
- 1CCF的A类期刊和会议有哪些?人工智能顶会ACL,ICML,NeurIPS,ICLR论文投稿时间以及影响因子等_ccfa类期刊
- 2机器学习与高维信息检索 - Note 1 - 信息检索、机器学习与随机变量_高维信息搜索
- 3【Oracle】玩转Oracle数据库(三):数据库的创建和管理_oracle 创建数据库
- 4云计算的技术发展趋势_云计算技术的发展趋势
- 5Mac上如何安装Mysql5以及可视化工具navicat_可视化工具navicatmac 版
- 6map中的value保存遇到的问题_map里面的value可以放数组吗
- 7Vue使用socket实现实时通信
- 8FIR带通滤波器设计与验证_带通滤波器 csdn
- 9FIFO设计笔记(双口RAM、同步FIFO、异步FIFO)Verilog及仿真_双口异步ram空满判断的方法
- 10案例115:基于微信小程序的音乐播放器的设计与实现
解密Prompt系列3. 冻结LM微调Prompt: Prefix-tuning & Prompt-tuning & P-tuning
赞
踩
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型。这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品。和前两章微调LM和全部冻结的prompt模板相比,微调Prompt范式最大的区别就是prompt模板都是连续型(Embedding),而非和Token对应的离散型模板。核心在于我们并不关心prompt本身是否是自然语言,只关心prompt作为探针能否引导出预训练模型在下游任务上的特定能力。
固定LM微调Prompt的范式有以下几个优点
- 性价比高!微调参数少,冻结LM只微调prompt部分的参数
- 无人工参与!无需人工设计prompt模板,依赖模型微调即可
- 多任务共享模型!因为LM被冻结,只需训练针对不同任务的prompt即可。因此可以固定预训练模型,拔插式加入Prompt用于不同下游任务
Prefix-Tuning
Paper: 2021.1 Optimizing Continuous Prompts for Generation Github:Prompt: Continus Prefix Prompt Task & Model:BART(Summarization), GPT2(Table2Text)
最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。
先唠两句可控文本生成,哈哈其实整个Prompt范式也是通用的可控文本生成不是,只不过把传统的Topic控制,文本情绪控制,Data2Text等,更进一步泛化到了不同NLP任务的生成控制~~
Prefix-Tuning可以理解是CTRL 1 模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评前面加’Reviews Rating:5.0’,差评前面加’Reviews Rating:1.0’, 政治评论前面加‘Politics Title:’,把语言模型的生成概率,优化成了基于文本主题的条件概率。
Prefix-Tuning进一步把control code优化成了虚拟Token,每个NLP任务对应多个虚拟Token的Embedding(prefix),对于Decoder-Only的GPT,prefix只加在句首,对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头。在下游微调时,LM的参数被冻结,只有prefix部分的参数进行更新。不过这里的prefix参数不只包括embedding层而是虚拟token位置对应的每一层的activation都进行更新。

对于连续Prompt的设定,论文还讨论了几个细节如下
-
prefix矩阵分解 作者发现直接更新多个虚拟token的参数效果很不稳定,因此作者在prefix层加了MLP,分解成了更小的embedding层 * 更大的MLP层。原始的Embedding层参数是n_prefix * emb_dim, 调整后变为n_prefix * n_hidden + n_hidden * emb_dim。训练完成后这部分就不再需要只保留MLP输出的参数进行推理即可 个人感觉MLP的加入是为了增加多个虚拟token之间的共享信息,因为它们和常规的连续文本存在差异,需要被作为一个整体考虑,可能对prefix位置编码进行特殊处理也阔以??
-
prefix长度 prefix部分到底使用多少个虚拟token,直接影响模型微调的参数量级,以及处理长文本的能力。默认的prefix长度为10,作者在不同任务上进行了微调,最优参数如下。整体上prompt部分的参数量都在原模型的~0.1%
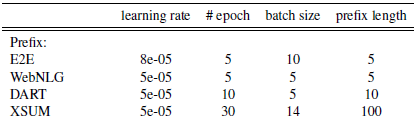
-
其他:作者还对比了把prefix放在不同位置,以及使用任务相关的Token来初始化prefix embedding的设定,前者局限性较大,后者在后面的paper做了更详细的消融实验。效果上在Table2Text任务上,只有0.1%参数量级的prompt tuning效果要优于微调,
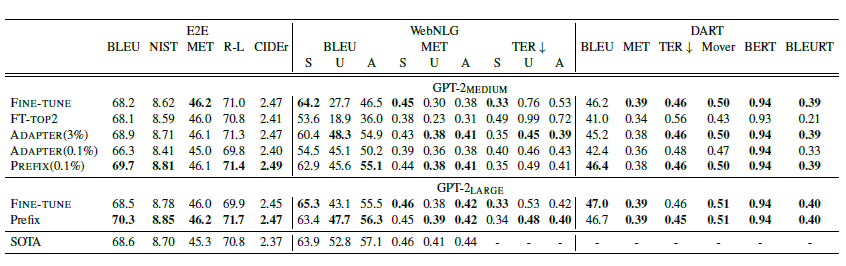
摘要任务上,prompt的效果要略差于微调。

