
- 1Springboot计算机毕业设计校园树洞微信小程序【附源码】开题+论文+mysql+程序+部署_树洞小程序
- 2关于SqlServer高并发死锁现象的分析排查_sql高并发锁死
- 3MySQL if函数使用详解_mysql if函数的使用
- 4如何在智能时代走向成功?从读懂华为的“朋友圈”开始
- 5设计模式-04.模板方法模式_模板方法模式使用场景
- 6单元测试中Mockito的verify方法的使用_mockito.verify
- 7Elasticsearch:用户安全设置_elasticsearch-users
- 8历史上的大部分编程语言_老编程语言
- 9Git【runtime error】_git命令 panic: runtime error:
- 10古诗词里百读不厌的388条金句_烱烱乎黯然失色,苦苦兮劳心于命;生不蚯鳅暗暗苦,哪来寒暑菊葵舒。
传神论文中心|第15期人工智能领域论文推荐_on llms-driven synthetic data generation, curation
赞
踩
在人工智能领域的快速发展中,我们不断看到令人振奋的技术进步和创新。近期,开放传神(OpenCSG)社区发现了一些值得关注的成就。传神社区本周也为对AI和大模型感兴趣的读者们提供了一些值得一读的研究工作的简要概述以及它们各自的论文推荐链接。
01 ESM3
传神社区注意到这篇文章中有以下亮点:ESM3是一款基于大型语言模型的全新生物模型,其生成了一种新的绿色荧光蛋白,称为esmGFP。该模型基于双向变换器,使用掩码语言模型作为目标函数,同时利用几何注意力机制来表示原子坐标,并应用链式思维提示生成荧光蛋白。ESM3估计,esmGFP相当于由进化模拟器完成的超过5亿年的自然进化。这表明ESM3不仅在蛋白质生成上具有开创性意义,还展示了其在生物计算和进化模拟中的强大潜力。
论文推荐链接:
https://www.opencsg.com/daily_papers/TK6CLeaCWPGz
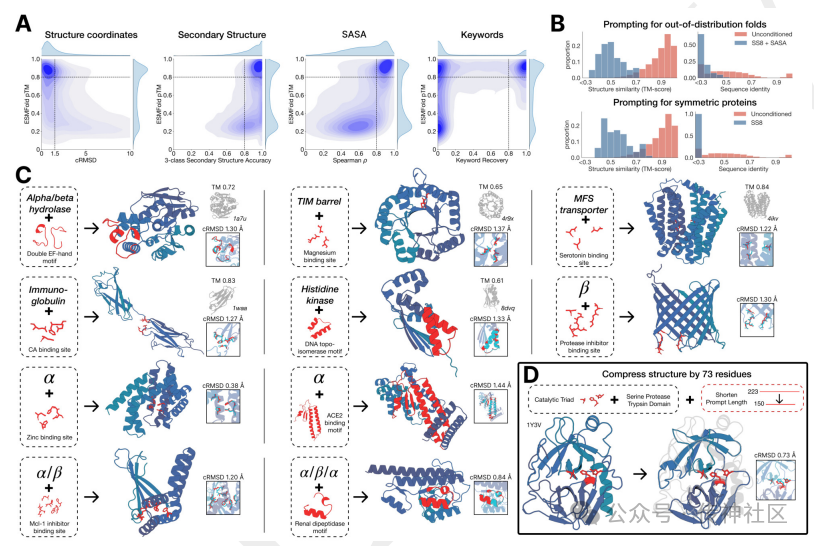
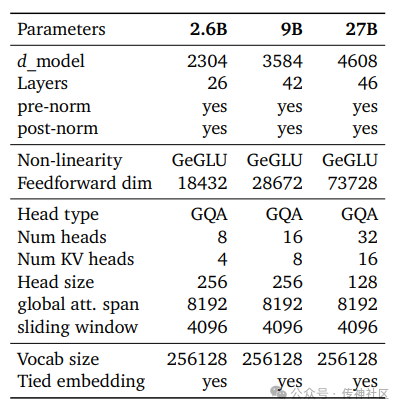
02 Gemma 2
传神社区注意到这篇文章中有以下亮点:这篇论文介绍了一款名为Gemma 2的模型家族,其参数范围从2B到27B不等。Gemma 2在推理、数学和代码生成方面展示了强大的能力,甚至超越了参数量是其两倍的模型。这表明Gemma 2不仅在多个关键任务上表现出色,还在效率和性能之间找到了平衡,具有重要的研究和应用价值。
论文推荐链接:
https://opencsg.com/daily_papers/GyqXDh8jmvLo
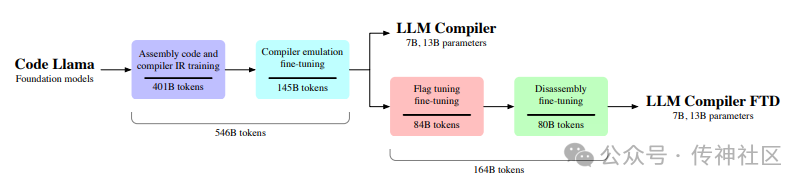
03 LLM Compiler
