
- 1stm32串口通信,收发字符串,并对其进行解析_stm32串口接收字符串
- 2节点内DataNode磁盘使用率不均衡处理指导_dfs.datanode.fsdataset.volume.choosing.policy
- 3hadoop、hive、hbase的区别_hadoop hive 区别
- 4解决偶尔Github打开慢的问题
- 5如何写小说_操妣
- 6实时局部建图的深入思考 | MapTR继往开来的18篇论文剖析!
- 7野火FPGA跟练(四)——串口RS232、亚稳态
- 8C语言实现堆排序
- 9dockerfile详解_不依赖docker服务解析dockerfile
- 10江协科技/江科大-STM32入门教程-15.TIM输入捕获_什么情况下输入引脚发生指定电平跳变
漫谈 Flink Source 接口重构_sourcecontext 是同步的吗
赞
踩
对于大多数 Flink 应用开发者而言,无论使用高级的 Table API 或者是底层的 DataStream/DataSet API,Source 都是首先接触到且使用最多的 Operator 之一。然而其实从 2018 年 10 月开始,Flink 社区就开始计划重构这个稳定了多年的 Source 接口[1],以满足更大规模数据以及对接更丰富的 connector 的要求,另外还有更重要的一个目的: 统一流批两种计算模式。重构后的 Source 接口在概念和使用方式上都会有较大不同,无论对 Flink 应用开发者还是 Flink 社区贡献者来说都是十分值得关注的,所以本文将从”为什么要这样设计”的角度来谈谈 Source 接口重构的前因后果。这会涉及到较多的底层架构内容,要求读者有一定的基础或者有探索的兴趣。
现有 Source 接口
目前(Flink 1.9)Source 接口分为 DataStream/DataSet/Table API 三个不同的栈,但因为 Table API 是基于前两者的封装,我们在讨论底层接口的时候可以先排除掉它。Source 接口在 DataStream/DataSet API 中同样是负责数据的生成或摄入,但除此之外的功能有不小的差异。
DataStream API
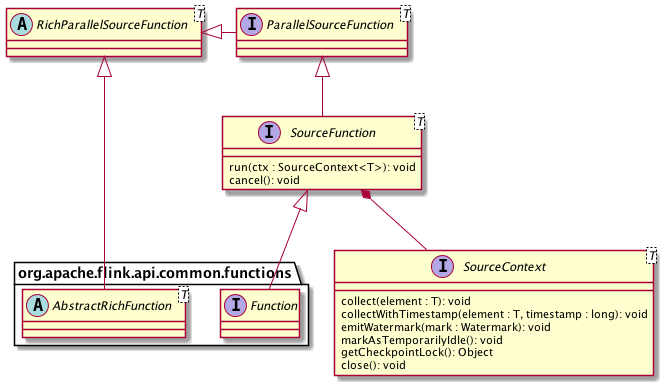
在 DataStream API 中 Source 对应的核心接口为 SourceFunction 以及 SourceContext。前者直接继承 Function 接口与 Operator 交互,负责通用的状态管理(比如初始化或取消);后者代表运行时的上下文,负责与单条记录级别的数据的交互。此外还有其他一些辅助类型的类或接口,整体的类图设计如下:
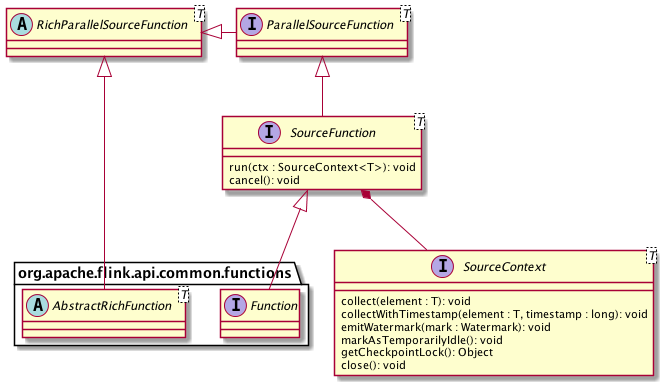
图一. DataStream API 的 Source 接口
其中 ParallelSourceFunction 进一步继承 SourceFunction,标记该 Source 为可并行化的,否则直接实现 SourceFunction 的 Source 的并行度只能为 1。而 RichParallelSourceFunction 则是在 ParallelSourceFunction 基础之上再结合 AbstractRichFunction,提供有状态的并行 Source 基类。用户要实现一个 Source,可以选择 SourceFunction、ParallelSourceFunction 或
RichParallelSourceFunction 中任意一个来作为切入口。但值得注意的是,如果 Source 是有状态的,那么为了保证一致性,状态的更新和正常的数据输出是不可以并行的。为此,SourceContext 提供了 Checkpoint 锁来方便 Source 进行同步阻塞。
运行时,Source 主要通过 SourceContext 来控制数据的输出。从 SourceContext 接口的方法即可以看出,Source 在接受到数据后的主要工作有以下几点:
- 从外部摄入数据或生成数据,输出到下游。
- 为数据生成 Event Time Timestamp(仅在 Time Characteristic 为 Event Time 时有用),比如 Kafka Source 的 Partition 级别的 Event time。
