
热门标签
热门文章
- 1NXP应用随记(八):S32K3XX的HSE学习记录(HSE\MU\UTEST\IVT\A,B SWAP)_s32k3 hse
- 2在苹果M3笔记本上用VMWare安装Linux_macbook air m3安卓虚拟机
- 3机器学习中的梯度下降
- 4认识爬虫:beautifulsoup4 库如何使用三种方式提取 html 网页元素?_python beautifulsoup查找html标签
- 5悄咪咪上线Kimi智能体,论文助手(文末有福利)_kimi 支持做智能体吗
- 6AI未来已来!亚马逊云科技峰会揭秘生成式AI的无限可能_云科技峰会 亚马逊 观众礼物
- 7中霖教育怎么样?二建继续教育什么意思?
- 8安卓 SDKManager 使用_sdkmanager.bat
- 9Docker可视化界面安装_docke ui安装教程
- 10ChatGPT的Mac客户端正式发布了_chatgpt支持mac什么版本的
当前位置: article > 正文
Java项目(二)--Springboot + ElasticSearch 构建博客检索系统(3)- 分词器介绍_springboot为字段指定es分词器
作者:在线问答5 | 2024-07-21 08:39:57
赞
踩
springboot为字段指定es分词器
分词器介绍
ES作为全文检索服务,势必要对原始的文本进行内容的拆分,才能进行有效的索引。而拆分原始内容到一个一个小的词,或语义单元,这部分的功能由ES的分词器去完成的。
常见分词器