Prompt-tuning
Paper: 2021.4 The Power of Scale for Parameter-Efficient Prompt Tuning prompt:Continus Prefix Prompt Github: [https://github.com/google-research/prompt-tuning]Task: SuperGLUE NLU任务 Model: T5 1.1(在原T5上进行了细节优化)

Prompt-tuning是以上prefix-tuning的简化版本,面向NLU任务,进行了更全面的效果对比,并且在大模型上成功打平了LM微调的效果~
简化
对比Prefix-tuning,prompt-tuning的主要差异如下,
论文使用100个prefix token作为默认参数,大于以上prefix-tuning默认的10个token,不过差异在于prompt-tuning只对输入层(Embedding)进行微调,而Prefix是对虚拟Token对应的上游layer全部进行微调。因此Prompt-tuning的微调参数量级要更小,且不需要修改原始模型结构,这是“简化”的来源。相同的prefix长度,Prompt-tuning(<0.01%)微调的参数量级要比Prefix-tuning(0.1%~1%)小10倍以上,如下图所示
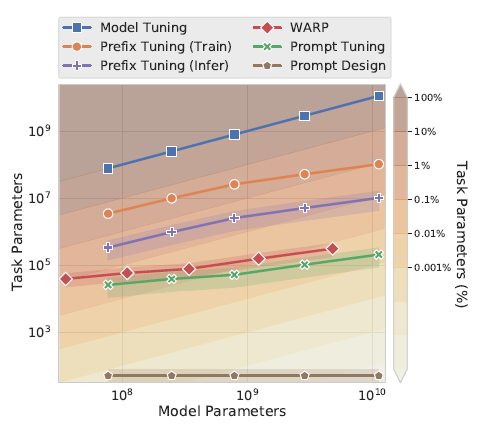
为什么上面prefix-tuning只微调embedding层效果就不好,放在prompt-tuning这里效果就好了呢?因为评估的任务不同无法直接对比,个人感觉有两个因素,一个是模型规模,另一个是继续预训练,前者的可能更大些,在下面的消融实验中会提到
效果&消融实验
下图,在SuperGLUE任务上,随着模型参数的上升,Promp-tuning快速拉近和模型微调的效果,110亿的T5模型(上面prefix-tuning使用的是15亿的GPT2),已经可以打平在下游多任务联合微调的LM模型,并且远远的甩开了Prompt Design(GPT3 few-shot)

作者也做了全面的消融实验,包括以下4个方面,最核心的感受就是只要模型足够够大一切都好说
- prompt长度(a):固定其他参数,作者尝试了{1,5,20,100,150}, 当模型规模到百亿后,只要prompt长度大于1,更长的prompt并不能带来效果提升
- Prompt初始化(b): 作者尝试了随机uniform初始化,用标签文本空间初始化,和用Top5K高频词采样初始化,在10^8规模,标签词初始化效果最好。作者发现预测label也会在对应prompt空间内。不过到百亿规模后,初始化带来的影响就会消失
- T5继续预训练©:作者认为T5本身的Span Corruption预训练目标和掩码词,并不适合冻结LM的场景,因为在微调中模型可以调整预训练目标和下游目标的差异,而只使用prompt可能无法弥合差异。其实这里已经能看出En-Dn框架在生成场景下没有GPT这样的Decoder来的自然。因此作者基于LM目标对T5进行继续预训练
- 继续预训练step(d):以上的继续预训练steps,继续预训练步数越高,模型效果在不同模型规模上越单调。

