
- 1flowable 和activiti 数据库表结构对比说明_activiti flowable
- 2【多模态MLLMs+图像编辑】MGIE:苹果开源基于指令和大语言模型的图片编辑神器(24.02.03开源)_guiding instruction-based image editing via multim
- 3短剧app广告变现系统开发 源码搭建
- 4自己制作“EleksTubeIPS创意复古RGB拟辉光管时钟”分享《四》-(持续更新2022-2-28)_ips辉光刷机教程
- 5文本表示(一)—— word2vec(skip-gram CBOW) glove, transformer, BERT_glove和transformer
- 6git入门:git常用命令 | 代码的拉取、修改、提交、推送命令及原理_git拉取命令
- 7第十四届蓝桥杯第一期模拟赛试题与题解 C++_蓝桥杯模拟赛题型
- 8C++编程语言中stringstream类介绍
- 9AIGC|什么是深度学习?_aigc时代深度学习
- 10MapReduce模型(对数据的统计分析)_使用mapreduce统计数量占比
BestBlogs.dev 推荐文章 第1期_刚完成 bestblogs.dev 的第三期精选推送,果然又有“惊喜”,推送过程中发现有
赞
踩
亲爱的开发者朋友们,
欢迎阅读本期的 Newsletter!在本期内容中,我和人工智能从 1800+ 的文章中精心挑选了 50 篇关于编程技术、人工智能、产品设计和商业科技领域的最新资讯和深度解读,旨在帮助您扩展视野,获取最前沿的知识和洞见。欢迎你点击 https://www.bestblogs.dev/#subscribe 链接进行订阅。
在编程技术方面,我们将探讨 Cloudflare 如何利用 Kafka 处理每年万亿条消息的技术细节,并批评当前架构设计中的过度设计问题,倡导简洁高效的 KISS 原则。此外,我们还为您介绍了领域驱动设计(DDD)理论的实际应用,以及前端全球化的实用指南,帮助您在复杂的开发环境中游刃有余。
在人工智能领域,您将了解到微软最新发布的 AI PC——Copilot+ PC,它集成了超过 40 个 AI 模型,支持实时处理和多语言翻译,带来了前所未有的用户体验。我们还将深入分享“AI 教父” Geoffrey Hinton 的最新访谈,探索他在人工智能研究和人才选拔方面的独到见解,并了解提示词技术和框架的进阶文章,Hugging Face 推出的 ZeroGPU 计划,以及 Databricks 如何利用 DSPy 优化大型语言模型(LLM)管道的实际案例。
在产品设计和商业科技部分,英伟达 CEO 黄仁勋分享了公司在 AI 和计算技术领域的最新突破。a16z 联合创始人分享了他们对 AI 和创业的独特见解,探讨了小型 AI 初创公司如何在竞争中脱颖而出。埃隆·马斯克在 VivaTech 大会上的专访则谈到了人类未来的太空探索计划和对人工智能的深切担忧。我们还拆解了 Canva 的 SEO 营销策略,展示了 Zapier 的创业故事,并介绍了如何利用 AI 工具高效创建 PowerPoint 演示文稿和通过语音命令获取答案的新应用程序 Arc Search。
好了,让我们开始阅读吧~
编程技术
深度剖析 Cloudflare 的万亿消息 Kafka 基础设施
Cloudflare 的万亿消息 Kafka 基础设施:深入分析 | BestBlogs
From ByteByteGo Newsletter
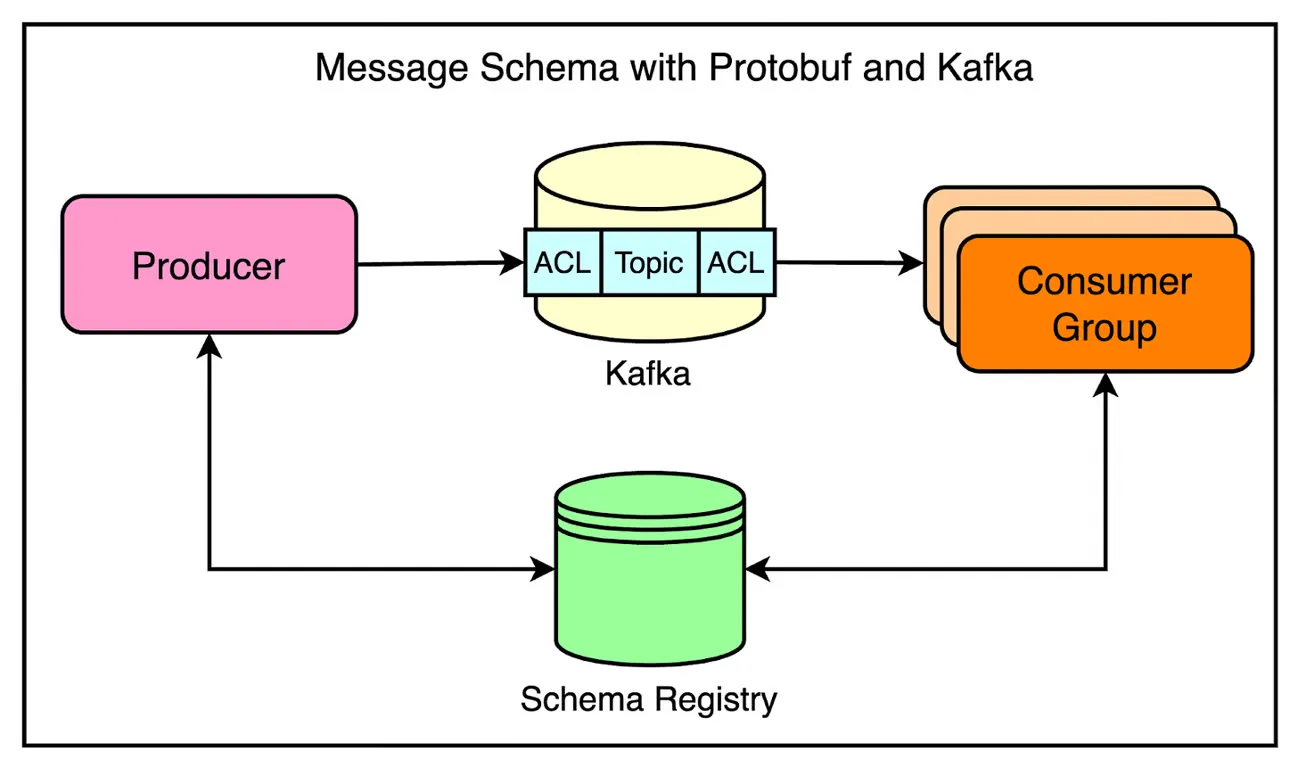
文章详细介绍了 Cloudflare 如何从单体架构转向分布式系统,并成功扩展 Kafka 以处理每年 1 万亿条消息。首先回顾了早期单体架构的局限性,如何通过引入 Kafka 实现服务解耦和重试机制。为了应对服务之间无结构通信的问题,Cloudflare 使用 Protocol Buffers(Protobuf)定义严格的消息格式和架构。"生产者和消费者可以通过架构注册表共享对消息结构的理解。"
在扩展性方面,Cloudflare 通过增强 SDK 的可见性和利用 Kubernetes 的健康检查机制,提升了系统的可靠性和稳定性。他们还通过批量消费优化了邮件系统的处理能力。"智能健康检查的实施改善了值班体验和整体客户满意度。"
结论部分总结了 Cloudflare 的宝贵经验,如在配置和简化之间取得平衡、增强系统可见性、确保生产者和消费者之间的清晰契约,以及在组织内共享知识和最佳实践。"生产者和消费者之间清晰明确的契约对于构建可独立发展的松散耦合系统至关重要。"
过度设计的架构师们,应该拿去祭天
From dbaplus社群
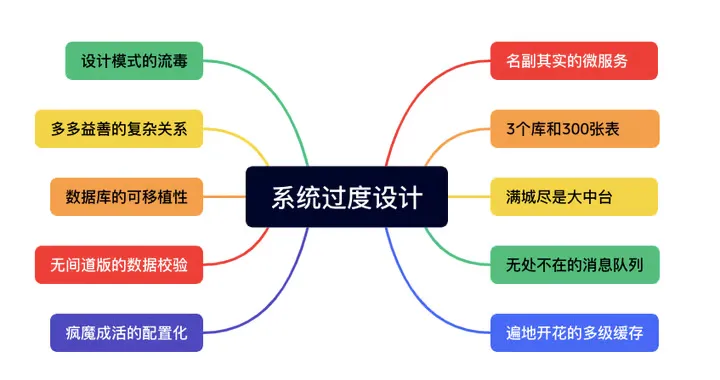
这篇文章吐槽了目前普遍存在的过度设计问题,为了体现架构师的价值,动不动就要系统具备前瞻性、灵活性、复用性、伸缩性、可维护性、可扩展性、低耦合性、高内聚性、可移植性。这里面 90% 都是过度设计。
保持简单就能让系统运行更好,更容易维护扩展,越是资深的人,越明白这个道理。文章批评了软件架构中过度设计的趋势,列举了过度微服务、数据库分区、大中台、消息队列、多级缓存、设计模式、复杂关系、数据库可移植性、数据校验和配置化的几个案例。作者提倡 KISS(保持简单,愚蠢)原则。
DDD 领域驱动设计理论
From 得物技术
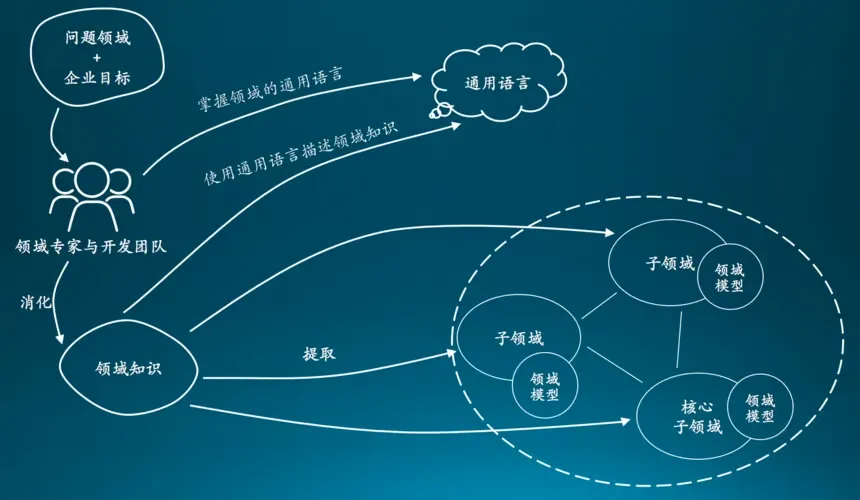
本文深入探讨了领域驱动设计(DDD)理论,这是一种概念上简单但实际上具有挑战性的方法论。文章讨论了 DDD 如何提升技术和业务思考能力,改善全局视野和结构化思维,并提供系统化的技术理念。文章对比了 DDD 与传统的 MVC 架构,强调了 DDD 在处理复杂业务场景中的优势,以及促进统一语言、清晰边界定义和领域能力积累与复用的重要性。同时,文章还涵盖了 DDD 的战略和战术方面,强调其在战略业务建模和战术实施中的作用。
一文搞懂七种基本的 GC 垃圾回收算法
一文搞懂七种基本的 GC 垃圾回收算法 | BestBlogs
From 腾讯技术工程
文章详细介绍了七种常见的垃圾回收(GC)算法及其基本原理,帮助读者建立系统的GC知识框架。作者建议:“学习GC就要系统性的学,形成自己的知识框架,后面再学习其他的GC实现,就知道该放在框架的哪个地方”。文章涵盖了标记-清除法、引用计数法、标记-复制算法、标记-压缩算法、保守式GC、分代垃圾回收和增量式垃圾回收。
20 种不同并发模型示例,带你深入理解并发模型
20 种不同并发模型示例,带你深入理解并发模型 | BestBlogs
From 腾讯技术工程
这篇文章由腾讯程序员分享了 20 种不同并发模型的示例代码,并对每种模型进行了性能测试和分析,旨在帮助读者深入理解并发模型。作者受《Linux 后端开发工程实践》的启发,在其基础上实现了支持长连接的并发模型,并完善了协议解析效率和基准测试工具。
文章的核心在于展示不同的 I/O 模型和并发处理方式,包括阻塞 I/O、非阻塞 I/O、多路 I/O 复用、信号驱动 I/O 和异步 I/O。特别指出,"流式解析(来多少字节,就解析多少字节)+ 协程切换(I/O 不可用时切换到其他协程)+ Reactor 定时器实现非阻塞 I/O 的超时机制,就可以很好的解决这种拒绝服务攻击"。通过这种方式,文章展示了如何高效地处理并发请求,避免服务挂起或 CPU 使用率飙升的问题。
作者将所有相关代码开源在 GitHub 上,项目名为 MyEchoServer,并详细介绍了项目结构和预备工作,包括应用层协议、命令行参数解析和协程池的实现。基准测试工具支持多线程 + Reactor 模型,能产生足够大的请求负载,用于评估并发模型的性能。
总之,这篇文章通过具体的代码实例和详尽的分析,为读者提供了宝贵的学习资源,帮助更好地理解和应用并发模型。
万字长文入门前端全球化
From 字节前端 ByteFE
许多国内企业正积极开拓国际市场,如 Shopee、阿里的 Lazada、字节的 TikTok、拼多多海外版 Temu、以及服装快消领域的 Shein 等。当国内市场存量业务达到峰值预期时,海外业务成为各公司未来收入增长的主要动力,因此,国际化已成为越来越重要的职业发展方向。本文详细解释了前端全球化的完整过程,涵盖了国际化(i18n)和本地化(l10n)的关键概念,并展示了实现面向全球用户的产品所需的技术和文化方面的要求。
全网最佳 websocket 封装:完美支持断网重连、自动心跳!
