要区别包括:
- 存储和操作数据的方式
- 谁可以访问数据
- 可以存储多少数据
从一开始,电子表格就是专门针对单一用户而设计的,其特性也反映了这一点。它非常适合不需要执行太多高度复杂的数据操作的单一用户或少数用户。相反,数据库是为了保存大量甚至海量有组织的信息而设计的,它允许多个用户同时使用高度复杂的逻辑和语言,快速、安全地访问和查询数据。
二、数据库的相关概念
1.什么是结构化查询语言 (SQL)
目前几乎所有的关系数据库都使用 SQL 编程语言来查询、操作和定义数据,进行数据访问控制。SQL 最初于 20 世纪 70 年代由 IBM 开发,当时 Oracle 是一个主要的贡献者,这推动了 SQL ANSI 标准的实施,而 SQL 的兴起也刺激了 IBM、Oracle 和 Microsoft 等公司开始全面扩张。时至今日,虽然 SQL 仍被广泛使用,但是新的编程语言也已经崭露头角。
SQL分类:
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构
代表指令: create, drop, alter- DML【data manipulation language】 数据操纵语言,用来对数据进行操作
代表指令: insert,delete,update
DML中又单独分了一个DQL,数据查询语言,代表指令: select- DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务
代表指令: grant,revoke,commit
2.什么是数据库管理系统 (DBMS)
数据库通常离不开完备的数据库软件程序,也就是数据库管理系统 (DBMS)。DBMS 充当数据库与其用户或程序之间的接口,允许用户检索、更新和管理信息的组织和优化方式。此外,DBMS 还有助于监督和控制数据库,提供各种管理操作,例如性能监视、调优、备份和恢复。
常见的数据库软件或 DBMS 有 MySQL、Microsoft Access、Microsoft SQL Server、FileMaker Pro、Oracle Database 和 dBASE。
3.什么是 MySQL 数据库
MySQL 是一种开源的基于 SQL 的关系数据库管理系统。它专门针对 Web 应用进行设计和优化,可以在任何平台上运行。互联网的兴起带来许多新的和不同的需求,MySQL 开始成为 Web 开发人员以及基于 Web 的应用的首选平台。它可以处理数以百万计的查询和数以千计的事务,因此深受那些需要进行大量资金转账的电商企业的欢迎。随需应变的灵活性是 MySQL 的一项主要特点。
目前全球许多顶级的互联网网站和基于 Web 的应用均采用 MySQL 作为 DBMS,例如 Airbnb、Uber、LinkedIn、Facebook、Twitter 和 YouTube。
三、数据库分类
目前数据库主要分为传统的关系型数据库(SQL)和非关系型数据库(NoSQL),当然还有近几年新出现的NewSQL新型数据库、分布式数据库等等。
1.关系型数据库(SQL)
传统的关系型数据库有着悠久的历史,从上世纪60年代开始就已经在航空领域发挥作用。因为其严谨的一致性以及通用的关系型数据模型接口,收获了很大一批的用户。
关系型数据库是把数据以表的形式进行储存,然后再各个表之间建立关系,通过这些表之间的关系来操作不同表之间的数据。