- 计算 Watermark 并输出(仅在 Time Charateristic 为 Event Time 时有用)。
- 当暂时不会有新数据时将自己标记为 Idle,以避免下游一直等待自己的 Watermark。
DataSet API
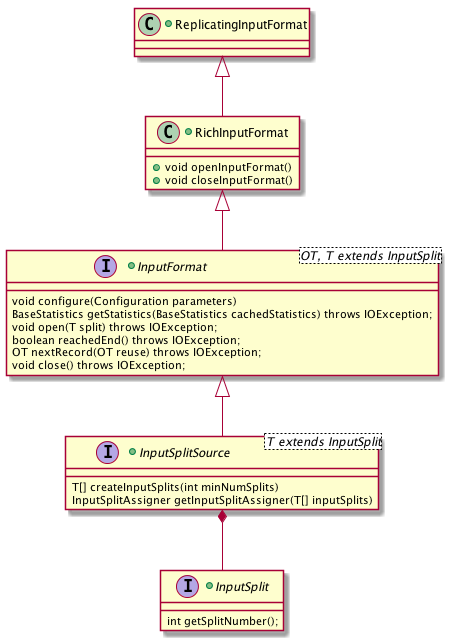
在 DataSet API 中 Source 对应的核心接口为 InputFormat。InputFormat 命名风格上借鉴了 Hadoop 的风格,在功能上也比较相近,具体有以下三点:
- 描述输入的数据如何被划分为不同的 InputSplit(继承于 InputSplitSource)。
- 描述如何从单个 InputSplit 读取记录,具体包括如何打开一个分配到的 InputSplit,如何从这个 InputSplit 读取一条记录,如何得知记录已经读完和如何关闭这个 InputSplit。
- 描述如何获取输入数据的统计信息(比如文件的大小、记录的数目),以帮助更好地优化执行计划。
第 1、3 两点功能会被 JobManager (JobMaster) 在调度 Exection 时使用,而第 2 点读取数据功能则会在运行时被 TaskManager 使用。
围绕 InputFormat,DataSet 还提供一系列接口,总体的类图如下:
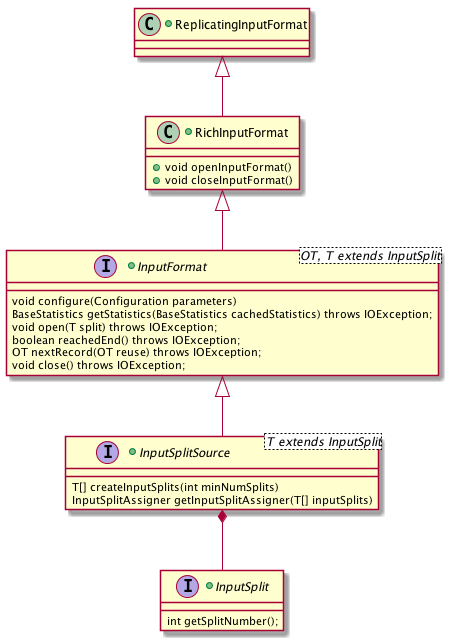
- InputSplitSource 为 InputFormat 的超类,负责划分 InputSplit (第一点功能),不再赘述。
- InputSplit 表示一个逻辑分区,必要的信息其实只有 Split 的 ID(或者下标),InputFormat 会根据这个 ID 来读取输入数据的对应分区。
- RichInputFormat 拓展 InputFormat,加上
openInputFormat()和closeInputFormat()方法来管理运行时的状态。比起 InputFormat 的open()和close()是在每个 InputSplit 级别调用,它们是在每次 Task Exectuion 级别调用,而每次 Task Exectuion 可以读多个 InputSplit。比如 TaskManager 要读取 HBase Table,那么它要打开和关闭一个 HTable 的连接,这个连接可以在多读多个 TableInputSplit 时复用。 - ReplicatingInputFormat 拓展 RichInputFormat,为输入数据提供广播的能力。换句话说,通过 ReplicatingInputFormat 输入的数据会被每个实例重复读取,典型的应用是 Join 操作。
有趣的是,除了上述典型的 DataSet 场景,InputFormat 还可以在 Streaming 场景中使用。通过 StreamExecutionEnvironment#createInput(InputFormat),Flink 可以持续监控一个文件系统目录。InputFormat 会被传递给 ContinuousFileReaderOperator,后者是一个非并行化的算子(并行度只能为 1),会将目录新增的文件作为 FileInputSplit 传递给下游的 ContinuousFileReaderOperator,然后 ContinuousFileReaderOperator 再使用 InputFormat 来读取这些 InputSplit。所以虽然架构设计上不是特别一致,但 InputFormat 一定程度上是体现了流批统一的思想的。
存在的问题
不符合流批一体要求
首先,目前的 Source 接口栈最显而易见的问题 DataStream 和 DataSet 在 API 设计上的不统一。这个很大程度上是出于历史原因,在 Flink 最初开发之时业界普遍认为批处理和流处理是相对独立的,而直到 2016 年 Google 《The Dataflow Model》等文章的发表,业界才有比较完整的理论支持来统一两者。所以 Flink 社区当时分离开 DataStream 和 DataSet 来分别迭代开发也十分正常,但这也成了流批融合的新趋势下的负担。
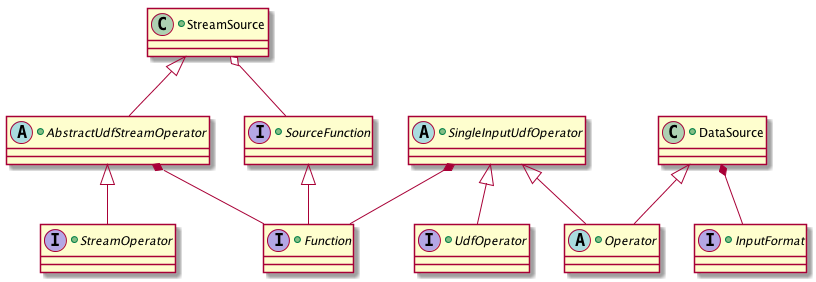
