
- 1004--利用系统溢出漏洞提权_上传溢出漏洞利用 exp 进行提权
- 2更新GitHub上自己 Fork 的代码与原作者的项目进度一致_在fork后的代码上修改原项目会被改动吗
- 3自动驾驶数据闭环与工程化_自动驾驶数据闭环参考文献
- 4头歌Hadoop 开发环境搭建及HDFS初体验(第2关:配置开发环境 - Hadoop安装与伪分布式集群搭建)_hadoop安装与伪分布式集群搭建头歌(2)_第2关:配置开发环境 - hadoop安装与伪分布式集群搭建
- 5完美解决错误: 找不到符号 DataBindingComponent_databindingcomponent 找不到符号
- 6【Python】【进阶篇】十四、Tkinter的布局管理器_python tkinter布局助手
- 7w3c 收银系统算法挑战_if (!cid)
- 8虚幻UE 增强输入-触发器_ue5增强输入系统trigger教程
- 9DataX数据同步工具使用
- 10verilog中reg,integer的使用规则_verilog integer用法
mapreduce的setup方法_mapreduce流程
赞
踩
mapTask运行机制
mapTask并行度:同时存在几个mapTask
TextInputFormat中的getSplits方法返回的是切片数目,有多少切片就有几个mapTask。
获取文件的切片的几个参数控制:
mapred.min.split.size 没有配置的话默认值是1
mapred.max.split.size 没有配置的话默认值是 Long.MAX_VALUE
如果没有配置上面这两个参数,我们文件的切片大小就是128M,与我们的block块相等
正常一个block块对应一个mapTask
mapTask流程
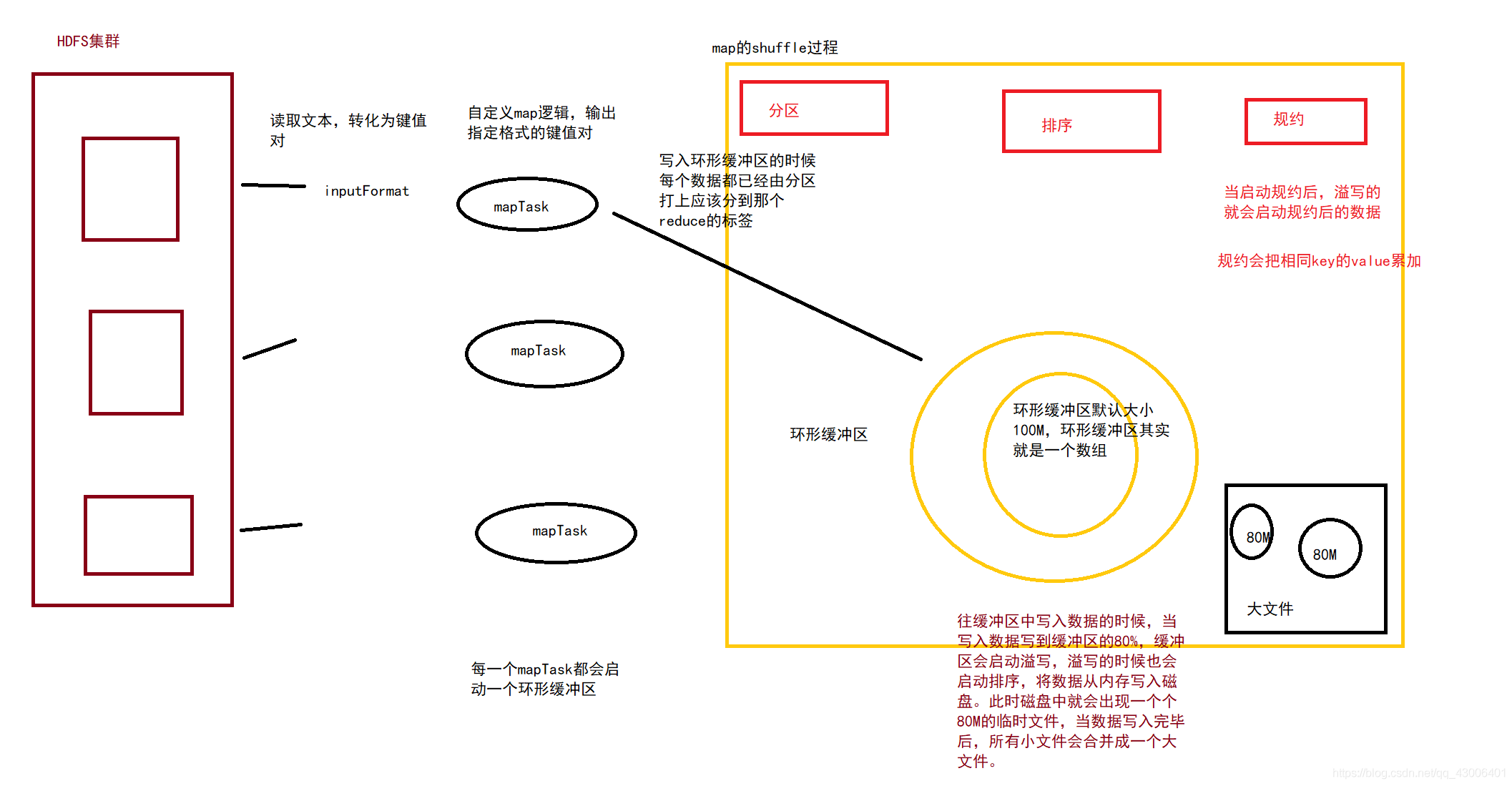
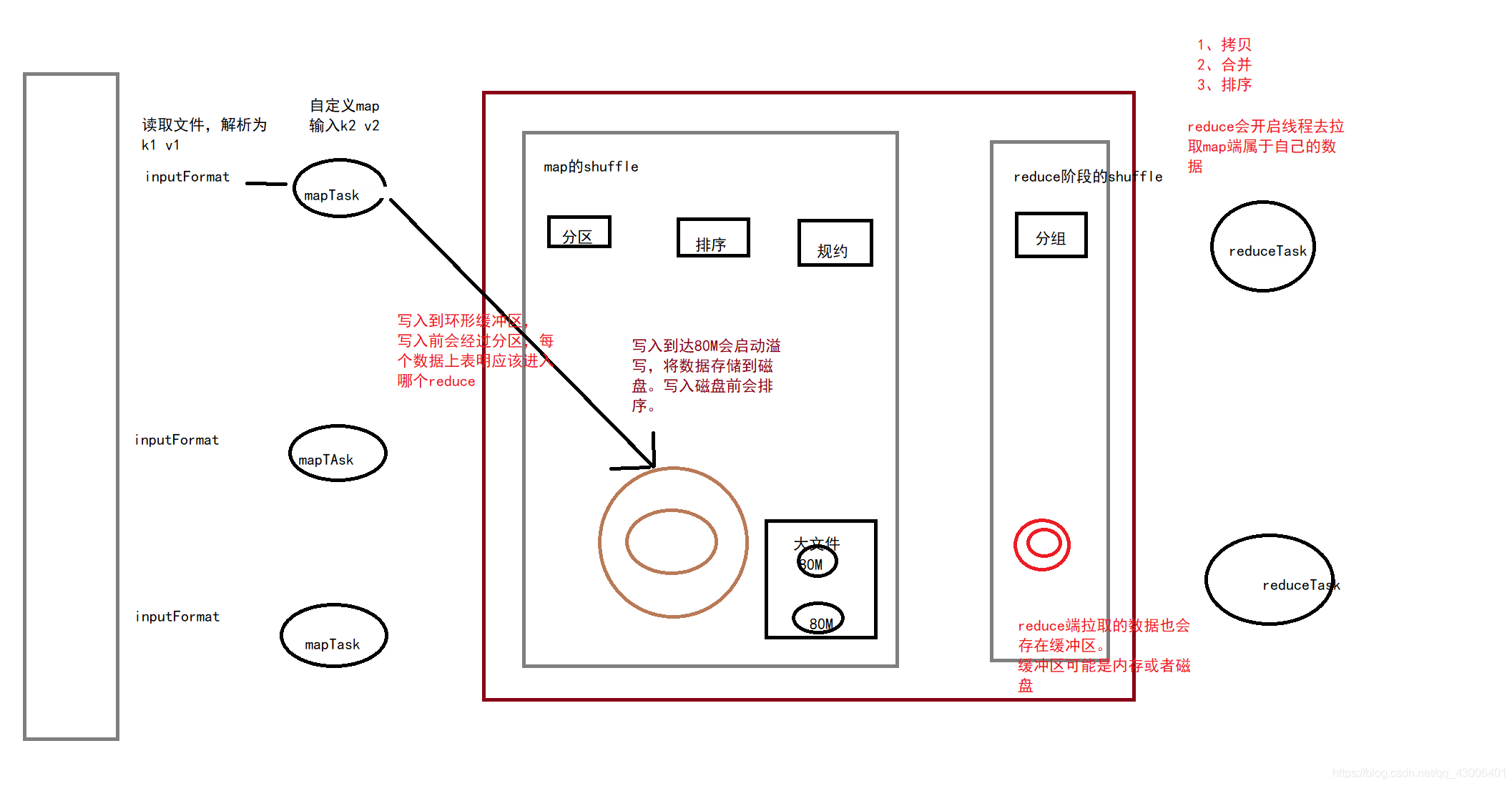
1、inputFormat读取文件数据,并解析为相对应的键值对k1,v1
