
- 1Nature Medicine·DEPLOY模型:从病理学图像直接预测DNA甲基化,破解CNS肿瘤诊断难题!_deep learning from histopathology and methylation
- 2Docker Desktop总是占用C盘空间的终极解决之道_docker desktop 2.3.0.4
- 3快速搞定前端JS面试 -- 第十二章 运行环境 (页面加载、性能优化、安全)(1)_加载页面资源
- 4Java使用PaddleOCR,这可能是Java目前最通用的OCR_paddleocr java
- 5C语言基础之单向链表_c语言单向链表
- 6ElasticSearch搜不出来数据原因以及使用RabbitMQ出现问题和SpringBoot单体项目集成RabbitMQ_elasticsearch 搜索能连接上 不能搜索
- 7太强了!10大开源大模型!_开源模型
- 8hive内部表与外部表入门_hive外部表demo
- 9ubuntu jdk tomcat mysql_Ubuntu 下 JDK+Tomcat+MySql 环境的搭建
- 10基于Springboot框架+微信小程序实现商场电子优惠券系统设计演示【附项目源码+论文说明】分享_优惠券管理系统
解密Prompt系列9. 模型复杂推理-思维链COT基础和进阶玩法
赞
踩
前言
终于写了一篇和系列标题沾边的博客,这一篇真的是解密prompt!我们会讨论下思维链(chain-of-Thought)提示词究竟要如何写,如何写的更高级。COT其实是Self-ASK,ReACT等利用大模型进行工具调用方案的底层逻辑,因此在Agent调用章节之前我们会有两章来讲思维链
先打预防针,COT当前的研究多少存在一些玄学成分,部分COT的研究使用的模型并非SOTA模型,以及相同的COT模板在不同模型之间可能不具备迁移性,且COT的效果和模型本身能力强相关,哈哈可以去围观COT小王子和Claude友商的Prompt决战]。本章只是为大家提供一些思维链设计的思路,以及给Agent调用做一些铺垫。
思维链的核心是为了提高模型解决复杂推理问题的能力,包括但不限于符号推理,数学问题,决策规划等等,Chain-of-Thought让模型在得到结果前,模拟人类思考推理的过程生成中间的推理步骤。适用于以下场景
- 有挑战的任务
- 解决任务本身需要多步推理
- 模型规模对任务效果的提升相对有限
COT基础用法
Few-shot COT
Chain of Thought Prompting Elicits Reasoning in Large Language Models
开篇自然是COT小王子的成名作,也是COT的开山之作,单看引用量已经是一骑绝尘。

论文的核心是通过Few-shot的方案,来引导模型生成中间推理过程,并最终提高模型解决复杂问题的能力。核心逻辑很Simple&Naive
- 通过在Few-shot样本中加入推理过程,可以引导模型在解码过程中,先给出推理过程,再得到最终答案
- 类似中间推理过程的加入,可以显著提高模型在常识推理,数学问题,符号推理等复杂推理问题上的模型表现。