赶快收藏!全网最佳 websocket 封装:完美支持断网重连、自动心跳! | BestBlogs
From 掘金本周最热
WebSocket 是前端开发中必须掌握的技术,这篇文章封装了weboskect,完美支持了断网重连、自动心跳的功能,且完全兼容原生写法,无任何学习负担,开开箱即用!
VSCode 深度配置 - settings.json
VSCode 深度配置 - settings.json | BestBlogs
From 稀土掘金技术社区
按照这篇文章配置了 VS Code,打字流畅度提升 114 倍。
这篇文章详细介绍了如何通过配置 VSCode 的 settings.json 文件,来提升开发效率和使用体验。作者通过多年经验,总结出了一系列优化配置,从打字流畅度提升到代码提示智能化,覆盖了 VSCode 各方面的功能。
文章说到:“一堆插件推荐的文章,天天叫你装插件实现,明明自带的功能”,许多推荐的插件功能实际上可以通过内置配置实现,合理使用 VSCode 的内置功能,避免插件臃肿带来的性能问题。例如通过 smooth scrolling 和 cursor animations 的配置,可以显著提升打字体验,让输入如流水般顺滑。此外,智能代码提示配置能够减少不必要的错误,提高编码效率,而自定义窗口样式则增加了代码块结构的可读性。
GitHub 最火开源监控系统 Prometheus,我却发现了它的一个 Bug(feature)?
GitHub 上最火开源监控系统 Prometheus,我却发现了它的一个 Bug(特性)? | BestBlogs
From 腾讯云开发者
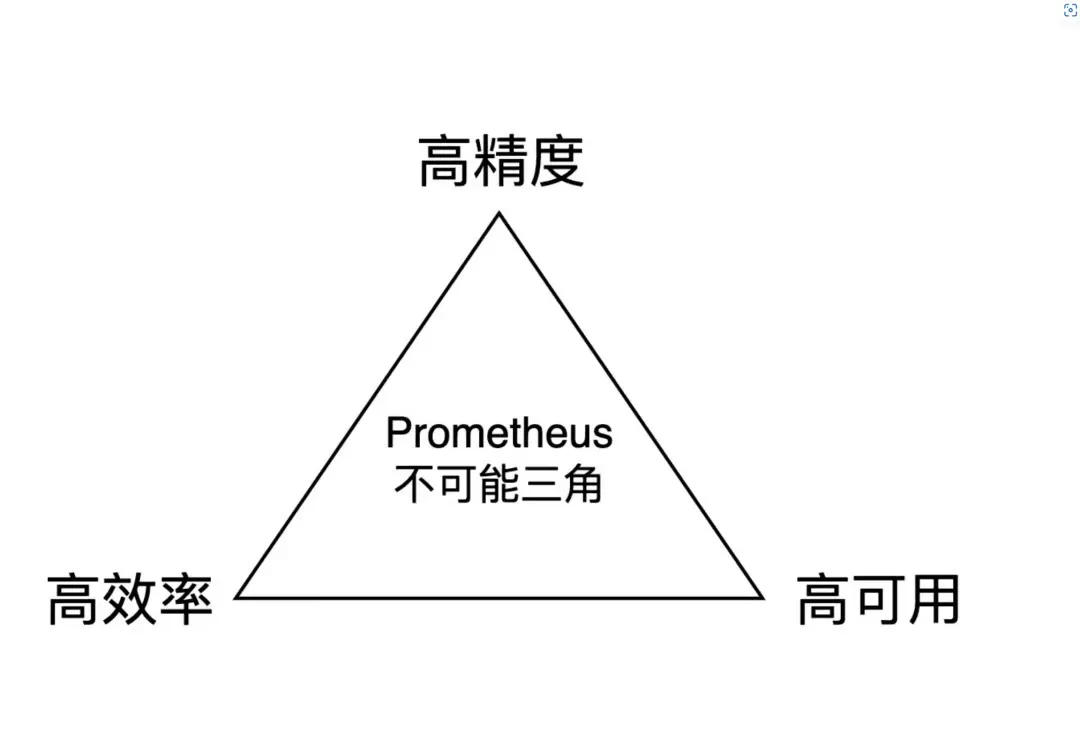
文章深入探讨了 Prometheus 这一源于 Google Borgmon 灵感的热门开源监控系统中存在的指标值不准的“奇怪现象”。尽管被公认为云原生监控的标准,用户常遇到诸如 CPU 核心计数和百分位数值不符等问题。文章阐述了 Prometheus 为保证效率和可用性牺牲精度的原因,涉及外推、插值、窗口对齐等概念。通过实例分析,说明了即使存在不准确性,Prometheus 为何仍被广泛推荐。
AI 驱动的前端 UI 组件生成器(Next.js,GPT4,Langchain 和 CopilotKit)
【第 3268 期】AI 驱动的前端 UI 组件生成器(Next.js,GPT4,Langchain 和 CopilotKit) | BestBlogs
From 前端早读课
本文详细介绍了如何利用 Next.js、GPT4、Langchain 和 CopilotKit 构建一个 AI 驱动的前端 UI 组件生成器。文章通过实例代码和步骤,指导读者如何搭建和运行这个前端 UI 组件生成器,并解释了如何通过整合 CopilotKit 来生成 UI 组件代码和实现教程。
使用 Ollama + Flutter 开发本地跨平台聊天机器人
使用 Ollama + Flutter 开发本地跨平台聊天机器人 | BestBlogs
From 奇舞精选
这篇文章详细介绍了如何使用 Ollama 和 Flutter 开发一个本地跨平台聊天机器人。Ollama 是基于 Go 语言的本地大模型运行框架,Flutter 是 Google 的开源跨平台开发框架。文章展示了在 macOS 和 Android 上的运行效果,讲解了项目结构、聊天页面布局、数据倒序显示及滚动加载更多数据的方法。
一个淘宝服务端工程师的年度总结
From 大淘宝技术
这位开发者的年度总结值得一看!