standard:ES默认的分词器,会将词汇单元进行小写形式,并且去除一些停用词和标点符号等等。支持中文,采用的方法为单字切分。
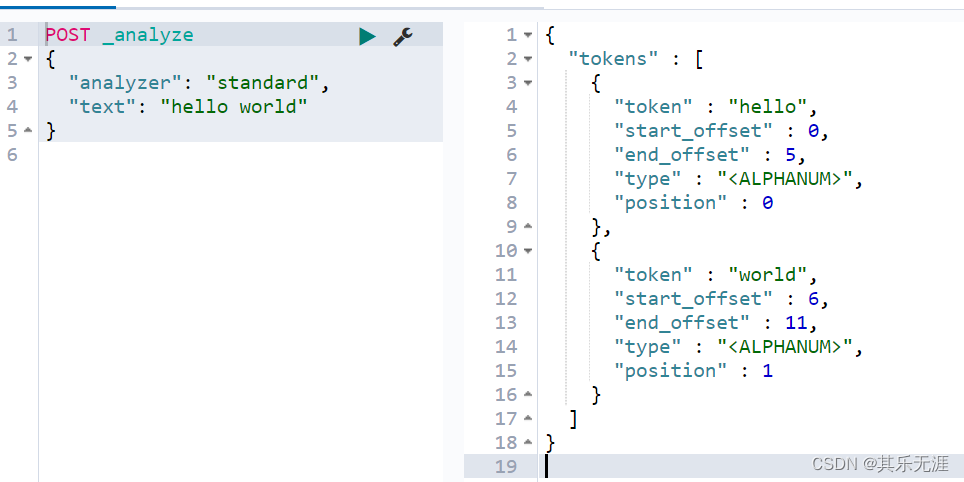
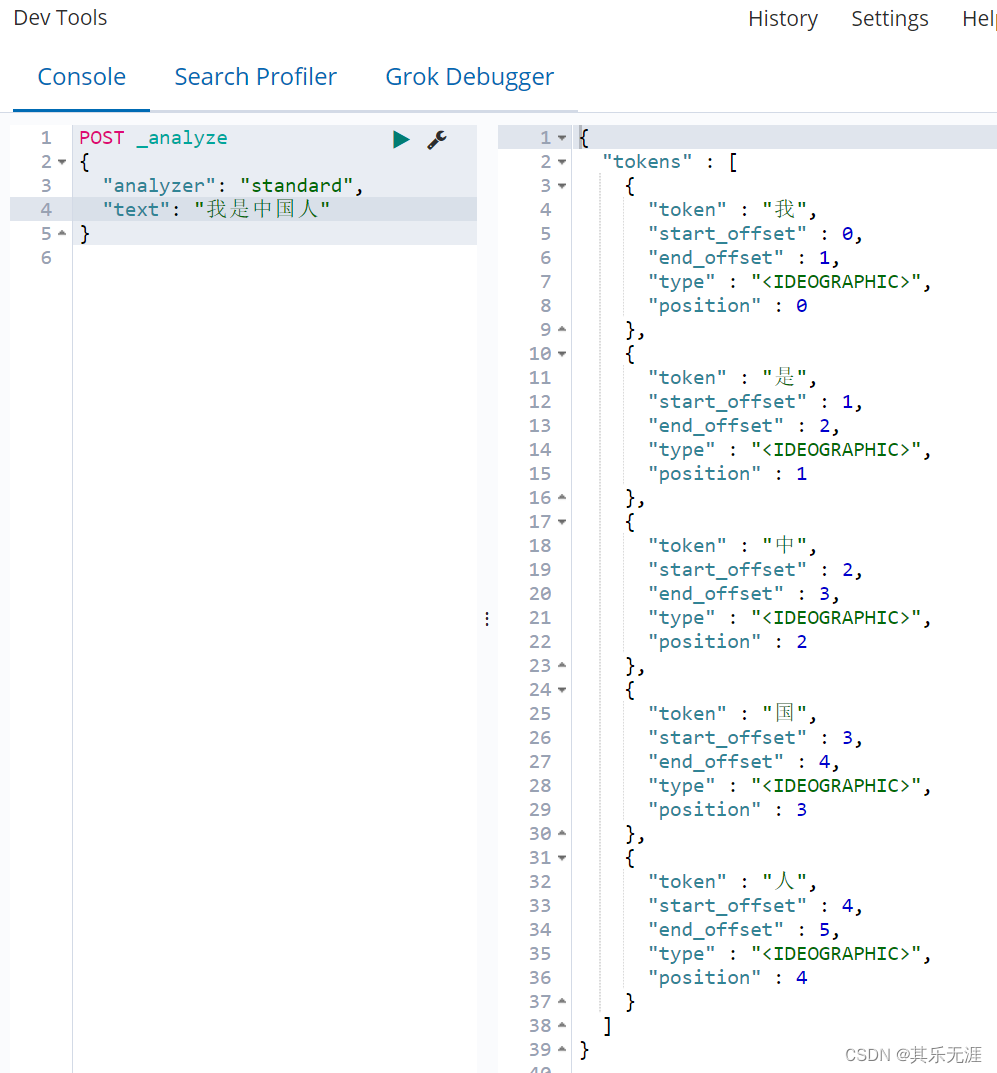
simple:该分词器首先通过非字母字符来分割文本信息,然后将词汇单元统一为小写形式。该分词器会去除掉数字类型的一些字符。