现在的状况是 DataStream 和 DataSet 共享很多相同的代码,比如面向用户代码 UDF 的基础接口 Function 或计算逻辑的通用 RichFunction 都代码在 flink-core 中,但分场景使用的代码则分别存在于 flink-java 和 flink-streaming-java 中。典型的是两者在 Operator 上也是不同的,前者使用 org.apache.flink.api.java.operators.Operator 作为基类,而后者使用的是 org.apache.flink.streaming.api.operators.StreamOperator。StreamSource 和 DataSource 是 DataStream 和 DataSet 代表数据源的 Operator,它们分别封装了上文所说的 SourceFunction 和 InputFormat 两个接口。总体的关系大致如下(省去了部分非关键的类或接口)。
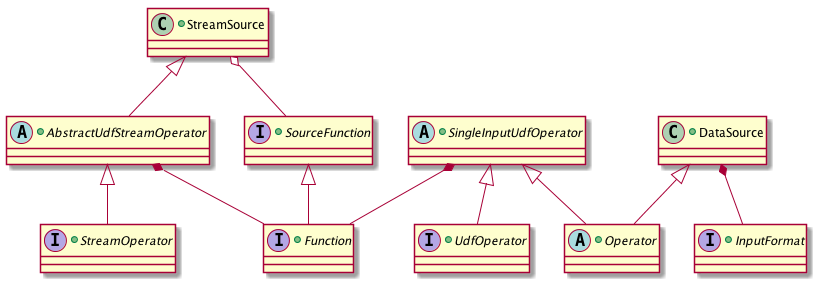
图三. DataStream 与 DataSet Source 接口的关系
从图中可以方便地看到一个很不协调的地方便是 StreamSource 属于 AbstractUdfStreamOperator,因此可以直接使用 Function 接口,但是 DataSource 却不属于 SingleInputUdfOperator (这里应该是 AbstractUdfOperator 才合理,但 DataSet API 没有提供这层抽象),因此具体的读取数据源逻辑不是写在 Function 中,而是写在 InputFormat 中,这就造成需要为同一种外部存储系统开发维护两套重复性很高 Source。
不便动态发现数据源变更
分布式存储系统通常都以某种”存储块”的方式来实现水平拓展,这种”存储块”在不同系统中有不同的命名,常见的有 Split/Partition/Shard,下游的计算引擎也会按照这些”存储块”的粒度进行工作分配。
在批处理计算中,输入数据源以作业启动时读取的元数据为准, Split 的数目不会在运行时改变,不需要动态监控数据源变化,但需要根据 TaskManager 处理的进度来动态分配 Split。因此 Flink DataSet 的做法是抽象出 Split Assigner(属于 InputFormat 的一部分)。作业启动时 Split Assigner 会读取数据源的元数据,随后一直运行在 JobManager 端负责将现有 Split 分配给空余的 TaskManager,直至所有的 Split 都完成处理 。
而实时流处理则却通常要动态发现新增的 Split,然后分配到现有的 TaskManager 上,比如 Kafka 的 Partition Discovery,同时也需要动态分配新 Partition 这样的一个机制。通常来说 Source 需要在初始化时新建一个线程来负责检测数据源的变更,若有则需要重新调整工作分配。不过与 DataSet 统一 JobManager 端中心化分配不同,DataStream 做动态检测的线程运行在每个 TaskManager 上,新发现的 Partition 是依靠每个 SubTask 按预先的规则分配。这样背后的原因是,InputFormat 设计了一部分逻辑运行在 JobManager 上,而 SourceFunction 则完全运行在 TaskManager 上,缺乏一个中心化的管理者。
不便 Source Subtask 间的协作
不同于 DataSet 中 Source Subtask 之间几乎是完全独立的,DataStream 中 Source Subtask 通常需要某种程度上的协作,比如不同 Subtask 之间的 Event Time 对齐。
Event Time 对齐的背景是 Subtask 间的 Event Time 进度可能是不同的,但下游 Watermark 总是取最低者,这就导致对于基于 Watermark 的算子来说,它一直从 Event Time 快的 Subtask 摄入数据但这些数据总是得不到清理,进一步造成该算子的 State 逐渐膨胀。
解决这个问题的思路是,在一个 Source Subtask 自己 Event Time 明显先进于其他 Source Subtask 时,与其继续摄入数据并让下游自己缓存,不如直接阻塞自己的消费来等其他 Source Subtask 跟上,这就称为 Event Time 对齐。
