
- 1【大模型应用开发 动手做AI Agent】Agent的各种记忆机制_ai- agent 记忆
- 2Dev++软件连接Sqlite
- 3制作目标检测数据集入门到精通(一)常用数据集(及下载数据网站)汇总_ai目标提取 金属数据集
- 4PostgreSQL 事件触发器_postgres 触发器
- 5Pytorch学习笔记(深度之眼)(4)之模型容器_pytorch中imgs.view函数
- 60基础在ROS系统中实现RRT算法(三)RVIZ中用arbotix控制机器人运动_ros导航中可以不依据栅格地图实现rrt算法的路径规划吗
- 7Oracle学习XII —— Oracle集合运算_oracle 集合运算
- 8流程表单设计器开源优势多 助力实现流程化!
- 9【Py/Java/C++三种语言OD独家2024D卷真题】20天拿下华为OD笔试之【DP】2024D-抢7游戏【欧弟算法】全网注释最详细分类最全的华为OD真题题解
- 10PostgreSQL中的事件触发器,用途多多_pg查询表上的触发器
Spark环境配置与安装_第2关:安装与配置spark开发环境
赞
踩
目前,CSDN博文搜索有时候看不到博文发表时间,如果以后能像百度学术那样有搜索的时间范围选项不知道会不会更好一点。虽说百度也收录了CSDN博文,可以搜到。
前提,官网说明要先安装配置好java8或者java11。
此处,博主安装在已经配置好Hadoop伪分布的虚拟机Linux上,Hadoop2.7.3,Java1.8.x。
参考网文,首先安装Scala:
Linux命令行,mkdir /usr/scala
不知道为什么,官网下载按钮点击以后没有下载。
于是,选择在博文自制Spark安装详细过程(含Scala)看到的链接,下载2.11.7版本的Scala。
在下载压缩包的目录下解压并移动到目标目录,tar -xf scala-2.11.7.tgz ,mv scala-2.11.7 /usr/scala
注:想给文件改名在同一目录下 mv scala-2.11.7.tgz scala,scala不要提前建好,不然就变成目录嵌套了。语句mv scala-2.11.7 /usr/scala执行后,效果/usr/scala/scala-2.11.7。博主后来改了文件名字,将scala解压内容放到了/usr/Spark/scala下。
配置环境变量,vim /etc/profile,文件末尾添加export PATH=$PATH:/usr/Spark/scala/bin,建议加个注释,以后自己能看懂,如下:
# added by AnXining 2020.6.5
export PATH=$PATH:/usr/Spark/scala/bin
- 1
- 2
每次修改完环境变量,记得要source /etc/profile
检查配置是否成功,scala -version
然后,安装Spark:
官网选择与Hadoop2.7.x对应版本,此处博主选择spark-3.0.0-preview2-bin-hadoop2.7.tgz,由链接跳转到了一个镜像选择页面。


将spark解压并移动到/usr/Spark中,解压内容在/usr/Spark/spark目录下,接着配置环境变量vim ~./.bash_profile,文件尾部添加:(第一次被动插入代码片段,因为忽然发现无法输入$符号)
export SPARK_HOME=/usr/Spark/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin在这里插入代码片
- 1
- 2
source ~/.bash_profile
Spark文件配置:
将slaves.template改名为slaves
cd /usr/local/spark/conf //配置文件所在目录
mv slaves.template slaves //修改为spark可识别文件
- 1
- 2
修改slaves文件,vim slaves
注:本次伪单机分布式,暂时不加slave,不做改动
将spark-env.sh.template改名为spark-env.sh,mv spark-env.sh.template spark-env.sh
修改slaves文件,vim spark-env.sh
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.147.147
- 1
- 2
- 3
以上按照自己的安装路径以及ip填写,ifconfig查看ip
启动Hadoop和Spark,/home/hadoop/hadoop/sbin/start-all.sh,/usr/Spark/spark/sbin/start-master.sh
jps命令查看启动状态
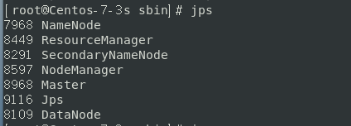
打开主节点浏览器,输入http://localhost:8080/,例如:
http://192.168.147.147:8080/
 输入spark-shell打开操作窗口
输入spark-shell打开操作窗口