传神社区注意到这篇文章中有以下亮点:LLM Compiler是一组专为代码优化任务设计的开源预训练模型(参数量分别为7B和13B)。这些模型基于Code Llama构建,并在包含5460亿个LLVM-IR和汇编代码的语料库上进行训练。此外,这些模型经过指令微调以解释编译器行为。该模型组实现了自动调优搜索77%的优化潜力,并且在14%的情况下能够准确进行反汇编,与其训练所用的自动调优技术相比表现出色。这表明这些模型在代码优化和编译器行为模拟方面具有重要应用前景。
论文推荐链接:
https://opencsg.com/daily_papers/nUpLWqhMSW2M
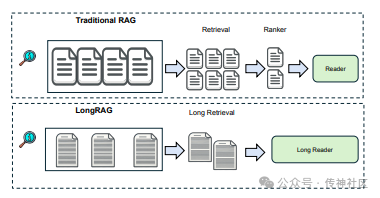
04 Enhancing RAG with Long-Context LLMs
传神社区注意到这篇文章中有以下亮点:这篇论文介绍了一种名为LongRAG的新方法,该方法结合了RAG和长上下文大型语言模型(LLM)以增强性能。LongRAG使用长检索器,通过处理更长的检索单元,显著减少了提取的单元数量。长阅读器接收这些长检索单元,并利用长上下文LLM的零样本答案提取能力来提高整个系统的性能。该方法在HotpotQA(全维基)数据集上达到了64.3%的成绩,与当前最先进的模型表现相当。这表明LongRAG在复杂问答任务中具有显著的潜力和竞争力。
论文推荐链接:
https://opencsg.com/daily_papers/Bv5dyXH3UhuL
05 Improving Retrieval in LLMs through Synthetic Data
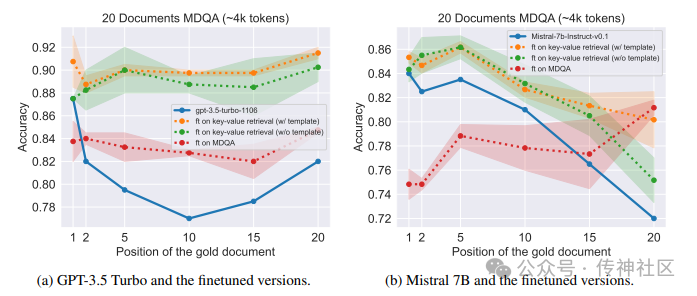
传神社区注意到这篇文章中有以下亮点:这篇论文介绍了一种通过合成数据改进大型语言模型(LLM)信息检索的微调方法。这种方法在提高信息检索准确性的同时,保持了对长上下文输入的推理能力。微调数据集包含350个数字字典键值检索任务样本。研究发现,这种方法缓解了“中途丢失”现象,并在信息检索和长上下文推理方面均提高了性能。这表明该微调方法在增强LLM的信息检索能力和长上下文处理能力方面具有显著效果。
论文推荐链接:
https://opencsg.com/daily_papers/gqV1FTpUCZ1r
06 GraphReader
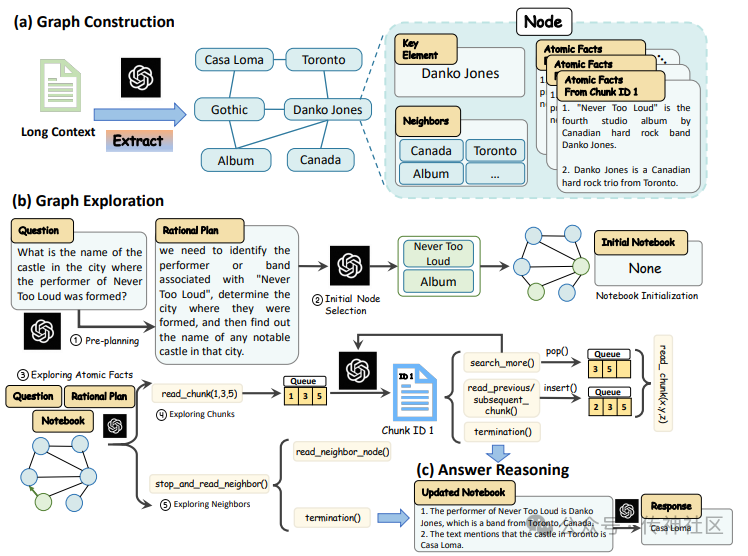
传神社区注意到这篇文章中有以下亮点:GraphReader是一种图基代理系统,用于增强大型语言模型(LLM)的长上下文能力。GraphReader将长文本结构化为图,并通过代理使用预定义函数和逐步的合理计划来探索图,以有效生成问题的答案。在上下文长度从16k到256k的范围内,GraphReader的表现始终优于GPT-4-128k。这表明GraphReader在处理长文本和复杂问答任务中具有显著的优势。
论文推荐链接:
https://opencsg.com/daily_papers/Sz5yxj8GGzXX
07 Faster LLM Inference with Dynamic Draft Trees