Event Time 对齐要求 Source Subtask 间的协作,通常需要在 Master 节点上新增一个协调者(Coordinator),由协调者来管控 Split/Partition 的元数据(这点在目前的 SourceFunction 接口上是做不到的),来判定某个 Source Subtask 是否需要阻塞。另外,相似的协作需求还有 Work Stealing 等。
容易造成瓶颈的 Checkpoint Lock
在 DataStream 作业中,为了保证 State 更新和输出记录的一致性,两者是要通过 Checkpoint Lock 来进行同步的。SourceFunction 可以通过 SourceContext 来获取 Checkpoint Lock,例如如下代码:
- public void run(SourceContext<T> ctx) {
- while (isRunning) {
- synchronized (ctx.getCheckpointLock()) {
- ctx.collect(count);
- count++;
- }
- }
- }
而问题在于这个锁并不是公平锁,也就是说 SourceFunction 有可能一直占据 Checkpoint Lock 导致 Checkpoint 被阻塞。另外这种比较重度的锁也不符合 actor 或者说 mailbox 模式的非阻塞设计。
线程缺乏统一管理
在 DataStream 应用中,Source 通常会需要一些 IO 线程来避免阻塞 Task 主线程,而这些线程目前是每个 Source 独立实现,这就造成各个 Source 需要自己设计复杂的线程模型。比如常用的 Kafka Connector,每个 FlinkKafkaConsumer 会额外启动一个 Fetcher 线程负责调用 Kafka Consumer API 进行消费,然后通过阻塞队列交给 TaskThread 来进行消费。
改进思路
统一流批 Source 接口
作为统一流批处理算子的最前一环,Source 接口首先需要被按照 Flink 推崇的”批处理是流处理的特例”的思想重新设计。按照社区长期目标,Flink 会新增 BoundedDataStream 来逐步取代 DataSet,而 BoundedDataStream 基于目前的 DataStream API,算子基本可以复用。
按照 FLIP-27,新的 Source 接口暂停名为 Source,它类似一个工厂类,主要构造 SplitEnumerator 和 SplitReader(该两者的作用将在下一节提及),并且可以同时为流批服务。Source 的使用方式将大致如下:
- ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
-
- FileSource<MyType> theSource = new ParquetFileSource("fs:///path/to/dir", AvroParquet.forSpecific(MyType.class));
-
- // The returned stream will be a DataStream if theSource is unbounded.
- // After we add BoundedDataStream which extends DataStream, the returned stream will be a BoundedDataStream.
- // This allows users to write programs working in both batch and stream execution mode.
- DataStream<MyType> stream = env.source(theSource);
-
- // Once we add bounded streams to the DataStream API, we will also add the following API.
- // The parameter has to be bounded otherwise an exception will be thrown.
