
May 25th, 2013
原文:http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/
日前,Apache Hadoop YARN已被提升为Apache软件基金会的子项目,这是一个值得庆祝的里程碑。这里我们也第一时间为各位献上Apache Hadoop YARN项目的系列介绍文章。YARN是一个普适的、分布式的应用管理框架,运行于Hadoop集群之上,用以替代传统的Apache Hadoop MapReduce框架。
MapReduce 模式
本质上来说,MapReduce模型包含两个部分:一是Map过程,将数据拆分成若干份,分别处理,彼此之间没有依赖关系;二是Reduce过程,将中间结果汇总计算成最终结果。这是一种简单而又条件苛刻的模型,但也促使它成为高效和极易扩展的并行计算方式。
Apache Hadoop MapReduce是当下最流行的开源MapReduce模型。
特别地,当MapReduce配合分布式文件系统,类似Apache Hadoop HDFS,就能在大集群上提供高吞吐量的计算,这一经济效应是Hadoop得以流行的重要原因。
这一模式成功的原因之一是,它使用的是“移动计算能力至数据节点”而非通过网络“移动数据至计算节点”的方式。具体来说,一个MapReduce任务会被调度到输入数据所在的HDFS节点执行,这会极大地减少I/O支出,因为大部分I/O会发生在本地磁盘或是同一机架中——这是核心优势。
回顾2011年的Apache Hadoop MapReduce
Apache Hadoop MapReduce是Apache基金会下的开源项目,实现了如上所述的MapReduce编程模式。作为一个在该项目中全职开发了六年的工作者,我通常会将它细分为以下几个部分:
- 提供给最终用户使用的 MapReduce API ,用来编写MapReduce应用程序。
- MapReduce框架 ,用来实现运行时的各个阶段,即map、sort/shuffle/merge、reduce。
- MapReduce系统 ,一个完整的后端系统,用来运行用户的MapReduce应用程序,管理集群资源,调度上千个并发脚本。
这样的划分可以带来非常明显的优势,即最终用户只需关心MapReduce API,而让框架和后端系统去处理资源管理、容错、调度等细节。
目前,Apache Hadoop MapReduce系统由一个JobTracker和多个TaskTracker组成,也分别称他们为master和slave节点。
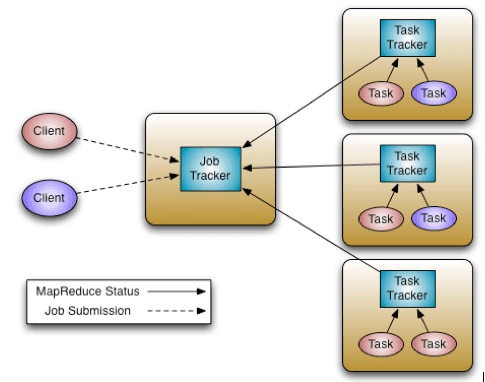
JobTracker负责的工作包括资源管理(即管理工作节点TaskTracker),跟踪资源消耗和可用情况,以及每个脚本的生命周期(脚本调度,进度跟踪,容错等)。
TaskTracker的职责比较简单:根据JobTracker的指令来启动和关闭工作进程,并定时向JobTracker汇报处理进度。
其实很早我们就意识到Hadoop的MapReduce框架需要被拆解和调整,特别是JobTracker,我们需要提升它的可扩展性,提高对集群的利用率,让用户能够方便地进行升级(即用户需要的敏捷性),并能支持MapReduce以外的脚本类型。
长久以来,我们都在做修复和更新,如近期加入的JobTracker高可用和HDFS故障恢复(这两个特性都已包含在Hortonworks Data Platform v1中)。但我们渐渐发现,这些特性会增加维护成本,而且并不能解决一些核心问题,如支持非MapReduce脚本,以及敏捷性。
为什么要支持非MapReduce类型的脚本?
