
热门标签
热门文章
- 1广州大学2020操作系统实验一:进程管理与进程通信
- 2用git rebase合并_new blank line at eof.
- 3Python(3)获取Prometheus数据:RPS峰值、响应时间等监控指标,并保存到本地csv文件中_prometheus python
- 4hacker入门——最好用的渗透测试工具_hacker使用
- 5使用JAVA代码实现跳动爱心(脱单节程序员必备哦)_java爱心代码跳动
- 6malloc/free内存碎片的产生原因_malloc free造成内存碎片
- 7Linux下安装ZooKeeper
- 8Github——设置默认分支_github 改变默认分支
- 9特别详细的Spring Cloud 系列教程1:服务注册中心Eureka的启动_eureka启动
- 10ICE(Interactive Connectivity Establishment)
当前位置: article > 正文
Spark系列之数据倾斜:数据倾斜之痛_spark streaming的数据倾斜
作者:在线问答5 | 2024-08-13 17:48:21
赞
踩
spark streaming的数据倾斜
本博文的主要内容包括:
- Spark性能真正的杀手
- 数据倾斜多么痛
1、关于性能调优首先谈数据倾斜,为什么?
(1)因为如果数据倾斜,其他所有的调优都是笑话,因为数据倾斜主要导致程序跑步起来或者运行状态不可用。
(2)数据倾斜最能代表spark水平的地方,spark是分布式的,如果理解数据倾斜说明你对spark运行机制了如指掌。
2、数据倾斜两大直接致命性的后果:
(1)、OOM,一般OOM都是由于数据倾斜所致!
(2)、速度变慢、特别慢、非常慢、极端的慢、不可接受的慢!
何为数据倾斜如下图所示:
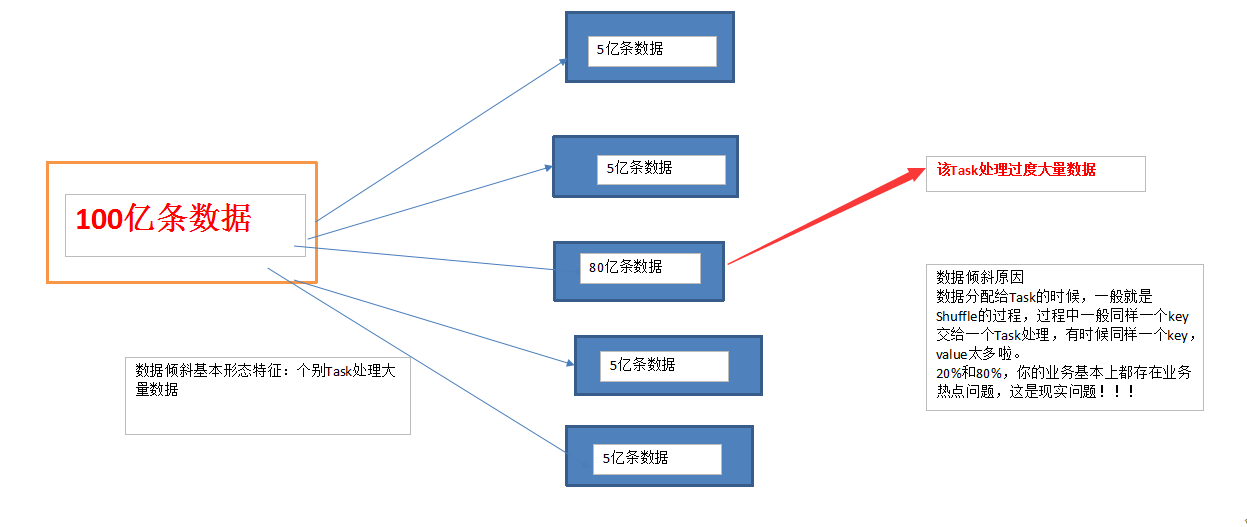
3、性能调优最好的方法。
数据倾斜解决掉之后最好的方法就是加内存和CPU 。
4、数据倾斜的定位:
(1)Web UI,可以清晰看见哪些个Task运行的数据量大小;
(2)Log,Log的一个好处是可以清晰的告诉是哪一行出现问题OOM,同时可以清晰的看到在具体哪个Stage出现了数据倾斜(数据倾斜一般是在Shuffle过程中产生的),从而定位具体Shuffle的代码;也有可能发现绝大多数Task非常快,但是个别Task非常慢;
(3)代码走读,重点看join、groupByKey、reduceByKey等关键代码;
(4)对数据特征分布进行分析;
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/在线问答5/article/detail/975887
推荐阅读
相关标签

