
热门标签
热门文章
- 1linux服务器安全(1)_faillogenab配置
- 2使用Docker Compose 搭建lnmp_docker compose lnmp
- 3服务器安装ubuntu18.04,然后配置环境深度学习环境
- 4Python实战案例分享:爬取当当网商品数据
- 5Spring Boot最经典的20道面试题,你都会了吗?_springboot面试题
- 6大语言模型的直接偏好优化(DPO)对齐在PAI-QuickStart实践_大模型dpo算法
- 7如何用ChatGPT复现nature正刊论文,自然科学领域人员必看_chatgpt复现论文中的代码
- 8数据结构思维导图,超全!超详细!
- 9Spring Cloud Alibaba微服务实战八 - Seata 整合Nacos
- 10【ARXIV2204】Simple Baselines for Image Restoration_simplebaseline arxiv
当前位置: article > 正文
大模型学习笔记七:LLM应用_llm session
作者:在线问答5 | 2024-07-20 10:44:37
赞
踩
llm session
文章目录
-
- 一、维护生产级别的LLM应用,需要做的事
- 二、符合需求的LLM App维护平台
- 三、LangFuse
-
- 1)替换OpenAI客户端(把跟OpenAI交互记录到LangFuse)
- 1.1)几个基本概念
- 2)通过LangChain的回调函数触发记录(上面用的原生OpenAI接口,下面是调用LangChain的接口)
- 3)构建一个实际应用
- 3.1)用trace记录一个多次调用LLM的过程
- 3.2)用session记录一个用户的多轮对话(记得多次对话历史)
- 4)数据集与测试(每次测试都得看数据集来体现指标变好还是变坏)
- 4.1)在线标注
- 4.2)上传已有数据集
- 4.3)定义评估函数
- 4.4)运行测试
- 4.5)promp调优与回归测试(prompt增加思维链)
- 5)prompt版本管理
- 6)如何比较两个句子的相似性(一些经典 NLP 的评测方法)
- 7)基于LLM的测试方法
- 四、LangSmith
- 五、Prompt Flow
- 六、总结
一、维护生产级别的LLM应用,需要做的事
1、各种指标监控与统计:访问记录、响应时长、Token用量、计费等等(系统各个模块的访问记录和响应时间,整体的费用)
2、调试 Prompt
3、测试/验证系统的相关评估指标
4、数据集管理(便于回归测试,看以往测试的结果)
5、Prompt 版本管理(便于升级/回滚)
二、符合需求的LLM App维护平台
1、LangFuse(重点)): 开源 + SaaS(免费/升级版付费),LangSmith 平替,可集成 LangChain 也可直接对接 OpenAI API;
2、 LangSmith: LangChain 的官方平台,SaaS 服务(付费),非开源;
3、 Prompt Flow:微软开发,开源 + Azure AI云服务,可集成 Semantic Kernel(但貌合神离)。
import os
os.environ["LANGCHAIN_TRACING_V2"]=""
os.environ["LANGCHAIN_API_KEY"]=""
- 1
- 2
- 3
三、LangFuse
1)替换OpenAI客户端(把跟OpenAI交互记录到LangFuse)
-
简介
1、开源,支持 LangChain 集成或原生 OpenAI API 集成
2、官方网站:https://langfuse.com/
3、项目地址:https://github.com/langfuse -
注册(通过官方云服务使用:)
注册: cloud.langfuse.com
创建 API Key
LANGFUSE_SECRET_KEY="sk-lf-..."
LANGFUSE_PUBLIC_KEY="pk-lf-..."
- 1
- 2
- 3
- 4
- 5
- 部署(源码部署)
#1、Clone repository
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# 2、Run server and db
docker compose up -d
# 3、在自己部署的系统中生成上述两个 KEY
# 并在环境变量中指定服务地址
LANGFUSE_SECRET_KEY="sk-lf-..."