whitespace:仅仅是去除空格,然后对字符没有任何的小写化,并且该分词器不支持中文,而且它对生成的词汇单元没有作其他的一些标准化的处理。
language:特定语言的分词器,目前该分词器也是不支持中文的。
IK分词器的安装和使用
IK分词器是目前ES开源社区对于中文分词支持最好的第三方的插件。
首先,我们下载IK分词器插件。
IK分词器github地址为:
https://github.com/medcl/elasticsearch-analysis-ik
点击右下角releases
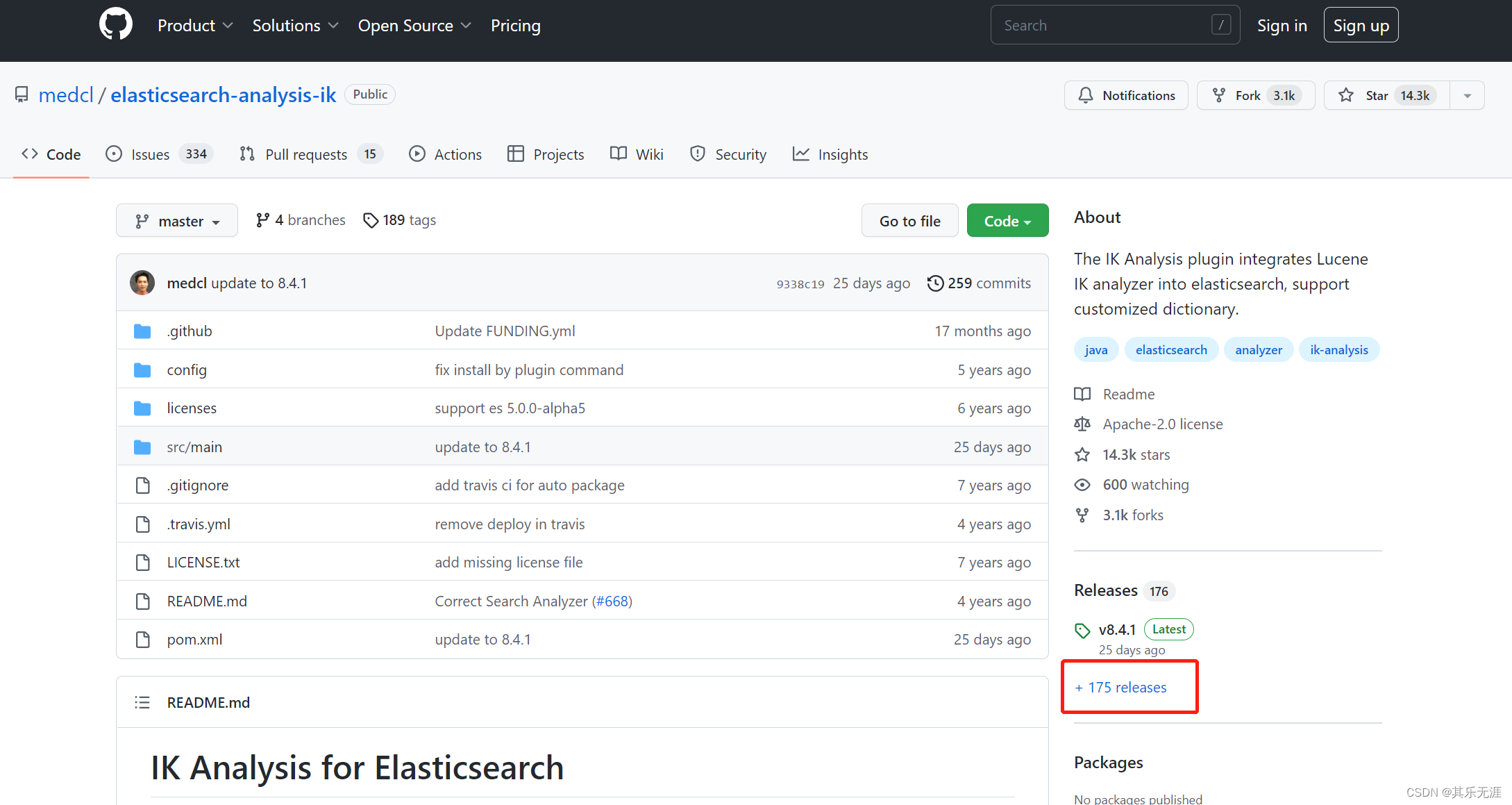
然后找到ES对应的版本,点击Assets,然后点击下载zip包。
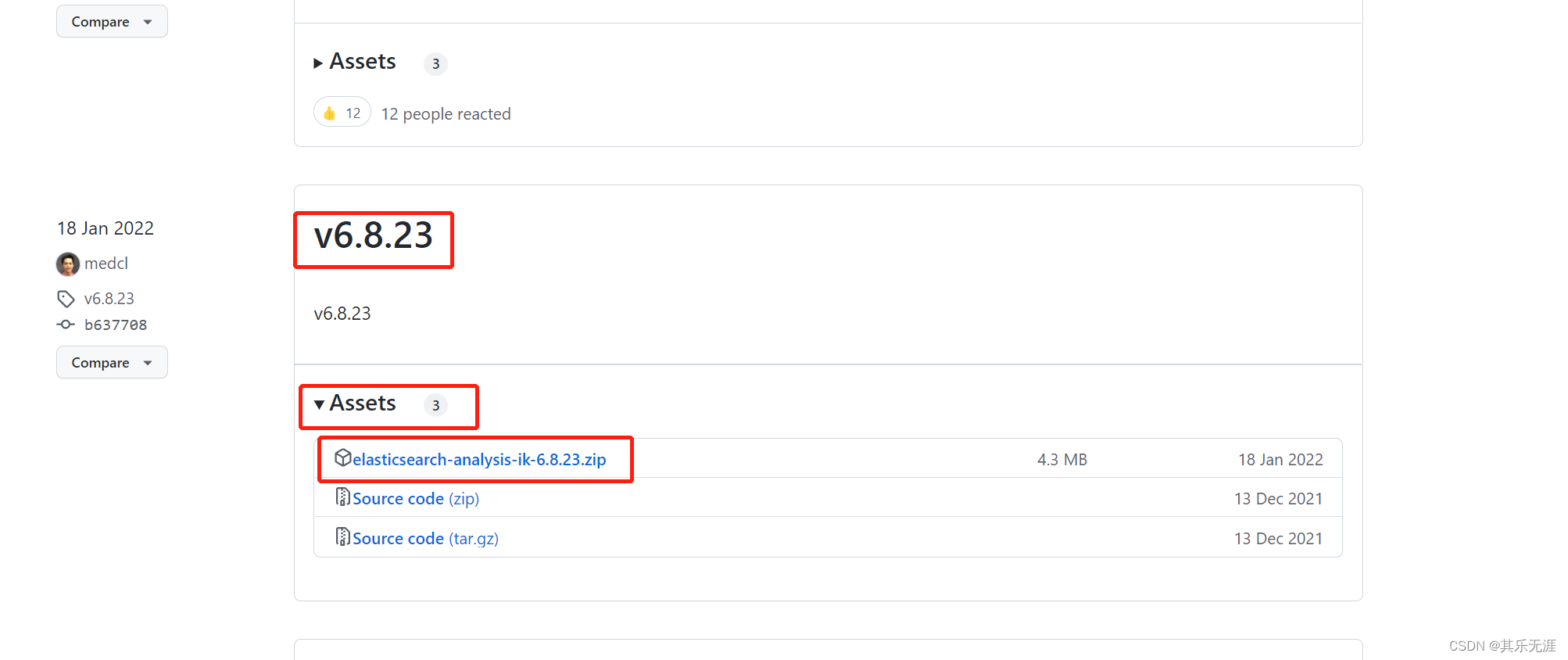
下载完之后解压到elasticsearch-6.8.23\plugins\目录下

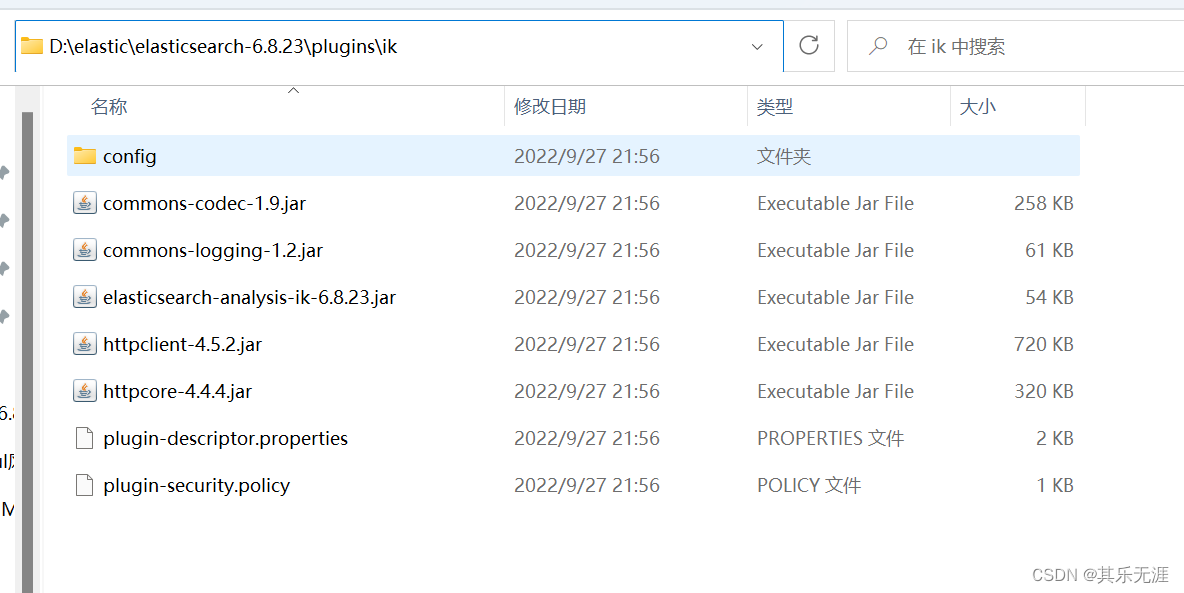
然后重启ES,IK分词器才会生效。
IK分词器插件默认提供了两种分词器:
ik_smart
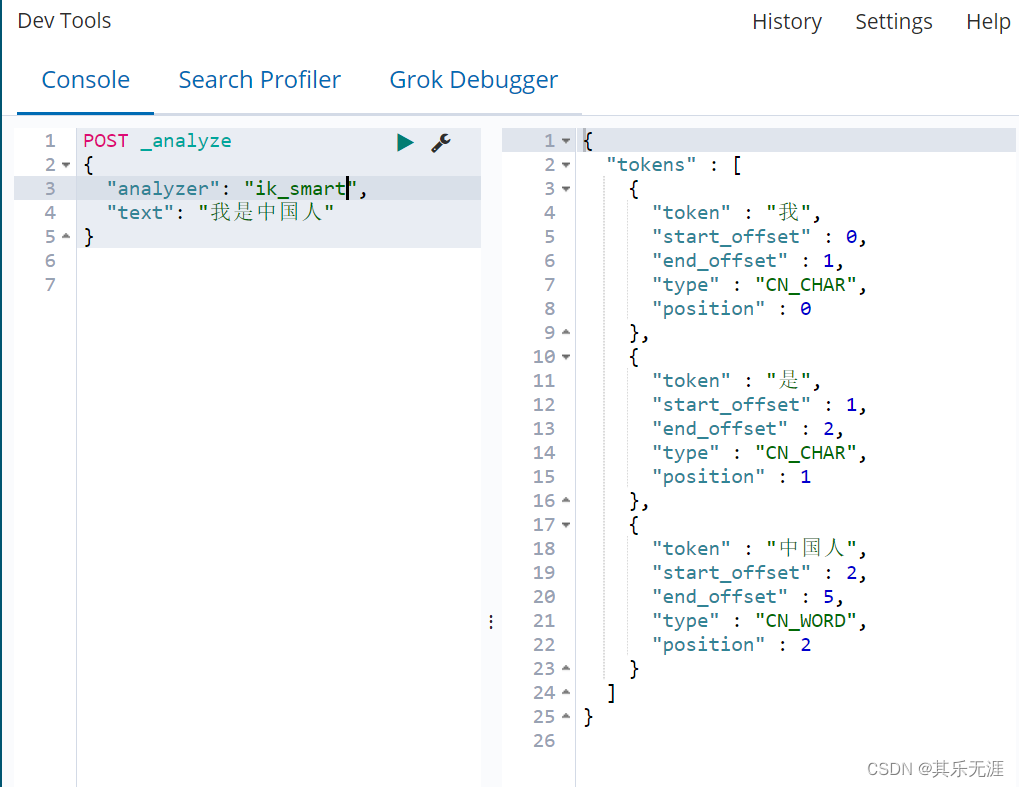
ik_max_word
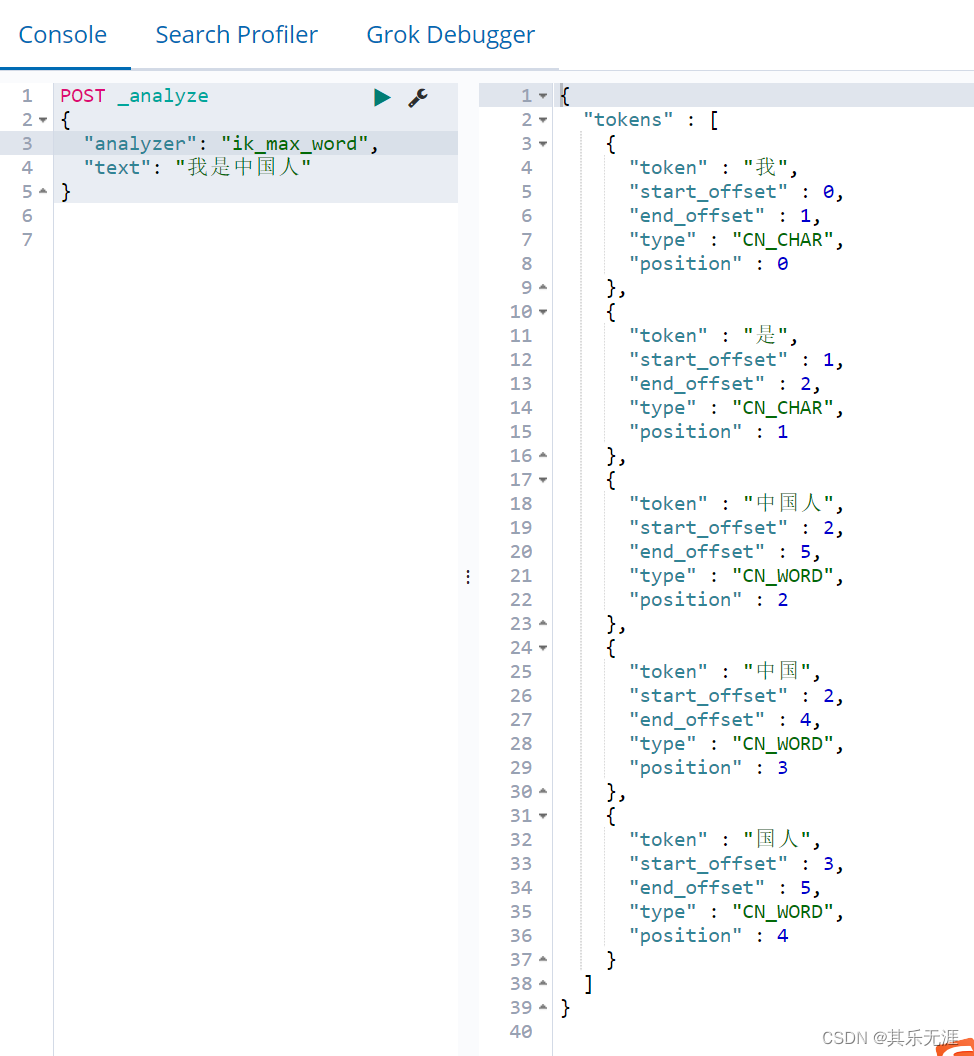
那么,为什么IK分词器对于中文有如此本地化的理解呢,原因是IK分词器内置了很多字典。
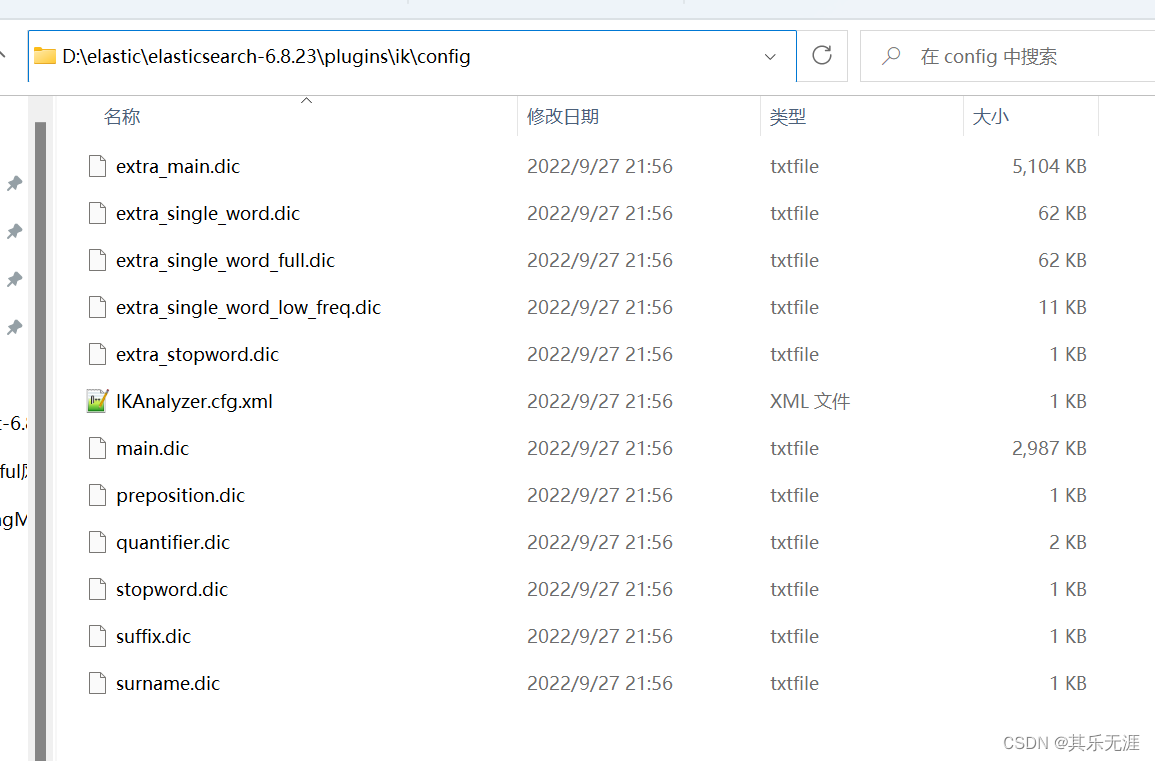
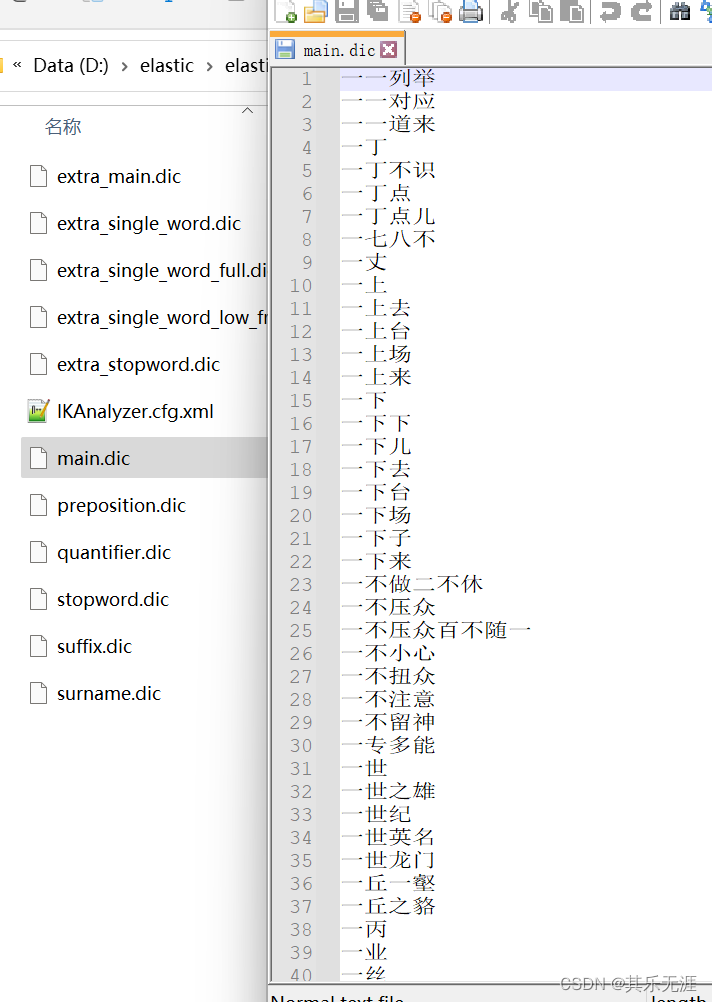