常见的关系型数据库有MySQL、Oracle、PostgreSQL等等。
关系型数据库是依据关系模型来创建的数据库,所谓的关系模型是指“一对一、一对多、多对多”,通过关系模型来构建二维表格
一对一:身份证号、校园卡
一对多:班级-学生、部门-职员
多对多:课程-学生、书籍-作者
优点:
- 数据安全(磁盘)、数据一致性
- 二维表结构直观,易理解
- 使用SQL语句操作非常方便,可用于比较复杂的查询
缺点:
- 读写性能较差
- 不擅长处理较复杂的关系
2.非关系型数据库(NoSQL)
到了2000年代,由于互联网应用的兴起,互联网应用需要支持大规模的并发用户,并且要保持永远在线。但是传统的关系型数据库却因为无法支持如此大规模数据和访问量而成为了整个系统的瓶颈。最简单直接的办法是不断升级硬件系统,使用更多的CPU,内存和硬盘。但是这种方法只是提高了性能,并且呈现明显的收益递减效应。更糟糕的是,将数据库从一个机器迁移到另一个机器是一个比较复杂的过程,通常需要较长的停机时间。而这对于Web应用来说是不可接受的。
这些问题引发了2000年代NoSQL的诞生。NoSQL的关键是它们放弃了传统关系型数据库的强事务保证和关系模型,通过所谓最终一致性和非关系数据模型(例如键值对,图,文档)来提高Web应用所注重的高可用性和可扩展性。
相比于关系型数据库,表与表之间是有关系的,利用表与表之间的关系进行各种操作。而NoSQL没有固定的表结构,且数据之间不存在表与表之间的关系,数据之间可以是独立的,因此NoSQL也可以用于分布式系统上。
NoSQL大致可以分为四种:
| 分类 | 数据模型 | 优势 | 举例 |
|---|---|---|---|
| 键值数据库 | 哈希表 | 查询快、易部署、高并发 | Redis、Memcached |
| 列存储数据库 | 列式数据存储 | 查询快,数据压缩率高,不需要额外建立索引 | HBase |
| 文档型数据库 | 键值对扩展 | 将数据以文档的形式储存,数据结构不定 | MongoDB |
| 图数据库 | 节点和关系组成的图 | 利用图结构的相关算法 | Neo4j、JanusGraph |
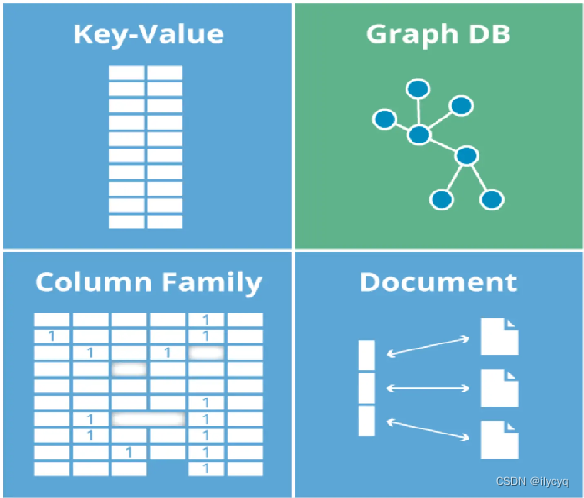
- 键值数据库
键值数据库类似于传统语言中使用的哈希表。可以通过key来添加、删除、查询数据,因为使用key主键来访问,所以键值数据库有很高的性能及拓展性。
例如现在很火的redis,由于其数据是储存于内存,读写速度非常快。Redis在一秒内读写可以超过十万个键值。它虽然是作为数据库来开发的,现在更广泛的应用于缓存、消息队列。
- 列存储数据库
不同于关系型数据库的以行为单位储存,列存储数据库将数据存储于列族中,一个列族存储经常被一起查询的相关数据。
先来说说行式数据库,行式数据库是一行一行进行存储的,我们进行查询的时候,也要一行一行进行扫描。例如,我们要从上面的课程表中查询 name 是线代的课程,还会同时查询到很多我们不需要的信息。即使我们需要的一列的数据,也要进行整行扫描。这在某些场景下是很浪费IO效率的。
列式数据库主要运用于海量数据分析。因为在进行数据分析的时候,我们通常只会查询表中的一列或者几列,这时只用把这几列拿出来就可以了,其他不需要查询的我们也不关心,大大提高了检索的效率。
关于行列式数据库差别以及各自的应用场景,有兴趣可以再看看:列式数据库和行式数据库的区别、什么是ClickHouse?