作者闵大为分享了他在 2023 年的工作和学习中的感悟与心得。文章围绕领域驱动设计、知识积累与应用、判断力培养等多个方面展开,提供了丰富的实践经验和深刻的思考。
作者通过总结《实现领域驱动设计》的学习过程,强调在学习过程中需要自己的思考与判断:“不是‘跟着跑’就算真正的努力,在跟随过程中,如果缺少自己的思考与判断,往往成长很慢。” 他还指出,结构化的系统知识是提升的关键,尤其是具备“好奇心”和“求知欲”以及“学以致用”的心态。
在谈到判断力的培养时,作者提到:“收集判断信息、基于投入产出的量化公式、模拟仿真是做出正确判断的三个要点。” 他通过生活中的开车经历,生动地说明了如何在信息不全的情况下做出理性决策。
此外,作者分享了从理论到实践的过程,强调亲身实践的重要性:“如果你不迈出这一步,那么一直都会是‘再等一等,会更好’。” 他通过“简洁应用框架 VSEF”项目,将知识整合并输出,体现了对自我认知的不断完善。
最后,作者表示,写文章的不易和坚持是他前进的动力:“每篇文章都当做和读者的一次深度对话,虽然互相看不到,但这的确是我前进的动力。”
Building a Copilot for Git History With pgvector & Timescale
使用 pgvector 和 Timescale 构建 Git 历史辅助工具 | BestBlogs
From Timescale Blog
在这篇文章中,John McBride 详细介绍了 OpenSauced 团队如何利用 Timescale 和 pgvector 构建一个 Git 历史的 Copilot,以提供开源项目的实时洞察和指标。OpenSauced 团队面临的主要挑战是处理和存储 GitHub 上不断产生的海量数据。他们选择 Timescale 作为时间序列数据的核心技术,结合 pgvector 实现矢量存储和搜索,从而开发了名为 StarSearch 的 AI 功能。
- Timescale 在时间序列数据处理方面的卓越性能,帮助 OpenSauced 以极高的速度和可靠性处理 GitHub 事件数据。
- pgvector 的使用简化了数据存储和搜索过程,避免了数据重复和复杂的数据库管理。
- OpenSauced 团队通过熟悉的 PostgreSQL 技术减少了学习成本,提高了开发效率。
作者表示:“通过使用 pgvector 将我们 Timescale 中拉取请求事件表中的相关信息与 LLM 提示结合,我们为用户解锁了一种全新的洞察方式。”
Introducing GitHub Copilot Extensions: Unlocking unlimited possibilities with our ecosystem of partners
介绍 GitHub Copilot 扩展:通过我们的合作伙伴生态系统解锁无限可能 | BestBlogs
From The GitHub Blog
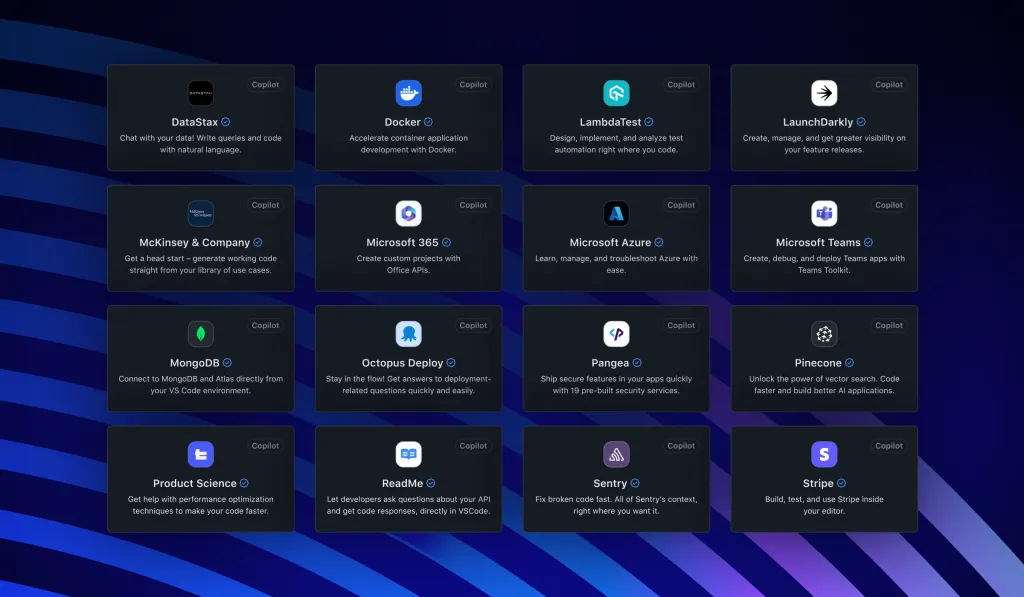
Copilot 的世界正在变得更大,通过让开发者保持更长时间的工作流并允许他们用自然语言做更多事情来改善开发者体验。GitHub Copilot 扩展使开发者能够使用他们喜欢的工具和服务在不离开 IDE 或 GitHub.com 的情况下构建和部署到云端。主要合作伙伴包括 DataStax、Docker、LambdaTest 等。扩展支持 GitHub Copilot Chat、Visual Studio 和 VS Code。组织还可以为内部工具创建私有扩展。此举旨在减少上下文切换,保持工作流状态,并加速软件交付。
Spring Boot 3.3.0 available now
Spring Boot 3.3.0 现已推出 | BestBlogs
From Spring Blog
Spring Boot 团队宣布了 3.3.0 版本的发布,并介绍了该版本的多个新特性和改进。新版本主要包括:
- CDS 支持:改进启动时间,减少内存消耗。
- 可观测性改进:支持 Micrometer 的 @SpanTag,新增 Process InfoContributor 和 Prometheus 1.x 支持。
- Spring Security 改进:JwtAuthenticationConverter 的自动配置。
- 服务连接支持:支持 Apache ActiveMQ Artemis 和 LDAP。
- Docker Compose 支持:兼容 Bitnami 容器镜像。
- 虚拟线程支持:Websockets 的虚拟线程支持。
- Base64 资源支持:在属性文件和 YAML 文件中支持 Base64 资源。
- SBOM 支持:新增 SBOM actuator 端点。
- 文档重构:基于 Antora 完全重新设计的文档。
- SSL SNI 支持:嵌入式 Web 服务器的 SSL SNI 支持。
- 依赖升级:升级到多个 Spring 项目的新版本,并采用最新稳定版本的第三方库。
Celebrating Kotlin 2.0: Fast, Smart, and Multiplatform
庆祝 Kotlin 2.0:快速、智能、多平台 | BestBlogs
From The JetBrains Blog
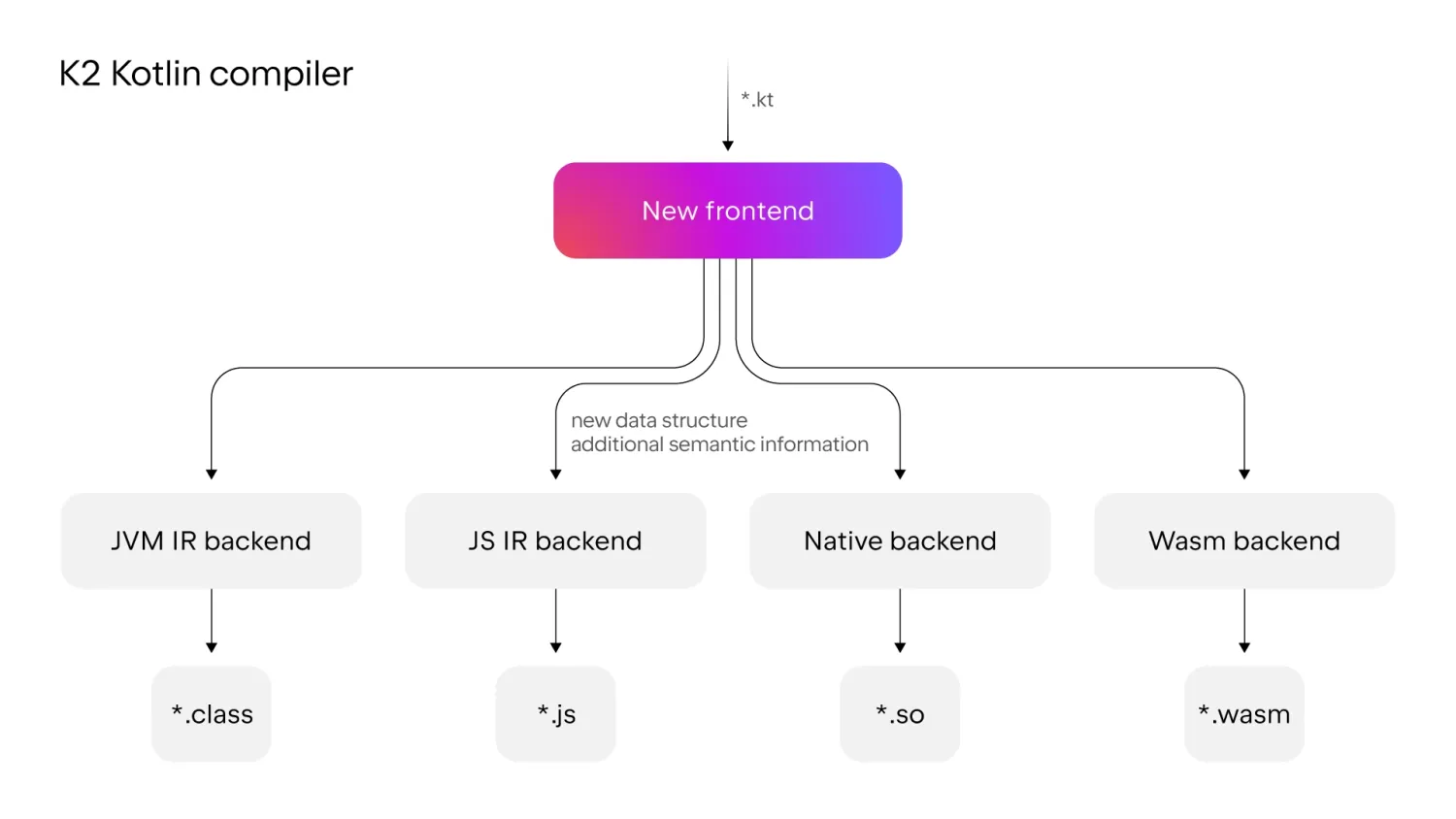
Kotlin 2.0 正式发布,带来了稳定且高效的 K2 编译器,它在编译速度、代码分析和多平台支持方面都有显著提升。Kotlin 因其简洁和安全的语法而受到开发者的欢迎,并已成为 Android 开发的主要语言。Kotlin 多平台(KMP)支持跨多个平台共享代码,而 Kotlin 2.0 在 KMP 方面引入了更多增强功能,包括对 Compose Multiplatform 项目的原生支持。
AI Gateway is generally available: a unified interface for managing and scaling your generative AI workloads
AI 网关现已全面可用:统一界面管理与扩展您的生成式 AI 工作负载 | BestBlogs
From The Cloudflare Blog
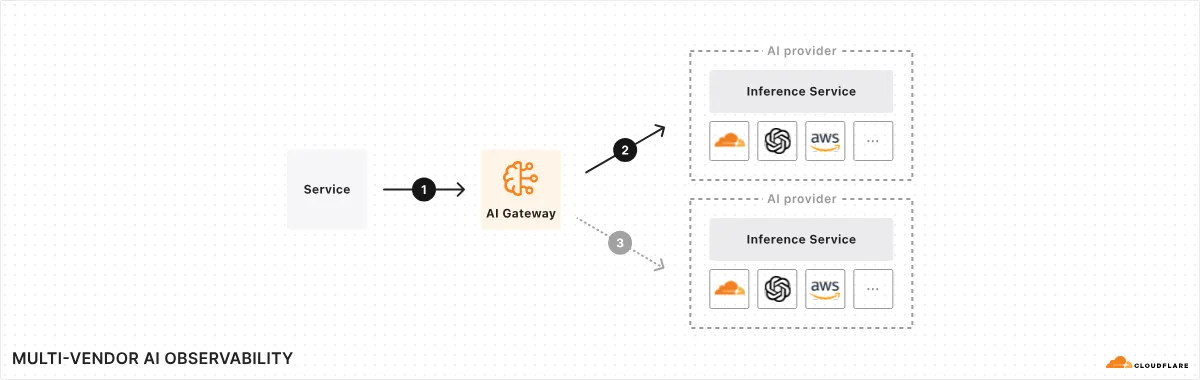
由 Cloudflare 推出的 AI 网关现已全面可用。该 AI 运维平台提供了一个统一界面,用于管理和扩展生成式 AI 工作负载,通过一行代码即可提供速率限制、自定义缓存、实时日志和跨多个提供商的聚合分析等功能。它作为您的服务与推理提供商之间的代理,增强了性能、安全性、可靠性和可观测性。