- BoundedDataStream<MyType> batch = env.boundedSource(theSource);
独立出数据源的工作发现和分配值得注意的是,ExecutionEnvironment 将根据 Source#isBounded 直接返回 DataStream 或者 BoundedDataStream,无需用户切换 Environmnet。
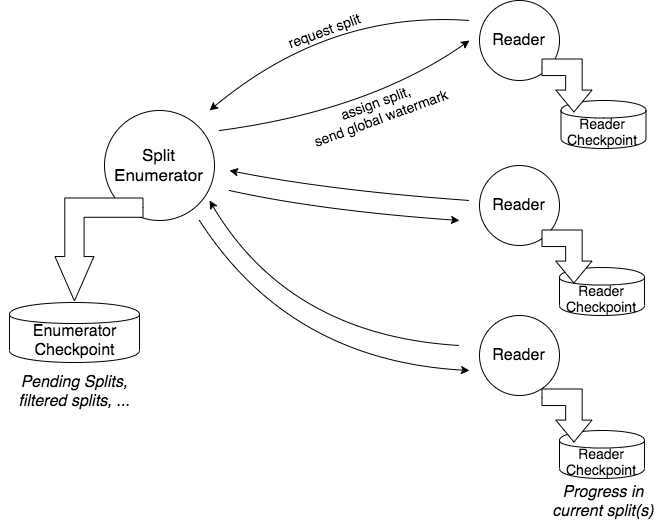
在底层,Source 构造出的 SplitEnumerator 和 SplitReader 将分别负责发现和分配 Split 和 Split 的实际读取处理。相比之下,目前在 DataSet API 中的发现和分配 Split 由 JobManager 统一负责,而 DataStream 的对应工作则由 TaskManager 各自完成。
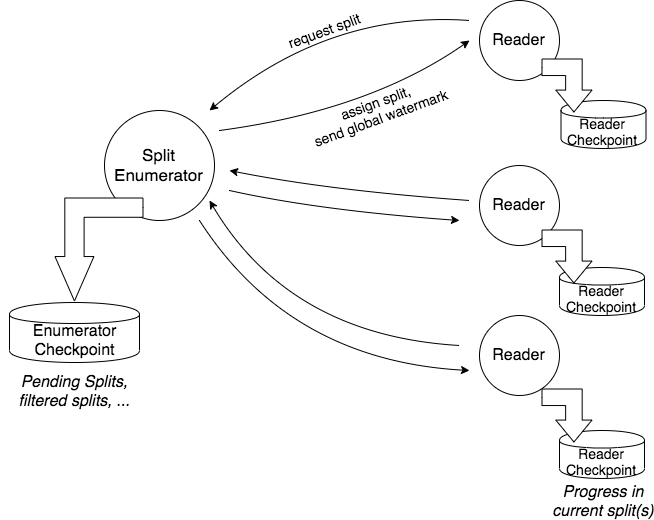
图四. SplitEnumerator 和 SplitReader
SplitEnumerator 在作业启动时以单并行度运行,读取数据源元数据并构建 Split,按照分配策略将 Split 分配给 SplitReader,类似于现在 InputFormat 构造的 SplitAssigner,但不同点在于还要额外管理 DataStream 的管理工作,比如 Checkpoint 和 Watermark。SplitEnumerator 有三种现实方案: 运行在 JobManager 上(目前 SplitAssigner 的做法),或者以一个单并行度 Task 的方式运行在 TaskManager 上(类似目前 ContinuousFileMonitoringFunction 的做法),或者以一个新独立组件的方式运行。目前社区是比较偏向使用独立组件的方式,但未完全确定。感兴趣的读者可以研究下各种方案的优劣,相信可以从中学到不少东西。