LANGFUSE_PUBLIC_KEY="pk-lf-.."
LANGFUSE_HOST="http://localhost:3000"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 安装相关库
!pip install --upgrade langfuse
- 1
- 开始替换OpenAI客户端
from datetime import datetime from langfuse.openai import openai from langfuse import Langfuse import os trace = Langfuse().trace( name = "hello-world", user_id = "wzr", release = "v0.0.1" ) completion = openai.chat.completions.create( name="hello-world", model="gpt-3.5-turbo", messages=[ { "role": "user", "content": "对我说'Hello, World!'"} ], temperature=0, trace_id=trace.id, ) print(completion.choices[0].message.content)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 回复
Hello, World!
- 1
-
该回答的记录
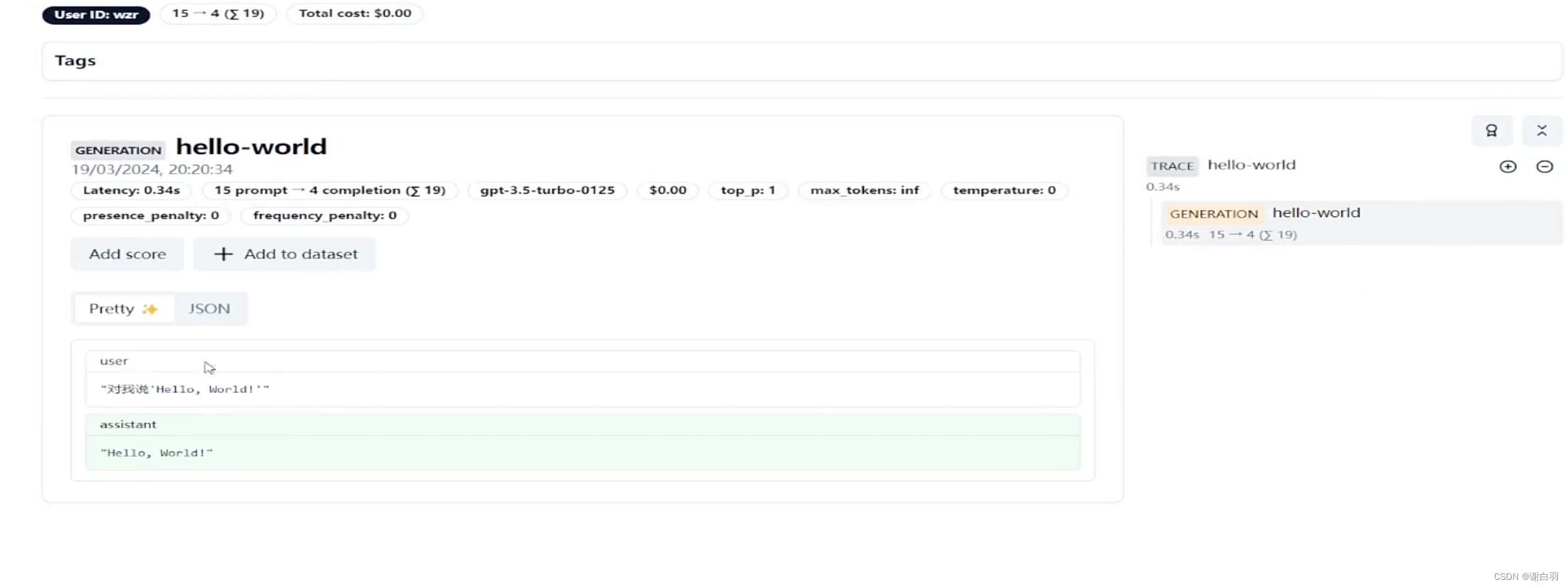
-
提问记录
1.1)几个基本概念
1、·Trace 一般表示用户与系统的一次交互,其中记录输入、输出,也包括自定义的 metadata 比如用户名、session id等;
2、一个 trace 内部可以包含多个子过程,这里叫 observarions;
3、Observation 可以是多个类型:
- Event 是最基本的单元,用于记录一个 trace 中的每个事件;
- Span 表一个 trace 中的一个"耗时"的过程;
- Generation 是用于记录与 AI 模型交互的 span,例如:调用 embedding 模型、调用 LLM。
4、Observation 可以嵌套使用。
- 举例
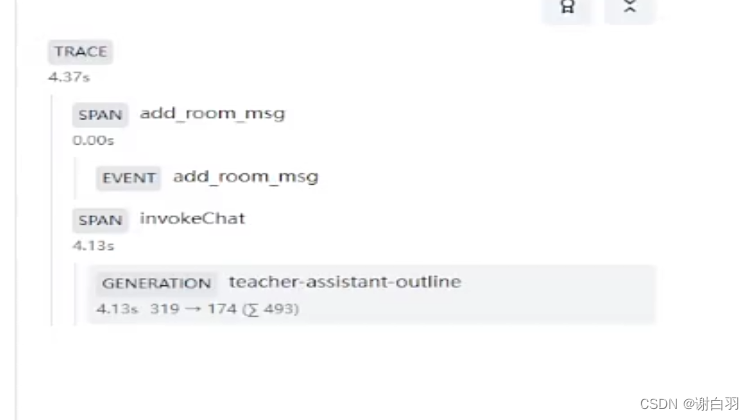
2)通过LangChain的回调函数触发记录(上面用的原生OpenAI接口,下面是调用LangChain的接口)
from langfuse.callback import CallbackHandler handler = CallbackHandler( trace_name="SayHello", user_id="wzr", ) --------------------------------------- from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, ) from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI from langchain_core.runnables import RunnablePassthrough model = ChatOpenAI(model="gpt-3.5-turbo-0613") prompt = ChatPromptTemplate.from_messages([ HumanMessagePromptTemplate.from_template("Say hello to {input}!") ]) # 定义输出解析器 parser = StrOutputParser() chain = ( { "input":RunnablePassthrough()} | prompt | model | parser ) chain.invoke(input="AGIClass", config={ "callbacks":[handler]})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 回复打印
'Hello AGIClass! How can I assist you today?'
- 1
3)构建一个实际应用
- 需求
1、根据课程内容,判断学生问题是否需要老师解答
2、判断该问题是否需要老师解答,回复’Y’或’N’
3、判断该问题是否已有同学问过
#1、构建 PromptTemplate from langchain.prompts import PromptTemplate need_answer=PromptTemplate.from_template(""" ********* 你是AIGC课程的助教,你的工作是从学员的课堂交流中选择出需要老师回答的问题,加以整理以交给老师回答。 课程内容: {outlines} ********* 学员输入: {user_input} ********* 如果这是一个需要老师答疑的问题,回复Y,否则回复N。 只回复Y或N,不要回复其他内容。""") check_duplicated=PromptTemplate.from_template(""" ********* 已有提问列表: [ {question_list} ] ********* 新提问: {user_input} ********* 已有提问列表是否有和新提问类似的问题? 回复Y或N, Y表示有,N表示没有。 只回复Y或N,不要回复其他内容。""") outlines=""" LangChain 模型 I/O 封装 模型的封装 模型的输入输出 PromptTemplate OutputParser 数据连接封装 文档加载器:Document Loaders 文档处理器 内置RAG:RetrievalQA 记忆封装:Memory 链架构:Chain/LCEL 大模型时代的软件架构:Agent ReAct SelfAskWithSearch LangServe LangChain.js """ question_list=[ "LangChain可以商用吗", "LangChain开源吗", ] #2、创建 chain model = ChatOpenAI(temperature=0,model_kwargs={ "seed":42}) parser = StrOutputParser() chain1 = ( need_answer | model | parser
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/856439
推荐阅读
相关标签

