
- 1编程语言命名规范_请结合所学以及网络资料,介绍一下编程语言有哪些命名规则
- 2linux安装redis超级详细教程_linux环境部署redis6.2.10
- 3推动内容安全生态与通用大模型良性融合_内容安全通过大模型解决
- 4Linux : 解决ssh命令失败(ssh: Network is unreachable),MobaXtermSSH连接超时(Network error:Conection timed out )_ssh network is unreachable
- 5分布式系统—ELK日志分析系统概述及部署
- 6mysql添加用户_mysql添加用户
- 7C语言写二叉树_建立二叉树的代码c语言
- 8超详细的VSCode下载和安装教程(非常详细)从零基础入门到精通,看完这一篇就够了。
- 9PyCharm查看运行状态的步骤及方式!_pycharm 运行进度
- 10等保系列之——网络安全等级保护测评:工作流程及工作内容_网络安全等级保护测评流程
Hive On Spark 概述、安装配置、计算引擎更换_hive on spark配置
赞
踩
因为我们的版本选择的纯净版,所以需要在 Spark 环境文件中指定已经安装的 Hadoop 路径。
cd $SPARK_HOME/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
在该文件末尾添加,指定 Hadoop 路径:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
添加完成之后,保存并退出。
其中 $(hadoop classpath) 的作用是获取 Hadoop 类路径的值 (需要提前配置 Hadoop 的环境变量,否则获取不到) ,我们可以直接打印看看它存储的内容:

在 Hive 配置 Spark 参数
进入 Hive 的 conf 目录中,创建 Spark 配置文件,指定相关参数。
cd $HIVE_HOME/conf
vim spark-default.conf
添加如下配置内容:
指定提交到 yarn 运行
spark.master yarn
开启日志并存储到 HDFS 上
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop120:8020/spark-logDir
指定每个执行器的内存
spark.executor.memory 1g
指定每个调度器的内存
spark.driver.memory 1g
配置文件创建完成后,在 HDFS 上创建 Spark 的日志存储目录。
hadoop fs -mkdir /spark-logDir
上传 Jar 包并更换引擎
因为只在一台机器上安装了 Hive 和 Spark,所以当我们将任务提交到 Yarn 上进行调度时,可能会将该任务分配到其它节点,这就会导致任务无法正常运行,所以我们需要将 Spark 中的所有 Jar 包到 HDFS 上,并告知 Hive 其存储的位置。
上传文件
hadoop fs -mkdir /spark-jars
cd $SPARK_HOME
hadoop fs -put ./jars/* /spark-jars
在 Hive 的配置文件中指定 Spark jar 包的存放位置:
cd $HIVE_HOME/conf
vim hive-site.xml
在其中添加下列三项配置:
spark.yarn.jars hdfs://hadoop120:8020/spark-jars/* hive.execution.engine spark hive.spark.client.connect.timeout 5000配置项添加完成后,我们就配置好了 Hive On Spark,下面对其进行测试。
测试 Hive On Spark
进入 Hive 中创建测试表:
drop table if exists books;
create table books(id int,book_name string);
写入测试数据:
insert into books values (1,‘bigdata’);
insert into books values (2,‘hive’);
insert into books values (3,‘spark’);
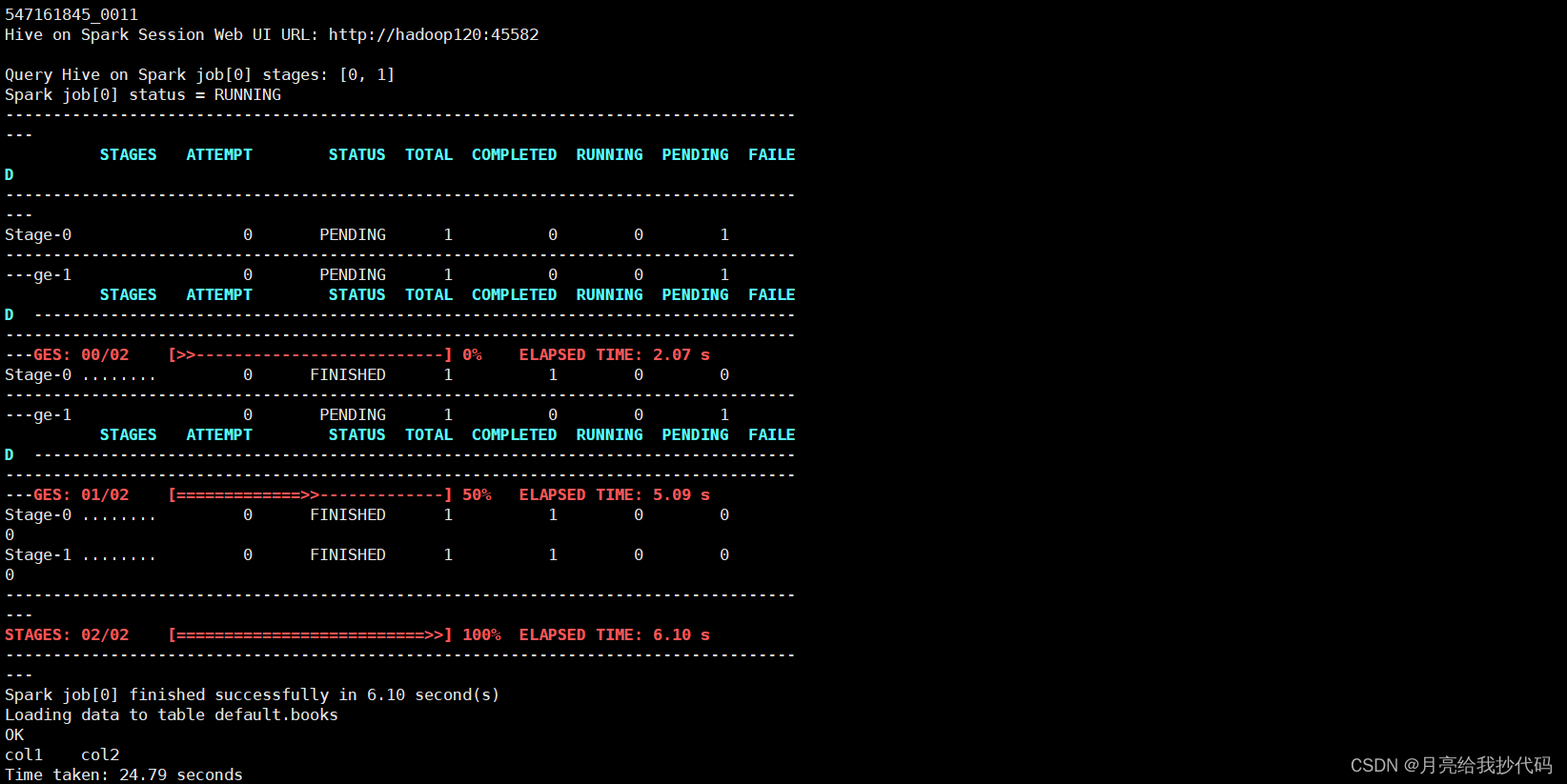
注意,每次打开终端的首次 MR 操作会消耗比较多的时间,要去与 Yarn 建立连接、分配资源等,大概
30s至1m左右。
程序运行时,可以访问其给出的 WEB URL 地址(http://hadoop120:45582 不固定),访问后如下所示:
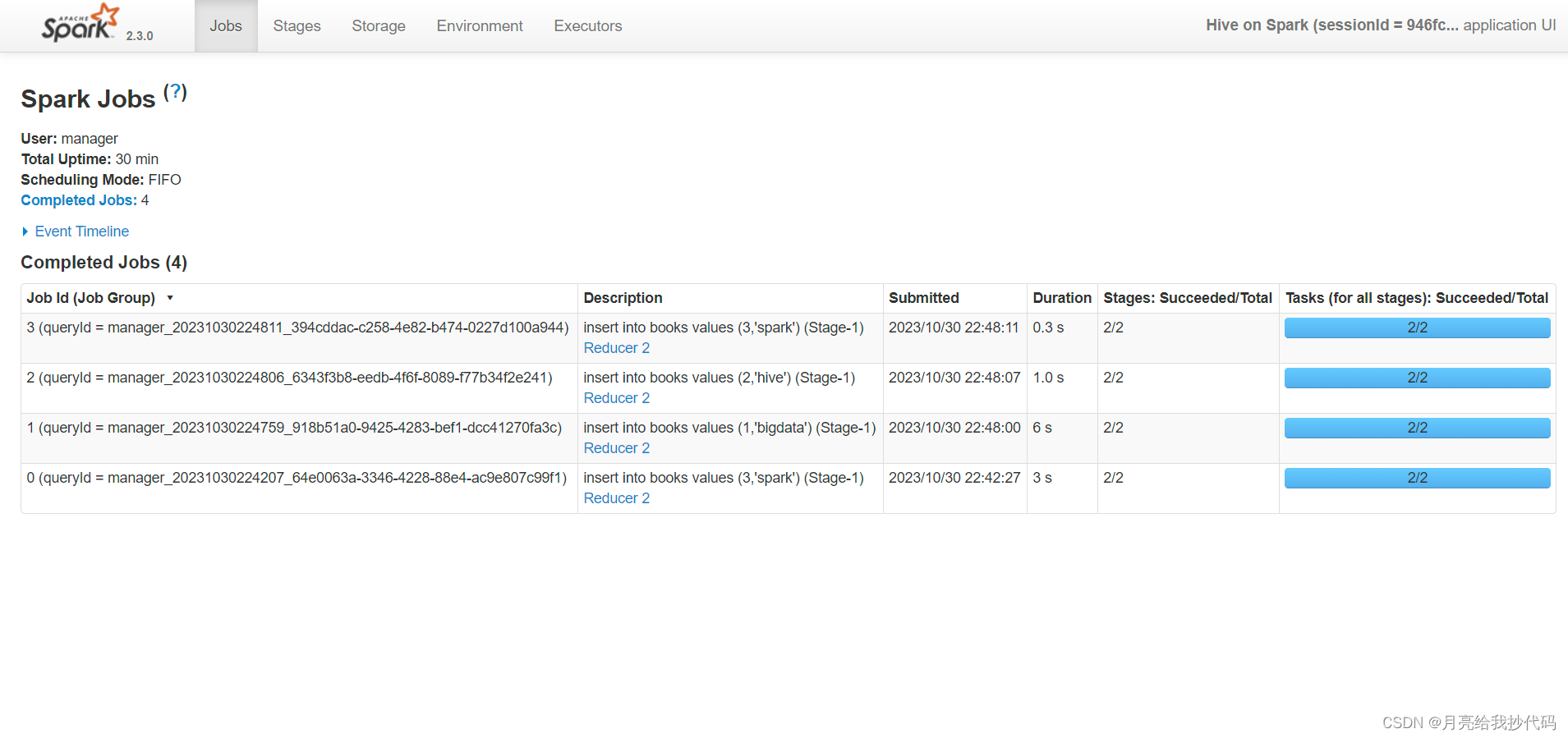
可以看到运行速度还是嘎嘎快的(真是受够了 MR!):
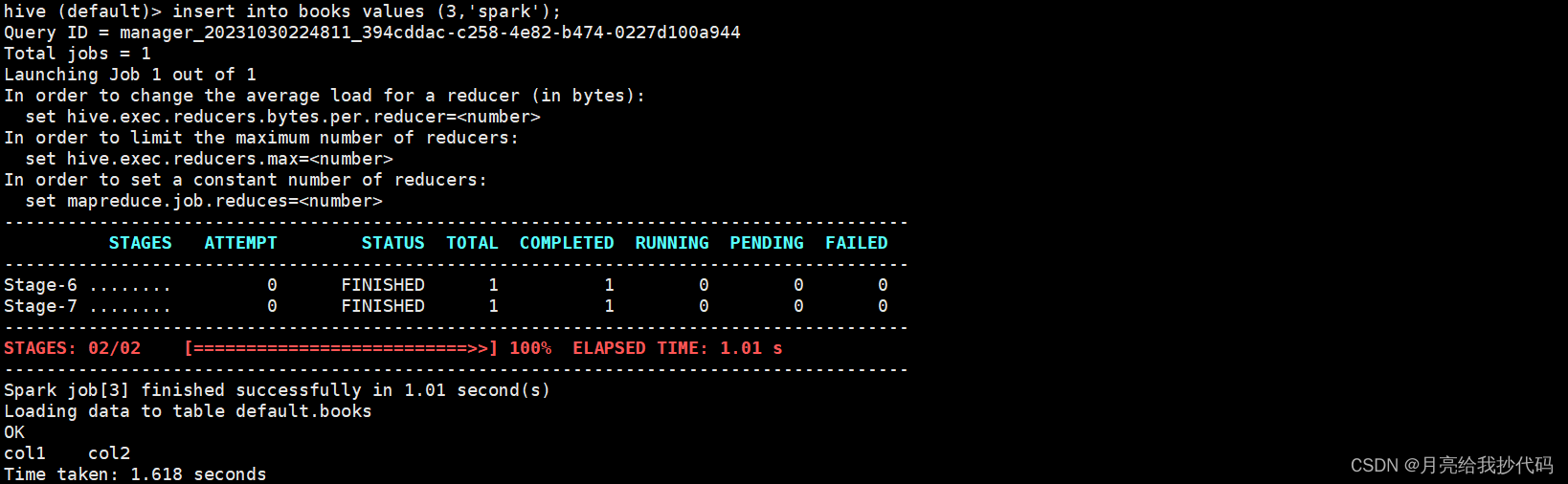
查询结果:
select * from books;

数据插入完成,测试成功。
Yarn 资源分配设置