SplitReader 负责的工作则类似目前 DataStream 的 SourceFunction,不同点在于除了被动地接受 Split,SplitReader 还可以主动向 SplitEnumerator 请求 Split,这主要是满足批处理场景的需求。
通过这样的清晰分工,Source 的抽象性大大提升,新 Source 的开发和现有 Source 的迭代都更有规范可遵循,对用户来说也更容易理解。
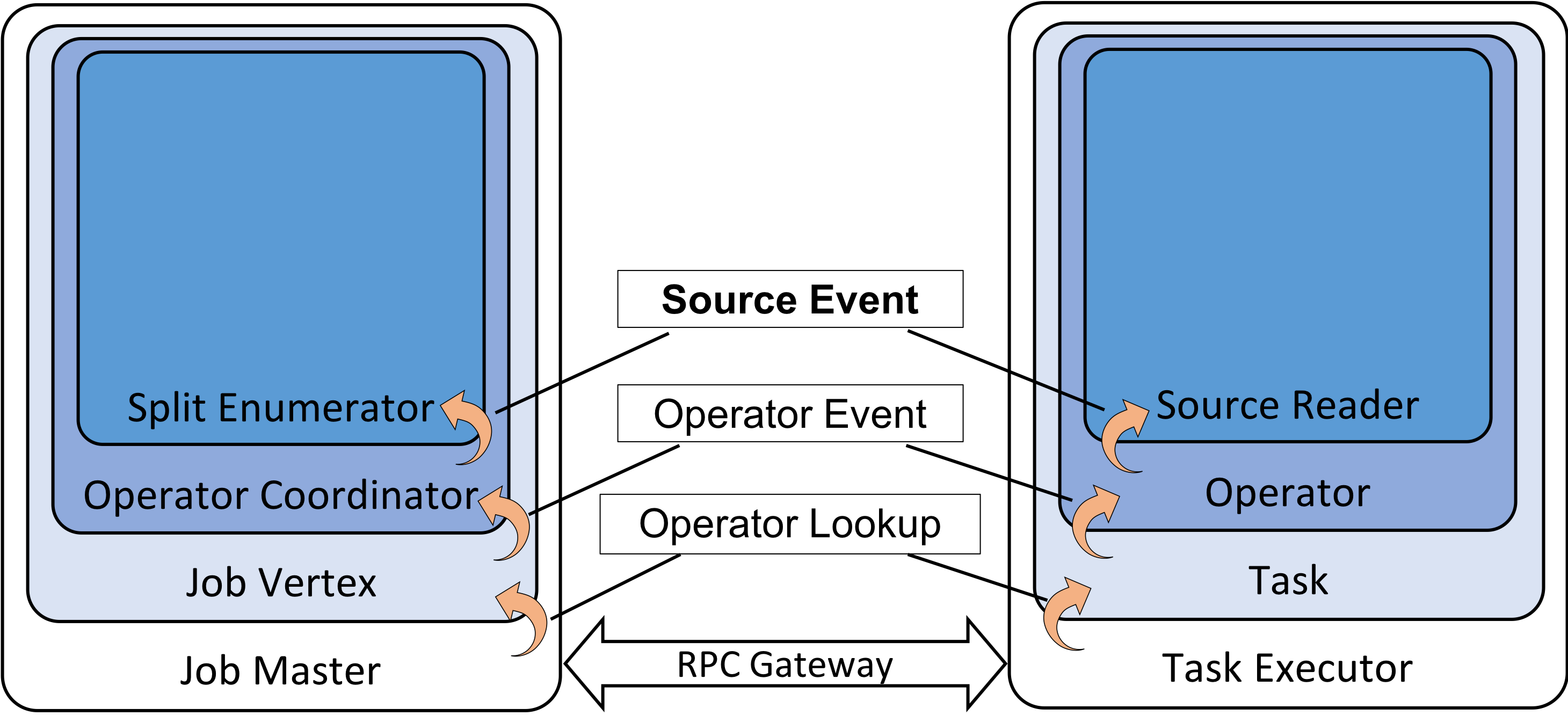
新增 Source Subtask 间的通信机制
按照新架构,在运行期间 SplitEnumerator 和 SplitReader 不时会需要通信协作,比如分配新 Split 或 Event Time 对齐。这个通信将复用大部分现有的 JobManager 和 TaskManager 的 RPC 机制(基于 SplitEnumerator 以独立组件运行在 JobManager 端的方案),在这基础上加上 Operator 级别的协调者,比如上文提到的 Source 协调者。

其中 SourceEvent 是 SplitEnumerator 和 SplitReader 通信的消息,比如 SplitEnumerator 新分配 Split 或者 SplitReader 处理完已分配 Split 主动请求新 Split。而 OperatorEvent 则是更通用化的 Operator 协调者与 Operator 通信的消息。
SplitReader 线程模型
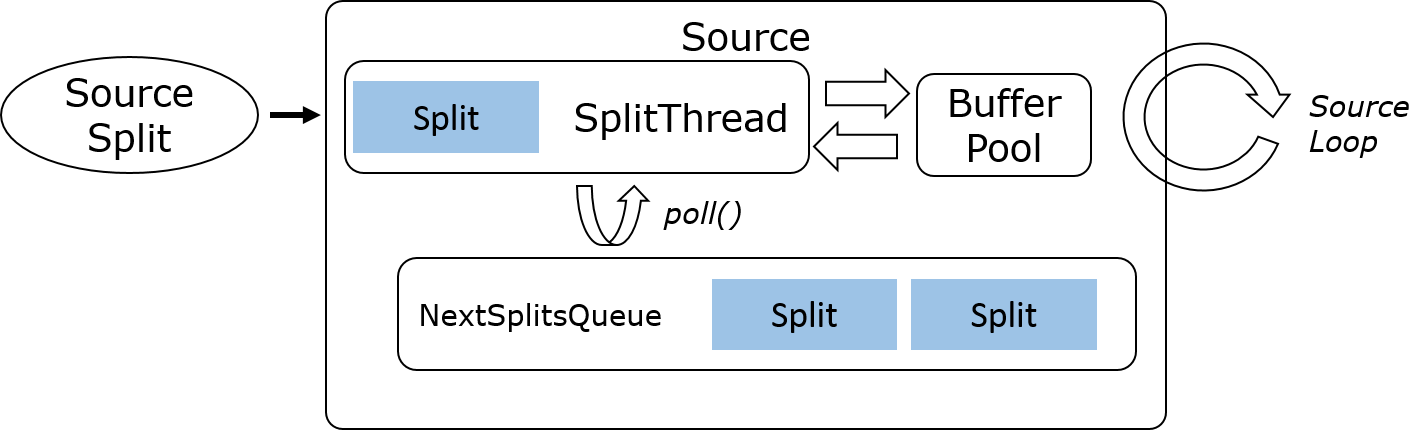