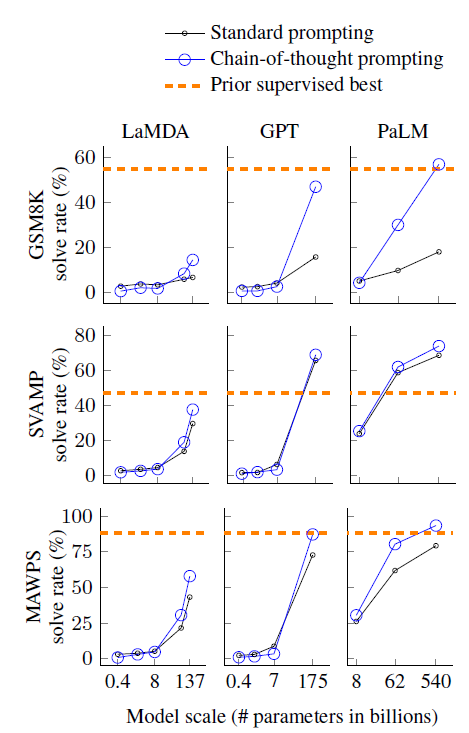
先看效果,见上图,可以得到几个insights
- COT带来的效果提升具有涌现性,只在100B左右的大模型上才出现显著更优的效果,但作者没有给出模型规模的影响原因
- COT带来的效果提升在复杂问题例如GSM8K上表现更显著
让我们直观来看下COT的Few-shot模板构建,以及对解码的影响。这里我们使用Belle的数学COT指令样本采样10个构建了一组few-shot思维链指令,如下,

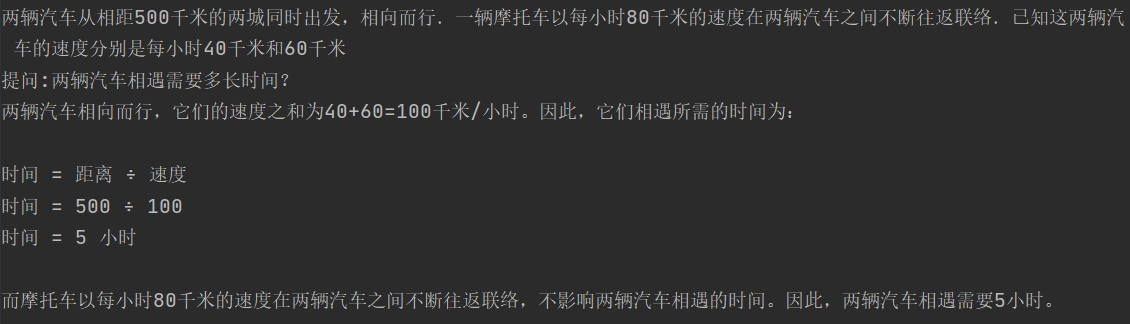
测试数学能力嘛,小学奥数经典的汽车相遇问题走一个,问题:两辆汽车从相距500千米的两城同时出发,相向而行.一辆摩托车以每小时80千米的速度在两辆汽车之间不断往返联络.已知这两辆汽车的速度分别是每小时40千米和60千米,求两汽车相遇时,摩托车共行驶了多少千米?题目不复杂500/(40+60)*80 = 400千米
以下分别使用ChatGPT和ChatGLM在Greedy-search模式下进行解码,分别是直接提问和加入few-shot-cot后再提问
| prompt | chatgpt | chatglm-6b |
|---|---|---|
| 直接提问 | 设两汽车相遇时间为t | 设两汽车相遇时,摩托车行驶了 x |
| few-shot COT | 设摩托车共行驶了x千米,则两辆汽车相遇时,摩托车往返的次数为x/500。在每次往返中,摩托车行驶的距离为80千米,所以摩托车共行驶的距离为:x = (80千米) × (x/500) = 0.16x千米两辆汽车相遇时,它们的总路程为500千米,所以它们相遇所用的时间为:t = 500千米 / (40千米/小时 + 60千米/小时) = 5小时根据摩托车的速度和时间,可以得到:x = 80千米/小时 × 5小时 = 400千米因此,摩托车共行驶了400千米。 | 设两汽车相遇时,摩托车行驶了 x |
加入COT之后chatgpt和chatglm都双双答对了,虽然有运气成分,且推理过程还显得有点智障吧。但你会发现不加入few-shot COT模型同样会进行推理再给出答案,而非像论文中给出的模型会直接直接给一个答案没有任何推理。原因是论文使用的是text-davinci-002是没有经过RLHF的旧版本模型。我们在一些需要推理的多项选择问题上也进行了测试,不管是使用few-shot COT还是加入COT指令样本进行微调,确实都能带来一定程度上推理/数学能力的提升。
论文还进行了一些消融实验包括
- 准确率提升是否来自数学公式的引入?
论文尝试了few-shot部分只加入公式并不能显著提升效果。个人感觉这个消融实验不太完整,因为很多复杂MWP问题模型很难映射到单一的公式,而先进行问题分解后再逐步映射到中间公式,在我们的场景里是可以提升效果的。这里推荐两个数据集:APE210K和Math23K分别是猿辅导和腾讯开源的数学世界问题转化成公式的数据集,大家可以自己试试看
- 准确率提升是否因为few-shot-cot帮助模型更好的召回相应的知识?