可解释
考虑Prompt-tuning使用Embedding来表征指令,可解释性较差。作者使用cosine距离来搜索prompt embedding对应的Top5近邻。发现
- embedding的近邻出现语义相似的cluster,例如{ Technology / technology / Technologies/ technological / technologies }, 说明连续prompt实际可能是相关离散prompt词的聚合语义
- 当连续prompt较长(len=100), 存在多个prompt token的KNN相同:个人认为这和prefix-tuning使用MLP那里我的猜测相似,prompt应该是一个整体
- 使用标签词初始化,微调后标签词也大概率会出现在prompt的KNN中,说明初始化可以提供更好的prior信息加速收敛
P-Tuning
Paper: 2021.3, GPT Understands, Too prompt:Continus Prefix Prompt Task: NLU任务, 知识探测任务 github: [https://github.com/THUDM/P-tuning]Model: GPT2 & BERT
P-Tuning和Prompt-Tuning几乎是同时出现,思路也是无比相似。不过这个在prompt综述中被归类为LM+Prompt同时微调的范式,不过作者其实两种都用了。因此还是选择把p-tuning也放到这一章,毕竟个人认为LM+Prompt的微调范式属实有一点不是太必要。。。
论文同样是连续prompt的设计。不过针对上面提到的Prompt的整体性问题进行了优化。作者认为直接通过虚拟token引入prompt存在两个问题
- 离散性:如果用预训练词表的embedding初始化,经过预训练的词在空间分布上较稀疏,微调的幅度有限,容易陷入局部最优。这里到底是局部最优还是有效信息prior其实很难分清
- 整体性:多个token的连续prompt应该相互依赖作为一个整体,不谋而合了!
针对这两个问题,作者使用双向LSTM+2层MLP来对prompt进行表征, 这样LSTM的结构提高prompt的整体性,Relu激活函数的MLP提高离散型。这样更新prompt就是对应更新整个lstm+MLP部分的Prompt Encoder。下面是p-tuning和离散prompt的对比
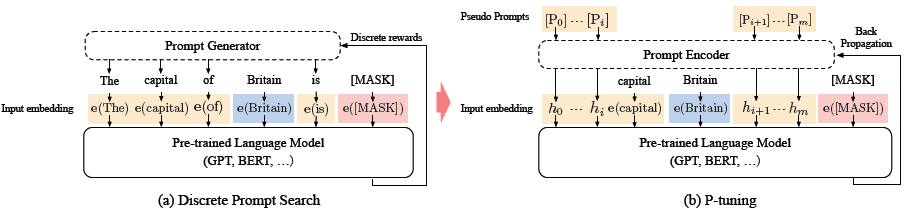
作者分别对LAMA知识探测和SuperGLUE文本理解进行了评测。针对知识抽取,作者构建的prompt模板如下,以下3是虚拟prompt词的数量,对应prompt encoder输出的embedding数
- BERT:(3, sub,3,obj,3)
- GPT(3,sub,3,obj)
在知识探测任务中,默认是固定LM只微调prompt。效果上P-tuning对GPT这类单项语言模型的效果提升显著,显著优于人工构建模板和直接微调,使得GPT在不擅长的知识抽取任务中可以基本打平BERT的效果。
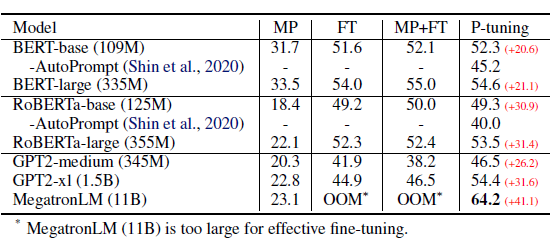
针对SuperGLUE作者是做了LM+Prompt同时微调的设定。个人对LM+prompt微调的逻辑不是认同,毕竟1+1<2,同时微调它既破坏了预训练的语言知识,也没节省微调的参数量级,感觉逻辑上不是非常讲的通(哈哈坐等之后被打脸)。结论基本和以上知识探测相似

开头说优点,结尾说下局限性
- 可解释性差:这是所有连续型prompt的统一问题
- 收敛更慢: 更少的参数想要撬动更大的模型,需要更复杂的空间搜索
- 可能存在过拟合:只微调prompt,理论上是作为探针,但实际模型是否真的使用prompt部分作为探针,而不是直接去拟合任务导致过拟合是个待确认的问题
- 微调可能存在不稳定性:prompt-tuning和p-tuning的github里都有提到结果在SuperGLUE上无法复现的问题
如何学习AI大模型?
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