上文提到 Checkpoint Lock 是现在 Source 的瓶颈之一,这是因为 Checkpoint 和计算任务是由不同线程来执行,而新接口将遵循单线程的 actor/mailbox 模式,所以不再需要 Checkpoint Lock 来同步线程。
根据 FLIP-27 的设计,SplitReader 将调用外部存储系统客户端 API 读取数据,转换为目标数据类型后,push 到一个缓冲区(Buffer 或者 Queue),然后 Flink 内部的 Source Loop 线程再读取这个缓冲中的数据。
根据外部存储系统客户端的 API 调用方式(阻塞、非阻塞、异步)和 Flink 执行模式(流处理/批处理)的不同,Source 可以分为以下几种模式:
1) 单 Split 串行
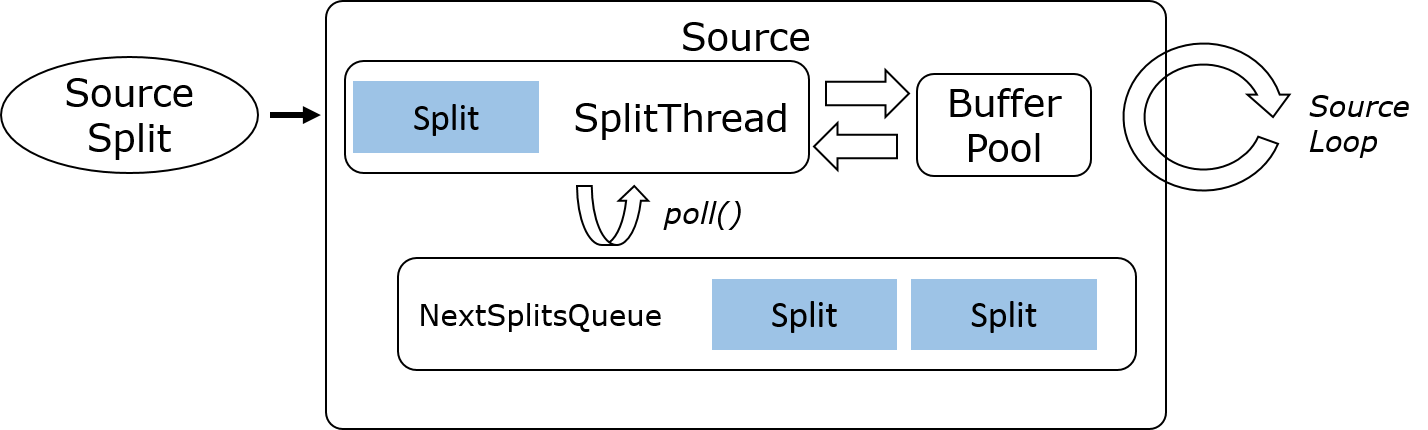
这种模式通常符合批处理场景,比如 File Source、Database Source。工作流程是作业启动时 SplitEnumerator 会将 Split 分配到每个 SplitReader 的 Split Queue 中,然后 SplitReader 会逐一串行处理,并输出到 Buffer 供后续线程读取。
2)多 Split 多路复用

多 Split 多路复用通常适用于流处理场景一个客户端可以处理多个 Split 的情况。典型的例子就是单个 Kafka Consumer 可以消费多个 Topic 的多个 Partition。工作流程是作业启动时 SplitEnumerator 会批量分配现有 Split 给 SplitReader,后者启动一个 IO 线程读取所有的 Split,处理后输出到 Buffer 或 Queue 供后续线程读取。
3) 多 Split 多线程