2、自定义map程序,解析为我们想要的k2,v2
3、在写入环形缓冲区前会进入分区阶段,每个数据指定将要进入哪一个reduce
4、写入环形缓冲区。环形缓冲区默认大小为100M,当写入的数据到达80M的时候,会启动溢写。
5、在溢写的时候会对溢写数据进行排序,然后再写入磁盘的临时文件中。
6、当该mapTask数据写入完成后,所有临时文件会合并成一个大文件
mapTask基础设置配置
设置一:设置环型缓冲区的内存值大小(默认设置如下)
mapreduce.task.io.sort.mb 100
设置二:设置溢写百分比(默认设置如下)
mapreduce.map.sort.spill.percent 0.80
设置三:设置溢写数据目录(默认设置)
mapreduce.cluster.local.dir ${hadoop.tmp.dir}/mapred/local
设置四:设置一次最多合并多少个溢写文件(默认设置如下)
mapreduce.task.io.sort.factor 10
reduceTask机制
reduceTask流程
1、copy ,reduce开启线程拉取属于自己的数据
2、合并 ,将数据进行合并也就是分组
3、排序 reduce局部排序,每个reduce间不干扰
reduce的copy也是有个缓冲区,缓冲区类似与mapTask,缓冲区有限定值,满了以后存入磁盘
mapReduce全流程
Snappy压缩
可以配置文件中设置也可以代码中设置
reduce端join算法
reduce太少:每个reduce压力太大
reduce太多:资源浪费
map端join算法
去掉reduce
采用缓存
package cn.nina.mr.demo6;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper {
//在程序主类运行方法里加了缓存文件,这里可以获取缓存文件
Map map = null;
//重写setup方法获取缓存文件,将缓存文件内容存储到map当中去
@Override
protected void setup(Context context) throws IOException, InterruptedException {
map = new HashMap();
//从context中获取configuration
Configuration configuration = context.getConfiguration();
//只有一个缓存文件,所以可以直接取第一个
URI[] cacheFiles = DistributedCache.getCacheFiles(configuration);
URI cacheFile = cacheFiles[0];
//获取文件系统
FileSystem fileSystem = FileSystem.get(cacheFile, configuration);
//获取文件输入流,如何将流转换成字符串
FSDataInputStream open = fileSystem.open(new Path(cacheFile));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(open));
String line = null;
while ((line = bufferedReader.readLine()) != null){
String[] lineArray = line.split(",");
map.put(lineArray[0],line);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
//获取到商品表数据
String product = map.get(split[2]);
//将商品表和订单表进行拼接
context.write(new Text(value.toString()+"\t"+product),NullWritable.get());
}
}