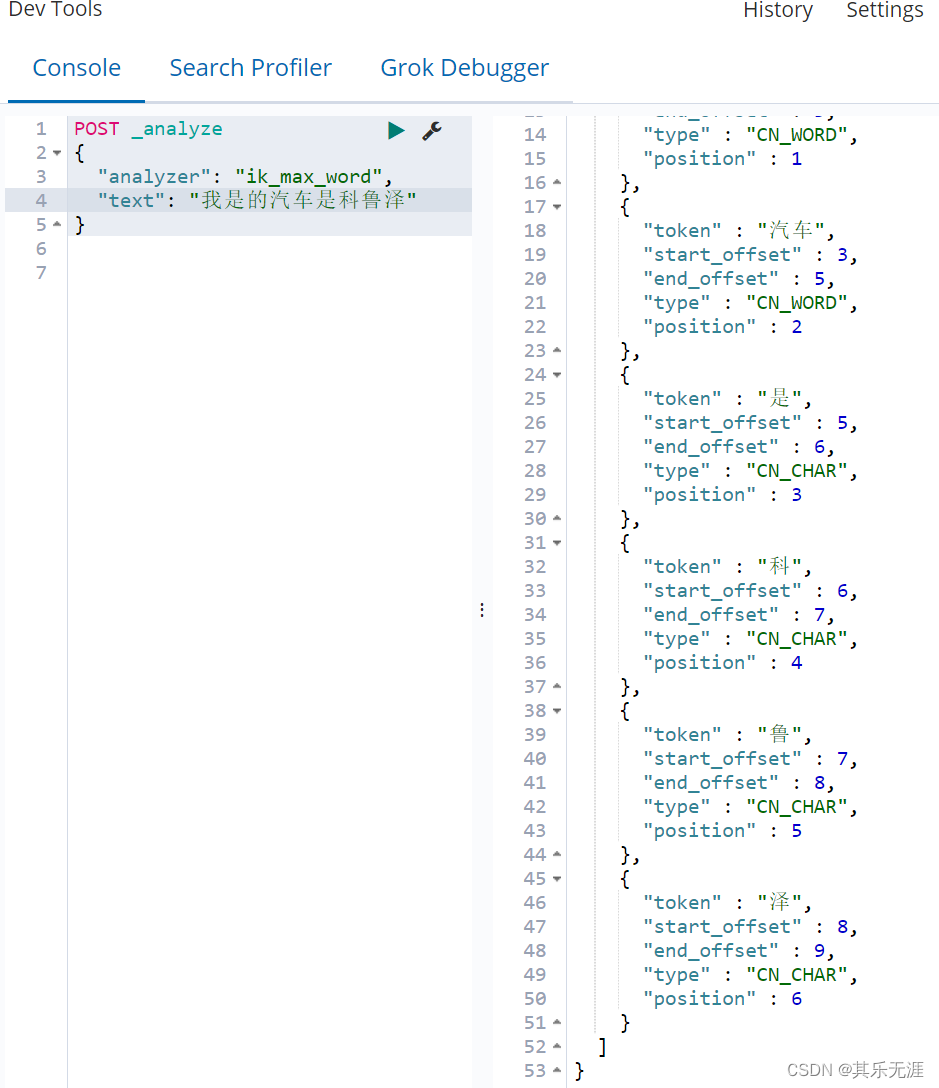
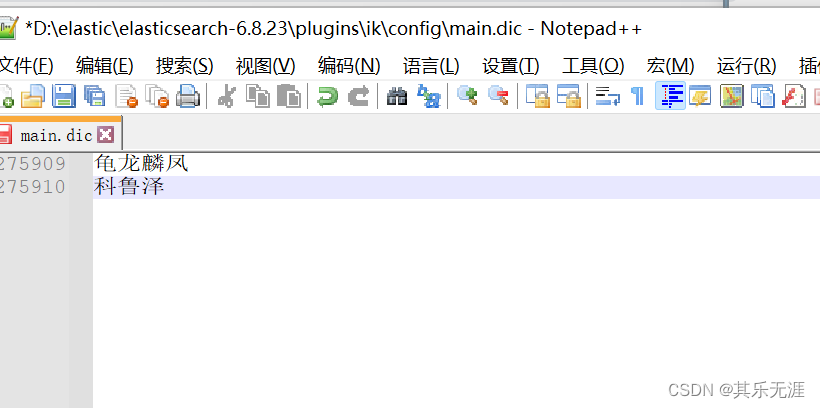
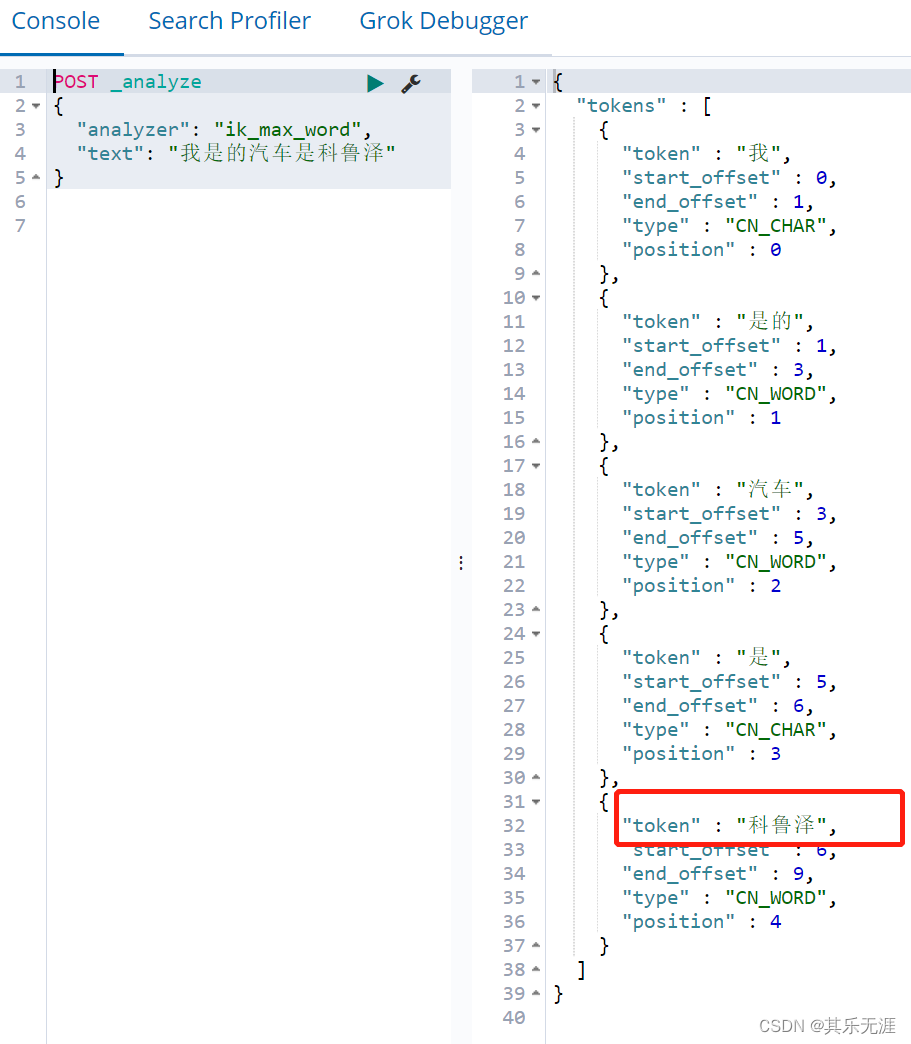
如果某个词没被分词成功,则在字典里添加重启即可。
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/860244
推荐阅读

相关标签