- 文档型数据库
文档型数据库与键值数据库是类似的,只不过它将数据用文档的形式储存,数据存储可以是XML、JSON等多种形式。

- 图数据库
图数据库允许我们将数据以图的方式存储。实体会被作为顶点,而实体之间的关系则会被作为边。因为使用的是灵活的图模型,所以可以拓展到多个服务器上。图数据库没有标准的SQL查询语言。许多Graph DB都有restful式的数据接口或者查询API。
图数据库一般用于推荐系统、处理社交网络等等。
社交领域:Facebook, Twitter,Linkedin用它来管理社交关系,实现好友推荐
零售领域:eBay,沃尔玛使用它实现商品实时推荐,给买家更好的购物体验
金融领域:摩根大通,花旗和瑞银等银行在用图数据库做风控处理
汽车制造领域:沃尔沃,戴姆勒和丰田等顶级汽车制造商依靠图数据库推动创新制造解决方案
电信领域:Verizon, Orange和AT&T 等电信公司依靠图数据库来管理网络,控制访问并支持客户360
酒店领域:万豪和雅高酒店等顶级酒店公司依使用图数据库来管理复杂且快速变化的库存
四、MYSQL架构
1.各组件功能
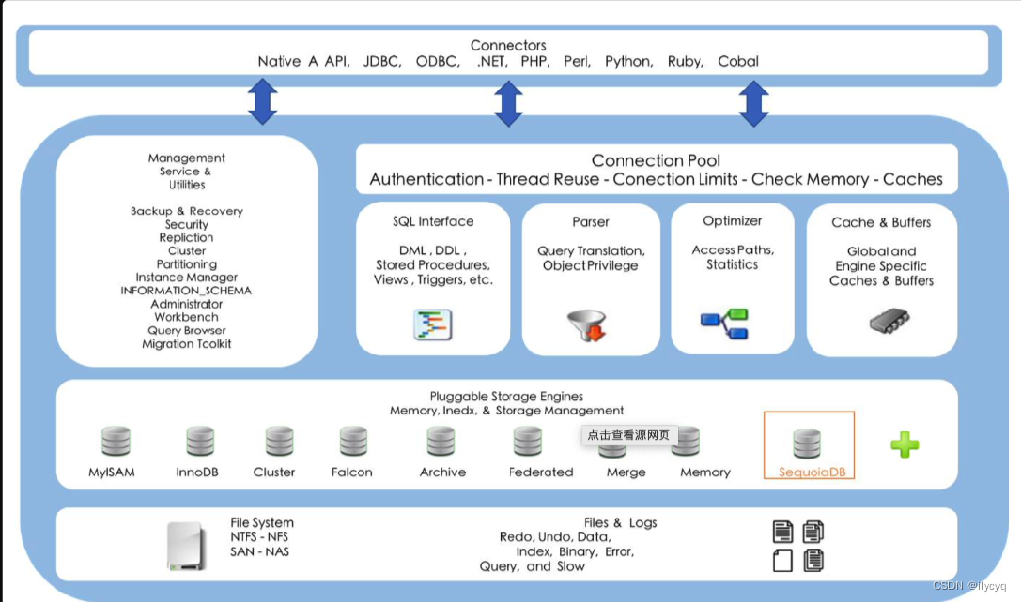
-
Connectors:与其他编程语言中的sql 语句进行交互,如php、java等;
-
Management Serveices & Utilities:系统管理和控制工具;
-
Connection Pool (连接池):管理缓冲用户连接,线程处理等需要缓存的需求;
-
SQL Interface (SQL接口)
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface; -
Parser (解析器)
SQL命令传递到解析器的时候会被解析器验证和解析;
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,后面SQL语句的传递和处理就是基于这个结构的;
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的,语句将不会继续执行下去;
- Optimizer (查询优化器)
SQL语句在查询之前会使用查询优化器对查询进行优化(产生多种执行计划,最终数据库会选择最优化的方案去执行,尽快返会结果) 他使用的是“选取-投影-联接”策略进行查询;
用一个例子就可以理解:select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤;
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤将这两个查询条件联接起来生成最终查询结果;
- Cache和Buffer (查询缓存)
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据;
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等; - Engine (存储引擎)
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制。(这种访问机制就叫存储引擎)
2.SQL执行语句过程
数据库通常不会被直接使用,而是由其他编程语言通过SQL语句调用mysql,由mysql处理并返回执行结果。那么Mysql接受到SQL语句后,又是如何处理?