Vercel Ship 2024 recap
Vercel Ship 2024 回顾 | BestBlogs
From Vercel News
在 Vercel Ship 2024 活动中,Vercel 推出了多项新功能,旨在提升前端开发的效率和安全性。Vercel Ship 2024 展示了前端云的强大功能,强调了集成、生态系统和团队构建网络最佳产品的能力。主要发布的新功能包括:
- 改进的 Vercel 平台和 Next.js 集成:新的特性标志(Feature Flags)集成,使开发者可以更轻松地在 Vercel Web Analytics 和日志中查看特性标志的影响。
- Vercel 防火墙:这款新防火墙功能允许用户创建自定义规则来记录、阻止、挑战或限速(测试版)流量,提供了强大的应用安全性管理。防火墙配置更改可在全球范围内 300 毫秒内传播,并支持快速回滚。
- Vercel 工具栏改进:新工具包括 Open Graph 预览、无障碍审计和交互时序,帮助优化网站响应性和用户体验。
- Next.js 15 发布候选版:支持 React 19 RC 和 React 编译器(实验性),改进了缓存机制,并引入了新的局部预渲染和 next/after API(实验性)。
- v0 和 Vercel AI SDK:v0 通过增强平台可靠性和自动添加 ARIA 属性,使从想法到 UI 的生成更快更可靠。Vercel AI SDK 是一个 TypeScript 库,用于构建支持 AI 的应用,简化了构建智能网页应用的流程。
You should keep a developer’s journal
From Stack Overflow Blog

这篇文章分享了每个开发者都应该养成的一个好习惯:记录开发者日志。
开发者保持日志可以显著提高编程效率,并有助于职业发展。开发者日志不仅帮助定义问题、减少不确定性,还能从经验中学习、避免分心和管理情绪。文章中提到:“开发者日志是一个定义你正在解决的问题并记录你尝试过的方法和有效方法的地方。”通过记录问题和假设,可以更快找到解决方案。作者建议在工作开始前明确当天的目标,并在遇到困难时记录思考过程。文章还指出,写日志有助于将脑海中的问题和任务记录下来,避免打断当前工作:“将你头脑中的想法或问题写在日志中,然后再处理。”保持日志不仅能帮助理清思路,还能在回顾时发现自己的成长和不足。
此外,文章强调日志是个人的思维组织工具,写得清晰易读即可,无需追求完美:“你的开发者日志是你用来组织和处理思维的私人文件,写得清楚易读即可,但不需要达到别人认为的‘好写作’标准。”这种记录方式不仅有助于开发者个人的成长,也可以在团队中分享经验,促进共同进步。
Online Safety – A Guide to Protecting Yourself
From freeCodeCamp
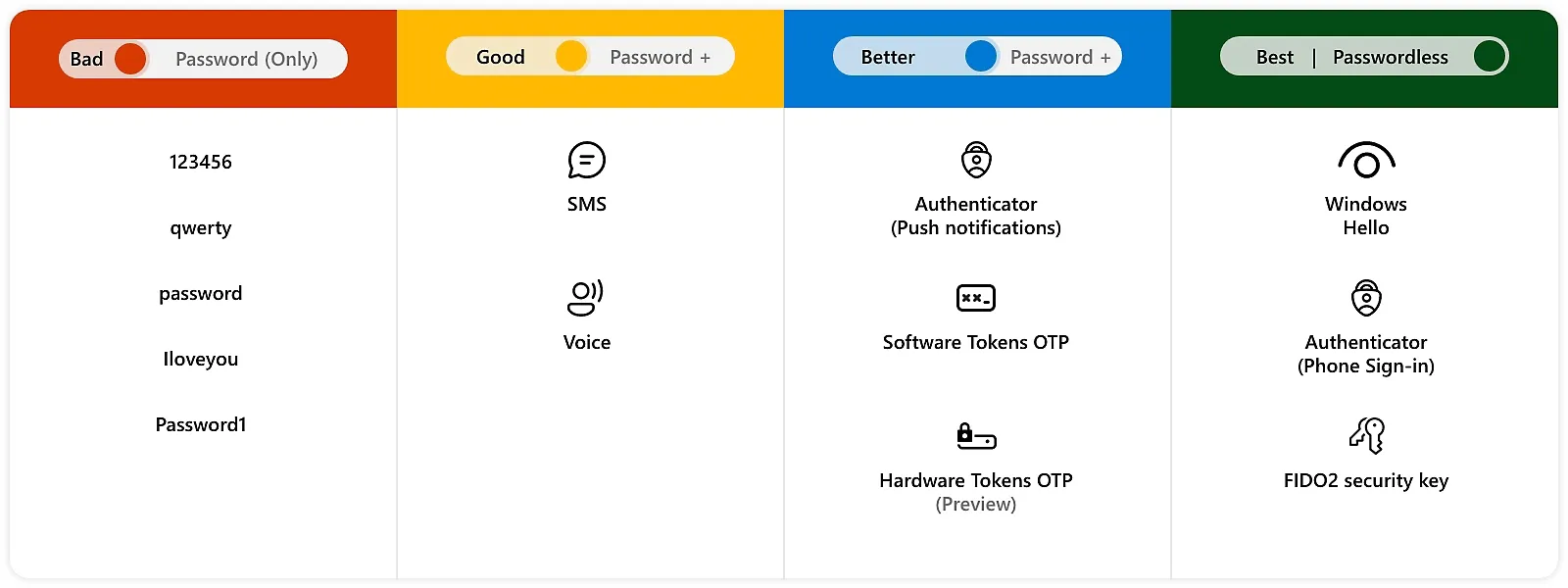
在现代社会,保护数字账户的安全至关重要,文章详细探讨了如何确保在线账户的安全。随着互联网的发展,用户名和密码系统成为识别个人身份的常见方式,但也带来了许多安全隐患。常见的网络攻击方式包括网络钓鱼、身份盗窃和社会工程攻击等。为了应对这些威胁,文章提出了几项关键策略:
- 无密码登录方法:使用面部识别(Face ID)、指纹登录或密码钥匙(Passkeys)。这种方法“更容易使用且更加安全,减少了许多常见的在线安全问题”。
- 密码管理工具:如 BitWarden 或 1Password,帮助创建和管理强密码。
- 多因素认证(MFA):通过时间基 OTP(TOTP)或邮件验证增加额外的安全层,即使密码被泄露,也能显著降低风险。
文章强调:“密码管理器简化了密码管理,提高了安全性。”这种方法虽然初期设置有些复杂,但长远来看,安全性和便捷性大大提升。通过这篇文章,读者可以了解在线安全的重要性,并学会如何保护自己的数字身份和个人信息。希望这些建议能帮助你在互联网上安心浏览。
人工智能
微软重新定义 AI PC:与 GPT-4o 共享一个屏幕,看过的东西再也不会忘
微软重新定义 AI PC:与 GPT-4o 共享一个屏幕,看过的东西再也不会忘 | BestBlogs
From 量子位

微软发布了新一代 AI PC,即 Copilot+ PC,集成了 40 多个 AI 模型,支持 AI 实时处理。这款新 PC 在游戏时可与 AI 实时对话,支持自然语言搜索文件和浏览记录,并能实时翻译 40 多种语言。它采用了结合 CPU、GPU 和 NPU 的新系统架构,增强了 AI 工作负载的功能 20 倍,效率提高 100 倍。该 PC 旨在理解用户,而非用户理解它,并由高通的骁龙 X Elite 处理器驱动,采用 ARM 架构以提升电池续航。
AI 教父 Hinton 最新万字精彩访谈:直觉,AI 创新的洞见和思考,未来
AI 教父 Hinton 最新万字精彩访谈:直觉,AI 创新的洞见和思考,未来 | BestBlogs
From Web3天空之城

在这篇精彩的访谈中,被誉为“AI 教父”的 Geoffrey Hinton 分享了他在人工智能研究、人才选拔以及与合作伙伴共事方面的独到见解。Hinton 强调直觉在选拔人才中的重要性,并回忆了他在卡内基梅隆大学的经历,感受到学生对未来的信心与投入。
Hinton 认为系统规模和数据量是科技进步的关键因素,尽管新算法如 Transformer 也很重要。他解释了大型语言模型通过寻找共同结构来提高编码效率,并通过类比进行创新。他指出:“大型语言模型应通过推理进行训练,而不仅仅是模仿人类行为。”此外,他提到多模态学习将极大地提升模型的理解和推理能力。
在探讨大脑与人工智能的关系时,Hinton 提出了三种观点:符号观点、向量观点和嵌入观点,认为“将符号转换成大向量是最合理的模型”。他回顾了早期使用 GPU 进行神经网络训练的直觉,强调了这种方法对机器学习研究的重要性。
Hinton 还讨论了 AI 助手的潜力和社会影响,特别是在医疗保健领域。他指出:“如果助手具有自我反省的能力,那么它们也可能有感觉。”他也表达了对 AI 可能被用于恶意行为的担忧。
这篇访谈文章不仅展现了 Hinton 在 AI 领域的深刻洞见,还为我们理解大脑与人工智能的本质提供了宝贵的思考。
月之暗面杨植麟:互联网研发是“种树”,大模型研发是“承包森林”
月之暗面杨植麟:互联网研发是“种树”,大模型研发是“承包森林” | BestBlogs
From 腾讯科技
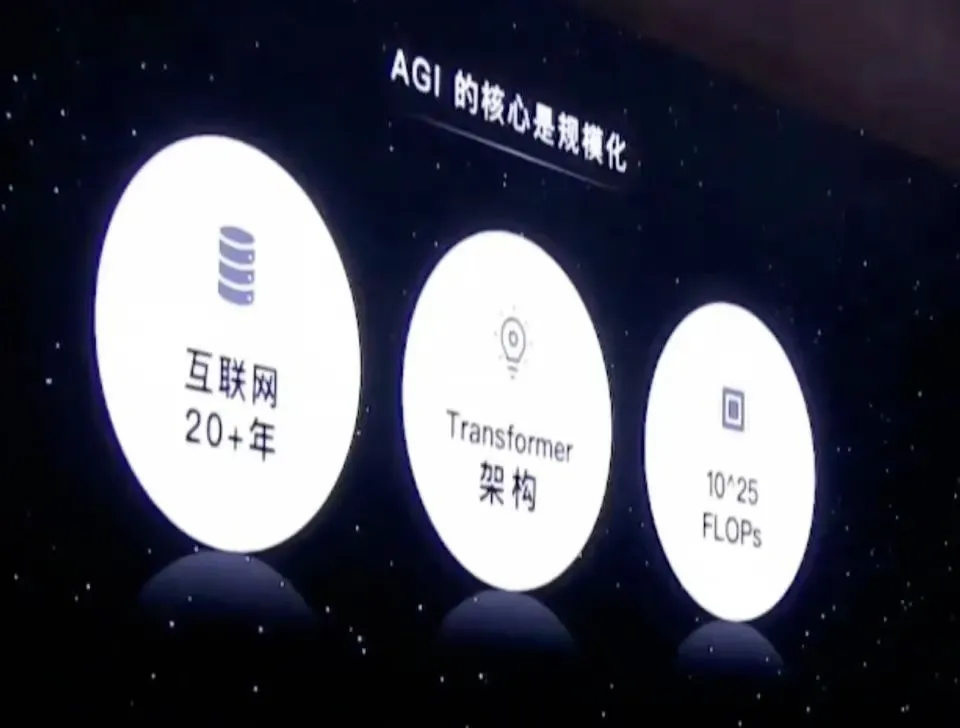