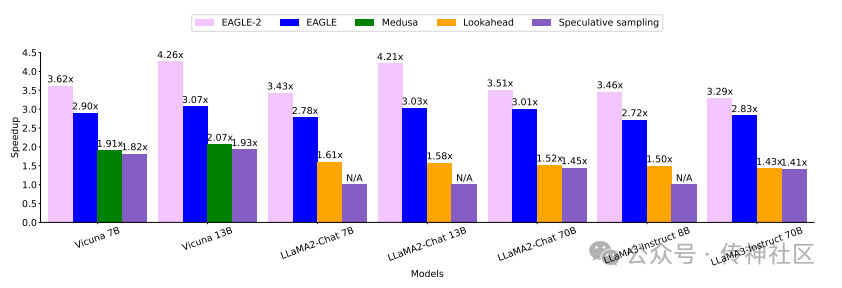
传神社区注意到这篇文章中有以下亮点:《Faster LLM Inference with Dynamic Draft Trees》提出了一种上下文感知的动态草稿树方法,用于提升大型语言模型的推理速度。相比之前依赖位置的静态草稿树方法,动态草稿树通过增加接受的草稿标记数量,显著提高了推理速度,达到了3.05倍至4.26倍的加速比,比之前的工作快了20%-40%。这种创新方法在优化LLM推理效率方面表现出色,值得关注。
论文推荐链接:
https://opencsg.com/daily_papers/asX5jXi6wJH2
08 Following Length Constraints in Instructions
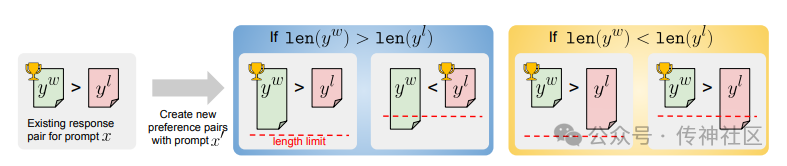
传神社区注意到这篇文章中有以下亮点:《Following Length Constraints in Instructions》提出了一种处理长度偏差的方法,使语言模型能够更好地遵循长度限制指令。该方法通过使用包含长度指令的增强数据集对模型进行DPO微调,显著减少了长度限制的违反情况,同时保持了高响应质量。这种创新方法在优化模型遵循长度限制指令方面表现出色。
论文推荐链接:
https://opencsg.com/daily_papers/HgrXAm9a7HHt
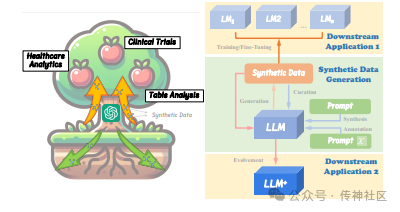
09 On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation
传神社区注意到这篇文章中有以下亮点:《On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation》综述了基于大型语言模型(LLM)的合成数据生成、管理和评估方法。论文亮点包括全面介绍了LLM在合成数据生成方面的最新进展、数据管理技术以及评估方法,展示了LLM在提高数据质量和多样性方面的强大潜力。
论文推荐链接:
https://opencsg.com/daily_papers/FLcCpuwNFUHu
10 Adam-mini
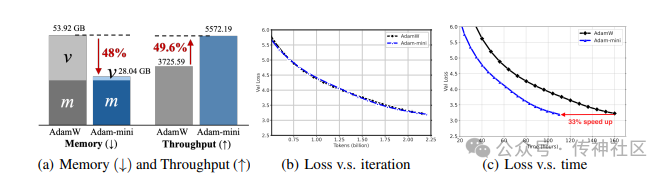
传神社区注意到这篇文章中有以下亮点:Adam-mini是一种新的优化器,通过使用更少的学习率减少了45%-50%的内存占用,同时在性能上与AdamW相当甚至更优。该优化器将参数精细地分块,并为每个块分配单一的高质量学习率,从而超越Adam。在从125M到7B规模的语言模型上进行预训练、SFT和RLHF时,Adam-mini始终表现出一致的优异性能。
论文推荐链接:
https://opencsg.com/daily_papers/CAVfZHYCuCjA
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