MapReduce对大部分应用程序来说已经足够,但仍有一些场景并不适用,如图形计算(Google Pregel /Apache Giraph)、交互式建模(MPI)。当所有的企业数据都已存放在Hadoop HDFS中时,支持多种处理模型就变得额外重要。
此外,MapReduce本质上是以批量处理为核心的,对于日益增长的实时和近实时处理的客户需求,如流式计算以及CEPFresil等,就无能为力了。
如果Hadoop能够支持这一特性,企业会从对Hadoop的投资中得到更多回报,因为他们可以减少数据迁移所需要的管理和维护成本。
为何要提升可扩展性?
根据摩尔定律,同样的价格所能购买到的计算能力一直在大幅上升。让我们看看以下两组数字:
- 2009年:8核CPU,16GB内存,4x1TB硬盘;
- 2012年:16核以上的CPU,48至96GB内存,12x2TB或12x3TB的硬盘。
同样价格的服务器,其各方面的计算能力要比两到三年以前提升了两倍。Hadoop的MapReduce在2009年便能支持约5000台节点,所以随着机器性能的提升,对其高可扩的要求也与日俱增。
集群资源利用率不高的典型症候是?
在现有的系统中,集群由节点组成,节点上有map槽位和reduce槽位,两者不能互相替代。这样一来,很有可能map槽位已经耗尽,而reduce还是空闲的,反之亦然。修复这一问题对于提升集群资源利用率来说是必不可少的。
敏捷性为何重要?
在现实应用中,Hadoop通常会部署在共享的、多租户的系统上。所以,对Hadoop进行升级时会影响很大一部分甚至是所有的应用。基于这一点,用户会对升级持保守态度,因为不想因此引发一系列的问题。所以,一个支持多版本Hadoop的架构就变得非常重要。
Apache Hadoop YARN 诞生
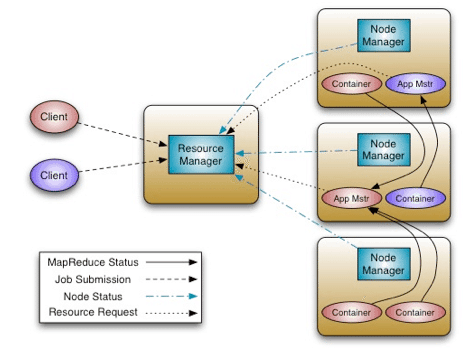
YARN的核心思想是将JobTracker的两个职能,即资源管理和脚本调度/监控,分解为两个独立的组件:全局ResourceManager以及按应用拆分的ApplicationMaster(AM)。
主节点的ResourceManager以及其它节电的NodeManager(NM),形成了一个新的更为通用的分布式应用管理模式。
ResourceManager负责应用程序的资源分配。ApplicationMaster会和ResourceManager进行协商,并与节点上的NodeManager协作,运行和监控每个工作进程。
ResourceManager的调度器是可定制的,能够根据计算能力、队列大小进行资源调配。调度器不包含任何对工作进程的监控和跟踪,不会去重启失败的脚本。调度器会根据应用程序申请的资源进行分配,它是建立在一个资源容器抽象层(Resource Container)之上的,其中包括了内存、CPU、硬盘、网络等要素信息。
NodeManager运行在每个节点之上,负责运行应用程序的工作进程,监控它们的资源占用情况,并向ResourceManager汇报。
每个应用都会有一个专属的ApplicationMaster,它会负责和调度器协商资源分配,跟踪工作进程的状态和进度。ApplicationMaster本身也是以一个工作进程来运行的。
以下是YARN的架构图:
值得一提的是,我们在为YARN开发MapReduce API时没有做任何较大的改动,所以现有的程序可以很方便地进行迁移。关于这点我们会在以后的文章中详述。
//下一节我们会深入了解YARN的架构,阐述它所带来的各种优点,如高可扩、支持多类型脚本(MapReduce、MPI等),以及它是如何提升集群资源利用率的。