在第五届上海创新创业青年 50 人论坛上,月之暗面创始人杨植麟发表了演讲,分享了他的创业初衷和心得。他形象地比喻互联网研发为“种树”,强调其专注于单一功能和项目的深耕,而大模型研发则如“承包森林”,涵盖广泛、多样的技术应用,代表了更加宏大的视野和系统的复杂性。杨植麟指出,AI 的发展得益于互联网、Transformer 架构和半导体技术的发展,这三个因素共同促成了 AI to C 的机会。他提到,“互联网最大的价值,其实是为 AI 积累了二十多年的数据”。他强调,多模态技术和数据瓶颈的突破是 AGI 发展的关键,需要通过生成数据来扩展数据集,并认为算力的提升和利用率是决定模型性能的关键因素。杨植麟还预测,随着技术的发展,“AI 在工作流程中的角色将大幅增加”,从而提高整体效率和创新能力。他表示,希望在创业过程中把更多精力放在“爬楼梯”上,而不仅仅是“看风景”,以此回应技术研发和商业变现之间的平衡取舍。
MiniMax 闫俊杰:今天的 AI 应用都不会成为 Super App,但这不重要
MiniMax 闫俊杰:今天的 AI 应用都不会成为 Super App,但这不重要 | BestBlogs
From Founder Park

MiniMax 创始人兼 CEO 闫俊杰分享了对 AI 技术和应用的深入见解。他认为,当前的 AI 应用不太可能成为像微信一样的超级应用,但这并不重要,关键在于技术的底层创新和用户体验的提升。
闫俊杰提到,OpenAI 的 GPT-4o 发布会展示了惊艳的语音交互效果,但技术实现其实并不复杂。这反映了 OpenAI 从底层思考问题的能力。相比之下,谷歌的发布会展示了多模态 AI 搜索,尽管难度较高,但对用户体验的提升非常显著。
他强调:“多模态融合是 AI 行业的‘必答题’,决定了效率类产品的成败。”当前全球每天使用 AI 产品的人只有四千多万,而移动端的渗透率不到 1%,远低于短视频、长视频和社交产品的 50% 以上。未来的 AI 产品公司应当努力让更多场景和人群使用 AI,提高用户渗透率。
此外,闫俊杰认为,AI 助手可以让手机操作系统占领更多用户时间,因为它可以满足多样化需求。他还提到,语音交互相比文字交互更便宜,因为语音处理速度较慢。AI 产品的核心挑战在于优化语言模型和多模态模型的结合,以提升整体模型的上限。
闫俊杰指出:“对做模型的公司来说,自己做产品几乎是必然的选择。对做产品的公司也是一样,如果它们的产品做得很大,它们也希望自己掌控模型。”他认为,AI 公司的创新必须体现在技术和产品体验上,只有这样才能在激烈的竞争中立足。
百川智能发布 Baichuan 4 及首款 AI 智能助手百小应,模型能力国内第一
百川智能发布 Baichuan 4 及首款 AI 智能助手百小应,模型能力国内第一 | BestBlogs
From 百川大模型
5 月 22 日,百川智能发布最新一代基座大模型 Baichuan 4,并推出成立之后的首款 AI 助手“百小应”。 Baichuan 4 相较 Baichuan 3 在各项能力上均有极大提升,其中通用能力提升超过 10%,数学和代码能力分别提升 14%和 9%,在国内权威大模型评测机构 SuperCLUE 的评测中,模型能力国内第一。 此外,Baichuan 4 还具备行业领先的多模态能力,在各大评测基准上表现优异,领先 Gemini Pro、Claude3-sonnet 等多模态模型。 在 Baichuan 4 强大能力的基础上,百川智能将搜索技术与大模型深度融合,推出懂搜索、会提问的 AI 助手“百小应”。
Prompt 高阶 | 链与框架
From 人人都是产品经理
一篇全面介绍提示词技术和框架的进阶文章,首先介绍了 Prompt 的基本概念,即指向模型的输入文本或指令,用以引导模型生成特定输出。接着,详细阐述了不同类型的 Prompt 技术:
- 零样本(Zero-shot):不需要针对特定任务的参考样本,仅依赖模型的泛化能力进行推理和输出。
- 小样本(Few-shot):通过提供少量示例,引导模型进行学习和推理。
- 思维链(CoT):要求模型展示推理过程,而非直接给出答案,包括无样本参考思维链、示例说明和自我一致性(CoT-SC)。
- 思维树(TOT):通过递进的中间结果组织推理过程,使用树状结构进行思维追踪和评估。
- 思维图(GoT):将信息建模为图结构,顶点代表信息单位,边代表依赖关系,实现更复杂的思维模式。
- Boosting of Thoughts(BoT):通过迭代优化的方式,逐步增强思维推理链条的质量。
文章还提供了 Prompt 编写技巧,如撰写清晰具体的指令、结构化输出、条件控制、模型思考时间等,并介绍了几种 Prompt 框架,如 ICLR 上提出的 ICIO、CRISPE、RGCS 等,以及如何基于这些框架优化 Prompt。
最后,文章探讨了 Prompt 的应用场景,包括 LLM 意图识别、格式化输出和 Agent 框架,并强调了通过迭代和优化提高 LLM 输出效果的重要性。
AI 开发者必备〖LLM 选购指南〗,搞定全球极致性价比!(薅尽大模型降价的羊毛
主题日报◉AI 开发者必备〖LLM 选购指南〗,搞定全球极致性价比!(薅尽大模型降价的羊毛 | BestBlogs
From ShowMeAI研究中心
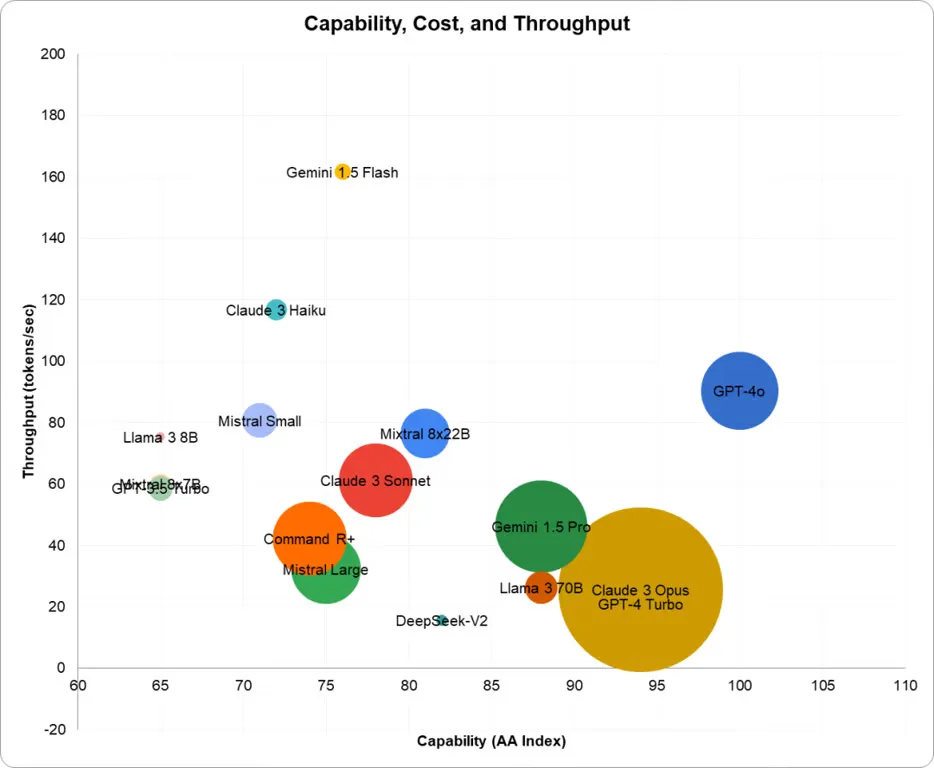
- 5月6日,深度求索发布 DeepSeek v2,依仗其架构创新带来的推理成本降低,把国产大模型价格卷到每百万 token 输入只需要 1 元人民币的价格洼地。
- 5月11日,智谱宣布 GLM-3-Turbo 降价,128K 上下文,每百万 token 价格与 DeepSeek v2 持平。
- 5月15日,字节发布豆包大模型,32K上下文版本,每百万token输入价格降至 0.8 元,输出是 2 元。虽然没有其发布会 PPT 宣传的那么夸张,但价格是实打实降低了。
- 5月21日,阿里宣布通义9款大模型降价,其中 Qwen-Long 每百万token输入价格降至 0.5 元 (降价幅度高达 97%),输出是2元 (降价幅度高达 90%)。
- 5月21日,百度宣布文心大模型的 ERNIE Speed、ERNIE Lite 两款模型免费,包括了 8K 和 128K 上下文版本。
- 5月22日,腾讯宣布主力模型混元 Lite免费。混元 Standard 每百万token输入价格降至 4.5 元,输出是 5 元;新上线的混元 Standard 256K 新模型每百万token输入价格降至15 元,输出是60 元;降价幅度超过 50%。
接下来一段时间,AI开发者们势必密切关注国内外大模型价格和性能!