当我们在 Hive On Spark 模式下同时启用多个 Hive 客户端进行操作时,会发现,后启动的多个 Hive 执行任务时(可能)会卡住,如下所示:
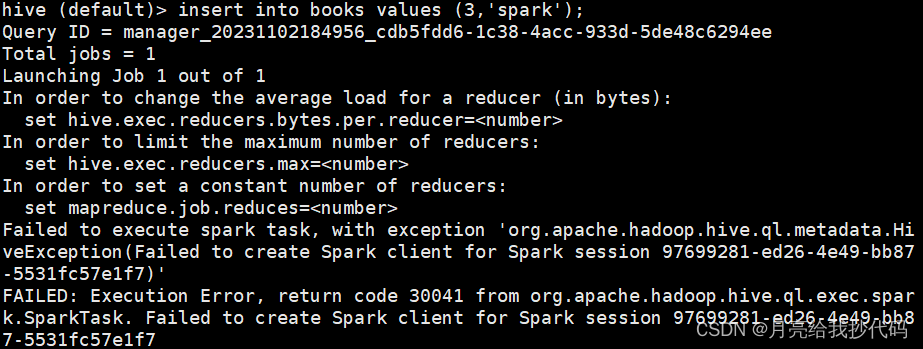
进入历史服务器,查看该任务的执行详情,会发现如下提示:
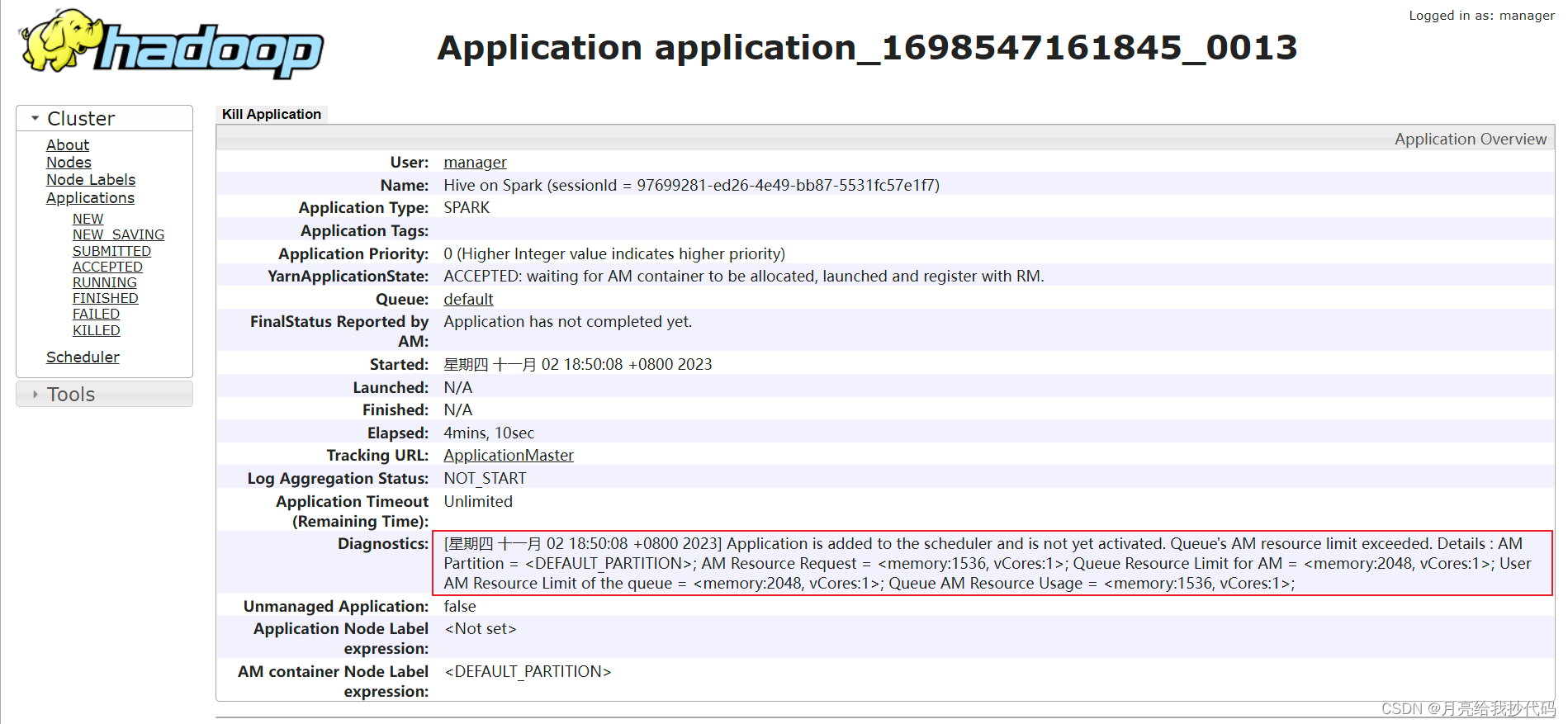
提示任务已经添加但是未激活,原因是 AM 资源溢出。
Yarn 默认使用的是容量调度器 Capacity Scheduler(队列),该队列的总容量默认为 Yarn 总资源的 %10(1024的倍数),当前我的 Yarn 集群环境分配的总资源为 18G,所以这里队列的最大容量为 2048MB,也就是 2G。
我启动第一个 Hive 客户端运行程序后,Yarn 成功的为其分配了 AM 资源,当我又启动了其它的 Hive 客户端运行程序时,就会导致 AM 资源分配失败,因为两个 AM 的总资源相加已经达 3G 左右,所以会导致任务卡顿或失败。
解决方法:提高 Yarn 为队列分配的总资源,修改 Hadoop 配置文件目录下的 capacity-scheduler.xml 文件,调整资源分配比例,默认为 0.1,对学习环境不太友好,建议调整为 0.8。
cd $HADOOP_HOME/etc/hadoop
vim capacity-scheduler.xml
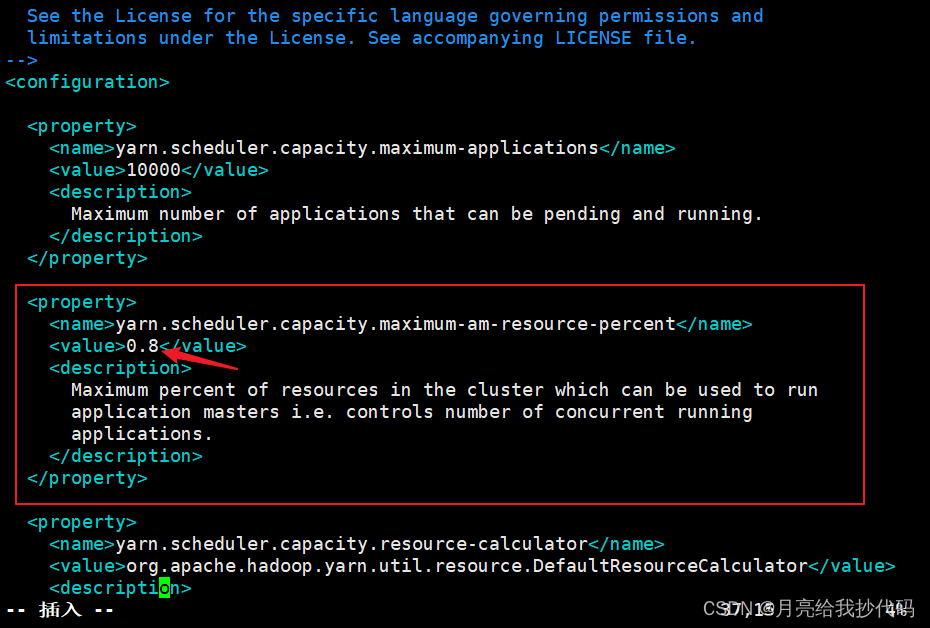
修改完成后,注意将该文件同步到集群中的其它机器,然后重启 Yarn 即可。
解决依赖冲突问题
当我们在使用 Hive On Spark 时,可能会发生如下依赖冲突问题:
Job failed with java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.mapreduce.lib.input.FileInputFormat
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:262)
at org.apache.hadoop.hive.shims.Hadoop23Shims
1.
l
i
s
t
S
t
a
t
u
s
(
H
a
d
o
o
p
23
S
h
i
m
s
.
j
a
v
a
:
134
)
a
t
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
m
a
p
r
e
d
u
c
e
.
l
i
b
.
i
n
p
u
t
.
C
o
m
b
i
n
e
F
i
l
e
I
n
p
u
t
F
o
r
m
a
t
.
g
e
t
S
p
l
i
t
s
(
C
o
m
b
i
n
e
F
i
l
e
I
n
p
u
t
F
o
r
m
a
t
.
j
a
v
a
:
217
)
a
t
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
m
a
p
r
e
d
.
l
i
b
.
C
o
m
b
i
n
e
F
i
l
e
I
n
p
u
t
F
o
r
m
a
t
.
g
e
t
S
p
l
i
t
s
(
C
o
m
b
i
n
e
F
i
l
e
I
n
p
u
t
F
o
r
m
a
t
.
j
a
v
a
:
75
)
a
t
o
r
g
.
a
p
a
c
h
e
.
h
a
d
o
o
p
.
h
i
v
e
.
s
h
i
m
s
.
H
a
d
o
o
p
S
h
i
m
s
S
e
c
u
r
e
1.listStatus(Hadoop23Shims.java:134) at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:217) at org.apache.hadoop.mapred.lib.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:75) at org.apache.hadoop.hive.shims.HadoopShimsSecure
1.listStatus(Hadoop23Shims.java:134)atorg.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:217)atorg.apache.hadoop.mapred.lib.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:75)atorg.apache.hadoop.hive.shims.HadoopShimsSecureCombineFileInputFormatShim.getSplits(HadoopShimsSecure.java:321)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

YKknQcb-1712520494264)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-xBDYcupA-1712520494264)]