首先程序的请求会通过mysql的connectors与其进行交互,请求到处后,会暂时存放在连接池(connection pool)中并由处理器(Management Serveices & Utilities)管理。当该请求从等待队列进入到处理队列,管理器会将该请求丢给SQL接口(SQL Interface)。SQL接口接收到请求后,它会将请求进行hash处理并与缓存中的结果进行对比,如果完全匹配则通过缓存直接返回处理结果;否则,需要完整的走一趟流程:
(1)由SQL接口丢给后面的解释器(Parser),解释器会判断SQL语句正确与否,若正确则将其转化为数据结构。
(2)解释器处理完,便来到后面的优化器(Optimizer),它会产生多种执行计划,最终数据库会选择最优化的方案去执行,尽快返会结果。
(3)确定最优执行计划后,SQL语句此时便可以交由存储引擎(Engine)处理,存储引擎将会到后端的存储设备中取得相应的数据,并原路返回给程序。
3.存储引擎
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
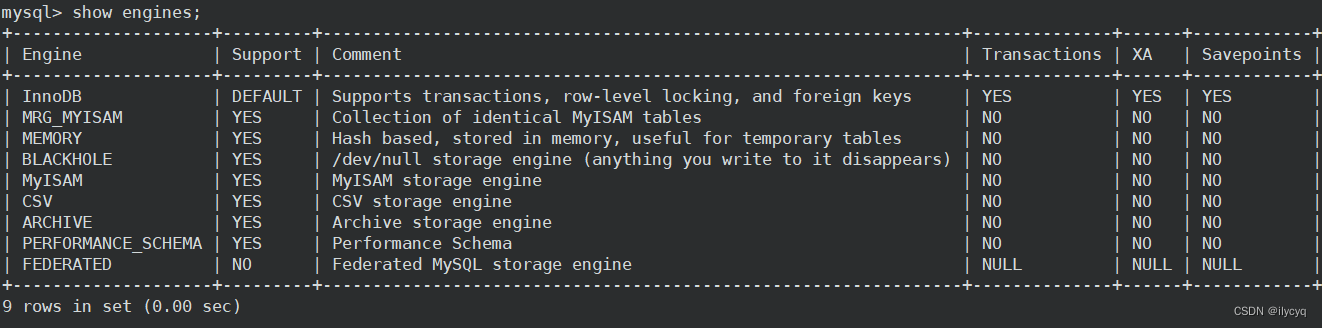
在MYSQL中,我们可以用show engines;来查询引擎,我们可以发现 InnoDB 是默认的存储引擎:
下面列举了常用引擎的对比:
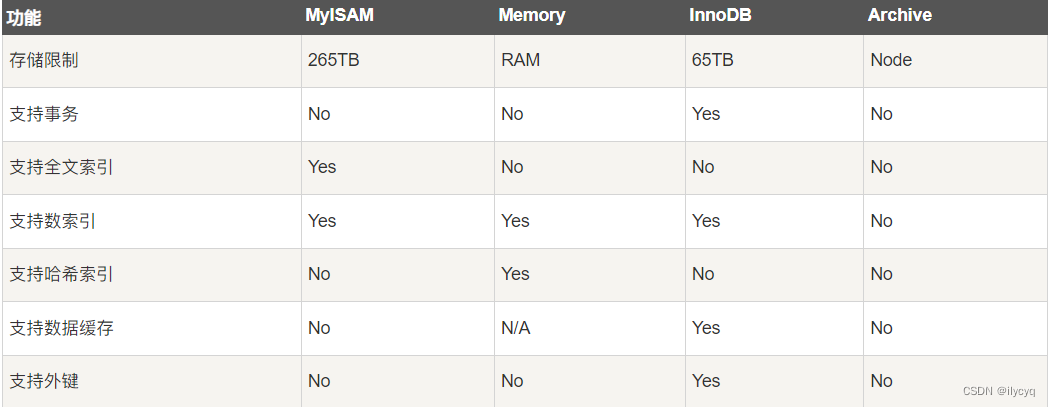
我们常用的就是InnoDB和MyISAM,其中MySQL5.5之后默认的存储引擎是InnoDB。
- InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。(类似需求一般用mongoDB)