Hugging Face ZeroGPU 计划正式发布——提供价值一千万美元的免费共享 GPU
Hugging Face ZeroGPU 计划正式发布——提供价值一千万美元的免费共享 GPU | BestBlogs
From Hugging Face
Hugging Face 推出 ZeroGPU 计划,提供价值一千万美元的免费高性能 GPU,旨在降低人工智能领域研究人员和开发者的门槛,推动 AI 技术的普及和创新,通过提供 GPU 资源优化 AI 模型部署和性能。
Meta 首发「变色龙」挑战 GPT-4o,34B 参数引领多模态革命!10 万亿 token 训练刷新 SOTA
Meta 首发「变色龙」挑战 GPT-4o,34B 参数引领多模态革命!10 万亿 token 训练刷新 SOTA | BestBlogs
From 新智元

Meta 团队发布的最新“混合模态”模型 Chameleon,它能够在单一神经网络中无缝处理文本和图像。经过 10 万亿 token 训练,Chameleon 拥有 34 亿参数,其性能接近 GPT-4V,并刷新了 SOTA 基准。Chameleon 采用统一的 Transformer 架构,使用文本、图像和代码进行训练,通过早期融合方法,将所有输入映射到一个共同的表示空间,从而实现无缝处理。Meta 团队还引入了一系列架构创新和训练技术,以应对训练过程中遇到的挑战。Chameleon 在各种基准测试中表现优于 Llama 2,并与 Mixtral 和 Gemini Pro 等领先模型竞争。正如文章中所提到的,“Chameleon 在纯文本任务中,性能和 Gemini Pro 相当”,并在视觉问答和图像标注基准上刷新了 SOTA,显示出强大的多模态处理能力。
Karpathy 称赞,从零实现 LLaMa3 项目爆火,半天 1.5k star
Karpathy 称赞,从零实现 LLaMa3 项目爆火,半天 1.5k star | BestBlogs
From 机器之心
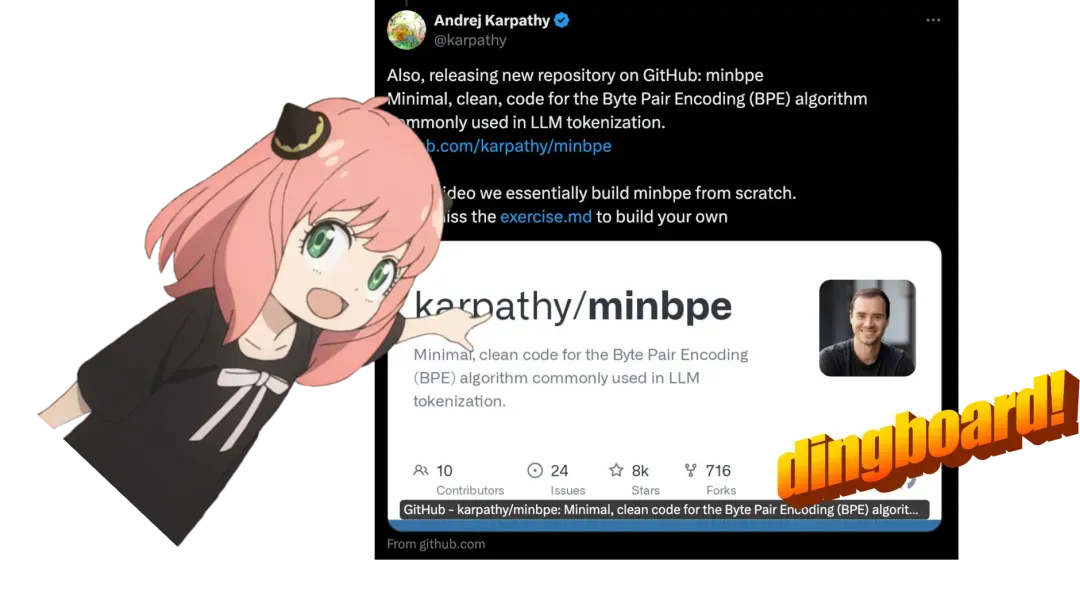
开发者 Nishant Aklecha 发布了从零实现 LLaMa3 模型的项目,该项目在 GitHub 上迅速走红,发布半天内获得 1.5k star,并得到了知名 AI 研究员 Karpathy 的高度评价。
文章详细介绍了该项目的技术实现,包括跨多个头的注意力矩阵乘法、位置编码等核心部分。项目不仅提供了完整的代码和解释,还通过加载 Meta 提供的 LLaMa3 模型文件、实现分词器、构建模型层和注意力机制,展示了从零开始实现复杂 AI 模型的全过程。
对于开发者和 AI 从业者而言,这篇文章提供了宝贵的学习资源和实践机会,通过详细的代码实现和解释,帮助他们深入理解大模型的内部机制和实现细节。
映射大语言模型的思维 [译]
From 宝玉的分享

Anthropic 团队展示了对现代生产级大语言模型 Claude Sonnet 的内部机制进行详细研究的重大突破。研究识别出数百万个概念在模型中的表示方式,有助于提升 AI 模型的安全性和可解释性。这项工作具有里程碑意义,揭示了 AI 模型内部复杂行为的特征。
- 模型内部表示的揭示:通过字典学习技术,识别出 Claude 3.0 Sonnet 模型中数百万个特征,涵盖城市、人物、科学领域等具体概念,以及编程语法和抽象情感等。
- 特征的多模态和多语言表现:这些特征不仅能对文本作出反应,还能对图像中的概念作出反应。例如,金门大桥特征在多种语言和图像输入中都能激活。
- 操控特征的实验:通过人工放大或抑制特征,观察模型行为的变化。例如,放大“金门大桥”特征,使 Claude 回答集中于金门大桥,甚至在无关问题中也是如此。
- 安全性提升的潜力:发现与安全性相关的特征,如代码漏洞、欺骗、偏见等,可以监控和引导 AI 系统行为,减少偏见,防止有害内容生成。
正如文章所述:“这种现象在更高层次的抽象概念中也适用,表明 AI 模型内部的概念组织在某种程度上反映了人类对相似性的理解。” 这揭示了模型内部机制的复杂性和潜在的安全改进方法。通过这些研究,Anthropic 希望进一步提升 AI 模型的透明度和可靠性,确保其在实际应用中的安全性。
Automate online tasks with MultiOn and LlamaIndex — LlamaIndex, Data Framework for LLM Applications
使用 MultiOn 和 LlamaIndex 自动化在线任务 — LlamaIndex,LLM 应用程序的数据框架 | BestBlogs
From LlamaIndex Blog
本文探讨了 MultiOn(一个 AI 代理平台)与 LlamaIndex(LLM 应用程序的数据框架)的集成。文章展示了这些技术如何自动化和简化网络交互,重点是通过技术演练管理电子邮件交互和网络浏览。集成过程包括设置 AI 代理、整合 Gmail 搜索工具、使用必要的工具初始化代理,并执行代理的任务流程以搜索、总结和生成对电子邮件的响应。
New models added to the Phi-3 family, available on Microsoft Azure
微软 Azure 新增 Phi-3 系列模型 | BestBlogs
From Microsoft Azure Blog
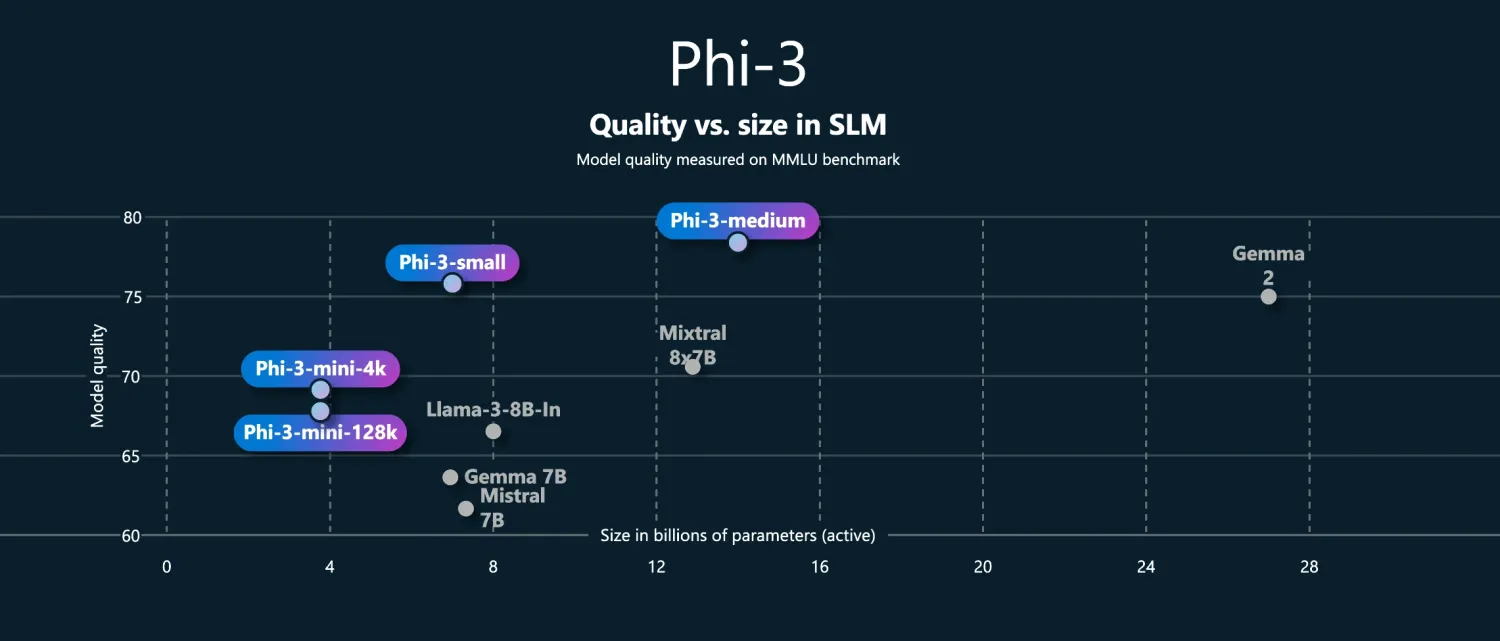
Microsoft Azure 宣布在 Phi-3 系列中新增多个模型,包括 Phi-3-vision,这是一款结合语言和视觉能力的多模态模型。Phi-3-vision 拥有 4.2B 参数,能够处理图像和文本的推理任务,尤其适用于图表和图形理解。
此外,Phi-3 系列还包括其他模型:
- Phi-3-mini:具有 3.8B 参数,提供 128K 和 4K 两种上下文长度。
- Phi-3-small:具有 7B 参数,提供 128K 和 8K 两种上下文长度,超越同尺寸及更大尺寸的模型。
- Phi-3-medium:具有 14B 参数,提供 128K 和 4K 两种上下文长度。
文章指出:“这些小型语言模型具有强大的推理能力,同时具备高效和经济的优势。”Phi-3 系列模型优化了多种硬件的运行效率,适用于 NVIDIA GPU 和 Intel 加速器,并通过 ONNX Runtime 和 DirectML 提供支持。
2024 GitHub Accelerator: Meet the 11 projects shaping open source AI
2024 GitHub 加速器:了解塑造开源 AI 的 11 个项目 | BestBlogs
From The GitHub Blog
GitHub 加速器宣布第二期入选项目,致力于促进全球开源 AI 项目的发展与创新,涉及领域广泛,包括模型微调、测试平台、AR/VR 及机器人导航等。
- unsloth AI - 由澳大利亚的 Daniel 和 Michael Han 兄弟创立,旨在使定制 AI 模型更易于访问。unsloth 利用新兴技术和能力,以更快的速度和更少的内存微调开源模型。
- Giskard - 由 Alex Combessie 和 Weixuan XIAO 建立,是一个用于测试和评估大语言模型的开源库,旨在提高 AI 模型的质量、透明度和问责制。
- A-Frame - 由 Diego Marcos 开发,是一个使 AR/VR 和 3D 内容开发在网页浏览器中变得易于访问的框架,现重点集成 AI 工作流。
- Nav2 - 由 Steve Macenski 领导,是一个用于机器人操作系统 (ROS) 导航框架,已被全球多家公司采用,提供可靠和高效的机器人技术部署。
- OpenWebUI - 由 Tim Baek 创立,旨在构建最佳用户界面,使有限或无互联网接入的人也能利用 AI 技术。
- LLMware.ai - 由 Namee Oberst 创立,专注于构建安全和敏感的 LLM AI 代理和 RAG 模型,适用于金融和法律机构。
- LangDrive - 由 Michael Vandi 和 Spatika 创建,提供一个简单的框架,通过 API 和配置文件训练和部署生产级语言模型。