论文尝试了先给出答案再进行推理的prompt模板,发现效果显著变差。说明few-shot-COT只是激活模型给出推理,推理过程本身才是模型效果提升的核心。我们在一些需要推理的多项选择问题上也发现,先推理再回答选项的效果显著优于先回答选项再给出推理过程
zero-shot COT
Large Language Models are Zero-Shot Reasoners
除了使用Few-shot-COT样本可以让模型给出推理过程,单纯用指令也可以让模型给出思维链,且能进一步提升模型复杂问题推理能力。论文中效果最好的激活思维链的指令是"Let’s think step by step"哈哈哈,我当时论文看到这里感觉空气都凝固了

zero-shot-COT在论文中需要两步解码,第一步用Let’s think step by step让模型给出推理过程,第二步把推理过程和问题一起输入模型,让模型给出结果。但实际使用时你会发现,基本上第一步解码模型就会在推理结束时给出结果,而把带结果的输入再输入模型,极大概率第二步模型会给出相同的答案,所以其实zero-shot-COT也可以直接一步到位。
咱主打一个和相遇问题死磕,还是摩托车和货车相遇,咱使用几组不同的激活词再来问一遍
| 激活词 | chatgpt | chatglm |
|---|---|---|
| 请一步步的推理分析解决以下问题 | 设两汽车相遇时间为t小时,则两汽车相遇时的距离为(40+60)t=100t千米。由于两汽车相向而行,所以它们的相对速度为40+60=100千米/小时。因此,摩托车在t小时内往返的距离为2×80t=160t千米。根据题意,摩托车在两汽车相遇时停止往返,因此摩托车共行驶的距离为160t千米。将上述两个式子联立,解得t=2.5小时。因此,摩托车共行驶的距离为160×2.5=400千米。 | 设两汽车相遇时,摩托车行驶了 x |
| 请逐步推理回答问题 | 设两汽车相遇时间为t小时,则两汽车相遇时的距离为(40+60)t=100t千米。根据题意,摩托车以80千米/小时的速度在两汽车之间不断往返,因此摩托车在t小时内往返的路程为2×80×t=160t千米。所以,摩托车共行驶了160t千米。将两式相等,得到:100t=500t=5此,两汽车相遇时,摩托车共行驶了160×5=<<160*5=800>>800千米。 | 设两汽车相遇时,摩托车行驶了 x |