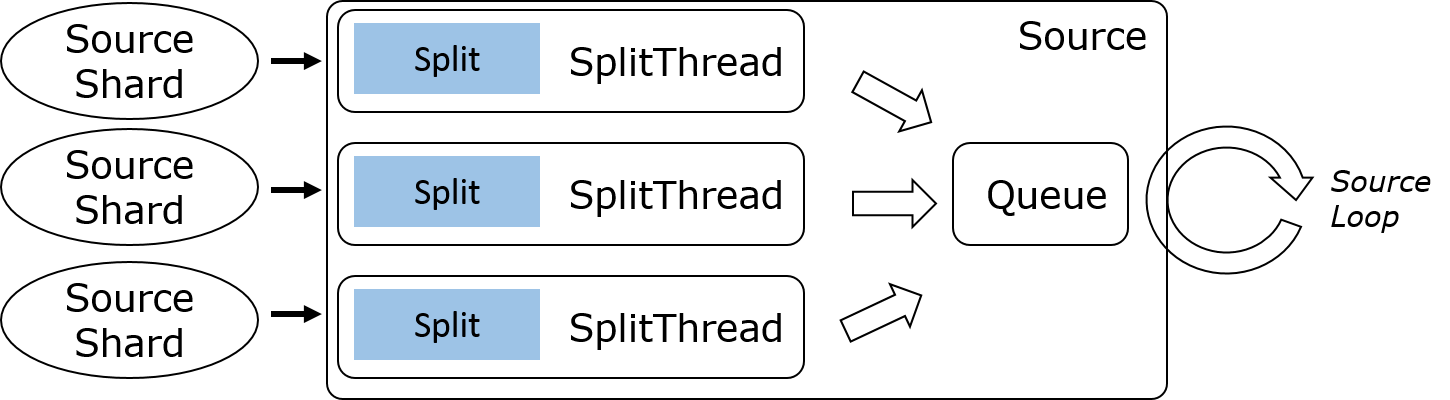
多 Split 多线程通常适用于流处理场景每个客户端只处理单个 Split 的情况,比如 Kinesis Consumer 会为每个 Kinesis Shard 单独起一个线程来读取数据。工作流程类似于 Kafka,不过每条 IO 线程都有单独的输出队列,这样下游可以选择性地读取某个 Shard 的数据,这对于 Event Time 对齐的特性十分重要。
总结
综上所述,目前的 Source 接口不符合流批的发展趋势,同时因为缺乏 Flink 引擎内置线程模型的支持,开发新的 Source 和为现有 Source 开发 Event Time 对齐等功能都十分不方便。为此 Flink 社区起草了 FLIP-27 来重构 Source 接口,核心是统一流批两种执行模式的 Source 架构,但底层的调度和算法则根据 Source 类型来判断。新接口的核心是 SplitEnumerator 和 SplitReader,前者负责发现和分配 Split、触发 Checkpoint 等管理工作, 后者负责 Split 的实际读取处理。此外,新增 Operator 间的通信机制,让 Source Subtask 之间可以协调完成 Event Time 对齐等新特性。最后,SplitReader 底层封装了通用的线程模型,相比目前的 SourceFunction 大大简化了 Source 的实现。


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
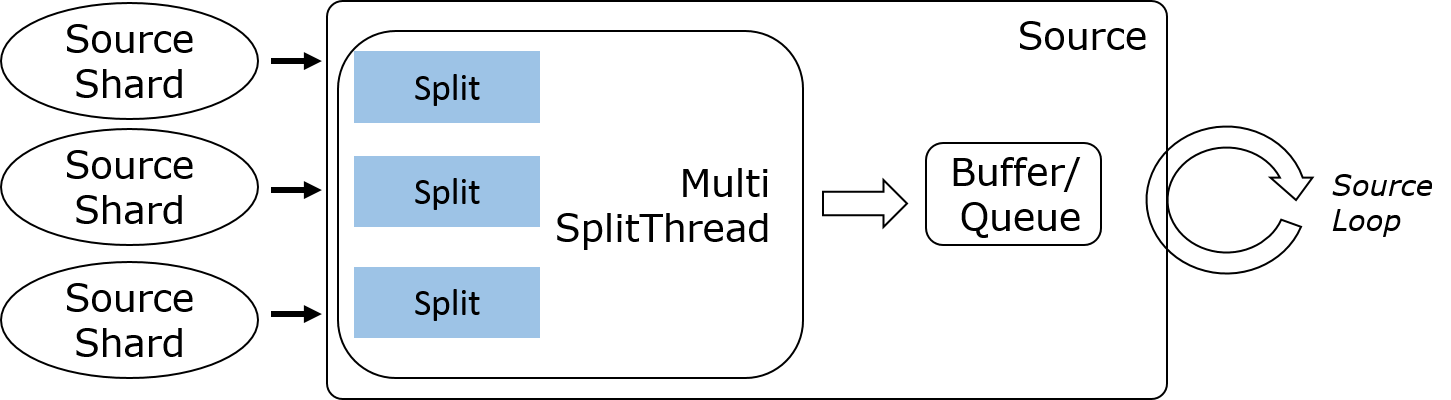{kind=link}
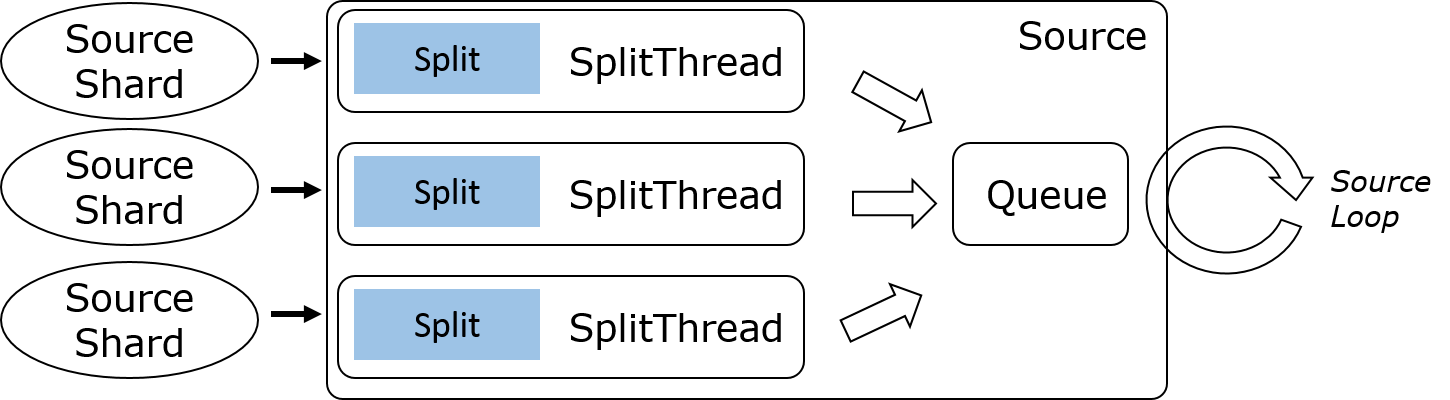{kind=link}