- HackingBuddyGPT - 由 Andreas Happe 和 Jurgen Cito 创建,旨在帮助道德黑客和安全专业人员利用 LLMs 提高安全性。
- Web-Check - 由 Alicia Sykes 创立,旨在通过 AI 驱动的安全洞察使互联网更安全。
- marimo - 由 Akshay Agrawal 和 Myles Scolnick 创立,提供一个可重现、可维护和可生产化的 Python 笔记本,用于 AI 和机器学习。
- Talkd.ai - 由 Vinicious Mesel 创立,提供一个统一的 LLM 聊天 API,使多种 LLM 和上下文的抽象层更易于管理和使用。
Optimizing Databricks LLM Pipelines with DSPy
使用 DSPy 优化 Databricks LLM 管道 | BestBlogs
From Databricks
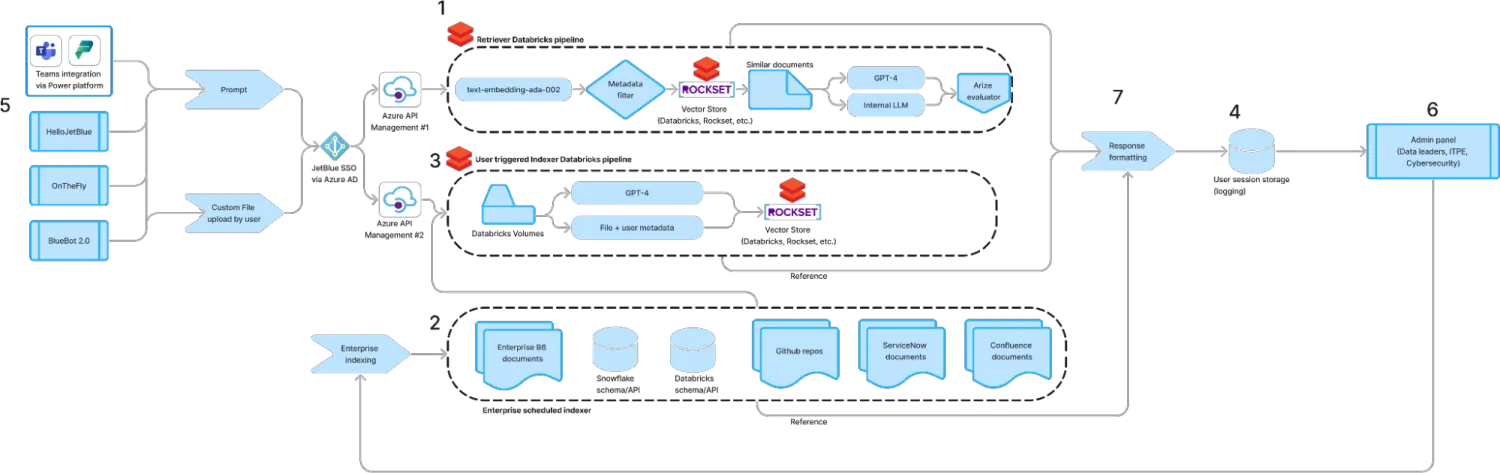
Databricks 博客文章介绍了 DSPy,该库将声明式语言模型调用编译为自我改进的管道。DSPy 通过多阶段管道和模块化设计,优化了大型语言模型(LLM)的性能,提升了自然语言处理应用的效率。
DSPy 的自我改进能力显著提高了回答质量和检索精度,减少了手动调整提示词的需求。JetBlue 的案例展示了 DSPy 的强大功能,从客户反馈分类到预测性维护聊天机器人,DSPy 帮助他们快速开发先进的 LLM 解决方案,提高运营效率。
正如文章所述:“这些现成的平台高度依赖于超出最终用户和管理员控制范围的参数。通过构建结合 LLM 调用和传统软件开发的复合系统,企业可以轻松适应和优化这些解决方案以满足其需求。” 这强调了 DSPy 在构建高效、灵活且可控的 AI 应用中的重要性。
Large Language Models for Code: Exploring the Landscape, Opportunities, and Challenges
代码大语言模型:探索现状、机遇与挑战 | BestBlogs
From InfoQ

本文是 Hugging Face 的机器学习工程师 Loubna Ben Allal 发表的关于代码领域大语言模型(LLMs)的演讲,详细介绍了 LLMs 的起源、培训过程、现状及未来展望。
大语言模型在代码领域的应用起源于 2021 年的 GitHub Copilot,这显著提高了代码完成的效果;训练 LLMs 需要大量资源,包括 GPU 和海量数据;代码 LLMs 的训练过程包括预训练、监督微调(SFT)和通过人类反馈的强化学习(RLHF)。文章还介绍了多个开源代码生成模型,如 BigCode 项目、Meta 的 Code Llama 以及 Salesforce 的 CodeGen。
BigCode 项目特别强调数据透明性和开源,发布了 StarCoder 和 StarCoder2 模型。正如 Loubna 所言:“我们很自豪能够通过 BigCode 项目为社区训练这些模型,采用开放和透明的方式。”这一项目不仅提供了最大的开源代码数据集 The Stack,还允许用户检查并选择退出其代码是否在数据集中。
产品&设计&商业&科技&思维
为什么说互联网方法论在 AI 上差不多全是错的
为什么说互联网方法论在 AI 上差不多全是错的 | BestBlogs
From 人人都是产品经理
在这篇文章中,作者深入探讨了为什么互联网的方法论在人工智能领域几乎全然无效。文章指出,互联网的核心在于“链接”,其价值来源于“借”,强调单点突破和快速扩展。然而,人工智能的核心特征是“智能”,其目的是直接创造价值,提升价值创造的效率。这种深层次的差异决定了两者需要完全不同的方法论。
正如作者所言:“智能是用来直接创造价值的。几乎我们身边每一个产品,最后价值创造的核心驱动都是智能。”这一观点揭示了人工智能在各个应用场景中的深远影响,不同于互联网依赖链接的浅层价值,人工智能致力于深层次的价值创造。
英伟达业绩再超预期,黄仁勋亲自解密
From 腾讯科技
英伟达近期业绩大幅超出预期,CEO 黄仁勋强调人工智能对各行业的变革性影响。公司致力于加速人工智能和计算技术领域的创新,并专注于扩展到主权人工智能、汽车和医疗保健等新市场。尽管在中国市场面临挑战,英伟达仍致力于为其全球客户群提供先进的解决方案。
世界顶级风投 a16z 创始人对谈 AI 与创业,信息量爆炸!
世界顶级风投 a16z 创始人对谈 AI 与创业,信息量爆炸!(两万字长文,建议收藏) | BestBlogs
From 腾讯科技
a16z 联合创始人马克·安德森(Marc Andreessen)和本·霍洛维茨(Ben Horowitz)分享了对 AI 和创业的深刻见解,重点在于小型 AI 初创公司如何在面对大型科技公司的算力和数据优势时竞争,很多观点值得学习和思考:
- "小型 AI 初创公司需要专注于构建与大公司不同的、具有独特价值的产品和服务。"
- "数据作为可出售资产常被高估,真正的价值在于如何利用数据,而非数据本身。"
- "技术进步和市场反应存在不确定性,风险投资模型接受一定比例的失败作为创新过程的一部分。"
- "历史上的重大技术进步往往伴随着金融泡沫,这是新技术推广的自然组成部分。"
- "人工智能的发展可能面临从开放到封闭的选择,这将对其普及和创新产生深远影响。"
马斯克最新专访实录:我最大的希望是“火星”,最大的恐惧是“人工智能”
马斯克最新专访实录:我最大的希望是“火星”,最大的恐惧是“人工智能” | BestBlogs
From 腾讯科技

埃隆·马斯克在法国巴黎举行的 2024 年 VivaTech 大会上通过远程方式分享了他对未来生活的愿景。关键点包括:
- 马斯克预计在 10 年内将人类送上火星,并在人类在 5 年内重返月球,创造多行星文明。
- 他对地球未来表示担忧,并强调太空殖民对人类生存的重要性。
- 马斯克讨论了需用诚实训练人工智能,批评现有科技公司过于追求政治正确。
- 他的 xAI 目标是追求真理和好奇心,在人工智能领域脱颖而出。
- 马斯克提到了 Neuralink 治疗脑脊髓损伤的潜力以及人工智能在教育领域的前景。
万字实录:投钱、烧钱与赚钱,五位 AI 大咖的不同 AI 观
万字实录:投钱、烧钱与赚钱,五位 AI 大咖的不同 AI 观|甲子光年 | BestBlogs
From 甲子光年

在这篇文章中,五位 AI 大咖在甲子光年举办的“AI 创生时代”大会上,围绕 AI 行业的关键问题展开了深入讨论。主要议题包括 AI 基础模型技术的发展、技术与市场的平衡、产品市场契合(PMF)和杀手级应用的出现、先发优势与后发优势等。
朱啸虎认为,AI 应用即将大爆发,并强调“千万不要追求技术的领先,不要纠结于产品中有多少是 AI,有多少是人工,因为技术迭代太快了,一定要追求能不能达到商业化质量。” 傅盛则指出,“AI 是底层的生产力革命,应用是关键点,能够引发大规模传播和用户使用。”
李志飞强调,当前的 AI 模型和产品仍然是半成品,需更加关注市场和商业化。他认为创业者应避免被价值观绑架,更多地关注用户需求。汪玉表示,AI 领域充满无限可能,技术创新需要与现实紧密结合。张建中指出,算力资源的匮乏是当前 AI 发展的主要瓶颈,大型基础设施的建立至关重要。
万字干货:用户增长原来可以如此简单(40 图)
万字干货:用户增长原来可以如此简单(40 图) | BestBlogs
From 人人都是产品经理
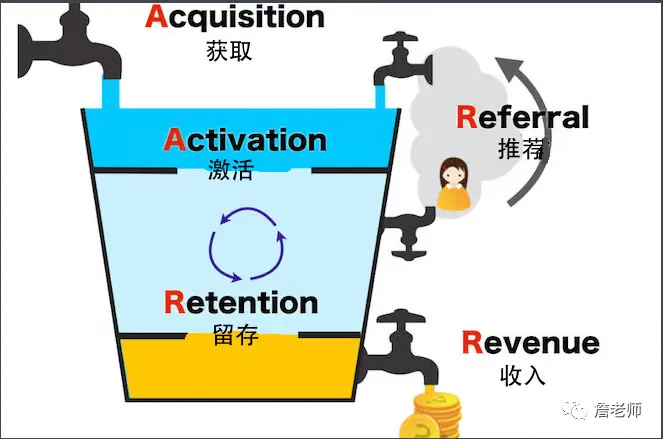
介绍用户增长非常全面和贴地气的一篇文章,值得一读! 本文深入探讨了用户增长和增长策略,通过一个简单的数学问题引申到产品和业务增长的策略。文章强调了扩大用户获取渠道(X)和减少用户流失(Y)以实现显著的净用户增长。 同时,讨论了增长策略思维的价值,增长策略背后的简单性,以及各种用户获取渠道,包括自然流量、应用商店、微信等。强调了多元化用户获取方法的重要性,以及理解和利用不同平台和渠道以实现最大增长的。文章最后强调了持续探索和优化增长,确保可持续和有效的用户获取策略的重要性。
Kimi chat 的打赏付费模式暗藏玄机,与直接付费购买相比有巨大优势!