2组提示词,只有第一组让chatgpt给出了正确的答案,整体上提示词的效果很玄学,我们在不同问题上例如多项选择,数学计算也试过很多不同的方案,没找到啥规律。论文作者也尝试了不同的指令词来验证zero-shot-COT对指令词的依赖程度,见下表。整体上只要指令词有引导模型逐步推理的含义在,对模型效果都是有提升的。我个人也是看到这里才觉得zero-shot-COT可能确实有一定的合理性,因为指令提供的上文语义确实和模型推理的解码语义存在一定的相关性。

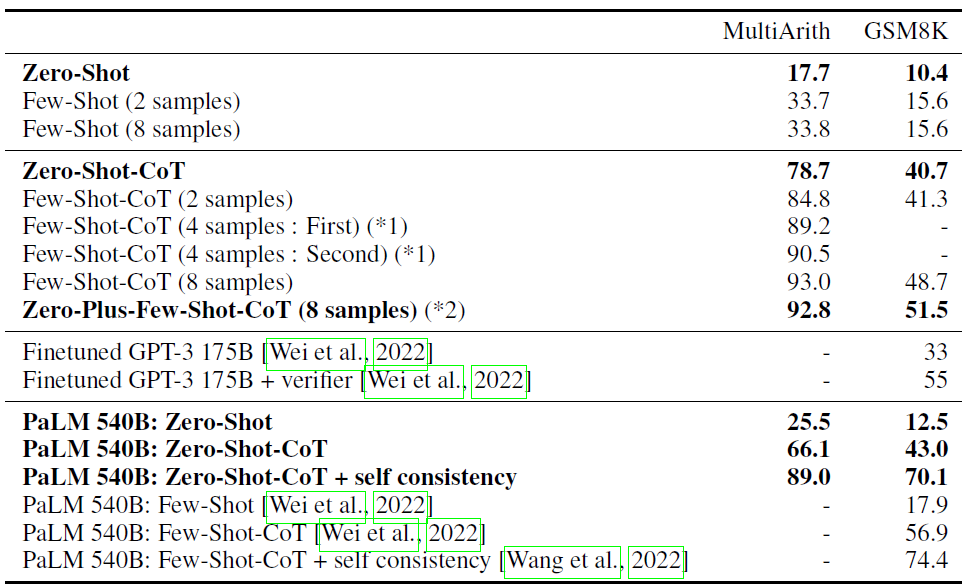
效果上,论文在MultiArith和GSM8k上和few-shot-cot进行了对比,整体上比few-shot略差,但是要显著超越只使用指令的baseline。不过需要注意,这里的评测模型还是是text-davinci-002,是没有经过RLHF只做了SFT的版本,并不是当前的最强模型,因此下图的效果提升放到GPT4上会打不小的折扣。毕竟GPT-4使用few-shot-COT在GSM8k上准确率已经奔着90%+去了。在模型大小上,zero-shot-COT同样具有规模效应,只在大模型上才表现出超越常规指令的效果
COT进阶用法
以上不论是few-shot还是zero-shot COT都还是基于模型自身给出推理过程,而人工不会过多干预推理过程。在进阶用法中会对推理过程做进一步的人工干预来引导解码步骤,进一步提升解码准确率,且以下的进阶方案是可以组合使用的。
Self-Consistency
SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
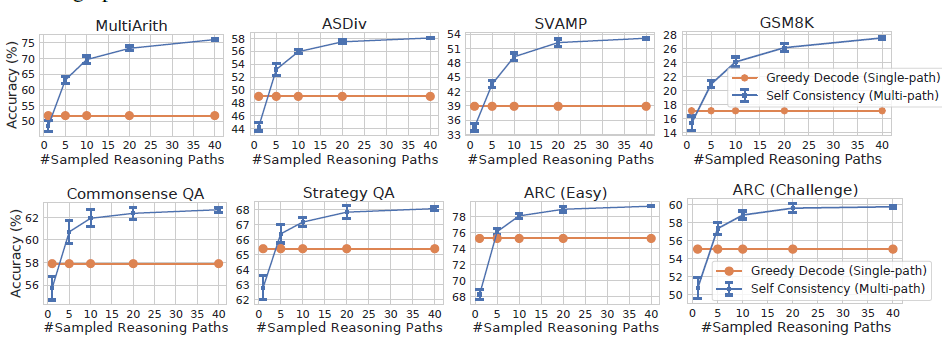
self-consistency是在few-shot-cot的基础上,用Ensemble来替换Greedy Search,来提高解码准确率的一种解码策略,论文显示加入self-consistency,可以进一步提升思维链的效果GSM8K (+17.9%)。
在使用大模型进行固定问题回答例如多项选择,数学问题时,我们往往会采用Greedy-Search的方式来进行解码,从而保证模型解码生成固定的结果,不然的话使用随机解码,我采样4次,模型把ABCD都选了一遍,那这题模型到底是答对了还是答错了??但每一步都选Top Token的局部最优的解码方案很显然不是全局最优的,而self-consistency其实提供了一种无监督的Ensemble方案,来对模型随机解码生成的多个回复“投票”出一个更准确答案,如下图