Kimi chat 的打赏付费模式暗藏玄机,与直接付费购买相比有巨大优势! | BestBlogs
From 人人都是产品经理
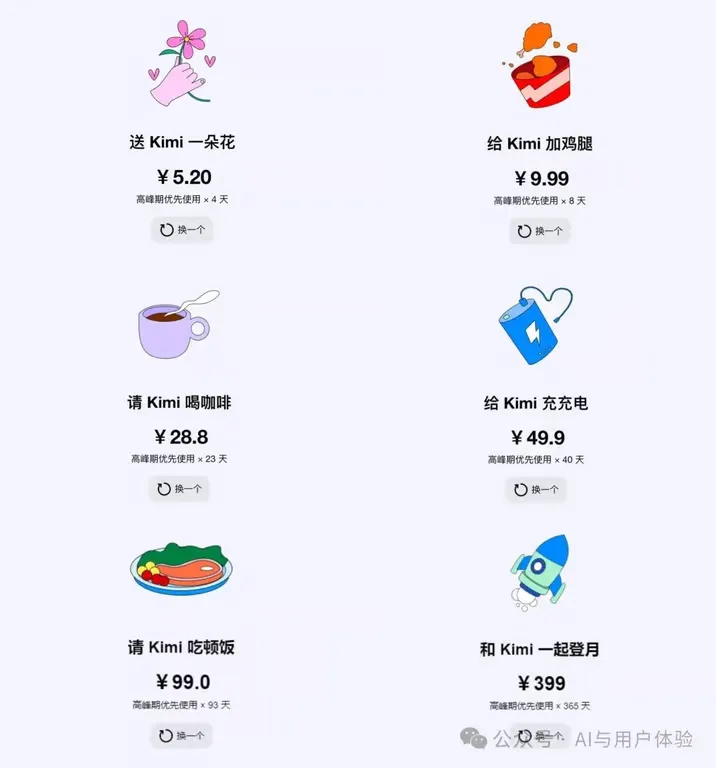
Kimi chat 推出了基于打赏的付费模式,与传统的包月付费模式相比,这种模式在增强用户粘性和心理认同方面具有独特优势。它通过不规则的使用天数定价策略,避免了与传统包月产品的直接比较,同时可能利用反向价格敏感锚点来促进用户的付费意愿。此外,这种模式还能激励产品设计团队继续优化产品,为公司带来可持续的收入。
Zapier 不走寻常路的 8 个收获
深度|Zapier 不走寻常路的 8 个收获 | BestBlogs
From Z Potentials

- 你一定需要大量融资吗?
Zapier 创立于密苏里州,没有依赖大量资金支持,通过仅筹集 130 万美元实现了公司估值 50 亿美元的目标。他们从当地的成功企业中汲取灵感,发展业务而不盲目追随主流创业建议。 - 从 Day 1 开始考虑销售
许多创始人忽视了市场推广的重要性,Zapier 则从一开始就重视分销策略。通过创建应用程序目录和登陆页面,他们在没有客户的情况下吸引了潜在用户,并不断改进产品。 - 解决真正的问题,哪怕产品很简陋
Zapier 注重解决实际用户问题,即使产品还不完善。他们通过 Skype 观察客户使用产品,了解痛点并不断迭代改进,最终赢得了客户的认可。 - 非必要不扩大招聘
Zapier 慎重扩展团队,创始人亲自负责各项工作,了解业务的每一部分。这种方式让他们在雇佣新员工时能够准确识别需求,避免了不必要的扩展导致的效率低下。 - 但要更早些引入有经验的管理者
尽早引入有经验的管理者可以提升团队效率。Zapier 在团队规模达到 30-40 人时才引入职业经理人,事后认为这一决定有些晚。引入愿意从事具体事务的高级领导者对初创公司至关重要。 - 建立庞大的企业不一定要走企业化道路
Zapier 专注于中小型企业,解决这些客户的实际问题,而不是盲目追求大企业客户。他们强调根据客户需求调整策略,而不是一味追求宏伟目标。 - 避免陷入产品功能开发竞赛
Zapier 注重解决用户实际问题,而不是盲目跟随竞争对手的功能开发。他们关注“边缘客户”,了解这些客户为什么没有选择自己,并根据反馈改进产品。 - 莫因连胜而沾沾自喜
Foster 强调保持谦逊和灵活,正视成功和失败的原因。好的决策未必带来好的结果,反之亦然。创业者应保持灵活,避免固执己见,以便在不断变化的环境中取得成功。
每年访问量超 2.7 亿,拆解 Canva 从 0 到 1 的 SEO 营销策略
每年访问量超 2.7 亿,拆解 Canva 从 0 到 1 的 SEO 营销策略 | BestBlogs
From Founder Park

这篇文章详细拆解了 Canva 从 0 到 1 的 SEO 营销策略,揭示了其成功背后的关键因素。Canva 通过设计针对不同用户搜索意图的落地页、深刻理解用户搜索意图、重视内容目录和反向链接的建设,成功获得了超过 400 万的反向链接和每年 2.7 亿的访问量。
Canva 的创作页和发现页分别针对 “创作邀请函” 和 “邀请函模板” 的用户需求,优化了 SEO 策略。文章提到:“搜索意图是用户在搜索引擎中输入查询时的主要目标或需求,有 4 种关键的搜索意图类型:信息、导航、交易和调研。” 这一点强调了理解用户搜索意图的重要性。
此外,Canva 投资于反向链接的建设和推广,通过建立一支外联 BD 专家团队,识别并捕捉提到相关关键词的页面,建立高质量的反向链接。文章指出:“反向链接越多,一定程度会被搜索引擎视为内容丰富,那就是 SEO 友好,自然就会给到更高的域名权重。” 这说明反向链接对 SEO 的影响至关重要。
通过这些策略,Canva 实现了流量和用户转化率的大幅提升,成为 SaaS 行业中 SEO 营销的典范。
降低认知负荷的七种设计策略
From 人人都是产品经理
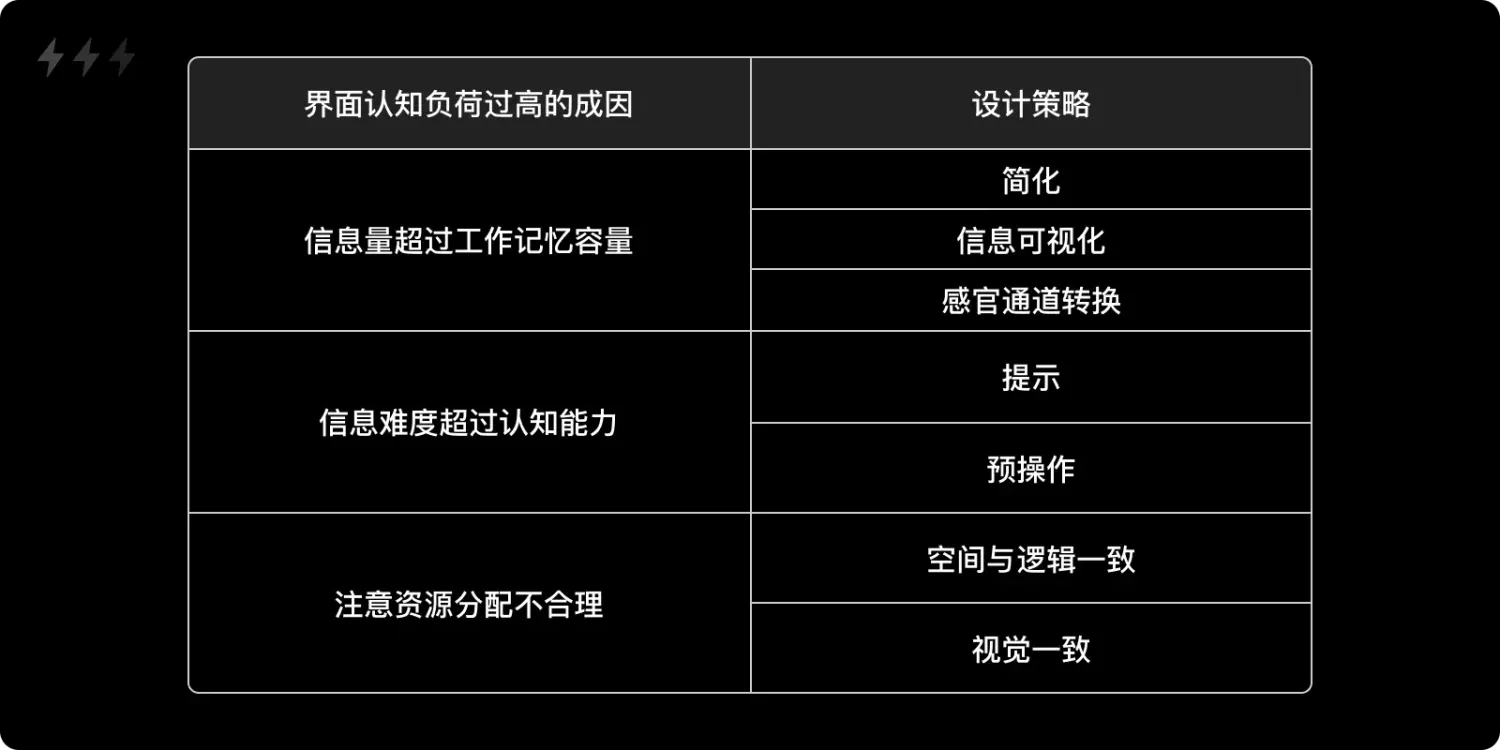
在本文中作者详细介绍了在 UX 设计中减少用户认知负荷的七种有效策略。这些策略旨在通过简化界面、信息可视化和多感官通道转换等方法,优化用户体验,提升界面可用性。
文章指出,简化设计不仅仅是删除内容,更在于组织、隐藏和转移信息,确保用户注意力集中在核心功能上。通过信息可视化,将复杂的数据转化为直观的图形,帮助用户快速理解和处理信息。多感官通道转换则利用视觉、听觉等多种感官,提高信息传递效率,例如在地图应用中使用语音导航减少驾驶者的视觉负担。
其中,作者强调:“当信息量超过单一感官通道的认知上限时,转换感官通道或同时使用多个通道可以显著提升认知效率。”这句话点明了多感官结合在降低认知负荷中的重要性。
此外,提示策略和预操作策略通过提供额外的信息和模拟练习,帮助用户更好地理解和掌握复杂任务。保持空间与逻辑一致性,以及视觉一致性,可以使用户快速适应界面,减少认知资源的消耗。
通过这七种策略,设计师可以有效地降低用户在使用界面时的认知负荷,创造出更加高效和愉悦的用户体验。
美学大咖亲选!8 种世界上被公认的绝美颜色!
美学大咖亲选!8 种世界上被公认的绝美颜色! | BestBlogs
From 优设

色彩,作为视觉艺术的灵魂,一直以其独特的魅力吸引着人们的目光。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