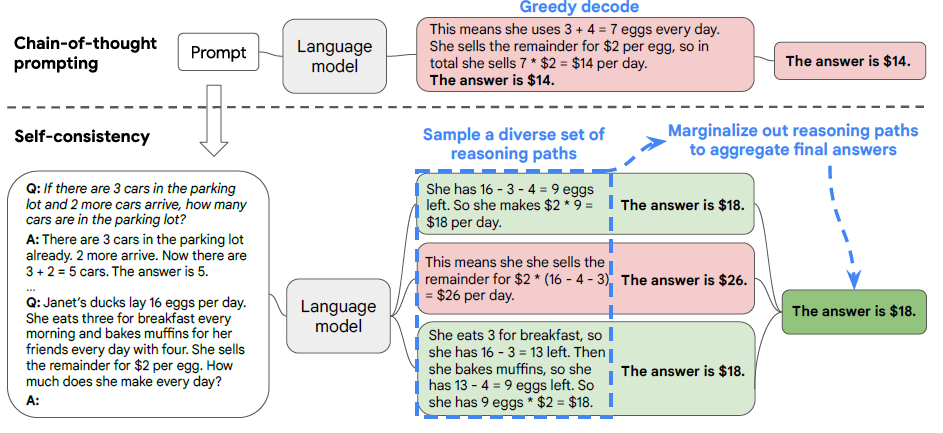
self-consistency的基础假设很人性化:同一个问题不同人也会给出不同的解法,但正确的解法们会殊途同归得到相同的正确答案。以此类比模型解码,同一问题不同随机解码会得到不同的思维链推理过程,期望概率最高的答案,准确率最高。那核心就变成针对多个解码输出,如何对答案进行聚合。论文对比了以下几种方案
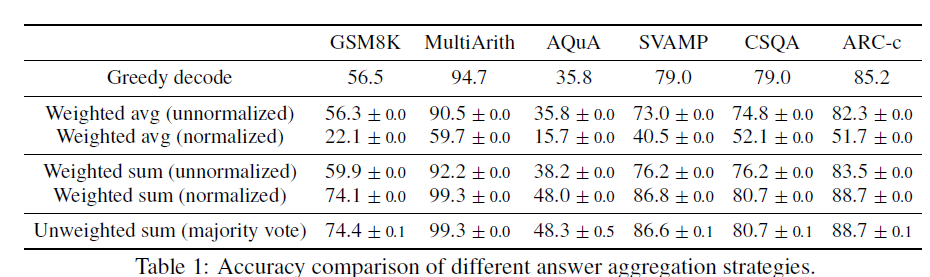
给定指令prompt和问题question,模型通过随机解码会生成一组a1,a2,…am
- major vote:直接对解码后的结果投票大法投出一个出现概率最高的答案。该说不说大道至简,最简单的方案往往是最好的, 论文后面的结果都是基于投票法给出的
- normalized weighted sum: 计算(ri,ai)
(ri,ai) 路径的概率,既模型输出的每一个token条件解码概率求和,并对解码长度K进行归一化。虽然这里略让人惊讶,本以为加权结果应该会更好,可能一定程度也说明模型的解码概率在答案的正确性上其实不太有区分度。
p(ri,ai|prompt,question)=exp(1kK∑k=1logP(tk|prompt,question,t1,…tk−1))
针对解码参数论文还做了一些测试
- 随机参数:self-consistency支持不同的随机解码策略,在参数设定上需要平衡解码的多样性和准确率,例如temperature太低会导致解码差异太小,投票投了个寂寞,太高又会影响最终的准确率。看测试可能top-p=40, temperature=0.5是一个不错的测试起点
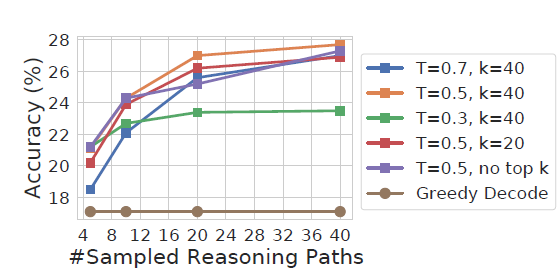
- 采样次数:major vote的效果很依赖候选样本数,论文中很豪横采样了40次,地主家的儿子也不敢这么玩…看效果采样5次以上就能超过Greedy解码,具体解码次数看你家有多少余粮吧…
Least-to-Most
LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS
如果说上面的Self-Consisty多少有点暴力出奇迹,那Least-to-Most明显更优雅一些。思路很简单,在解决复杂问题时,第一步先引导模型把问题拆分成子问题;第二步逐一回答子问题,并把子问题的回答作为下一个问题回答的上文,直到给出最终答案,主打一个循序渐进的解决问题。也可以理解为通过few-shot来引导模型给出更合理,更一致的推理思路,再根据这个思路在解决问题。
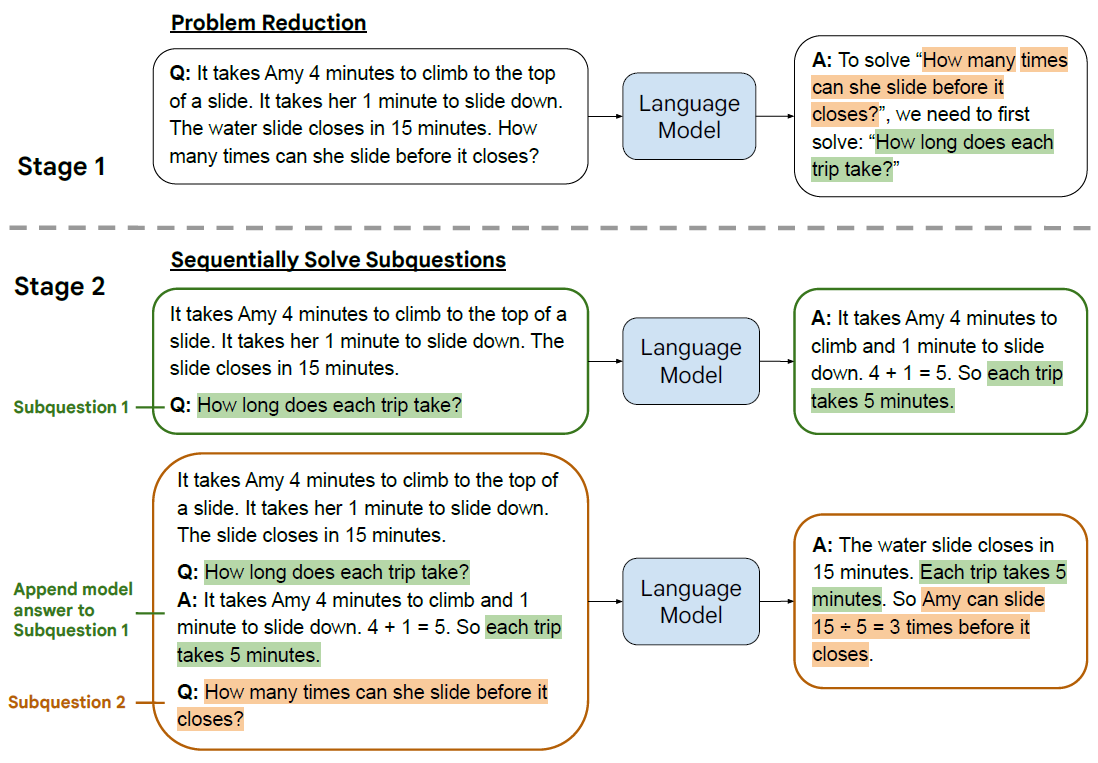
设计理念很好,但我最好奇的是few-shot-COT要如何写,才能引导模型针对不同场景进行合理的问题拆解。这里我们还是看下针对数学问题的few-shot应该如何构建的,论文中的few-shot-prompt是纯手工写制作,这里我采用chatgpt来生成再人工调整。从APE21K中随便抽了3个问题,注意不要太简单,已经有论文证明,few-shot-COT样本的推理步骤越多效果越好。这里我拆解问题的Prompt(未调优)是"对以下数学问题进行问题拆解,分成几个必须的中间解题步骤并给出对应问题, 问题:",来让ChatGPT生成中间的解题步骤作为few-shot-cot模板
- Problem Reducing 问题拆解

还是同一道相遇问题,通过Reduce prompt,ChatGPT输出:要解答摩托车共行驶了多少千米?我们需要回答以下问题:“两辆汽车相遇需要多长时间?”,"摩托车在这段时间内共行驶了多少千米?
以上的问题拆解不是非常稳定,有时会包括最终的问题,有时只包括中间的解题步骤,为了保险起见,你可以在解析的问题后面都再加一个原始的问题。
- Sequentially Solve 子问题有序回答
把Reduce步骤的子问题解析出来,按顺序输入chatgpt,先回答第一个子问题
再把第一个子问题和回答一起拼接作为上文,这里使用对话history也可以,拼接只是为了直观展示

Least-to-Most最值得借鉴的还是它问题拆分的思路,这在后面被广泛借鉴,例如Agent调用如何拆分每一步的调用步骤,以及如何先思考再生成下一步Action,在这些方案里都能看到Least-to-Most的影子。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

